为什么 AI 推理天然更偏向 ARM(而不是 x86)
——当算力从机房回到每个人手里,架构的命运也开始改变
1. 这一切的转折,都从一次看似普通的推理部署开始
我第一次真正意识到“AI 推理与传统 CPU 世界格格不入”,是在一个并不宏大的项目里。那时我们要把一个 7B 的模型塞进边缘设备上运行,想当然地认为“推理嘛,让 x86 服务器顶着就行”。直到我们把负载打开、看着 CPU 风扇像直升机一样狂转、推理延迟飘忽、功耗像失控的水龙头,我们才察觉:问题不在模型,而在架构。
推理的节奏很奇怪,它不像数据库那样充满分支,也不像游戏逻辑那样需要大量随机执行。反而更像一条规则清晰的河,你给它矩阵,它就哗啦啦算下去;你给它 KV 缓存,它就稳稳取出来;它最怕的不是 CPU 不够强,而是访存不稳定、功耗不耐跑,以及那些 CPU 为通用计算准备的“聪明但累赘”的特性。
那一刻我意识到一个更深的现实:
AI 推理需要的不是一台强大的 CPU,而是一套能和推理节奏合拍的体系。
这也正是 ARM 悄悄走红的原因。
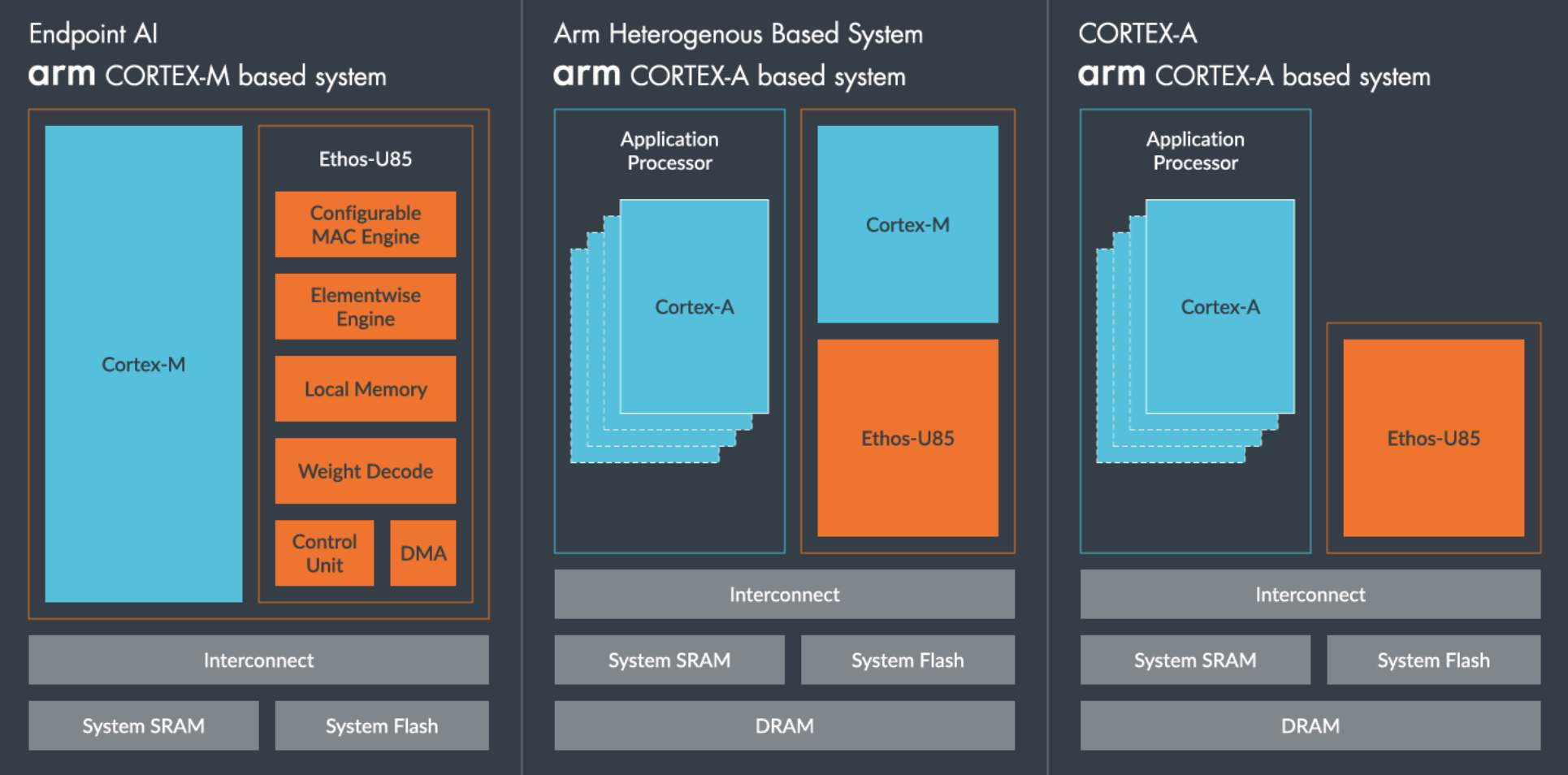
2. ARM 与推理之间的和弦:一种结构性匹配
你只要真正把推理拆开,就能看到它和 ARM 的契合是从底层结构开始的,而不是因为某个厂商的市场推广。矩阵乘法的密集性、访存的确定性、执行路径的单调性,这些特点让推理更像是“稳定长跑”,而不是“短跑 + 障碍赛”。
传统的 x86 CPU,把大量硅面积和功耗预算都压在复杂乱序执行、深度管线、分支预测和兼容性上,它像一个被训练得极端全面的钢琴家——能弹复杂曲子、能处理极端逻辑、能解决所有通用场景。但问题是:AI 推理不是钢琴曲。
它需要的是强劲的持续流量、可预测的节奏和低功耗的体质。ARM 这类轻量而规整的 RISC 架构,从来不喜欢用“聪明的硬件”压住复杂逻辑,而是让编译器、调度器和更轻的执行路径共同完成任务。它像一个能够在野外随时开唱的吉他手,不需要昂贵的设备,也不害怕长时间持续输出,只要你给它足够的能量,它就能稳定演奏到底。
更妙的是,ARM 的 SoC 哲学从第一天起就把 GPU、NPU、DSP 看成天然伙伴,而不是外接设备。AI 推理本质上是“协奏”,不是“独奏”。一个让 CPU、NPU、GPU 共享一致性内存、多级缓存和调度通道的架构,天然就比传统的 CPU 中心架构更接近未来的推理形态。
当推理的节奏与架构的节奏重叠,你就知道 ARM 不是“后来者”,而是“刚好对味”。
3. 当算力不再在远方:ARM 成为唯一贯穿端、边、云的语言
如果你把今天的 AI 计算体系画成一张图,你会惊讶地发现一件事:
唯一同时出现在手机、边缘主机、车载系统、智能硬件、轻量 PC、甚至云端服务器中的,是 ARM。
这意味着什么?意味着未来的模型推理链路不再需要跨架构来迁移与折返。
一个模型可以:
在手机上执行预推理,
把任务丢给边缘盒子做补全,
再让云端完成大规模融合计算,
最后又顺滑地回到手机完成呈现。
整个过程不需要从 x86 切到 ARM 再切回 x86,而是像一条平稳流动的河,在同一种架构下自然完成。
AI 推理越下沉,越靠近现实世界;而现实世界的算力,不是机房,而是 ARM。
这种“全链路连续性”不仅是性能问题,更是生态和未来模型形式的决定性要素。未来的大模型将越来越像流体,而不是固体——它会在设备间流动、在个人与云之间流动、在本地与服务之间流动,这需要一种共同语言,而那语言不是 x86。
4. 软件栈的自发迁移:当生态不需要被推动,它就是真的来了
真正令人震惊的不是 ARM 的硬件,而是过去一年软件生态对 ARM 的态度变化。不是“兼容”,而是“第一顺位支持”。从 Apple MLX 到 PyTorch MPS,从 TensorRT 到 ONNX Runtime,从 TVM 到 MLC LLM,从各家 NPU 框架到轻量推理引擎,怎么看都像是整个行业在为 ARM 重新写一层“AI runtime 的底座”。
更奇妙的是——这些迁移几乎不是被强推出来的。工程师是最诚实的,他们会自然选择那些跑得更顺、更节能、更贴近应用现场的体系结构。
当软件生态开始主动偏向某个架构,就说明时代底层的倾向已经悄悄定调了。
5. 从集中到分布,从服务器到每个人:这是 ARM + AI 的核心意义
AI 的黄金年代看似始于大模型在云端爆发,但它的普及一定发生在边缘、端侧、个人设备、嵌入式系统。推理不可能永远停在远方的机房里,它必须回到我们触手可及的地方——我们的手机、耳机、眼镜、车机、家里每一个轻量设备。它必须随时响应、随地运行、无需网络、无需等待。
当算力要从集中走向分布,当推理要从云端回到每个人身边,唯一能承托这种变化的架构,只能是 ARM。
这并不是 ARM 更“先进”,也不是 x86 过时,而是计算模式变了。AI 时代的算力形态不再是“强度优先”,而是“能效优先”;不是“单核强打”,而是“多单元协奏”;不是“远方集中”,而是“身边分布”。
ARM 恰好生在了这个节奏里。
结语:AI 选择 ARM,不是趋势,是归宿
写到这里,我更愿意把视角收回来——不是谈处理器,也不是谈架构,而是谈技术发展的方向感。
当推理这件事从复杂逻辑变成稳定计算,从中心集群变成本地智能体,从昂贵成本变成人人可用的资源,它自然会寻找最贴合自己的底座。ARM 是那个底座,不靠市场营销,不靠路线图,而是因为它的节奏、能效、协作方式,与推理的需求一一重叠。
x86 是上一个时代最伟大的建筑;
ARM 是下一个时代最自然的基础设施。
AI 推理选择 ARM,并不是偏好,而是回家。
如果你也在研究端侧推理、NPU 编译、模型压缩或系统架构重塑,欢迎在评论区分享你的实践。我很愿意和你一起继续把这条“AI 的新底座”探索得更透彻。