极客说|重大发布:vLLM V1
作者:魏新宇 - 微软 AI 全球黑带高级技术专家
排版:Alan Wang

「极客说」 是一档专注 AI 时代开发者分享的专栏,我们邀请来自微软以及技术社区专家,带来最前沿的技术干货与实践经验。在这里,您将看到深度教程、最佳实践和创新解决方案。关注「极客说」,与行业顶尖专家一起探索科技的无限可能!
参考:https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
从 vLLM V0 中学习
在过去的 1.5 年里,vLLM V0 成功地支持了各种模型、功能和硬件。然而,随着时间推移,系统变得越来越复杂:
-
功能碎片化:不同的功能是独立开发的,缺乏统一的架构。
-
难以整合:由于各个模块之间耦合度高,增加新功能或优化变得困难。
-
技术债累积:代码复杂,维护成本高。
V1 的目标
vLLM V1 的诞生是为了应对这些挑战。其设计目标是:
-
简化代码结构:使代码更加模块化,方便开发和维护。
-
提高性能:减少 CPU 开销,充分利用 GPU 资源。
-
统一架构:将关键优化整合到一个统一的系统中。
-
零配置:默认启用最佳的功能和优化,减轻用户负担。
vLLM V1 的新特性
优化的执行循环和 API 服务器
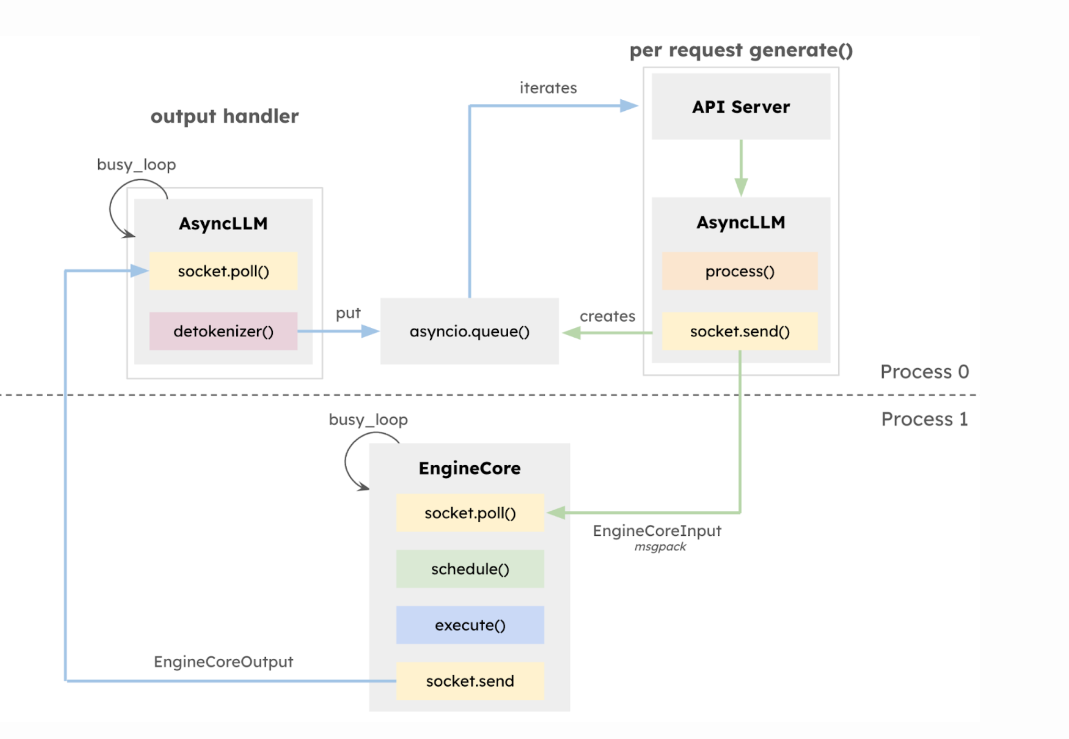
背景
在处理用户请求时,系统需要执行以下任务:
-
接收并解析请求。
-
准备输入数据(如分词)。
-
执行模型推理。
-
生成输出(如解码)。
-
返回结果给用户。
在 V0 中,CPU 需要处理大量任务,特别是在 GPU 执行时间很短的情况下(例如处理小模型或使用高性能 GPU),CPU 成为瓶颈。
V1 的改进
-
多进程架构:将 API 服务器和核心执行循环分离到不同的进程。
-
任务并行化:让 CPU 密集型任务(如分词、解码)与 GPU 推理并行进行。
实际场景举例
假设有大量用户同时向你的聊天机器人发送消息。V1 的多进程架构允许系统同时处理新的用户请求、准备输入数据,以及执行模型推理。这样,当 GPU 在处理一个请求的推理时,CPU 可以为下一个请求做好准备,减少了等待时间,提高了整体吞吐量。
简单且灵活的调度器
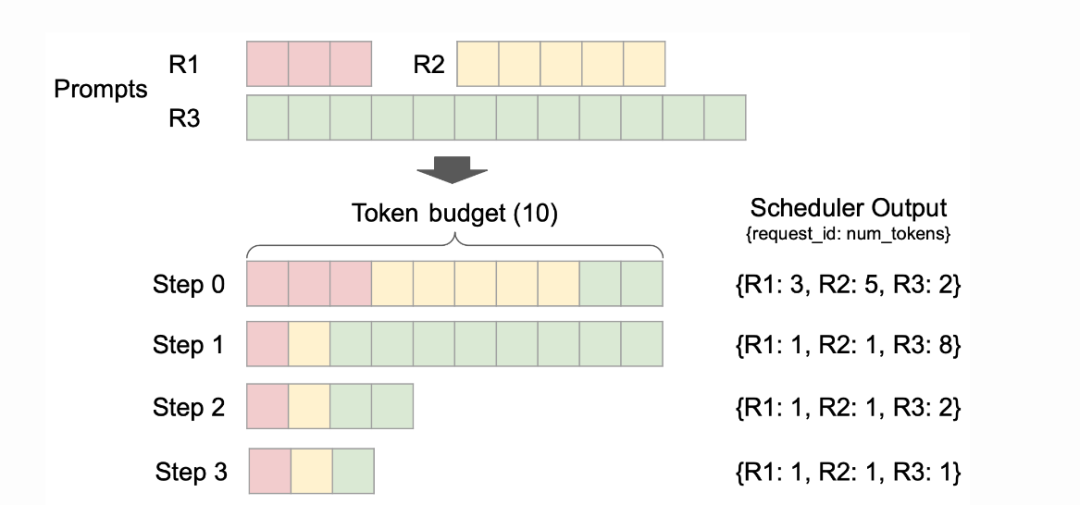
调度器的作用
决定哪些请求在何时被处理,以及每个请求处理多少个令牌(tokens)。
V1 的改进
-
统一处理方式:将用户输入的提示和模型生成的输出统一看待。
-
灵活调度策略:使用简单的数据结构(如 {request_id: num_tokens})表示调度决策。
-
支持高级特性:如分块预填充、前缀缓存、推测性解码等。
实际场景举例
在处理长文本生成时,调度器可以动态分配资源。例如,对于需要生成长段落的请求,调度器可以决定一次处理更多的令牌,而对于短回复的请求,则少分配一些资源。这样,系统可以更有效地利用 GPU,满足不同请求的需求。
零开销的前缀缓存
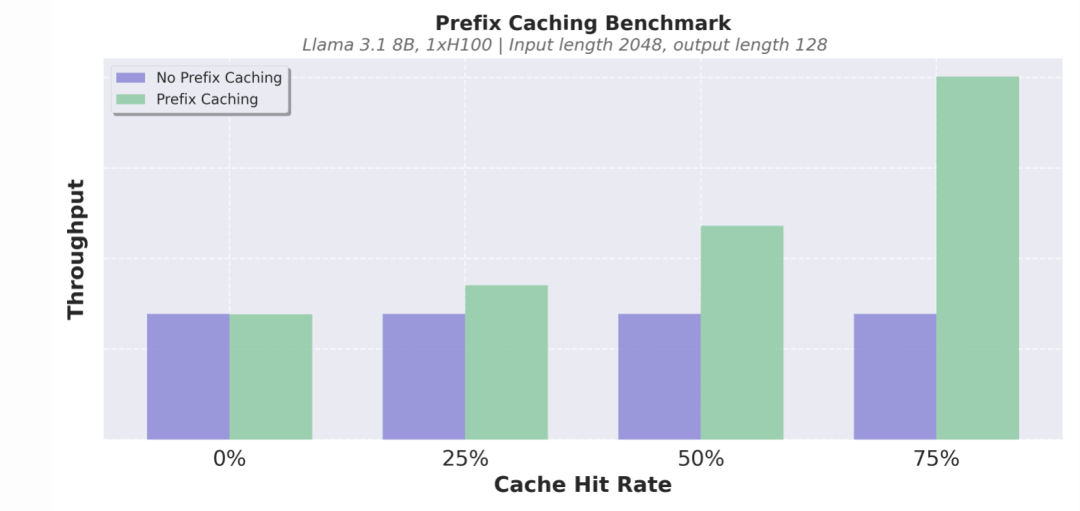
什么是前缀缓存
当不同的请求有相同的输入前缀时,可以缓存这些前缀的计算结果,避免重复计算,提高效率。
V1 的改进
-
优化数据结构:实现常数时间的缓存插入和淘汰。
-
最小化开销:即使缓存命中率很低,也几乎不会带来额外的性能损失。
实际场景举例
在提供 API 服务时,可能会有多个用户发送相同的开头,例如“Once upon a time”。通过前缀缓存,系统可以复用之前的计算结果,加速响应。
针对张量并行推理的清晰架构
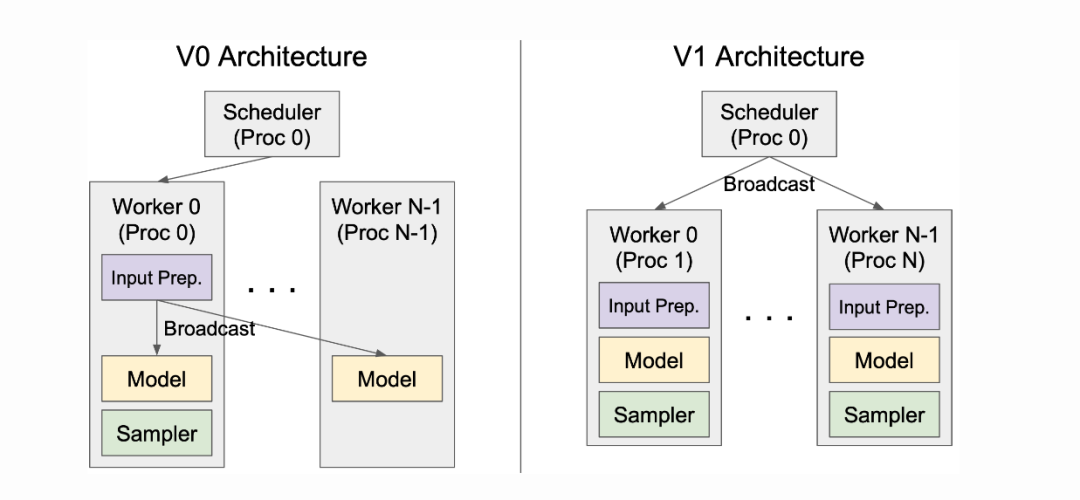
什么是张量并行
将模型的参数和计算分布在多个 GPU 上,以处理超大规模的模型。
V1 的改进
-
对称架构:调度器和每个 GPU 工作进程独立运行,架构清晰。
-
高效通信:在工作进程中缓存请求状态,只传输增量更新,减少通信开销。
实际场景举例
当你需要部署一个特别大的模型(如 70B 参数的模型),需要使用多张 GPU。V1 的架构使得多 GPU 之间的协作更加高效,确保模型能够以最佳性能运行。
高效的输入准备 
问题所在
在 V0 中,每次执行模型推理都要重新准备输入数据,带来较高的 CPU 开销。
V1 的改进
-
持久化批次:缓存输入张量,只在需要时更新。
-
优化数据操作:使用高效的 Numpy 操作,减少 CPU 使用。
实际场景举例
对于连续的对话或多轮交互,用户的输入可能只有少量变化。V1 可以复用之前的输入数据,只处理变化的部分,提高响应速度。
torch.compile 和分段 CUDA 图 
torch.compile 的作用
自动优化 PyTorch 模型的执行效率。
V1 的改进
-
自动优化模型:利用 torch.compile,减少手动优化的工作量。
-
让推理速度提升两倍:torch.compile
-
分段 CUDA 图:解决 CUDA 图在处理动态输入时的限制,提高灵活性。
实际场景举例
开发者可以专注于模型本身的改进,而无需花费大量时间在性能优化上。V1 自动确保模型以高效的方式运行。
CUDA 图是 CUDA 引入的一项高级特性。它的主要作用是:
-
将一系列 GPU 操作(如计算内核、数据传输等)预先记录下来,形成一个有向无环图(DAG,Directed Acyclic Graph)。
-
然后,可以一次性将整个图提交给 GPU 执行,而不是逐个操作地提交。
为什么要使用 CUDA 图?
在传统的 GPU 编程中,CPU 和 GPU 通常需要频繁通信:
-
CPU 负责启动 GPU 的计算任务,例如内核启动、数据传输等。
-
每当需要执行一个 GPU 操作,CPU 都要向 GPU 发出指令,这会产生一定的开销,尤其是在操作较多或操作较小的情况下。
使用 CUDA 图有以下优势:
-
减少 CPU 和 GPU 之间的通信开销:
-
由于提前将多个操作记录下来,一次性提交给 GPU,降低了 CPU 发出指令的频率。
-
减轻了 CPU 的负担,使其可以处理其他任务。
-
-
提高 GPU 的执行效率:
-
GPU 可以连续地执行预先定义好的操作序列,无需等待 CPU 的指令,提高了并行度。
-
减少了 GPU 的空闲时间,更好地利用了计算资源。
-
-
优化性能:
-
对于包含大量小型计算任务的应用,使用 CUDA 图可以显著提升性能。
-
减少了指令的调度和同步开销。
-
在 vLLM V1 中的应用
在 vLLM V1 中,CUDA 图被用于优化大型语言模型的推理过程。具体来说:
-
挑战:
-
大型语言模型在生成文本时,会进行大量的小规模计算步骤,每个步骤可能涉及到不同的 GPU 操作。
-
如果每个操作都需要 CPU 发出指令,会导致大量的通信开销,降低整体性能。
-
-
解决方案:
-
使用 CUDA 图,将推理过程中需要的多个 GPU 操作预先记录下来,形成一个执行图。
-
一次性将整个图提交给 GPU,GPU 可以自主连续地执行这些操作,无需每次都等待 CPU 的指令。
-
-
效果:
-
减少了 CPU 与 GPU 之间的通信,降低了延迟。
-
提高了 GPU 的利用率,加速了模型的推理速度。
-
提升了整体性能,为用户提供更快速的响应。
-
举个例子
为了更好地理解,我们可以把这个过程比作工厂的流水线生产:
-
传统方式:
-
工人(GPU)在每完成一个步骤后,都需要等待主管(CPU)的下一道指令。
-
这种方式下,工人可能会经常停下来等待指令,效率不高。
-
-
使用 CUDA 图的方式:
-
主管(CPU)在开始前,就把整个生产流程(多个步骤)设计好,形成一个“流程图”。
-
工人(GPU)按照这个流程图,连续地完成所有步骤,中间不需要再向主管请示。
-
这样,工人可以一直忙碌,减少了等待时间,生产效率大大提高。
-
增强对多模态大型语言模型的支持
多模态大型语言模型(MLLM)
能够处理文本、图像等多种类型输入的模型。
V1 的改进
-
优化输入预处理:将图像等输入的预处理移到独立进程,避免阻塞 GPU。
-
多模态前缀缓存:支持对图像输入的缓存,加速重复处理。
-
灵活调度:允许将多模态输入的处理分散到多个步骤,提高效率。
实际场景举例
在一个需要处理图像问答的系统中,V1 可以快速处理用户上传的图像,并生成回答。如果同一张图像被多次询问,系统可以利用缓存,加速响应。
FlashAttention 3
FlashAttention 3 的作用
一种高性能的注意力机制计算方法,适用于 Transformer 模型。
V1 的改进
-
集成 FlashAttention 3:在高动态性计算中提供高效的注意力计算。
-
支持各种功能:在合并预填充和解码等动态批处理场景下表现出色。
实际场景举例
对于需要高吞吐量和低延迟的应用,如实时翻译或大规模聊天服务,FlashAttention 3 可以确保模型在高负载下保持良好性能。
重量选手:FlashAttention-3
性能提升
总体效果
-
吞吐量提升:相比 V0,V1 的吞吐量提升最高可达 1.7 倍。
-
延迟降低:更快的响应时间,改善用户体验。
具体示例
-
文本模型:在 Llama 3.1 8B 和 Llama 3.3 70B 上测试,V1 在高并发请求下表现出更好的性能。
-
视觉语言模型:在 Qwen2-VL 上,V1 的改进更加显著,特别是在处理图像输入时。
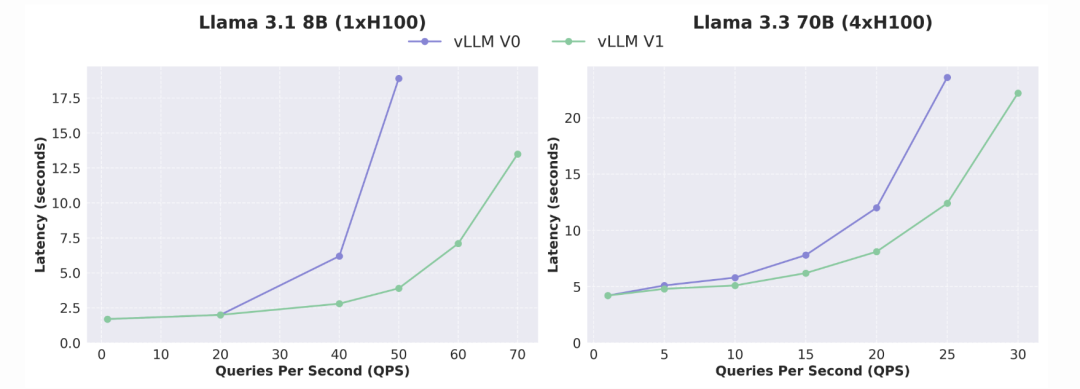
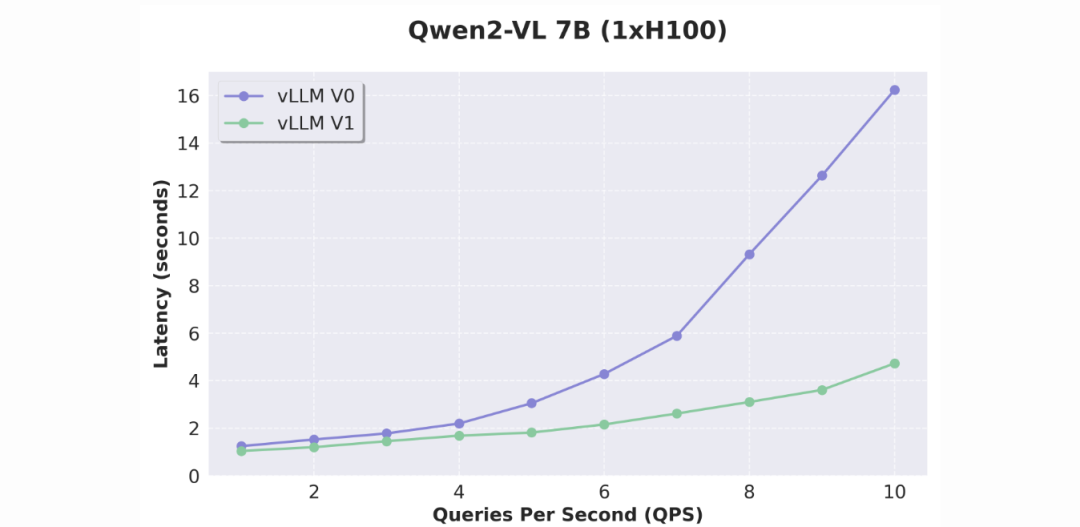
展望未来
-
持续优化:团队将继续改进 V1 的性能和功能。
-
扩展支持:增加对更多模型类型、功能和硬件的支持。
当前的限制和未来工作
模型支持
-
目前支持:仅解码器的 Transformer 模型(如 Llama)、MoE 模型(如 Mixtral)、部分视觉语言模型(如 Qwen2-VL)。
-
暂不支持:编码器-解码器架构(如多模态 Llama 3.2)、基于 Mamba 的模型(如 Jamba)、嵌入模型。
功能限制
-
缺少的功能:log probs、提示 log probs、流水线并行、结构化解码、推测性解码、Prometheus 指标、LoRA 等。
-
开发中:团队正在努力缩小功能差距,并添加新的优化。
硬件支持
-
当前支持:仅支持 NVIDIA Ampere 或更新的 GPU。
-
未来计划:扩展到其他硬件平台,如 TPU。
如何开始使用 vLLM V1
1. 安装最新版本的 vLLM:
pip install vllm --upgrade2. 安装最新版本的 vLLM:
pip install vllm --upgrade3. 设置环境变量:
export VLLM_USE_V1=14. 使用 vLLM:
-
通过 Python API 或命令行使用,无需更改现有代码。
-
启动兼容 OpenAI 的服务器:
vllm serve <模型名称>
总结
vLLM V1 通过重构架构、优化性能和扩展功能,显著提升了大型语言模型的推理效率。对于开发者和用户来说,这意味着更快的响应和更好的体验。
资料推荐
智能 GitHub Copilot 副驾驶® 提示和技巧https://info.microsoft.com/GC-DevOps-CNTNT-FY25-08Aug-23-Smart-GitHub-Copilot-Tips-and-Tricks-SRGCM12801_LP01-Registration---Form-in-Body.html![]() https://info.microsoft.com/GC-DevOps-CNTNT-FY25-08Aug-23-Smart-GitHub-Copilot-Tips-and-Tricks-SRGCM12801_LP01-Registration---Form-in-Body.html
https://info.microsoft.com/GC-DevOps-CNTNT-FY25-08Aug-23-Smart-GitHub-Copilot-Tips-and-Tricks-SRGCM12801_LP01-Registration---Form-in-Body.html
Azure OpenAI 生成式人工智能白皮书https://info.microsoft.com/GC-AzureAI-CNTNT-FY25-08Aug-21-Azure-OpenAI-Generative-Artificial-Intelligence-White-Paper-SRGCM12789_LP01-Registration---Form-in-Body.html![]() https://info.microsoft.com/GC-AzureAI-CNTNT-FY25-08Aug-21-Azure-OpenAI-Generative-Artificial-Intelligence-White-Paper-SRGCM12789_LP01-Registration---Form-in-Body.html
https://info.microsoft.com/GC-AzureAI-CNTNT-FY25-08Aug-21-Azure-OpenAI-Generative-Artificial-Intelligence-White-Paper-SRGCM12789_LP01-Registration---Form-in-Body.html
利用 AI 和 DevOps 重新定义开发人员体验https://info.microsoft.com/ww-landing-redefining-the-developer-experience.html?lcid=ZH-CN![]() https://info.microsoft.com/ww-landing-redefining-the-developer-experience.html?lcid=ZH-CN
https://info.microsoft.com/ww-landing-redefining-the-developer-experience.html?lcid=ZH-CN
SAP on Microsoft Cloudhttps://info.microsoft.com/GC-SAP-CNTNT-FY25-08Aug-27-SAP-on-Microsoft-Cloud-SRGCM12804_LP01-Registration---Form-in-Body.html![]() https://info.microsoft.com/GC-SAP-CNTNT-FY25-08Aug-27-SAP-on-Microsoft-Cloud-SRGCM12804_LP01-Registration---Form-in-Body.html
https://info.microsoft.com/GC-SAP-CNTNT-FY25-08Aug-27-SAP-on-Microsoft-Cloud-SRGCM12804_LP01-Registration---Form-in-Body.html