PyTorch深度学习框架60天进阶学习计划 - 第25天:移动端模型部署(第一部分)
PyTorch深度学习框架60天进阶学习计划 - 第25天:移动端模型部署(第一部分)
学习目标
- 使用TensorRT优化图像分类模型
- 实践INT8量化校准技术
- 测试Android端推理帧率提升效果
1. 移动端模型部署概述
深度学习模型在训练阶段通常运行在高性能GPU上,但在实际应用中,尤其是移动端设备,资源受限且对功耗敏感。因此,模型部署前的优化至关重要。今天我们将专注于使用NVIDIA的TensorRT工具优化PyTorch训练的图像分类模型,并测试其在Android设备上的性能提升。
1.1 移动端部署面临的挑战
| 挑战 | 描述 | 解决方向 |
|---|---|---|
| 计算资源有限 | 移动设备CPU/GPU性能弱于服务器 | 模型压缩、量化 |
| 内存限制 | RAM容量小,无法加载大模型 | 模型剪枝、蒸馏 |
| 功耗敏感 | 电池容量有限,需控制功耗 | 高效算法、硬件加速 |
| 多平台适配 | Android、iOS等平台差异大 | 跨平台框架、针对性优化 |
| 实时性要求 | 用户交互需低延迟 | 模型并行、流水线设计 |
1.2 常用移动端部署技术对比
| 技术 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| TensorRT | 高性能、支持多精度、完整优化 | 仅支持NVIDIA设备、学习曲线陡 | 高性能设备、需要极致性能 |
| TensorFlow Lite | 跨平台支持好、工具链完整 | 优化不如TensorRT彻底 | 通用安卓设备部署 |
| ONNX Runtime | 兼容性强、支持多框架 | 优化程度中等 | 需要跨框架兼容性场景 |
| PyTorch Mobile | 与PyTorch无缝衔接、易用 | 性能较差、占用较大 | 快速原型验证、简单场景 |
| NCNN | 超轻量级、专为移动优化 | API不友好、生态较小 | 极度轻量的场景 |
2. TensorRT基础
2.1 什么是TensorRT?
TensorRT是NVIDIA提供的高性能深度学习推理优化器,能显著提升GPU上的推理性能。其核心优势包括:
- 网络优化:层融合、去除不必要的重排、优化内存使用
- 精度校准:支持FP32、FP16、INT8多种精度模式
- 动态张量内存:最小化内存占用
- 多流执行:支持并行处理多个输入流
- 多精度支持:平衡精度和性能
2.2 TensorRT工作流程
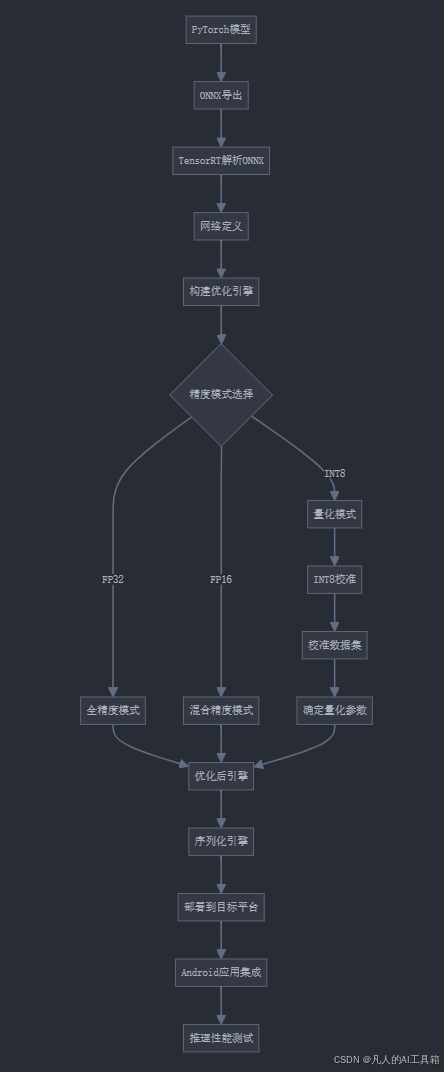
3. 从PyTorch到TensorRT的转换流程
3.1 环境准备
首先,我们需要设置正确的环境。以下是所需的主要组件:
# 安装必要的依赖
pip install torch torchvision onnx numpy Pillow pycuda
# 注意:TensorRT需要单独安装,不能通过pip安装
# 请从NVIDIA官网下载对应版本的TensorRT
3.2 PyTorch模型到ONNX的转换
ONNX (Open Neural Network Exchange) 是一个开放格式,用于表示深度学习模型。它能够在不同框架间转换模型,是连接PyTorch和TensorRT的桥梁。
import torch
import torchvision.models as models
import os
def convert_to_onnx(model_name='resnet50', batch_size=1, opset_version=11):
"""
将PyTorch预训练的图像分类模型转换为ONNX格式
Args:
model_name: 模型名称,如'resnet50', 'mobilenet_v2'等
batch_size: 推理时的批量大小
opset_version: ONNX操作集版本
Returns:
onnx_path: 保存的ONNX模型路径
"""
print(f"正在转换{model_name}为ONNX格式...")
# 加载预训练模型
if model_name == 'resnet50':
model = models.resnet50(pretrained=True)
elif model_name == 'mobilenet_v2':
model = models.mobilenet_v2(pretrained=True)
elif model_name == 'efficientnet_b0':
model = models.efficientnet_b0(pretrained=True)
else:
raise ValueError(f"不支持的模型: {model_name}")
# 设置为评估模式
model.eval()
# 创建输入tensor
input_tensor = torch.randn(batch_size, 3, 224, 224)
# 导出路径
onnx_path = f"{model_name}.onnx"
# 导出为ONNX格式
torch.onnx.export(
model, # 要转换的模型
input_tensor, # 模型输入
onnx_path, # 输出文件路径
export_params=True, # 存储训练后的参数权重
opset_version=opset_version,# ONNX算子集版本
do_constant_folding=True, # 是否执行常量折叠优化
input_names=['input'], # 输入名称
output_names=['output'], # 输出名称
dynamic_axes={ # 动态尺寸支持
'input': {0: 'batch_size'},
'output': {0: 'batch_size'}
}
)
# 验证ONNX模型
import onnx
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
print(f"模型已成功转换并保存到 {onnx_path}")
print(f"模型输入: {onnx_model.graph.input}")
print(f"模型输出: {onnx_model.graph.output}")
return onnx_path
if __name__ == "__main__":
# 可选模型: resnet50, mobilenet_v2, efficientnet_b0
model_name = "mobilenet_v2"
onnx_path = convert_to_onnx(model_name=model_name, batch_size=1)
print(f"ONNX模型已保存到: {onnx_path}")
3.3 ONNX到TensorRT引擎的转换
一旦我们有了ONNX格式的模型,下一步就是使用TensorRT将其优化并创建推理引擎。
import os
import sys
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import time
class ONNXtoTensorRT:
def __init__(self):
"""初始化TensorRT相关组件"""
# 创建logger
self.logger = trt.Logger(trt.Logger.WARNING)
# 创建构建器
self.builder = trt.Builder(self.logger)
# 创建网络定义
self.network = self.builder.create_network(
1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
)
# 创建配置对象
self.config = self.builder.create_builder_config()
# 解析器
self.parser = trt.OnnxParser(self.network, self.logger)
# 设置工作空间大小 (1GB)
self.config.max_workspace_size = 1 << 30
def build_engine_from_onnx(self, onnx_path, engine_path, precision="fp32"):
"""
从ONNX模型创建TensorRT引擎
Args:
onnx_path: ONNX模型路径
engine_path: 输出引擎路径
precision: 精度模式,可选 'fp32', 'fp16', 'int8'
Returns:
成功则返回True,否则返回False
"""
print(f"从ONNX模型构建TensorRT引擎,精度模式: {precision}")
# 读取ONNX模型
with open(onnx_path, "rb") as model:
if not self.parser.parse(model.read()):
print(f"ERROR: ONNX模型解析失败")
for error in range(self.parser.num_errors):
print(self.parser.get_error(error))
return False
# 设置精度模式
if precision.lower() == "fp16" and self.builder.platform_has_fast_fp16:
print("启用FP16模式")
self.config.set_flag(trt.BuilderFlag.FP16)
elif precision.lower() == "int8" and self.builder.platform_has_fast_int8:
print("启用INT8模式")
self.config.set_flag(trt.BuilderFlag.INT8)
# INT8模式需要校准器,这里将在下一节中详细实现
# 构建并序列化引擎
print("构建TensorRT引擎中...")
start_time = time.time()
engine = self.builder.build_engine(self.network, self.config)
build_time = time.time() - start_time
print(f"引擎构建完成,耗时: {build_time:.2f}秒")
if engine:
with open(engine_path, "wb") as f:
f.write(engine.serialize())
print(f"TensorRT引擎已保存到: {engine_path}")
return True
else:
print("ERROR: 引擎构建失败")
return False
def load_engine(self, engine_path):
"""
加载序列化的TensorRT引擎
Args:
engine_path: 引擎文件路径
Returns:
TensorRT引擎
"""
print(f"加载TensorRT引擎: {engine_path}")
runtime = trt.Runtime(self.logger)
with open(engine_path, "rb") as f:
engine_data = f.read()
engine = runtime.deserialize_cuda_engine(engine_data)
if engine:
print("引擎加载成功")
return engine
else:
print("ERROR: 引擎加载失败")
return None
def infer(self, engine, input_data):
"""
使用TensorRT引擎进行推理
Args:
engine: TensorRT引擎
input_data: 输入数据 (numpy数组)
Returns:
输出数据 (numpy数组)
"""
# 创建执行上下文
context = engine.create_execution_context()
# 分配内存
h_input = cuda.pagelocked_empty(input_data.shape, dtype=np.float32)
h_output = cuda.pagelocked_empty(
(input_data.shape[0], 1000), dtype=np.float32) # 假设输出是1000类
# 将输入数据复制到主机内存
np.copyto(h_input, input_data)
# 分配设备内存
d_input = cuda.mem_alloc(h_input.nbytes)
d_output = cuda.mem_alloc(h_output.nbytes)
# 创建CUDA流
stream = cuda.Stream()
# 将输入数据从主机内存复制到设备内存
cuda.memcpy_htod_async(d_input, h_input, stream)
# 执行推理
bindings = [int(d_input), int(d_output)]
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# 将输出数据从设备内存复制到主机内存
cuda.memcpy_dtoh_async(h_output, d_output, stream)
# 同步流
stream.synchronize()
return h_output
if __name__ == "__main__":
# 示例用法
converter = ONNXtoTensorRT()
onnx_path = "mobilenet_v2.onnx"
engine_path = "mobilenet_v2_fp32.trt"
# 构建FP32精度引擎
success = converter.build_engine_from_onnx(
onnx_path=onnx_path,
engine_path=engine_path,
precision="fp32"
)
if success:
# 加载引擎
engine = converter.load_engine(engine_path)
# 准备输入数据
input_data = np.random.rand(1, 3, 224, 224).astype(np.float32)
# 运行推理
start_time = time.time()
output = converter.infer(engine, input_data)
inference_time = time.time() - start_time
print(f"推理完成,耗时: {inference_time*1000:.2f}毫秒")
print(f"输出形状: {output.shape}")
# 获取Top-5预测类别
top5_indices = np.argsort(output[0])[-5:][::-1]
print(f"Top-5预测类别索引: {top5_indices}")
4. INT8量化校准
4.1 INT8量化原理
INT8量化是一种将模型从FP32或FP16精度降低到INT8精度的技术。它通过将浮点权重和激活值映射到8位整数范围内,能显著减少内存占用和计算开销,加速推理过程。
INT8量化的主要步骤:
- 确定动态范围:分析权重和激活值的分布,确定最大/最小值
- 缩放:通过缩放因子将FP32值映射到INT8范围(-128到127)
- 校准:使用代表性数据集校准量化参数
- 应用量化:使用校准参数进行真实推理
4.2 TensorRT INT8校准过程
要在TensorRT中应用INT8量化,需要实现一个校准器来收集网络中的激活统计信息:
import os
import numpy as np
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
from PIL import Image
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import torchvision.datasets as datasets
import time
class ImagenetCalibrationDataset(Dataset):
"""ImageNet校准数据集加载器"""
def __init__(self, calibration_dir, num_samples=100):
"""
初始化校准数据集
Args:
calibration_dir: 校准图像目录
num_samples: 采样数量
"""
self.image_list = []
# 查找所有图像文件
for root, _, files in os.walk(calibration_dir):
for file in files:
if file.endswith(('.jpg', '.jpeg', '.png')):
self.image_list.append(os.path.join(root, file))
# 限制样本数量
self.image_list = self.image_list[:num_samples]
# 图像预处理转换
self.transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
print(f"加载了{len(self.image_list)}张校准图像")
def __len__(self):
return len(self.image_list)
def __getitem__(self, idx):
img_path = self.image_list[idx]
image = Image.open(img_path).convert('RGB')
tensor = self.transform(image)
return tensor.numpy()
# 实现INT8校准器
class ImageNetEntropyCalibrator(trt.IInt8EntropyCalibrator2):
"""ImageNet INT8熵校准器"""
def __init__(self, calibration_dir, batch_size=8, num_samples=100, cache_file="calibration.cache"):
"""
初始化校准器
Args:
calibration_dir: 校准图像目录
batch_size: 批量大小
num_samples: 采样数量
cache_file: 校准缓存文件路径
"""
super().__init__()
self.cache_file = cache_file
self.batch_size = batch_size
# 创建校准数据集
dataset = ImagenetCalibrationDataset(calibration_dir, num_samples)
self.dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4
)
# 迭代器
self.iterator = iter(self.dataloader)
# 分配CUDA内存
self.device_input = cuda.mem_alloc(batch_size * 3 * 224 * 224 * 4) # NCHW, FP32
# 存储未使用批次
self.batches = []
for batch in self.dataloader:
self.batches.append(batch)
self.batch_idx = 0
print(f"校准器已准备好,共{len(self.batches)}个批次")
def get_batch_size(self):
"""返回校准批次大小"""
return self.batch_size
def get_batch(self, names):
"""
获取下一批校准数据
Args:
names: 输入张量名称列表
Returns:
是否还有数据
"""
if self.batch_idx >= len(self.batches):
return None
# 获取当前批次
batch = self.batches[self.batch_idx].astype(np.float32)
# 如果批次不完整则填充
if batch.shape[0] < self.batch_size:
# 填充到完整批次
padding = np.zeros((self.batch_size - batch.shape[0], 3, 224, 224), dtype=np.float32)
batch = np.concatenate([batch, padding], axis=0)
# 复制到GPU
cuda.memcpy_htod(self.device_input, batch)
self.batch_idx += 1
return [self.device_input]
def read_calibration_cache(self):
"""
读取校准缓存
Returns:
缓存数据或None
"""
if os.path.exists(self.cache_file):
with open(self.cache_file, "rb") as f:
return f.read()
return None
def write_calibration_cache(self, cache):
"""
写入校准缓存
Args:
cache: 校准数据
"""
with open(self.cache_file, "wb") as f:
f.write(cache)
print(f"校准缓存已保存到{self.cache_file}")
# 扩展ONNXtoTensorRT类以支持INT8校准
class ONNXtoTensorRTwithINT8(ONNXtoTensorRT):
def build_engine_with_int8(self, onnx_path, engine_path, calibration_dir, batch_size=8, num_samples=100):
"""
使用INT8校准构建TensorRT引擎
Args:
onnx_path: ONNX模型路径
engine_path: 输出引擎路径
calibration_dir: 校准图像目录
batch_size: 校准批次大小
num_samples: 校准样本数量
Returns:
成功则返回True,否则返回False
"""
print(f"从ONNX模型构建INT8 TensorRT引擎")
# 读取ONNX模型
with open(onnx_path, "rb") as model:
if not self.parser.parse(model.read()):
print(f"ERROR: ONNX模型解析失败")
for error in range(self.parser.num_errors):
print(self.parser.get_error(error))
return False
# 启用INT8模式
if self.builder.platform_has_fast_int8:
print("启用INT8模式")
self.config.set_flag(trt.BuilderFlag.INT8)
# 创建校准器
calibrator = ImageNetEntropyCalibrator(
calibration_dir=calibration_dir,
batch_size=batch_size,
num_samples=num_samples,
cache_file="calibration.cache"
)
# 设置INT8校准器
self.config.int8_calibrator = calibrator
else:
print("警告: 平台不支持INT8,将回退到FP32")
# 构建并序列化引擎
print("构建TensorRT引擎中...")
start_time = time.time()
engine = self.builder.build_engine(self.network, self.config)
build_time = time.time() - start_time
print(f"引擎构建完成,耗时: {build_time:.2f}秒")
if engine:
with open(engine_path, "wb") as f:
f.write(engine.serialize())
print(f"INT8 TensorRT引擎已保存到: {engine_path}")
return True
else:
print("ERROR: 引擎构建失败")
return False
if __name__ == "__main__":
# 此处需要有校准数据集,可以使用部分ImageNet验证集
# 如果没有,可以创建一个临时目录存放几张图像
calibration_dir = "calibration_images"
if not os.path.exists(calibration_dir):
os.makedirs(calibration_dir)
print(f"请在{calibration_dir}目录下放置校准图像")
# 示例用法
converter = ONNXtoTensorRTwithINT8()
onnx_path = "mobilenet_v2.onnx"
engine_path = "mobilenet_v2_int8.trt"
# 构建INT8精度引擎
if os.path.exists(calibration_dir) and len(os.listdir(calibration_dir)) > 0:
success = converter.build_engine_with_int8(
onnx_path=onnx_path,
engine_path=engine_path,
calibration_dir=calibration_dir,
batch_size=8,
num_samples=100 # 使用100张图像进行校准
)
if success:
print("INT8引擎构建成功")
else:
print(f"请在{calibration_dir}目录下放置校准图像后再运行")
4.3 量化校准的最佳实践
INT8量化校准是一个关键步骤,其质量直接影响最终模型的准确性。以下是一些最佳实践:
| 最佳实践 | 说明 |
|---|---|
| 校准数据集选择 | 使用能代表真实数据分布的样本,通常100-1000张图像即可 |
| 批次大小设置 | 较大的批次可加速校准过程,但需根据GPU内存调整 |
| 缓存校准结果 | 保存校准缓存文件,避免重复校准 |
| 校准算法选择 | TensorRT提供多种校准算法:熵校准器、分位数校准器等 |
| 预处理一致性 | 确保校准和推理时使用相同的预处理流程 |
| 观察精度下降 | 监控量化前后的精度,确保可接受的精度损失 |
5. 性能测试与比较
为了全面评估不同精度模式下的模型性能,我们将实现一个完整的性能测试框架:
import os
import time
import numpy as np
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import torch
import torchvision.models as models
from PIL import Image
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import json
import pandas as pd
from tabulate import tabulate
class PerformanceTester:
def __init__(self):
"""初始化性能测试器"""
self.logger = trt.Logger(trt.Logger.WARNING)
# 图像预处理转换
self.transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# ImageNet类别映射
self.idx_to_class = self._load_imagenet_labels()
def _load_imagenet_labels(self):
"""加载ImageNet类别标签"""
# 加载标签映射
try:
with open('imagenet_labels.json', 'r') as f:
return json.load(f)
except:
# 如果文件不存在,返回简单的索引映射
return {str(i): f"class_{i}" for i in range(1000)}
def load_engine(self, engine_path):
"""
加载TensorRT引擎
Args:
engine_path: 引擎文件路径
Returns:
TensorRT引擎
"""
runtime = trt.Runtime(self.logger)
with open(engine_path, "rb") as f:
engine_data = f.read()
engine = runtime.deserialize_cuda_engine(engine_data)
if not engine:
raise RuntimeError(f"引擎加载失败: {engine_path}")
return engine
def prepare_input(self, image_path):
"""
准备模型输入
Args:
image_path: 图像路径
Returns:
处理后的输入张量
"""
image = Image.open(image_path).convert('RGB')
tensor = self.transform(image)
return tensor.numpy()
def infer_tensorrt(self, engine, input_data, num_warmup=10, num_runs=100):
"""
使用TensorRT引擎进行推理并测量性能
Args:
engine: TensorRT引擎
input_data: 输入数据 (numpy数组)
num_warmup: 预热运行次数
num_runs: 性能测试运行次数
Returns:
性能指标和推理结果
"""
# 创建执行上下文
context = engine.create_execution_context()
# 预留内存
h_input = cuda.pagelocked_empty(input_data.shape, dtype=np.float32)
h_output = cuda.pagelocked_empty((input_data.shape[0], 1000), dtype=np.float32)
# 复制输入数据
np.copyto(h_input, input_data)
# 分配设备内存
d_input = cuda.mem_alloc(h_input.nbytes)
d_output = cuda.mem_alloc(h_output.nbytes)
# 创建CUDA流
stream = cuda.Stream()
# 设置绑定
bindings = [int(d_input), int(d_output)]
# 预热
print(f"进行{num_warmup}次预热推理...")
for _ in range(num_warmup):
cuda.memcpy_htod_async(d_input, h_input, stream)
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
cuda.memcpy_dtoh_async(h_output, d_output, stream)
stream.synchronize()
# 性能测试
print(f"执行{num_runs}次性能测试...")
latencies = []
for _ in range(num_runs):
# 记录开始时间
start_time = time.time()
# 推理
cuda.memcpy_htod_async(d_input, h_input, stream)
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
cuda.memcpy_dtoh_async(h_output, d_output, stream)
stream.synchronize()
# 记录结束时间
end_time = time.time()
latencies.append((end_time - start_time) * 1000) # 转换为毫秒
# 计算性能指标
avg_latency = np.mean(latencies)
min_latency = np.min(latencies)
max_latency = np.max(latencies)
p95_latency = np.percentile(latencies, 95)
fps = 1000 / avg_latency
# 获取输出结果
output = h_output.copy()
# 释放资源
del context
return {
"avg_latency_ms": avg_latency,
"min_latency_ms": min_latency,
"max_latency_ms": max_latency,
"p95_latency_ms": p95_latency,
"fps": fps,
"output": output
}
def infer_pytorch(self, model_name, input_data, num_warmup=10, num_runs=100):
"""
使用PyTorch模型进行推理并测量性能
Args:
model_name: 模型名称
input_data: 输入数据 (numpy数组)
num_warmup: 预热运行次数
num_runs: 性能测试运行次数
Returns:
性能指标和推理结果
"""
# 加载预训练模型
if model_name == 'resnet50':
model = models.resnet50(pretrained=True)
elif model_name == 'mobilenet_v2':
model = models.mobilenet_v2(pretrained=True)
elif model_name == 'efficientnet_b0':
model = models.efficientnet_b0(pretrained=True)
else:
raise ValueError(f"不支持的模型: {model_name}")
# 设置为评估模式
model.eval()
# 确定设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 转换输入
tensor_input = torch.from_numpy(input_data).to(device)
# 预热
print(f"进行{num_warmup}次预热推理...")
with torch.no_grad():
for _ in range(num_warmup):
_ = model(tensor_input)
# 性能测试
print(f"执行{num_runs}次性能测试...")
latencies = []
output = None
with torch.no_grad():
for _ in range(num_runs):
# 记录开始时间
start_time = time.time()
# 推理
output = model(tensor_input)
# 同步GPU
if device.type == 'cuda':
torch.cuda.synchronize()
# 记录结束时间
end_time = time.time()
latencies.append((end_time - start_time) * 1000) # 转换为毫秒
# 计算性能指标
avg_latency = np.mean(latencies)
min_latency = np.min(latencies)
max_latency = np.max(latencies)
p95_latency = np.percentile(latencies, 95)
fps = 1000 / avg_latency
# 获取输出结果并转换为numpy
output = output.cpu().numpy()
return {
"avg_latency_ms": avg_latency,
"min_latency_ms": min_latency,
"max_latency_ms": max_latency,
"p95_latency_ms": p95_latency,
"fps": fps,
"output": output
}
def compare_results(self, pytorch_output, tensorrt_output, top_k=5):
"""
比较PyTorch和TensorRT的输出结果
Args:
pytorch_output: PyTorch推理结果
tensorrt_output: TensorRT推理结果
top_k: 比较Top-K结果
Returns:
比较结果
"""
# 获取Top-K预测
pytorch_top_indices = np.argsort(pytorch_output[0])[-top_k:][::-1]
tensorrt_top_indices = np.argsort(tensorrt_output[0])[-top_k:][::-1]
# 检查Top-1是否匹配
top1_match = pytorch_top_indices[0] == tensorrt_top_indices[0]
# 计算Top-K准确率
topk_match_count = len(set(pytorch_top_indices) & set(tensorrt_top_indices))
topk_accuracy = topk_match_count / top_k
# 计算输出差异
l2_diff = np.sqrt(np.sum((pytorch_output - tensorrt_output) ** 2))
return {
"top1_match": top1_match,
"topk_accuracy": topk_accuracy,
"l2_diff": l2_diff,
"pytorch_top_indices": pytorch_top_indices,
"tensorrt_top_indices": tensorrt_top_indices,
"pytorch_top_classes": [self.idx_to_class.get(str(idx), f"class_{idx}") for idx in pytorch_top_indices],
"tensorrt_top_classes": [self.idx_to_class.get(str(idx), f"class_{idx}") for idx in tensorrt_top_indices]
}
def benchmark_and_compare(self, model_name, image_path, engines, num_runs=100):
"""
对比不同精度引擎的性能和准确性
Args:
model_name: 模型名称
image_path: 测试图像路径
engines: 引擎路径字典 {精度: 路径}
num_runs: 测试运行次数
Returns:
基准测试结果
"""
# 准备输入数据
input_data = self.prepare_input(image_path)
input_batch = np.expand_dims(input_data, axis=0)
results = {}
# 运行PyTorch基准测试
print(f"运行PyTorch基准测试...")
results["pytorch"] = self.infer_pytorch(model_name, input_batch, num_runs=num_runs)
# 运行不同精度TensorRT基准测试
for precision, engine_path in engines.items():
print(f"运行{precision} TensorRT基准测试...")
engine = self.load_engine(engine_path)
results[precision] = self.infer_tensorrt(engine, input_batch, num_runs=num_runs)
# 比较输出结果
comparison = self.compare_results(results["pytorch"]["output"], results[precision]["output"])
results[precision].update({"comparison": comparison})
# 汇总性能指标
summary = self.summarize_results(results)
return results, summary
def summarize_results(self, results):
"""
汇总基准测试结果
Args:
results: 基准测试结果字典
Returns:
汇总数据
"""
# 提取性能指标
summary = {
"framework": [],
"avg_latency_ms": [],
"min_latency_ms": [],
"max_latency_ms": [],
"p95_latency_ms": [],
"fps": [],
"speedup": [],
"top1_match": [],
"topk_accuracy": [],
"l2_diff": []
}
# 添加PyTorch结果
base_latency = results["pytorch"]["avg_latency_ms"]
summary["framework"].append("PyTorch")
summary["avg_latency_ms"].append(results["pytorch"]["avg_latency_ms"])
summary["min_latency_ms"].append(results["pytorch"]["min_latency_ms"])
summary["max_latency_ms"].append(results["pytorch"]["max_latency_ms"])
summary["p95_latency_ms"].append(results["pytorch"]["p95_latency_ms"])
summary["fps"].append(results["pytorch"]["fps"])
summary["speedup"].append(1.0)
summary["top1_match"].append("基准")
summary["topk_accuracy"].append("基准")
summary["l2_diff"].append(0.0)
# 添加TensorRT结果
for precision in [k for k in results.keys() if k != "pytorch"]:
summary["framework"].append(f"TensorRT {precision}")
summary["avg_latency_ms"].append(results[precision]["avg_latency_ms"])
summary["min_latency_ms"].append(results[precision]["min_latency_ms"])
summary["max_latency_ms"].append(results[precision]["max_latency_ms"])
summary["p95_latency_ms"].append(results[precision]["p95_latency_ms"])
summary["fps"].append(results[precision]["fps"])
summary["speedup"].append(base_latency / results[precision]["avg_latency_ms"])
summary["top1_match"].append("是" if results[precision]["comparison"]["top1_match"] else "否")
summary["topk_accuracy"].append(f"{results[precision]['comparison']['topk_accuracy']*100:.1f}%")
summary["l2_diff"].append(results[precision]["comparison"]["l2_diff"])
return summary
def plot_performance(self, summary):
"""
可视化性能比较
Args:
summary: 汇总结果
"""
# 创建DataFrame
df = pd.DataFrame(summary)
# 设置图表样式
plt.style.use('ggplot')
# 创建图表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 绘制延迟比较图
x = np.arange(len(df["framework"]))
ax1.bar(x, df["avg_latency_ms"], color='skyblue')
ax1.set_title('平均延迟比较')
ax1.set_xlabel('框架/精度')
ax1.set_ylabel('延迟 (ms)')
ax1.set_xticks(x)
ax1.set_xticklabels(df["framework"], rotation=45, ha='right')
# 在条形上方添加数值标签
for i, v in enumerate(df["avg_latency_ms"]):
ax1.text(i, v + 0.1, f"{v:.2f}", ha='center')
# 绘制FPS比较图
ax2.bar(x, df["fps"], color='lightgreen')
ax2.set_title('帧率 (FPS) 比较')
ax2.set_xlabel('框架/精度')
ax2.set_ylabel('FPS')
ax2.set_xticks(x)
ax2.set_xticklabels(df["framework"], rotation=45, ha='right')
# 在条形上方添加数值标签
for i, v in enumerate(df["fps"]):
ax2.text(i, v + 0.1, f"{v:.2f}", ha='center')
plt.tight_layout()
plt.savefig('performance_comparison.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印性能表格
print("\n性能比较表格:")
print(tabulate(df, headers='keys', tablefmt='grid', showindex=False))
if __name__ == "__main__":
# 测试示例
tester = PerformanceTester()
model_name = "mobilenet_v2"
image_path = "test_image.jpg" # 替换为实际测试图像路径
# 确保测试图像存在
if not os.path.exists(image_path):
# 如果测试图像不存在,创建一个随机图像用于测试
print(f"未找到测试图像: {image_path},创建随机测试图像...")
random_image = np.random.randint(0, 255, (224, 224, 3), dtype=np.uint8)
random_pil = Image.fromarray(random_image)
random_pil.save(image_path)
# 定义要测试的引擎
engines = {
"FP32": f"{model_name}_fp32.trt",
"FP16": f"{model_name}_fp16.trt",
"INT8": f"{model_name}_int8.trt"
}
# 过滤掉不存在的引擎
engines = {k: v for k, v in engines.items() if os.path.exists(v)}
if not engines:
print("未找到任何TensorRT引擎,请先运行转换脚本生成引擎文件")
else:
print(f"找到以下引擎文件: {list(engines.keys())}")
# 执行基准测试
results, summary = tester.benchmark_and_compare(
model_name=model_name,
image_path=image_path,
engines=engines,
num_runs=50 # 减少运行次数以加快测试
)
# 显示性能比较
tester.plot_performance(summary)
6. Android端部署与优化
将TensorRT优化后的模型部署到Android设备上需要几个关键步骤。我们将使用TensorRT的Android库和JNI接口来实现高效的移动端推理。
6.1 Android集成架构
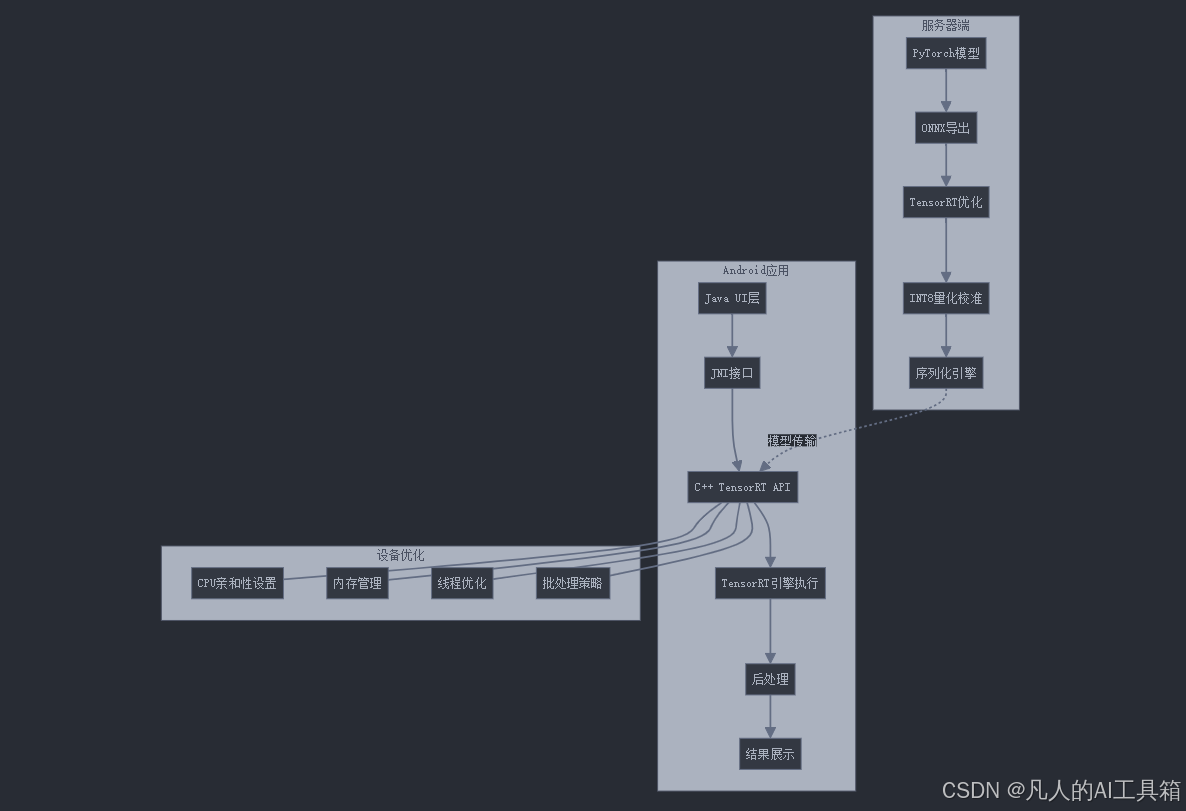
6.2 Android端TensorRT集成
以下是Android应用程序中集成TensorRT的核心步骤:
- 项目配置:在Android项目的build.gradle中添加必要的配置
- JNI接口设计:定义与C++层的接口
- C++实现:使用TensorRT API实现推理逻辑
- Java层调用:在Java/Kotlin中调用本地方法
6.2.1 Android项目配置
首先,在Android项目的app/build.gradle中添加以下配置:
// app/build.gradle
android {
// ...其他配置...
defaultConfig {
// ...应用基本配置...
// 启用CMake支持
externalNativeBuild {
cmake {
cppFlags "-std=c++14"
arguments "-DANDROID_STL=c++_shared"
}
}
// 指定支持的ABI
ndk {
abiFilters 'arm64-v8a', 'armeabi-v7a'
}
}
// 配置CMake
externalNativeBuild {
cmake {
path "src/main/cpp/CMakeLists.txt"
version "3.18.1"
}
}
// 配置资源目录,存放TensorRT引擎文件
sourceSets {
main {
assets.srcDirs = ['src/main/assets']
}
}
// ...其他配置...
}
dependencies {
// ...其他依赖...
// 添加CameraX库用于相机访问
implementation "androidx.camera:camera-camera2:1.1.0"
implementation "androidx.camera:camera-lifecycle:1.1.0"
implementation "androidx.camera:camera-view:1.1.0"
// 添加图像处理库
implementation 'com.github.bumptech.glide:glide:4.12.0'
}
6.2.2 CMake配置
接下来,创建CMakeLists.txt文件来配置C++构建:
cmake_minimum_required(VERSION 3.10.2)
# 设置项目名
project("tensorrtdemo")
# 设置TensorRT位置 (需要在设备上安装TensorRT或者自行编译)
set(TENSORRT_ROOT ${CMAKE_SOURCE_DIR}/src/main/cpp/tensorrt)
# 添加TensorRT头文件路径
include_directories(
${TENSORRT_ROOT}/include
)
# 添加TensorRT库路径
link_directories(
${TENSORRT_ROOT}/lib
)
# 添加源文件
add_library(
tensorrt_wrapper
SHARED
src/main/cpp/tensorrt_wrapper.cpp
src/main/cpp/image_processor.cpp
)
# 查找Android日志库
find_library(
log-lib
log
)
# 链接库
target_link_libraries(
tensorrt_wrapper
# TensorRT库
${TENSORRT_ROOT}/lib/libnvinfer.so
${TENSORRT_ROOT}/lib/libnvinfer_plugin.so
${TENSORRT_ROOT}/lib/libnvparsers.so
${TENSORRT_ROOT}/lib/libnvonnxparser.so
# CUDA库
${TENSORRT_ROOT}/lib/libcudart.so
${TENSORRT_ROOT}/lib/libcudnn.so
# Android库
${log-lib}
jnigraphics
)
# 设置C++标准
set_target_properties(
tensorrt_wrapper
PROPERTIES
CXX_STANDARD 14
CXX_STANDARD_REQUIRED YES
)
6.2.3 JNI接口实现
以下是C++层的TensorRT包装器实现:
#include <jni.h>
#include <string>
#include <vector>
#include <memory>
#include <android/log.h>
#include <android/bitmap.h>
#include <android/asset_manager.h>
#include <android/asset_manager_jni.h>
#include <NvInfer.h>
#include <NvOnnxParser.h>
// 定义日志宏
#define LOG_TAG "TensorRTWrapper"
#define LOGD(...) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, __VA_ARGS__)
#define LOGI(...) __android_log_print(ANDROID_LOG_INFO, LOG_TAG, __VA_ARGS__)
#define LOGE(...) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, __VA_ARGS__)
// TensorRT Logger类
class Logger : public nvinfer1::ILogger {
public:
void log(Severity severity, const char* msg) noexcept override {
switch (severity) {
case Severity::kINTERNAL_ERROR:
LOGE("INTERNAL_ERROR: %s", msg);
break;
case Severity::kERROR:
LOGE("ERROR: %s", msg);
break;
case Severity::kWARNING:
LOGI("WARNING: %s", msg);
break;
case Severity::kINFO:
LOGI("INFO: %s", msg);
break;
case Severity::kVERBOSE:
LOGD("VERBOSE: %s", msg);
break;
default:
LOGI("UNKNOWN: %s", msg);
break;
}
}
} gLogger;
// TensorRT引擎管理器
class TensorRTEngine {
private:
// TensorRT组件
nvinfer1::ICudaEngine* mEngine = nullptr;
nvinfer1::IExecutionContext* mContext = nullptr;
// 输入输出缓冲区
void* mDeviceBuffers[2] = {nullptr, nullptr};
void* mHostInputBuffer = nullptr;
void* mHostOutputBuffer = nullptr;
// 引擎参数
int mInputIndex = -1;
int mOutputIndex = -1;
int mBatchSize = 1;
int mInputH = 224;
int mInputW = 224;
int mInputC = 3;
int mOutputSize = 1000; // 默认ImageNet分类数量
// 清理资源
void cleanup() {
if (mContext) {
mContext->destroy();
mContext = nullptr;
}
if (mEngine) {
mEngine->destroy();
mEngine = nullptr;
}
if (mHostInputBuffer) {
free(mHostInputBuffer);
mHostInputBuffer = nullptr;
}
if (mHostOutputBuffer) {
free(mHostOutputBuffer);
mHostOutputBuffer = nullptr;
}
for (int i = 0; i < 2; i++) {
if (mDeviceBuffers[i]) {
cudaFree(mDeviceBuffers[i]);
mDeviceBuffers[i] = nullptr;
}
}
}
public:
TensorRTEngine() = default;
~TensorRTEngine() {
cleanup();
}
// 从文件加载引擎
bool loadEngine(AAssetManager* assetManager, const std::string& engineFile) {
cleanup();
// 打开资产文件
AAsset* asset = AAssetManager_open(assetManager, engineFile.c_str(), AASSET_MODE_BUFFER);
if (!asset) {
LOGE("Failed to open engine file: %s", engineFile.c_str());
return false;
}
// 读取引擎数据
size_t size = AAsset_getLength(asset);
std::vector<char> engineData(size);
AAsset_read(asset, engineData.data(), size);
AAsset_close(asset);
LOGI("Engine file size: %zu bytes", size);
// 创建运行时和反序列化引擎
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(gLogger);
if (!runtime) {
LOGE("Failed to create TensorRT Runtime");
return false;
}
// 设置DLA核心(如果设备支持)
// runtime->setDLACore(0);
mEngine = runtime->deserializeCudaEngine(engineData.data(), size);
runtime->destroy();
if (!mEngine) {
LOGE("Failed to deserialize CUDA engine");
return false;
}
// 创建执行上下文
mContext = mEngine->createExecutionContext();
if (!mContext) {
LOGE("Failed to create execution context");
mEngine->destroy();
mEngine = nullptr;
return false;
}
// 获取输入输出索引
mInputIndex = mEngine->getBindingIndex("input");
mOutputIndex = mEngine->getBindingIndex("output");
if (mInputIndex == -1 || mOutputIndex == -1) {
LOGE("Invalid binding index found. Input: %d, Output: %d", mInputIndex, mOutputIndex);
cleanup();
return false;
}
// 获取输入维度
auto inputDims = mEngine->getBindingDimensions(mInputIndex);
mBatchSize = inputDims.d[0];
mInputC = inputDims.d[1];
mInputH = inputDims.d[2];
mInputW = inputDims.d[3];
// 获取输出维度
auto outputDims = mEngine->getBindingDimensions(mOutputIndex);
mOutputSize = outputDims.d[1];
LOGI("Engine loaded. Input: %dx%dx%dx%d, Output: %d",
mBatchSize, mInputC, mInputH, mInputW, mOutputSize);
// 分配主机和设备内存
size_t inputSize = mBatchSize * mInputC * mInputH * mInputW * sizeof(float);
size_t outputSize = mBatchSize * mOutputSize * sizeof(float);
// 分配主机内存
mHostInputBuffer = malloc(inputSize);
mHostOutputBuffer = malloc(outputSize);
// 分配CUDA内存
cudaMalloc(&mDeviceBuffers[mInputIndex], inputSize);
cudaMalloc(&mDeviceBuffers[mOutputIndex], outputSize);
return true;
}
// 执行推理
bool infer(float* inputData, float* outputData) {
if (!mContext || !mEngine) {
LOGE("Engine not initialized");
return false;
}
// 输入数据大小
size_t inputSize = mBatchSize * mInputC * mInputH * mInputW * sizeof(float);
size_t outputSize = mBatchSize * mOutputSize * sizeof(float);
// 复制输入数据到主机缓冲区
memcpy(mHostInputBuffer, inputData, inputSize);
// 复制主机数据到设备
cudaMemcpy(mDeviceBuffers[mInputIndex], mHostInputBuffer, inputSize, cudaMemcpyHostToDevice);
// 执行推理
bool status = mContext->executeV2(mDeviceBuffers);
if (!status) {
LOGE("Inference execution failed");
return false;
}
// 复制结果回主机
cudaMemcpy(mHostOutputBuffer, mDeviceBuffers[mOutputIndex], outputSize, cudaMemcpyDeviceToHost);
// 复制结果到输出缓冲区
memcpy(outputData, mHostOutputBuffer, outputSize);
return true;
}
// 获取输入尺寸
void getInputDims(int& batch, int& channels, int& height, int& width) const {
batch = mBatchSize;
channels = mInputC;
height = mInputH;
width = mInputW;
}
// 获取输出尺寸
int getOutputSize() const {
return mOutputSize;
}
};
// 全局引擎实例
static std::unique_ptr<TensorRTEngine> gEngine;
// 图像处理函数(在image_processor.cpp中实现)
extern "C" {
extern void preprocessImage(const uint32_t* inputPixels, int width, int height, float* outputBuffer);
}
// JNI方法实现
extern "C" {
JNIEXPORT jboolean JNICALL
Java_com_example_tensorrtdemo_TensorRTWrapper_initTensorRT(
JNIEnv* env,
jobject thiz,
jobject assetManager,
jstring engineFile) {
// 获取引擎文件名
const char* engineFileName = env->GetStringUTFChars(engineFile, nullptr);
// 获取资产管理器
AAssetManager* mgr = AAssetManager_fromJava(env, assetManager);
// 创建引擎实例
if (!gEngine) {
gEngine = std::make_unique<TensorRTEngine>();
}
// 加载引擎
bool success = gEngine->loadEngine(mgr, engineFileName);
// 释放字符串
env->ReleaseStringUTFChars(engineFile, engineFileName);
return static_cast<jboolean>(success);
}
JNIEXPORT jfloatArray JNICALL
Java_com_example_tensorrtdemo_TensorRTWrapper_runInference(
JNIEnv* env,
jobject thiz,
jobject bitmap) {
if (!gEngine) {
LOGE("TensorRT engine not initialized");
return nullptr;
}
// 获取Bitmap信息
AndroidBitmapInfo bitmapInfo;
if (AndroidBitmap_getInfo(env, bitmap, &bitmapInfo) != ANDROID_BITMAP_RESULT_SUCCESS) {
LOGE("Failed to get bitmap info");
return nullptr;
}
// 检查Bitmap格式
if (bitmapInfo.format != ANDROID_BITMAP_FORMAT_RGBA_8888) {
LOGE("Bitmap format not supported: %d", bitmapInfo.format);
return nullptr;
}
// 获取引擎输入尺寸
int batchSize, channels, height, width;
gEngine->getInputDims(batchSize, channels, height, width);
// 锁定Bitmap像素
void* bitmapPixels;
if (AndroidBitmap_lockPixels(env, bitmap, &bitmapPixels) != ANDROID_BITMAP_RESULT_SUCCESS) {
LOGE("Failed to lock bitmap pixels");
return nullptr;
}
// 分配输入和输出缓冲区
int inputSize = batchSize * channels * height * width;
std::vector<float> inputBuffer(inputSize);
// 预处理图像
preprocessImage(static_cast<uint32_t*>(bitmapPixels), bitmapInfo.width, bitmapInfo.height, inputBuffer.data());
// 解锁Bitmap像素
AndroidBitmap_unlockPixels(env, bitmap);
// 分配输出缓冲区
int outputSize = gEngine->getOutputSize();
std::vector<float> outputBuffer(outputSize);
// 执行推理
bool success = gEngine->infer(inputBuffer.data(), outputBuffer.data());
if (!success) {
LOGE("Inference failed");
return nullptr;
}
// 创建Java浮点数组返回结果
jfloatArray resultArray = env->NewFloatArray(outputSize);
env->SetFloatArrayRegion(resultArray, 0, outputSize, outputBuffer.data());
return resultArray;
}
JNIEXPORT void JNICALL
Java_com_example_tensorrtdemo_TensorRTWrapper_destroyTensorRT(
JNIEnv* env,
jobject thiz) {
// 释放引擎
gEngine.reset();
LOGI("TensorRT engine destroyed");
}
JNIEXPORT jintArray JNICALL
Java_com_example_tensorrtdemo_TensorRTWrapper_getInputDims(
JNIEnv* env,
jobject thiz) {
if (!gEngine) {
LOGE("TensorRT engine not initialized");
return nullptr;
}
// 获取输入尺寸
int batchSize, channels, height, width;
gEngine->getInputDims(batchSize, channels, height, width);
// 创建并返回尺寸数组
jintArray dimsArray = env->NewIntArray(4);
jint dims[4] = {batchSize, channels, height, width};
env->SetIntArrayRegion(dimsArray, 0, 4, dims);
return dimsArray;
}
}
清华大学全五版的《DeepSeek教程》完整的文档需要的朋友,关注我私信:deepseek 即可获得。
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!