深度学习论文分享(十)A Tutorial on Principal Component Analysis
深度学习论文分享(十)A Tutorial on Principal Component Analysis
- 前言
- Abstract
- I. INTRODUCTION
- II. MOTIVATION: A TOY EXAMPLE
- III. FRAMEWORK: CHANGE OF BASIS
- A. A Naive Basis
- B. Change of Basis
- C. Questions Remaining
- IV. VARIANCE AND THE GOAL
- A. Noise and Rotation
- B. Redundancy
- C. Covariance Matrix
- D. Diagonalize the Covariance Matrix
- E. Summary of Assumptions
- V. SOLVING PCA USING EIGENVECTOR DECOMPOSITION
- VI. A MORE GENERAL SOLUTION USING SVD
- A. Singular Value Decomposition
- B. Interpreting SVD
- C. SVD and PCA
- VII. DISCUSSION
- A. Limits and Statistics of Dimensional Reduction
前言
关于PCA主成分分析法的一篇解释
Abstract
主成分分析(PCA)是现代数据分析的支柱——一个被广泛使用但(有时)很少被理解的黑箱。本文的目标是消除这个黑盒背后的魔力。这份手稿侧重于建立一个坚实的直觉如何和为什么主成分分析工作。这份手稿通过简单的直觉,PCA背后的数学推导,将这些知识具体化。本教程不回避非正式地解释这些想法,也不回避数学。希望通过解决这两个方面的问题,所有层次的读者都能够更好地理解主成分分析以及何时、如何和为什么应用这一技术。
I. INTRODUCTION
主成分分析(PCA)是现代数据分析中的标准工具——在从神经科学到计算机图形学的不同领域中——因为它是一种从混乱的数据集中提取相关信息的简单、非参数方法。PCA以最小的努力为如何将复杂的数据集降低到一个较低的维度提供了一个路线图,以揭示有时隐藏在它下面的简化结构。
本教程旨在提供对主成分分析(PCA)的直观理解与深入探讨。我们将从一个简单示例出发,直观阐释PCA的核心目标;随后通过线性代数的数学框架建立严格表述,给出明确的数学解。在此过程中,我们将揭示PCA与奇异值分解(SVD)技术之间的深刻关联。这种理解将帮助我们构建实际应用PCA的方法体系,并认知其底层假设。希望通过系统掌握PCA,为读者奠定机器学习与降维领域的研究基础。
本文的讨论与解释采用教程式的非正式表述方式,核心目标在于知识传授。虽然严格的数学证明偶尔必要(详见附录),但对教程主体并非关键——这些证明专为追求完整数学理解的读者准备。我们仅预设读者具备线性代数基础,全文将基于线性代数概念展开深入探讨,并避免涉及统计学与优化理论中的复杂议题(相关讨论参见专章)。欢迎随时联系笔者提出建议、修正或意见。
II. MOTIVATION: A TOY EXAMPLE
我们的视角是这样的:作为实验研究者,我们试图通过测量系统中各种量(如光谱、电压、速度等)来理解某些现象。但问题是,由于数据显得模糊不清、难以解读甚至存在冗余,我们往往无法真正洞察现象的本质。这并非小问题,而是实证科学面临的根本性障碍。在神经科学、网络索引、气象学和海洋学等复杂系统研究中,这类情况比比皆是——需要测量的变量数量可能庞大到难以处理,有时甚至具有误导性,因为其内在关联往往可能非常简单。
以图1所示的物理教学示例为例:假设我们正在研究物理学中的理想弹簧系统。该系统由质量为m的小球连接在无质量、无摩擦的弹簧上构成。当小球从平衡位置拉开一小段距离释放后(即弹簧被拉伸),由于是理想弹簧,它会沿x轴以固定频率无限期地绕平衡位置振荡。
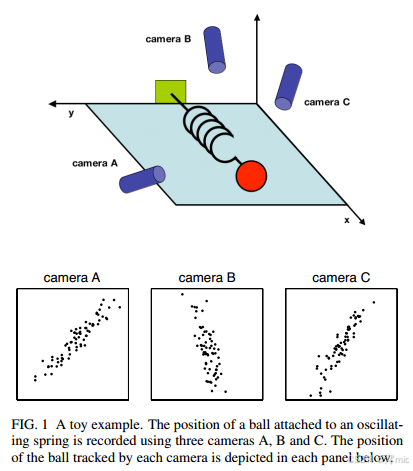
这是一个经典物理问题,其中x方向的运动可通过时间的显函数精确求解。换言之,该系统的基础动力学规律可表示为单变量x的函数。
然而作为缺乏认知的实验者,我们对这些一无所知。我们既不清楚应该测量哪些轴向,更不了解关键维度的数量。因此,我们决定在三维空间中对小球位置进行测量(毕竟我们生活在三维世界)。具体操作是:在研究对象周围布置三台高速摄像机,每台以120帧率记录小球二维投影位置。但问题在于——由于认知局限,我们甚至无法确定真实的x/y/z轴向,只能以任意角度 a ⃗ 、 b ⃗ 、 c ⃗ \vec{a}、\vec{b}、\vec{c} a、b、c架设摄像机,这些测量轴向之间的夹角可能都不是直角!经过数分钟拍摄后,核心问题依然存在:如何从这些数据中还原出简洁的x方向运动方程?
我们事先就明白,如果足够明智,本应只需用一台摄像机测量x轴方向的位置。但现实情况往往并非如此——我们通常难以确定哪些测量最能反映系统的真实动力学特性,甚至常常会记录下远超实际需要的维度数据。
此外,我们还必须应对现实中棘手的噪声问题。在这个示例中,这意味着我们需要处理空气阻力、不完美的摄像机,甚至是弹簧的非理想摩擦。噪声污染了我们的数据集,只会进一步模糊动力学特征。这个简单示例正是实验人员日常面临的挑战。在我们深入探讨抽象概念时,请牢记这个例子。希望通过本文的阐述,我们能够充分理解如何利用主成分分析来系统性地提取x变量。
III. FRAMEWORK: CHANGE OF BASIS
主成分分析的核心目标,在于找出最具意义的新基来重新表达数据集。其理想效果是:通过新基变换能过滤噪声并揭示隐藏结构。以弹簧系统为例,PCA的明确目标就是判定"动力学变化仅沿x轴发生"。换言之,PCA旨在确认 x x x轴单位基向量 x ^ \hat{x} x^才是关键维度。这一判断能让研究者有效区分:哪些动力学特征是重要的、哪些是冗余的、哪些纯属噪声。
A. A Naive Basis
随着研究目标的明确定义,我们也需要对数据进行更精确的表述。我们将每个时间采样点(或实验试次)视为数据集中的独立样本。在每个采样时刻,我们记录一组包含多维度测量值的数据(如电压、位置等)。具体到我们的数据集中:在某一时刻,摄像机A记录的小球位置坐标为
(
x
A
,
y
A
)
(x_A, y_A)
(xA,yA)。因此,单个样本可以表示为一个6维列向量。
A
⃗
=
[
x
A
y
A
x
B
y
B
x
C
y
C
]
\vec{A}=\left [ \begin{matrix} x_A \\ y_A \\ x_B \\ y_B \\ x_C \\ y_C \\ \end{matrix} \right ]
A=
xAyAxByBxCyC
其中每台摄像机提供的二维位置投影共同构成向量 X ⃗ \vec{X} X。若以120Hz采样频率记录10分钟,我们将获得10×60×120=72000个此类向量。
通过这个具体案例,让我们用抽象术语重新表述这个问题。每个样本 X ⃗ \vec{X} X都是一个 m m m维向量,其中 m m m代表测量类型的数量。也就是说,每个样本都是位于某个正交规范基所张成的 m m m维向量空间中的一个向量。根据线性代数知识,所有测量向量都可以表示为这组单位长度基向量的线性组合。那么,这个正交规范基究竟是什么?
这个问题通常是被默认却常被忽视的前提假设。假设我们只分析摄像机A采集的示例数据, ( x A , y A ) (x_A, y_A) (xA,yA)的正交规范基是什么?直观选择可能是 { ( 1 , 0 ) , ( 0 , 1 ) } \{(1,0),(0,1)\} {(1,0),(0,1)},但为何不选 { ( √ 2 / 2 , √ 2 / 2 ) , ( − √ 2 / 2 , − √ 2 / 2 ) } \{(√2/2,√2/2),(-√2/2,-√2/2)\} {(√2/2,√2/2),(−√2/2,−√2/2)}或其他任意旋转基?原因在于:直观基反映了数据采集方式。当我们记录位置 ( 2 , 2 ) (2,2) (2,2)时,实际记录的是摄像机窗口中"左2单位、上2单位"的位置坐标,而非" ( √ 2 / 2 , √ 2 / 2 ) (√2/2,√2/2) (√2/2,√2/2)方向2√2单位加垂直方向0单位"的数值。因此原始基本质上映射着我们的测量方法。
在线性代数中如何表达这种直观基?对于二维情况, { ( 1 , 0 ) , ( 0 , 1 ) } \{(1,0),(0,1)\} {(1,0),(0,1)}可以表示为行向量。由这些行向量构成的矩阵就是2×2单位矩阵 I I I。我们可以将其推广到 m m m维情况,构建 m × m m×m m×m单位矩阵:
B
=
[
b
1
b
2
b
3
b
4
b
5
b
6
]
=
[
1
0
0
0
0
0
0
1
0
0
0
0
0
0
1
0
0
0
0
0
0
1
0
0
0
0
0
0
01
0
0
0
0
0
0
1
]
=
I
\mathbf{B}=\left [ \begin{matrix} \mathbf{b_1} \\ \mathbf{b_2} \\ \mathbf{b_3} \\ \mathbf{b_4} \\ \mathbf{b_5} \\ \mathbf{b_6} \\ \end{matrix} \right ]=\left [ \begin{matrix} 1 &0 & 0 & 0 & 0 & 0 \\ 0 &1 & 0 & 0 & 0 & 0 \\ 0 &0 & 1 & 0 & 0 & 0 \\ 0 &0 & 0 & 1 & 0 & 0 \\ 0 &0 & 0 & 0 & 01 & 0 \\ 0 &0 & 0 & 0 & 0 & 1 \\ \end{matrix} \right ] = \mathbf{I}
B=
b1b2b3b4b5b6
=
1000000100000010000001000000010000001
=I
其中每个行向量
b
i
\mathbf{b}_i
bi都是具有
m
m
m个分量的正交基向量。我们可以将这个初始基视为有效起点——由于所有数据都在此基下记录,因此可直接表示为
{
b
i
}
\{\mathbf{b}_i\}
{bi}的线性组合。
B. Change of Basis
基于上述严格定义,我们现在可以更精确地表述PCA的核心问题:是否存在另一种基——即原始基的某种线性组合——能够最优地重新表达我们的数据集?
细心的读者可能已注意到"线性"这个刻意添加的关键词。实际上,PCA做出一个严格但强有力的假设:线性。这个假设通过限制潜在基的集合,极大地简化了问题。在此约束下,PCA只能将数据重新表达为基向量的线性组合。
设
X
\mathbf{X}
X为原始数据集,其中每列代表一个数据样本(或时间点上的观测值,即
X
⃗
\vec{X}
X)。在弹簧示例中,
X
X
X是一个
m
×
n
m×n
m×n矩阵,其中
m
=
6
m=6
m=6,
n
=
72000
n=72000
n=72000。设
Y
\mathbf{Y}
Y是通过线性变换
P
\mathbf{P}
P关联的另一个
m
×
n
m×n
m×n矩阵。
X
\mathbf{X}
X是原始记录数据集,而
Y
\mathbf{Y}
Y是该数据集的新表示。
P
X
=
Y
\begin{equation} \mathbf{PX=Y} \end{equation}
PX=Y
也让我们定义下列量。在本节中,
x
i
\mathbf{x}_i
xi和
y
i
\mathbf{y}_i
yi是列向量,但要预先警告。在所有其他部分中,
x
i
\mathbf{x}_i
xi和
y
i
\mathbf{y}_i
yi是行向量
- p i \mathbf{p}_i pi表示矩阵 P \mathbf{P} P的行向量
- x i \mathbf{x}_i xi表示矩阵 X \mathbf{X} X的列向量(即单个观测值 X ⃗ \vec{X} X)
- y i \mathbf{y}_i yi表示矩阵 Y \mathbf{Y} Y的列向量
式1表示基的变换,因此可作多种解释:
- P \mathbf{P} P是将 X \mathbf{X} X变换为 Y \mathbf{Y} Y的矩阵
- 在几何上, P \mathbf{P} P是通过旋转和拉伸将 X \mathbf{X} X变换为 Y \mathbf{Y} Y的操作
- P \mathbf{P} P的行向量 { p 1 , . . . , p m } \{\mathbf{p}_1,...,\mathbf{p}_m\} {p1,...,pm}是用于表示 X X X列向量的一组新基向量
最后一种解释虽不明显,但通过展开 P X \mathbf{PX} PX的显式点积运算即可得证。
P X = [ p 1 ⋮ b 6 ] [ x 1 ⋯ x n ] Y = [ p 1 ⋅ x 1 ⋯ p 1 ⋅ x n ⋮ ⋱ ⋮ p m ⋅ x 1 ⋯ p m ⋅ x n ] \mathbf{PX}=\left [ \begin{matrix} \mathbf{p_1} \\ \mathbf{\vdots} \\ \mathbf{b_6} \\ \end{matrix} \right ]\left [ \begin{matrix} \mathbf{x_1} & \cdots & \mathbf{x_n} \end{matrix} \right ]\\ \mathbf{Y}=\left [ \begin{matrix} \mathbf{p_1}\cdot\mathbf{x_1} & \cdots &\mathbf{p_1}\cdot\mathbf{x_n} \\ \mathbf{\vdots} & \ddots & \vdots \\ \mathbf{p_m}\cdot\mathbf{x_1} & \cdots &\mathbf{p_m}\cdot\mathbf{x_n} \\ \end{matrix} \right ] PX= p1⋮b6 [x1⋯xn]Y= p1⋅x1⋮pm⋅x1⋯⋱⋯p1⋅xn⋮pm⋅xn
我们可以注意到
Y
\mathbf{Y}
Y的每一列的形式。
y
i
=
[
p
i
⋅
x
i
⋮
p
m
⋅
x
i
]
\mathbf{y_i}=\left [ \begin{matrix} \mathbf{p_i \cdot x_i} \\ \mathbf{\vdots} \\ \mathbf{p_m \cdot x_i} \\ \end{matrix} \right ]
yi=
pi⋅xi⋮pm⋅xi
我们可以看出, y i \mathbf{y_i} yi的每个系数都是 x i \mathbf{x_i} xi与 P \mathbf{P} P中对应行向量的点积。换言之, y i \mathbf{y_i} yi的第 j j j个系数就是其在 P \mathbf{P} P第 j j j行向量上的投影。这实际上正符合 y i \mathbf{y_i} yi在基 { p 1 , . . . , p m } \{\mathbf{p}_1,...,\mathbf{p}_m\} {p1,...,pm}上投影的方程形式。因此, P \mathbf{P} P的行向量正是用于表示 X \mathbf{X} X列向量的一组新基向量。
C. Questions Remaining
通过线性假设,问题简化为寻找合适的基变换。该变换中的行向量 { p 1 , . . . , p m } \{\mathbf{p}_1,...,\mathbf{p}_m\} {p1,...,pm}将成为 X \mathbf{X} X的主成分。由此引出几个关键问题:
- 重新表达 X \mathbf{X} X的最佳方式是什么?
- 如何选择最优基 P \mathbf{P} P?
要回答这些问题,我们需要进一步思考:我们希望 Y \mathbf{Y} Y具有哪些特征。显然,要获得合理结果,仅线性假设远远不够——这些附加条件的选择正是下节要探讨的主题。
IV. VARIANCE AND THE GOAL
现在最重要的问题来了:最好地表达数据意味着什么?这一部分将对这个问题建立一个直观的答案,并在此过程中加入额外的假设。
A. Noise and Rotation
任何数据集中的测量噪声都必须足够低,否则无论采用何种分析技术,都无法提取有效信号信息。噪声不存在绝对标度,其量化总是相对于信号强度而言。常用的衡量指标是信噪比(SNR),即方差比
σ
2
\sigma^2
σ2。
S
N
R
=
σ
s
i
g
n
a
l
2
σ
n
o
i
s
e
2
SNR = \frac{\sigma^2_{signal}}{\sigma^2_{noise}}
SNR=σnoise2σsignal2
高信噪比(SNR ≫ 1)对应高精度测量结果,而低信噪比则表明数据噪声干扰严重。
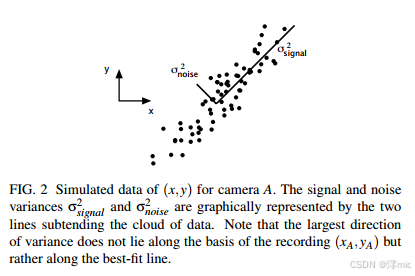
Fig2: 摄像机A的(x, y)模拟数据图示。信号方差σ²_signal与噪声方差σ²_noise由数据云两侧的线段直观表示。需特别注意:最大方差方向并不沿记录基(xA, yA)分布,而是位于最佳拟合线方向上。
让我们仔细分析图2中摄像机A的数据。由于弹簧始终做直线运动,每台摄像机记录的应该同样是直线轨迹。因此,任何偏离直线的数据分布都属于噪声。图中各线段分别表示信号与噪声引起的方差,两者长度之比可衡量数据云的聚集程度:可能呈现细线状(SNR≫1)、圆形(SNR=1)或更差情况。基于合理测量假设,我们定量认为测量空间中方差最大的方向包含目标动力学特征。图2中最大方差方向既非 x A ^ = ( 1 , 0 ) \hat{x_A}=(1, 0) xA^=(1,0)也非 y A ^ = ( 0 , 1 ) \hat{y_A}=(0, 1) yA^=(0,1),而是数据云长轴方向。由此可推定,目标动力学特征存在于具有最大方差(通常对应最高SNR)的方向上。
我们的假设表明:寻找的目标基并非初始基,因为 ( x A , y A ) (x_A, y_A) (xA,yA)方向并不对应最大方差方向。最大化方差(根据假设即最大化SNR)等价于对初始基进行适当旋转。这一直观认识对应图2中 σ s i g n a l 2 \sigma^2_{signal} σsignal2线段指示的方向。在图示二维情况下,最大方差方向即数据云的最佳拟合线方向。因此,将初始基旋转至与最佳拟合线平行,就能揭示二维情况下弹簧的运动方向。如何将此概念推广到任意维度?在探讨这个问题前,我们需要从另一个视角重新审视。
B. Redundancy
图2揭示了数据中另一个干扰因素——冗余,这在弹簧案例中尤为明显:多个传感器记录了完全相同的动态信息。若重新审视图2,我们不禁要问:是否真有必要同时记录两个变量?图3展示了任意两种测量类型 r 1 r_1 r1与 r 2 r_2 r2之间可能存在的关联情况,其中左图显示两个毫无关联的观测值。由于无法通过 r 2 r_2 r2预测 r 1 r_1 r1,因此我们称 r 1 r_1 r1和 r 2 r_2 r2互不相关。

Fig3: 两个独立测量值
r
1
r_1
r1与
r
2
r_2
r2可能存在的冗余关系谱系:左侧测量值完全不相关,因为两者无法相互预测;而右侧测量值高度相关,表明存在严重冗余。
在图3的另一个极端情况下,右侧面板展示出高度相关的观测数据。这种极端相关可能由以下情况导致:
- 当摄像机 A A A与 B B B距离过近时, ( x A , x B ) (x_A, x_B) (xA,xB)的分布关系
- 采用不同单位制(如 x A x_A xA以米为单位, x A ^ \hat{x_A} xA^以英寸为单位)测量同一物理量
显然,对于图3右图所示情况,仅记录单一变量比记录双变量更具实际意义。原因在于:通过最佳拟合线可从 r 2 r_2 r2精确推算 r 1 r_1 r1(反之亦然)。仅记录单一响应不仅能更简洁地表达数据,还能将传感器记录量从2个变量降至1个。这正是降维技术的核心思想所在。
C. Covariance Matrix
在二维变量情况下,通过计算最佳拟合线斜率并评估拟合优度,可以轻松识别冗余数据。但如何将这种方法量化并推广到任意高维空间?让我们考察两个零均值测量数据集:
A
=
{
a
1
,
a
2
,
⋯
,
a
n
}
,
B
=
{
b
1
,
b
2
,
⋯
,
b
n
}
,
A=\{a_1,a_2,\cdots,a_n\}, B=\{b_1,b_2,\cdots,b_n\},
A={a1,a2,⋯,an},B={b1,b2,⋯,bn},
其中下标表示采样编号。A和B的方差分别定义为,
σ
A
2
=
1
n
Σ
i
a
i
2
,
σ
B
2
=
1
n
Σ
i
b
i
2
\sigma^2_{A}=\frac{1}{n}\Sigma_i{a^2_i}, \sigma^2_{B}=\frac{1}{n}\Sigma_i{b^2_i}
σA2=n1Σiai2,σB2=n1Σibi2
A与B的协方差正是这一思想的直接推广。
c o v a r i a n c e o f A a n d B ≡ σ A B 2 = 1 n Σ i a i b i covariance\quad of\quad A\quad and\quad B ≡ \sigma^2_{AB} =\frac{1}{n}\Sigma_i{a_ib_i} covarianceofAandB≡σAB2=n1Σiaibi
协方差度量两个变量间线性关系的强度:大正值表示强正相关,大负值则对应强负相关,其绝对值大小直接反映冗余程度。关于协方差还需注意:
- 当且仅当 A A A与 B B B不相关时 σ A B 2 \sigma^2_{AB} σAB2为零(如图2左图)
- 当 A = B A=B A=B时, σ A B 2 \sigma^2_{AB} σAB2等于 σ A 2 \sigma^2_{A} σA2
我们可以将
A
A
A和
B
B
B等价地转换为对应的行向量:
a
=
[
a
1
a
2
⋯
a
n
]
b
=
[
b
1
b
2
⋯
b
n
]
a = [a_1 a_2 \cdots a_n] \\ b = [b_1 b_2 \cdots b_n]
a=[a1a2⋯an]b=[b1b2⋯bn]
从而将协方差表示为点积矩阵运算。需要注意的是,实际计算协方差
σ
A
B
2
\sigma^2_{AB}
σAB2时采用
1
(
n
−
1
)
∑
a
i
b
i
\frac{1}{(n-1)}∑aᵢbᵢ
(n−1)1∑aibi作为归一化常数。这一细微调整源于估计理论,但已超出本教程讨论范围。
σ
A
B
2
≡
1
n
a
b
T
\sigma^2_{AB}\equiv\frac{1}{n}\mathbf{a}\mathbf{b^T}
σAB2≡n1abT
最终我们可以将两个向量的情况推广到任意数量。将行向量
a
\mathbf{a}
a和
b
\mathbf{b}
b分别重命名为
x
1
\mathbf{x_1}
x1和
x
2
\mathbf{x_2}
x2,并考虑其他带索引的行向量
x
3
,
⋯
,
x
m
\mathbf{x_3},\cdots,\mathbf{x_m}
x3,⋯,xm。定义一个新的
m
×
n
m×n
m×n矩阵
X
\mathbf{X}
X:
X
=
[
x
1
⋮
x
m
]
\mathbf{X}=\left [ \begin{matrix} \mathbf{x_1} \\ \mathbf{\vdots} \\ \mathbf{x_m} \\ \end{matrix} \right ]
X=
x1⋮xm
对 X \mathbf{X} X的一种解释如下: X \mathbf{X} X的每一行对应某种特定类型的所有测量值,每一列则对应某次特定试验的测量值集合(即第3.1节中的 X ⃗ \vec{X} X)。由此我们得到协方差矩阵 C X \mathbf{C_X} CX的定义:
C X ≡ 1 n X X T \begin{equation} \mathbf{C_X}\equiv\frac{1}{n}\mathbf{X}\mathbf{X^T} \end{equation} CX≡n1XXT
- 协方差矩阵 C X \mathbf{C_X} CX是一个 m × m m×m m×m的对称方阵(附录A定理2)
- 其对角线元素表示各类测量值的方差。
- C X \mathbf{C_X} CX的非对角项是测量类型之间的协方差。
协方差矩阵 C X \mathbf{C_X} CX记录了所有测量值对之间的协方差关系,其数值反映了测量数据中的噪声与冗余特性:
- 对角线元素:根据假设,较大方差值对应有意义的数据结构
- 非对角元素:较大绝对值表示高度冗余
假设我们可以对 C X \mathbf{C_X} CX进行优化处理,现定义经处理的协方差矩阵为 C Y \mathbf{C_Y} CY。那么,我们希望 C Y \mathbf{C_Y} CY具有哪些优化特征呢?
D. Diagonalize the Covariance Matrix
我们可以将前两节的核心目标总结为:(1) 通过协方差,衡量最小化冗余;(2) 通过方差,最大化信号。那么优化后的协方差矩阵 C Y \mathbf{C_Y} CY应具备哪些特征?
- C Y \mathbf{C_Y} CY所有非对角元素应为零,即 C Y \mathbf{C_Y} CY必须为对角矩阵。换言之, Y \mathbf{Y} Y已实现去相关。
- Y \mathbf{Y} Y中各维度应按方差大小降序排列。
对角化 C Y \mathbf{C_Y} CY存在多种方法,值得注意的是PCA选择了最简便的途径:它假设所有基向量 { p 1 , . . . , p m } \{\mathbf{p}_1,...,\mathbf{p}_m\} {p1,...,pm}都是标准正交的,即 P \mathbf{P} P为正交矩阵。为何这一假设最简便?
设想PCA的工作原理:在图2的简单示例中, P \mathbf{P} P如同广义旋转操作,将基向量对齐至最大方差方向。在多维空间中,这一过程可通过以下算法实现:
- 在 m m m维空间中选择使 X \mathbf{X} X方差最大的归一化方向,保存为向量 p 1 \mathbf{p_1} p1
- 继续寻找下一个最大方差方向,但受正交条件约束,仅在与已选方向正交的空间中进行搜索,保存为 p i \mathbf{p_i} pi
- 重复上述步骤直至选够 m m m个向量
最终得到的有序向量集 p \mathbf{p} p就是主成分。
虽然这个简单算法在理论上可行,但真正体现正交假设优越性的是:该假设使得问题存在高效解析解。我们将在后续章节讨论两种解法。
值得注意的是,通过设定方差降序排列,我们获得了评估主方向重要性的方法——每个方向 p 1 \mathbf{p_1} p1对应的方差量化了其"主成分"程度,从而实现对基向量的排序。现在让我们暂停片刻,回顾达成这一数学目标所做的所有假设及其意义。
E. Summary of Assumptions
本节将总结PCA背后的假设,并揭示这些假设可能失效的场景。
- 线性假设
线性假设将问题框定为基变换。多个研究领域已探索如何将该概念推广至非线性体系(参见讨论部分)。 - 大方差蕴含重要结构
该假设隐含数据具有高信噪比的前提,因此大方差主成分表征有意义结构,小方差主成分则对应噪声。需注意这是较强假设且可能不成立(参见讨论)。 - 主成分正交性
该假设通过直观简化,使PCA能借助线性代数分解技术求解。下文将重点阐述这两种技术。
至此我们已完成PCA推导的全部分析,接下来仅需解决线性代数问题。第一种解法较为直接,第二种则需理解重要的矩阵分解方法。
V. SOLVING PCA USING EIGENVECTOR DECOMPOSITION
基于特征向量分解的重要性质,我们推导出PCA的第一种代数解法。再次明确:数据集 X \mathbf{X} X是 m × n m×n m×n矩阵,其中 m m m为测量类型数量, n n n为样本数量。该目标可归纳如下:
寻找一个标准正交矩阵 P \mathbf{P} P,使得在 Y = P X \mathbf{Y=PX} Y=PX变换下,协方差矩阵 C Y = 1 n Y Y T \mathbf{C_Y}=\frac{1}{n}\mathbf{YY^T} CY=n1YYT成为对角矩阵。此时 P \mathbf{P} P的行向量即为 X \mathbf{X} X的主成分。
我们首先根据未知变量重写
C
Y
\mathbf{C_Y}
CY。
C
Y
=
1
n
Y
Y
T
=
1
n
(
P
X
)
(
P
X
)
T
=
1
n
P
X
X
T
P
T
=
P
(
1
n
X
X
T
)
P
T
C
Y
=
P
C
X
P
T
\mathbf{C_Y}=\frac{1}{n}\mathbf{YY^T} \\ =\frac{1}{n}\mathbf{(PX)(PX)^T} \\ =\frac{1}{n}\mathbf{PXX^TP^T} \\ =\mathbf{P(\frac{1}{n}XX^T)P^T} \\ \mathbf{C_Y=PC_XP^T}
CY=n1YYT=n1(PX)(PX)T=n1PXXTPT=P(n1XXT)PTCY=PCXPT
注意到我们在最后一行已经确定了 X \mathbf{X} X的协方差矩阵。
我们的方案是利用对称矩阵的性质:任何对称矩阵 A \mathbf{A} A都能被其特征向量组成的正交矩阵对角化(根据附录A定理3和4)。对于对称矩阵 A \mathbf{A} A,定理4给出 A = E D E T \mathbf{A=EDE^T} A=EDET,其中 D \mathbf{D} D为对角矩阵, E \mathbf{E} E是以特征向量为列构成的矩阵。
矩阵 A \mathbf{A} A可能只有 r ≤ m r≤m r≤m个正交特征向量,其中 r r r为矩阵的秩。当 A \mathbf{A} A的秩小于 m m m时,矩阵退化或所有数据都位于 r ≤ m r≤m r≤m维的子空间中。在保持正交性约束的前提下,我们可以通过选取额外的 ( m − r ) (m-r) (m−r)个正交向量来"填充"矩阵 E E E。这些附加向量不会影响最终解,因为其对应方向的方差为零。
现在关键在于:我们选择矩阵 P \mathbf{P} P,使其每一行 p i \mathbf{p_i} pi都是 1 n X X T \mathbf{\frac{1}{n}XX^T} n1XXT的特征向量。这样选择下, P ≡ E T \mathbf{P\equiv E^T} P≡ET。结合附录A定理1( P − 1 = P T \mathbf{P^{-1}= P^T} P−1=PT),即可完成对 C Y \mathbf{C_Y} CY的求解。
显然,这样的 P \mathbf{P} P选择实现了 C Y \mathbf{C_Y} CY的对角化——这正是PCA的核心目标。我们可以通过矩阵 P \mathbf{P} P和 C Y \mathbf{C_Y} CY来总结PCA的结果:
- X \mathbf{X} X的主成分是协方差矩阵 C X = 1 n X X T \mathbf{C_X=\frac{1}{n}XX^T} CX=n1XXT的特征向量
- C Y \mathbf{C_Y} CY的第 i i i个对角元素即为 X \mathbf{X} X沿 p i \mathbf{p_i} pi方向的方差
实际计算PCA时需:(1) 消除各测量类型的均值 (2) 计算 C X \mathbf{C_X} CX的特征向量。附录B提供的Matlab代码演示了该解法。
VI. A MORE GENERAL SOLUTION USING SVD
本节涉及较多数学推导,跳过不会影响理解连续性,仅为完整呈现而设。我们将推导PCA的另一种代数解法,并揭示PCA与奇异值分解(SVD)的密切关联——事实上二者的关系如此紧密,以至于名称常被混用。不过我们将看到,SVD是理解基变换的更通用方法。
首先快速推导分解过程,随后解释其数学含义,最后将这些结果与PCA相联系。
A. Singular Value Decomposition
设 X \mathbf{X} X为任意 n × m n×m n×m矩阵(请注意,在本节中,只有我们将约定从m×n逆转到n×m。该派生的原因将在第6.3节中明确),且 X T X \mathbf{X^TX} XTX是秩为 r r r的 m × m m×m m×m对称方阵。我们以看似随意的方式定义以下关键量:
- { v ^ 1 , v ^ 2 , ⋯ , v ^ r } \{\mathbf{\hat{v}_1,\hat{v}_2,\cdots,\hat{v}_r}\} {v^1,v^2,⋯,v^r}是对称矩阵 X T X \mathbf{X^TX} XTX的 m × 1 m×1 m×1正交特征向量集,对应特征值为 { λ 1 , λ 2 , ⋯ , λ r } \{\mathbf{{\lambda}_1,{\lambda}_2,\cdots,{\lambda}_r}\} {λ1,λ2,⋯,λr},满足: X T X v ^ i = λ i v ^ i \mathbf{XᵀXv̂ᵢ = λᵢv̂ᵢ} XTXv^i=λiv^i
- 定义奇异值 σ i ≡ λ i σᵢ ≡ \sqrt{ λᵢ} σi≡λi(取正实数根)
- { u ^ 1 , u ^ 2 , ⋯ , u ^ r } \{\mathbf{\hat{u}_1,\hat{u}_2,\cdots,\hat{u}_r}\} {u^1,u^2,⋯,u^r}是 n × 1 n×1 n×1向量集,定义为: u ^ i ≡ ( 1 / σ i ) X v ^ i \mathbf{ûᵢ ≡ (1/σᵢ)Xv̂ᵢ} u^i≡(1/σi)Xv^i
最终定义蕴含两个新的重要性质:
- 正交性条件: u ^ i ⋅ u ^ j = δ i j \mathbf{ûᵢ·ûⱼ = δᵢⱼ} u^i⋅u^j=δij (当i=j时为1,否则为0)
- 范数特性: ‖ X v ^ i ‖ = σ i \mathbf{‖Xv̂ᵢ‖ = σᵢ} ‖Xv^i‖=σi
定理5已证明这两个性质。至此,我们已具备构建矩阵分解的所有要素。奇异值分解的标量形式正是第三个定义的重新表述。
X v ^ i = σ i u ^ i \begin{equation} \mathbf{X\hat{v}_i=\sigma_i\hat{u}_i} \end{equation} Xv^i=σiu^i
这个结果表明了很多。 X \mathbf{X} X乘以 X T X \mathbf{X^TX} XTX的特征向量等于标量乘以另一向量。
特征向量集合 { v ^ 1 , v ^ 2 , ⋯ , v ^ r } \{\mathbf{\hat{v}_1,\hat{v}_2,\cdots,\hat{v}_r}\} {v^1,v^2,⋯,v^r}与向量集合 { u ^ 1 , u ^ 2 , ⋯ , u ^ r } \{\mathbf{\hat{u}_1,\hat{u}_2,\cdots,\hat{u}_r}\} {u^1,u^2,⋯,u^r}共同构成r维空间中的标准正交基组。
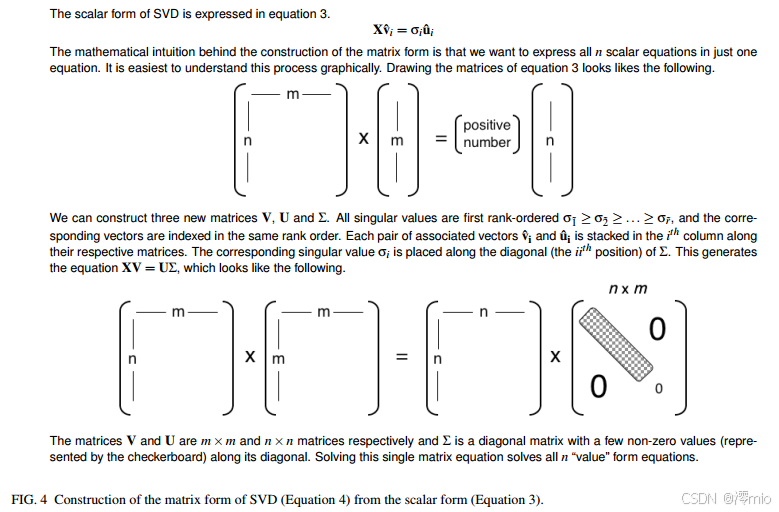
根据图4所示构造方法,我们可以将所有向量关系总结为单个矩阵乘法表示。首先构造新的对角矩阵
Σ
Σ
Σ:
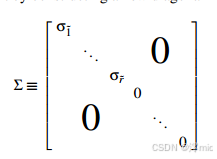
其中
σ
1
^
≥
σ
2
^
≥
.
.
.
≥
σ
r
^
\sigma_{\hat{1}} ≥ \sigma_{\hat{2}} ≥ ... ≥ \sigma_{\hat{r}}
σ1^≥σ2^≥...≥σr^为按秩排序的奇异值序列。相应地,我们构造以下配套的正交矩阵:
V
=
[
v
^
1
^
,
v
^
2
^
,
⋯
,
v
^
r
^
]
U
=
[
u
^
1
^
,
u
^
2
^
,
⋯
,
u
^
r
^
]
\mathbf{V=[\hat{v}_{\hat{1}},\hat{v}_{\hat{2}},\cdots,\hat{v}_{\hat{r}}]} \\ \mathbf{U=[\hat{u}_{\hat{1}},\hat{u}_{\hat{2}},\cdots,\hat{u}_{\hat{r}}]}
V=[v^1^,v^2^,⋯,v^r^]U=[u^1^,u^2^,⋯,u^r^]
其中我们已分别追加了
(
m
−
r
)
(m-r)
(m−r)和
(
n
−
r
)
(n-r)
(n−r)个标准正交向量来"填充"矩阵
V
\mathbf{V}
V和
U
\mathbf{U}
U(以处理退化情况)。图4直观展示了如何将这些部分组合形成SVD的矩阵形式:
X
V
=
U
Σ
\mathbf{XV = UΣ}
XV=UΣ
其中
V
\mathbf{V}
V和
U
\mathbf{U}
U的每列都实现了分解的标量形式,即式3。由于
V
\mathbf{V}
V是正交矩阵,两边同乘
V
−
1
=
V
T
\mathbf{V⁻¹=Vᵀ}
V−1=VT即得到最终分解式:
X = U Σ V T \begin{equation} \mathbf{X = UΣVᵀ } \end{equation} X=UΣVT
尽管这一推导看似缺乏直观动机,但分解式具有强大功能。式4表明:任意矩阵 X \mathbf{X} X都可分解为一个正交矩阵、对角矩阵和另一个正交矩阵的乘积(即旋转-拉伸-再旋转的过程)。理解式4的深层含义将是下节的重点。
B. Interpreting SVD
SVD的最终形式简洁却内涵深刻。我们不妨将式3重新理解为
X
a
=
k
b
\mathbf{Xa}=k\mathbf{b}
Xa=kb
其中
a
\mathbf{a}
a、
b
\mathbf{b}
b为列向量,
k
\mathbf{k}
k为标量常数。向量组
{
v
^
1
,
v
^
2
,
.
.
.
,
v
^
m
}
\mathbf{\{v̂₁,v̂₂,...,v̂ₘ\}}
{v^1,v^2,...,v^m}类比于
a
\mathbf{a}
a,
{
u
^
1
,
u
^
2
,
.
.
.
,
u
^
n
}
\mathbf{\{û₁,û₂,...,ûₙ\}}
{u^1,u^2,...,u^n}类比于
b
\mathbf{b}
b。其独特之处在于:这两组向量分别是
m
m
m维和
n
n
n维空间的标准正交基。直观地说,它们似乎能生成所有可能的"输入"(
a
\mathbf{a}
a)和"输出"(
b
\mathbf{b}
b)。那么能否严格证明
{
v
^
1
,
v
^
2
,
.
.
.
,
v
^
m
}
\mathbf{\{v̂₁,v̂₂,...,v̂ₘ\}}
{v^1,v^2,...,v^m}和
{
u
^
1
,
u
^
2
,
.
.
.
,
u
^
n
}
\mathbf{\{û₁,û₂,...,ûₙ\}}
{u^1,u^2,...,u^n}确实生成所有可能的输入输出空间呢?
通过对式4进行数学推导,我们可以将这一假设精确化:
X
=
U
Σ
V
T
U
T
X
=
Σ
V
T
U
T
X
=
Z
\mathbf{X = UΣVᵀ}\\ \mathbf{UᵀX = ΣVᵀ}\\ \mathbf{UᵀX = Z}
X=UΣVTUTX=ΣVTUTX=Z
其中,定义
Z
≡
Σ
V
T
\mathbf{Z ≡ ΣVᵀ}
Z≡ΣVT。需注意,原列向量
{
u
^
1
,
u
^
2
,
.
.
.
,
u
^
n
}
\mathbf{\{û₁,û₂,...,ûₙ\}}
{u^1,u^2,...,u^n}现作为行向量存在于
U
T
\mathbf{Uᵀ}
UT中。将此式与式1对比可见,
{
u
^
1
,
u
^
2
,
.
.
.
,
u
^
n
}
\mathbf{\{û₁,û₂,...,ûₙ\}}
{u^1,u^2,...,u^n}在此处的功能等价于
{
p
^
1
,
.
.
.
,
p
^
m
}
\{\mathbf{\hat{p}}_1,...,\mathbf{\hat{p}}_m\}
{p^1,...,p^m}。因此,
U
T
\mathbf{Uᵀ}
UT实现了从
X
\mathbf{X}
X到
Z
\mathbf{Z}
Z的基变换。延续之前的列向量变换逻辑,可以得出:正交基
U
T
\mathbf{Uᵀ}
UT(或
P
\mathbf{P}
P)对列向量的变换特性表明,
U
T
\mathbf{Uᵀ}
UT正是张成
X
\mathbf{X}
X列空间的基。列空间的数学定义严格刻画了矩阵所有可能的"输出"范围。
SVD具有一种精妙的对称性,使我们能定义对偶概念——行空间:
X
V
=
(
X
V
)
T
=
(
Σ
U
)
T
V
T
X
T
=
U
T
Σ
V
T
X
T
=
Z
\mathbf{XV = }\\ \mathbf{(XV)ᵀ = (ΣU)ᵀ}\\ \mathbf{VᵀXᵀ = UᵀΣ}\\ \mathbf{VᵀXᵀ = Z}
XV=(XV)T=(ΣU)TVTXT=UTΣVTXT=Z
其中,定义
Z
≡
U
T
Σ
\mathbf{Z ≡ UᵀΣ}
Z≡UTΣ。此时
V
T
\mathbf{Vᵀ}
VT的行向量(即V的列向量)成为将
X
T
\mathbf{Xᵀ}
XT变换为
Z
\mathbf{Z}
Z的正交基。由于X转置的存在,V正是张成X行空间的正交基。行空间同样严格定义了任意矩阵可能的"输入"范围。
当前我们仅触及了SVD深层内涵的表层。但就本教程而言,这些知识已足以理解PCA如何嵌入这一框架。
C. SVD and PCA
显然,PCA和SVD密切相关。让我们返回到原始的 m × n m×n m×n数据矩阵 X \mathbf{X} X。我们可以将新的矩阵 Y \mathbf{Y} Y定义为 n × m n×m n×m矩阵。 Y \mathbf{Y} Y是第6.1节的推导中规定的适当的 m × n m×n m×n尺寸。这就是6.1和图4中尺寸“翻转”的原因
Y
≡
1
n
X
T
\mathbf{Y}\equiv \frac{1}{\sqrt n}X^T
Y≡n1XT
Y
\mathbf{Y}
Y的每一列的均值为零。通过分析
Y
T
Y
\mathbf{Y^TY}
YTY,
Y
\mathbf{Y}
Y的选择变得清晰。
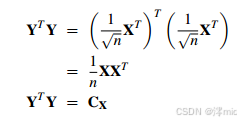
根据构造,
Y
T
Y
\mathbf{Y^TY}
YTY即为
X
\mathbf{X}
X的协方差矩阵。由第5节可知,
X
\mathbf{X}
X的主成分正是
C
X
\mathbf{C_X}
CX的特征向量。若对
Y
\mathbf{Y}
Y进行SVD分解,则矩阵
V
\mathbf{V}
V的列向量即为
Y
T
Y
=
C
X
\mathbf{Y^TY=C_X}
YTY=CX的特征向量。因此,
V
\mathbf{V}
V的列向量就是
X
\mathbf{X}
X的主成分。这一算法已封装于附录B的Matlab代码中。
这意味着什么? V \mathbf{V} V张成的行空间对应于 Y ≡ 1 n X T \mathbf{Y}\equiv \frac{1}{\sqrt n}X^T Y≡n1XT,因此 V \mathbf{V} V必然也张成 1 n X T \frac{1}{\sqrt n}X^T n1XT的列空间。由此可得:寻找主成分等价于求取X列空间的标准正交基。
VII. DISCUSSION
主成分分析(PCA)之所以获得广泛应用,在于它通过线性代数的解析解揭示了复杂数据集中的本质结构。图5简要总结了PCA的实施流程。

PCA的核心优势在于量化各维度对数据变异性的贡献度——通过测量各主成分方向的方差,可比较不同维度的相对重要性。使用此方法的深层期望是:仅需少量主成分(少于测量类型数量)的方差,就能合理表征整个数据集。这正是所有降维方法的基本原理,也是当前研究的热点领域。以弹簧系统为例,尽管记录了6个维度,PCA却能识别出主要变异仅存在于单一维度(运动方向 x ^ \hat{x} x^)。
虽然PCA能成功处理众多实际问题,但严谨的研究者必须追问:PCA何时会失效?在回答之前,我们需注意该算法的一个显著特点:PCA是完全非参数化的——可处理任何数据集并给出唯一解,无需调整参数或考虑数据采集方式。从积极角度看,这种"即插即用"的特性保证了结果的唯一性和客观性;但从另一角度看,PCA对数据来源的"不可知性"也是其局限。例如图6a所示的摩天轮乘客追踪案例,数据本可由单一变量(轮盘进动角θ)完美描述,但PCA却无法还原该变量。

Fig6:PCA失效的典型案例(红线标示)。
(a) 摩天轮乘客追踪(黑点显示),其全部动态可由轮盘相位角θ这一非线性基组合完美描述;
(b) 本数据集因非高斯分布和非正交轴导致PCA失效,最大方差方向与正确解不符。
A. Limits and Statistics of Dimensional Reduction
要更深入地理解PCA的局限性,需要审视其基本假设,并更严谨地考量数据来源。简言之,该方法的核心目标是实现数据集去相关化——即消除二阶依赖性。其实现方式可类比在美国西部小镇的探路策略:先沿最长主干道行驶,遇大路则直角转弯,如此反复。此比喻中,PCA要求每条新道路必须与前路垂直,但如图6b所示,数据(或城镇)可能沿非正交轴分布,这种正交性要求显然过于严苛。图6展示的两个案例中,PCA都给出了不尽人意的结果。
为解决这些问题,必须明确定义何为"最优结果"。在降维语境下,一个成功标准是降维表示能多大程度还原原始数据。统计上,这需要定义误差函数(或称损失函数)。可以证明,在均方误差(即L2范数)这一常见损失函数下,PCA能提供最优的降维表示。这意味着正交主成分方向确实是预测原始数据的最佳解。但面对图6案例,该结论似乎与直觉相悖。
矛盾的关键在于分析目标的设定。PCA的目标是消除数据中的二阶依赖性。而图6数据集存在更高阶的变量间依赖,仅消除二阶依赖自然无法揭示全部结构。(何时二阶依赖足以揭示数据集中的所有依赖关系?当数据的一阶和二阶统计量构成充分统计量时,这一统计条件即被满足。例如,高斯分布的数据集就满足这一特性。)
针对高阶依赖的解决方案有多种:若具备先验知识,可对数据施加非线性变换(如核方法)将其转换到更合适的基空间,例如将图6a数据转为极坐标表示,这种参数化方法常称为核PCA。
另一思路是从更广义的统计依赖性定义出发,要求降维后的数据维度间统计独立。这类称为独立成分分析(ICA)的算法,已在许多PCA失效的领域取得成功。ICA虽广泛应用于信号和图像处理,但其解有时难以计算。