简单-快速-高效——模块化解析controlnet网络结构
资源
-
ControlNet论文:Adding Conditional Control to Text-to-Image Diffusion Models
-
官方项目:lllyasviel/ControlNet: Let us control diffusion models
-
ControlNet 1.1项目地址:lllyasviel/ControlNet-v1-1-nightly
-
diffusers框架的ControlNet训练脚本:diffusers/examples/controlnet
参考讲解
-
https://blog.csdn.net/jarodyv/article/details/132739842
-
https://www.zhangzhenhu.com/aigc/controlnet.html#id11
-
https://zhuanlan.zhihu.com/p/660924126
简介
controlnet是一种可控图像生成方法,通过添加相应的条件控制图片,来达到生成图像符合控制图像的特征的效果。
文生图模型,依赖文本提示,但对复杂结构(如人体姿态、建筑透视)控制不足,易出现结构扭曲。ControlNet通过引入外部条件信号,将“自由生成”变为“精准控制”,解决结构与内容一致性问题。

核心网络单元
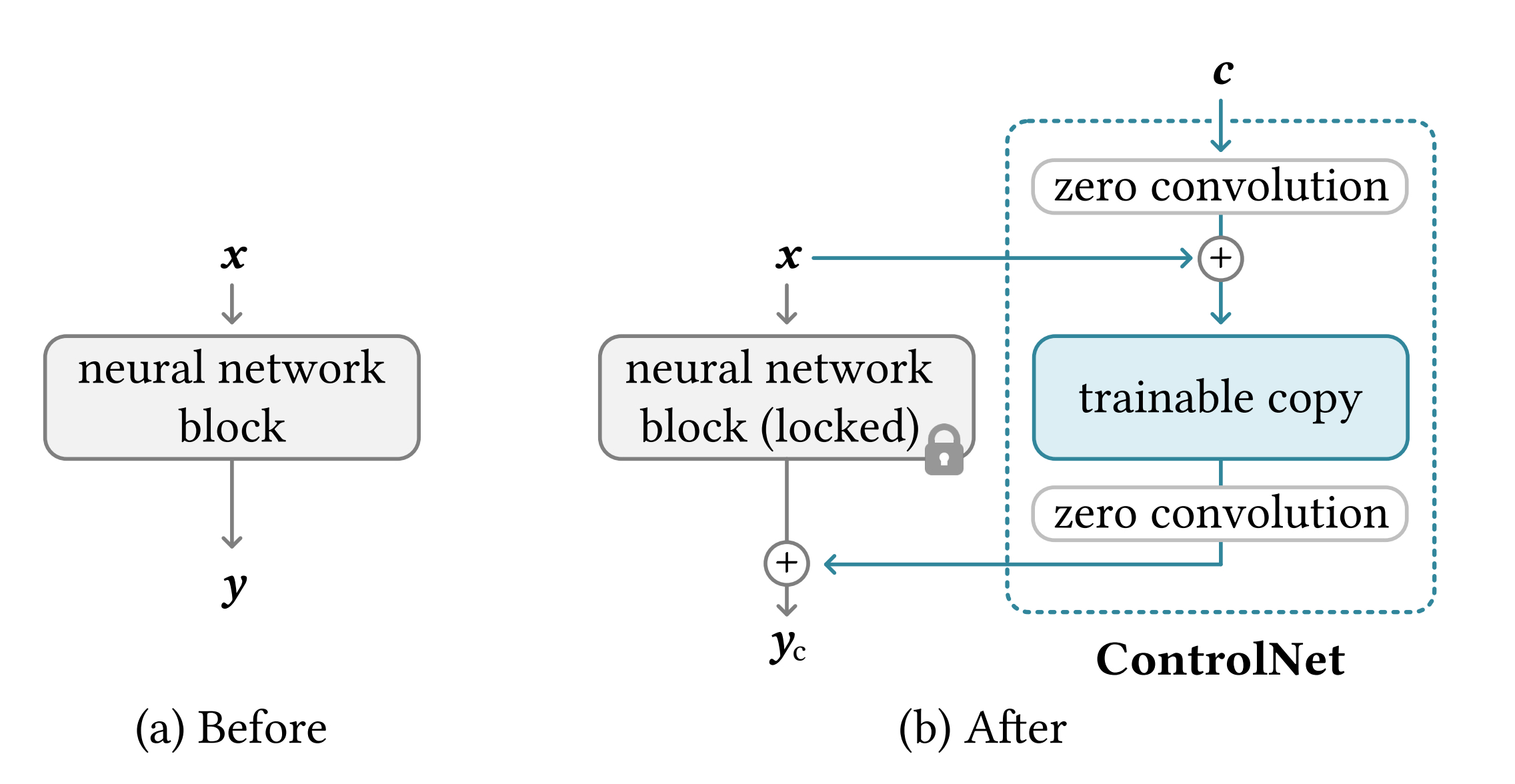
在原始生图模型的基础上,对于生图模型的每个block,controlnet将主模型权重被复制,分为锁定副本与可训练副本,
在“可训练”副本上施加控制条件,然后将施加控制条件之后的结果和原来SD模型的结果相加(addd)获得最终的输出结果。 F o u t = F m a i n + α ⋅ Z e r o C o n v ( F c o n t r o l ) F_{out} = F_{main}+\alpha\cdot ZeroConv(F_{control}) Fout=Fmain+α⋅ZeroConv(Fcontrol),其中α为控制强度系数
训练过程中“锁定”副本中的权重保持不变,保留了Stable Diffusion模型原本的能力。使用额外数据对“可训练”副本进行微调,学习我们想要添加的条件。因为有原始的文生图模型作为预训练权重,所以我们使用小批量数据集就能对控制条件进行学习训练,同时不会破坏生成模型原本的能力。
zeroconv
ControlNet模型的最小单元结构中在复制的训练block前后都添加了ZeroConv,ZeroConv权重矩阵 W 和偏置 b 初始化为全零的1×1卷积
$W {init}=0, b{init}=0 $
这样在一开始训练ControlNet,无论输入条件是什么,控制分支的输出特征在经过ZeroConv模块后输出都为零。
F c o n t r o l = W i n i t ⋅ x + b i n i t = 0 F_{control} = W_{init}\cdot x + b_{init} = 0 Fcontrol=Winit⋅x+binit=0
此时整个模型的输出跟原始的生图模型输出保持一致,也就是完全保留了原始模型的生成能力。之后通过梯度下降,ZeroConv 的权重逐步更新,控制分支的特征 F c o n t r o l F_{control} Fcontrol逐渐增强,实现对生成过程的精准控制。
ZeroConv保证了原始生图模型的基础能力,ControlNet训练也只是在原始模型的基础上进行优化。初始梯度仅来自损失函数对控制分支的微弱需求,梯度更新平缓,避免震荡。能够避免模型过度拟合,并在针对特定问题时具有良好的泛化性,在小规模甚至个人设备上进行训练成为可能。
论文中对核心最小单元的结构进行了对比实验。对比了
ZeroConv+可训练副本
随机初始化+可训练副本
不复制可训练副本几种方式
发现在可训练副本前后添加一个zero conv的控制生成效果是最好的

整体网络结构
以sd模型为例
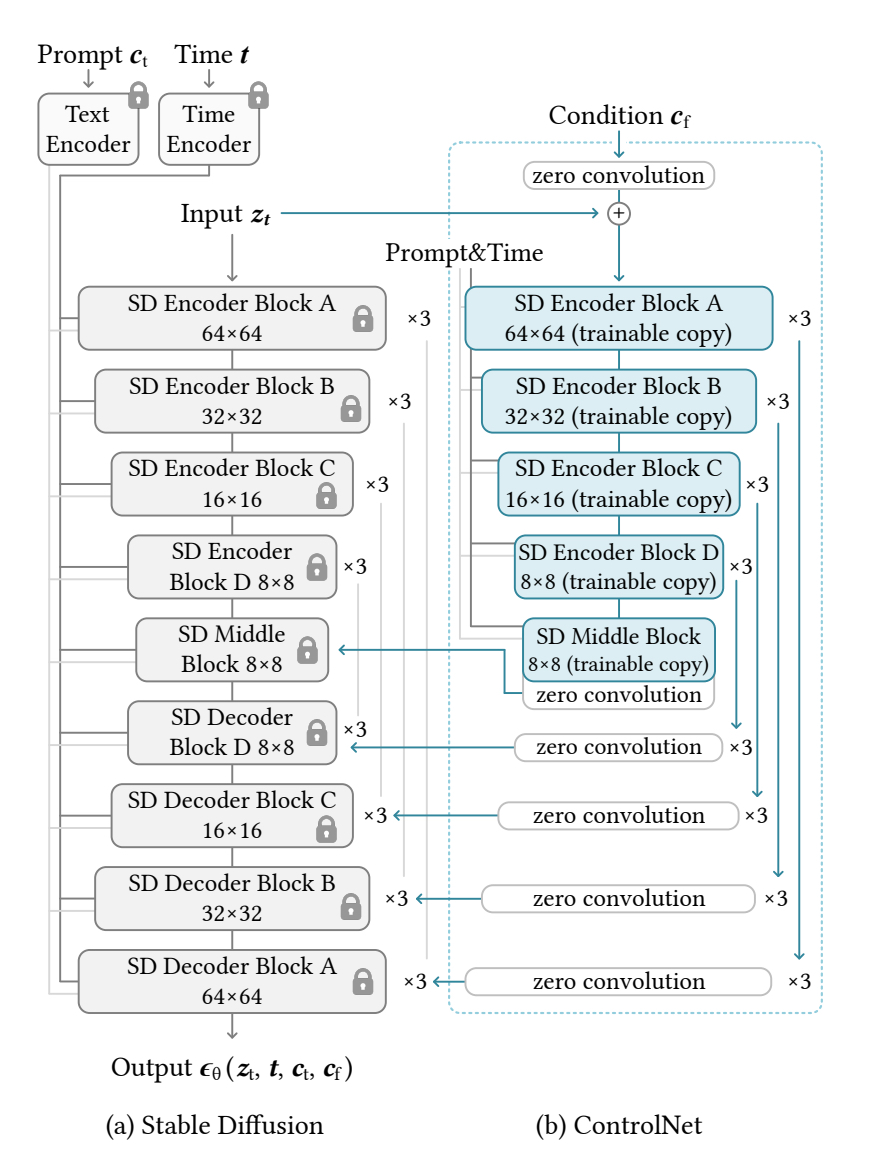
参考模块:stable diffusion的网络结构
因为sd是在隐空间中进行的unet变化,分辨率进行了四倍下采样。所以实际上图中的 c o n d i t i o n C f conditionC_{f} conditionCf是controlnet的参考图片通过了几层卷积进行了4倍下采样后的结果
训练过程
整体来说controlnet只在原本的生图模型的基础上增加了一个模块,整体结构容易理解。
只是将原本的 F m a i n F_{main} Fmain变成了 F o u t = F m a i n + α ⋅ Z e r o C o n v ( F c o n t r o l ) F_{out} = F_{main}+\alpha\cdot ZeroConv(F_{control}) Fout=Fmain+α⋅ZeroConv(Fcontrol)。其中通过α可以控制不同训练阶段controlnet的影响强度。
训练loss上也与原来的训练保持一致,只是在生成噪声预测的过程中增加了一个controlnet条件。只需要将(sd的训练loss)
L SD = E x 0 , ϵ , t [ ∥ ϵ − ϵ θ ( x t , t , c text ) ∥ 2 2 ] \mathcal{L}_{\text{SD}} = \mathbb{E}_{x_0, \epsilon, t} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c_{\text{text}}) \|_2^2 \right] LSD=Ex0,ϵ,t[∥ϵ−ϵθ(xt,t,ctext)∥22]
变成:
L ControlNet = E x 0 , ϵ , t , c [ ∥ ϵ − ϵ θ ( x t , t , c text , c cond ) ∥ 2 2 ] \mathcal{L}_{\text{ControlNet}} = \mathbb{E}_{x_0, \epsilon, t, c} \left[ \| \epsilon - \epsilon_\theta(x_t, t, c_{\text{text}}, c_{\text{cond}}) \|_2^2 \right] LControlNet=Ex0,ϵ,t,c[∥ϵ−ϵθ(xt,t,ctext,ccond)∥22]
在实际训练过程中可以随机用空字符串替换 50% 的文本提示。有助于 ControlNet 更好地理解输入条件图的含义。【参考资料】
