自然语言处理实战——基于混合专家模型(MoE)的文本生成
目录
一、引言
二、整体目标与核心架构
三、核心模块与功能详解
1. 环境配置与参数设置
2. 数据预处理模块
3. 混合专家模型(MoE)定义
4. 损失函数与优化器
5. 训练与评估函数
6. 文本生成函数
7. 主程序(训练与生成)
四、基于混合专家模型(MoE)的文本生成的Python代码完整实现
五、程序运行结果展示
六、总结
一、引言
本文的实战项目是基于混合专家模型(MoE)的文本生成,核心功能是通过训练字符级语言模型,实现英文文本续写(给定前缀文本,自动生成后续内容)。代码包含从数据预处理、模型构建、训练优化到文本生成的完整流程,以下是各部分功能的详细介绍以及Python代码完整实现。
二、整体目标与核心架构
- 核心任务:构建字符级文本生成模型,学习文本序列的概率分布,实现 “给定前缀→生成后续字符” 的续写功能。
- 模型架构:采用混合专家模型(MoE),由多个 LSTM 专家网络和一个门控网络组成,通过门控动态选择专家输出并加权组合,提升生成多样性和效率。
- 关键优化:引入负载均衡损失,避免门控网络过度依赖少数专家,确保所有专家资源被充分利用。
三、核心模块与功能详解
1. 环境配置与参数设置
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, random_split
# ... 其他库# 中文字体设置(确保可视化图表中文正常显示)
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False# 设备自动选择(优先GPU,无则用CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
功能:导入必要的库(PyTorch 深度学习框架、数据处理工具、可视化工具等),配置中文显示,自动选择计算设备(GPU 加速训练,CPU 作为备选)。
-
超参数设置:
SEQ_LEN=50:输入序列长度(用前 50 个字符预测第 51 个字符)。HIDDEN_DIM=256:专家网络 LSTM 的隐藏层维度(控制模型容量)。NUM_EXPERTS=4:专家网络数量(MoE 的核心组件,分工处理不同特征)。TOP_K=2:每个输入激活的专家数量(稀疏激活,减少计算量)。BATCH_SIZE=64:训练批次大小(平衡效率与稳定性)。EPOCHS=20:训练轮次(控制模型收敛程度)。- 其他参数:学习率、嵌入维度等,用于调整模型训练细节。
2. 数据预处理模块
该模块负责将原始文本转换为模型可输入的张量格式,核心是字符级词汇表构建和序列生成。
-
TextDataset 类:
class TextDataset(Dataset):def __init__(self, text, seq_len):# 构建字符→索引映射(词汇表)chars = sorted(list(set(text)))self.char2idx = {c: i for i, c in enumerate(chars)} # 字符→索引self.idx2char = {i: c for i, c in enumerate(chars)} # 索引→字符self.vocab_size = len(chars) # 词汇表大小(唯一字符数)# 文本转换为索引序列self.data = [self.char2idx[c] for c in text]def __getitem__(self, idx):input_seq = self.data[idx:idx+SEQ_LEN] # 输入:前50个字符索引target_char = self.data[idx+SEQ_LEN] # 目标:第51个字符索引return torch.tensor(input_seq), torch.tensor(target_char)- 功能:将原始文本转换为字符级索引序列,生成训练所需的 “输入 - 目标” 对(输入是长度为 50 的字符序列,目标是下一个字符)。
- 词汇表:通过
char2idx和idx2char实现字符与整数索引的映射,解决模型无法直接处理字符的问题。
-
数据加载与划分:
def load_text_data():# 加载示例文本(莎士比亚名句),清理后返回sample_text = "To be, or not to be, that is the question: ..."text = sample_text.replace("\n", " ").strip().lower() # 清理:去空行、小写化return text# 加载文本并创建数据集 text = load_text_data() dataset = TextDataset(text, SEQ_LEN)# 划分训练集(80%)和验证集(20%) train_size = int(0.8 * len(dataset)) train_dataset, val_dataset = random_split(dataset, [train_size, val_size])# 数据加载器(批量读取数据,支持打乱) train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True) val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)- 功能:加载示例文本(可替换为任意英文文本),通过
TextDataset转换为模型输入格式,划分训练集(用于参数更新)和验证集(用于监控过拟合),并通过DataLoader实现批量读取。
- 功能:加载示例文本(可替换为任意英文文本),通过
3. 混合专家模型(MoE)定义
该模块是核心,包含专家网络、门控网络和 MoE 整体架构,实现 “分而治之” 的序列处理逻辑。
-
Expert(专家网络):
class Expert(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim) # 字符嵌入层self.lstm = nn.LSTM( # LSTM层(处理序列特征)input_size=embedding_dim,hidden_size=hidden_dim,batch_first=True)self.fc = nn.Linear(hidden_dim, vocab_size) # 输出层(预测下一个字符)def forward(self, x, hidden=None):x_embed = self.embedding(x) # 字符索引→嵌入向量(batch, seq_len, embedding_dim)lstm_out, hidden = self.lstm(x_embed, hidden) # LSTM处理序列last_out = lstm_out[:, -1, :] # 取最后一个时间步输出(batch, hidden_dim)logits = self.fc(last_out) # 预测下一个字符的logits(batch, vocab_size)return logits, hidden- 功能:每个专家是一个独立的 LSTM 网络,负责学习文本序列的部分特征(例如,有的专家擅长学习标点规律,有的擅长学习词汇搭配)。
- 输入输出:输入字符索引序列→输出下一个字符的预测分数(logits),同时返回 LSTM 隐藏状态(用于生成时维持上下文)。
-
Gating(门控网络):
class Gating(nn.Module):def __init__(self, hidden_dim, num_experts, top_k):super().__init__()self.gate = nn.Sequential( # 门控权重计算网络nn.Linear(hidden_dim, hidden_dim),nn.Tanh(),nn.Linear(hidden_dim, num_experts))self.top_k = top_k # 稀疏激活的专家数量def forward(self, hidden_state):raw_weights = self.gate(hidden_state) # 原始权重(batch, num_experts)weights = F.softmax(raw_weights, dim=1) # 归一化(权重和为1)# 稀疏激活:仅保留权重最高的top_k个专家if self.top_k is not None:top_k_indices = torch.topk(weights, self.top_k, dim=1)[1]mask = torch.zeros_like(weights).scatter_(1, top_k_indices, 1)weights = weights * mask # 过滤低权重专家weights = weights / (weights.sum(dim=1, keepdim=True) + 1e-8) # 重新归一化return weights- 功能:根据输入序列的特征(隐藏状态),为每个专家分配权重,决定 “哪些专家更适合处理当前序列”。
- 稀疏激活:通过
top_k参数仅激活权重最高的 2 个专家,减少冗余计算,提升效率。
-
MoEGenerator(MoE 生成器):
class MoEGenerator(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_experts, top_k):super().__init__()self.experts = nn.ModuleList([ # 初始化多个专家Expert(vocab_size, embedding_dim, hidden_dim) for _ in range(num_experts)])self.gating = Gating(hidden_dim, num_experts, top_k) # 门控网络def forward(self, x, hidden_list=None):# 1. 所有专家独立处理输入,得到输出和隐藏状态expert_logits = []new_hidden_list = []for expert in self.experts:logits, hidden = expert(x, hidden_list[i] if hidden_list else None)expert_logits.append(logits)new_hidden_list.append(hidden)# 2. 计算门控权重(基于专家隐藏状态的均值)hidden_states = torch.stack([h[0].squeeze(0) for h in new_hidden_list], dim=1)avg_hidden = hidden_states.mean(dim=1) # 序列特征(batch, hidden_dim)weights = self.gating(avg_hidden) # 专家权重(batch, num_experts)# 3. 加权组合专家输出,得到最终预测expert_logits = torch.stack(expert_logits, dim=1) # (batch, num_experts, vocab_size)logits = torch.sum(expert_logits * weights.unsqueeze(-1), dim=1) # 加权求和return logits, new_hidden_list, weights- 功能:整合专家网络和门控网络,实现 “多专家分工→门控选优→加权组合” 的生成逻辑。
- 核心逻辑:每个专家独立处理输入序列,门控网络根据序列特征分配权重,最终通过权重加权组合专家的预测结果,得到下一个字符的最终预测。
4. 损失函数与优化器
-
负载均衡损失:
def load_balancing_loss(gating_weights):expert_mean = gating_weights.mean(dim=0) # 每个专家的平均权重(跨批次)target = torch.ones_like(expert_mean) / NUM_EXPERTS # 目标:均匀分布(1/4)return F.mse_loss(expert_mean, target) # 均方误差:鼓励权重分布均匀- 功能:防止门控网络 “偷懒”(过度依赖少数专家),通过最小化 “专家平均权重” 与 “均匀分布” 的差异,强制所有专家参与决策,提升模型泛化能力。
-
总损失与优化器:
criterion = nn.CrossEntropyLoss() # 主损失:预测字符与真实字符的交叉熵 optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE) # 优化器:Adam(自适应学习率) lambda_lb = 0.05 # 负载均衡损失的权重(平衡主损失与正则化)- 总损失:
总损失 = 交叉熵损失 + 0.05×负载均衡损失,既保证预测准确性,又确保专家资源充分利用。
- 总损失:
5. 训练与评估函数
-
train 函数(模型训练):
def train(model, loader, optimizer, criterion, lambda_lb):model.train() # 训练模式(启用 dropout/batchnorm)total_loss = 0.0for input_seq, target_char in tqdm(loader, desc="训练"):input_seq, target_char = input_seq.to(device), target_char.to(device)optimizer.zero_grad() # 清零梯度# 前向传播:获取预测logits和门控权重logits, _, weights = model(input_seq)# 计算损失ce_loss = criterion(logits, target_char) # 交叉熵损失lb_loss = load_balancing_loss(weights) # 负载均衡损失loss = ce_loss + lambda_lb * lb_loss# 反向传播与参数更新loss.backward() # 计算梯度optimizer.step() # 更新参数total_loss += loss.item() * input_seq.size(0) # 累计损失return total_loss / len(loader.dataset) # 平均损失- 功能:在训练集上迭代更新模型参数,通过反向传播最小化总损失,学习文本序列的规律。
-
evaluate 函数(模型评估):
def evaluate(model, loader, criterion):model.eval() # 评估模式(关闭 dropout/batchnorm)total_loss = 0.0with torch.no_grad(): # 禁用梯度计算(加速+节省内存)for input_seq, target_char in tqdm(loader, desc="评估"):input_seq, target_char = input_seq.to(device), target_char.to(device)logits, _, _ = model(input_seq)loss = criterion(logits, target_char) # 仅计算交叉熵损失(无正则化)total_loss += loss.item() * input_seq.size(0)return total_loss / len(loader.dataset) # 平均损失- 功能:在验证集上评估模型性能(不更新参数),监控模型是否过拟合(若验证损失上升而训练损失下降,说明过拟合)。
6. 文本生成函数
def generate_text(model, prefix, max_len=100, temperature=1.0):model.eval() # 评估模式# 前缀处理:转换为索引,调整长度为SEQ_LEN(填充/截断)prefix_indices = [char2idx.get(c, 0) for c in prefix.lower()]prefix_indices = (prefix_indices + [0]*SEQ_LEN)[:SEQ_LEN] if len(prefix_indices) < SEQ_LEN else prefix_indices[-SEQ_LEN:]input_seq = torch.tensor(prefix_indices).unsqueeze(0).to(device)generated = list(prefix) # 生成结果初始化(包含前缀)hidden_list = None # 专家隐藏状态(维持上下文连贯性)with torch.no_grad():for _ in range(max_len):# 预测下一个字符logits, hidden_list, _ = model(input_seq, hidden_list)# 温度调整概率分布(控制多样性)logits = logits / temperature # 温度>1:分布更平缓(多样性高);<1:更陡峭(确定性高)probs = F.softmax(logits, dim=1) # 转换为概率next_idx = torch.argmax(probs, dim=1).item() # 贪婪解码:选概率最高的字符next_char = idx2char[next_idx] # 索引→字符generated.append(next_char) # 加入生成结果# 更新输入序列(滑动窗口:移除第一个字符,加入新生成的字符)input_seq = torch.cat([input_seq[:, 1:], torch.tensor([[next_idx]], device=device)], dim=1)return ''.join(generated) # 拼接为完整文本
- 功能:基于训练好的模型,根据输入前缀生成后续文本,核心是 “滑动窗口 + 隐藏状态传递” 维持上下文连贯性。
- 解码策略:采用贪婪解码(选择概率最高的字符),通过
temperature参数控制生成多样性(例如,temperature=0.7生成较保守但连贯的文本,1.2生成更多样但可能混乱的文本)。
7. 主程序(训练与生成)
if __name__ == "__main__":# 初始化模型model = MoEGenerator(...).to(device)# 训练模型train_losses, val_losses = [], []for epoch in range(EPOCHS):train_loss = train(...) # 训练一轮val_loss = evaluate(...) # 验证train_losses.append(train_loss)val_losses.append(val_loss)print(f"训练损失: {train_loss:.4f}, 验证损失: {val_loss:.4f}")# 绘制损失曲线(可视化训练过程)plt.plot(train_losses, label="训练损失")plt.plot(val_losses, label="验证损失")plt.title("训练与验证损失曲线")plt.show()# 生成文本示例prefixes = ["to be or not to", ...] # 前缀列表for prefix in prefixes:generated_text = generate_text(model, prefix, max_len=80, temperature=0.7)print(f"前缀: {prefix}\n生成: {generated_text}")
- 功能:串联整个流程,先训练模型并记录损失,通过损失曲线观察模型收敛情况;训练完成后,使用示例前缀生成文本,展示模型的生成效果。
四、基于混合专家模型(MoE)的文本生成的Python代码完整实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, random_split
from tqdm import tqdm
import matplotlib.pyplot as plt
from collections import defaultdict# 设置中文字体
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False# 设备配置(自动选择GPU/CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# ----------------------------
# 超参数设置
# ----------------------------
SEQ_LEN = 50 # 输入序列长度(用前50个字符预测第51个)
HIDDEN_DIM = 256 # 专家网络隐藏层维度
NUM_EXPERTS = 4 # 专家数量
TOP_K = 2 # 每个步骤激活的专家数量
BATCH_SIZE = 64
EPOCHS = 20 # 训练轮次
LEARNING_RATE = 1e-3
EMBEDDING_DIM = 128 # 字符嵌入维度# ----------------------------
# 数据预处理
# ----------------------------
class TextDataset(Dataset):"""字符级文本数据集:输入序列→目标字符"""def __init__(self, text, seq_len):self.seq_len = seq_len# 构建字符→索引映射(字符级词汇表)chars = sorted(list(set(text)))self.char2idx = {c: i for i, c in enumerate(chars)}self.idx2char = {i: c for i, c in enumerate(chars)}self.vocab_size = len(chars)# 文本转换为索引序列self.data = [self.char2idx[c] for c in text]def __len__(self):return len(self.data) - self.seq_lendef __getitem__(self, idx):# 输入:前seq_len个字符input_seq = self.data[idx:idx + self.seq_len]# 目标:第seq_len+1个字符(下一个字符)target_char = self.data[idx + self.seq_len]return torch.tensor(input_seq, dtype=torch.long), torch.tensor(target_char, dtype=torch.long)def load_text_data():"""加载示例文本(可替换为更长的英文文本)"""sample_text = """To be, or not to be, that is the question:Whether 'tis nobler in the mind to sufferThe slings and arrows of outrageous fortune,Or to take arms against a sea of troublesAnd by opposing end them. To die, to sleep—No more—and by a sleep to say we endThe heartache and the thousand natural shocksThat flesh is heir to: 'tis a consummationDevoutly to be wish'd. To die, to sleep;To sleep, perchance to dream—ay, there's the rub:For in that sleep of death what dreams may come,When we have shuffled off this mortal coil,Must give us pause. There's the respectThat makes calamity of so long life:For who would bear the whips and scorns of time,The oppressor's wrong, the proud man's contumely,The pangs of despised love, the law's delay,The insolence of office and the spurnsThat patient merit of the unworthy takes,When he himself might his quietus makeWith a bare bodkin? Who would fardels bear,To grunt and sweat under a weary life,But that the dread of something after death,The undiscovered country from whose bournNo traveller returns, puzzles the willAnd makes us rather bear those ills we haveThan fly to others that we know not of?Thus conscience does make cowards of us all;And thus the native hue of resolutionIs sicklied o'er with the pale cast of thought,And enterprises of great pith and momentWith this regard their currents turn awry,And lose the name of action."""# 清理文本(移除多余空行,统一为小写)text = sample_text.replace("\n", " ").strip().lower()return text# 加载并预处理数据
text = load_text_data()
dataset = TextDataset(text, SEQ_LEN)
vocab_size = dataset.vocab_size
char2idx = dataset.char2idx
idx2char = dataset.idx2char
print(f"文本长度: {len(text)} 字符")
print(f"词汇表大小(唯一字符数): {vocab_size}")# 划分训练集与验证集(8:2)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])# 数据加载器
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)# ----------------------------
# 混合专家模型(MoE)定义
# ----------------------------
class Expert(nn.Module):"""LSTM专家网络:处理序列,输出下一个字符的logits"""def __init__(self, vocab_size, embedding_dim, hidden_dim):super().__init__()self.embedding = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(input_size=embedding_dim,hidden_size=hidden_dim,batch_first=True)self.fc = nn.Linear(hidden_dim, vocab_size) # 输出维度=词汇表大小def forward(self, x, hidden=None):x_embed = self.embedding(x) # (batch_size, seq_len, embedding_dim)lstm_out, hidden = self.lstm(x_embed, hidden) # lstm_out: (batch_size, seq_len, hidden_dim)last_out = lstm_out[:, -1, :] # 取最后一个时间步输出 (batch_size, hidden_dim)logits = self.fc(last_out) # (batch_size, vocab_size)return logits, hiddenclass Gating(nn.Module):"""门控网络:基于序列状态分配专家权重"""def __init__(self, hidden_dim, num_experts, top_k):super().__init__()self.num_experts = num_expertsself.top_k = top_kself.gate = nn.Sequential(nn.Linear(hidden_dim, hidden_dim),nn.Tanh(),nn.Linear(hidden_dim, num_experts))def forward(self, hidden_state):raw_weights = self.gate(hidden_state) # (batch_size, num_experts)weights = F.softmax(raw_weights, dim=1) # 归一化# 稀疏激活:仅保留top-k权重if self.top_k is not None and self.top_k < self.num_experts:top_k_values, top_k_indices = torch.topk(weights, self.top_k, dim=1)mask = torch.zeros_like(weights)mask.scatter_(1, top_k_indices, 1)weights = weights * maskweights = weights / (weights.sum(dim=1, keepdim=True) + 1e-8) # 避免除0return weightsclass MoEGenerator(nn.Module):"""MoE文本生成器:整合专家网络和门控网络"""def __init__(self, vocab_size, embedding_dim, hidden_dim, num_experts, top_k):super().__init__()self.experts = nn.ModuleList([Expert(vocab_size, embedding_dim, hidden_dim)for _ in range(num_experts)])self.gating = Gating(hidden_dim, num_experts, top_k)def forward(self, x, hidden_list=None):batch_size = x.size(0)num_experts = len(self.experts)# 初始化专家隐藏状态(若未提供)if hidden_list is None:hidden_list = [None for _ in range(num_experts)]# 1. 计算所有专家的输出和隐藏状态expert_logits = []new_hidden_list = []for i in range(num_experts):logits, hidden = self.experts[i](x, hidden_list[i])expert_logits.append(logits)new_hidden_list.append(hidden)# 2. 提取专家隐藏状态用于门控hidden_states = torch.stack([h[0].squeeze(0) for h in new_hidden_list], dim=1) # (batch, experts, hidden)avg_hidden = hidden_states.mean(dim=1) # (batch, hidden)# 3. 计算门控权重weights = self.gating(avg_hidden) # (batch, experts)# 4. 加权组合专家输出expert_logits = torch.stack(expert_logits, dim=1) # (batch, experts, vocab)weights = weights.unsqueeze(-1) # (batch, experts, 1)logits = torch.sum(expert_logits * weights, dim=1) # (batch, vocab)return logits, new_hidden_list, weights# 初始化模型
model = MoEGenerator(vocab_size=vocab_size,embedding_dim=EMBEDDING_DIM,hidden_dim=HIDDEN_DIM,num_experts=NUM_EXPERTS,top_k=TOP_K
).to(device)# ----------------------------
# 损失函数与优化器
# ----------------------------
def load_balancing_loss(gating_weights):"""负载均衡损失:鼓励专家均匀被使用"""expert_mean = gating_weights.mean(dim=0) # (num_experts,)target = torch.ones_like(expert_mean) / NUM_EXPERTS # 目标均匀分布return F.mse_loss(expert_mean, target)criterion = nn.CrossEntropyLoss() # 生成任务交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
lambda_lb = 0.05 # 负载均衡损失权重# ----------------------------
# 训练与评估函数
# ----------------------------
def train(model, loader, optimizer, criterion, lambda_lb):model.train()total_loss = 0.0for input_seq, target_char in tqdm(loader, desc="训练"):input_seq = input_seq.to(device)target_char = target_char.to(device)optimizer.zero_grad()# 前向传播logits, _, weights = model(input_seq)# 计算总损失(主损失 + 负载均衡损失)ce_loss = criterion(logits, target_char)lb_loss = load_balancing_loss(weights)loss = ce_loss + lambda_lb * lb_loss# 反向传播与优化loss.backward()optimizer.step()total_loss += loss.item() * input_seq.size(0)return total_loss / len(loader.dataset) # 平均损失def evaluate(model, loader, criterion):model.eval()total_loss = 0.0with torch.no_grad():for input_seq, target_char in tqdm(loader, desc="评估"):input_seq = input_seq.to(device)target_char = target_char.to(device)logits, _, _ = model(input_seq)loss = criterion(logits, target_char)total_loss += loss.item() * input_seq.size(0)return total_loss / len(loader.dataset) # 平均损失# ----------------------------
# 文本生成函数
# ----------------------------
def generate_text(model, prefix, max_len=100, temperature=1.0):"""基于前缀生成后续文本(贪婪解码)"""model.eval()# 前缀处理:转换为索引并调整长度prefix_indices = [char2idx.get(c, 0) for c in prefix.lower()]if len(prefix_indices) < SEQ_LEN:prefix_indices = [0] * (SEQ_LEN - len(prefix_indices)) + prefix_indices # 填充else:prefix_indices = prefix_indices[-SEQ_LEN:] # 截断input_seq = torch.tensor(prefix_indices, dtype=torch.long).unsqueeze(0).to(device)generated = list(prefix)hidden_list = None # 专家隐藏状态(维持上下文)with torch.no_grad():for _ in range(max_len):# 预测下一个字符logits, hidden_list, _ = model(input_seq, hidden_list)# 温度调整概率分布logits = logits / temperatureprobs = F.softmax(logits, dim=1)# 贪婪选择概率最高的字符next_idx = torch.argmax(probs, dim=1).item()next_char = idx2char[next_idx]generated.append(next_char)# 更新输入序列(滑动窗口)input_seq = input_seq[:, 1:] # 移除首个字符input_seq = torch.cat([input_seq, torch.tensor([[next_idx]], device=device)], dim=1)return ''.join(generated)# ----------------------------
# 主程序:训练模型并生成文本
# ----------------------------
if __name__ == "__main__":# 训练模型train_losses, val_losses = [], []print("\n开始训练...")for epoch in range(EPOCHS):print(f"\nEpoch {epoch + 1}/{EPOCHS}")train_loss = train(model, train_loader, optimizer, criterion, lambda_lb)val_loss = evaluate(model, val_loader, criterion)train_losses.append(train_loss)val_losses.append(val_loss)print(f"训练损失: {train_loss:.4f}, 验证损失: {val_loss:.4f}")# 绘制损失曲线plt.figure(figsize=(8, 4))plt.plot(train_losses, label="训练损失")plt.plot(val_losses, label="验证损失")plt.xlabel("Epoch")plt.ylabel("Loss")plt.title("训练与验证损失曲线")plt.legend()plt.show()# 生成文本示例print("\n===== 文本生成示例 =====")prefixes = ["to be or not to","whether 'tis nobler","to die, to sleep"]for prefix in prefixes:generated_text = generate_text(model, prefix, max_len=80, temperature=0.7)print(f"\n前缀: {prefix}")print(f"生成: {generated_text}")
五、程序运行结果展示
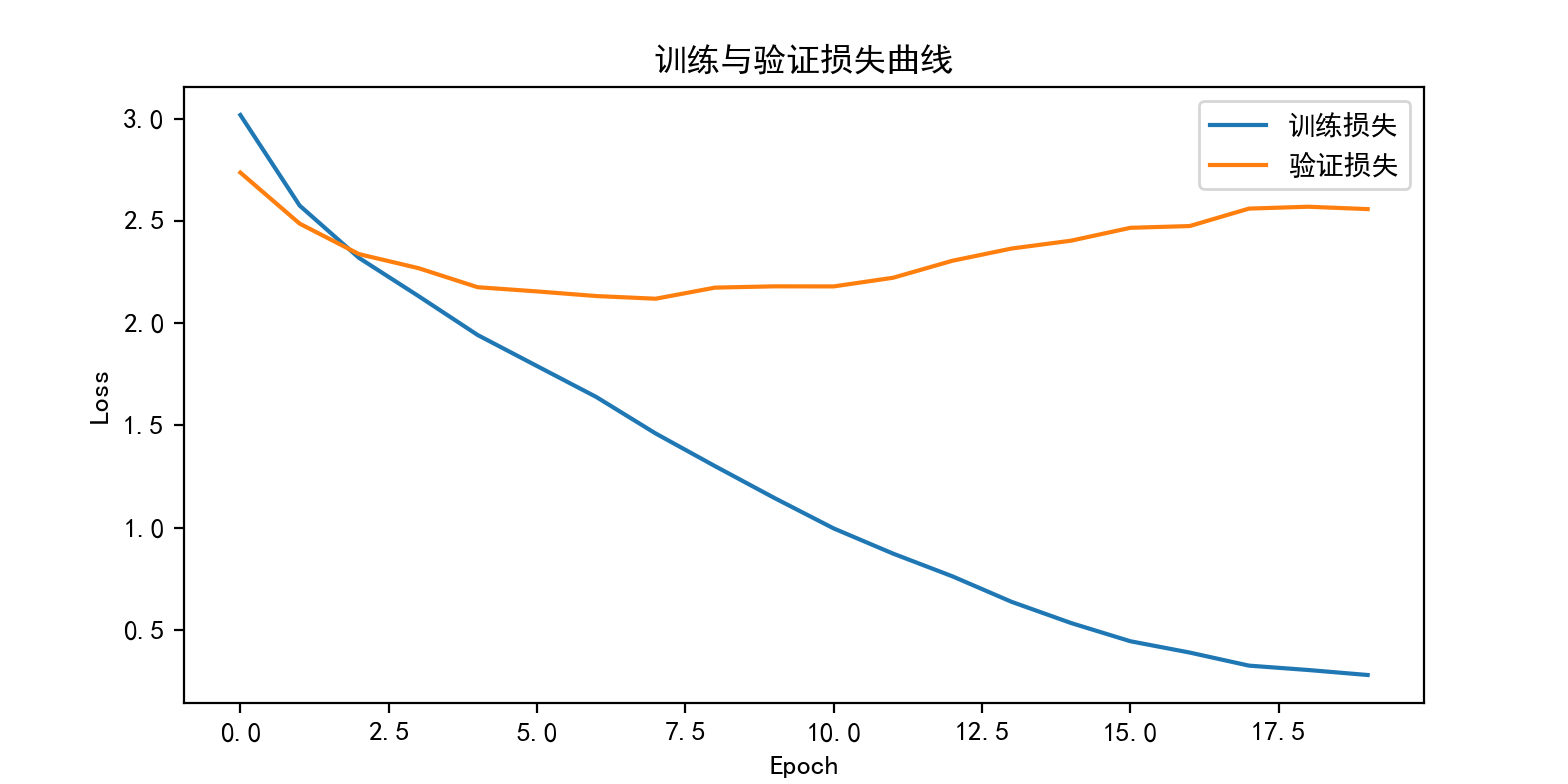
使用设备: cpu
文本长度: 1531 字符
词汇表大小(唯一字符数): 32
开始训练...
Epoch 1/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.67it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 27.07it/s]
训练损失: 3.0181, 验证损失: 2.7364
Epoch 2/20
训练: 100%|██████████| 19/19 [00:02<00:00, 7.15it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 27.28it/s]
训练损失: 2.5747, 验证损失: 2.4865
Epoch 3/20
训练: 100%|██████████| 19/19 [00:02<00:00, 7.01it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 26.69it/s]
训练损失: 2.3189, 验证损失: 2.3374
Epoch 4/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.92it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 26.88it/s]
训练损失: 2.1326, 验证损失: 2.2689
Epoch 5/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.75it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 27.70it/s]
训练损失: 1.9416, 验证损失: 2.1755
Epoch 6/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.91it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 25.56it/s]
训练损失: 1.7899, 验证损失: 2.1550
Epoch 7/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.87it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 25.98it/s]
训练损失: 1.6384, 验证损失: 2.1323
Epoch 8/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.62it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 25.03it/s]
训练损失: 1.4600, 验证损失: 2.1192
Epoch 9/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.71it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 26.60it/s]
训练损失: 1.3003, 验证损失: 2.1735
Epoch 10/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.64it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 26.17it/s]
训练损失: 1.1446, 验证损失: 2.1798
Epoch 11/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.56it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 23.26it/s]
训练损失: 0.9955, 验证损失: 2.1795
Epoch 12/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.66it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 25.22it/s]
训练损失: 0.8725, 验证损失: 2.2217
Epoch 13/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.53it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 26.42it/s]
训练损失: 0.7613, 验证损失: 2.3049
Epoch 14/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.35it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 24.59it/s]
训练损失: 0.6363, 验证损失: 2.3648
Epoch 15/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.45it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 24.64it/s]
训练损失: 0.5328, 验证损失: 2.4031
Epoch 16/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.42it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 26.06it/s]
训练损失: 0.4436, 验证损失: 2.4662
Epoch 17/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.36it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 22.98it/s]
训练损失: 0.3883, 验证损失: 2.4748
Epoch 18/20
训练: 100%|██████████| 19/19 [00:02<00:00, 6.39it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 25.29it/s]
训练损失: 0.3242, 验证损失: 2.5602
Epoch 19/20
训练: 100%|██████████| 19/19 [00:03<00:00, 6.30it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 25.54it/s]
训练损失: 0.3028, 验证损失: 2.5693
Epoch 20/20
训练: 100%|██████████| 19/19 [00:03<00:00, 6.33it/s]
评估: 100%|██████████| 5/5 [00:00<00:00, 23.06it/s]
训练损失: 0.2784, 验证损失: 2.5577
===== 文本生成示例 =====
前缀: to be or not to
生成: to be or not to sleep, porther 'tis nater deat dear, whent he in the respespes the prould b
前缀: whether 'tis nobler
生成: whether 'tis nobler in the makes cayt of the in the prount the insoleng end to sleep, porther
前缀: to die, to sleep
生成: to die, to sleep— porther 'tis nater deat dear, whent he in the respespes the prould bear th
六、总结
本文介绍了一个完整的基于混合专家模型的文本生成的自然语言处理实战的项目,核心优势在于:
- MoE 架构:通过多个专家分工处理文本特征,门控动态选择最优组合,平衡模型容量与效率。
- 负载均衡:避免专家资源浪费,提升模型泛化能力。
- 完整流程:从数据预处理到模型训练、评估、生成,覆盖文本生成任务的全链路。
通过调整超参数(如专家数量、隐藏层维度、训练轮次)或替换训练文本,可适配不同场景的文本生成需求(如诗歌、小说续写等)。