Xenium | 细胞邻域(Cellular Neighborhood)分析(fixed k-nearest neighbor)
CN分析概念最早来源于空间单细胞蛋白组Codex文章,Coordinated Cellular Neighborhoods Orchestrate Antitumoral Immunity at the Colorectal Cancer Invasive Front。

定义
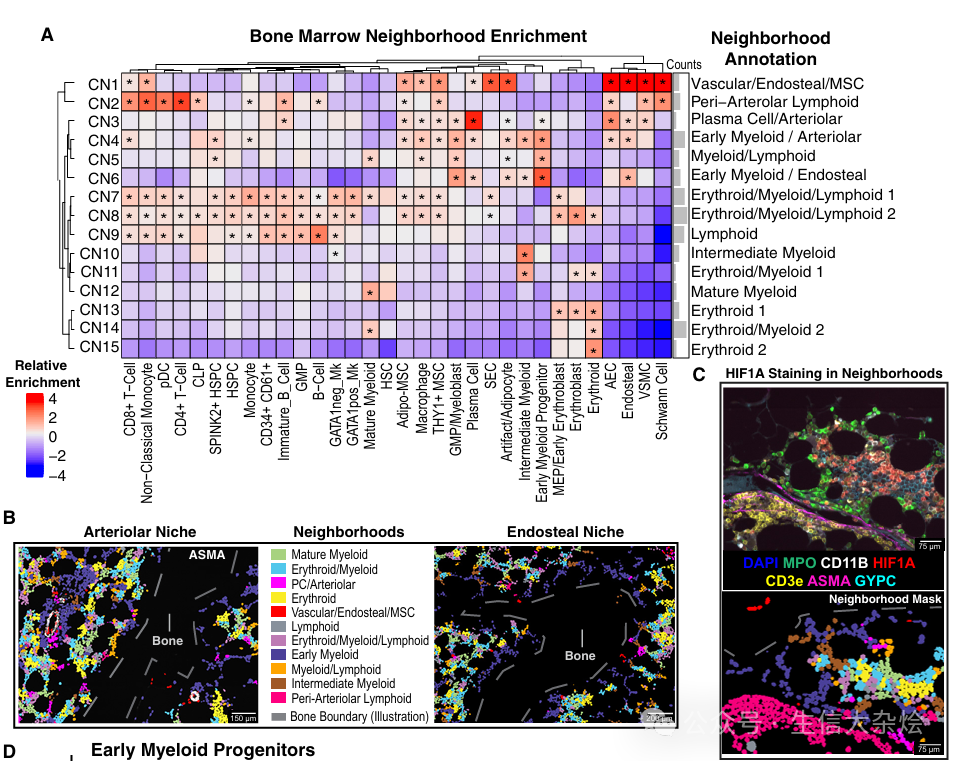
Cell Neighborhood(细胞邻域)指骨髓微环境中空间上邻近的细胞群体形成的功能单元,这些单元由特定细胞类型组成,反映细胞间的物理邻近性和潜在相互作用。邻域的划分基于细胞类型的共定位模式,例如:动脉-内骨膜邻域(Arterio-endosteal neighborhood):富含早期髓系前体细胞(EMPs)和粒细胞-单核祖细胞(GMPs),靠近动脉和骨表面;红细胞生成岛(Erythroid islands):由巨噬细胞和红细胞前体细胞组成;间充质-白血病细胞邻域(MSC-blast neighborhoods):在AML样本中,间充质基质细胞(MSCs)与白血病原始细胞共定位。
计算方法
-
无监督邻域分析
-
邻近窗口构建:以每个细胞为中心,计算其与周围10个最近邻细胞的物理距离,形成局部窗口。
-
K-means聚类:将所有窗口的细胞类型组成进行聚类(如K=15),识别出具有相似细胞类型组成的空间区域,即邻域。
-
富集分析:通过超几何检验(hypergeometric test)评估每个邻域中特定细胞类型的富集程度。公式如下:
P=(Kk)(N−Kn−k)(Nn)P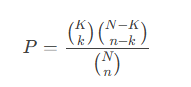
-
其中,NN为总细胞数,KK为某细胞类型的总数量,nn为邻域内细胞数,kk为邻域内该细胞类型的数量。通过Benjamini-Hochberg方法校正多重假设检验的p值。
-
-
邻域注释
根据富集的细胞类型和已知生物学知识(如动脉、内骨膜的位置),为每个聚类赋予生物学意义的名称(如“早期髓系-动脉邻域”)。
除了上述文章中的使用固定K近邻方法(fixed k-nearest neighbors)定义细胞Neighborhood,还有种方法是固定半径范围内(fixed radius)细胞定义细胞Neighborhood
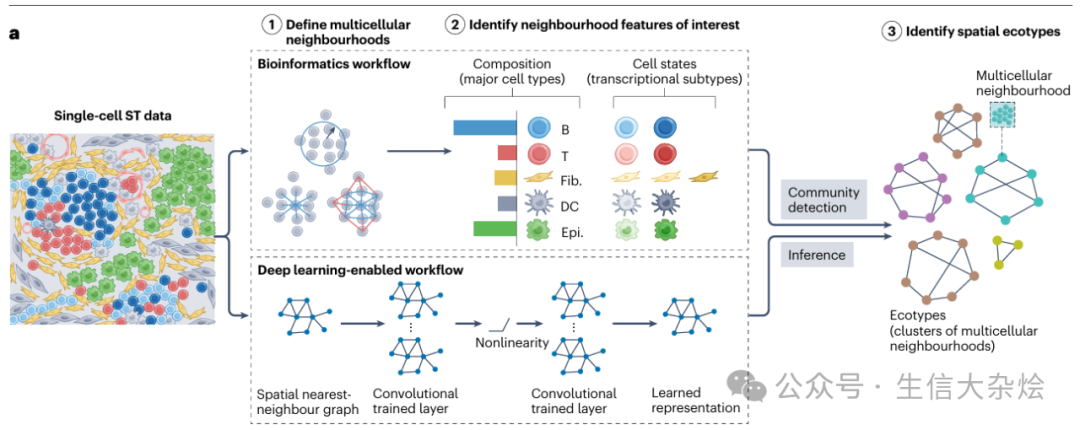
fixed K-nearest neighbors
import numpy as np
import pandas as pd
import scanpy as sc
import seaborn as sns
from sklearn.neighbors import NearestNeighbors
from sklearn.cluster import MiniBatchKMeans
import matplotlib.pyplot as plt
from matplotlib.pyplot import rc_context
def cellular_neighborhood_knn(adata, column, n_neighbors=10, k=10, n_clusters=10, out_dir=None):
spatial_coords = adata.obsm['spatial']
onehot_encoding = pd.get_dummies(adata.obs[column])
# 计算最近邻居
nbrs = NearestNeighbors(n_neighbors=n_neighbors).fit(spatial_coords)
distances, indices = nbrs.kneighbors(spatial_coords)
# 对每个cell,计算其邻居的类型分布
cluster_cols = adata.obs[column].unique()
values = onehot_encoding[cluster_cols].values
def compute_window_sums(indices, values, k):
windows = []
for idx in range(indices.shape[0]):
neighbors = indices[idx, :k]
window_sum = values[neighbors].sum(axis=0)
windows.append(window_sum)
return np.array(windows)
windows = compute_window_sums(indices, values, k)
km = MiniBatchKMeans(n_clusters=n_clusters, random_state=0)
labels = km.fit_predict(windows)
adata.obs[f'CNs_{n_clusters}'] = [f'CN{i}' for i in labels]
adata.obs.to_csv(os.path.join(out_dir, f'CNs_{n_clusters}_all_cell_features.xls'), sep='\t', index=None)
# 保存聚类中心
k_centroids = km.cluster_centers_
# 计算Fold Change (fc)
tissue_avgs = values.mean(axis=0)
fc = np.log2(((k_centroids + tissue_avgs) / (k_centroids + tissue_avgs).sum(axis=1, keepdims=True)) / tissue_avgs)
fc = pd.DataFrame(fc, columns=adata.obs[column].unique())
fc.index = 'CN' + fc.index.astype(str)
sns.set_style("white")
g = sns.clustermap(fc, vmin=-2, vmax=2, cmap="vlag", row_cluster=False, col_cluster=True, linewidths=0.5, figsize=(6, 6))
g.ax_heatmap.tick_params(right=False, bottom=False)
plt.savefig(os.path.join(out_dir, f"CNs_{n_clusters}.png"), dpi=300, bbox_inches='tight')
return adata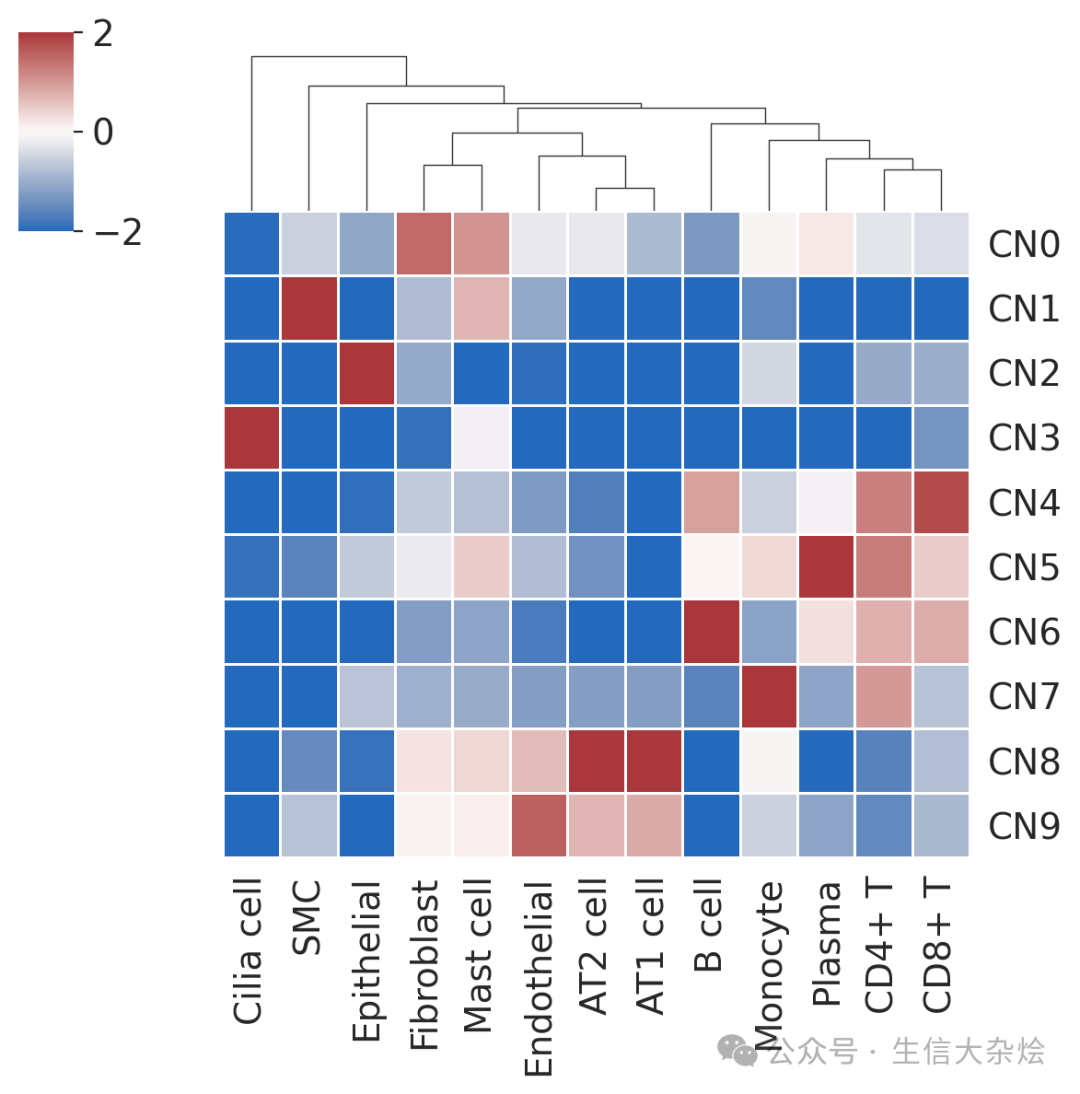


Xenium | 空间原位转录组数据分析全解
Xenium数据分析 | 下机数据读取
Xenium数据分析 | 数据预处理、单细胞降维聚类、细胞类型定义
空间转录组 | 细胞niche分析