在 Hadoop 生态使用 JuiceFS,并为Hive提供HDFS存储安装指南
文章目录
- 1.介绍
- 1.1 什么是Hadoop?
- 1.2 为什么不用Hadoop HDFS?
- 1.3 什么是Hive?
- 1.4 Hive架构
- 1.5 JuiceFS取代原生Hadoop HDFS
- 2.部署准备
- 2.1 MinIO和JuiceFS安装
- 2.2 自定义镜像
- 2.3 Hadoop Config
- 3 部署方式
- 3.2 docker run方式
- 3.2 docker-compose 方式
- 3.3 k8s方式
- 4 环境验证
- 4.1 Hadoop CLI
- 4.2 Hive CLI
- 4.3 DBeaver验证
JuiceFS 提供与 HDFS 接口高度兼容的 Java 客户端,Hadoop 生态中的各种应用都可以在不改变代码的情况下,平滑地使用 JuiceFS 存储数据。
1.介绍
1.1 什么是Hadoop?
https://aws.amazon.com/cn/what-is/hadoop/
https://cloud.google.com/learn/what-is-hadoop?hl=zh-CN
Apache Hadoop 是一种开源框架,用于高效存储和处理从 GB 级到 PB 级的大型数据集。利用 Hadoop,您可以将多台计算机组成集群以便更快地并行分析海量数据集,而不是使用一台大型计算机来存储和处理数据。
Hadoop 是基于 Java 的开源框架,可为应用管理大量数据的存储和处理。Hadoop 使用分布式存储和并行处理来处理大数据和分析作业,将工作负载分解为可同时运行的较小工作负载。
Hadoop 框架主要由四个模块组成,这四个模块协同运行以形成 Hadoop 生态系统:
Hadoop 分布式文件系统 (HDFS):作为 Hadoop 生态系统的主要组成部分,HDFS 是一个分布式文件系统,在该系统中,各个 Hadoop 节点都对其本地存储空间中的数据执行操作。这样可以消除网络延迟,实现对应用数据的高吞吐量访问。此外,管理员无需预先定义架构。
Yet Another Resource Negotiator (YARN):YARN 是一个资源管理平台,负责管理集群中的计算资源并使用它们来调度用户的应用。它在整个 Hadoop 系统上执行调度和资源分配。
MapReduce:MapReduce 是一个用于大规模数据处理的编程模型。在 MapReduce 模型中,较大数据集的子集和处理子集的指令会被分派到多个不同的节点,其中每个子集都由一个节点与其他处理作业并行处理。处理结果后,各个子集会合并到一个更小、更易于管理的数据集中。
Hadoop Common:Hadoop Common 包括其他Hadoop 模块使用和共享的库和实用程序。
除了 HDFS、YARN 和 MapReduce 以外,整个 Hadoop 开源生态系统仍在不断发展,其中包括许多可帮助收集、存储、处理、分析和管理大数据的工具和应用。例如 Apache Pig、Apache Hive、Apache HBase、Apache Spark、Presto 和 Apache Zeppelin。
1.2 为什么不用Hadoop HDFS?
- 不适合小文件存储,元数据管理压力大,即使文件只有 1KB,也会占用一个完整的数据块(如 128MB),磁盘利用率极低
- NameNode 存在单点故障风险
- JuiceFS可以解决上述问题

1.3 什么是Hive?
https://aws.amazon.com/cn/what-is/apache-hive/
Apache Hive 是可实现大规模分析的分布式容错数据仓库系统。该数据仓库集中存储信息,您可以轻松对此类信息进行分析,从而做出明智的数据驱动决策。Hive 让用户可以利用 SQL 读取、写入和管理 PB 级数据。
Hive 建立在 Apache Hadoop 基础之上,后者是一种开源框架,可被用于高效存储与处理大型数据集。因此,Hive 与 Hadoop 紧密集成,其设计可快速对 PB 级数据进行操作。Hive 的与众不同之处在于它可以利用 Apache Tez 或 MapReduce 通过类似于 SQL 的界面查询大型数据集。
1.4 Hive架构
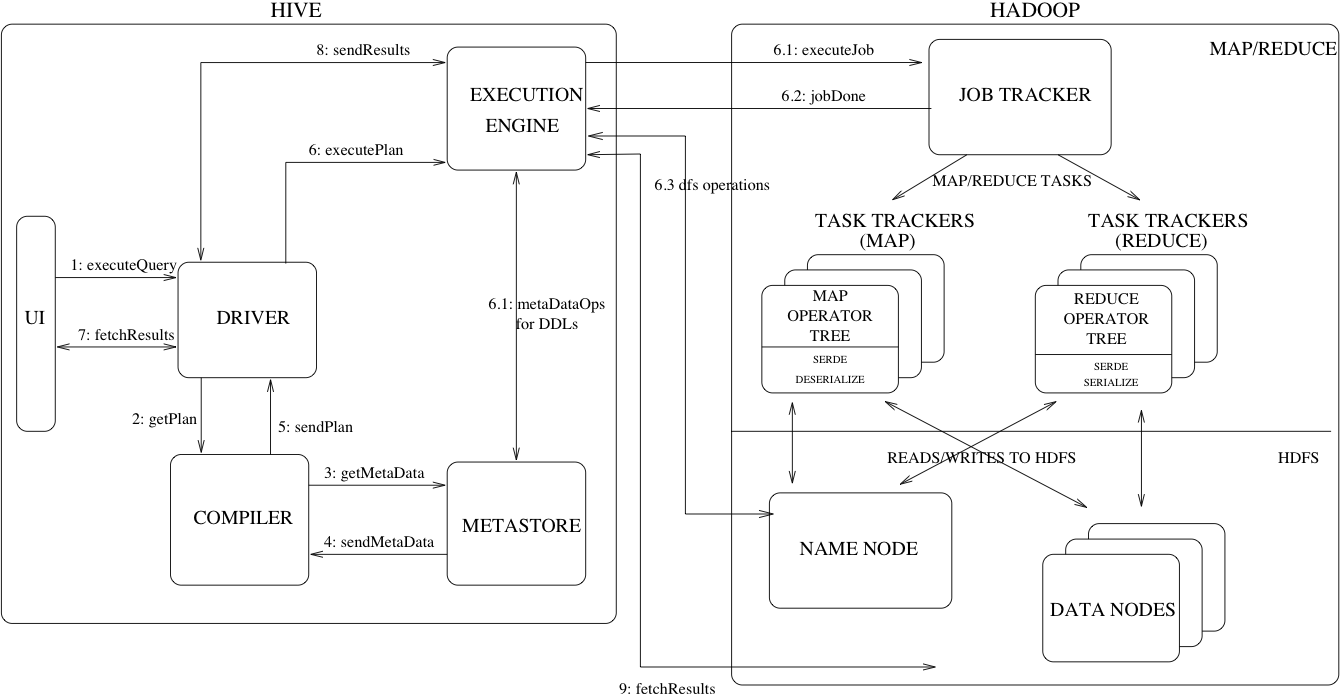
展示了 Hive 的主要组件及其与 Hadoop 的交互。如图所示,Hive 的主要组件包括:
UI——用户通过该界面向系统提交查询和其他操作。截至2011年,该系统采用命令行界面,同时正在开发基于Web的图形用户界面(GUI)。
驱动程序——接收查询的组件。该组件实现了会话句柄的概念,并提供基于 JDBC/ODBC 接口的执行和获取 API。
编译器 – 该组件解析查询,对不同的查询块和查询表达式进行语义分析,并最终借助从元数据存储中查找的表和分区元数据生成执行计划。
Metastore – 该组件存储仓库中各种表和分区的所有结构信息,包括列和列类型信息、读取和写入数据所需的序列化器和反序列化器以及存储数据的相应 HDFS 文件。
执行引擎——负责执行编译器生成的执行计划的组件。该计划是一个包含多个阶段的有向无环图(DAG)。执行引擎管理计划中各个阶段之间的依赖关系,并在相应的系统组件上执行这些阶段。
1.5 JuiceFS取代原生Hadoop HDFS
Hadoop部分我们使用JuiceFS的Hadoop Client
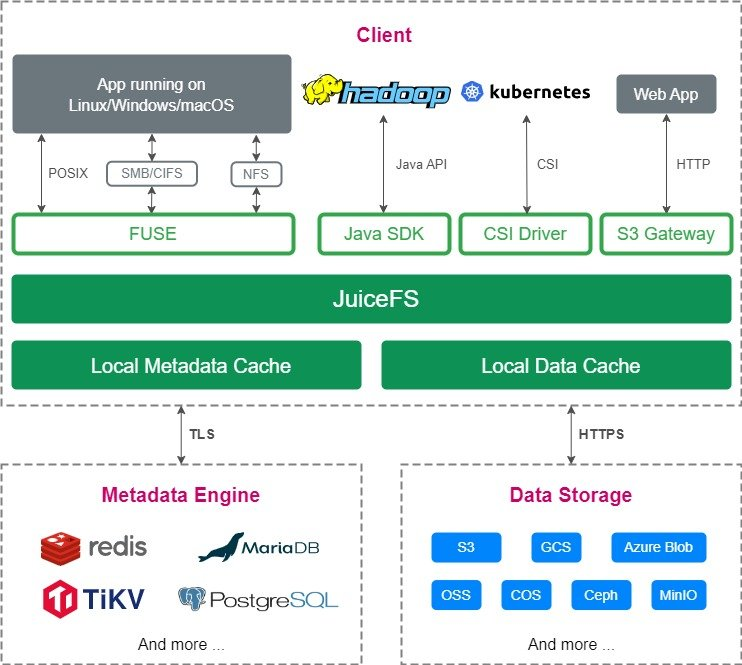
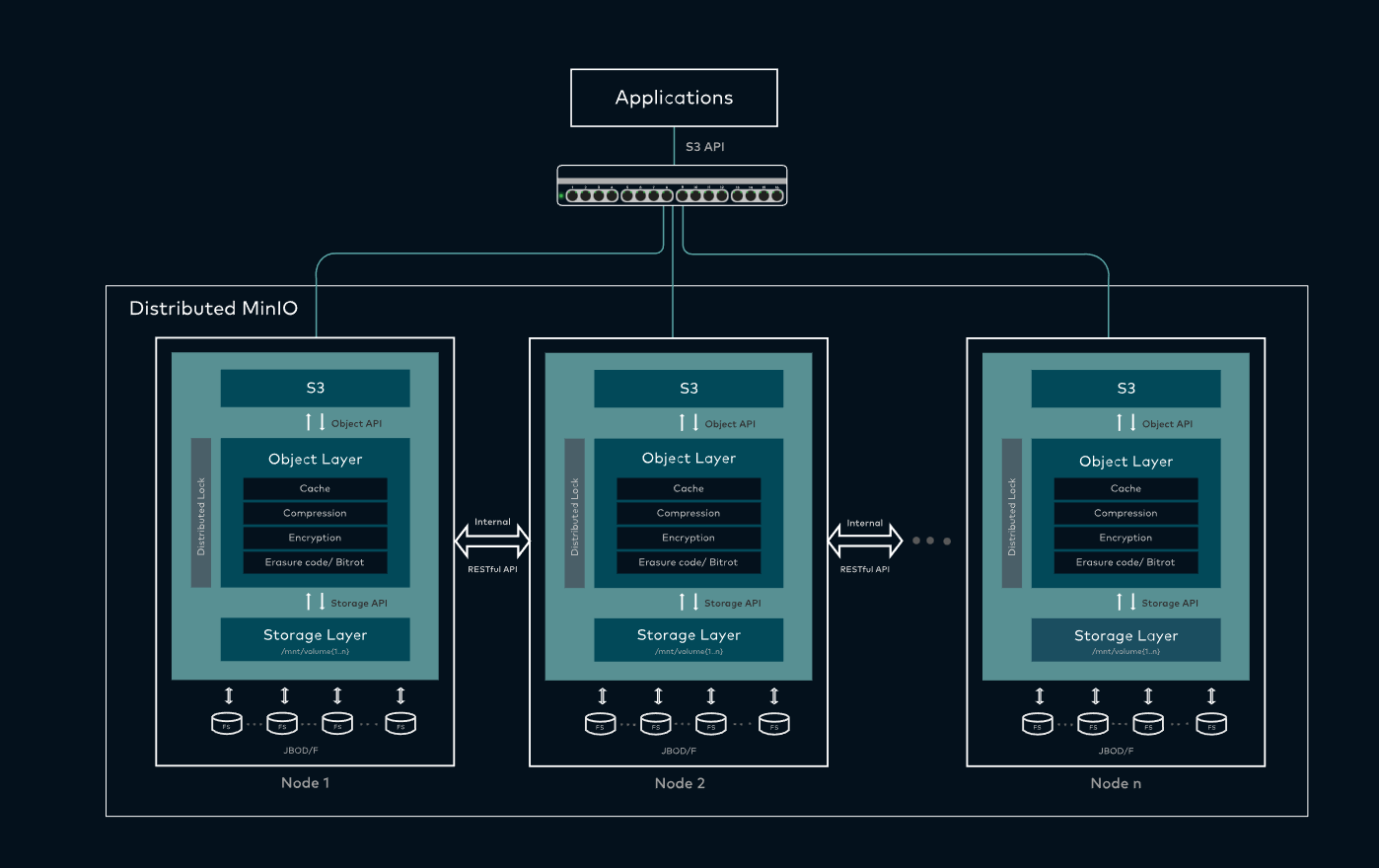
Data Storage部分,我们使用MinIO
总结:
JuiceFS 客户端(Client):Hadoop、k8s CSI 驱动
元数据引擎(Metadata Engine):Redis
数据存储(Data Storage):MinIO
2.部署准备
2.1 MinIO和JuiceFS安装
MinIO安装参见之前我的博文:在Linux Debian和k8s上部署MinIO集群中
JuiceFS安装参见之前我的博文:JuiceFS为K8s提供CSI存储安装指南
juicefs format \--storage s3 \--bucket http://@pve-node5:9000/jfs-public \--access-key CzrsezeekHXSEbsGh4q7 \--secret-key qxvUp3Bae9hR8s3gR5XJUc0ZZn5Rx2EwIRnRiK7j \redis://:redis_P6B5Pb@xxx:6379/12 \jfs-public
2.2 自定义镜像
加入juicefs-hadoop.jar和postgresql.jar
# https://hub.docker.com/r/apache/hive
FROM apache/hive:4.1.0# https://github.com/juicedata/juicefs/releases
RUN wget https://github.com/juicedata/juicefs/releases/download/v1.2.4/juicefs-hadoop-1.2.4.jar -O /tmp/juicefs-hadoop.jar
# https://mvnrepository.com/artifact/org.postgresql/postgresql
RUN wget https://repo1.maven.org/maven2/org/postgresql/postgresql/42.7.8/postgresql-42.7.8.jar -O /tmp/postgresql.jarUSER root
# https://juicefs.com/docs/zh/community/hadoop_java_sdk/#%E7%A4%BE%E5%8C%BA%E5%BC%80%E6%BA%90%E7%BB%84%E4%BB%B6
RUN mv /tmp/juicefs-hadoop.jar /opt/hadoop/share/hadoop/common/lib/
RUN mv /tmp/postgresql.jar /opt/hive/lib/USER hive
构建镜像
LATEST_TAG=4.2.0
docker build --build-arg LATEST_TAG=$LATEST_TAG -t duhongming/hive:$LATEST_TAG .
# 推送到官网镜像
docker push duhongming/hive:$LATEST_TAG
# 推送到阿里镜像
docker tag duhongming/hive:$LATEST_TAG registry.cn-hangzhou.aliyuncs.com/dockerdance/hive:$LATEST_TAG
docker push registry.cn-hangzhou.aliyuncs.com/dockerdance/hive:$LATEST_TAG
大家可使用我的镜像:
国外:duhongming/hive:4.2.0
国内:registry.cn-hangzhou.aliyuncs.com/dockerdance/hive:4.2.0
2.3 Hadoop Config
core-site.xml配置示例
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--https://juicefs.com/docs/zh/community/hadoop_java_sdk#%E9%85%8D%E7%BD%AE%E7%A4%BA%E4%BE%8B-->
<configuration><property><name>fs.jfs.impl</name><value>io.juicefs.JuiceFileSystem</value></property><property><name>fs.AbstractFileSystem.jfs.impl</name><value>io.juicefs.JuiceFS</value></property><property><name>juicefs.meta</name><value>redis://:redis_P6B5Pb@xxx:6379/12</value></property><property><name>juicefs.cache-dir</name><value>/data*/jfs</value></property><property><name>juicefs.cache-size</name><value>1024</value></property><property><name>juicefs.access-log</name><value>/tmp/juicefs.access.log</value></property>
</configuration>
3 部署方式
3.2 docker run方式
其中SERVICE_NAME,metastore 负责管理 Hive 元数据,hiveserver2 负责提供客户端接入和 SQL 执行服务,二者是 Hive 架构中功能完全不同的核心组件。
| 对比维度 | Metastore | HiveServer2 |
|---|---|---|
| 作用定位 | 元数据 “管家”,管理 Hive 的元数据 | 客户端 “网关”,提供 Hive 远程访问能力 |
| 核心功能 | 1. 存储表名、字段、分区、数据存储路径等元数据;2. 提供元数据读写接口,供 Hive CLI、Spark 等组件调用 | 1. 接收客户端(JDBC/ODBC 等)的 SQL 请求;2. 解析、优化 SQL 并提交执行;3. 返回执行结果;4. 支持多客户端并发连接和权限控制 |
| 通信协议 | 内部使用 Thrift 协议(默认) | 支持 JDBC、ODBC、Thrift 等协议 |
| 依赖关系 | 依赖元数据库( Derby/MySQL 等) | 依赖 Metastore(执行 SQL 需读取元数据)、HDFS/YARN(存储数据、执行计算) |
| 客户端对接方式 | 不直接对接用户,供其他组件调用 | 直接对接用户 / 应用(如 Beeline、Java 程序、Superset 等) |
docker run -d -p 9083:9083 \
--env SERVICE_NAME=metastore \
--env DB_DRIVER=postgres \
--env SERVICE_OPTS="-Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver -Djavax.jdo.option.ConnectionURL=jdbc:postgresql://xxx:5432/metastore_db -Djavax.jdo.option.ConnectionUserName=metastore_db -Djavax.jdo.option.ConnectionPassword=wERzMdYPyf6rFfah" \
-v ./core-site.xml:/opt/hadoop/etc/hadoop/core-site.xml \
--name hive-metastore duhongming/hive:4.2.0
docker run -d -p 10000:10000 -p 10002:10002 \
--env SERVICE_NAME=hiveserver2 \
--env SERVICE_OPTS="-Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver -Djavax.jdo.option.ConnectionURL=jdbc:postgresql://xxx:5432/metastore_db -Djavax.jdo.option.ConnectionUserName=metastore_db -Djavax.jdo.option.ConnectionPassword=wERzMdYPyf6rFfah" \
--mount source=warehouse,target=/opt/hive/data/warehouse \
-v ./core-site.xml:/opt/hadoop/etc/hadoop/core-site.xml \
--name hive-server2 duhongming/hive:4.2.0
3.2 docker-compose 方式
docker compose -p hive up -d
services:metastore-standalone:image: duhongming/hive:4.2.0environment:SERVICE_NAME: metastoreDB_DRIVER: postgresSERVICE_OPTS: >--Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver-Djavax.jdo.option.ConnectionURL=jdbc:postgresql://xxx:5432/metastore_db-Djavax.jdo.option.ConnectionUserName=metastore_db-Djavax.jdo.option.ConnectionPassword=wERzMdYPyf6rFfahvolumes:- ./core-site.xml:/opt/hadoop/etc/hadoop/core-site.xmlports:- 9083:9083hiveserver2-standalone:image: duhongming/hive:4.2.0depends_on:- metastore-standaloneenvironment:SERVICE_NAME: hiveserver2IS_RESUME: trueSERVICE_OPTS: >--Dhive.metastore.uris=thrift://metastore-standalone:9083volumes:- ./core-site.xml:/opt/hadoop/etc/hadoop/core-site.xmlports:- 10000:10000- 10002:10002
3.3 k8s方式
---
# 2. Hive 数据仓库持久化卷声明(对应 docker run 的 warehouse 卷)
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: hive-warehouse
spec:accessModes:- ReadWriteOnceresources:requests:storage: 20Gi # 根据需求调整存储大小
---
# 3. Core-site.xml 配置文件 ConfigMap(对应 -v ./core-site.xml 挂载)
apiVersion: v1
kind: ConfigMap
metadata:name: hive-config
data:core-site.xml: |<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--https://juicefs.com/docs/zh/community/hadoop_java_sdk#%E9%85%8D%E7%BD%AE%E7%A4%BA%E4%BE%8B--><configuration><property><name>fs.jfs.impl</name><value>io.juicefs.JuiceFileSystem</value></property><property><name>fs.AbstractFileSystem.jfs.impl</name><value>io.juicefs.JuiceFS</value></property><property><name>juicefs.meta</name><value>redis://:redis_P6B5Pb@xxx:6379/12</value></property><property><name>juicefs.cache-dir</name><value>/data*/jfs</value></property><property><name>juicefs.cache-size</name><value>1024</value></property><property><name>juicefs.access-log</name><value>/tmp/juicefs.access.log</value></property></configuration>
---# 5. Hive Metastore 部署及服务(对应 metastore)
apiVersion: apps/v1
kind: Deployment
metadata:name: metastore
spec:replicas: 1selector:matchLabels:app: metastoretemplate:metadata:labels:app: metastorespec:containers:- name: metastoreimage: duhongming/hive:4.1.0env:- name: SERVICE_NAMEvalue: "metastore"- name: DB_DRIVERvalue: "postgres"# 在 metastore-standalone 的 Deployment.spec.template.spec.containers.env 中添加- name: METASTORE_PORTvalue: "9083" # 仅保留端口号,不要带协议和 IP- name: SERVICE_OPTSvalue: >--Djavax.jdo.option.ConnectionDriverName=org.postgresql.Driver -Djavax.jdo.option.ConnectionURL=jdbc:postgresql://xxx:5432/metastore_db -Djavax.jdo.option.ConnectionUserName=metastore_db -Djavax.jdo.option.ConnectionPassword=wERzMdYPyf6rFfahports:- containerPort: 9083 # Metastore 默认端口volumeMounts:- name: core-site # 挂载 core-site.xml(对应 -v ./core-site.xml)mountPath: /opt/hadoop/etc/hadoop/core-site.xmlsubPath: core-site.xmlvolumes:- name: core-siteconfigMap:name: hive-config # 引用前面定义的 ConfigMap
---
apiVersion: v1
kind: Service
metadata:name: metastore
spec:selector:app: metastoreports:- port: 9083targetPort: 9083
---
# 6. HiveServer2 部署及服务(对应 hiveserver2 及 docker run 配置)
apiVersion: apps/v1
kind: Deployment
metadata:name: hiveserver2
spec:replicas: 1selector:matchLabels:app: hiveserver2template:metadata:labels:app: hiveserver2spec:containers:- name: hiveserver2image: duhongming/hive:4.1.0 env:- name: SERVICE_NAMEvalue: "hiveserver2"- name: IS_RESUMEvalue: "true"- name: SERVICE_OPTSvalue: >--Dhive.metastore.uris=thrift://metastore.hive:9083ports:- containerPort: 10000 # HiveServer2 端口- containerPort: 10002 # Hive WebUI 端口volumeMounts:- name: hive-warehouse # 数据仓库卷(对应 --mount source=warehouse)mountPath: /opt/hive/data/warehouse- name: core-site # 挂载 core-site.xml(对应 -v ./core-site.xml)mountPath: /opt/hadoop/etc/hadoop/core-site.xmlsubPath: core-site.xmlreadinessProbe: # 检查 HiveServer2 是否就绪tcpSocket:port: 10000initialDelaySeconds: 60 # 启动较慢,延长初始化时间periodSeconds: 10volumes:- name: hive-warehousepersistentVolumeClaim:claimName: hive-warehouse- name: core-siteconfigMap:name: hive-config # 引用前面定义的 ConfigMap
---
apiVersion: v1
kind: Service
metadata:name: hiveserver2
spec:selector:app: hiveserver2type: LoadBalancerloadBalancerIP: 192.168.141.220ports:- port: 10000targetPort: 10000name: hive-thrift- port: 10002targetPort: 10002name: hive-webui
4 环境验证
4.1 Hadoop CLI
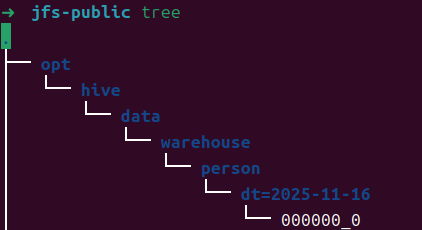
hadoop fs -ls jfs://jfs-public/
4.2 Hive CLI
beeline -u "jdbc:hive2://localhost:10000/default" -n hdfs
create table if not exists person(name string comment 'name',age int comment 'age'
)
partitioned by
(`dt` string comment 'dt'
)
stored as parquet
location 'jfs://jfs-public/person'
tblproperties
('parquet.compression'='SNAPPY','comment'='person'
);
insert into table person values('tom',25);select name, age from person;describe formatted person;
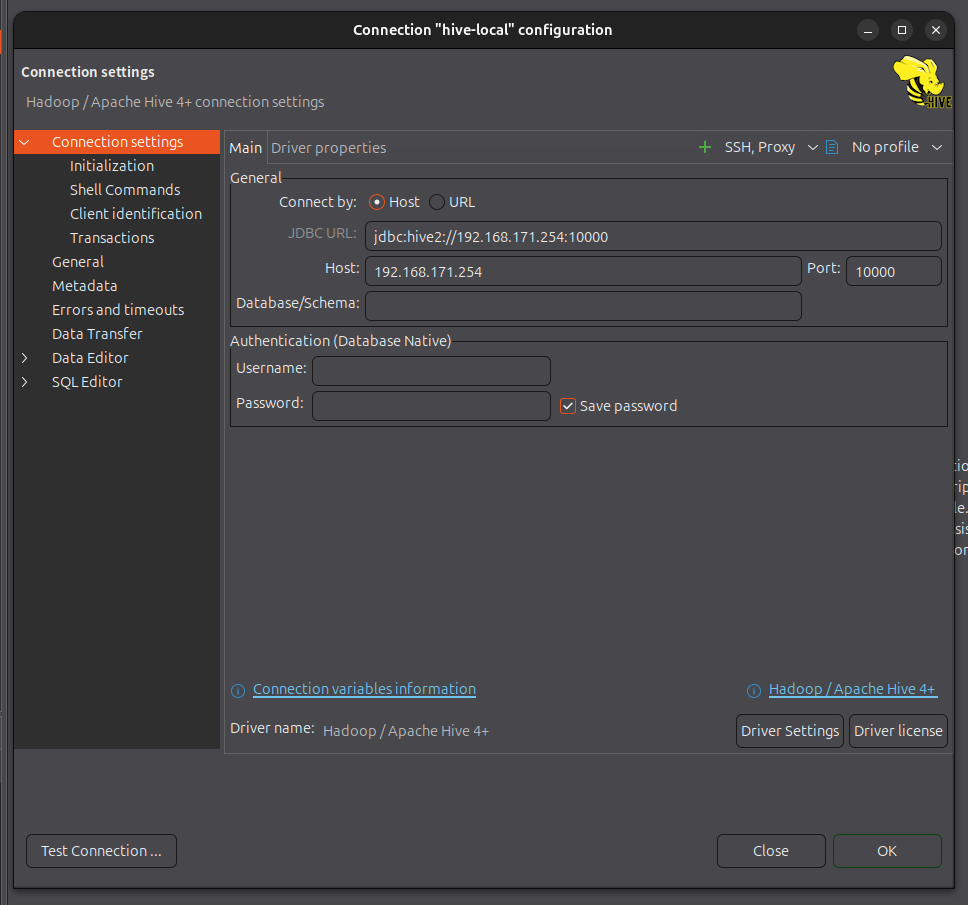
4.3 DBeaver验证
连接数据库
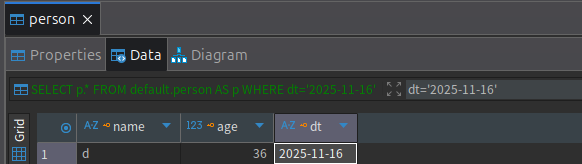
添加一条数据,并查询
查看JuiceFS文件系统