构建高性能企业RAG落地-分块的艺术

开篇
刚完成一个大型企业AI落地项目,携带着一系列理论从论证到落地到实际运行的惊喜成果给大家带来这一篇实战级的博客来讲解如何消除日常企业知识库、个人知识库幻觉的一系列消除和解决手法。
在RAG系统中,这种高效的实现往往是通过“分块”来实现的。你可以把它想象成把一本厚书分成几章——这样一来,阅读和理解就轻松多了。同样地,分块技术把大段复杂的文本拆分成更小、更容易处理的片段,让AI能更快、更准确地理解和处理信息。
按照上一篇我们在《一文看懂最前沿得高级RAG+设计是如何消灭AI幻觉的架构设计》中所述,2024年年底开始人们不断的在总结、探讨如何让AI在企业落地中可以减轻、甚至是最终消除幻觉的过程中,以OPENAI以及Google相关研发团队还有微软工程研究院和MIT都发表了一系列的论文、理论。其中最重要的就是RAG+的到来即Advanced Rag。
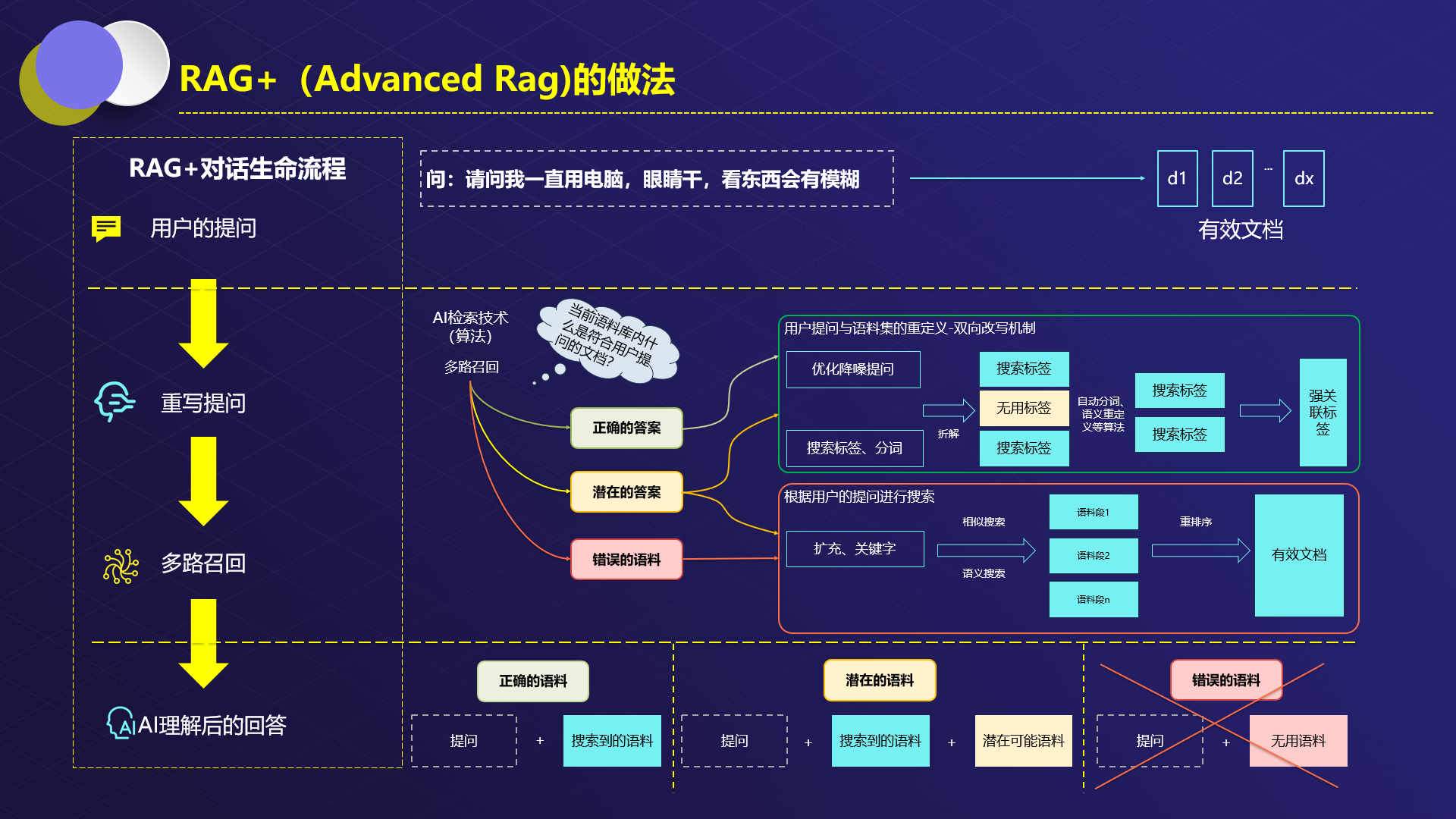
而Advanced Rag的特点就是:在数据真正进入企业知识核心库前一定要做预处理。
预处理又分:重写提示词和数据切片。
而此中的数据切片的重要性其实是占到了整个系统成功率得80%甚至更多,在本人落地经验中对数据切片如果使用得当与否是占到了整个RAG项目落地的90%+。
企业AI化与数字化其实都是在讲“数据切片”
无论是过去的企业数字化还是现在的企业AI化,数据是重中之重,这一点在OpenAI开发者生态大会被数度提到。
企业数字化讲究的是结构化数据
在实施企业数字化时,我们会先做一件事,那就是把无结构化的数据变成结构化的数据,进而才可以有“API化”。
无论是业务中台还是大数据中台,都需要结构化数据,甚至出钱去购买那些本企业不具备的数据间的“血缘关系”以及它们的“拓展”情况,典型的就是零售金融场景中的:数据标签。
企业AI化也讲究的是结构化数据那就是切片
企业在实施AI化时其实也需要结构化数据,那就是切片。这个切片其实和之前在实施企业数字化时我们需要字段结构明确、固定、清晰且包含有大量维度的JSON或者是DB数据是一样的道理。
企业实施AI落地中理想的数据到底长什么样子
这个问题其实已经不用论证了,而是在大模型发展至今业界的共识,而且在笔者接触了和BAT等大厂联合实施项目时的记录和总结。
那就是:一段一段不超过400字,这一段内不包括有任何回车的带有明确标签而且是具备独立含义内容的文字。
差的切片样例1
就是经常导致企业AI落地幻觉并且需要大量人工标的样例
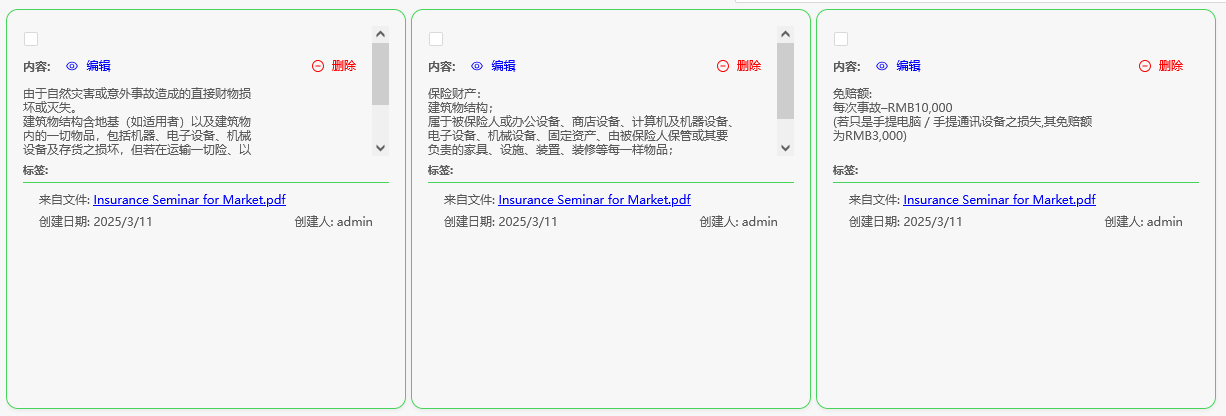
我们可以看到这种切片最糟糕的地方就是破坏了上下文含义,这样的切片如果是上百个之多,你搜:全额财产险保额?
AI基本都会拿人寿保险或者车险的保额来回答你。
这是因为保额额度、数值、价格和上下文被脱勾了,而在召回时如果你的TopK中有K个保额,那么AI怎么知道哪个数额对应的是哪一个保险条款呢?
差的切片样例2
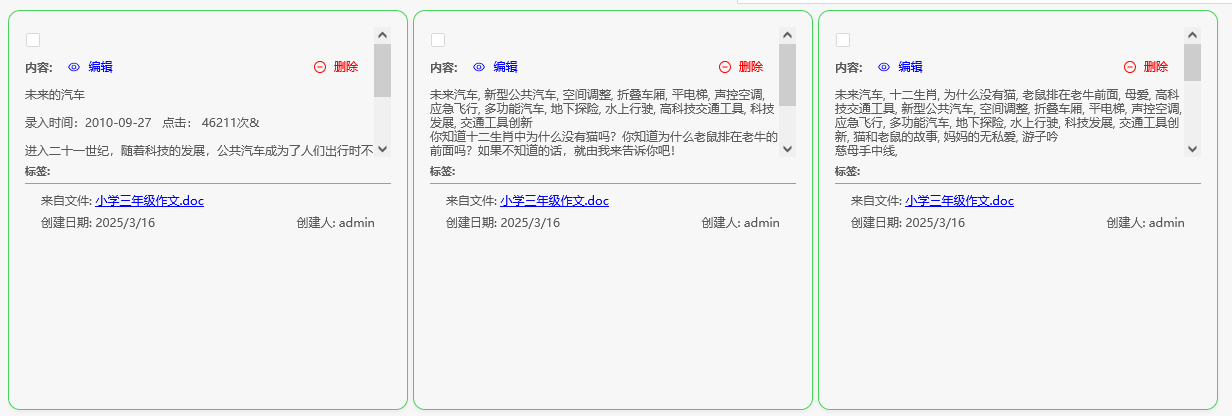
比如说我们在知识库内上传了100本书,每一本书都是30-40页左右的word。
然后它被切成了像下面这样。
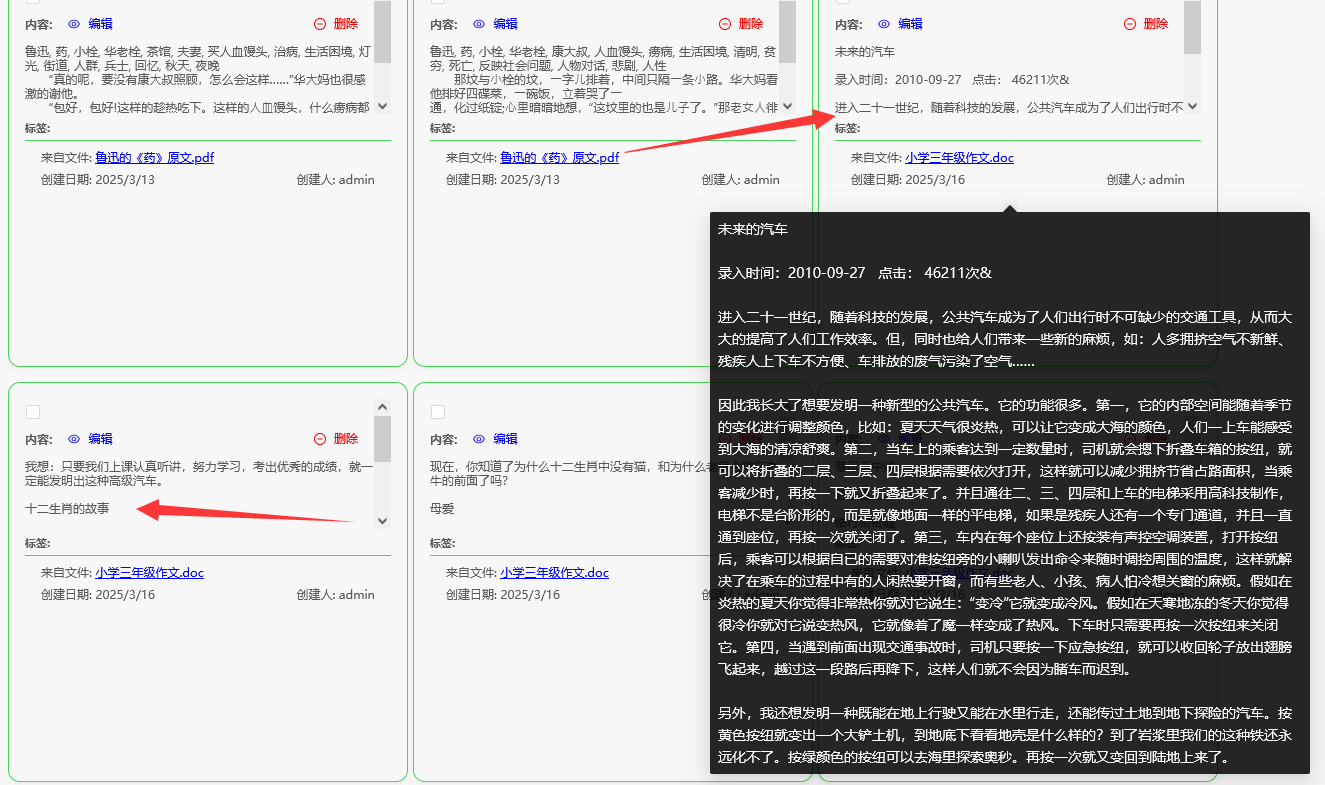
如上图,把未来汽车去和其它相关文章、故事混在一起,于是我们这样问AI(DeepSeek本地满血版布署后回答情况):
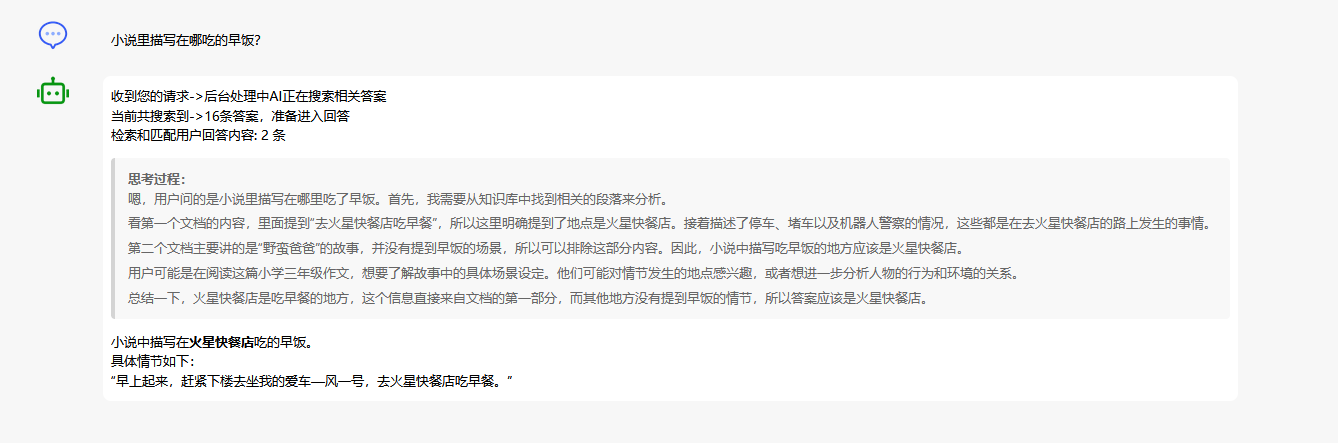
小说里描写在哪吃的早饭?
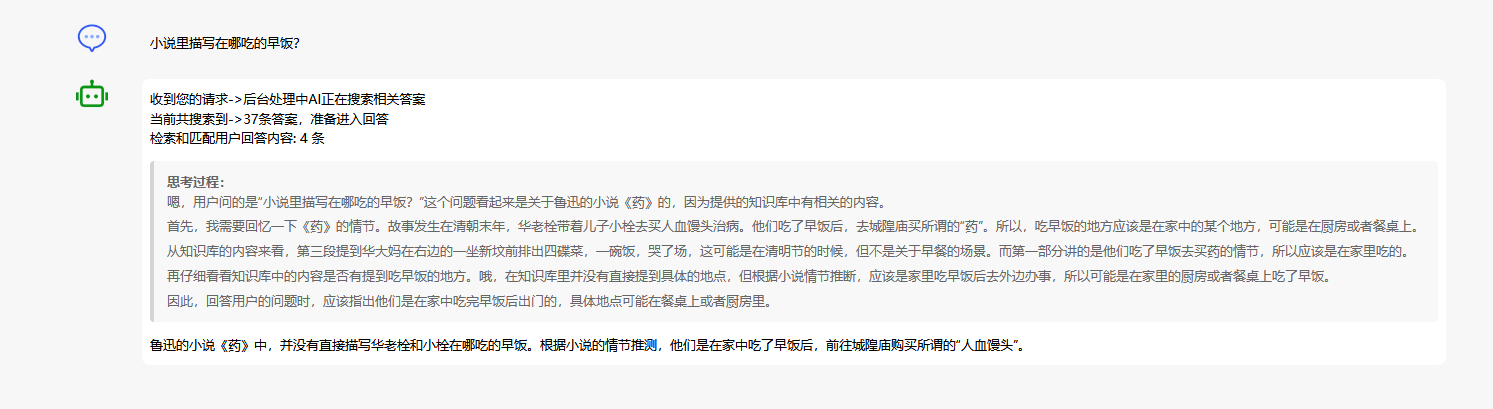
那么此时我们来看AI的回答,真能回答准那是见了鬼了,这就叫“过度拟合”。就是把一堆东西都塞在一起,自以为这样AI就可以区分?
在这边再多说一遍,现在的“AI”其实不是AI,它不会思考,它只是一个比大数据更加智能一些的超级预测体而己。千万不要指望AI可以“理解”。
你如果不告诉AI如何去理解的方式那么AI就会“乱回答”。
理想中的切片
虽然知识库内混杂各个文章但是每个文章的上下文是连贯或者就算不连贯也有AI去做“不同文章间”的标签和切割。
此时我们再来看,同样是用DeepSeek本地满血版布署后回答情况
对比原文:
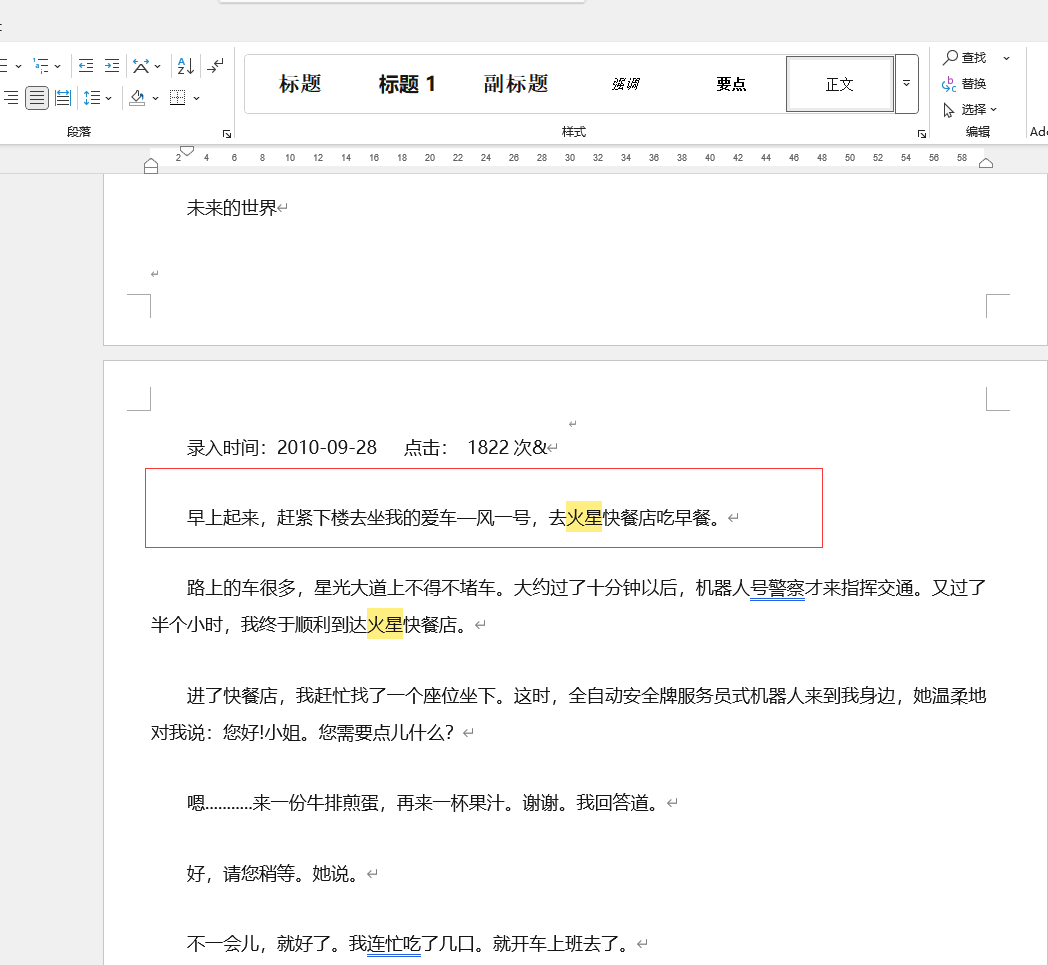
可以看到这个回答是perfect的!
这就是切片的艺术!切片其实就是和企业数字化实施时的“数据预处理”阶段一样,数据质量不行那么数字化实施后的结果一定也是不行的。
这就好比搜索能做得好,你的东西不光是要全,更要精准是一个道理。
切片分割的艺术
切片黄金法则总览
记得一个黄金法则:
分割的目的不是为了分割而分割,而是为了让数据能够被更好地检索和利用。分块在 RAG 架构里可是个“关键角色”,因为它直接决定了生成式 AI 应用的准确性。可以说,它是整个流程的“第一道关卡”。
这个黄金法则扩展开来讲就是:
小块头,大智慧:提高准确性
分块让系统能把文本切成更小的片段,方便索引和搜索。这样一来,当用户提问时,系统能快速找到最相关的片段,大大提高了检索的准确性。想象一下,与其在一整本书里翻找答案,不如直接定位到某一页的某一段——效率高多了!
大小适中,上下文更给力
不过,分块也不是越小越好。块太小可能会丢失上下文信息,块太大又会让模型难以聚焦。理想的分块大小能让生成模型更好地理解每个片段的上下文,从而生成更连贯、更准确的回答。这样一来,模型就不用在一大堆无关信息里“大海捞针”了。
可扩展性与性能:高效处理大数据
分块还能让 RAG 系统更高效地处理海量数据。通过把数据切成可管理的部分,系统可以并行处理这些块,减少计算负担,提升整体性能。这样一来,RAG 系统不仅能处理更多数据,还能跑得更快、更稳。
第一层:字符分割法
基本概念
-
分块大小:每个文本块的字符数量
-
重叠长度:相邻文本块之间共享的字符数量
优势与局限
优势:
-
实现简单直接
-
适合处理格式统一的纯文本
局限:
-
可能切割语义完整的句子
-
不考虑文本的自然结构
这就是外面所有的个人知识库搭建工具如:dify、coze、cherrystudio一类的分法,它们的切片分割 的目的只有一个,那就是减少:一次性传递给到AI的上下文越小、越省越好。
因此导致了大量的幻觉,而市面上存在的Rag或者是一些Rag Flow,90%以上的产品都归为这一类。
第二层:递归字符分割法
这种方法稍微会好一些,它会按照一系列分隔符逐级分割文本:
-
段落分隔符(\n\n)
-
句号分隔符(。)
-
逗号分隔符(,)
-
空格
-
字符
使用场景
-
处理结构化文档
-
需要保持语义完整性
-
文本具有明显的层级结构
这种方法会用在一起较低级或者不怎么严谨的企业FAQ场景中,它要求的是企业的数据本身需要被整理成一段一段,以最大化保某一段语义的完整性。
但是呢,这种手法对企业本身数据提出了巨大的“人肉运营打标”需求,这就是我在之前几篇里说到的,企业本只想花个小10万,5万实施一个问答,结果光为了你准备所谓你认为合格的数据格式就要动用大半个运营团队,人肉纠正语料的成本付出比实施一个项目还贵,到最后项目效果又不好,还充满着:这个格式不对那个格式不对,都是企业自身的锅这些扯皮场景,因此企业实施了就没信心了。
这一类也包括了一系列的:按照markdown特定、PDF特定、Word特定切分都统统可以归属为这一类切分手法,这也是我提到的Rag1.0到Rag1.5代大量采用的实施手法:
那就是一屋子的人肉打标和纠正语义!
因此这种数据实施方式是长久不了的。
第三层:语义分割法
这是一种更高级的分割方法,它考虑文本的实际含义:
工作原理
-
计算文本片段的语义向量
-
分析相邻片段的语义相似度
-
在语义差异较大处进行分割
这种方法是诞生于2024年年底Rag+相关技术内,在外面介绍不多,只是在字面上看着这么高大上。
这种方法的原理很高级实施效果非常好,其实是提示语重写时手法类似,那就是针对这一段内容扩充生成大量的标注,它的终极目的是为了:提高RAG回答时的召回率,做到可召回内容>=用户的提问用的。
受到的局限
但是这种折分手法依然受到大段文章的限制,好比有一段内容语义完整其实要有4,000个字,如果折成10段,碰到以下这种情况:
第一段:运输中途险
第二段:保险标的最低25,000
第三段:免赔额度3,000
第四段:员工忠诚险
第五段:保险标的最低100,000如果是这样的上下文分布,那么AI的回答依然会出现上述例子中的情况。
这种折分手法只可以应对类似下面这种结构的文档:
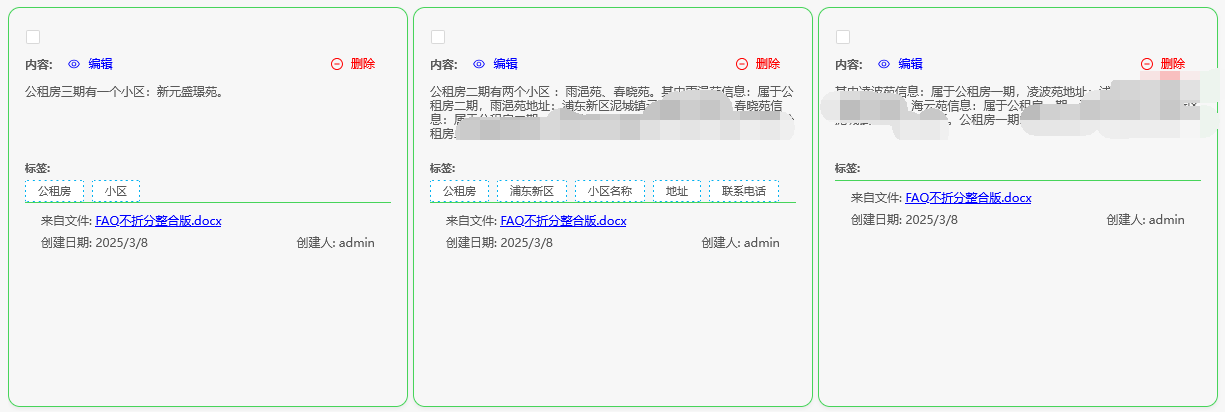
那就是:一问+一答、FAQ类,一段段有规律的且可以明确分成小块内容的文档。
但是它无法应对:小说、书、大段文章的知识入库。
具体折分如下手 法:
我们在进库时可以告诉AI:
现在有一段内容(此段落内不要有任何回车换行而是完整的一段)这段内容可能混杂有多条含议和知识点,请你根据不同的含义和知识点把它折成如:
[
"第一点知识",
"第二点知识",
"第三点知识"
]json字符串数组返回给我,折分时不要破坏语义,把一问一答或者Q和A认做是一段内容。
即把原文保留,只是语义上折分工作交给LLM去做智能折分。
第四层:长段落折分
这种折分手法类似第三层折分但是它不只是折分这么简单。
这种手法和:依赖大纲书写论文一样,它是通过一段一段理解了语义后再通过上下文间的“滑动窗口”进行折分后再拼接的手法。
前文笔者提到过和BAT大厂联合实施时也发现了它们最喜欢400字左右的一整段内容,但是当遇到长文后依旧一筹莫展。
于是大家就一起坐下来探讨,最终得到了这么一种手法,这正是从依赖多级大纲写长论文中得到的灵感,于是当时大家就试了一下。
结果发觉效果惊人的好,后来通过一些MIT的论文也最终得到了验证,原来微软工程院和一些超大型LLM在微调时也是这么干的。
那就是块状切分+语义分割+语义总结。
第一步:块状切分+字符分割结合
我们按照一个chunk:400字左右一切,切分时在物理上要做完整段落标记,即不是绝对的400字一切,而是到了第400字我们看一下此处是否在文章里是属于一整个段,不存在行破坏或者段破坏,因此这样的chunk切出来基本在380~420个字符间浮动,这就是物理上保证这个chunk的完整性。
第二步:语义上折分+总结
光有块切割是会从上下文里破坏语义的,因此我们还要“贯连上下文”。拿上文例子:
第一段:运输中途险
第二段:保险标的最低25,000
第三段:免赔额度3,000
第四段:员工忠诚险
第五段:保险标的最低100,000来举例,经过了长段落得这种混合切分特别是到了第二步语义折分总结后会变成这样的内容进入企业知识库
第一段:运输中途险
第二段:{"前面一段内容":"运输中途险", "本段内容": "保险标的最低25,000"}
第三段:{"前面一段内容":"运输中途险保险标的", "本段内容": "免赔额度3,000"}
第四段:{"前面一段内容":"运输中途险,标的是25,000免赔:3,000", "本段内容": "员工忠诚险"}
第五段:{"前面一段内容":"员工忠诚险", "本段内容": "保险标的最低100,000"}即每次在处理总数为Topn条数据的n>1<n条时把n-1条记录的摘要(视知识条目实际情况,总结成在50-150个具备es搜索关键字形式的摘要)追加到本段内容开头。
于是把这样的内容在召回时再给到LLM,那么这一下就彻底解决了长段、大段文章因为切割被强行打断后语义的“拾回”。
这种手法在后面几个落地的项目中被无数次的证明是彻底解决因为大段落在折分时被打断如何重拾(重接)的终极方法。
总结一下RAG中的切分
分块这招对优化RAG系统来说,绝对是个关键策略。它能让系统的回答更准、更贴合上下文,还能轻松应对大规模需求。
说白了,把大段文本切成小块,不仅找东西更快更准,还能让AI应用的整体效率蹭蹭往上涨。
但又不能为了分块而分,而且上述4层没有一个绝对或者唯一可行的方案,实施时是混合实施的。分块分得好项目已经成功了90%。
好了,结束今还天的分享,关键还是大家要自己动手去验证。
另:本文系统截图正是本人准备于不久后要开源的“fountain"高级RAG系统,一旦开源本人会在第一时间告诉大家源码所在地址(内含了RAG+以及这种高级的混合切片-高度自定义可配置工具)。