Linux 中的 CPU。文章 1. 利用率
大家好!我是大聪明-PLUS!
中央处理器(CPU)是任何计算机系统的核心。高效的CPU使用直接影响应用程序和整个系统的性能。即使您的服务器处理的任务并非计算密集型(例如存储每月仅供用户访问一次的文件存档),没有CPU也无法运行。
本文旨在帮助读者全面了解Linux中的CPU资源利用率。
第一条 处置
我们先来看 CPU 利用率。它反映了系统处理器时间的使用情况,包括哪些类型的任务正在消耗资源以及消耗的百分比。换句话说,它直接回答了“当前谁在消耗系统的计算资源,以及如何消耗?”这个问题。为此,Linux 内核将所有消耗的时间分为几个主要类别:用户空间、系统空间(或内核空间)、空闲时间、I/O 等待、中断和软中断。
很多球队都能提供类似的统计数据,但最常见和最熟悉的选项是top或htop。
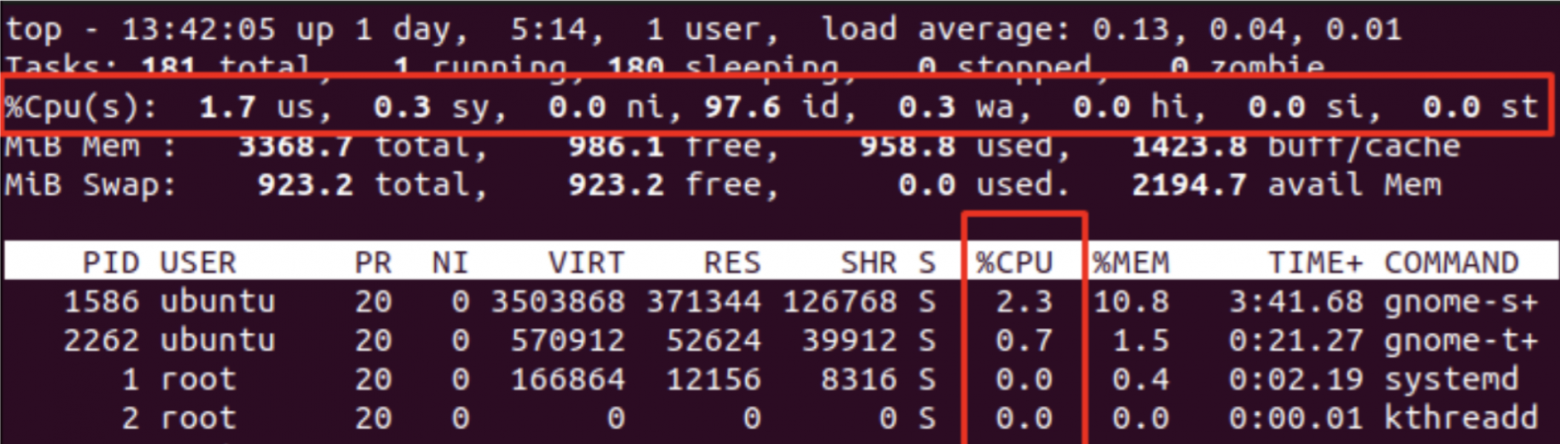
如果我们以最高输出结果为基础,结果将如下所示:
-
用户 CPU 时间(us)——用户空间所花费的时间;
-
sy(系统 CPU 时间)——类似地,在内核空间(系统空间)中花费的时间;
-
ni(Nice CPU time)——单独估算的用户空间进程所花费的时间,这些进程的优先级已被降低(例如,操作员、启动脚本等)。也就是说,它们已被设置为执行优先级较低的任务;
-
id(空闲)— 空闲时间(不活动);
-
wa(I/O 等待)— 等待输入/输出操作所花费的时间;
-
hi(硬件 IRQ)— 处理硬件中断所花费的时间;
-
si(软件 IRQ)——类似地,指处理软件中断所花费的时间;
-
st(偷取时间)是一个非常有趣的含义,我们已经在另一篇文章中写过了。
类别
我们先稍作休息,更详细地探讨一下这些要点。首先是“在Linux中,内核会将时间划分为不同的类别”。这是如何实现的呢?Linux内核使用计数器和定时器来测量处理器在任何给定时刻的状态。正如我们之前提到的,这些状态被分为几个关键类别:
-
用户空间:处理器执行用户进程(应用程序)所花费的时间。此时间在进程以用户模式运行时记录。
-
系统空间(内核空间):执行内核模式操作所花费的时间。这包括执行系统调用、处理中断和执行驱动程序。
-
空闲时间:处理器处于空闲状态且系统处于待机模式的时间。在现代系统中,处理器可以进入节能状态。
-
I/O 等待:处理器等待输入/输出操作(例如访问磁盘或网络设备)所花费的时间。
-
中断:硬件中断处理时间
-
软中断:软件中断处理程序(softirq)的执行时间
Linux 内核利用这些分类,采用多种机制来测量 CPU 时间,并估算每个类别所花费的时间。此类计数机制的示例包括:
1. 定时器(Jiffies)是 一种系统滴答计数器,它会在每个系统定时器滴答时以指定的频率递增。内核使用定时器来测量处理器在各种类别(例如,CPU 进程、CPUuser, system, idle, iowait 处理等)上花费的时间,并在每次上下文切换或事件处理时更新相应的计数器。这使得操作系统能够监控 CPU 负载、调度任务并收集进程统计信息。
系统定时器是处理器或芯片组中的一种硬件机制,它以指定的频率向内核发送中断。
系统滴答是 Linux 内核中最小的时间测量单位,由系统定时器定义。
每次中断都意味着一个系统时钟周期已经过去,内核会更新其内部时间计数器。
每次定时器中断都会导致内核分析 CPU 的当前状态并更新统计信息。
如果进程运行在用户空间,则
utime其值递增。如果在核心区域,
stime则会增加如果进程正在等待 I/O,则会增加
iowait因此,系统时钟是 Linux 用来测量 CPU 使用率、切换任务上下文和管理进程调度的机制。
2. 上下文切换:每次进程或任务切换时,内核都会记录当前处于哪个状态(用户空间或内核空间),并更新相应的计数器。内核调度器会跟踪任务执行的开始和结束。
3. 中断事件:内核记录硬件和软件中断(例如,I/O 请求),并将它们的处理时间添加到相应的类别中。中断处理时间会添加到irq (硬件中断)或softirq (软件中断)中。
4. 进程状态跟踪:内核监视进程状态,例如“准备运行”、“正在运行”和“等待 I/O”。这些状态被调度器捕获,并用于更新指标iowait (I/O 等待时间)等idle。
5. 高分辨率定时器是 一种 能够以微秒级精度进行更精确时间测量的机制。它们被用于现代 Linux 版本中,以实现更精确的性能分析。
存储结果
以这种方式收集的数据需要以某种方式存储和更新。内核使用多种方式来实现这一点。例如,如果讨论的是正在运行的进程,那么每个进程的信息都存储在一个task_struct名为进程控制块(Process Control Block, PCB)的数据结构中——PCB 是操作系统用来管理和存储进程所有信息的进程对象。PCB 包含许多时间计数器,例如,用于显示进程在执行期间用户模式或系统模式下消耗的 CPU 时间。
处理器状态数据(用户、系统、空闲、I/O等待等)存储在内核数据结构中,可通过内核访问。/proc.
内核还会根据系统时钟和 CPU 计数器更新这些数据。例如,如果我们采用最简单的方式查看统计信息,我们可以访问 /proc/stat 文件,内核会在该文件中记录所有利用率类别的信息:
/proc 目录下还有许多其他接口文件,可以用来获取此类统计信息。例如:
/proc/[PID]/stat— 包含 PID 的过程的详细统计信息。
包含:
-
utime, stime:在用户空间和系统空间中花费的时间。 -
starttime:流程开始时间。 -
nvcsw, nivcsw:自愿和强制的上下文切换。
cat /proc/1234/stat
-
/proc/[PID]/task/[TID]/stat类似于/proc/[PID]/stat,但针对的是进程内的线程。可用于对多线程应用程序进行详细分析。 -
/proc/softirqs软件中断(softirq)统计信息。包含每个处理器处理的softirq数量。 -
/proc/interrupts硬件中断统计信息。包含每个处理器已处理的硬件中断计数器。
幸运的是,我们不必每天手动审查这些内容——顶级和类似的实用程序会像其他许多程序一样,为您解析这些数据源。
实际应用性
所以,我们已经弄清楚了CPU利用率是什么,它由哪些部分组成,也大致了解了它的计算方法、结果存储在哪里以及如何监控它们。那么,接下来呢?我们为什么需要它?
在我看来,所有答案大同小异。也就是说,无论如何,最终都取决于分析服务器状态并找出负载消耗的来源。我们考虑两种场景:故障排除(一切正常,然后突然出现问题)和负载测试。在负载测试中,我们需要了解在负载增加的过程中,系统何时开始因计算资源不足而性能下降,以及大部分资源消耗在哪里。为此,我们将使用下表对这两种情况进行比较:
总而言之
监控 CPU 利用率及其组成部分有助于我们了解系统资源的使用情况以及问题出现的位置。这对于优化应用程序、诊断瓶颈以及配置服务器以确保其在高负载下稳定运行至关重要。此外,不仅要关注当前值,还要收集不同时间段的历史统计数据。这样,一旦出现问题,我们就可以将当前读数(例如,周五上午)与上周同一天同一时间段的数据,以及本月初或上月底的数据进行比较。这使我们能够了解是否遇到了全新的问题,或者是否是之前从未遇到过的情况,又或者只是利用率原本就很高,而今天只是突破了某个阈值。