如何在上线后出现重大故障时进行应急响应
上线后出现重大故障,是对团队技术栈、应急流程和组织协同能力的极限考验。应急响应的核心是立即从“混乱”转向“有序控制”,其首要目标是“快速恢复服务”(MTTR),而非“追查根因”。 成功的响应流程包括:第一,立即成立应急小组(战时指挥部),明确总指挥(Incident Commander),统一信息渠道,并快速评估“爆炸半径”;第二,将“变更”作为第一嫌疑人,通过监控、日志等数据迅速定位问题;第三,果断执行止损操作,优先选择“回滚”,若回滚不可行则考虑降级或热修复;第四,保持高频、透明的内外沟通,管理利益相关者预期;最后,在服务恢复后,必须进行多维度验证并逐步放量,防止二次雪崩。这是一个止血、诊断、治疗的系统工程,其效率直接决定了故障对业务的最终损害程度。
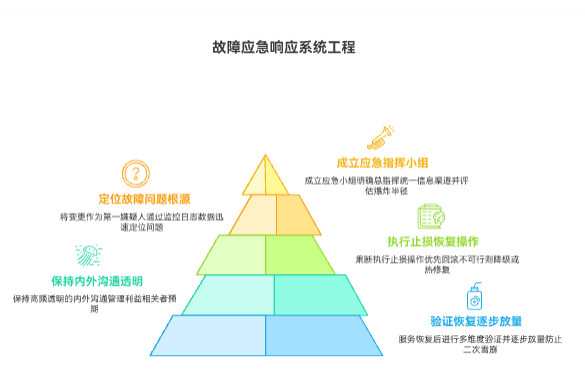
一、 应急响应的核心原则:从混乱走向控制
重大故障发生时,第一现场必然是混乱的:报警声、即时通讯工具的刷屏、以及来自各方的压力。应急响应的第一要务,就是用标准化的流程强行注入秩序,将团队从“应激反应”切换到“主动响应”。
黄金10分钟:立即响应与评估影响面
故障的“黄金10分钟”决定了后续响应的基调。当监控系统(Monitoring)发出警报或收到用户(客服)的集中反馈时,一线响应人员(如On-Call工程师)必须立即行动。
- 确认(Acknowledge): 立即在告警系统或工作群中“确认”收到,宣告“有人正在处理”。这是阻止混乱蔓延的第一步。
- 评估“爆炸半径”(Blast Radius): 立即回答几个核心问题:
- 影响谁? 是全部用户、特定区域用户、还是某个特定功能的用户?
- 影响什么? 是核心功能(如登录、支付)还是边缘功能(如修改头像)?
- 严重程度? 是系统完全不可用(Hard Down)还是性能严重下降(Slowdown)?
这个初步的“分诊”(Triage)至关重要,它决定了应急响应的优先级和需要投入的资源规模。
建立“战时指挥部”:明确角色与分工
一旦确认故障级别为“重大”(例如P0或P1级),必须立即成立“战时指挥部”(War Room)。这不一定是一个物理空间,更可能是一个专用的即时通讯频道(如Slack/Teams频道)或紧急电话会议。
“战时指挥部”的灵魂是任命一个“总指挥”(Incident Commander, IC)。 IC的职责不是亲自修复故障,而是“协调”所有资源、“推动”流程进展和“做出”关键决策。
除了IC,还应立即明确几个关键角色:
- 技术负责人(Ops Lead): 通常是SRE或资深开发,负责组织技术力量进行诊断和修复。
- 沟通负责人(Comms Lead): 负责对内(管理层)和对外(客户、法务、公关)发布统一、准确的信息。
- 记录员(Scribe): 负责在指挥频道中记录所有关键行动、发现、决策和时间点,为事后复盘提供“黑匣子”。
角色的明确,是确保团队在巨大压力下依旧能够高效协同、避免“多头指挥”或“无人负责”的关键。
二、 诊断与定位:分秒必争的“第一嫌疑人”
在指挥部成立的同时,技术负责人的诊断工作必须分秒必争地展开。在故障定位上,我们必须遵循科学的怀疑主义和数据驱动的原则。
“变更”是永远的第一嫌疑人
超过90%的线上故障是由“变更”引起的。 这里的“变更”是一个广义概念,它包括:
- 代码发布: 刚刚上线的那个新版本。
- 配置变更: 无论是通过配置中心还是手动修改的任何参数。
- 基础架构变更: 如K8s集群升级、网络策略调整、数据库迁移。
- 数据变更: 如一个大型的数据清洗脚本执行。
因此,技术负责人的第一个问题永远是:“5分钟前(或故障发生前),我们做了什么?” 立即拉取所有系统(应用、中间件、基础设施)的变更记录,这是定位问题的最快路径。
数据驱动排查:监控、日志与指标的三角测量
如果变更不明显,或者变更已回滚但问题依旧,团队必须立即转向“数据驱动”的排查。正如管理大师 W. 爱德华兹·戴明(W. Edwards Deming)所言:“没有数据,你只是另一个有观点的人。” (Without data, you're just another person with an opinion.)
在故障排查中,数据主要来自“可观测性”(Observability)的三大支柱:
- 监控指标(Metrics): 查看关键的系统仪表盘。错误率(Error Rate)是否飙升?延迟(Latency)是否激增?吞吐量(Throughput)是否断崖式下跌?使用RED方法(Rate, Errors, Duration)或USE方法(Utilization, Saturation, Errors)来系统性地审视服务健康度。
- 日志(Logs): 指标告诉我们“哪里出错了”,日志告诉我们“为什么出错了”。立即聚合日志系统(如ELK, Splunk),筛选“ERROR”或“FATAL”级别的日志。寻找是否有新的、异常的错误信息在刷屏。
- 链路追踪(Traces): 在复杂的微服务架构中,链路追踪是定位瓶颈和错误传递路径的神器。一个请求在哪个服务节点失败了?哪个下游服务响应超时了?
通过这三者的“三角测量”,技术团队可以迅速将问题范围从“整个系统”缩小到“某个特定服务”或“某个特定组件”。
三、 快速恢复:止损优先于追查根因
在应急响应中,我们必须牢记一个至高无上的原则:“恢复服务”的优先级永远高于“追查根因”。 换句话说,先救火,再调查纵火犯。
MTTR(Mean Time To Recovery,平均恢复时间)是衡量应急响应团队能力的第一指标。 在这个阶段,IC必须果断决策,选择最快、最稳妥的方式让服务“活过来”。
止损的艺术:回滚、降级与热修复
技术团队必须在最短时间内(例如15分钟内)提出止损方案。方案通常有三种,按优先级排序:
- 回滚(Rollback): 这是最安全、最推荐的首选方案。 如果故障是由明确的“变更”(尤其是代码发布)引起的,立即执行回滚操作,退回到上一个稳定版本。回滚的优势在于确定性高、风险低。团队必须确保自己的发布系统(CI/CD)具备“一键回滚”的能力。
- 优雅降级(Graceful Degradation): 如果回滚不可行(例如,变更涉及不可逆的数据库结构),或者故障源头不明,此时应考虑“降级”。即通过配置中心或功能开关(Feature Flag),暂时关闭那个“非核心”但“导致了雪崩”的功能。例如,关闭商品推荐服务,以保住核心的“交易”服务。这是“牺牲车,保住帅”的策略。
- 热修复(Hotfix): 这是最高风险、万不得已才用的方案。 它意味着在极短时间内,针对已发现的Bug编写补丁代码,并直接部署到生产环境。热修复的风险在于,高压下的代码极易引入新Bug,导致“二次雪崩”。只有在“回滚不可行”且“不修复将导致灾难性后果”(如资金安全问题)时才应考虑。
决策的权衡:速度、风险与用户体验
总指挥(IC)此时是决策的核心。IC需要基于技术负责人提供的信息,在“恢复速度”、“修复风险”和“用户体验”之间做出权衡。
- 如果回滚需要30分钟,但热修复只需要5分钟(但有20%的失败风险),IC该如何选择?
- 如果降级会影响10%的“边缘用户”,但不降级可能在1小时后导致100%的用户不可用,IC该如何决策?
这些决策没有标准答案,极度考验IC的经验、魄力和对业务的理解。
四、 协同与沟通:管理“信息风暴”
在技术团队紧张排查的同时,另一场“风暴”正在“战时指挥部”外酝酿——来自管理层、其他业务部门、客服乃至公关的“信息风暴”。
对内同步:单一可信源与状态更新
沟通负责人(Comms Lead)的首要任务是“对内同步”。
- 建立“单一可信源”(SSOT): “战时指挥部”频道(或电话会议)是唯一的信息来源。严禁技术人员在其他群聊中“私下”发布未经确认的信息。 这可以防止谣言和混乱的猜测。
- 定时状态更新(Status Update): 沟通负责人必须按照固定频率(例如,P0故障每15分钟一次)向管理层和相关方通报进展。即使“没有进展”,也要通报“仍在排查中”,这能极大地缓解管理层的焦虑。
团队需要一个统一的信息集散地,无论是专用的即时通讯频道,还是像Worktile这样的通用项目管理工具中的专用看板,来集中透明地同步所有人的进展和当前状态。
对外安抚:坦诚、及时、统一口径
如果故障已经影响到外部用户(例如,App无法访问),对外沟通就必须启动。
- 坦诚(Honesty): 不要撒谎,不要使用“系统升级”等拙劣的借口。承认“我们遇到了技术问题”,这比欺骗更能赢得用户的长期信任。
- 及时(Timeliness): 在官网、App公告、官方社交媒体上第一时间发布简短声明,告知用户“已知悉,在修复”。
- 统一口径(Unified): 确保所有对外出口(客服、公关、销售)的口径是完全一致的,所有说辞必须由“沟通负责人”统一提供。
一个糟糕的对外沟通,其造成的“品牌损害”可能远超故障本身的“技术损失”。
五、 故障恢复与验证:确保“警报”真正解除
当技术团队执行了“回滚”或“热修复”后,IC绝不能立即宣布“故障解除”。一个草率的“All Clear”信号可能导致在修复未完成时,大量用户涌入,造成系统二次崩溃。
多维度验证:从系统指标到业务功能
验证必须是多维度的,以确保系统不仅是“启动了”,而且是“健康了”。
- 系统指标验证: 技术负责人必须确认,之前异常的“监控指标”(错误率、延迟)已经回落到正常基线水平。
- 日志验证: 确认异常的“错误日志”已经停止刷屏。
- 业务功能验证: 这是最关键的。必须由QA团队(甚至产品经理)立即介入,按照预先准备的核心业务用例(P0 Use Cases)进行一轮“冒烟测试”。例如,“用户能否登录?能否下单?能否支付成功?”
只有当系统指标和业务功能都确认恢复正常后,才能进入下一阶段。
逐步放量与持续观察
即使验证通过,也不应立即“全量开放”。最佳实践是“逐步放量”(Gradual Ramp-up)或“灰度放开”。
- 如果使用了“降级”手段,此时应逐步开启被关闭的功能,并密切观察监控大盘。
- 如果使用了“回滚”,并且是蓝绿部署(Blue-Green Deployment)或金丝雀发布(Canary Release)环境,应先导入1%的流量,观察5分钟,然后10%,然后50%,最后100%。
在全量放开后,应急小组不应立即解散,必须进入“持续观察期”(例如,至少1小时),确保系统在新一轮高峰流量下保持稳定。当所有指标平稳渡过观察期后,IC才能正式宣布:“故障解除,应急响应结束。”
六、 事后复盘(Post-Mortem):从“故障”中提取“资产”
应急响应的结束,恰恰是“改进”的开始。如果不对故障进行深入复盘,那么团队只是“熬过”了灾难,而没有从中“学习”。
正如哲学家乔治·桑塔亚那(George Santayana)所说:“那些不能铭记过去的人,注定要重蹈覆辙。” (Those who cannot remember the past are condemned to repeat it.)
故障复盘(Post-Mortem)的目的,就是将被动的“故障”转化为主动的“组织资产”。
“无指责”复盘文化:对事不对人
复盘的成功与否,取决于其“文化”。Google SRE文化中最重要的“无指责复盘”(Blameless Post-mortem)是行业金标准。
- 基本假设: 假定每个参与者在当时的情况下,都已尽其所能。
- 焦点: 我们的目标不是“惩罚”那个“按错按钮”的人,而是要回答“为什么我们的系统如此脆弱,以至于一个人的失误就能导致P0故障?”“为什么我们的告警没有更早发现?”
- 对事不对人: 从“张三误操作了配置”转向“配置发布的审核流程存在缺陷”。
只有在“心理安全”的环境下,团队成员才敢于暴露真正的流程问题。
5 Whys:深挖根本原因与改进项
复盘会必须在故障后(例如3-5个工作日内)举行。会议的核心工具是“5 Whys”(五个为什么)分析法,用于深挖根本原因(Root Cause)。
- (例)Why 1:服务崩溃了。因为数据库连接池满了。
- Why 2:为什么连接池满了?因为一个慢查询SQL占用了所有连接。
- Why 3:为什么会有慢查询?因为一个新功能上线,代码逻辑有缺陷。
- Why 4:为什么有缺陷的代码能上线?因为Code Review没看出来,测试也没覆盖到。
- Why 5:为什么测试没覆盖?因为QA没理解这个功能的极端数据场景。
复盘的最终产出,必须是一系列可执行、可追踪的“行动项”(Action Items, AIs)。 这些改进项(例如:“为配置发布增加自动化CI/CD”、“为慢查询SQL增加告警”、“优化QA的测试用例库”)必须被追踪到底。这些AIs可以被郑重地录入到像研发项目管理系统PingCode这样的工具中,分配明确的责任人(Owner)和截止日期(Due Date),确保它们被逐一关闭,真正提升系统的健壮性。
七、 预防与改进:构建高可用性系统
应急响应是“被动防御”,而一个成熟的组织必须追求“主动预防”。
固化SOP与自动化预案
复盘的成果应该被固化。
- SOP(标准操作程序): 将本次故障的成功响应经验,沉淀为标准文档。例如,“数据库连接池告警SOP”,下次再发生,任何人(即使是新人)都能按图索骥,快速响应。
- 自动化预案(Playbooks): 将SOP代码化、自动化。例如,当检测到连接池满时,系统自动执行“隔离故障实例”、“限制新连接”等预案脚本,实现“自愈”(Self-Healing)。
混沌工程:主动制造失败
最高阶的预防,是“混沌工程”(Chaos Engineering)。与其等待故障发生,不如“主动制造”可控的故障。
像Netflix的Chaos Monkey一样,在生产环境中随机“杀死”服务实例、“注入”延迟、“制造”网络分区。混沌工程的价值在于,它能持续、主动地“演练”你的应急响应流程和系统的容错能力,在“非上班时间”暴露问题,而不是在“流量高峰期”暴露。
只有经历过千锤百炼的演练,团队才能在下一次真正的“重大故障”来临时,从容不迫,化危为机。
常见问答(FAQ)
Q1: 故障响应中,最大的忌讳是什么?
A1: 慌乱、指责和信息混乱。 1. 慌乱会导致做出错误的决策(如在高压下进行高风险的热修复); 2. 指责会破坏“无指责”文化,导致无人敢说真话; 3. 信息混乱(多头指挥、谣言四起)会极大地浪费排查时间。
Q2: 谁应该被任命为“总指挥”(Incident Commander)?
A2: 不一定是技术最强的人,但必须是“大局观”最强、“协调能力”最好、“决策最果断”的人。 IC的核心职责是管理流程、协调资源和做出权衡,而不是亲自写代码。
Q3: 为什么“回滚”是首选方案?
A3: 因为“恢复速度”(MTTR)是第一优先级。 回滚是路径最确定、风险最低、速度通常最快的“止血”方案。先让服务恢复,我们有大把的时间在服务稳定后去慢慢排查“根因”,但我们无法承受服务长时间宕机的业务损失。
Q4: 什么是“无指责”复盘?为什么它这么重要?
A4: “无指责”复盘(Blameless Post-mortem)是假定“每个人都已尽力”的前提下,专注于分析“流程”和“系统”缺陷,而非“个人”失误。它之所以重要,是因为只有在“心理安全”的环境下,工程师才敢于暴露问题(而不是隐藏问题),团队才能找到真正的根本原因并进行改进。