MySQL学习笔记
MySQL关系型数据库,其中的实体,每个实体的可以有多个属性,属性不许在分,用于区分不同实体的属性是Key,属性有一定约束。
每一张数据表表示一种实体
数据库规范
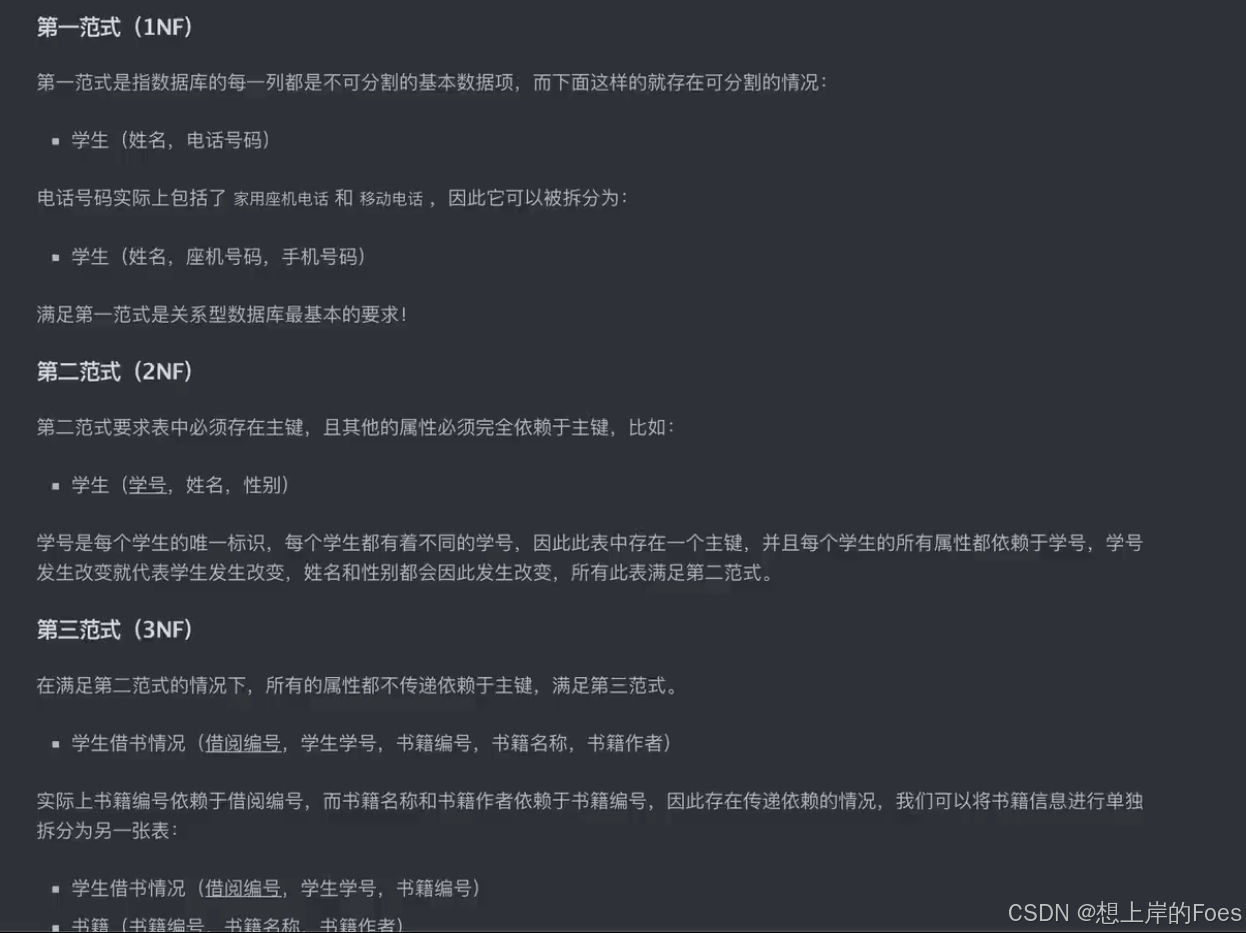
视图
本质就是查询的结果,但是只是虚表,不是真正存在的数据,只是通过视图显示,但是也可以通过视图进行修改。
例如
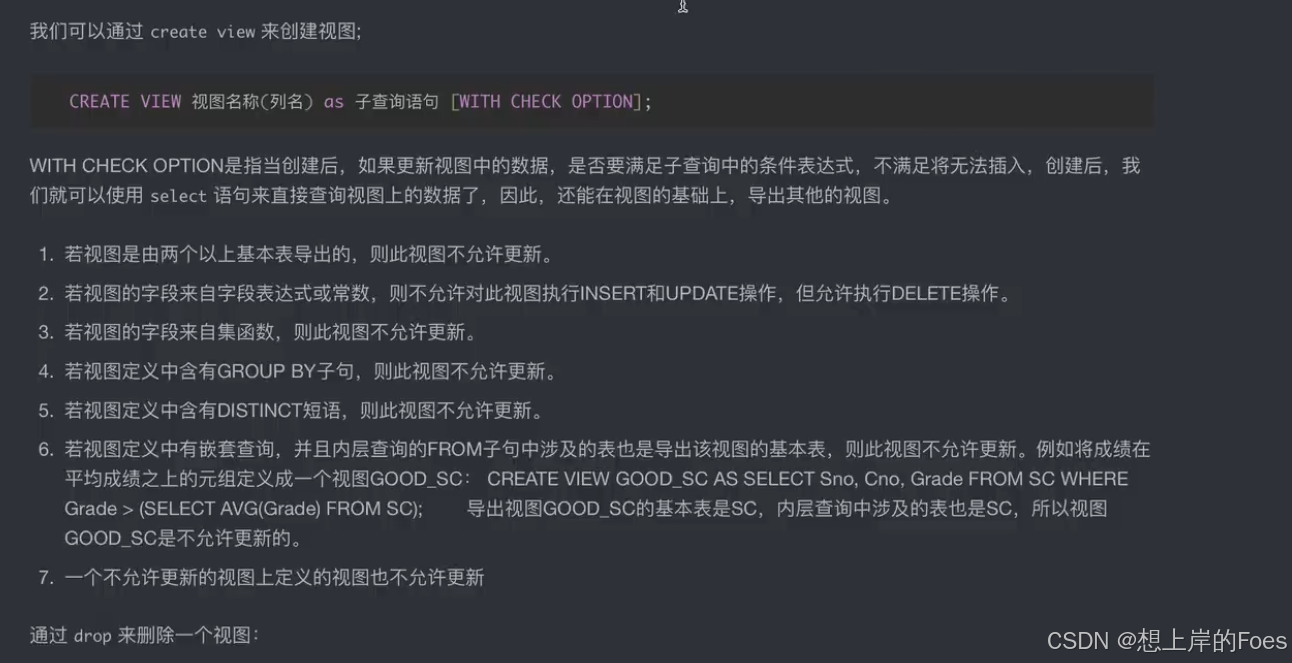
索引
当数据量大时一条条查询数据就慢,但是可以通过建立索引来提升查询速度
索引方式有二叉树和Hash,有多种索引类型
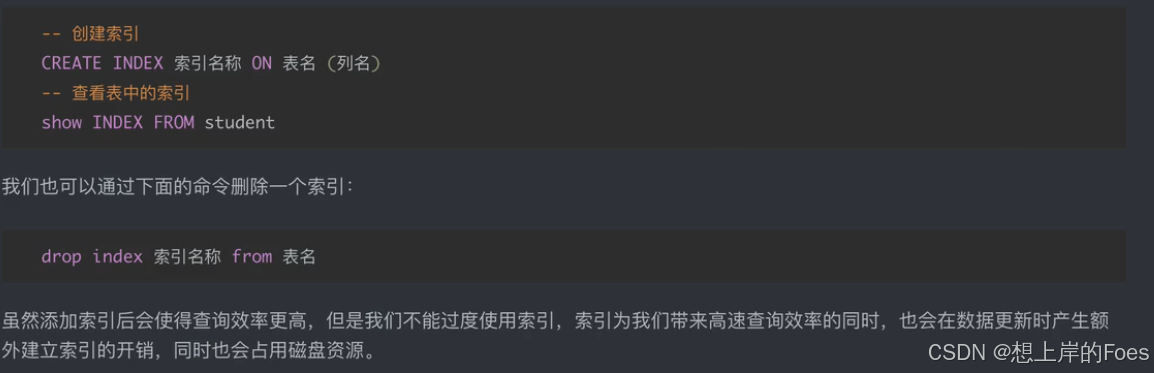
触发器
在某些特定条件,例如执行某个语句时,会自动执行相关的操作,一般用来判断合法性和安全性,相对更加灵活,此时可以从新旧表中对以及变化的数据进行操作。
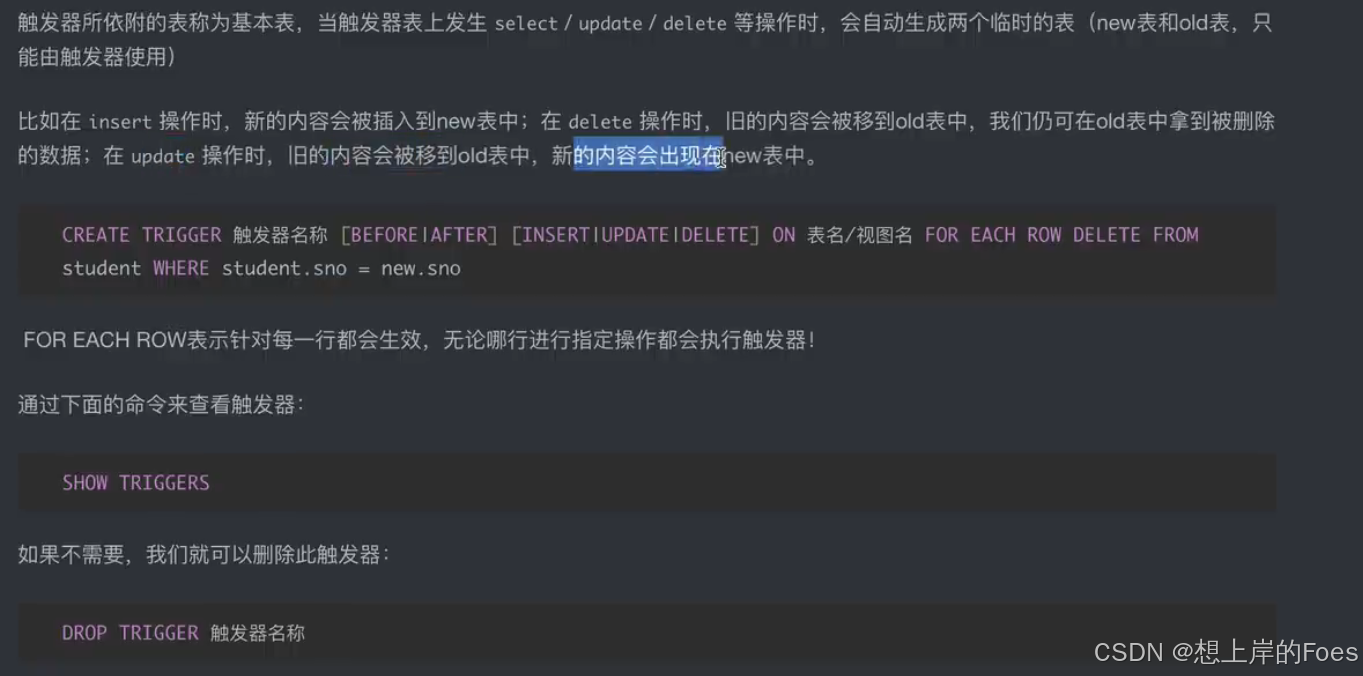
举例将删除的信息的外键去除。
![]()
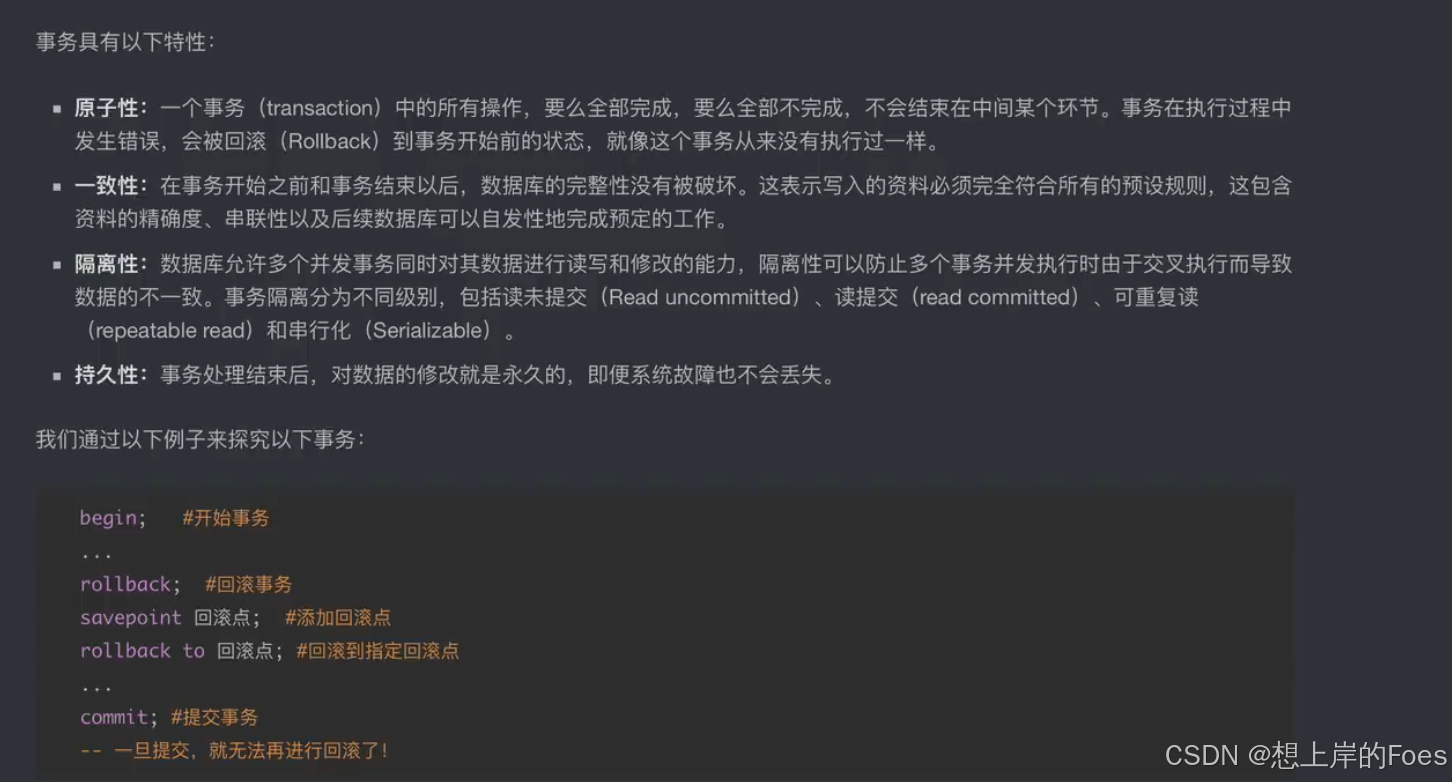
事务
MySQL使用的数据引擎中只有InnoDB允许事务,也就是对数据操作的原子性
存储引擎
索引进阶
索引相当于一本书的目录,用来快速找到数据。
单列索引,只针对一列数据建立索引。

除全文外,其余索引都是直接使用
全文索引是用来匹配文章中的单词用例如下,其中单词长度大于4,body是建立索引的位置

组合索引
将多个列组合绑定成为一个索引,此时这个索引相当与上文的单列索引。
索引速度
Uni>Noraml,如果是组合索引但是使用单个条件查询,此时在前的数据速度快。在后的速度慢,因为只有在前的正常能走索引,但如果联合使用,速度又和等效的单列索引一样快。
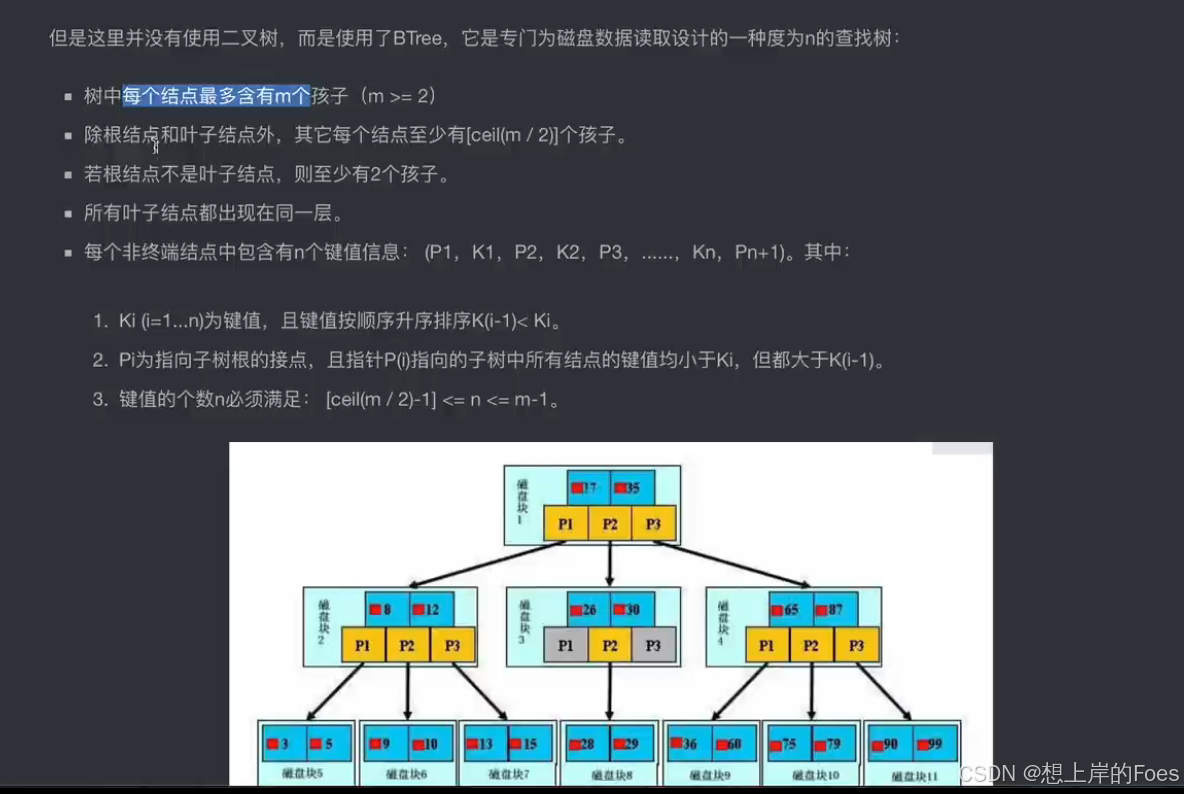
索引底层原理
使用索引的原因是MySQL采用磁盘存储,每一次磁盘IO要消耗大量时间,因此使用索引减少检索次数也就减少检索时间,虽然会增加复杂度
索引底层实现是Hash和B-tree,Hash实现能达到O(1)的时间复杂度,
但是有以下三个问题
 如果使用B-Tree,虽然会损失一点速度,但是能够解决上述的这些问题
如果使用B-Tree,虽然会损失一点速度,但是能够解决上述的这些问题
查找举例(类似二叉搜索数)

但是由于Btree中的节点内容是整条记录,这样读取时间就会比较久,因此改进引入B+Tree
非叶子节点不保存整条记录,运用的思想类似BTree
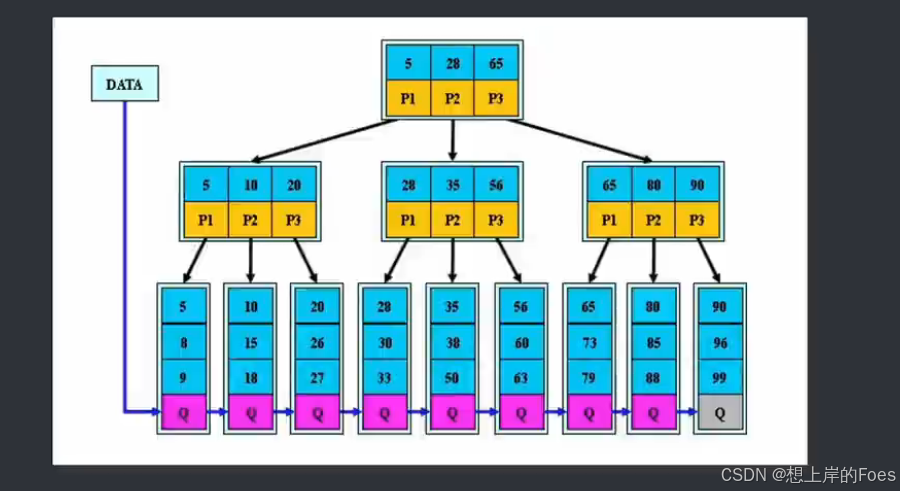

这样读取IO时间少且相对固定(都需走到叶子节点才能得到数据),MySQL默认使用B+📕
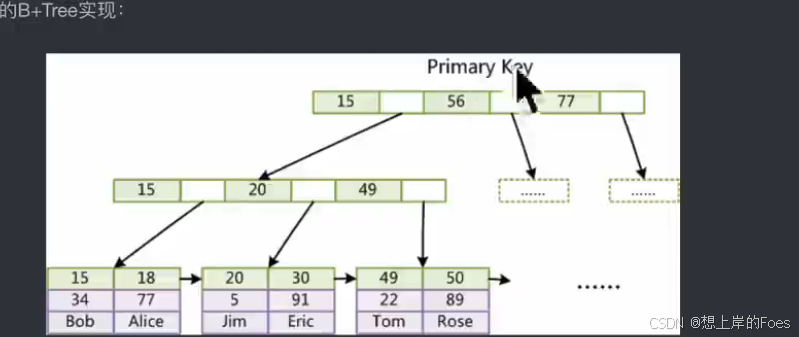
MyISAM引擎实现B+树
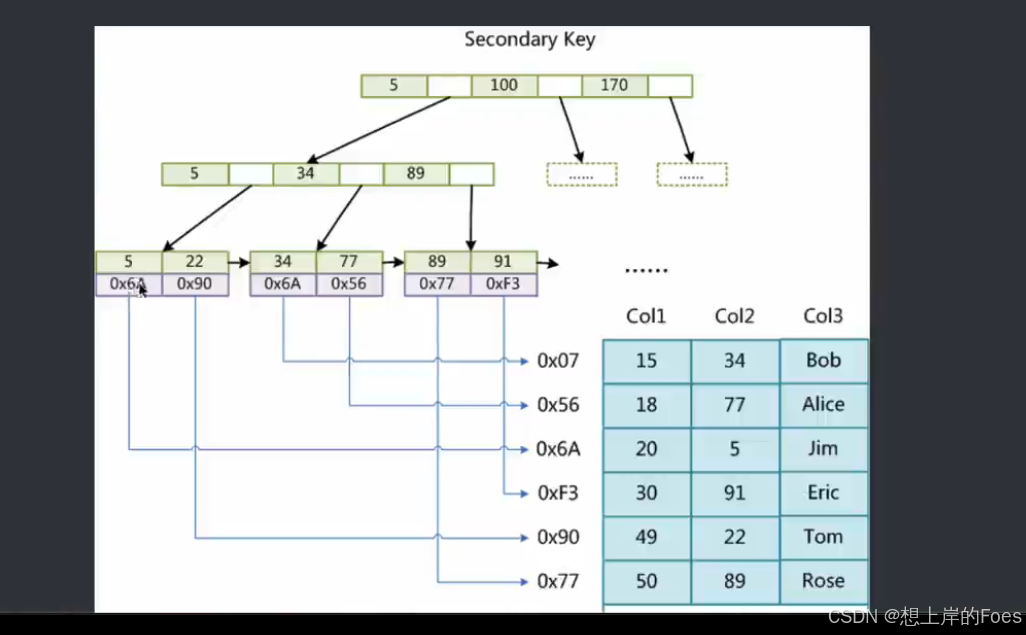
InnoDB实现
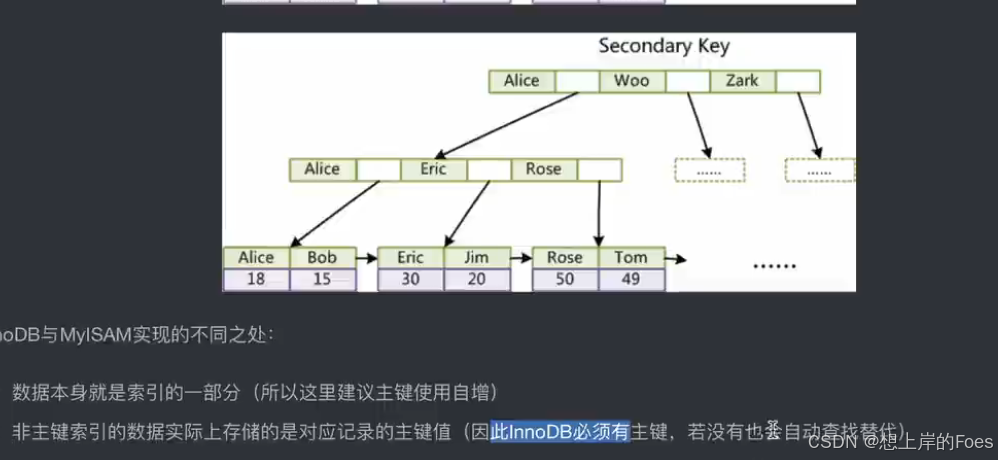
对于InnoDB,数据本身就是索引的一部分,且一定要存在主键,否则也会自己寻找代替,因为其余索引存的值是对应记录的主键
锁机制
事务的隔离级别机制

MySQL默认是RR,但是一定程度上解决了幻读问题

锁
分为读锁和写锁

从作用域考虑:全局锁,表锁,行锁(只有InnoDB支持)
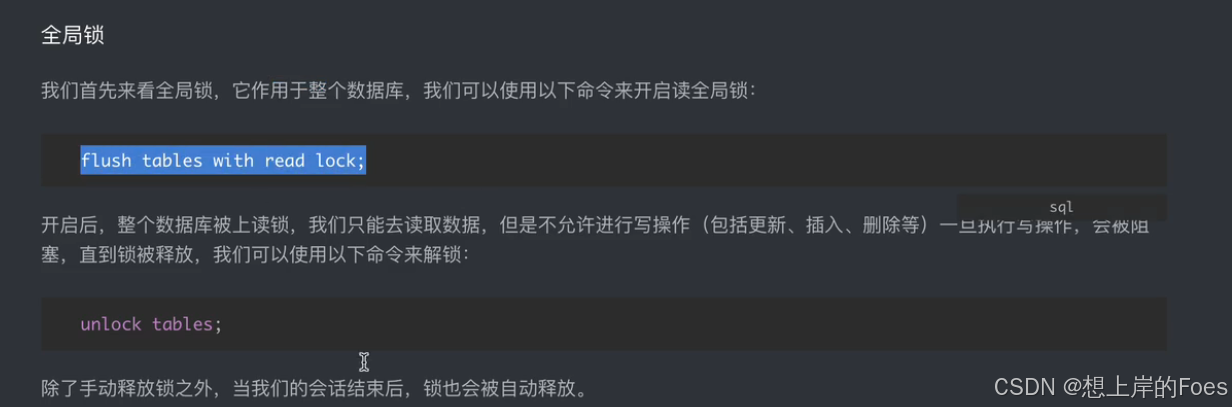

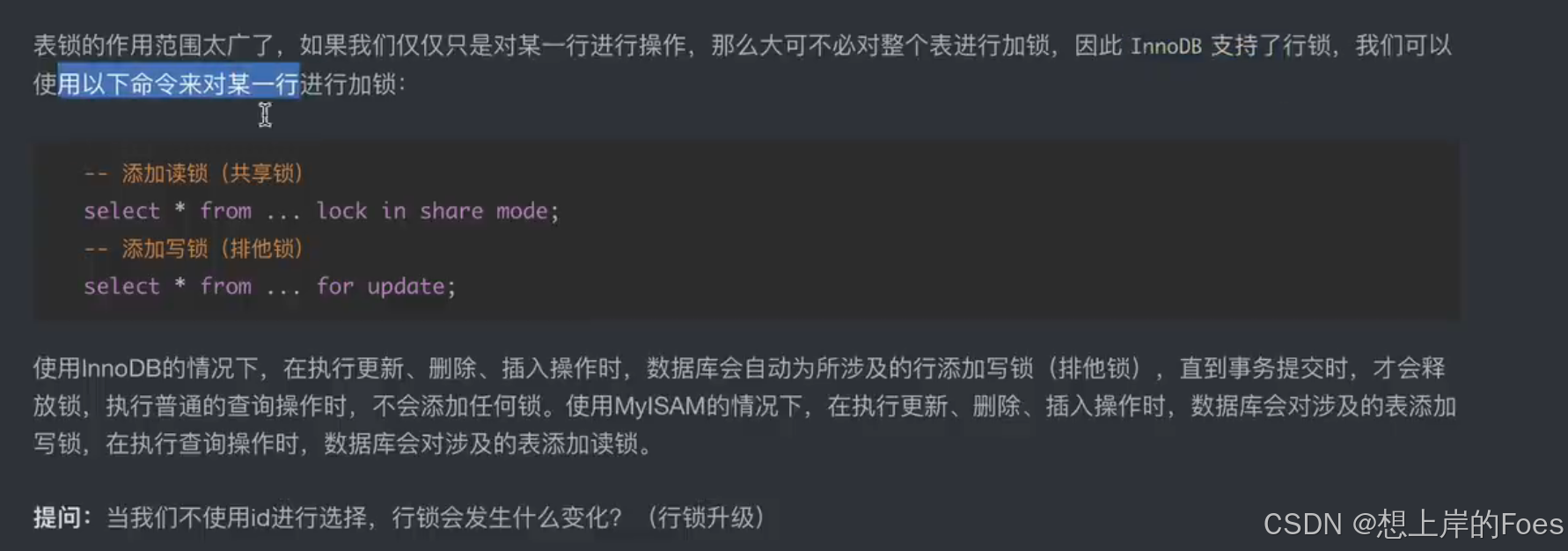
但是如果没有走索引(如没有使用主键),行锁有可能升级为表锁,因为无法精确找到具体应该修改的位置,如果对条件加上索引,让它精确就不会发生上述问题。
行锁还可以继续下分


单一索引精准匹配时记录锁,索引存在但没有实际记录间隙锁 ,索引存在多数据存在才是临建锁
间隙锁解决幻读问题的原理是,锁住的是没插入数据的空间,防止其插入数据
