简单程序语言理论与编译技术·18 语法制导翻译SDT
本文是记录专业课“程序语言理论与编译技术”的部分笔记。
LECTURE 18(语法制导翻译SDT)
1、上讲讲到的Annotated语法树如下图。但是其保存时会浪费空间,况且有些属性算完了就没用了。

2、因为每条规则都与产生式有关,因此可以一边做语法分析一边做翻译,这就是SDT。这种翻译是静态的、被parser驱动的,我们不称其为algorithm,而是称为scheme。

这里{}内的是某种程序,中部尾部的写法都可以。
3、自下而上的语法制导翻译器。注意,这里的符号栈、状态栈和语义栈是同步的。

可以这么理解:前两列定义语言,第三列根据语言写了一个编译器:

这里的ss是语义栈,右边第一行参看下图。右边前三行都是不同风格的栈写法。

4、两种属性,如下图。自下而上的方法(如ocamlyacc)多半搞不定继承属性。

例:C语言变量声明的类似文法及其语法树如下图。注意这里,id的类型源于L,自底而上的方法无法规约。
第一种方法——“猜”。观察,L的前面一定是T,直接去找源头的T的类型(在栈里)即可。


怎么写semantics actions?如下图:

第二种方法,看如下文法。C.i不在栈中,直接找B.s,但可惜程序里没有真正的符号栈,故而不好找B。此外,也不知道是从那条路来的,C前面是aB还是aBA。若是前者,则B在$0,若是后者,则是$-1。解决方法看下图右表,添加了M用作传递。原理是修改文法,将依赖项固定在某个位置。

5、递归下降法又能计算综合属性,也能计算一部分的继承属性,如下图(将继承属性作为参数直接传递)。这里红色是继承属性,蓝色是综合属性:

6、大型例子:C语言的声明翻译。

注意,这里的R->P D,依赖于P的len,指代包了几层指针。P->*P1这里后面的式子少了个len。具体例子如下:

随后计算类型如下图。先从S开始(integer)抵达L,L将属性分发给R和L,到目前为止都是传递,随后开始计算。
以R为例:R那边P长度为1,R为整型,因此D为指向整型的指针,注意这里还有数组,因此推出id是array(pointer(int))。

接下来写代码,注意,课上的案例为了方便使用纯函数式写法,自己写应当使用mutable。

注意这里的token是单词,symbol代表左右括号(方便)。tp是类型,后两行代表某类型的数组和某类型的指针。设计完两个数据结构和输出后,开始设计:

对于Decl,input拆出tok和xs,是先匹配一下第一个,tok只能是int或char。然后tok交给S分析,再送回,整体交给L分析。

对于L,原本是L->R, L | R,有误,需要提取出公因子,改成图中的式子和L'->, L | 空。可以看到这里的倒数第三行处理的,L;倒数第二行则处理的空串,但这里不应该用_,而是应该用Follow集。

对于指针,看右上第七行,这实现了指针的多层包裹。对于数组,如下图:

最后包装,将字符串转成token的链表,再对链表进行变换(用map):
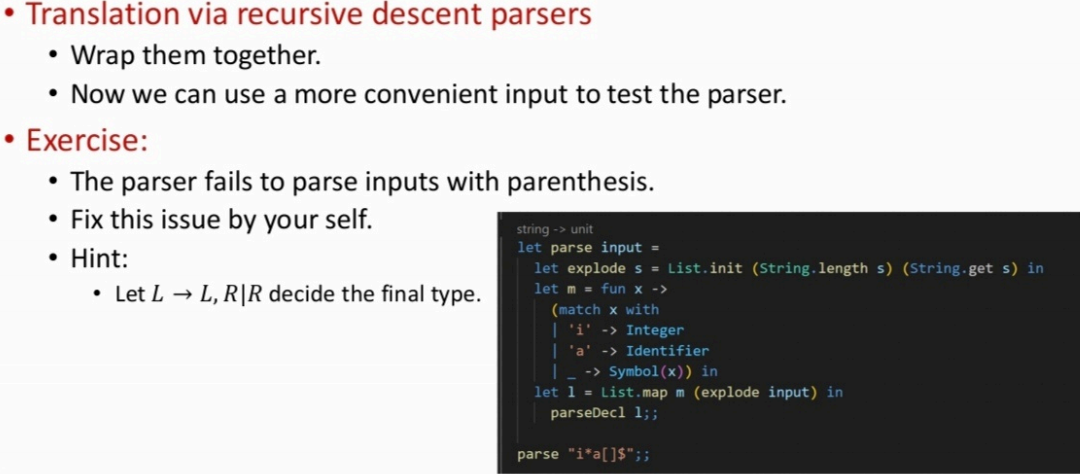
注意,以上最终程序其实还有bug,比如输入parse "i(*a)[]$",会认为是*->integer而没有考虑数组。因为全部按左边跑,看不到[],无法预先把array加进去,发现[]时已经打印完了。修改提示:做一个返回,在返回的时候再打印。