TensorFlow深度学习实战(9)——卷积神经网络应用
TensorFlow深度学习实战(9)——卷积神经网络应用
- 0. 前言
- 1. 计算机视觉
- 1.1 分类和定位
- 1.2 语义分割
- 1.3 目标检测
- 1.4 实例分割
- 2. 迁移学习
- 2.1 Keras Applications
- 2.2 TensorFlow Hub
- 3. 视觉问答
- 4. 神经网络的可解释性
- 5. 视频处理
- 6. 文本文档
- 7. 音频和音乐
- 8. 卷积操作总结
- 8.1 常规 CNN
- 8.2 扩张卷积
- 8.3 转置卷积
- 8.4 可分离卷积
- 8.5 深度卷积
- 8.6 深度可分离卷积
- 小结
- 系列链接
0. 前言
在卷积神经网络 (Convolutional Neural Network, CNN) 一节中,我们已讨论了 CNN,CNN 架构能够有效用于图像分类任务中。基本的 CNN 架构可以通过多种方式组合和扩展,以解决各种更复杂的任务。在本节中,我们将研究目标检测、图像分割等计算机视觉任务,并展示如何通过将 CNN 转换为更大、更复杂的架构来解决这些任务。
1. 计算机视觉
1.1 分类和定位
在分类和定位任务中,不仅需要预测图像中对象的类别,还要预测对象在图像中的边界框坐标。这类任务假设图像中只有一个对象实例。
这可以通过在经典的分类网络原有的分类头 (classification head) 外附加一个回归头 (regression head) 来实现。在分类网络中,卷积和池化操作的最终输出,称为特征图,输入到一个全连接网络,网络生成一个类别概率向量。这个全连接网络称为分类头,它使用分类损失函数 LcL_cLc,如分类交叉熵进行调优。
类似地,回归头是另一个全连接网络,它接收特征图,并生成一个向量 (x,y,w,h)(x, y, w, h)(x,y,w,h),表示边界框的左上角坐标 (xxx 和 yyy) 以及宽度和高度。使用连续损失函数 (LrL_rLr),如均方误差进行调优。整个网络通过两个损失函数的线性组合进行调优,即:
L=αLc+(1−α)LrL=\alpha L_c+(1-\alpha)L_r L=αLc+(1−α)Lr
其中,α\alphaα 是一个超参数,取值范围为 0 到 1。下图显示了一个经典的分类和定位网络架构:
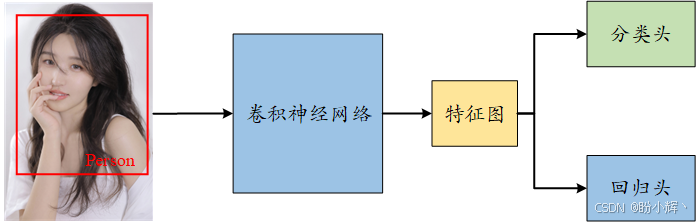
可以看到,与经典的 CNN 分类网络相比,区别在于增加了回归头。
1.2 语义分割
语义分割是另一类基于基本分类思想的问题,目标是将图像中的每一个像素分类为适当类别。
最简单的实现方法是为每个像素构建一个分类器网络,输入是每个像素周围的小范围区域。但在实际应用中,这种方法效果并不好,因此可以通过卷积操作处理图像,这样既能增加特征的深度,又能保持图像的宽度和高度不变。每个像素会得到一个特征图,通过一个全连接网络预测像素类别。但这种方法在实践中同样效率较低,通常不被采用。
第三种方法是使用编码器-解码器网络,其中编码器减少图像的宽度和高度,但增加其深度(特征数量),而解码器使用转置卷积操作来增加图像的大小并减少其深度,转置卷积(或上采样)是与正常卷积相反的过程。编码器-解码器网络的输入是图像,输出是分割图。U-Net 是一种流行的编码器-解码器架构,最初用于生物医学图像分割,并且在编码器和解码器之间有额外的跳跃连接。

1.3 目标检测
物体检测任务类似于分类和定位任务。最大不同在于,目标检测任务的图像中包含多个对象,需要为每一个对象输出其类别和边界框坐标。
解决此问题的一个简单方法是对输入图像进行许多随机裁剪,对于每个裁剪区域,应用之前描述的分类和定位网络。但这种方法在计算上代价高昂,并且成功的可能性不大。
更实用的方法是使用类似选择性搜索 (Selective Search) 的工具,利用传统计算机视觉技术在图像中找到可能包含对象的区域。这些区域称为区域提议,而检测这些区域的网络称为基于区域的卷积神经网络 (Region-based CNN, R-CNN)。在原始的 R-CNN 中,这些区域调整大小后输入到网络中,生成图像向量,这些向量通过基于支持向量机 (Support Vector Machine, SVM) 的分类器进行分类,并通过对图像向量使用线性回归网络来纠正外部工具提出的边界框。R-CNN 工作流程可以使用下图表示:

Fast R-CNN 是对 R-CNN 网络的改进。Fast R-CNN 仍然利用外部工具获取区域提议,但不是将每个区域提议单独输入 CNN,而是将整个图像输入 CNN,然后将区域提议映射到生成的特征图上。每个感兴趣的区域 (Region Of Interest, ROI) 通过 ROI 池化层,然后传递到一个全连接网络,生成 ROI 的特征向量。
ROI 池化是使用 CNN 进行目标检测任务中常用的操作。ROI 池化层使用最大池化将有效的 ROI 内的特征转换为一个具有固定空间大小的特征图,尺寸为 H x W (其中 H 和 W 是两个超参数)。然后将特征向量输入到两个全连接网络中,一个用于预测 ROI 的类别,另一个用于修正提议的边界框坐标。Fast R-CNN 工作流程如下所示:
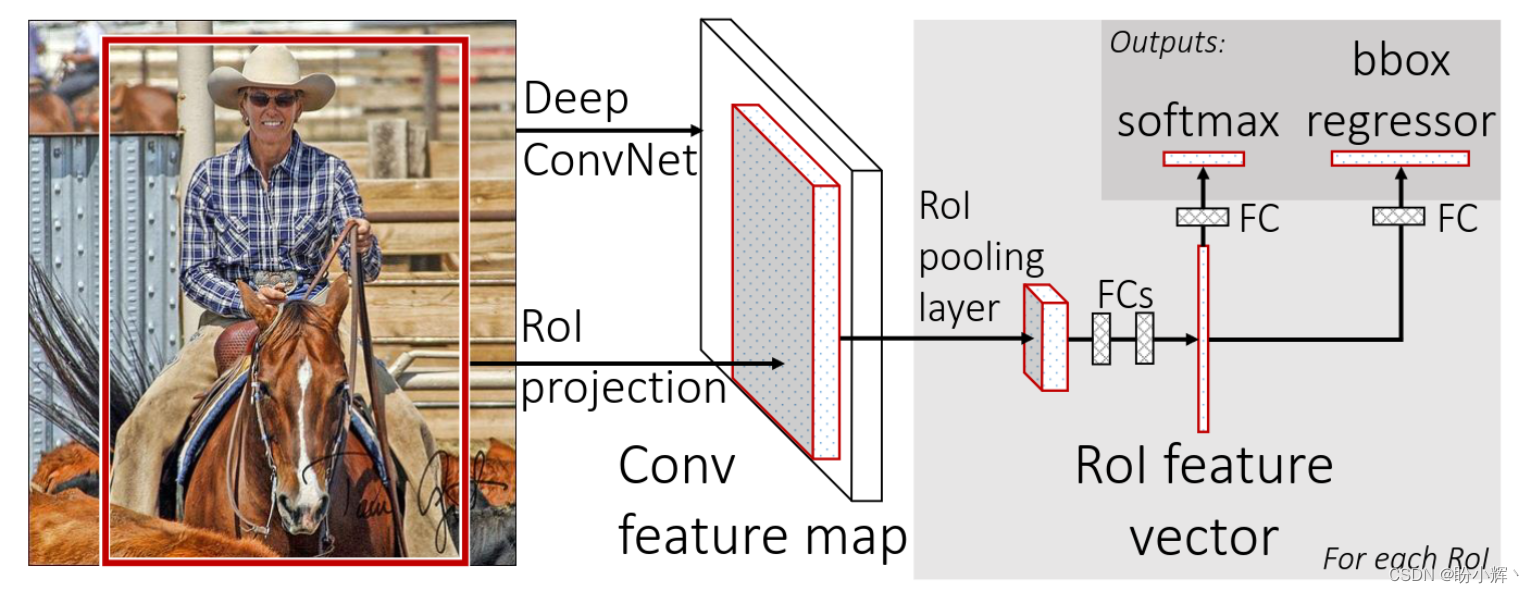
Fast R-CNN 比 R-CNN 快约 25 倍。Faster R-CNN 对 Fast R-CNN 的进一步改进,移除了外部区域提议机制,并使用区域提议网络 (Region Proposal Network, RPN),一个可训练的组件进行替代,且该组件直接嵌入到网络内部。区域提议网络的输出与特征图结合,并通过类似于 Fast R-CNN 网络的管道处理,如下图所示。

Faster R-CNN 网络的速度比 Fast R-CNN 网络快约 10 倍,比 R-CNN 网络快大约 250 倍。
另一类经典的目标检测网络是 YOLO (You Only Look Once)。在这类方法中,每张图像会被划分成预定义数量的区域,通常使用网格划分。在 YOLO 中,使用的是 7 x 7 的网格,得到 49 个子图像。对每个子图像应用一组预定的具有不同纵横比的锚框。给定 B 个边界框和 C 个对象类别,每张图像的输出是一个大小为 (7 * 7 * (5B + C)) 的向量。每个边界框都有一个置信度和坐标 (x, y, w, h),每个网格会预测该区域内检测到的不同目标的概率。YOLO 网络是一个卷积神经网络,最终的预测和边界框是通过聚合这个向量中的信息得到的。在 YOLO 中,使用一个卷积网络同时预测边界框和相关的类别概率。
1.4 实例分割
实例分割类似于语义分割,将图像的每个像素与类别标签相关联,但有以下区别,首先,它需要区分图像中同一类别的不同实例;其次,它不需要标注图像中的每一个像素。从某些方面来说,实例分割也类似于目标检测,不同之处在于,不是要预测边界框,而是希望预测覆盖每个对象的二进制掩码。
Mask R-CNN 是在 Faster R-CNN 基础上增加了一个卷积神经网络 (Convolutional Neural Network, CNN),这个 CNN 位于其回归头部前面,输入为每个 ROI 的边界框坐标,并将其转换为二进制掩码。
Mask R-CNN 整体架构如下:

在本节中,我们介绍了计算机视觉中流行的网络架构,这些架构都是由基本卷积神经网络和全连接架构组成,这种可组合性是深度学习最强大的特性之一。
2. 迁移学习
迁移学习的一个优点是可以重用预训练网络,从而节省时间和资源。有很多预训练网络工具,使用最广泛的工具包括 Keras Applications 和 TensorFlow Hub。
2.1 Keras Applications
Keras Applications 包含了多个用于图像分类的模型,这些模型(如 Xception、VGG16、VGG19、ResNet、ResNeXt、InceptionV3、InceptionResNetV2、MobileNet、DenseNet 和 NASNet )在 ImageNet 上进行了训练。
2.2 TensorFlow Hub
TensorFlow Hub (TF Hub) 是另一个预训练模型的集合。TensorFlow Hub 包括文本分类、句子编码、图像分类、特征提取、使用 GANs 生成图像以及视频分类的模型。
接下来,通过一个示例介绍如何使用 TF Hub。使用 MobileNetv2 创建一个简单的图像分类器:
import matplotlib.pylab as plt
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np
import PIL.Image as Imageclassifier_url ="https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2" #@param {type:"string"}IMAGE_SHAPE = (224, 224)# wrap the hub to work with tf.kerasclassifier = tf.keras.Sequential([hub.KerasLayer(classifier_url, input_shape=IMAGE_SHAPE+(3,))
])grace_hopper = tf.keras.utils.get_file('image.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg')
grace_hopper = Image.open(grace_hopper).resize(IMAGE_SHAPE)
grace_hopper = np.array(grace_hopper)/255.0
result = classifier.predict(grace_hopper[np.newaxis, ...])
predicted_class = np.argmax(result[0], axis=-1)
print (predicted_class)
可以看到,用法非常简单,只需使用 hub.KerasLayer() 包装 Hub 层。
3. 视觉问答
神经网络的一个优点是可以将不同的数据类型结合起来,提供统一的解释。例如,视觉问答 (Visual Question Answering, VQA) 结合了图像识别和文本自然语言处理。模型训练可以使用 VQA 数据集,该数据集包含关于图像的开放式问题。这些问题需要对视觉、语言和常识有所理解才能回答。

如果想尝试 VQA 任务,首先需要获取合适的训练数据集,常用数据集包括 VQA 数据集、CLEVR 数据集和 FigureQA 数据集;此外,也可以使用 Kaggle 的 VQA 挑战。然后,可以构建一个结合 CNN 和循环神经网络 (Recurrent Neural Network, RNN) 的模型。CNN 接收一个三通道 (224 x 224) 的图像作为输入,并为图像生成特征向量:
# Import Keras
import tensorflow as tf
from tensorflow.keras import layers, models# IMAGE
# Define CNN for visual processing
cnn_model = models.Sequential()
cnn_model.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=(224, 224, 3)))
cnn_model.add(layers.Conv2D(64, (3, 3), activation='relu'))
cnn_model.add(layers.MaxPooling2D(2, 2))
cnn_model.add(layers.Conv2D(128, (3, 3), activation='relu', padding='same'))
cnn_model.add(layers.Conv2D(128, (3, 3), activation='relu'))
cnn_model.add(layers.MaxPooling2D(2, 2))
cnn_model.add(layers.Conv2D(256, (3, 3), activation='relu', padding='same'))
cnn_model.add(layers.Conv2D(256, (3, 3), activation='relu'))
cnn_model.add(layers.Conv2D(256, (3, 3), activation='relu'))
cnn_model.add(layers.MaxPooling2D(2, 2))
cnn_model.add(layers.Flatten())
cnn_model.summary()#define the visual_model with proper input
image_input = layers.Input(shape=(224, 224, 3))
visual_model = cnn_model(image_input)
文本可以通过 RNN 编码,接收一个文本片段(问题)作为输入,并生成文本的特征向量:
# TEXT
#define the RNN model for text processing
question_input = layers.Input(shape=(100,), dtype='int32')
emdedding = layers.Embedding(input_dim=10000, output_dim=256, input_length=100)(question_input)
encoded_question = layers.LSTM(256)(emdedding)
然后,将两个特征向量(一个来自图像,一个来自文本)合并成一个联合向量,并将其作为输入提供给一个全连接网络,得到最终模型:
# combine the encoded question and visual model
merged = layers.concatenate([encoded_question, visual_model])
#attach a dense network at the end
output = layers.Dense(1000, activation='softmax')(merged)#get the combined model
vqa_model = models.Model(inputs=[image_input, question_input], outputs=output)
vqa_model.summary()
如果我们有一组带标签的图像,就可以学习描述图像的最佳问题和答案。
4. 神经网络的可解释性
神经网络的一个研究方向是理解神经网络到底学到了什么,以便了解神经网络为何能够如此准确地识别图像,即神经网络的可解释性。激活图旨在可视化平均激活函数的特征,通过这种方式,激活图生成了一个从网络视角看到的图像:

在以上图像中,用于视觉分类的 InceptionV1 网络学习了许多图像的完整特征,比如电子产品、屏幕、相机、建筑物、食物、动物耳朵和植物等。需要注意的是,网格单元被标记为置信度最高的分类,并且网格单元的大小取决于其内部激活的平均数量。这种表示方式允许我们检查网络的不同网络层以及激活函数如何响应输入。
我们已经学习了多种处理图像的 CNN 技术。接下来,我们将介绍视频处理。
5. 视频处理
在本节中,我们将介绍如何将 CNN 应用于视频以及可以使用的不同技术。
视频分类是一个活跃的研究领域,因为处理这种数据类型所需的数据量非常大。内存需求通常已经接近现代 GPU 的极限,可能需要在多台机器上进行分布式训练。目前,研究人员正在探索不同的研究方法:
- 逐帧分类,每次处理一个视频帧,将每一帧视为一个单独的图像,并使用
2D CNN进行处理,这种方法将视频分类问题简化为图像分类问题。每个视频帧都会产生一个分类输出,最终通过统计频率最高的类别作为整个视频的分类结果 - 构建一个单一的网络,将
2D CNN与RNN结合使用。这个方法的思想是CNN处理图像,而RNN处理视频中的序列信息。这类网络的训练较为困难,因为需要优化的参数量非常高 - 使用
3D ConvNet,3D ConvNet是对2D ConvNet的扩展,作用于3D张量(时间、图像宽度和图像高度)。这种方法是图像分类的一种扩展,3D ConvNet同样可能难以训练 - 不直接使用
CNN进行分类,而是将CNN用于存储每帧的离线特征。其核心思想是,特征提取可以通过迁移学习变得非常高效,在提取所有特征后,可以将它们作为一组输入传递给RNN,RNN学习跨多个帧的序列,并得出最终分类结果 - 第五种方法是
3D ConvNet方法的简单变体,最终层使用MLP而不是RNN,这种方法在计算需求方面更节省资源 - 第六种方法是
3D ConvNet方法的另一变体,其中特征提取阶段使用3D CNN提取空间和视觉特征,然后将这些特征传递给RNN或MLP
选择使用何种方法依赖于具体的应用。前三种方法通常计算开销更大但相对简单,而后三种方法则成本较低,并且通常能取得更好的性能。
我们已经介绍了 CNN 在图像和视频应用中的使用。接下来,我们将这些思想应用于文本上下文中。
6. 文本文档
表面看,文本和图像似乎几乎没有相似之处。但如果我们将一个句子或文档表示为矩阵,那么这个矩阵图像矩阵的区别并不大,在图像矩阵中,每个元素表示一个像素。那么,问题在于如何将一段文本表示为矩阵。矩阵的每一行是一个表示文本基本单元的向量,基本单元可以定义为字符,也可以定义为单词,或者将相似的单词聚合在一起,然后用向量表示每个集群。
需要注意的是,无论选择何种基本单元,都需要将基本单元映射到整数 ID,以便将文本视为矩阵。例如,如果有一个包含 10 行文本的文档,每行是一个 100 维的嵌入,那么可以用一个 10 x 100 的矩阵表示文档。在这个矩阵中,如果句子 X 包含由位置 Y 表示的嵌入向量,则元素会被激活。文本实际上并不完全是一个矩阵,更像是一个向量,因为位于相邻行的两个单词之间几乎没有关联。这是与图像不同,图像中位于相邻行的两个像素很可能存在某种程度的相关性。
将文本表示为向量,会丢失单词的位置信息。但实践证明,在许多实际应用中,了解一个句子是否包含特定的基本单元(字符、单词或聚合)是最重要的信息,即使并不了解该基本单元在句子中的具体位置。
7. 音频和音乐
我们已经学习了如何使用 CNN 处理图像、视频和文本。接下来,我们如何将 CNN 应用于音频处理。
使用深度学习模型合成音频之所以困难,是因为每个数字声音都是基于每秒 16,000 个采样点(甚至更多),而构建一个预测模型,学习基于之前的所有采样点来重现一个新样本,这是一个非常具有挑战性的任务。
WaveNet 是一种深度生成模型,用于生成原始音频波形。这项突破性技术由 Google DeepMind 提出,旨在教会计算机如何说话,结果令人印象深刻。实验显示,WaveNet 改进了文本转语音 (Text-to-Speech, TTS) 系统,使得合成语音与人类语音之间的差异减少了 50%。比较使用的指标称为平均意见评分 (Mean Opinion Score, MOS),这是一个主观的配对比较测试。在 MOS 测试中,受试者在听完每个声音刺激后,在从“差” (1) 到“优秀” (5) 的五分制上评估声音的自然程度。WaveNet 还可用于令计算机生成钢琴音乐等乐器的声音。
TTS 系统通常分为两类,拼接式和参数式:
- 拼接式
TTS是将单个语音片段先进行存储,然后在需要重现声音时重新组合。然而,这种方法不具备扩展性,因为只能重现已存储的语音片段,无法生成新声音或不同类型的音频 - 参数式
TTS通过创建模型来存储所有待合成音频的特征。在WaveNet出现之前,使用参数式TTS生成的音频不如拼接式TTS自然。WaveNet通过直接建模音频声音的生成显著提高了生成音频的自然程度,而不是使用中间信号处理算法
理论上讲,WaveNet 可以看作是由若干个一维卷积层堆叠而成的网络,每层卷积的步长为 1,并且没有池化层。输入和输出的维度上是相同的,因此卷积网络非常适合建模序列数据(如音频)。研究表明,为了使输出神经元的感受野 (receptive field) 达到较大的大小,需要使用大量的大尺寸卷积核或极大地增加网络深度。神经元的感受野是指该层中的神经元能够接收来自上一层的哪些输入。因此,纯卷积神经网络在学习如何合成音频时并不是特别有效。
WaveNet 的核心是扩张因果卷积 (Dilated Causal Convolutions,或称空洞卷积),这意味着在应用卷积层的卷积核时会跳过一些输入值。因此,扩张卷积就是带孔的卷积。例如,在一维中,大小为 3 的卷积核 w,如果扩张为 1,则会计算以下和:w[0] * x[0] + w[1] * x[2] + w[2] * x[4]。
简而言之,在扩张卷积中,通常步幅为 1,但并不限制使用其他步幅,下图展示了扩张(孔)大小为 0、1、3 时的情况:
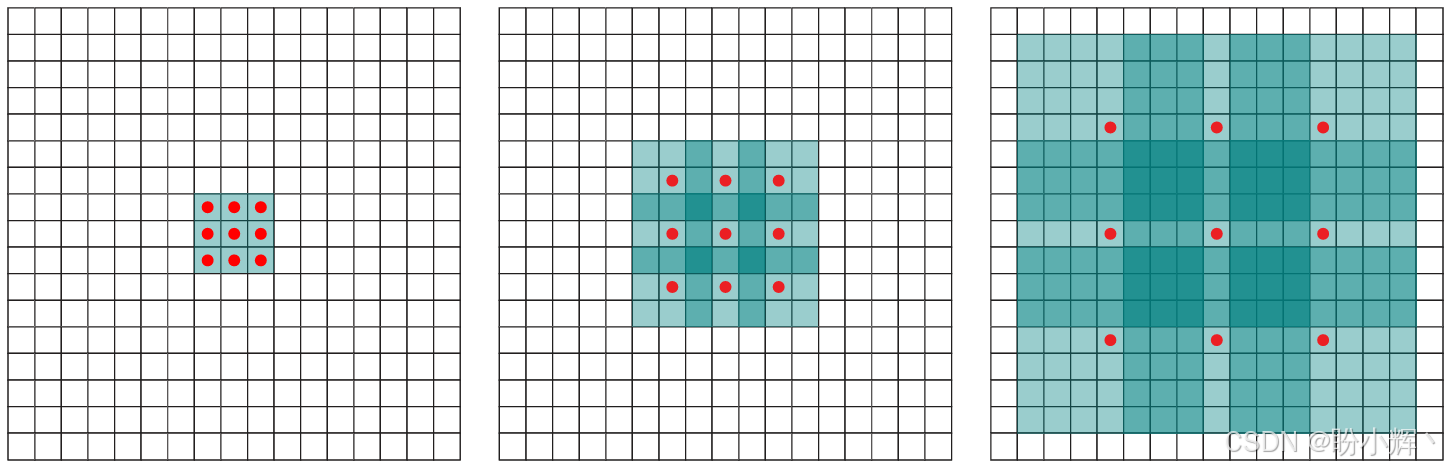
由于引入了孔的概念,可以堆叠多个扩张卷积层,使用指数增长的过滤器,并学习长期输入依赖关系,而不需要使用过于深的网络。因此,WaveNet 是一种卷积网络,其卷积层具有多种扩张因子,使感受野随着深度的增加而指数增长,从而有效覆盖数千个音频时间步。
在训练过程中,输入是从人类语音中录制的声音。波形量化为固定的整数范围。WaveNet 定义了一个初始卷积层,仅访问当前和之前的输入。然后,是多个扩张卷积层,仍然仅访问当前和之前的输入。最后,使用一系列全连接层结合之前的结果,然后是用于分类输出的 softmax 激活函数。
在每一步中,从网络中预测一个值并反馈到输入中。同时,计算下一步的新预测。损失函数是当前步骤的输出与下一步骤的输入之间的交叉熵。下图显示了 WaveNet 堆叠及其感受野的可视化,需要注意的是,生成过程可能较慢,因为波形必须按顺序合成,必须首先采样 xtx_txt,才能获得 x>tx_{>t}x>t,其中 xxx 是输入。
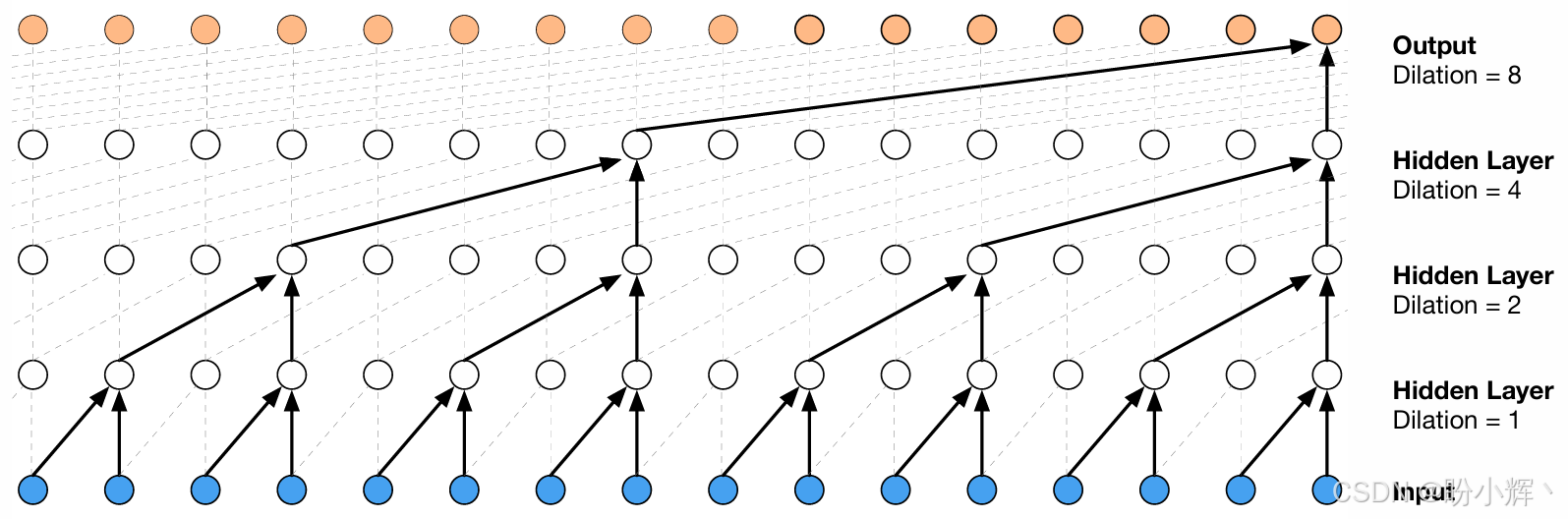
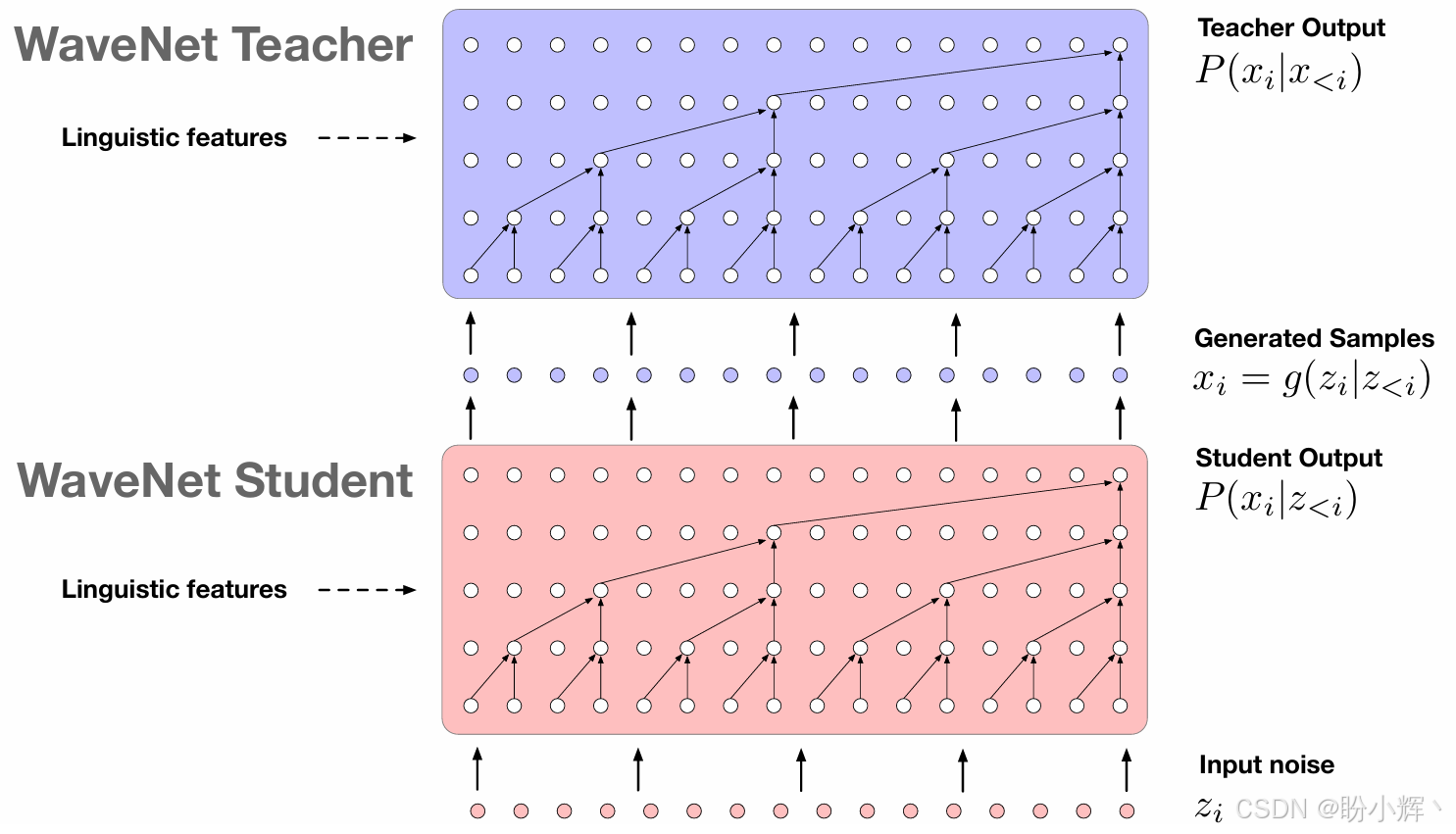
Parallel WaveNet 提出了一种并行采样的方法,速度提高了三个数量级。这种方法使用两个网络,一个作为 WaveNet 教师网络,虽然较慢但确保结果正确,另一个是 WaveNet 学生网络,试图模仿教师的行为;这种方法虽然准确度较低但更快。这种方法类似于生成对抗网络 (Generative Adversarial Network, GAN) 的方法,但学生网络并不像 GAN 中那样试图欺骗教师网络。事实上,该模型不仅速度更快,而且具有更高的保真度,能够以每秒 24,000 个样本的速度创建波形。
MuseNet 是 OpenAI 开发的一种音频生成工具。MuseNet 使用稀疏 Transformer 来训练一个 72 层的网络,拥有 24 个注意力头。Transformer 非常擅长预测序列中的下一元素,无论是文本、图像还是声音。
在 Transformer 中,每个输出元素都与输入元素连接,二者之间的权重通过注意力机制动态计算。MuseNet 可以生成长达 4 分钟的音乐作品,使用 10 种不同的乐器,能够结合从乡村音乐到莫扎特,再到披头士的风格。
8. 卷积操作总结
本节将总结不同的卷积操作。一个卷积层有 III 个输入通道,并产生 OOO 个输出通道,该层包含 I×O×KI \times O \times KI×O×K 个参数,其中 KKK 是卷积核中的参数量。
8.1 常规 CNN
常规 CNN 接收输入图像(二维)、文本(二维)或视频(三维),并对输入应用多个卷积核。每个卷积核像一个在输入区域滑动的手电筒,照射到的区域称为感受野。每个卷积核的深度与输入深度相同(例如,如果图像的深度为 3,则卷积核的深度也必须是 3)。
当卷积核在输入图像上滑动时,卷积核中的值与输入值相乘,乘积随后求和得到一个单一值。这一过程会在每个活动区域上重复,从而生成一个激活图(也称为特征图)。可以使用多个卷积核,每个卷积核作为一个特征识别器。例如,对于图像,卷积核可以识别边缘、颜色和线条等。将卷积核值视为权重,并通过反向传播在训练过程中进行微调。
卷积层可以通过以下配置参数进行设置:
- 卷积核大小:卷积的视野范围
- 步幅:卷积核遍历图像时的步长
- 填充:定义如何处理输入的边界
8.2 扩张卷积
扩张卷积 (Dilated convolution),也称空洞卷积 (atrous convolution),引入了另一个配置参数:
- 扩张率:卷积核中值之间的间距
扩张卷积在许多场景中都有应用,包括使用 WaveNet 的音频处理。
8.3 转置卷积
转置卷积是一个与常规卷积方向相反的变换,例如,可以用于将特征图投影到更高维空间或构建卷积自编码器。理解转置卷积的一种方式是首先计算常规 CNN 在给定输入形状下的输出形状,然后,我们通过转置卷积反转输入和输出的形状。TensorFlow 支持使用 Conv2DTranspose 层执行转置卷积,这可以用于生成对抗网络 (Generative Adversarial Network, GAN) 中生成图像。
8.4 可分离卷积
可分离卷积旨在将卷积核分离为多个步骤。假设卷积为 y=conv(x,k)y = conv(x, k)y=conv(x,k),其中 yyy 是输出,xxx 是输入,kkk 是卷积核。假设卷积核是可分离的,即 k=k1⋅k2k = k1\cdot k2k=k1⋅k2,其中 “⋅\cdot⋅” 表示点积。在这种情况下,可以通过先进行两个一维卷积(使用 k1k_1k1 和 k2k_2k2)来获得与执行二维卷积(使用 kkk )相同的结果,可分离卷积常用于节省计算资源。
8.5 深度卷积
考虑一个具有多个通道的图像,在常规 2D 卷积中,卷积核的深度与输入相同,能够混合通道以生成每个输出元素。在深度卷积中,每个通道保持独立,卷积核被拆分为通道,每个卷积单独应用,然后将结果堆叠回一个张量中。
8.6 深度可分离卷积
深度可分离卷积与可分离卷积并不相同。深度可分离卷积完成深度卷积后,还会执行一个额外的步骤,在通道之间进行 1x1 卷积。深度可分离卷积在 Xception 中得到了应用,也用于 MobileNet,这是一种特别适用于移动和嵌入式视觉应用的模型,因为它具有较小的模型尺寸和更低的复杂度。
小结
在本节中,我们介绍了卷积神经网络 (Convolutional Neural Network, CNN) 在不同领域的广泛应用,从传统的图像处理和计算机视觉,到视频处理、音频处理以及文本处理。短短几年间,CNN 已经在机器学习领域引起了巨大变革。如今,多模态处理已广泛流行,将文本、图像、音频和视频结合在一起以实现更好的性能,通常通过结合 CNN 和其他技术(如 Transformer 和强化学习等)完成。
系列链接
TensorFlow深度学习实战(1)——神经网络与模型训练过程详解
TensorFlow深度学习实战(2)——使用TensorFlow构建神经网络
TensorFlow深度学习实战(3)——深度学习中常用激活函数详解
TensorFlow深度学习实战(4)——正则化技术详解
TensorFlow深度学习实战(5)——神经网络性能优化技术详解
TensorFlow深度学习实战(6)——回归分析详解
TensorFlow深度学习实战(7)——分类任务详解
TensorFlow深度学习实战(8)——卷积神经网络
TensorFlow深度学习实战(10)——构建VGG模型实现图像分类
TensorFlow深度学习实战(11)——迁移学习详解
TensorFlow深度学习实战(12)——风格迁移详解
TensorFlow深度学习实战(13)——词嵌入技术详解
TensorFlow深度学习实战(14)——神经嵌入详解
TensorFlow深度学习实战(15)——循环神经网络详解
TensorFlow深度学习实战(16)——编码器-解码器架构
TensorFlow深度学习实战(17)——注意力机制详解
TensorFlow深度学习实战(18)——主成分分析详解
TensorFlow深度学习实战(19)——K-means 聚类详解
TensorFlow深度学习实战(20)——受限玻尔兹曼机
TensorFlow深度学习实战(21)——自组织映射详解
TensorFlow深度学习实战(22)——Transformer架构详解与实现
TensorFlow深度学习实战(23)——从零开始实现Transformer机器翻译
TensorFlow深度学习实战(24)——自编码器详解与实现
TensorFlow深度学习实战(25)——卷积自编码器详解与实现
TensorFlow深度学习实战(26)——变分自编码器详解与实现
TensorFlow深度学习实战(27)——生成对抗网络详解与实现
TensorFlow深度学习实战(28)——CycleGAN详解与实现
TensorFlow深度学习实战(29)——扩散模型(Diffusion Model)
TensorFlow深度学习实战(30)——自监督学习(Self-Supervised Learning)
TensorFlow深度学习实战(31)——强化学习(Reinforcement learning,RL)
TensorFlow深度学习实战(32)——强化学习仿真库Gymnasium
TensorFlow深度学习实战(33)——深度Q网络(Deep Q-Network,DQN)
TensorFlow深度学习实战(34)——深度确定性策略梯度
TensorFlow深度学习实战(35)——TensorFlow Probability
TensorFlow深度学习实战(36)——概率神经网络
TensorFlow深度学习实战(37)——自动机器学习(AutoML)
TensorFlow深度学习实战(38)——深度学习的数学原理
TensorFlow深度学习实战(39)——常用深度学习库
TensorFlow深度学习实战(40)——机器学习实践指南
TensorFlow深度学习实战(41)——图神经网络(GNN)
TensorFlow深度学习实战(42)——TensorFlow生态系统
TensorFlow深度学习实战(43)——TensorFlow.js