基于LLM 的 RAG 应用开发实战
1. RAG 是什么
在大模型应用领域,RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将信息检索技术与大语言模型(LLM)的文本生成能力相结合的技术框架。它的核心目标是通过引入外部知识源来增强大模型生成内容的准确性、相关性和时效性,同时解决大模型固有的局限性(如知识幻觉、静态知识、缺乏领域专长等)。
2. RAG 工作原理
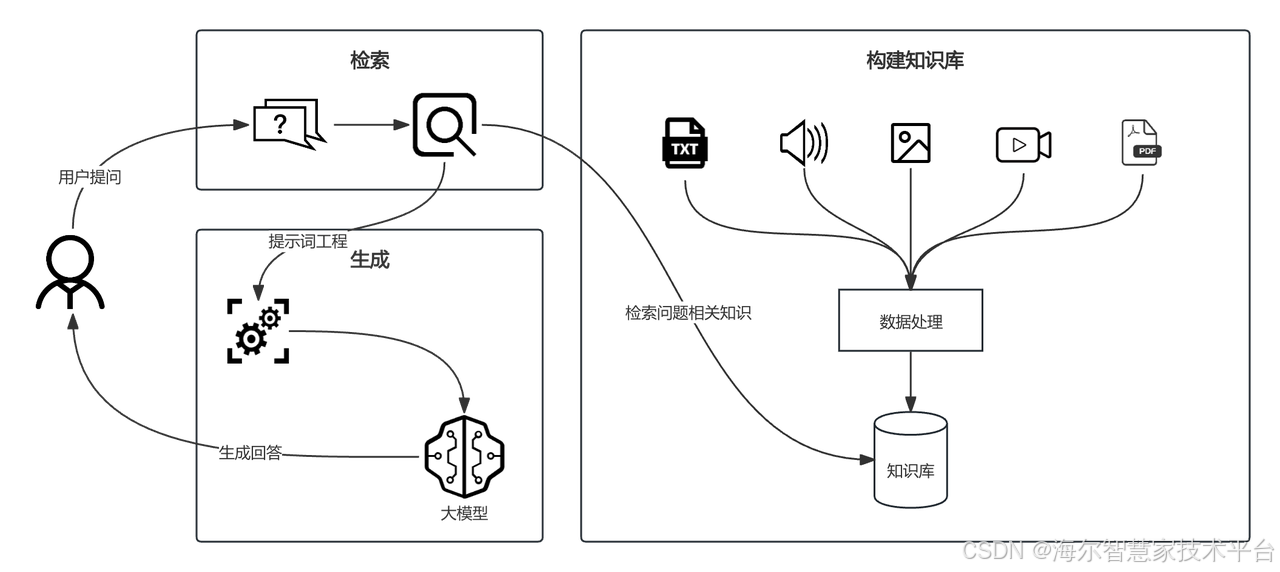
RAG 的工作流程通常分为两个关键阶段:
检索(Retrieval):
当用户输入一个查询(Query)时,RAG 系统首先会利用这个查询去搜索一个外部知识库。
这个知识库可以是:文档数据库、维基百科、企业内部文档、产品手册、代码库、知识图谱等任何结构化和非结构化数据。
检索过程通常使用语义搜索技术(如基于向量的相似度搜索,例如使用 OpenAI Embeddings 或 Sentence Transformers 等模型将文本转换为向量)。系统会找出与用户查询在语义上最相关的文本片段(Chunks)或文档。
检索的结果是一组最相关的信息片段。
增强生成(Augmented Generation):
检索到的相关片段(作为“证据”或“上下文”)会被注入到发送给大语言模型(LLM)的提示(Prompt)中。
原始的查询 + 检索到的上下文信息共同构成了一个新的、信息更丰富的提示。
LLM 基于这个包含相关上下文的增强提示来生成最终的回答。
LLM 在生成时,会综合利用自身学到的通用知识以及提示中提供的具体外部信息。
3. RAG 的核心价值与优势
减少幻觉(Hallucination):通过提供相关证据作为生成依据,极大降低了模型凭空捏造事实的可能性。生成的答案更倾向于基于提供的上下文。
知识更新与时效性:大模型的知识在训练完成后就固定了(截止到训练数据日期)。RAG 允许模型访问最新的、动态更新的外部知识库,使其能回答关于新事件、新研究、新产品的提问。
增强领域专业知识:可以将特定领域的专有知识(公司内部文档、技术手册、研究报告)注入到模型中,让通用大模型具备该领域的专业解答能力,而无需耗费巨大成本对整个模型进行微调(Fine-tuning)。
提高透明度和可验证性:因为答案是基于检索到的上下文生成的,系统可以追踪答案的来源(引用了哪个文档的哪一部分),提高了生成结果的可信度和可验证性。
成本效益:相对于微调一个大型模型(需要大量标注数据和计算资源),构建和维护一个检索知识库通常成本更低、更灵活。
处理私有/敏感数据:私有数据可以安全地存储在本地知识库中,无需上传到云端模型的训练服务器。RAG 在推理时按需检索这些数据,增强了隐私性和安全性。
4. RAG 应用场景
企业内部知识库问答:回答基于特定文档集合(如产品手册、公司制度、技术文档)的问题。
客服问答系统:准确回答用户关于产品、服务、订单等具体问题,引用官方信息。
研究助手:帮助研究人员从大量论文、报告中查找和总结相关信息。
内容摘要:生成基于特定来源(如长报告、会议记录)的摘要。
代码助手:检索相关的 API 文档、代码片段来辅助生成或解释代码。
5. 向量和向量数据库
在构建 RAG(检索增强生成)系统之前,理解向量(Vector)和向量数据库(Vector Database)至关重要。向量数据库也是 RAG 的核心引擎,直接影响系统的性能和准确性。
5.1 向量是什么
向量是一组有序的数字序列(例如
[0.2, -0.7, 1.4, ..., 0.05]),用于在高维空间(如 768 维或 1536 维)中表示文本、图像或音频的语义特征。由 嵌入模型(Embedding Model) 生成,模型将数据映射到数学空间(如 OpenAI 的
text-embedding-3-small)。
5.2 向量为什么能表示语义
相似语义 ≈ 邻近向量,例如:
“猫” 的向量 ≈ “猫咪” 的向量(余弦相似度 >0.9)
“苹果” (水果) 的向量 ≠ “苹果” (公司) 的向量
每个维度隐含抽象特征。例如:维度1可能表示“情感极性”,维度2表示“专业领域强度”。
5.3 向量在 RAG 中的核心作用
数据索引阶段
文本分块(Chunking):将 文本、PDF等原始数据拆分为 512~1024 字符的文本块。
向量化(Embedding):使用嵌入模型为每个块生成向量(如
text-embedding-3-small输出 1536 维向量)。索引构建:向量 + 元数据存入向量数据库。
检索阶段
查询向量化:用户问题 → 向量
V_q。语义搜索:计算
V_q与知识库所有向量的余弦相似度,返回 Top-5 最相关文本块。关键优化:重排序(Reranking):用交叉编码器(如
bge-reranker)精排 Top 结果,提升相关性。
5.4 向量数据库
向量数据库是专为处理向量数据(多维数值数组)设计的数据库,核心功能是通过相似性搜索快速找到与目标向量最接近的数据。
主要功能:
高效存储:管理海量高维向量(如AI模型生成的文本/图像嵌入向量)。
相似性检索:基于语义或特征匹配,实现“以图搜图”“语义搜索”等场景。
支持AI应用:为生成式AI(如RAG技术)、推荐系统、异常检测提供实时数据支撑。
5.4.1 主流向量数据库
数据库 | 核心功能及特点 | 优势 | 劣势 | 适用场景 |
Milvus |
|
| 运维相对复杂 |
|
Pinecone |
|
|
|
|
Qdrant |
|
| 大规模分布式部署方案不成熟,需要踩坑 | 高并发NLP、动态过滤 |
Weaviate |
|
|
|
|
pgvector |
|
|
| 传统应用向量化升级 |
Elasticsearch | 全文+向量混合搜索,成熟生态 |
|
|
|
MongoDB Atlas Vector Search |
| 完全托管,零运维 |
| 已在Atlas平台,需要增加向量搜索能力 |
5.4.2 Milvus 向量数据库基础用法
基于 Docker 部署
# Download the configuration file
$ wget https://github.com/milvus-io/milvus/releases/download/v2.6.0/milvus-standalone-docker-compose.yml -O docker-compose.yml
# Start Milvus
$ sudo docker compose up -d创建数据库
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)client.create_database(db_name="my_database_1"
)
创建 Collections
from pymilvus import MilvusClient, DataTypeclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)# Create schema
schema = MilvusClient.create_schema(auto_id=False,enable_dynamic_field=True,
)# Add fields to schema
schema.add_field(field_name="my_id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="my_vector", datatype=DataType.FLOAT_VECTOR, dim=5)
schema.add_field(field_name="my_varchar", datatype=DataType.VARCHAR, max_length=512)# Prepare index parameters
index_params = client.prepare_index_params()# Add indexes
index_params.add_index(field_name="my_id",index_type="AUTOINDEX"
)index_params.add_index(field_name="my_vector", index_type="AUTOINDEX",metric_type="COSINE"
)# Create a collection with the index loaded simultaneously
client.create_collection(collection_name="customized_setup_1",schema=schema,index_params=index_params
)插入实体
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)data=[{"id": 0, "vector": [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], "color": "pink_8682"},{"id": 1, "vector": [0.19886812562848388, 0.06023560599112088, 0.6976963061752597, 0.2614474506242501, 0.838729485096104], "color": "red_7025"},{"id": 2, "vector": [0.43742130801983836, -0.5597502546264526, 0.6457887650909682, 0.7894058910881185, 0.20785793220625592], "color": "orange_6781"},
]client.insert(collection_name="quick_setup",data=data
)基本向量搜索
from pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530",token="root:Milvus"
)# Single vector search
query_vector = [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592]
res = client.search(collection_name="quick_setup",anns_field="vector",data=[query_vector],limit=3,search_params={"metric_type": "IP"}
)for hits in res:for hit in hits:print(hit)6. 构建 RAG 系统
6.1 常见的开发框架和平台
维度 | LangChain | LlamaIndex | Dify |
核心定位 | 通用 LLM 应用开发框架,支持 RAG 在内的多种任务 | 专注数据索引与检索优化,为 RAG 提供高效数据层支持 | 开箱即用 RAG 系统,提供全流程可视化开发 |
数据索引能力 |
|
|
|
检索机制 |
|
|
|
生成优化 | 提供多阶段策略:查询转换(HyDE)、问题分解(Step-Back)、结果融合(RAG-Fusion) | 面向多文档的 Agent 调度,支持动态工具调用(QueryEngineTool) | 知识检索节点直连 LLM 上下文,自动注入参考内容 |
开发模式 | 代码优先:需 Python/JS 编写链(Chains)与代理(Agents) | API 驱动:聚焦索引构建与查询接口,简化检索集成 | 低代码界面:可视化工作流编排,无需编码构建 RAG 应用 |
适用场景 | 需高度定制的复杂 Agent 系统(如自主决策工具) | 多文档、跨数据集的高效检索场景(如企业级知识库) | 快速上线生产级 RAG 服务(如客服机器人、内部知识问答) |
6.2 项目实战
基于 RAG 构建智能问答系统,该系统可以根据给定的信息,回答用户关于“火星三日游”的咨询信息。
6.2.1 准备数据
使用 Markdown 文档保存“火星三日游”套餐信息。
# 火星三日游套餐分类
## **套餐一:赤焰挑战者套餐**
**主题**:极限探险
**目标人群**:冒险爱好者/年轻旅行者
**核心卖点**:太阳系最高火山速降 + 翼装穿越峡谷
**三日行程**:
- **Day1**- 奥林匹斯山磁力靴速降(2.1万米垂直落差)- 夜宿熔岩管洞穴零重力睡眠舱
- **Day2**- 水手谷翼装穿越沙暴- 尘魔旋风追击战(驾驶沙地战车)
- **Day3**- 地核钻井平台攀岩(采集氦-3晶体)- 磁轨弹射器返回轨道站
**客服触发关键词**:刺激, 挑战, 独家体验
**推荐话术**:
> “检测到您追求肾上腺素飙升!推荐『赤焰套餐』:
> - 死亡概率0.7%的火山速降(附NASA急救包)
> - 将名字永久刻在火星登陆纪念碑”## **套餐二:星火实验室套餐**
**主题**:亲子科普
**目标人群**:6-15岁亲子家庭
**核心卖点**:基因编辑生命体 + 穹顶城建造
**三日行程**:
- **Day1**- CRISPR基因工坊(改造荧光土豆)- 火星车水冰搜寻任务
- **Day2**- 熔岩管生态圈设计- 火星土壤3D打印昆虫模型
- **Day3**- 发射自建迷你穹顶城- 颁发「火星小科学家」证书
**客服触发关键词**:孩子, 学习, 安全
**推荐话术**:
> “识别到亲子需求!推荐『星火套餐』:
> - 儿童卡通版抗辐射服
> - 安全指数★★★★★
> - 宇宙快递孩子培育的荧光植物回地球”## **套餐三:红钻VIP套餐**
**主题**:奢华体验
**目标人群**:企业高管/高端客户
**核心卖点**:火星土地产权 + 双月音乐会
**三日行程**:
- **Day1**- 悬崖酒店星空下午茶- 磁悬浮火星沙画创作
- **Day2**- 双月全息声光秀- 氦-3矿物温泉疗愈
- **Day3**- 认购1km²火星土地- 竖立个人全息纪念雕塑
**客服触发关键词**:高端, 独家, 艺术
**推荐话术**:
> “尊享体验已就绪!选择『红钻套餐』可获得:
> - 比尔·盖茨同款悬崖酒店
> - 火星土地NFT证书(年涨幅+300%)
> - 特权免星际隔离”
\&\&
# 火星三日游套餐对比
## 从多个维度对比火星三日游套餐
**维度:体力要求**
- 赤焰挑战者:极高(需体能测试)
- 星火实验室:低(室内为主)
- 红钻VIP:中等(艺术创作为主)**维度:独特权益**
- 赤焰挑战者:登陆纪念碑刻名
- 星火实验室:穹顶城永久展示位
- 红钻VIP:火星土地产权NFT**维度:主要风险**
- 赤焰挑战者:死亡概率0.7%
- 星火实验室:基因污染风险
- 红钻VIP:产权法律纠纷**维度:参考价格**
- 赤焰挑战者:$150,000/人
- 星火实验室:$80,000/人(儿童半价)
- 红钻VIP:$250,000/人**维度:最佳人群**
- 赤焰挑战者:25-40岁冒险者
- 星火实验室:6-15岁亲子家庭
- 红钻VIP:企业高管/情侣6.2.2 基于 LangChain 框架构建
数据嵌入及索引
# 导入 HuggingFace 的 Embedding 模型,用于将文本转为向量
from langchain_huggingface import HuggingFaceEmbeddings
# 导入文本加载器,用于加载本地 markdown 文本
from langchain_community.document_loaders import TextLoader
# 导入 Milvus 向量数据库的适配器
from langchain_milvus.vectorstores import Milvus
# 导入 MarkdownHeaderTextSplitter,用于按 markdown 标题分段
from langchain.text_splitter import MarkdownHeaderTextSplitter# 指定 markdown 文件路径
markdown_path = "rag_data.md"
# 加载 markdown 文件内容
loader = TextLoader(file_path=markdown_path)
data = loader.load()# 设置分段规则:按一级标题(#)和二级标题(##)分段
headers_to_split_on = [("#", "Section"), # 一级标题作为 Section("##", "Subsection"), # 二级标题作为 Subsection
]# 初始化 markdown 分段器,strip_headers=False 表示保留标题内容
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on,strip_headers=False)
# 按规则分割文档,得到分段后的文档列表
split_docs = markdown_splitter.split_text(data[0].page_content)# 选择用于生成文本向量的模型,这里用 BAAI/bge-m3
model_name = "BAAI/bge-m3"
embeddings = HuggingFaceEmbeddings(model_name=model_name,model_kwargs={'device': 'cpu'}, # 指定在 CPU 上运行encode_kwargs={'normalize_embeddings': True} # 向量归一化,便于相似度检索
)# 连接远程 Milvus 向量数据库
vector_db = Milvus(embedding_function=embeddings, # 指定 embedding 方法collection_name="rag_data_collection", # 集合名称connection_args={"host": "localhost", # Milvus 服务地址"port": "19530","user": "root","password": "Milvus"},auto_id=True, # 主键自增drop_old=True # 如果已存在同名集合则先删除再新建
)# 将分段后的文档插入到 Milvus 向量数据库中
vector_db.add_documents(documents=split_docs)数据检索增强生成
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_milvus.vectorstores import Milvus
from langchain import hub
from langchain_deepseek import ChatDeepSeekmodel_name = "BAAI/bge-m3"
embeddings = HuggingFaceEmbeddings(model_name=model_name,model_kwargs={'device': 'cpu'},encode_kwargs={'normalize_embeddings': True}
)# 连接远程 Milvus
vector_db = Milvus(embedding_function=embeddings,collection_name="rag_data_collection", # 添加集合名称参数connection_args={"host": "localhost", # 确保这是正确的远程地址"port": "19530","user": "root","password": "Milvus"},auto_id=True,drop_old=False # 首次运行时创建新集合
)llm = ChatDeepSeek(model="deepseek-chat",temperature=0,max_tokens=None,timeout=None,max_retries=2,api_key="sk-58d35df8d09******fe0243923099b42",
)prompt = hub.pull("rlm/rag-prompt")def generate(query: str):docs_content = vector_db.similarity_search(query, k=3)messages = prompt.invoke({"question": query, "context": docs_content})response = llm.invoke(messages)print({"answer": response.content})generate("火星三日游有哪些套餐?")
# {'answer': '火星三日游提供多种套餐,包括: \n1. **赤焰挑战者套餐**:极限探险主题,含火山速降、翼装穿越等刺激项目,适合冒险爱好者。 \n2. **红钻VIP套餐**:奢华体验主题,含火星土地产权、双月音乐会等高端服务,适合企业高管。 \n3. **星火实验室套餐**(根据对比表补充):亲子友好,以室内活动为主,适合家庭游客。'}
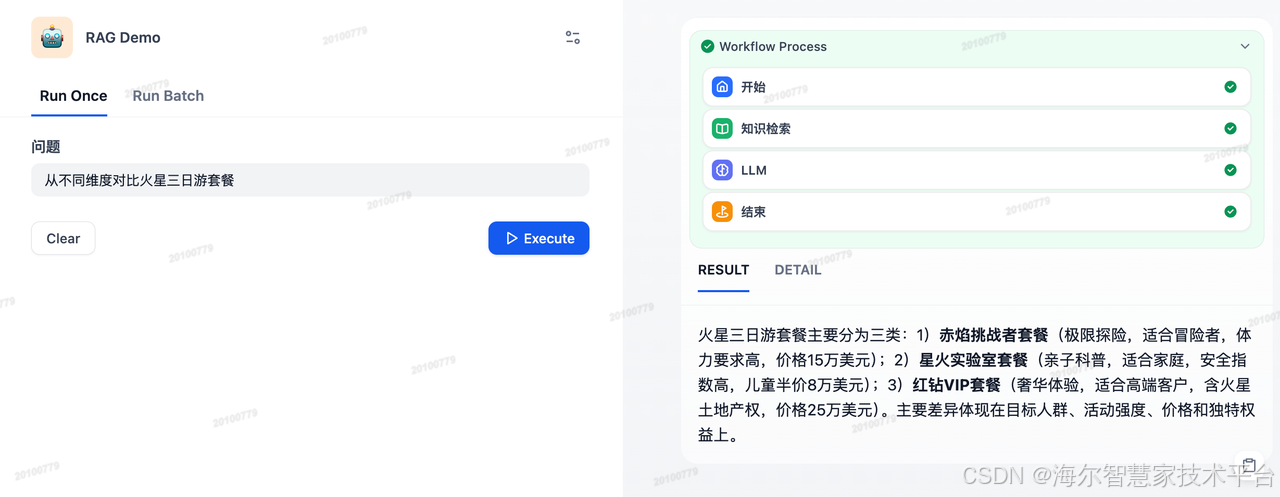
generate("从不同维度对比火星三日游套餐")
# {'answer': '从不同维度对比火星三日游套餐: \n1. **体力要求**:赤焰挑战者(极高)、星火实验室(低)、红钻VIP(中等)。 \n2. **独特权益**:赤焰挑战者(登陆纪念碑刻名)、星火实验室(穹顶城展示位)、红钻VIP(火星土地NFT)。 \n3. **价格**:赤焰挑战者(15万美元)、星火实验室(8万美元)、红钻VIP(25万美元)。'}
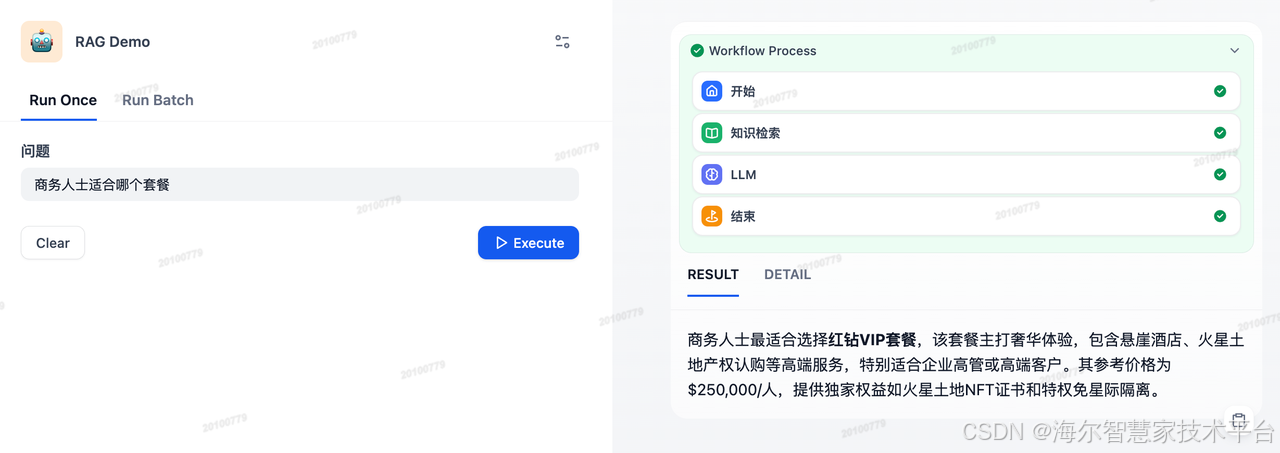
generate("商务人士适合哪个套餐")
# {'answer': '商务人士适合**红钻VIP套餐**,该套餐专为企业高管/高端客户设计,提供奢华体验,包括火星土地产权和双月音乐会等独家权益。其体力要求中等,以艺术创作为主,参考价格为$250,000/人。'}6.2.3 基于 Dify 构建
创建知识库,将 markdown 文档保存的“火星三日游”套餐信息导入
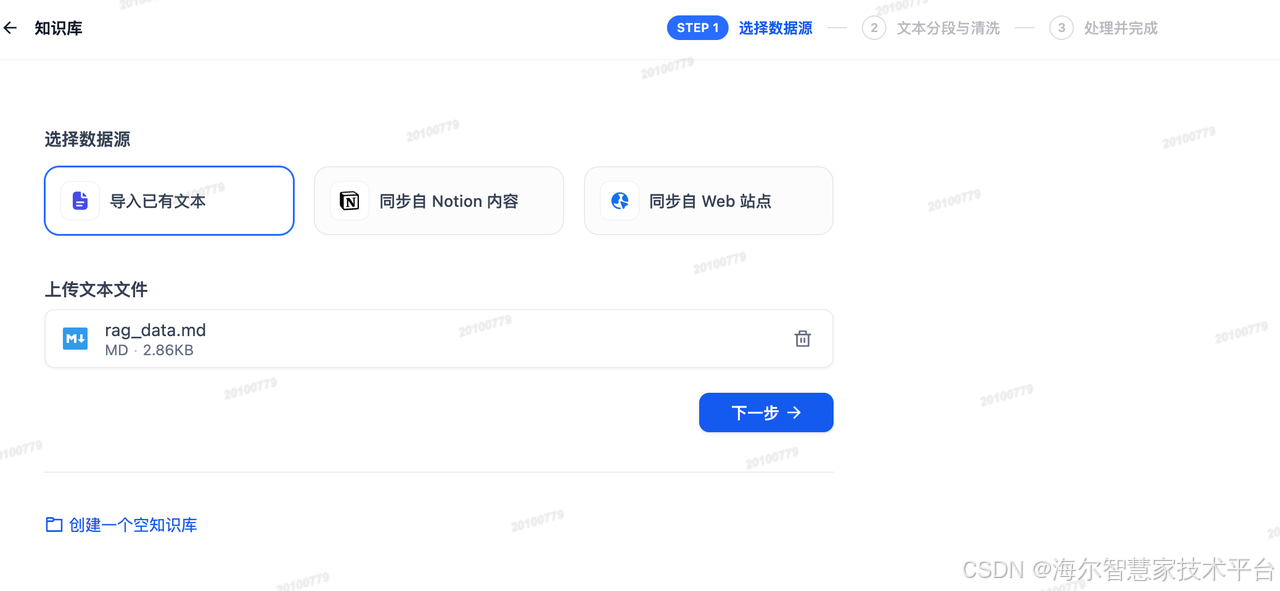
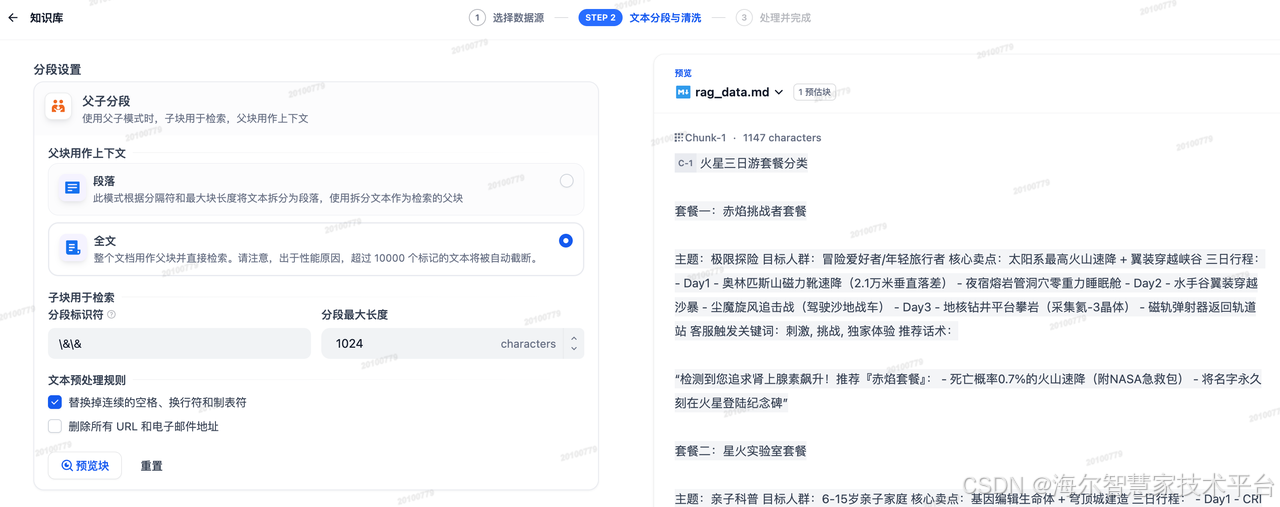
将导入的文本进行分段
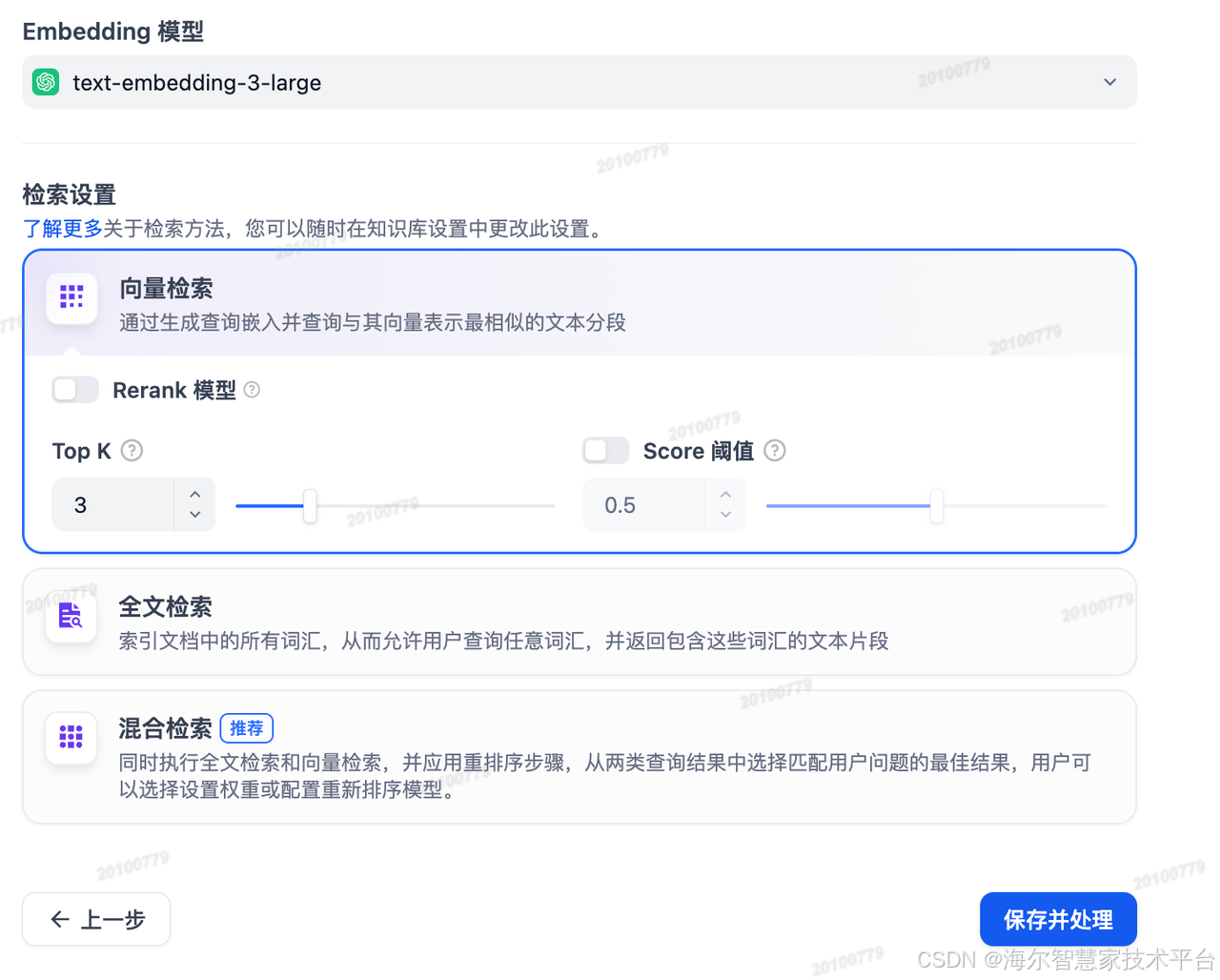
选择文本嵌入模型及检索设置
创建应用
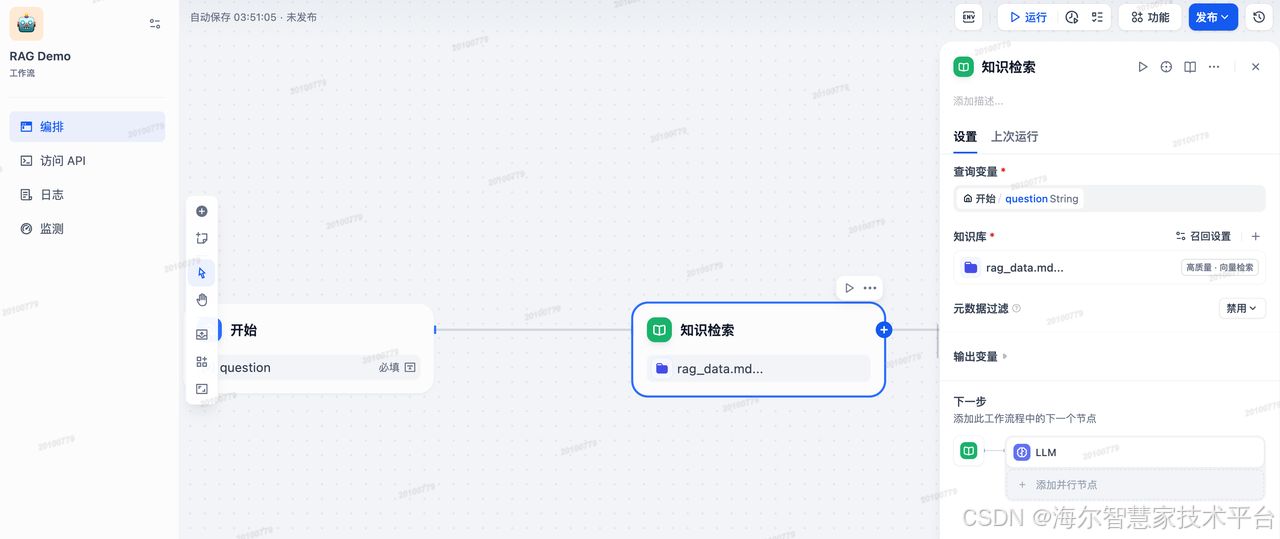
添加知识检索节点,并关联刚才创建的知识库
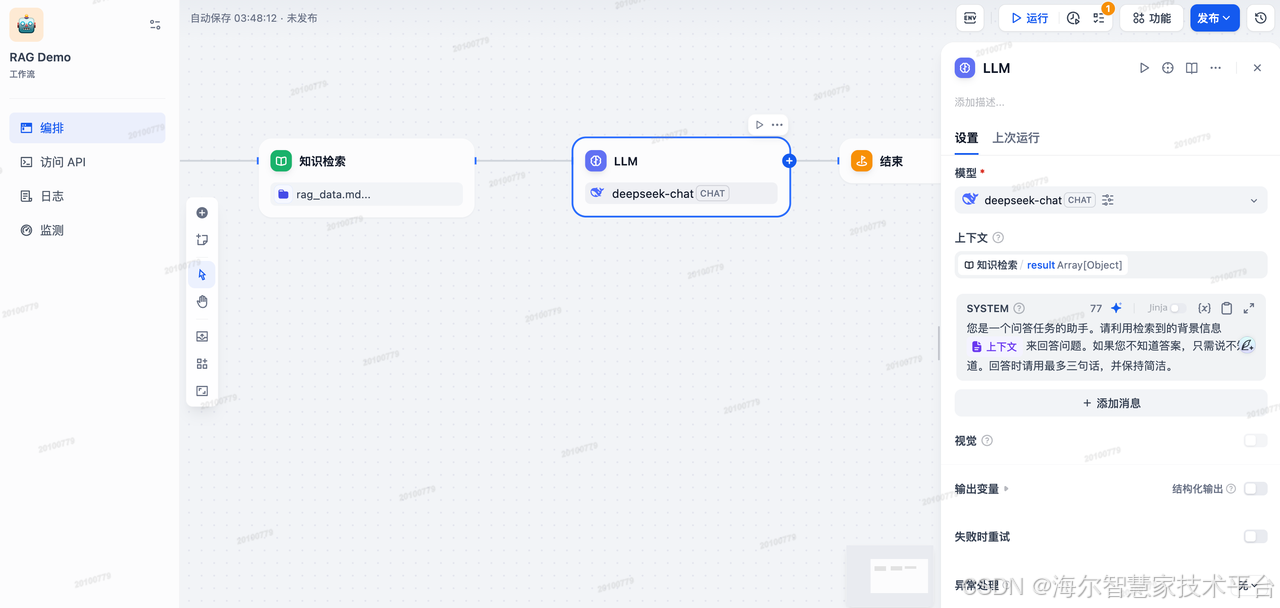
选择模型,并设置系统提示词
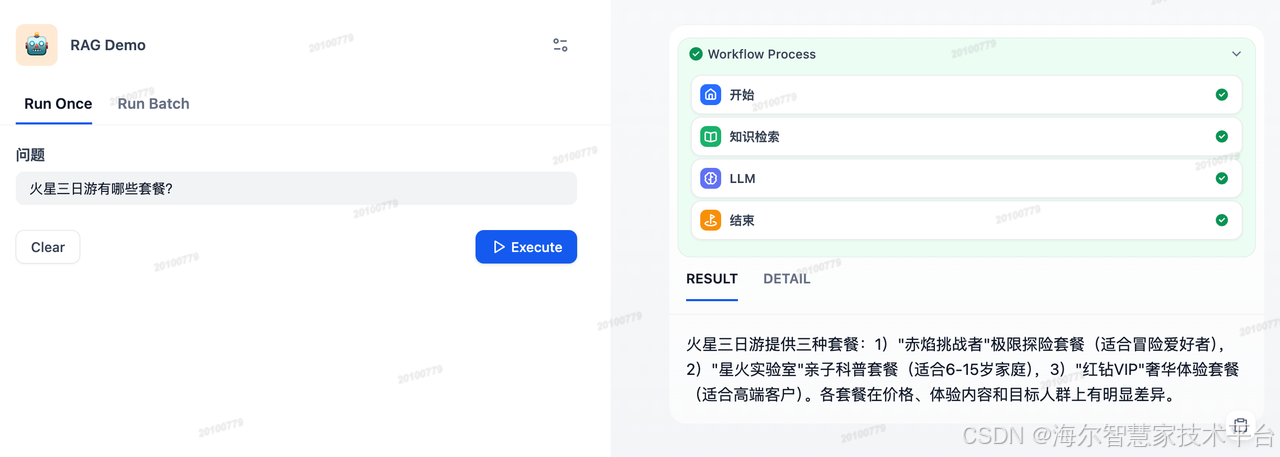
运行并测试应用
7. 团队介绍
「三翼鸟数字化技术平台-ToC服务平台」以用户行为数据为基础,利用推荐引擎为用户提供“千人千面”的个性化推荐服务,改善用户体验,持续提升核心业务指标。通过构建高效、智能的线上运营系统,全面整合数据资产,实现数据分析-人群圈选-用户触达-后效分析-策略优化的运营闭环,并提供可视化报表,一站式操作提升数字化运营效率。