深度学习处理时间序列(7)
使用双向RNN
最后一种方法是双向RNN(bidirectional RNN)。双向RNN是一种常见的RNN变体,它在某些任务上的性能比普通RNN更好。它常用于自然语言处理,可谓深度学习对自然语言处理的“瑞士军刀”。RNN特别依赖于顺序,它按顺序处理输入序列的时间步,而打乱时间步或反转时间步会完全改变RNN从序列中提取的表示。正是由于这个原因,如果顺序对问题很重要(比如温度预测问题),那么RNN的表现就会很好。双向RNN利用了RNN的顺序敏感性:它包含两个普通RNN(比如前面介绍过的GRU层和LSTM层),每个RNN分别沿一个方向对输入序列进行处理(按时间正序和按时间逆序),然后将它们的表示合并在一起。通过沿着两个方向处理序列,双向RNN能够捕捉到可能被单向RNN忽略的模式。
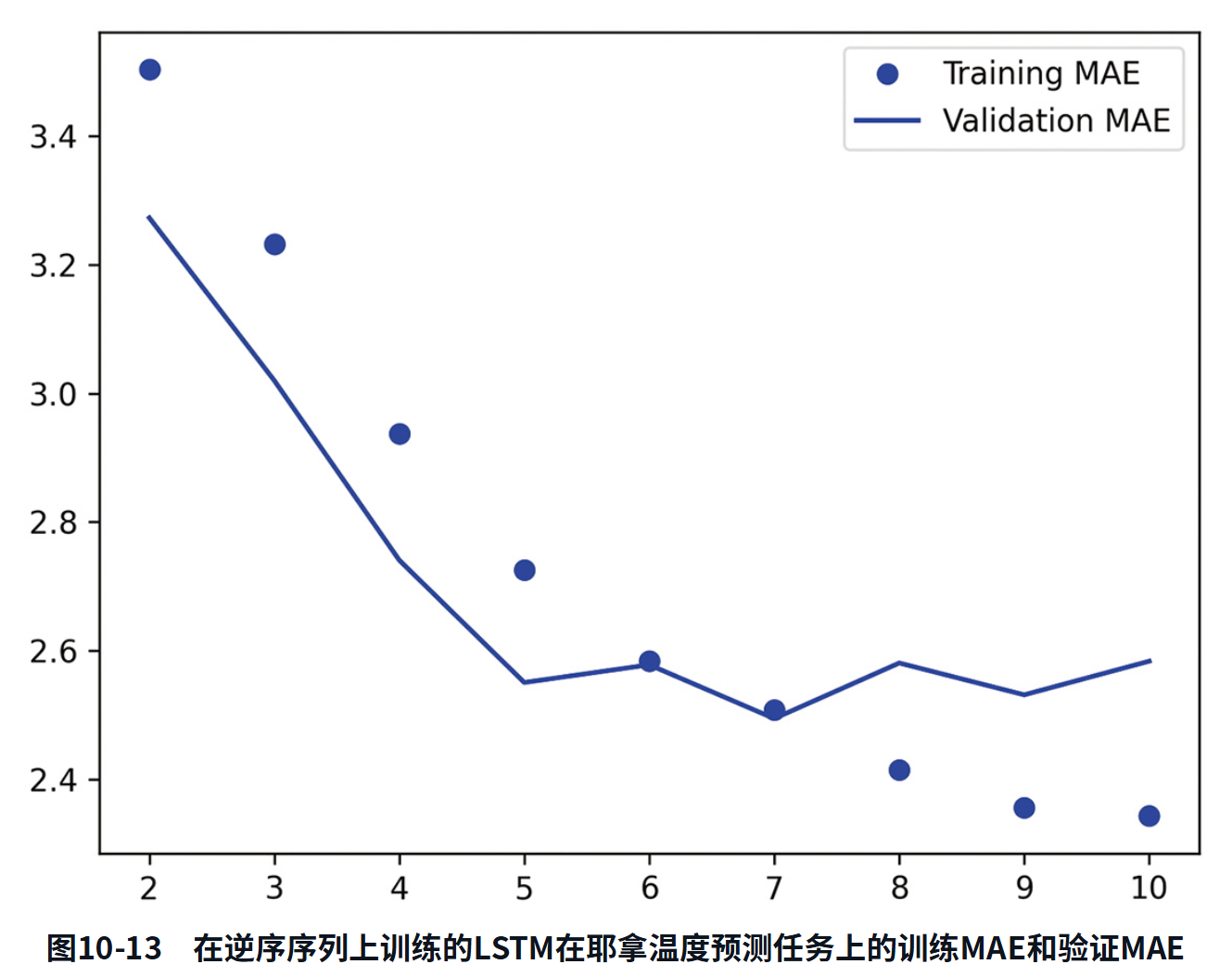
逆序LSTM的性能甚至比基于常识的基准还要差很多,这说明在本例中,按时间正序处理对成功解决问题很重要。这非常合理:底层的LSTM层通常更善于记住最近的过去,而不是遥远的过去。对这个问题而言,更晚的天气数据点当然比更早的天气数据点具有更强的预测能力(这也是基于常识的基准非常强大的原因)。因此,按时间正序的层必然比按时间逆序的层表现要好。然而,对于许多其他问题(包括自然语言),情况并非如此:直觉上看,一个单词对理解句子的重要性,通常并不取决于它在句子中的位置。对于文本数据,逆序处理的效果与正序处理一样好—你可以倒着阅读文本(试试吧)。虽然单词顺序对理解语言很重要,但使用哪种顺序并不重要。重要的是,在逆序序列上训练的RNN学到的表示不同于在原始序列上训练学到的表示,正如在现实世界中,如果时间倒流(你的人生是第一天死亡、最后一天出生),那么你的心智模型也会完全不同。在机器学习中,如果一种数据表示不同但有用,那么总是值得加以利用,并且这种表示与其他表示的差异越大越好。它提供了观察数据的全新角度,可以捕捉到数据中被其他方法忽略的内容,因此有助于提高模型在某个任务上的性能。这正是集成(ensembling)方法背后的原理。双向RNN正是利用这一想法来提高正序RNN的性能。它从两个方向查看输入序列(如图10-14所示),从而得到更加丰富的表示,并捕捉到仅使用正序RNN时可能忽略的一些模式。
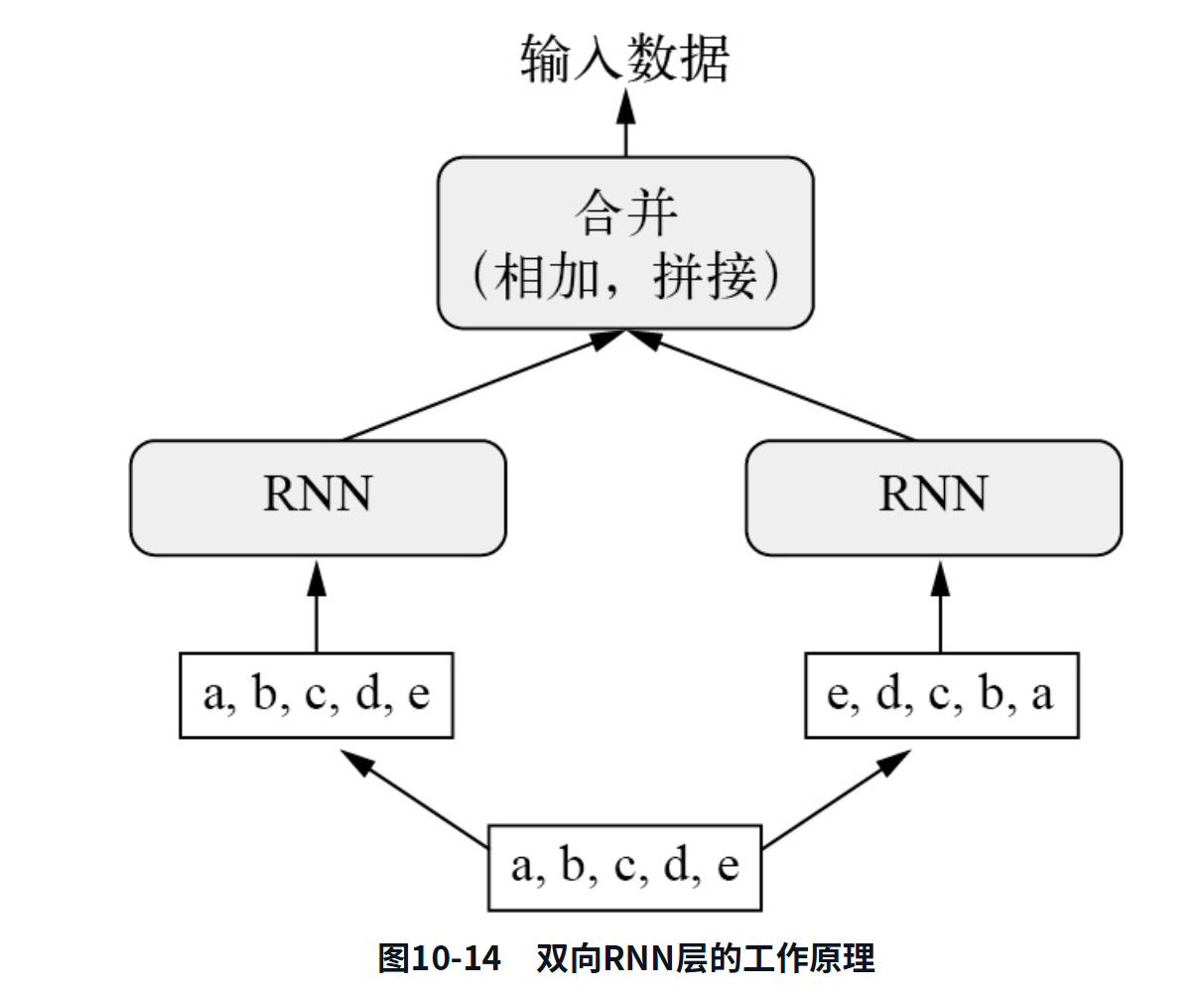
要想在Keras中将双向RNN实例化,你可以使用Bidirectional层,它的第一个参数是一个循环层实例。Bidirectional会对这个循环层创建第二个单独的实例,然后用一个实例按正序处理输入序列,用另一个实例按逆序处理输入序列。你可以在温度预测任务上试试这种方法,如代码清单10-24所示。
代码清单10-24 训练并评估双向LSTM
inputs = keras.Input(shape=(sequence_length, raw_data.shape[-1]))
x = layers.Bidirectional(layers.LSTM(16))(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop", loss="mse", metrics=["mae"])
history = model.fit(train_dataset,
epochs=10,
validation_data=val_dataset)
可以看到,双向LSTM的性能不如普通LSTM层。原因很容易理解:所有的预测能力肯定都来自于正序的那一半网络,因为我们已经知道逆序的那一半网络在这项任务上的性能很差(再次强调,这是因为在本例中,最近的过去比遥远的过去更重要)。同时,逆序的那一半网络使网络容量加倍,从而导致更早开始出现过拟合。然而,双向RNN非常适合用于文本数据或任何其他类型的数据,其中顺序很重要,但使用哪种顺序并不重要。事实上,在2016年的一段时间里,双向LSTM被认为是许多自然语言处理任务中最先进的方法(这是在Transformer架构兴起之前,后续会介绍这种架构)。
进一步实验
为了提高模型在温度预测问题上的性能,你还可以尝试下面这些做法。调节堆叠循环层中每层的单元个数和dropout比率。当前取值在很大程度上是随意选择的,因此可能不是最优的。调节RMSprop优化器的学习率,或者尝试使用其他优化器。在循环层上使用Dense层堆叠作为回归器,而不是单一的Dense层。改进模型输入:尝试使用更长或更短的序列,或者尝试使用不同的采样率,再或者做特征工程。如前所述,深度学习更像是一门艺术,而不是一门科学。我们可以提供指导,对于某个问题哪些方法可能有效、哪些方法可能无效,但归根结底,每个数据集都是独一无二的,你必须根据经验来评估不同的策略。目前没有任何理论能够提前准确地告诉你,怎样做才能最优地解决问题。你必须不断迭代。根据我的经验,在没有使用机器学习的基准上改进10%左右,可能是你在这个数据集上能得到的最佳结果。这不算很好,但这些结果是合理的:如果你能获得来自不同地点(范围很广)的数据,那么近期的天气是高度可预测的,但如果你只有单一地点的测量结果,那么近期天气就很难预测。你所在地点的天气演变,取决于周围地区当前的天气模式。
资本市场与机器学习
使用这里介绍的技术,尝试将其应用于预测股票市场的证券(或货币汇率等)的未来价格。然而,市场的统计特征与天气模式等自然现象非常不同。谈到市场,过去的表现并不能很好地预测未来的回报,正如靠观察后视镜是没法开车的。机器学习适用于那些过去能够很好地预测未来的数据集,比如天气、电力消耗或商店客流量。永远要记住,所有交易本质上都是信息套利:利用其他市场参与者所不具备的数据或洞察力来获得优势。如果试图使用众所周知的机器学习技术和公开可用的数据来击败市场,这实际上是一条死胡同,因为与其他人相比,你没有任何信息优势。你很可能会浪费时间和资源,却一无所获。
总结
遇到一个新问题时,最好首先为你选择的指标建立基于常识的基准。如果没有需要超越的基准,那么就无法判断是否取得了真正的进展。在尝试计算代价较高的模型之前,先尝试一些简单的模型,以证明增加计算代价是有意义的。有时简单模型就是你的最佳选择。如果顺序对数据很重要,特别是对于时间序列数据,那么循环神经网络(RNN)是一种很适合的方法,与那些先将时间数据展平的模型相比,其性能要更好。Keras中的两个基本的RNN层是LSTM层和GRU层。要在RNN中使用dropout,你应该使用不随时间变化的dropout掩码和循环dropout掩码。这二者都内置于Keras的循环层中,所以你只需使用循环层的dropout参数和recurrent_dropout参数即可。循坏层堆叠比单一RNN层具有更强的表示能力。它的计算代价也更高,因此不一定总是值得尝试的。虽然它在复杂问题(如机器翻译)上提供了明显的收益,但在小型的简单问题上可能不一定很适用。