算法精要:高效解题思路与技巧
本文记录了作者在学习基础算法过程中遇到的问题和注意事项,并非系统教程。部分内容会简略提及,适合有一定基础的读者回顾查阅,希望能为阅读本文的朋友提供帮助。
算法题普遍需要注意的点
- 先处理边界情况,再处理一般情况。
- 先想出暴力的一般思路,然后基于此思路再利用其他算法思想进行优化。
- 学会状态压缩(例如二进制枚举代替模拟过程,把二维问题转化成一维问题),将某些难的问题压缩成简单的数据结构去进行处理,这样有助于我们有一个更清晰的思路,代码能够更简洁的实现。
- 正难则反。
- 数组接收输入数据时,下标从1开始,下标为0的元素用作判断边界情况。
- 注意cin和cout的效率问题:要么用scanf和printf,要么加上代码处理掉输入输出流同步的问题解除cin和cout的绑定。
- 注意数据范围问题,必要时开long long。
模拟
一般只需要根据题目要求模拟行为即可,一般可以直接模拟的题目时间和空间复杂度都不会太大,属于竞赛中的“签到题”。
- 小心模拟过程中的边界情况。
- 就题论题分析好题目可能遇到的各种情况。
高精度运算
- 接收数据时,字符串接收大范围数据,然后逆序存储数据到整形数组中。
- 数字字符存入数组时,要注意减去字符'0'。
- 模拟列竖式进行运算,不进位。
- 最后统一进位处理。
- 处理前置0问题,位于计算结果位数前的0不计入有数据范围。
枚举
对于情况不多切空间时间复杂度不大的情况,我们可以选择把所有的情况都处理一下,不合理的排除,合理的就进行处理最后如果结果正确,就计入正确结果当中,也就是枚举。
普通枚举
选择合适的枚举方向,由少到多,由左往右,由上到下,从哪每个部分开始枚举等等
二进制枚举
当题目的给出的模拟过程,所要处理的数据是或者可以变成两种情况的排列组合,又或者返回结果可以通过二进制来代替,就可以考虑进行二进制枚举。
前缀和
前缀和的思想就是,我们输入一段数据到数组中,然后我们对数组进行特殊处理,让数组每一个下标对应的元素等于原数组从下标1开始到对应下标的元素之和。
一维前缀和
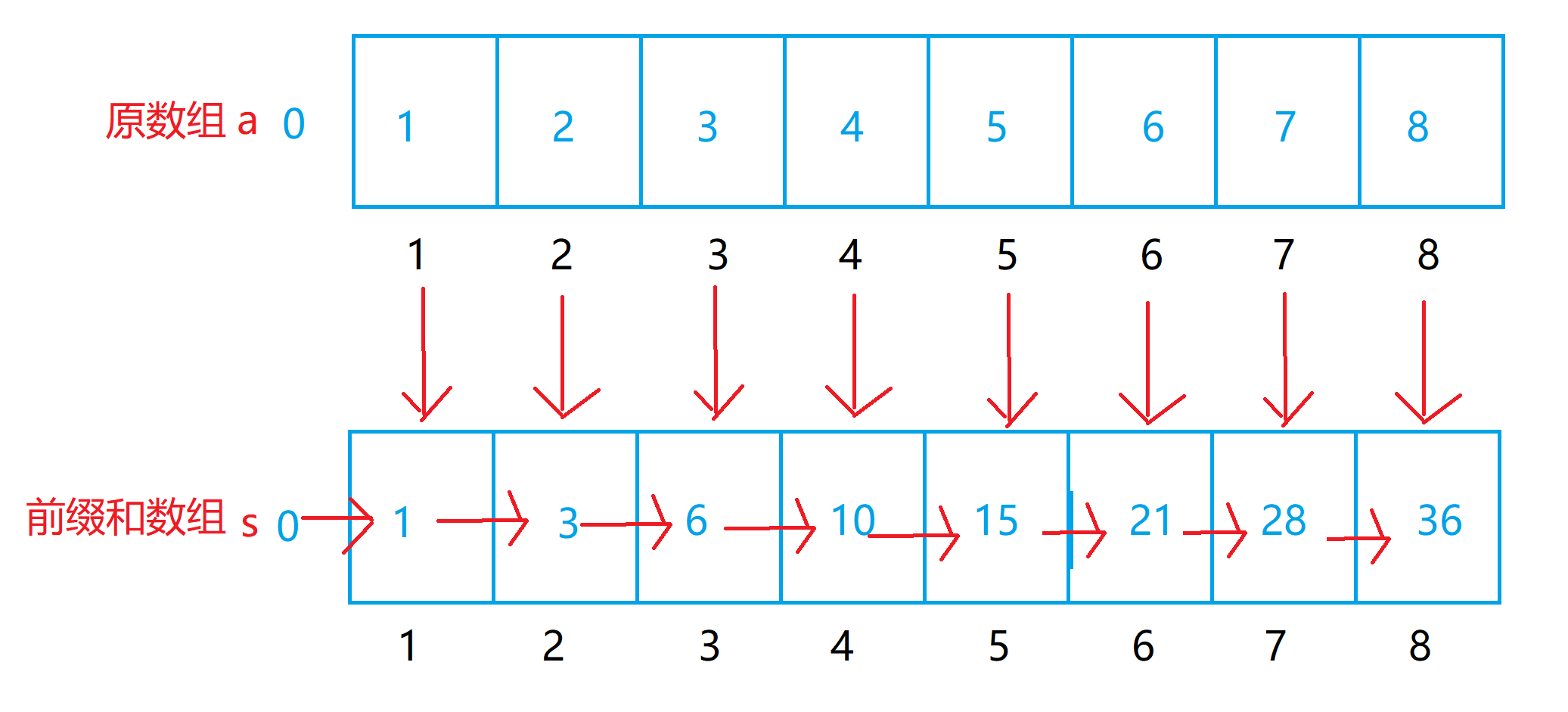
int a[N];// 原数组(N为数组总长度)
int s[N];// 前缀和数组//s[0] = a[0] = 0
//n为数组中的有效数据个数
for(int i = 1;i <= n;i++)
{s[i] = a[i] + s[i-1];// 根据原数组生成成前缀和数组
}//熟练之后,可以直接把原数组变成前缀和数组。
for(int i = 1;i <= n;i++)
{a[i] = a[i] + a[i-1];// 将原数组转化成前缀和数组
}二维前缀和
二维前缀和的定义和一维前缀和数组的定义类似,在二维的前缀和数组中,每一个坐标代表从原数组最开始下标到当前下标所围成的矩形区域所包围的所有元素之和。
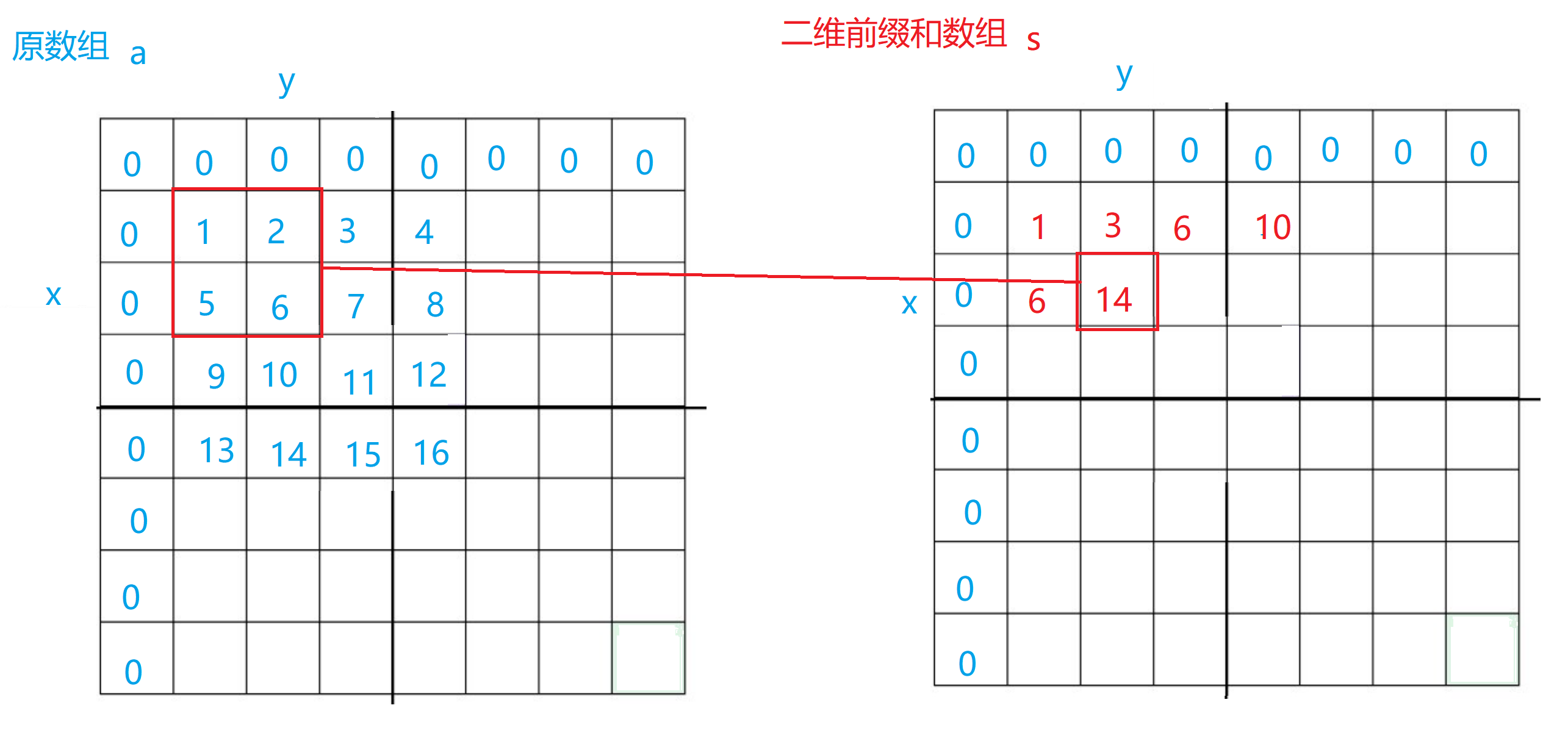
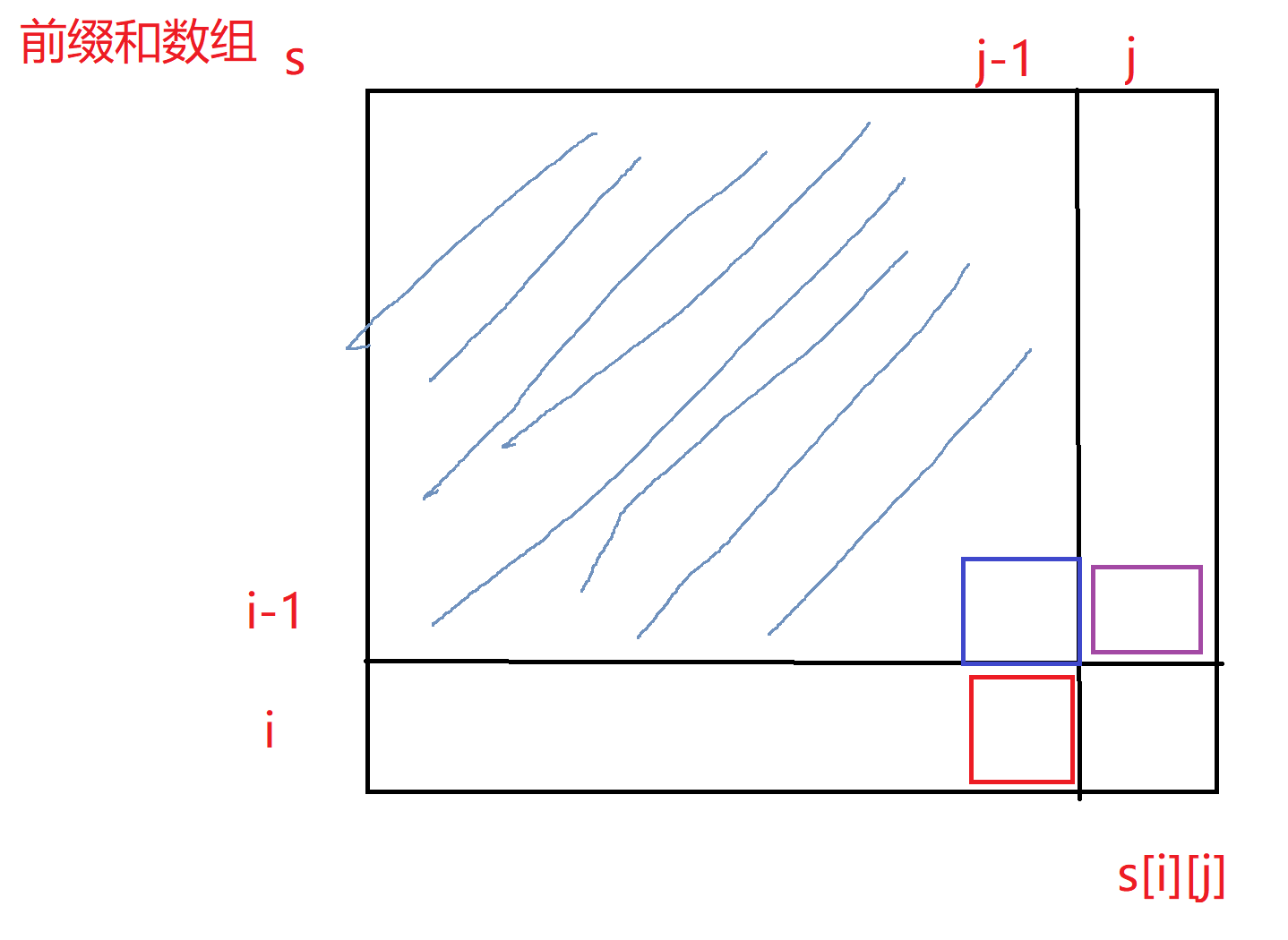
在原数组转化成二维前缀和数组的过程中,我们让 a [ i ] [ j ] 加上 f [ i ] [ j-1 ] 和 f [ i-1 ] [ j ],然后再减去f [ i -1] [ j-1 ],因为 f [ i ] [ j-1 ] 和 f [ i-1 ] [ j ]关于f [ i -1] [ j-1 ]这一部分(图中划线阴影处)的和其实已经重叠了,我们需要减去一份重叠的区域元素和,这样最后才会是正确的结果。
int a[N][N];// 原数组
int s[N][N];// 二维前缀和数组for(int i = 1;i <= n;i++)
{for(int j = 1;j <= n;j++){s[i][j] = a[i][j] + s[i-1][j] + s[i][j-1] - s[i-1][j-1];// 原数组处理成前缀和数组}
}for(int i = 1;i <= n;i++)
{for(int j = 1;j <= n;j++){a[i][j] = a[i][j] + a[i-1][j] + a[i][j-1] - a[i-1][j-1];// 熟练之后可以这样写}
}
差分
差分思想其实本质上和前缀和思想并无区别,只不过这里我们是先有差分数组,然后根据差分数组去生成实际的数组。
一维差分
差分数组中每一个元素对应着原数组对应下标的元素和前一个元素的差。
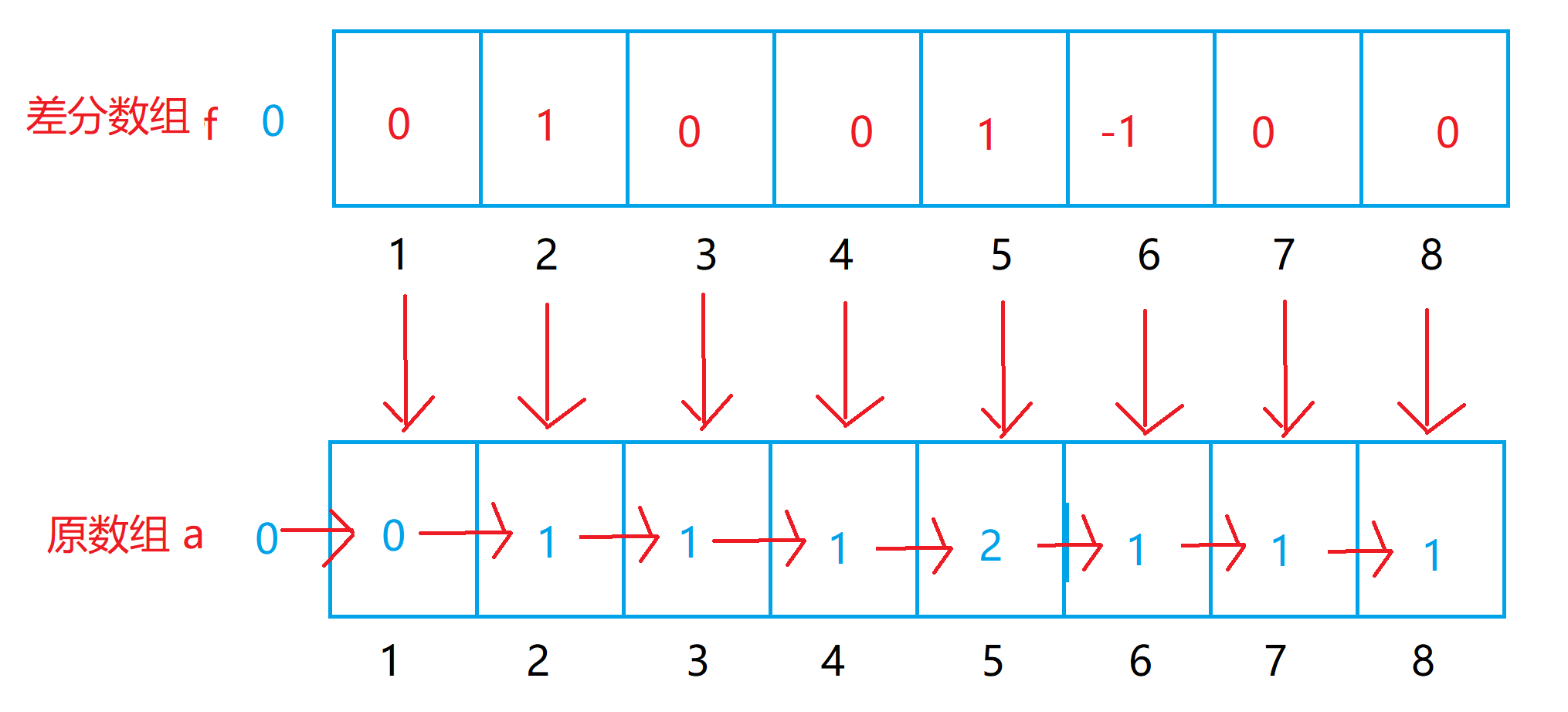
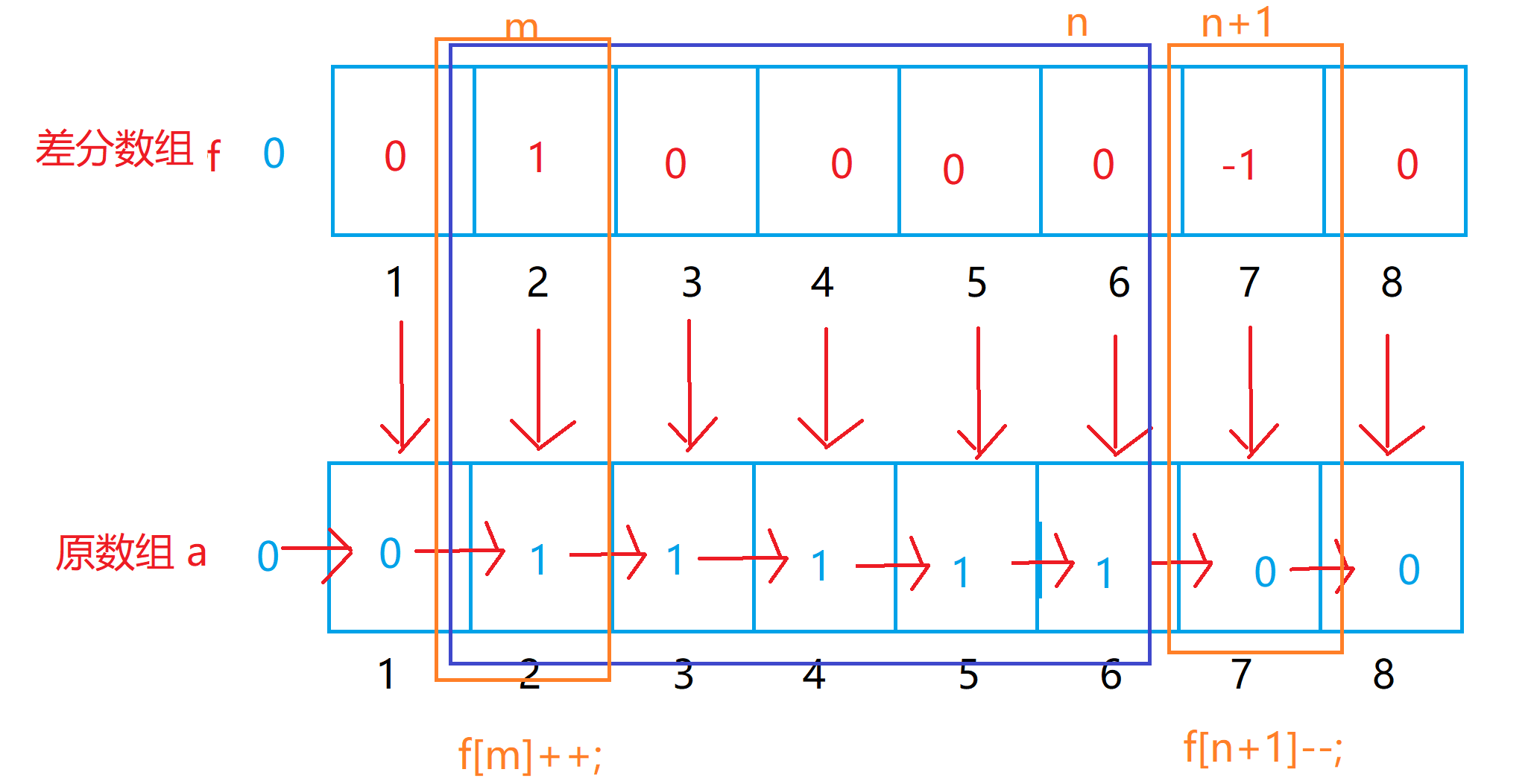
int f[N]; // 差分数组
int a[N]; // 原数组for(int i = 1;i <= n;i++)
{a[i] = a[i-1] + f[i];// 根据差分数组还原成原数组
}for(int i = 1;i <= n;i++)
{f[i] = f[i-1] + f[i];// 熟练之后可以直接这样写
}// 让原数组m到n之间的元素都+K,只需要对差分数组做如下两种操作f[m] += K;f[n+1] -= K; 二维差分
二维差分跟二维前缀和同理,如果我们对差分数组某个下标加上K,那么在原数组中以这个下标为左上角所围成的矩形区域的区间内的元素都加上K。
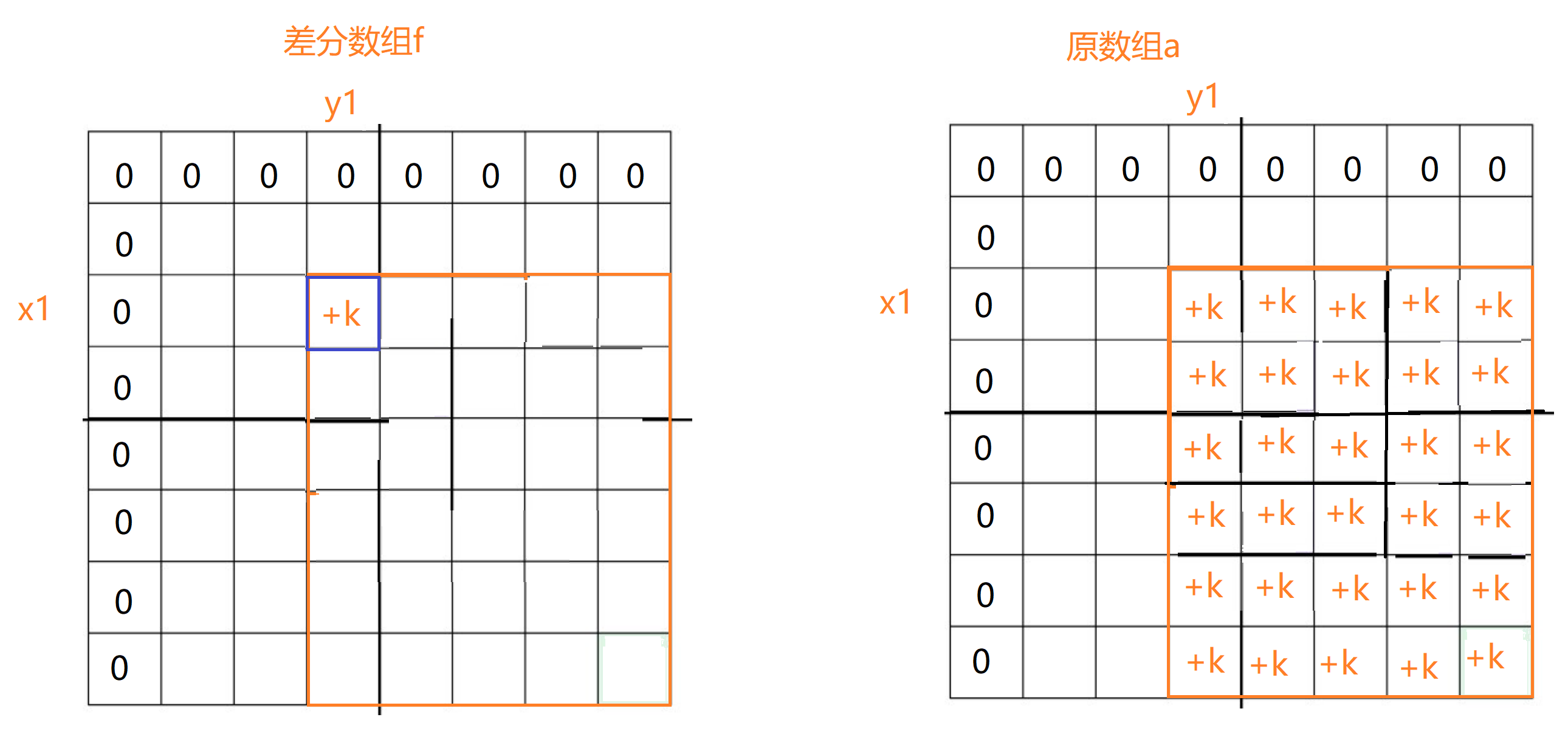
基于此,我们如果要是想让原数组某个区间的元素都加上K的话,对差分数组就可以进行如下操作。
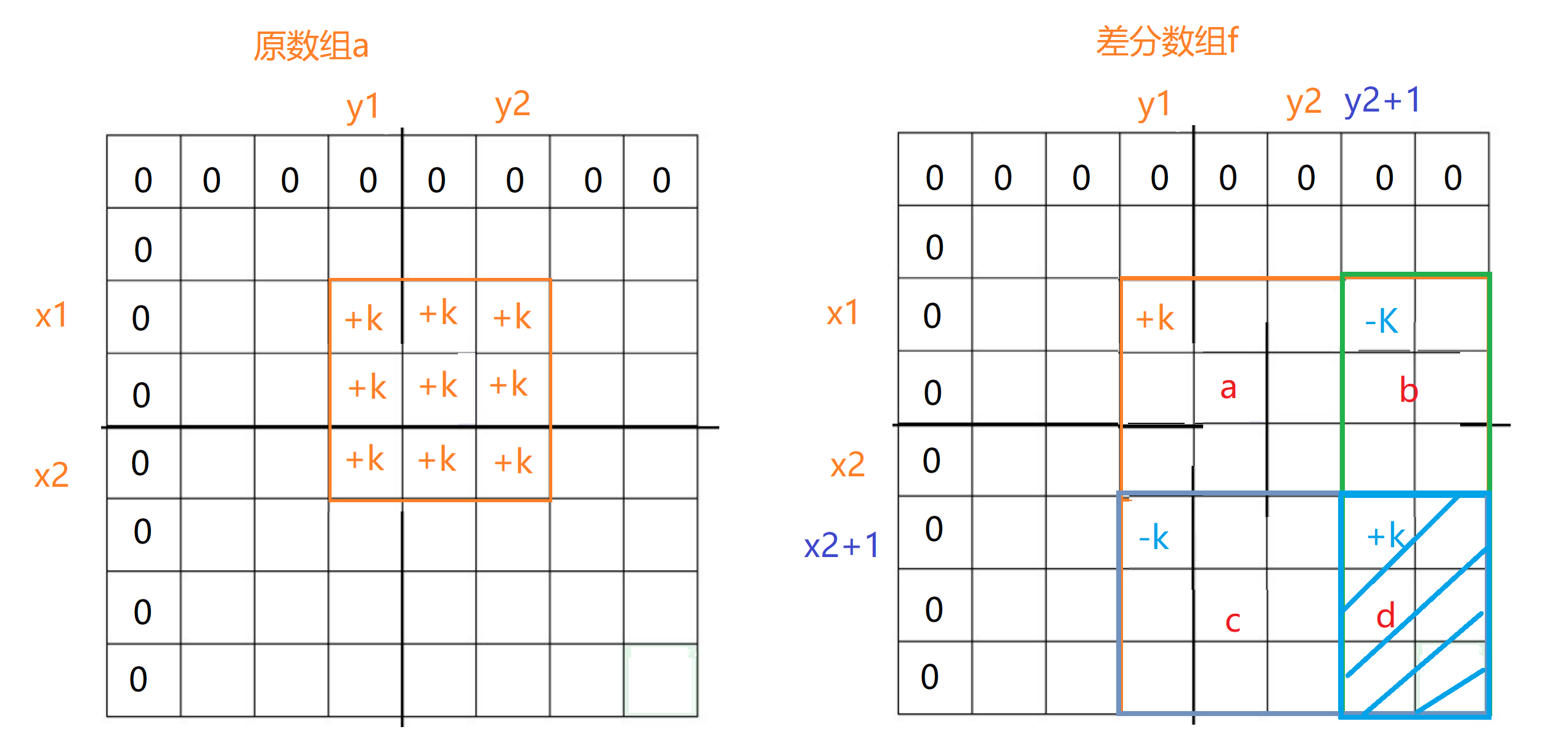
f[x1][y1] += k; // a 部分
f[x2+1][y1] -= k; // b 部分
f[x1][y2+1] -= k; // c 部分
f[x2+1][y2+1] += k; // b和c部分的重叠的d部分
基于二维前缀和数组的特性,我们在差分数组下标为[x1][y1]的位置加K后,原数组只要是横纵坐标均大于x和y的元素都+k,然后再在这个基础上,我们再只要在差分数组的特定位置减去K或者加上K,就可以顺利的只让部分区域的元素+k,具体步骤和代码实现已给出。
双指针(滑动窗口)
- 对于某些算法题目,我们需要用两个指针把有效区间包括进来,最后在计算或者返回有效数据的时候,需要用到双指针,也叫做滑动窗口思想。
- 需要用到滑动窗口思想的题目,一般给出的数据遍历方法或者有效区间的变换都是具有单向性的。
- 左右指针不能回退,当左右指针如果出现回退的情况,就不能用双指针思想去解题了。
- 双指针初始化
- right指针指向元素入窗口
- 判断窗口是否合法
- left指针指向元素出窗口
- 更新判断结构
对于需要用到双指针(滑动窗口)的题目,一般都是以上五步解题,根据题目要求的不同,可能会略有调整,但大体不会发生改变。
二分算法
- 对数据使用二分算法之前,一定要先确保数据范围有序。
- 如果数据无序,我们需要先对数据进行排序。
- 把二分模板记忆正确。
- 有些题目是对数据进行二分,有些题目是根据答案进行二分处理。
- 当需要对答案进行二分的时候,我们首先要发现答案和题目数据之间的关联,发现其二段性,然后我们就可以二分了。
//a:存储有效数据的数组 //key:目标值// 查找目标区间的左端点 while(left < right) {int mid = left + (right - left) // 2;if(key > a[mid]) left = mid + 1;// 位于有效区间内部时,右指针不断往左靠else right = mid; }// 查找目标区间的右端点 while(left < right) {// 查找右端点时,求mid+1int mid = left + (right - left + 1) / 2;// 位于有效区间内部时,左指针不断往右靠if(key >= a[mid]) left = mid;else right = mid - 1; }
贪心
贪心的策略就是根据题目要求,把每一步都做到最优,然后最后做到全体最优。
- 注意在想出贪心策略的时候,不要着急去敲代码,如果在时间有限的情况下,尽量先用极端情况去证明一下自己的贪心思想。
哈夫曼编码
哈夫曼编码也利用的是贪心的算法去实现的一个经典的编码思想,具体讲解见下面的文章。
哈夫曼树与哈夫曼算法![]() https://blog.csdn.net/2502_90265864/article/details/153660697?spm=1001.2014.3001.5501
https://blog.csdn.net/2502_90265864/article/details/153660697?spm=1001.2014.3001.5501
区间问题
在很多贪心算法中,我们会遇到一些区间问题,对于这些不同的区间,我们要对其进行特殊的排序。
- 根据题目要求,判断怎么排序才能解决问题(按左端点排序还是右端点?按升序还是降序?)
- 注意有些题目是允许区间重叠的,有些题目是不允许区间重叠的,针对这一点我们要注意。
倍增思想
倍增的思想就是不断的对数据进行翻倍,能够把线性的计算处理,最后优化成指数级的时间复杂度。
模板题目
P1226 【模板】快速幂 - 洛谷

我们如果要求a的b次方的话,我们可以把b转化为二进制,然后根据位于二进制表示下的不同位的0和1,把a的倍增幂计入结果,利用二进制的思想,我们通过把a的b次方转化a的偶数次幂的乘积和,通过倍增幂数的运算,省去冗余的运算时间,提高了效率,把时间从O(n)优化到了O(lgn)的指数级别。
模板代码
// 求a的b次方对P取模的结果
LL qpow(LL a,LL b,LL p)
{LL ret = 1;while(b){// 如果b的二进制表示对位为1,则计入有效结果;否则,不执行语句。if(b & 1) ret = ret * a % p;a = a * a % p;b >>= 1;}return ret;
}取模运算的规则
如果计算过程只出现乘法和加法,那么就算在计算过程中取模运算,也不会对最后的结果产生影响。
如果计算过程中出现减法,如果在计算过程中直接取模,结果是有可能出现负数的,我们要在取模时进行“补正”。
- 如果计算过程中如果出现除法,再进行取模运算的话就会出现错误。
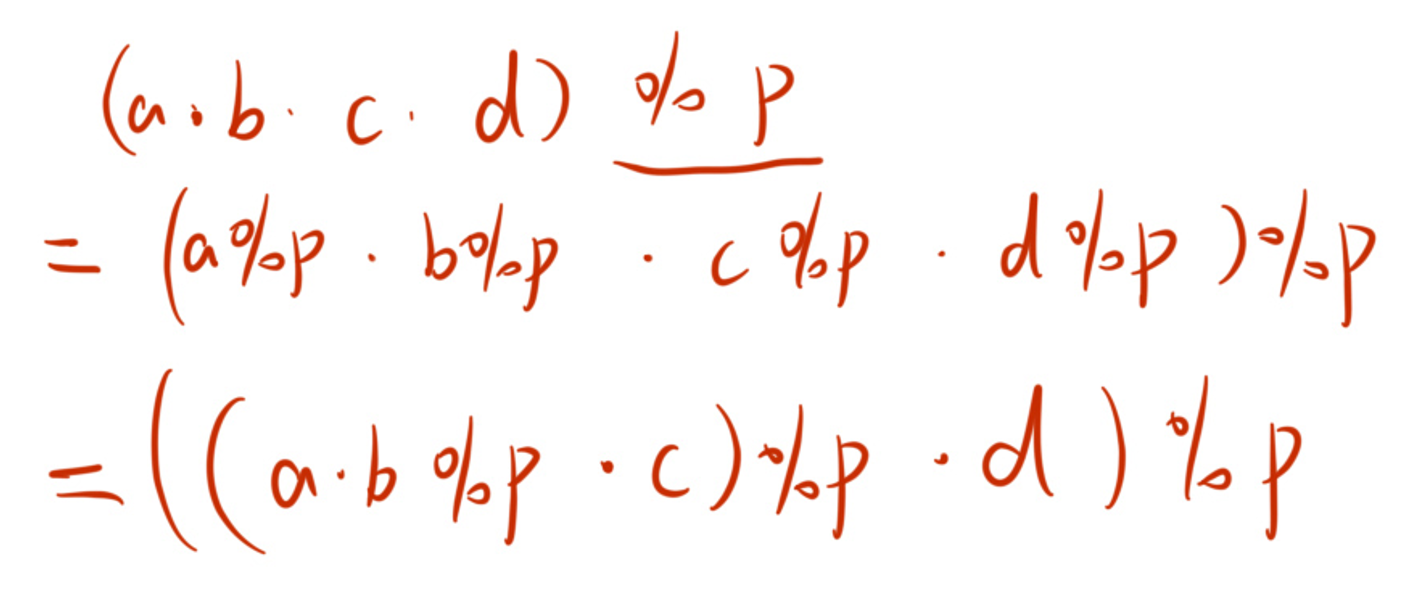
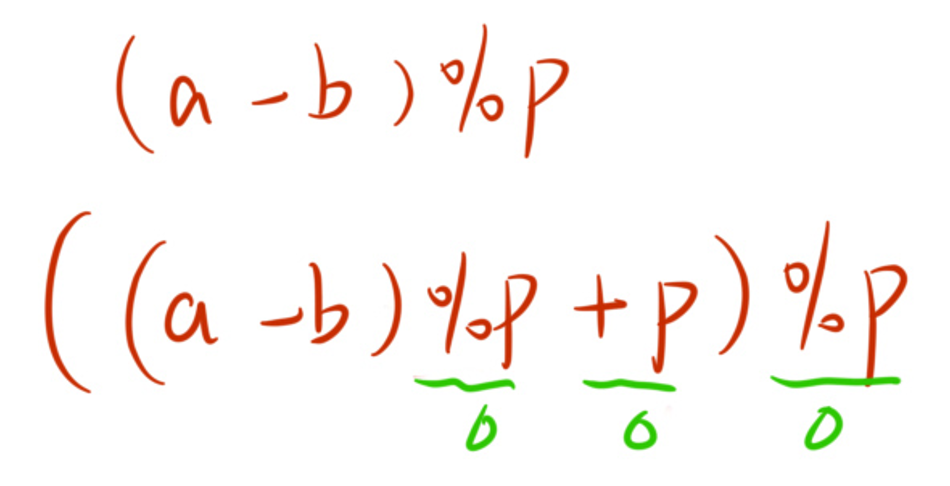
离散化
离散化的思想类似于哈希表,我们需要用一些数值范围比较大但是数据个数比较小的数据对应的值来映射到数组的下标时,我们就需要用到离散化的思想,例如{3,6,8,9}进行离散化之后就是{1,2,3,4}。
// 离散化⽅式⼆:排序 + STL
// 借助 STL,去重以及查找更⽅便
#include <iostream>
#include <unordered_map>
#include <algorithm>using namespace std;const int N = 1e5 + 10;int n;
int a[N]; // 原始数据
int tmp[N]; // ⽤来排序的数组int cnt;
unordered_map<int, int> id; // 记录离散化之后的值int main()
{cin >> n;for(int i = 1; i <= n; i++){int x; cin >> x;a[i] = x;tmp[i] = x; // 数据放进离散化数组中}// 离散化:排序 + 放进哈希表中sort(tmp+ 1, tmp + 1 + n);for(int i = 1; i <= n; i++){if(id.count(tmp[i])) continue; // 如果已经存过这个数,不做处理cnt++; // 这个数映射之后的值id[tmp[i]] = cnt; // 放进哈希表中}// 找到离散化之后的值for(int i = 1; i <= n; i++){int x = a[i];cout << x << "离散化之后是: " << id[a[i]] << endl; // ⼆分查找离散化之后的值}return 0;
}递归
当我们在遇到重复处理子问题的算法时,就可以考虑用递归去解决。
- 先找到需要处理的重复子问题,确认函数的功能及函数头的设计。
- 要设置递归出口,不然程序会报错 。
- 在书写函数体的时候,只专心处理好一个子问题,其他的地方交给递归去解决。
- 把递归函数体里面的递归想象成一个黑盒子,相信他一定能够帮你处理好子问题。(从宏观角度去看递归)
归并排序
#include<iostream>using namespace std;const int N = 1e5 + 10;typedef long long LL;LL a[N];int n;int temp[N];void merge_sort(int left,int right)
{if(left >= right) return;//首先把数组一分为二 int mid = left + (right - left)/2;//让左右数组有序 merge_sort(left,mid);merge_sort(mid+1,right);int cur1 = left;int cur2 = mid+1;int i = left;// 逐个按数值大小往临时数组存储(相当于左右数组一起排序后存储到临时数组)while(cur1 <= mid && cur2 <= right){if(a[cur1] <= a[cur2]) temp[i++] = a[cur1++];else temp[i++] = a[cur2++];}// 处理左右数组其中未排序的元素while(cur1 <= mid) temp[i++] = a[cur1++];while(cur2 <= right) temp[i++] = a[cur2++];// 把排序好的临时数组返回到原数组中for(int j = left;j <= right;j++){a[j] = temp[j];}
}int main()
{cin >> n;for(int i = 1;i <= n;i++){cin >> a[i];}merge_sort(1,n);for(int i = 1;i <= n;i++){cout << a[i] << ' ';}return 0;} 分治
分治,字⾯上的解释是「分⽽治之」,就是把⼀个复杂的问题分成两个或更多的相同或相似的⼦问题,直到最后⼦问题可以简单的直接求解,原问题的解即⼦问题的解的合并,分治的本质也是重复处理子问题,所以和递归思想是比较相似的。
快速排序
#include<iostream>
#include<ctime>
using namespace std;const int N = 1e5+10;typedef long long LL;int a[N];int get_random(int left,int right)
{return a[rand() % (right - left + 1) + left];
}void quick_sort(int left,int right)
{if(left >= right) return;//优化1:取随机基准值优化时间复杂度到O(N*lgN)级别 int p = get_random(left,right);// [left,l]:小于p的值(左区间)
// [l+1,i-1]:基准值p(中间区域)
// i:正在扫描的元素
// [i+1,r-1]:待扫描区域
// [r,right]:大于p的值(右区间)//优化2:分三段区间处理问题int l = left - 1;int r = right + 1;int i = left;while(i < r){// 如果a[i]小于基准值 p,i指向元素存放到左区间// 相当于交换a[l+1]和a[i],然后l和i都++ if(a[i] < p) swap(a[++l],a[i++]); // 如果a[i]等于基准值 p,i直接++(相当于把i所指向的区间归纳到基准值区)else if(a[i] == p) i++; // 如果a[i] 大于基准值 p,i指向元素存放到右区间 // 相当于交换a[l+1]和a[i],然后l(这里的i不++,因为r-1对应的元素是待扫描区域,我们需要再对着元素进行扫描)else swap(a[--r],a[i]);} // 三个区间 // [left,l] // 左区间 // [l+1,r-1] // [r,right] // 右区间 quick_sort(left,l); // 处理左区间 quick_sort(r,right); // 处理右区间
}int main()
{// 刷新随机函数的种子,防止生成的随机数重复。 srand(time(0));int n; cin >> n;for(int i = 1;i <= n;i++) cin >> a[i];quick_sort(1,n);for(int i = 1;i <= n;i++) cout << a[i] << ' ';return 0;
} 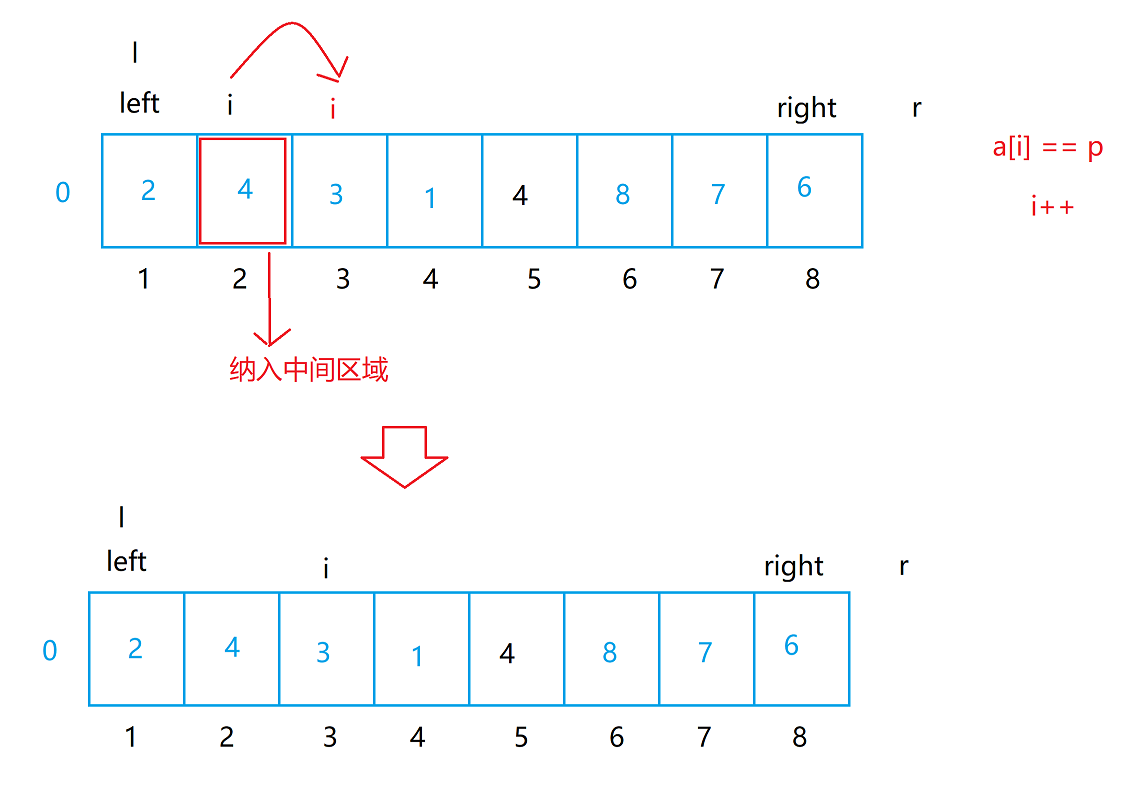
a[i] == p的情况
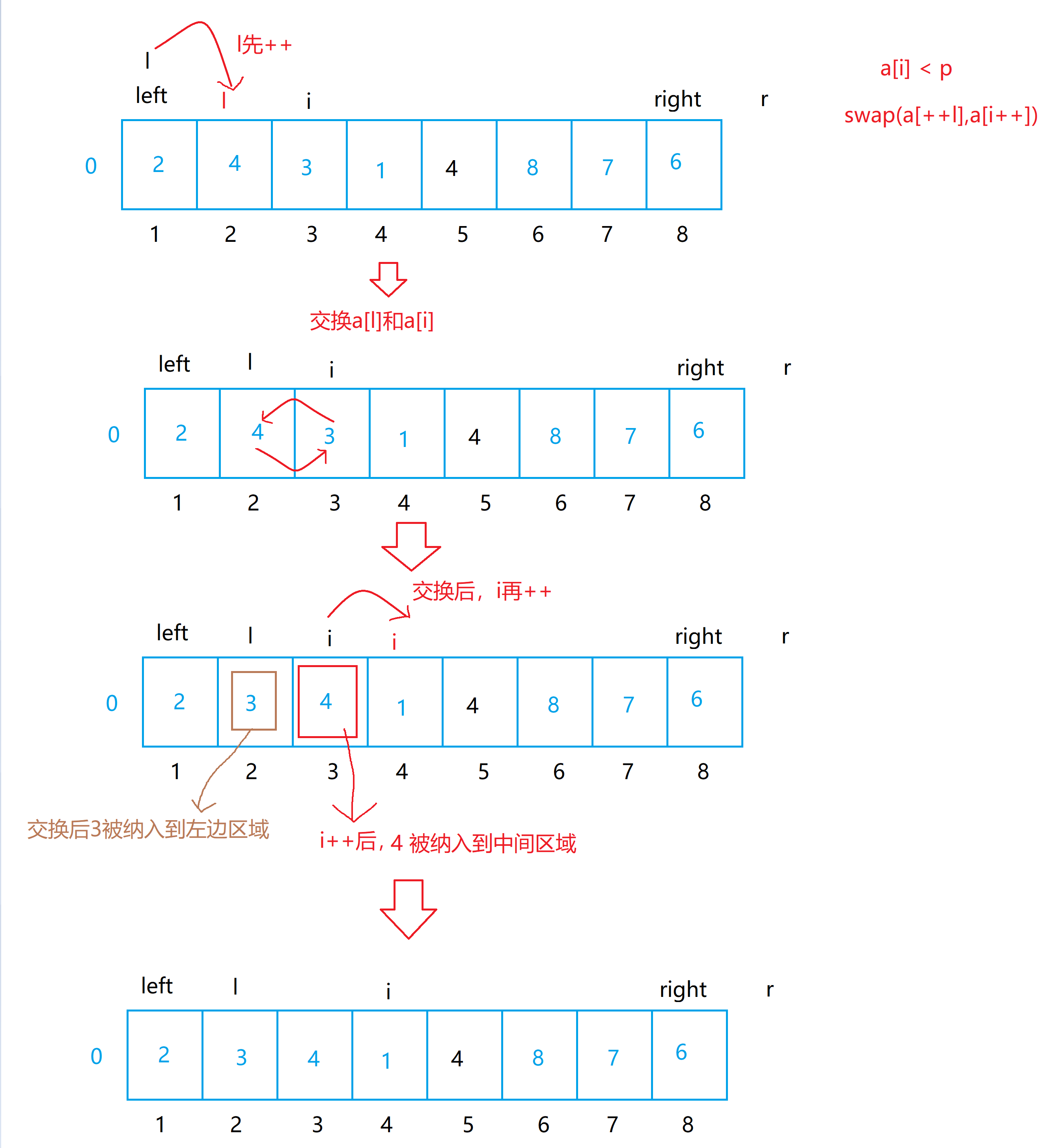
a[i] < p
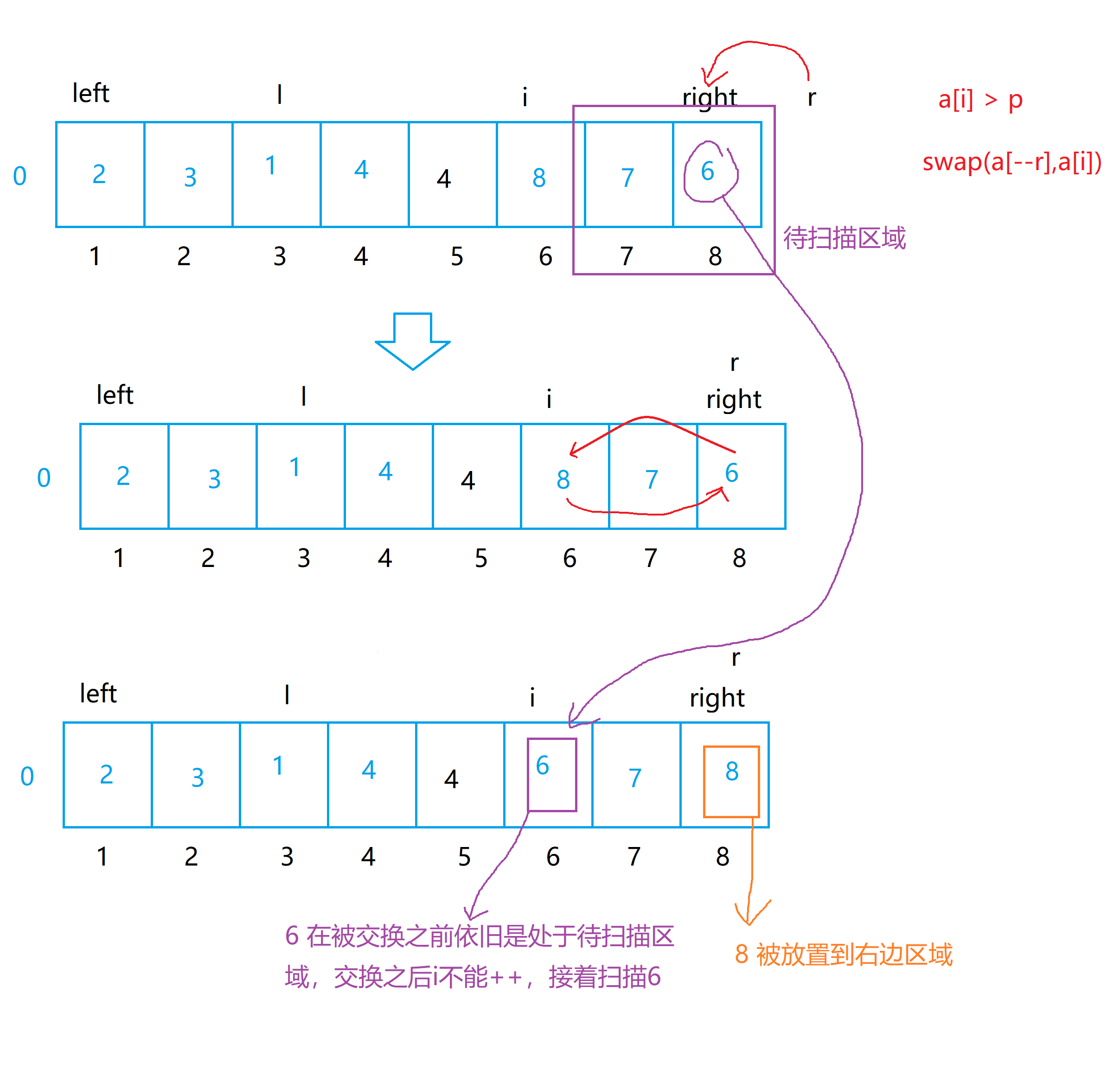
a[i] > p
这份基础算法总结希望能为读者提供切实的帮助。