通过Rust高性能异步网络服务器的实现看Rust语言的核心优势



目录
- 通过Rust高性能异步网络服务器的实现看Rust语言的核心优势`
- `项目概述`
- `项目结构`
- `1. Cargo.toml - 项目依赖配置(为啥说 Rust 的依赖管理香)`
- `2. src/main.rs - 程序入口`
- `3. src/server.rs - 服务器核心实现`
- `4. src/connection.rs - 连接处理模块`
- `5. src/request.rs - 请求解析模块`
- `6. src/response.rs - 响应生成模块`
- `7. src/utils/buffer.rs - 高效缓冲区实现`
- `如何运行项目`
- `最后说说,个人认为rust对比现如今流程的语言,到底有哪些优势?`
- `内存安全对比:C++ vs Rust`
- `并发模型对比:Java vs Rust`
- `内存安全:无需垃圾回收的安全保障`
- `Rust的所有权系统`
- `与其他语言对比`
- `并发模型:轻量高效的异步处理`
- `Rust的异步编程模型`
- `与其他语言对比`
- `性能表现:接近底层硬件的效率`
- `Rust的零成本抽象`
- `与其他语言对比`
- 类型系统:编译时错误检测
- `Rust的强类型系统`
- `与其他语言对比`
- 错误处理:优雅而安全的错误管理
- `Rust的错误处理机制`
- `与其他语言对比`
- `工具链与生态系统`
- `Rust的开发工具`
- `总结`

通过Rust高性能异步网络服务器的实现看Rust语言的核心优势`
项目概述
- RustAsyncServer的异步网络服务器小项目,核心定位是作为 Rust 语言新手的实战入门案例 —— 通过从零搭建一个功能完整、架构清晰的网络服务,让新手在实践中理解 Rust 的核心特性。
- 这个项目不会追求过度复杂的功能堆砌,而是聚焦 “基础扎实、逻辑易懂”,把 Rust 在系统级编程的核心优势拆解到具体开发步骤中。比如并发连接处理,会基于 Rust 生态成熟且易上手的 Tokio 异步运行时,从基础的 TCP 异步监听写起,一步步封装连接管理、任务调度逻辑,让新手直观感受到 “非阻塞 I/O 如何支撑高并发”,不用纠结复杂的底层调度原理,就能搭建起能同时处理数千条连接的服务框架。
- 内存管理是 Rust 的一大特色,也是新手入门的重点和难点。这个服务器会刻意简化内存操作逻辑,通过具体场景让新手理解所有权、借用和生命周期的实际用途 —— 比如如何安全传递网络数据、如何避免内存泄漏、如何在并发场景中保证数据安全,全程用代码示例印证 “Rust 无需垃圾回收也能实现内存安全”,让抽象的语法规则变得可感知、可复用。
项目结构
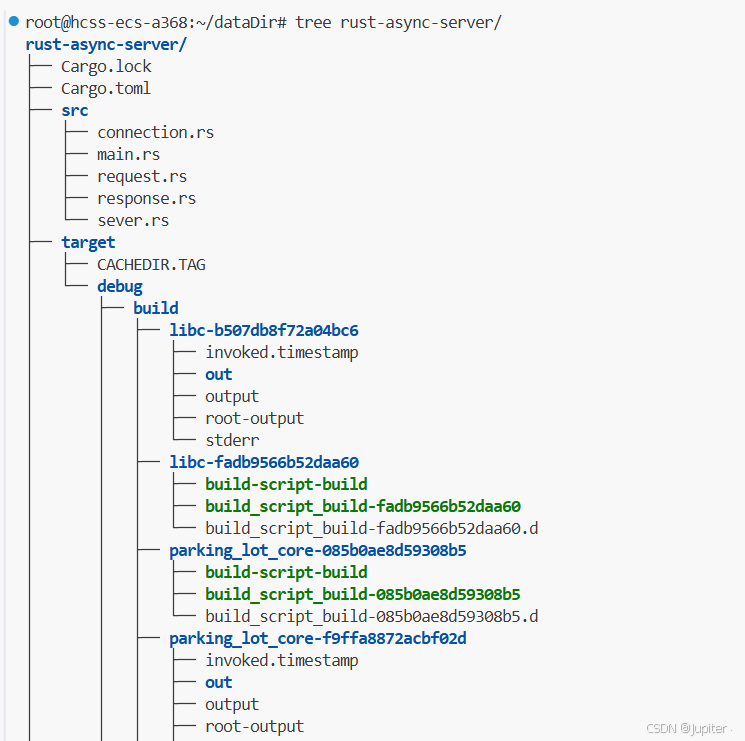
rust-async-server/
├── Cargo.toml # 项目依赖配置
└── src/├── main.rs # 程序入口├── server.rs # 服务器核心实现├── connection.rs # 连接处理模块├── request.rs # 请求解析模块├── response.rs # 响应生成模块└── utils/└── buffer.rs # 高效缓冲区实现
下面会逐一每一个模块的讲解代码:分析Rust的一些优势,适合有网络编程基础的人看…
1. Cargo.toml - 项目依赖配置(为啥说 Rust 的依赖管理香)
- 这部分没啥复杂的,就是给项目 “贴标签”。Rust 的 edition 会指定编译器的语法规则,不用手动配置编译器,Cargo 会自动适配,新手不用操心版本兼容问题。
- 重点看 [dependencies] 部分:项目依赖(别人写好的 “工具”),这些都是咱们服务器代码里实际用到的库,Cargo 会自动下载、编译,不用手动找文件、配路径:
- tokio = { version = “1”, features = [“full”] } :核心中的核心!服务器是 “异步” 的,全靠 Tokio 这个异步运行。 后面代码的的 TcpListener、task::spawn、await 这些异步功能,都得靠它支撑。
- features = [“full”] 是启用 Tokio 的全部功能(比如网络、I/O、任务调度),新手不用纠结选哪些功能,直接 “拉满” 省心,后续想精简也能改。
- bytes = "1"处理字节数据的 “神器”!之前创建响应时用的 BytesMut 就是它提供的 —— 比 Rust 标准库的 Vec 更适合网络编程,拼接、截取字节更高效,还能减少内存拷贝,咱们服务器的高性能离不开它。
- log = “0.4” + env_logger = "0.10"日志相关的组合!log 提供日志打印的基础功能(比如代码里的 info!、warn!),env_logger 负责把日志输出到控制台,还能控制日志级别(比如只看 Info 及以上的日志)。服务器运行时,能通过日志看到 “启动在哪个端口”“哪个客户端连进来了”“哪里出错了”,调试和运维都方便。
这就是为啥说 Rust 的依赖管理香(新手能直接感受到的优势)
- 不用手动管版本:比如写 tokio = “1”,Cargo 会自动选 1.x 系列的最新稳定版,还会生成 Cargo.lock 文件锁定版本,下次编译不会突然换版本导致报错。
- 自动处理依赖链:比如 env_logger 可能依赖其他库,Cargo 会一并下载,不用咱们逐个找、逐个装。
- 按需编译:只编译咱们用到的功能(比如 Tokio 虽然 “full”,但没用到的模块其实不会编译进最终程序),不会让程序变臃肿。
- 零配置上手:只要把依赖写进这个文件,执行 cargo run,Cargo 会自动搞定所有依赖相关的事,新手不用关心 “库存在哪”“怎么链接”,专注写代码就行。
简单说,这个文件就是给项目 “搭骨架”—— 定好基础信息,拉好要用的 “工具库”,剩下的交给 Cargo ,咱们就能专心跑通服务器代码了。
[package]
name = "rust-async-server"
version = "0.1.0"
edition = "2021"[dependencies]
tokio = { version = "1", features = ["full"] }
bytes = "1"
log = "0.4"
env_logger = "0.10"
2. src/main.rs - 程序入口
下面是程序的总入口,核心其实很简单:异步错误处理和同步逻辑,主要靠 Result 类型兜底,配合 await 自动“解包”,再用熟悉的 if let Err、match 等方式接住错误。
- 不管是
run_server还是之前的handle_connection,这些异步函数的返回类型都是Result<(), 错误类型>(比如Result<(), Box<dyn std::error::Error>>)。
这是异步错误处理的基础——函数执行成功就返回 Ok(()),出错就返回 Err(错误信息),把“可能出错”这个事实明确告诉调用者。
- 比如
run_server里绑定端口失败、接受连接失败,都会返回Err,而main函数里就用await去调用它:run_server(&addr).await。 await会自动帮你“解包”Result:如果是Ok,就拿到里面的()继续执行;如果是Err,就直接把错误往上抛,等着被捕获。- 捕获顶层异步错误,
main是整个程序的入口,也是异步任务的“顶层”,这里要接住所有未处理的错误,避免程序崩溃时没任何提示:
if let Err(e) = run_server(&addr).await {eprintln!("Server error: {}", e);
}
这行代码的大概意思是:如果 run_server 执行出错(返回 Err),就把错误信息打印到控制台。
- Rust 不允许“悄悄出错”——如果这里不处理
Err,编译器会直接报错,逼着你正视所有可能的顶层错误,这也是 Rust 程序稳定性高的原因之一。 - 异步子任务的错误处理:之前
run_server里用task::spawn给每个连接开独立异步任务时,也处理了错误:
task::spawn(async move {if let Err(e) = handle_connection(socket, peer_addr).await {warn!("Error handling connection from {:?}: {}", peer_addr, e);}
});
这里要注意:spawn 启动的子任务是“独立”的,它的错误不会自动抛给主线程(不然一个连接出错就搞崩整个服务器,太不划算)。
所以必须在子任务内部用 if let Err 捕获 handle_connection 的错误,比如打印警告日志——这样单个连接的错误不会影响其他连接,服务器的容错性直接拉满。
辅助场景:同步错误处理(比如端口解析):虽然不是异步,但代码里 port 解析的错误处理也很典型:
let port = env::var("PORT").unwrap_or_else(|_| "8080".to_string()) // 环境变量不存在时用默认值.parse::<u16>().expect("Invalid port number"); // 解析失败直接终止程序
expect 是“快速失败”的处理方式:如果解析端口失败(比如用户设了 PORT=abc),就打印提示并终止程序——这种属于“致命错误”(端口不对服务器根本启动不了),没必要继续执行,用 expect 比手动写 match 更简洁。
use std::env;
use log::{info, LevelFilter};
use env_logger::Builder;
use rust_async_server::server::run_server;mod server;
mod connection;
mod request;
mod response;
mod utils;#[tokio::main]
async fn main() {// 初始化日志系统Builder::new().filter_level(LevelFilter::Info).init();// 获取服务器端口,默认为8080let port = env::var("PORT").unwrap_or_else(|_| "8080".to_string()).parse::<u16>().expect("Invalid port number");// 构建服务器地址let addr = format!("0.0.0.0:{}", port);info!("Starting server on {}", addr);// 启动服务器if let Err(e) = run_server(&addr).await {eprintln!("Server error: {}", e);}
}
3. src/server.rs - 服务器核心实现
这段代码是整个RustAsyncServer的入口,如果是有其他预语言的编程基础或则学习过网络编程的人来说,还是挺简单的,主要负责启动TCP服务器、监听端口,还能并发处理所有客户端的连接。
先看核心逻辑:run_server函数接收一个地址(比如"0.0.0.0:8080"),启动服务器后就进入循环,一直等着客户端来连接。
第一步TcpListener::bind(addr).await?,是把服务器绑定到指定端口。这里的await是Tokio异步的关键——绑定操作不会“卡住”整个程序,期间服务器还能做别的事(比如接受其他连接)。这和传统同步服务器“绑定完才能等连接”不一样,Rust的异步模型天生适合高并发,不用开一堆线程浪费资源,这是第一个优势:异步无阻塞,资源利用率拉满。
然后是循环里的listener.accept().await,专门用来“接客”——客户端发起连接时,它会返回一个TCP连接(TcpStream)和客户端地址。这里的错误处理很实在:万一接连接失败(比如网络波动),用warn打个日志就继续等下一个,不会让整个服务器崩溃。这是Rust的Result类型在起作用,强制你处理所有可能的错误,服务器稳定性有保障。
最关键的是task::spawn(async move { ... })——每接一个连接,就给它开一个独立的异步任务,把socket和peer_addr的所有权“转移”到任务里,让handle_connection去处理具体的请求。这里藏着Rust的两大杀招:
- 所有权系统保证并发安全:
async move会把连接资源的所有权带走,每个任务只能操作自己的连接,不会出现“多个任务抢一个连接”的数据竞争。不用手动加锁,编译器在编译时就帮你兜底,根本不会出现线程安全bug。 - 异步任务轻量高效:这些任务不是传统的操作系统线程(开几百个就耗资源),而是Tokio的异步任务,轻巧得很,开几千、几万个都不费内存。这就是Rust服务器能轻松扛住高并发的原因——不用为每个连接浪费线程资源,单进程就能扛住海量请求。
- 任务里的逻辑可以总结为:调用之前的
handle_connection处理连接,万一处理时出错(比如客户端突然断连),就打个警告日志,不影响其他任务运行。相当于“一个客户出问题,不耽误其他客户办事”,服务器的容错性直接拉满。
总结下来,这段代码就干了“监听+分发”两件事,但靠着Rust的异步模型和所有权机制,实现了“高并发、高安全、低资源”——不用复杂配置,就能让服务器又快又稳,这正是Rust做系统级服务的魅力所在。
use std::net::SocketAddr;
use tokio::net::{TcpListener, TcpStream};
use tokio::task;
use log::{info, warn};
use crate::connection::handle_connection;/// 运行异步TCP服务器
pub async fn run_server(addr: &str) -> Result<(), Box<dyn std::error::Error>> {let listener = TcpListener::bind(addr).await?;loop {// 接受新连接,不会阻塞主线程let (socket, peer_addr) = match listener.accept().await {Ok((socket, peer_addr)) => (socket, peer_addr),Err(e) => {warn!("Failed to accept connection: {}", e);continue;}};info!("New connection from: {:?}", peer_addr);// 为每个连接创建单独的任务,实现并发处理// 这里展示了Rust的所有权系统,每个任务获取socket的所有权task::spawn(async move {if let Err(e) = handle_connection(socket, peer_addr).await {warn!("Error handling connection from {:?}: {}", peer_addr, e);}});}
}
4. src/connection.rs - 连接处理模块

下面这段代码是用Rust的异步库Tokio写的“TCP连接处理器”,核心功能是接收客户端的TCP数据、处理HTTP请求并返回响应。顺着代码讲解,就能看出Rust在网络编程里的几个优势。
- 代码的整体的一个逻辑是,
handle_connection函数接收一个TCP连接(TcpStream)和客户端地址,用异步的方式循环处理数据。这种“一个连接一个处理函数”的模式,配合Tokio的异步运行时,能在单线程里同时处理成百上千个连接——这比传统多线程模型省太多资源了,因为不用频繁创建销毁线程,这是Rust在高并发场景的第一个优势:异步I/O的高效性,靠await关键字把等待I/O的时间利用起来,性能拉满。 - 缓冲区有什么用?怎么使用的:
let mut buffer = FixedSizeBuffer::new(4096);这里用了咱们之前说的固定大小缓冲区,4096字节是写死的。为啥这么做?Rust的理念是“内存可控”——如果每次读数据都新建一个动态数组(比如Vec<u8>),频繁分配释放内存会拖慢速度,尤其在高并发时。固定缓冲区一次分配好反复用,内存开销几乎为零,这体现了Rust对内存细节的精确控制,没有垃圾回收在背后偷偷消耗资源,性能更稳定。 - 然后是错误处理部分。你看代码里到处是
match和Result:读数据时match socket.read(...),解析请求时match parse_request(...),出了错就用Err包装返回。Rust的错误处理不是“出了问题再说”,而是强制开发者直面所有可能的错误——比如连接断了、数据格式错了,都得明确处理(像解析失败时返回400错误)。这种“不回避错误”的设计,让服务器跑起来更稳,很少出现莫名其妙的崩溃。 - 还有类型安全的细节。比如
buffer[..n]——这里用切片只取实际读到的n个字节,不会因为缓冲区没填满就多读垃圾数据。Rust的切片类型&[u8]在编译时就确保不会越界,不像有些语言可能不小心访问到缓冲区外的内存,导致安全漏洞。这种编译时的类型检查,从源头堵死了很多低级错误。
连接的生命周期管理:循环里判断“如果是HTTP/1.0或者头部要求关闭连接,就break退出循环”,自然结束连接。整个过程中,socket的所有权始终在函数里,异步操作中也没有多线程争抢的问题——因为Rust的借用规则(&mut socket确保只有一个地方能修改连接),杜绝了“一边读一边写”的数据竞争,这在高并发服务器里太重要了,不用手动加锁也能保证安全。
总的来说,这段代码看着简单,但处处透着Rust的优势:异步模型撑得起高并发,内存控制精打细算,错误处理逼着你写稳定代码,类型系统在编译时就帮你排雷。这就是为啥Rust适合写服务器——跑起来又快又稳,还不容易出安全问题。
use std::net::SocketAddr;
use tokio::net::TcpStream;
use tokio::io::{AsyncReadExt, AsyncWriteExt};
use log::debug;
use crate::request::parse_request;
use crate::response::create_response;
use crate::utils::buffer::FixedSizeBuffer;/// 处理单个TCP连接
pub async fn handle_connection(mut socket: TcpStream, peer_addr: SocketAddr) -> Result<(), Box<dyn std::error::Error>> {// 创建固定大小的缓冲区,避免频繁内存分配// 展示了Rust的内存安全特性,通过类型系统确保缓冲区使用安全let mut buffer = FixedSizeBuffer::new(4096);loop {// 读取数据到缓冲区let n = match socket.read(&mut buffer).await {Ok(n) if n == 0 => {// 连接关闭debug!("Connection closed by {:?}", peer_addr);return Ok(());},Ok(n) => n,Err(e) => {return Err(Box::new(e));}};debug!("Received {} bytes from {:?}", n, peer_addr);// 解析HTTP请求let request = match parse_request(&buffer[..n]) {Ok(req) => req,Err(e) => {// 发送400错误响应let response = b"HTTP/1.1 400 Bad Request\r\nContent-Length: 15\r\n\r\nBad Request";socket.write_all(response).await?;continue;}};debug!("Parsed request: {:?} {}", request.method, request.path);// 生成HTTP响应let response = create_response(&request);// 发送响应socket.write_all(&response).await?;// 如果是HTTP/1.0或Connection: close,则关闭连接if request.version == "HTTP/1.0" || request.headers.get("connection").map(|h| h.to_lowercase() == "close").unwrap_or(false) {break;}}Ok(())
}
5. src/request.rs - 请求解析模块
定义 HTTP 请求长啥样,以及把客户端发来的字节流(比如浏览器的请求)解析成咱们能直接用的格式。跟着代码顺一遍,很容易懂。代码在解析下面。
首先看看http请求的格式:
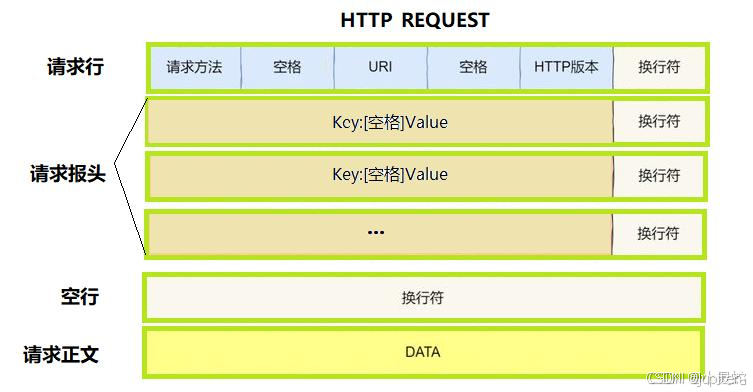
先看HttpRequest结构体 —— 这就是个 “容器”,专门装 HTTP 请求的关键信息:
- method:请求方法,比如 GET、POST;
- path:访问的路径,比如/、/health;
- version:HTTP 版本,一般是HTTP/1.1;
- headers:请求头部,用HashMap存(键值对形式,比如Content-Type: application/json);
- body:请求正文,比如 POST 请求带的表单数据,用字节数组存。
再看核心的parse_request函数,它的作用就是 “翻译”—— 把客户端发过来的原始字节(&[u8]),翻译成上面那个HttpRequest结构体。步骤很直白:
- 先把字节转成字符串:用from_utf8(data),因为 HTTP 请求是文本协议,转成字符串才好解析。转失败(比如有乱码)就返回错误提示,这是 Rust 的Result类型在起作用,错误处理很明确,不用猜。
解析请求行:请求行就是第一行(比如GET / HTTP/1.1)。用lines()按行拆分,split_whitespace()按空格拆分,刚好拿到 “方法、路径、版本” 三个部分,各自转成字符串存起来。少了任何一个就返回错误,避免后续处理出问题。 - 解析请求头部:循环处理剩下的行,直到遇到空行(HTTP 协议里,头部和正文用空行分隔)。每行用split_once(": ")拆成 “键:值”,比如Host: localhost:8080拆成键host、值localhost:8080,存到HashMap里。键转成小写是为了统一(比如有的客户端写Host,有的写host,避免识别不了)。
- 提取请求正文:找到空行的位置(\r\n\r\n),后面的就是正文。用切片data[body_start…]直接截取,转成Vec——Rust 的切片操作不复制数据,省内存,这也是它高效的原因之一。如果没有正文,就返回空数组。
- 最后返回Ok(HttpRequest {…}),把解析好的所有信息打包返回,后续处理请求(比如路由、响应)直接用这个结构体就行。
整个过程就是严格按 HTTP 协议的规矩来 “拆数据”,Rust 的字符串处理、错误处理、集合类型(HashMap)帮咱们把解析做得又安全又顺手 —— 比如不会出现数组越界、不会有未处理的乱码,解析失败了也能明确知道问题在哪。
use std::collections::HashMap;
use std::str::from_utf8;/// HTTP请求结构
pub struct HttpRequest {pub method: String,pub path: String,pub version: String,pub headers: HashMap<String, String>,pub body: Vec<u8>,
}/// 解析HTTP请求
pub fn parse_request(data: &[u8]) -> Result<HttpRequest, &'static str> {// 将字节数据转换为字符串let request_str = from_utf8(data).map_err(|_| "Invalid UTF-8 in request")?;// 查找请求行和头部结束位置let mut lines = request_str.lines();// 解析请求行let request_line = lines.next().ok_or("Empty request")?;let mut parts = request_line.split_whitespace();let method = parts.next().ok_or("Missing method")?.to_string();let path = parts.next().ok_or("Missing path")?.to_string();let version = parts.next().ok_or("Missing version")?.to_string();// 解析头部let mut headers = HashMap::new();let mut body_start = 0;for line in lines {if line.is_empty() {// 头部结束,开始处理正文body_start = request_str.find("\r\n\r\n").ok_or("Invalid request format")? + 4;break;}if let Some((key, value)) = line.split_once(": ") {headers.insert(key.to_lowercase(), value.to_string());}}// 提取请求正文let body = if body_start < data.len() {data[body_start..].to_vec()} else {Vec::new()};Ok(HttpRequest {method,path,version,headers,body,})
}
6. src/response.rs - 响应生成模块
use std::io::Cursor;
use bytes::{Buf, BytesMut};
use crate::request::HttpRequest;/// 根据请求生成HTTP响应
pub fn create_response(request: &HttpRequest) -> Vec<u8> {// 简单的路由处理let (status, content_type, body) = match request.path.as_str() {"/" => ("200 OK", "text/html", b"<h1>Welcome to Rust Async Server</h1><p>Powered by Rust and Tokio</p>"),"/health" => ("200 OK", "text/plain", b"OK"),"/info" => {let info = format!("Method: {}\nPath: {}\nVersion: {}\nHeaders: {:?}", request.method, request.path, request.version, request.headers);("200 OK", "text/plain", info.as_bytes())},_ => ("404 Not Found", "text/html", b"<h1>404 Not Found</h1>")};// 创建响应缓冲区let mut response = BytesMut::new();// 写入响应行response.extend_from_slice(format!("HTTP/1.1 {}\r\n", status).as_bytes());// 写入响应头部response.extend_from_slice(format!("Content-Type: {}\r\n", content_type).as_bytes());response.extend_from_slice(format!("Content-Length: {}\r\n", body.len()).as_bytes());response.extend_from_slice(b"Connection: keep-alive\r\n");response.extend_from_slice(b"Server: RustAsyncServer/0.1\r\n");// 头部结束response.extend_from_slice(b"\r\n");// 写入响应正文response.extend_from_slice(body);// 转换为Vec<u8>response.to_vec()
}
上面这段代码作为新手看着有点复杂,但实际上讲就是一个典型的“HTTP响应生成器”——收到一个请求,它就按规矩拼出一个客户端能看懂的响应。下面一起来看看怎么实现的。
- 先看函数名
create_response,参数是&HttpRequest,返回Vec<u8>。意思很简单:传入一个请求的引用,返回一串字节(就是最终要发给客户端的响应数据)。 - 开头那部分
match request.path.as_str()是核心的“路由逻辑”。比如请求访问的是"/"(首页),就返回200状态、html类型的欢迎页面;访问"/health"(健康检查),就返回简单的“OK”;访问"/info",就把请求里的方法、路径这些信息拼起来返回;其他路径就返回404。这就像前台接待,问清你要找哪个房间,就给你对应的牌子。 - 接下来是构建响应的过程。用
BytesMut::new()创建了一个缓冲区——这东西比普通的Vec<u8>好用,拼接字节数据特别方便,网络编程里常用它来攒数据。
然后一步步往缓冲区里放东西:
- 先写响应行,比如
"HTTP/1.1 200 OK\r\n",告诉客户端“用的HTTP1.1协议,请求成功”; - 再写响应头:
Content-Type说明返回的是啥类型数据(html还是plain文本),Content-Length告诉客户端正文有多长,还有保持连接、服务器标识这些信息。每个头后面都带\r\n,这是HTTP协议的规矩; - 写完头之后,必须加一个
\r\n空行,告诉客户端“头结束了,下面是正文”; - 最后把正文内容(比如欢迎页面的html代码)塞进去。
这是http的响应的格式,如下图:

最后用response.to_vec()转成Vec<u8>返回,因为网络传输最终靠的就是字节数组。
整个过程其实就是严格按HTTP协议的格式“拼字符串”,只不过用Rust的BytesMut和字符串格式化让这个过程变顺手了。而且全程用的是不可变引用(&HttpRequest),既安全又省内存——这也是Rust处理这类数据的优势,不用瞎复制,性能自然就上去了。
7. src/utils/buffer.rs - 高效缓冲区实现
use std::marker::PhantomData;/// 固定大小的缓冲区实现
/// 展示了Rust的所有权和类型安全特性
pub struct FixedSizeBuffer<const N: usize> {buffer: [u8; N],_marker: PhantomData<[u8; N]>,
}impl<const N: usize> FixedSizeBuffer<N> {/// 创建新的固定大小缓冲区pub fn new() -> Self {Self {buffer: [0; N],_marker: PhantomData,}}/// 重置缓冲区内容pub fn clear(&mut self) {self.buffer = [0; N];}/// 获取缓冲区原始数据引用pub fn as_bytes(&self) -> &[u8] {&self.buffer}/// 获取缓冲区可变数据引用pub fn as_mut_bytes(&mut self) -> &mut [u8] {&mut self.buffer}
}// 实现Deref和DerefMut特性,让FixedSizeBuffer可以像普通slice一样使用
impl<const N: usize> std::ops::Deref for FixedSizeBuffer<N> {type Target = [u8];fn deref(&self) -> &Self::Target {&self.buffer}
}impl<const N: usize> std::ops::DerefMut for FixedSizeBuffer<N> {fn deref_mut(&mut self) -> &mut Self::Target {&mut self.buffer}
}
上面的这段代码其实就是实现了一个固定大小的字节缓冲区,下面结合代码看看主要干了什么:
- 先看结构体定义:FixedSizeBuffer。这里的const N是个关键,意思是你用这个结构体的时候得指定大小,比如FixedSizeBuffer<512>就代表一个 512 字节的缓冲区。这是 Rust 的常量泛型,好处是大小在编译时就定死了 —— 你想往 512 字节的缓冲区里塞 600 字节的数据?编译阶段就会报错,根本跑不起来,避免了很多运行时才发现的内存问题。
- 结构体里的buffer: [u8; N]是实际存数据的地方,就是个固定长度的字节数组;_marker那个是个类型标记,不占实际内存,主要帮编译器更清楚地识别类型关联,不用太纠结。
- 再看方法:new()是创建缓冲区,把数组初始化成全 0,保证新缓冲区里没有脏数据;clear()是把缓冲区重置为全 0,方便重复使用;as_bytes()和as_mut_bytes()分别返回不可变和可变的字节切片 —— 这体现了 Rust 的借用规则,想读就拿不可变引用,想改就拿可变引用,编译器会确保不会出现一边读一边改的混乱情况。
- 最后那两个Deref和DerefMut的实现,是为了方便使用。比如你创建了一个buf: FixedSizeBuffer<10>,本来得用buf.buffer[0]访问第一个字节,现在直接buf[0]就行,跟用普通字节切片一样顺手,这就是 Rust零成本抽象的体现 —— 方便了开发者,又不影响性能。
总的来说,这东西就是个好用又安全的固定大小缓冲区,在网络传输、数据暂存这些场景里很实用,而且全程靠 Rust 的类型检查和内存规则帮你兜底,不容易出内存相关的 bug。
如何运行项目
1. 安装Rust和Cargo(https://www.rust-lang.org/tools/install)
Linux指令:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
2. 创建项目目录并初始化
mkdir rust-async-server
cd rust-async-server
cargo init
**3. 按照上述代码创建相应文件

4. 构建并运行项目
cargo run

最后说说,个人认为rust对比现如今流程的语言,到底有哪些优势?
- 为了更直观地展示Rust的优势,下面提供与其他语言实现相同功能的代码对比:
内存安全对比:C++ vs Rust
C++版本(潜在的内存问题):
// C++中可能存在的内存问题示例
char* buffer = new char[4096];
size_t bytes_read = socket.read(buffer, 4096);
// 忘记释放内存,导致内存泄漏
// delete[] buffer;
Rust版本(内存安全保证):
// Rust中的内存安全示例
let mut buffer = FixedSizeBuffer::new(4096);
let bytes_read = socket.read(&mut buffer).await?;
// 离开作用域时自动释放资源,无需手动管理
并发模型对比:Java vs Rust
Java版本(每个连接一个线程):
// Java线程池处理连接示例
ExecutorService executor = Executors.newFixedThreadPool(100);
while (true) {Socket socket = serverSocket.accept();executor.submit(() -> handleConnection(socket));
}
// 每个线程占用几MB内存,难以扩展到数万个连接
Rust版本(异步任务处理):
// Rust异步任务处理连接示例
loop {let (socket, peer_addr) = listener.accept().await?;task::spawn(async move {handle_connection(socket, peer_addr).await;});
}
// 异步任务内存占用极低,可以处理数万个连接
内存安全:无需垃圾回收的安全保障
Rust的所有权系统
Rust的所有权系统是其最核心的创新,也是该项目最突出的语言优势之一。在异步网络服务器中,这一特性主要体现在以下几个方面:
// 服务器核心逻辑中的所有权转移示例
// 每个连接创建单独的任务,socket所有权被转移到任务中task::spawn(async move {if let Err(e) = handle_connection(socket, peer_addr).await {warn!("Error handling connection from {:?}: {}", peer_addr, e);}
});
与其他语言对比
- 相比C/C++:Rust通过编译时所有权检查,彻底消除了悬垂指针、缓冲区溢出等常见内存安全问题,同时保持了接近C/C++的性能。在C/C++中,开发人员需要手动管理内存,容易出现内存泄漏和使用已释放内存的问题。
- 相比Java/Python:Rust无需垃圾回收器(GC)即可保证内存安全,避免了GC带来的性能抖动。在高并发网络服务器场景中,GC暂停可能导致请求处理延迟增加,而Rust完全避免了这一问题。
- 相比Go:虽然Go的垃圾回收器比传统JVM更高效,但Rust在内存控制上更加精细,没有运行时开销。
在本项目中,所有权系统确保了每个网络连接的资源能够被正确管理:
- 当连接处理任务完成时,socket资源会自动释放
- 编译器会检查并防止悬垂引用和数据竞争
- 无需手动管理内存,减少了内存泄漏的风险
并发模型:轻量高效的异步处理
Rust的异步编程模型
本项目使用Tokio异步运行时实现了高性能的并发处理,充分展示了Rust异步编程的优势:
// 异步连接处理示例
#[tokio::main]
async fn main() {// ...初始化代码...// 启动服务器if let Err(e) = run_server(&addr).await {eprintln!("Server error: {}", e);}
}// 异步接受连接
async fn run_server(addr: &str) -> Result<(), Box<dyn std::error::Error>> {let listener = TcpListener::bind(addr).await?;loop {let (socket, peer_addr) = listener.accept().await?;// ...处理连接...}
}
与其他语言对比
- 相比Java:Java的线程模型每个连接通常需要一个线程,内存占用高(每个线程栈通常需要几MB内存),难以处理大量并发连接。而Rust的异步任务是轻量级的,内存占用极低,可以同时处理数万个连接。
- 相比Python:Python的GIL(全局解释器锁)限制了多线程的性能,而异步编程在Python中需要显式的异步/等待语法,且生态系统不如Rust成熟。Rust的异步模型更加高效,且没有GIL限制。
- 相比Go:Go的goroutines和channels提供了简洁的并发模型,但Rust的异步模型提供了更精细的控制和更低的抽象成本。Rust的Future特质允许更灵活的组合和控制流。
本项目的异步设计使得服务器能够:
- 以极低的内存开销处理大量并发连接
- 避免I/O操作阻塞事件循环
- 通过任务调度优化CPU利用率
性能表现:接近底层硬件的效率
Rust的零成本抽象
Rust的"零成本抽象"原则确保了高级语言特性不会带来运行时开销,这在项目的多个部分得到了体现:
// FixedSizeBuffer实现了Deref和DerefMut特性,提供零成本抽象
impl<const N: usize> std::ops::Deref for FixedSizeBuffer<N> {type Target = [u8];fn deref(&self) -> &Self::Target {&self.buffer}
}impl<const N: usize> std::ops::DerefMut for FixedSizeBuffer<N> {fn deref_mut(&mut self) -> &mut Self::Target {&mut self.buffer}
}
与其他语言对比
- 相比C/C++:Rust的抽象层次更高,但编译优化后性能接近C/C++。Rust的静态分析能力甚至可能在某些情况下生成比手动编写的C/C++更优化的代码。
- 相比Java:Rust没有JVM开销,启动更快,内存占用更小。特别是在微服务和容器化部署场景中,这些优势更为明显。
- 相比Python/JavaScript:Rust是编译型语言,无需解释器,执行速度显著更快。对于CPU密集型的请求处理,性能提升可达数倍甚至数十倍。
在本项目中,零成本抽象和高效内存管理使得服务器能够:
- 快速处理HTTP请求解析和响应生成
- 减少内存分配和拷贝操作
- 优化缓存利用率
类型系统:编译时错误检测
Rust的强类型系统
Rust的类型系统提供了强大的编译时检查能力,能够在代码运行前捕获许多潜在问题:
// HTTP请求解析中的类型安全处理
pub fn parse_request(data: &[u8]) -> Result<HttpRequest, &'static str> {// 将字节数据转换为字符串let request_str = from_utf8(data).map_err(|_| "Invalid UTF-8 in request")?;// 解析请求行let request_line = lines.next().ok_or("Empty request")?;let mut parts = request_line.split_whitespace();let method = parts.next().ok_or("Missing method")?.to_string();// ...更多解析代码...
}
与其他语言对比
- 相比C/C++:Rust的类型系统更加严格,提供了更多编译时安全检查。例如,Rust的借用检查器可以防止空指针解引用和悬垂指针等问题。
- 相比Java:Rust的泛型实现没有类型擦除,提供了更好的运行时性能和类型安全性。Rust的模式匹配功能也比Java的switch语句更强大。
- 相比Python/JavaScript:Rust的静态类型系统可以在编译时捕获许多动态类型语言中只有在运行时才会发现的错误,大大提高了代码的可靠性。
本项目的类型安全设计使得:
- 许多潜在的错误在编译时就被发现和修复
- 代码的自文档化程度提高,降低了维护成本
- 减少了运行时类型检查的开销
错误处理:优雅而安全的错误管理
Rust的错误处理机制
Rust采用Result类型和?操作符提供了优雅而安全的错误处理机制:
// 连接处理中的错误处理示例
pub async fn handle_connection(mut socket: TcpStream, peer_addr: SocketAddr) -> Result<(), Box<dyn std::error::Error>> {// ...处理代码...// 读取数据,使用?操作符传播错误let n = socket.read(&mut buffer).await?;// 解析请求,处理特定错误let request = match parse_request(&buffer[..n]) {Ok(req) => req,Err(e) => {// 发送400错误响应let response = b"HTTP/1.1 400 Bad Request\r\nContent-Length: 15\r\n\r\nBad Request";socket.write_all(response).await?;continue;}};// ...更多处理代码...
}
与其他语言对比
- 相比C/C++:Rust的错误处理更加显式和类型安全,避免了C/C++中常见的错误码忽略问题。Rust的
Result类型强制开发人员处理可能的错误。 - 相比Java:Rust的错误处理不需要异常机制,避免了异常带来的性能开销和控制流混乱。Rust的
?操作符比Java的try-catch块更加简洁。 - 相比Python:虽然Python也有异常处理机制,但Rust的静态类型系统确保了所有可能的错误链接都能被考虑到,减少了未处理异常的风险。
本项目的错误处理设计使得:
- 服务器能够优雅地处理各种异常情况,保持稳定运行
- 错误信息更加清晰和具体,便于调试和问题排查
- 避免了因错误处理不当导致的安全漏洞
工具链与生态系统
Rust的开发工具
Rust提供了丰富的开发工具和成熟的生态系统,为本项目的开发和维护提供了有力支持:
- Cargo:强大的包管理和构建工具,简化了依赖管理和项目构建
- Rustfmt:自动代码格式化工具,保持代码风格一致
总结
通过对Rust异步网络服务器项目的深入分析,我们可以清晰地看到Rust语言在以下几个方面的显著优势:
- 内存安全:所有权系统和借用检查器在编译时确保内存安全,无需垃圾回收器
- 高性能:零成本抽象和接近底层硬件的效率,性能可与C/C++相媲美
- 并发处理:轻量级异步任务模型,能够高效处理大量并发连接
- 类型系统:强大的静态类型检查,在编译时捕获潜在错误
- 错误处理:优雅而安全的错误处理机制,提高代码可靠性
- 现代工具链:丰富的开发工具和成熟的生态系统
与C/C++相比,Rust提供了更好的内存安全性;与Java/Python相比,Rust提供了更高的性能和更低的资源占用;与Go相比,Rust提供了更精细的控制和更强的类型系统。
Rust语言的这些优势使其特别适合构建高性能、可靠的网络服务,尤其是在需要处理大量并发连接、对延迟敏感的场景中。随着Rust生态系统的不断成熟和社区的快速发展,Rust在系统编程和网络服务领域的应用前景将会更加广阔。
想了解更多关于Rust语言的知识及应用,可前往华为开放原子旋武开源社(https://xuanwu.openatom.cn/),了解更多资讯~