小杰-自然语言处理(two)——RNN系列——RNN为什么能做时序预测
1.RNN原理
循环神经网络(Recurrent Neural Network, RNN)是一类专门用于处理序列数据的神经网络,通过引入循环结构和隐藏状态来捕捉序列中的时序依赖关系,主要应用在文本生成、语音识别、时间序列预测、机器翻译等领域。
RNN 2D原理图:
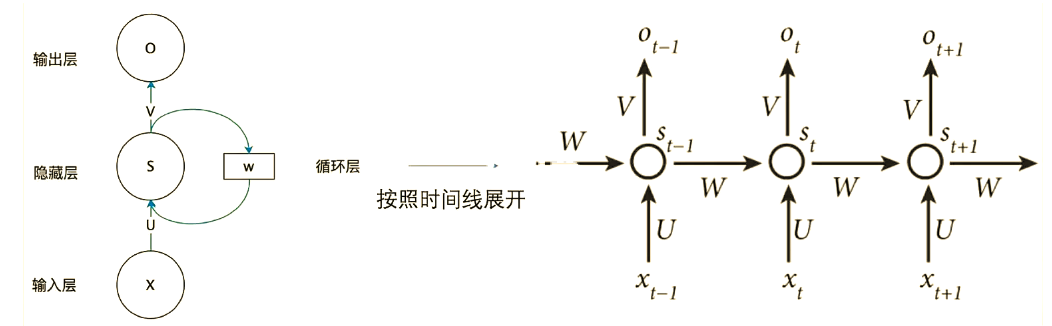
其中:

可以得到隐藏状态更新公式:
![]()
更新前向时输出计算的公式:
![]()
总结:RNN 的循环结构通过每个时间步整合当前输入与前一时间步的隐藏状态,实现序列信息的有效捕捉,RNN中的由于W、U、V 是共享的,也就是说,对于不同时刻的输入,循环神经网络都执行相同的操作。这种共享机制不仅可以极大的减少网络需要学习的参数数量,而且使得网络可以处理长度不固定的输入序列。如上图左边图所示。
1.1 RNN pytroch API讲解
import torch
import torch.nn as nn# pytorch 官方 RNN 是一个多对多结构的 RNN
# 官方 API: https://pytorch.org/docs/stable/generated/torch.nn.RNN.html#rnn
# num_layers: 不同权重的RNN堆叠多少层
# nonlinearity: 非线性激活函数
# bias: 是否学习偏置
# batch_first: 是否批次数,放到维度的首位
# dropout: dropout 操作,防止过拟合
# bidirectional: 是否是双向RNN
# 前两个参数为 input_size, hidden_size
model = nn.RNN(input_size=2,hidden_size=10,num_layers=1,nonlinearity='relu',bias=False,batch_first=True,bidirectional=False
)# 输入输出形状解释:
# 输入: input, h_0
# input: 输入参数,当只有一个批次数据时 (L, H_in),否则为 (L(长度), N(表示批次), H_in(维度)),当 batch_first=True 时,N 在最前面 (N, L, H_in)
# h_0: 输入隐藏状态,当只有一个批次数据时 (D * num_layers, H_out),否则为 (D * num_layers, N, H_out)
# 输出: output, h_n
# output: 输出参数,当只有一个批次数据时 (L, D * H_out),否则为 (L, N, D * H_out)
# h_n: 输出隐藏状态,当只有一个批次数据时 (D * num_layers, H_out),否则为 (D * num_layers, N, H_out)# 对上述符号的解释如下:
# N: 批次数
# L: 序列长度
# D: 双向RNN时为2,否则为1
# H_in: 序列中,每个输入的长度
# H_out: 隐藏状态的长度x = torch.rand(5, 3, 2)
h = torch.rand(1, 5, 10)
y, h = model(x, h)
print(y.shape)
print(h.shape)#
import torch
import torch.nn as nn# pytorch 官方 RNN 是一个多对多结构的 RNN
# 官方 API: https://pytorch.org/docs/stable/generated/torch.nn.RNN.html#rnn
# num_layers: 不同权重的RNN堆叠多少层
# nonlinearity: 非线性激活函数
# bias: 是否学习偏置
# batch_first: 是否批次数,放到维度的首位
# dropout: dropout 操作,防止过拟合
# bidirectional: 是否是双向RNN
# 前两个参数为 input_size, hidden_sizemodel = nn.RNN(input_size=100,hidden_size=10,num_layers=3,nonlinearity='relu',bias=False,batch_first=True,bidirectional=True
)# 输入输出形状解释:
# 输入: input, h_0
# input: 输入参数,当只有一个批次数据时 (L, H_in),否则为 (L(长度), N(表示批次), H_in(维度)),当 batch_first=True 时,N 在最前面 (N, L, H_in)
# h_0: 输入隐藏状态,当只有一个批次数据时 (D * num_layers, H_out),否则为 (D * num_layers, N, H_out)
# 输出: output, h_n
# output: 输出参数,当只有一个批次数据时 (L, D * H_out),否则为 (L, N, D * H_out)
# h_n: 输出隐藏状态,当只有一个批次数据时 (D * num_layers, H_out),否则为 (D * num_layers, N, H_out)# 对上述符号的解释如下:
# N: 批次数
# L: 序列长度
# D: 双向RNN时为2,否则为1
# H_in: 序列中,每个输入的长度
# H_out: 隐藏状态的长度x = torch.rand(32, 32, 100)
h = torch.rand(6, 32, 10)
y, h = model(x, h)
print(y.shape)
print(h.shape)# import torch
# #输入矩阵 2行3列
# x_t=torch.randint(0,4,(2,3))
# print(x_t)
# # w_u 是输入行为i=2,列为h=3
# w_u=torch.randint(0,4,(2,3))
# print(x_t@w_u.T) #@运算符其实matmul
# print(torch.matmul(x_t,w_u.T)) #@运算符其实matmul
# #w_hh
# w_hh=torch.randint(0,4,(2,2))
# #h_t1
# h_t1=torch.randint(0,4,(2,2))
# print(torch.matmul(w_hh,w_hh.T)) #@运算符其实matmul#hh矩阵
import torch
#输入矩阵 2行3列
x_t=torch.randint(0,4,(2,3))
print(x_t)
# w_u 是输入行为i=2,列为h=3
w_u=torch.randint(0,4,(2,3))
print(x_t@w_u.T) #@运算符其实matmul
print(torch.matmul(x_t,w_u.T)) #@运算符其实matmul
#w_hh
w_hh=torch.randint(0,4,(2,2))
#h_t1
h_t1=torch.randint(0,4,(2,2))
print(torch.matmul(h_t1,w_hh.T)) #@运算符其实matmul2. 基础原理
2.1 字符输入
在组件中,如下图指示,打开 字符输入 组件有一个输入框,可以看到:
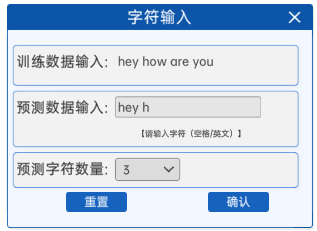
训练数据输入框默认有一句话:“hey how are you”,依然有预测数据输入hey ho,但是新增了一个新的下拉框,选择预测几个字符。
DNN 输入特征数固定(如 5 个),因全连接层权重维度固定,仅能处理固定长度输入;而 RNN 通过循环结构和隐藏状态传递,可动态处理任意长度序列 —— 每个时间步的计算仅依赖当前输入和前序隐藏状态,无需固定总长度,故输入长度可灵活变化。
2.2 文本特点
文本具有上下文关联性,单词或字母的排列遵循特定规律,非随机堆砌。
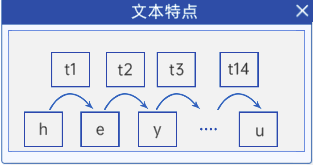
文本具有以下特点:
- 时序性:字符 / 单词有序排列,依赖上下文。
- 长期依赖:依赖关系可跨长段落,需全局信息理解。
- 离散性:由有限词汇表中的字符 / 单词组成。
- 可变长度:段落长度不固定,灵活多样。
2.3 数据集划分
RNN 的数据划分不同于 DNN,其输入为序列除去最后一个字符的部分,输出为序列除去第一个字符的部分,利用前后字符的时序依赖建模。

2.5 数据编码
将字母去重后,使用ASCII码顺序排列,得到下角标后将其转换成ont-hot编码。具体过程为:
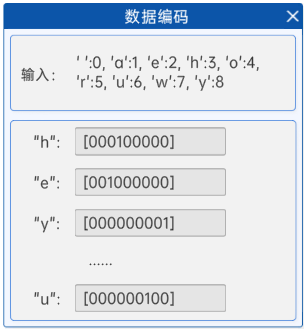
- 字母去重(hey how are you -> ['h', 'r', 'e', 'a', 'y', ' ', 'w', 'o', 'u'])
- 字母按照ASCII码排序(['h', 'r', 'e', 'a', 'y', ' ', 'w', 'o', 'u'] -> [' ', 'a', 'e', 'h', 'o', 'r', 'u', 'w', 'y'])
- 按照ASCII的顺序进行从0开始编号({' ': 0, 'a': 1, 'e': 2, 'h': 3, 'o': 4, 'r': 5, 'u': 6, 'w': 7, 'y': 8})
- 将每一个数字进行one-hot编码:
- ['h']对应着:[0, 0, 0, 1, 0, 0, 0, 0, 0]
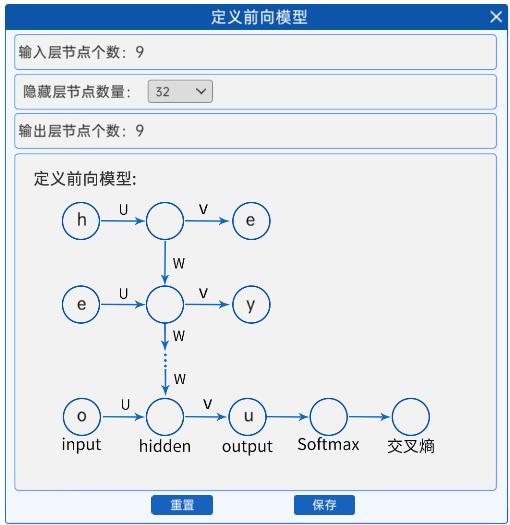
2.6 定义前向模型
输入的特征个数->隐藏层->输出层特征个数。
- 输入的特征个数是9,即[0, 0, 0, 1, 0, 0, 0, 0, 0]的长度。
- 采用一层的隐藏层,其节点个数是可选的。
- 输出层特征个数和输入特征个数是一样的,也是9。
2.7 定义损失函数和优化器
从上一个组件的图中可以看出,使用的是交叉熵损失函数,确认学习率和优化器Adam。

2.8 开始迭代
开始迭代就是一共训练的epochs。
2.9 显示频率设置
显示频率是每多少个epochs显示一次结果。
2.10 预测与输出
在预测时,会显示三个内容:
- 网络结构图,标注每个矩阵的shape。
- 损失函数的下降曲线与迭代次数的图,横坐标迭代次数,纵坐标损失。
- 预测结果,即在输入组件中预测数据输入的预测结果。
代码实现
import torch
import torch.nn as nn
import numpy as np
#定义输入文本
text = "hey how are you"
# text = "In Bejing Sarah bought a basket of apples In Guangzhou Sarah bought a basket of bananas" # 长文本示例
# 4、数据集预处理:字符集处理
chars = set(''.join(text)) # 提取文本中所有唯一字符
chars = sorted(chars) # 按ASCII码排序,确保映射一致性
int2char = dict(enumerate(chars)) # 整数到字符的映射字典
char2int = {char: ind for ind, char in int2char.items()} # 字符到整数的映射字典
# 4、数据集划分:构造输入-输出对
input_seq = []
target_seq = []
# 输入:文本去掉最后一个字符(保留前n-1个字符)
input_seq.append(text[:-1])
# 输出:文本去掉第一个字符(保留后n-1个字符),与输入一一对应
target_seq.append(text[1:])
# print(input_seq," ", target_seq)
# 将字符序列转换为整数索引序列
#输入
input_seq=[ [char2int[char] for char in seq] for seq in input_seq]
#标签
target_seq = [[char2int[char] for char in seq] for seq in target_seq]
#关键参数定义
maxlen=len(text)
#词表,最后决定输出 词汇表
dict_size=len(char2int)
#输入输出序列长度(去掉最后一个字符)
seq_len=maxlen-1
#训练的每一批次含几个数据
batch_size=1
def one_hot_encode(sequence, dict_size, seq_len, batch_size):"""将整数索引序列转换为one-hot编码张量:param sequence: 整数索引列表(形状:[batch_size, seq_len]):param dict_size: 字符表大小(one-hot维度):param seq_len: 序列长度:param batch_size: 批量大小:return: one-hot编码后的numpy数组(形状:[batch_size, seq_len, dict_size])"""features = np.zeros((batch_size, seq_len, dict_size), dtype=np.float32)for i in range(batch_size):for u in range(seq_len):features[i, u, sequence[i][u]] = 1 # 在对应索引位置设为1return features# 数据格式转换
input_seq = one_hot_encode(input_seq, dict_size, seq_len, batch_size) # 输入数据编码
input_seq = torch.from_numpy(input_seq) # 转换为PyTorch张量
target_seq = torch.Tensor(target_seq) # 目标数据(整数索引序列)
#模型包括RNN
class Model(nn.Module):def __init__(self,input_size,output_size,hidden_dim,n_layers):super(Model,self).__init__()self.hidden_dim=hidden_dim#隐藏层维度self.n_layers=n_layers#rnn多少层#定义RNNself.rnn=nn.RNN(input_size,hidden_dim,n_layers,batch_first=True)#定义输出层,将隐藏层输出映射到词表的维度self.fc=nn.Linear(hidden_dim,output_size)def forward(self,x):#获取batch_size是多少batch_size = x.size(0)#hidden初始化为0hidden=torch.zeros(self.n_layers,batch_size,self.hidden_dim)out,hidden=self.rnn(x,hidden)# 调整输出形状以便接入全连接层:将[batch_size, seq_len, hidden_dim]展平为[batch_size*seq_len, hidden_dim]#contiguous() 将非连续的数据out=out.contiguous().view(-1,self.hidden_dim)# 全连接层计算:映射到输出维度(字符表大小)out=self.fc(out)return out, hidden# 初始化模型:输入/输出维度=字符表大小,隐藏层维度=32,层数=1
model = Model(input_size=dict_size, output_size=dict_size, hidden_dim=32, n_layers=1)
# 训练参数设置
n_epochs = 1000 # 训练轮数
lr = 0.03 # 学习率
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失(适用于多分类任务)
optimizer = torch.optim.Adam(model.parameters(), lr=lr) # Adam优化器
# 模型训练循环
for epoch in range(1, n_epochs + 1):optimizer.zero_grad() # 梯度清零# 前向传播:输入数据input_seq,获取模型输出和隐藏状态output, hidden = model(input_seq)# 计算损失:将目标数据展平为一维张量(与output形状匹配)loss = criterion(output, target_seq.view(-1).long())# 反向传播和参数更新loss.backward()optimizer.step()# 打印中间训练结果(每50轮输出一次)if epoch % 50 == 0:print(f'Epoch: {epoch}/{n_epochs}.............', end=' ')print(f"Loss: {loss.item():.4f}")# 模型参数和输出形状检查(调试用)
print("\n模型输入输出形状:")
print("input shape:", input_seq.shape) # 输入形状:[batch_size, seq_len, dict_size]
print("out shape:", output.shape) # 输出形状:[batch_size*seq_len, dict_size]
print("hidden shape:", hidden.shape) # 隐藏状态形状:[n_layers, batch_size, hidden_dim]print("\n模型权重和偏置形状:")
print("input_w shape:", model.rnn.weight_ih_l0.shape) # 输入到隐藏层权重:[hidden_dim, input_size]
print("input_b shape:", model.rnn.bias_ih_l0.shape) # 输入到隐藏层偏置:[hidden_dim]
print("hidden_w shape:", model.rnn.weight_hh_l0.shape) # 隐藏层到隐藏层权重:[hidden_dim, hidden_dim]
print("hidden_b shape:", model.rnn.bias_hh_l0.shape) # 隐藏层到隐藏层偏置:[hidden_dim]
print("out_w shape:", model.fc.weight.shape) # 输出层权重:[output_size, hidden_dim]
print("out_b shape:", model.fc.bias.shape) # 输出层偏置:[output_size]# 定义预测函数:根据输入字符序列预测下一个字符
def predict(model, character):"""单步预测函数:输入字符序列,预测下一个字符:param model: 训练好的RNN模型:param character: 输入字符序列(字符串):return: 预测的下一个字符,当前隐藏状态"""# 将输入字符转换为整数索引序列character = np.array([[char2int[c] for c in character]])# 对输入序列进行one-hot编码character = one_hot_encode(character, dict_size, character.shape[1], 1)character = torch.from_numpy(character) # 转换为张量# 前向传播获取输出和隐藏状态out, hidden = model(character)# 对最后一个时间步的输出计算softmax概率prob = nn.functional.softmax(out[-1], dim=0).data# 获取概率最大的字符索引char_ind = torch.max(prob, dim=0)[1].item()return int2char[char_ind], hidden # 返回预测字符和隐藏状态# 定义文本生成函数:基于种子文本生成指定长度的序列
def sample(model, out_len, start='hey'):"""文本生成函数:从种子文本开始,生成指定长度的字符序列:param model: 训练好的RNN模型:param out_len: 生成的总长度:param start: 种子文本(初始输入):return: 生成的完整文本"""model.eval() # 切换到评估模式(关闭dropout等)chars = [ch for ch in start] # 将种子文本转换为字符列表size = out_len - len(chars) # 需要生成的字符数# 逐个字符生成for ii in range(size):# 预测下一个字符(使用当前字符列表作为输入)char, h = predict(model, chars)chars.append(char) # 将预测字符添加到结果中return ''.join(chars) # 拼接为完整字符串# 生成文本示例(基于训练好的模型)
# result = sample(model, 42, 'In Bejing Sarah bought a basket of') # 长文本生成示例
result = sample(model, 12, 'hey how ') # 短文本生成示例
print("\n生成结果:", result)