Crawl4ai 框架的学习与使用
Crawl4ai 框架的学习与使用
**梗概:**本文主要学习开源项目 Crawl4ai 的入门到实战中的使用。
参考文档:https://geekdaxue.co/read/Crawl4AI/quickstart
参考文档:https://crawl4ai.docslib.dev/advanced/multi-url-crawling/
参考博客:https://blog.csdn.net/gitblog_00177/article/details/148325069
1. Crawl4ai 初识
开源项目地址:https://github.com/unclecode/crawl4ai
介绍:Crawl4ai 是一个专注于网页爬取与数据提取的 Python 框架,主打简单易用和智能处理,尤其擅长处理现代网页(动态 JavaScript 渲染的界面),同时集成了 AI 能力用于数据清洗和结构化,适合从网页中提取高质量的信息。
核心特点:
- **自动处理动态内容:**内置浏览器渲染引擎(基于 Playwright),能爬取 JavaScript 动态生成的内容(如单页应用 SPA),无需手动分析 API。
- **AI 增强的数据提取:**支持通过自然语言描述(如 “提取所有产品名称和价格”)或结构化提示(如 JSON 格式)让 AI 自动提取信息,减少手动编写 XPath/CSS 选择器的工作量。
- **反爬机制的应对:**内置基础的反爬策略(如随机 User-Agent、请求间隔控制),降低被目标网站封禁的风险。
- **简洁 API:**提供直观的接口,几行代码即可完成爬取到提取的全流程。
- **多格式输出:**支持将提取结果保存为 json、csv 等格式,方便后续处理。
1.1 安装
Crawl4ai 安装 Playwright 处理浏览器的渲染,安装时需要同时配置浏览器的驱动;
# 安装框架
pip install crawl4ai # 安装 PlayWright 浏览器驱动(首次使用时执行)
playwright install
补充: PlayWright Playwright 是由 Microsoft 开发的一个开源自动化框架,主要用于测试和浏览器自动化。它的一个显著特点是支持 跨浏览器(Chromium、Firefox 和 WebKit)和跨平台(Windows、Linux 和 macOS)。对于爬虫开发者来说,它的价值在于能高效处理现代网页中常见的动态内容、JavaScript 渲染以及复杂的用户交互。
-
**自动等待:**Playwright 在执行操作之前等待元素可操作。 它还具有丰富的内省事件。 两者的结合消除了人为超时的需要 - 这是造成碎片测试的主要原因。
-
网络优先的断言: Playwright 断言是专门为动态网络创建的。 检查会自动重试,直到满足必要的条件。
-
追踪: 配置测试重试策略,捕获执行轨迹、视频、屏幕截图以消除碎片。
-
简单的使用
-
更详细的内容参考:https://blog.csdn.net/qq_40036519/article/details/153135397
-
同步方法,获取浏览器的截图
from playwright.sync_api import sync_playwright with sync_playwright() as p: # 创建同步的控制对象;# 启动浏览器browser = p.chromium.launch(headless=False) # 使用 launch 创建浏览器page = browser.new_page()# 打开网页page.goto("https://www.baidu.com/")# 截取屏幕截图page.screenshot(path="example.png")# 关闭浏览器browser.close()
-
异步方法,使用协程进行操作
import asyncio from playwright.async_api import async_playwright async def main():async with async_playwright() as p: # 创建异步的控制对象;browser = await p.chromium.launch(headless=False) # 使用协程进行操作;page = await browser.new_page() # 新建标签页await page.goto("https://www.baidu.com/") # 跳转到网页await page.screenshot(path="example2.png")await browser.close() asyncio.run(main())
-
1.2 简单使用
Crawl4ai 的核心工作流分为三步:初始化爬虫 → 爬取网页 → 提取数据(可结合 AI)。
基础爬取
适合采集只需要获取网页 HTML 或文本内容的场景:
# !/usr/bin/env python
# -*-coding:utf-8 -*-"""
@File : 1.py
@Time : 2025/10/22 10:42
@Author : zi qing bao jian
@Version : 1.0
@Desc :
"""
import asyncio
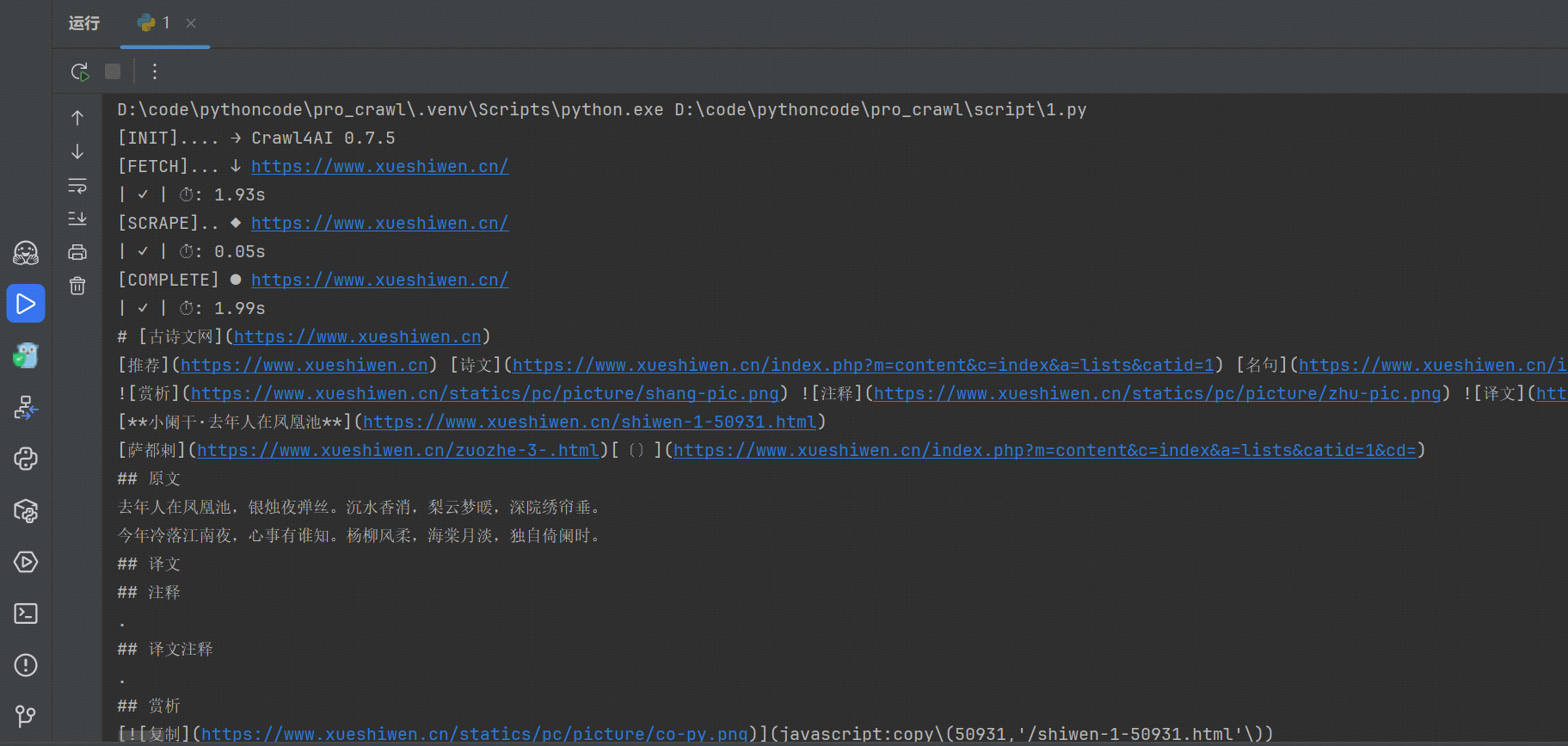
from crawl4ai import AsyncWebCrawlerasync def main():"""使用异步的协程进行处理. """async with AsyncWebCrawler() as crawler: # 创建异步爬虫的实例化对象result = await crawler.arun("https://www.xueshiwen.cn/") # 访问指定的 urlprint(result.markdown.raw_markdown)# 启动协程的函数
if __name__ == '__main__':asyncio.run(main())采集的网页:
得到的结果:
2. Crawl4ai 高级使用
本部分主要介绍 Crawl4ai 的高级使用的一些功能,如 AI 辅助数据提取、高级配置(反爬、代理、浏览器配置)、等待机制、结构化数据提取、异步与批量爬取、内容后处理。
2.1 AI 辅助数据提取
通过自然语言提示让 AI 自动提取结构化数据(需联网,依赖 OpenAI 等模型,需配置 API 密钥):
Crawl4ai 内置了智能内容清洗功能:
进行代码的 Debug 的时候,可以看到内部的一些属性。
async def clean_content():async with AsyncWebCrawler() as crawler:result = await crawler.arun(url="https://janineintheworld.com/places-to-visit-in-central-mexico",excluded_tags=['nav', 'footer', 'aside'], # 排除导航等非主要内容remove_overlay_elements=True, # 移除弹窗等覆盖元素word_count_threshold=10, # 内容块最小字数阈值)print(f"清洗前长度: {len(result.markdown.raw_markdown)}")print(f"清洗后长度: {len(result.markdown.fit_markdown)}")print(result.markdown.fit_markdown[:1000])
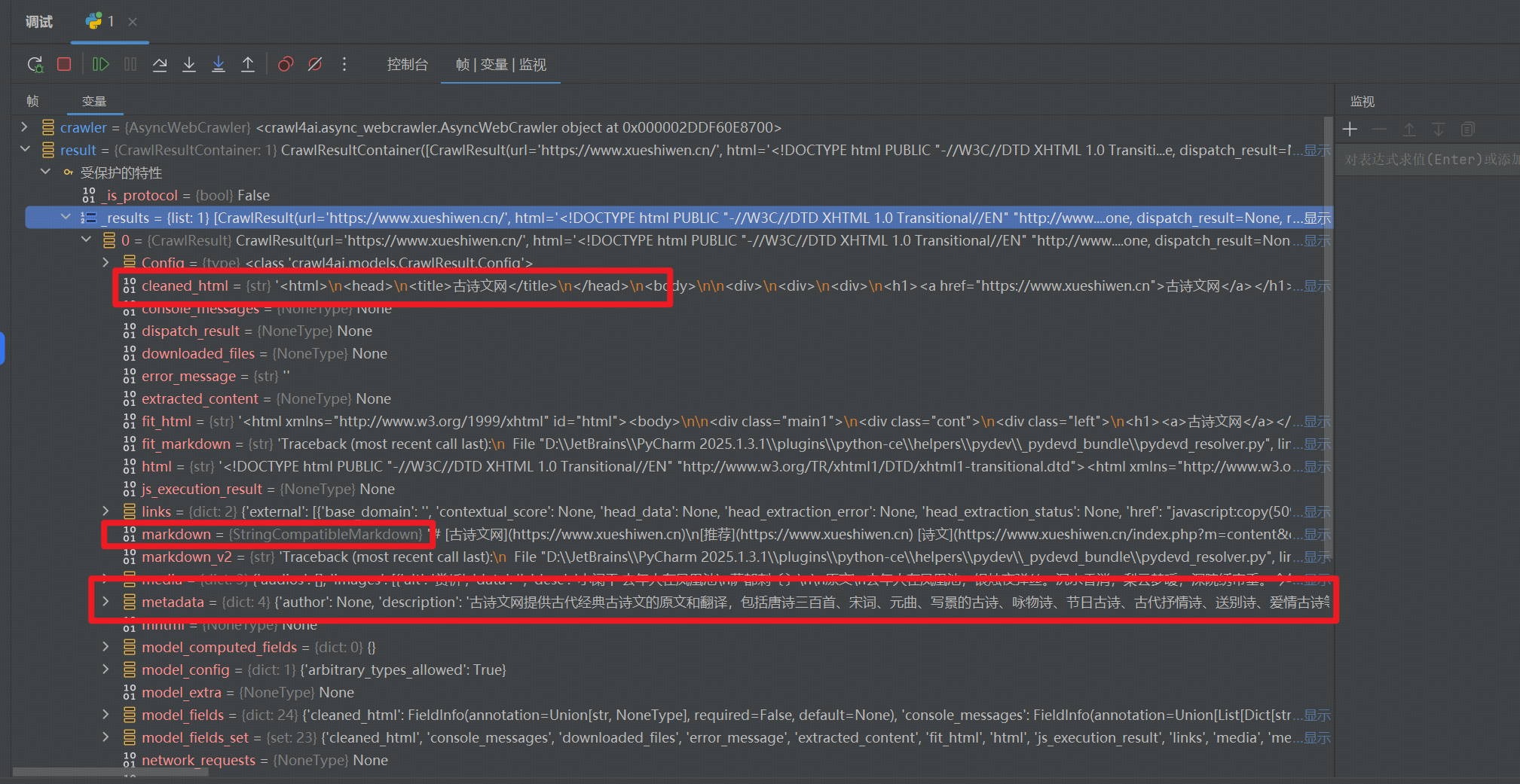
比较有用的信息为:
# markdown, links, mhtml(快照的形式), meida(图片Image, 视频 Video, 音频 Audio), response_headers(响应请求头)
# redirected_url(重定向 URL), session_id(模拟登录的操作的时候可能会用到)
2.2 信息提取
2.2.1 链接提取
# !/usr/bin/env python
# -*-coding:utf-8 -*-"""
@File : 2.py
@Time : 2025/10/22 14:02
@Author : zi qing bao jian
@Version : 1.0
@Desc : 使用 AI 辅助功能提取;
"""
import asyncio
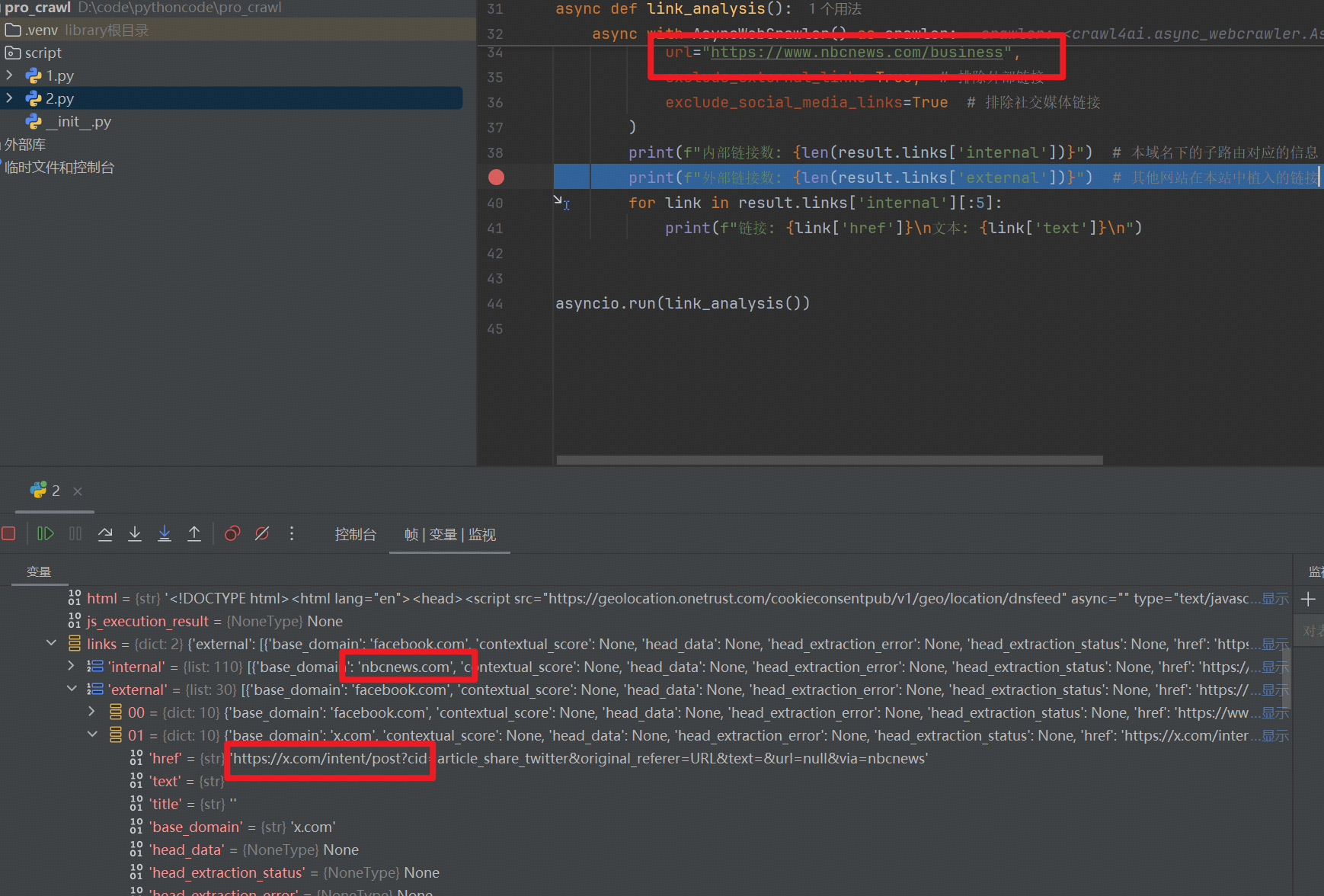
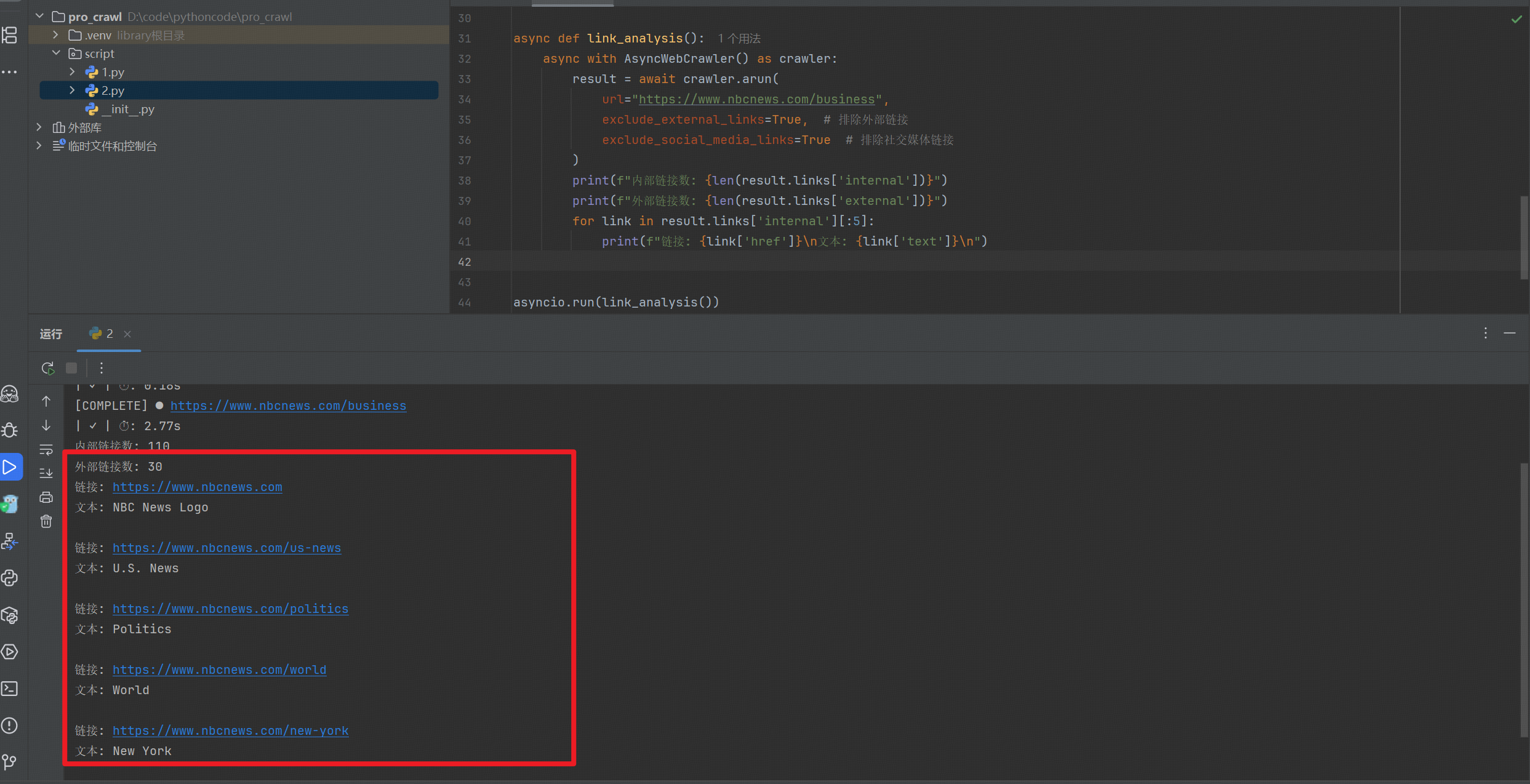
from crawl4ai import AsyncWebCrawlerasync def link_analysis():async with AsyncWebCrawler() as crawler:result = await crawler.arun(url="https://www.nbcnews.com/business",exclude_external_links=True, # 排除外部链接exclude_social_media_links=True # 排除社交媒体链接)print(f"内部链接数: {len(result.links['internal'])}")print(f"外部链接数: {len(result.links['external'])}")for link in result.links['internal'][:5]:print(f"链接: {link['href']}\n文本: {link['text']}\n")asyncio.run(link_analysis())
2.2.2 媒体资源提取
async def media_handling():async with AsyncWebCrawler() as crawler:result = await crawler.arun(url="https://www.nbcnews.com/business",exclude_external_images=False, # 包含外部图片screenshot=True # 生成页面截图)for img in result.media['images'][:5]:print(f"图片URL: {img['src']}, 描述: {img['alt']}, 相关性评分: {img['score']}")asyncio.run(media_handling())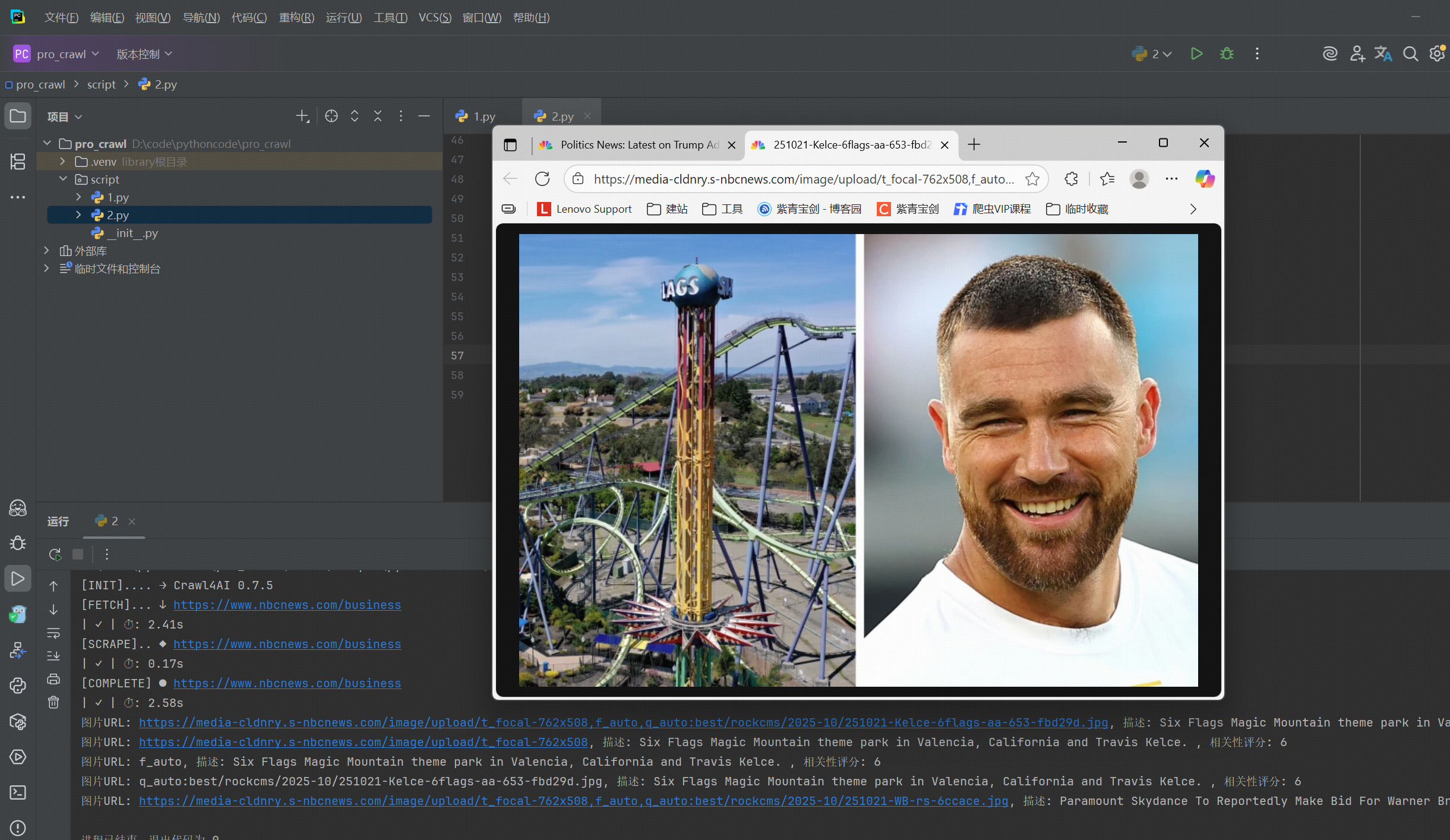
2.2.3 结构化提取数据
-
采集结果认识:
除了 Markdown,Crawl4AI 的
arun()方法还会返回一个CrawlResult对象,其中包含丰富的属性,例如原始 HTML、清洗后的 HTML、提取的媒体资源与链接、HTTP 状态码等。借助这些信息,用户可以更灵活地处理爬取结果。import asyncio from crawl4ai import AsyncWebCrawler, DefaultMarkdownGenerator, PruningContentFilter from crawl4ai.async_configs import BrowserConfig, CrawlerRunConfigasync def main():browser_config = BrowserConfig() # Default browser configurationrun_config = CrawlerRunConfig(markdown_generator=DefaultMarkdownGenerator(content_filter=PruningContentFilter(threshold=0.6),options={"ignore_links": True}))async with AsyncWebCrawler(config=browser_config) as crawler:result = await crawler.arun(url="https://blog.csdn.net/weixin_45399602/article/details/148739200",config=run_config)# 筛选结果进行处理;print(result.markdown) # Print clean markdown contentprint(result.html) # Raw HTMLprint(result.cleaned_html) # Cleaned HTMLprint(result.markdown.raw_markdown) # Raw markdown from cleaned htmlprint(result.markdown.fit_markdown) # Most relevant content in markdown# Check success statusprint(result.success) # True if crawl succeededprint(result.status_code) # HTTP status code (e.g., 200, 404)# Access extracted media and linksprint(result.media) # Dictionary of found media (images, videos, audio)print(result.links)if __name__ == "__main__":asyncio.run(main())
-
**采集阶段的配置:**在实际应用中,开发者往往需要根据场景自定义爬取,通过 CrawlerRunConfig , 我们可以指定字数阈值、是否过滤外部链接,是否去除弹窗元素、以及是否处理 iframe 等。这些配置可以使得爬取的过程更加的灵活;
import asyncio from crawl4ai import AsyncWebCrawler, DefaultMarkdownGenerator, PruningContentFilter from crawl4ai.async_configs import BrowserConfig, CrawlerRunConfig # 导入采集的配置;async def main():browser_config = BrowserConfig()run_config = CrawlerRunConfig(word_count_threshold=10, # 采集的时候字数阈值的设置;exclude_external_links=True, # 过滤掉外部的链接;remove_overlay_elements=True, # 移除弹窗等元素;process_iframes=True # 处理 iframe 中的关系)async with AsyncWebCrawler(config=browser_config) as crawler: # 此处配置浏览器的设置;result = await crawler.arun(url="https://blog.csdn.net/weixin_45399602/article/details/148739200",config=run_config # 此处设置运行时候的配置;)print(result.markdown) # Print clean markdown contentif __name__ == '__main__':asyncio.run(main())
-
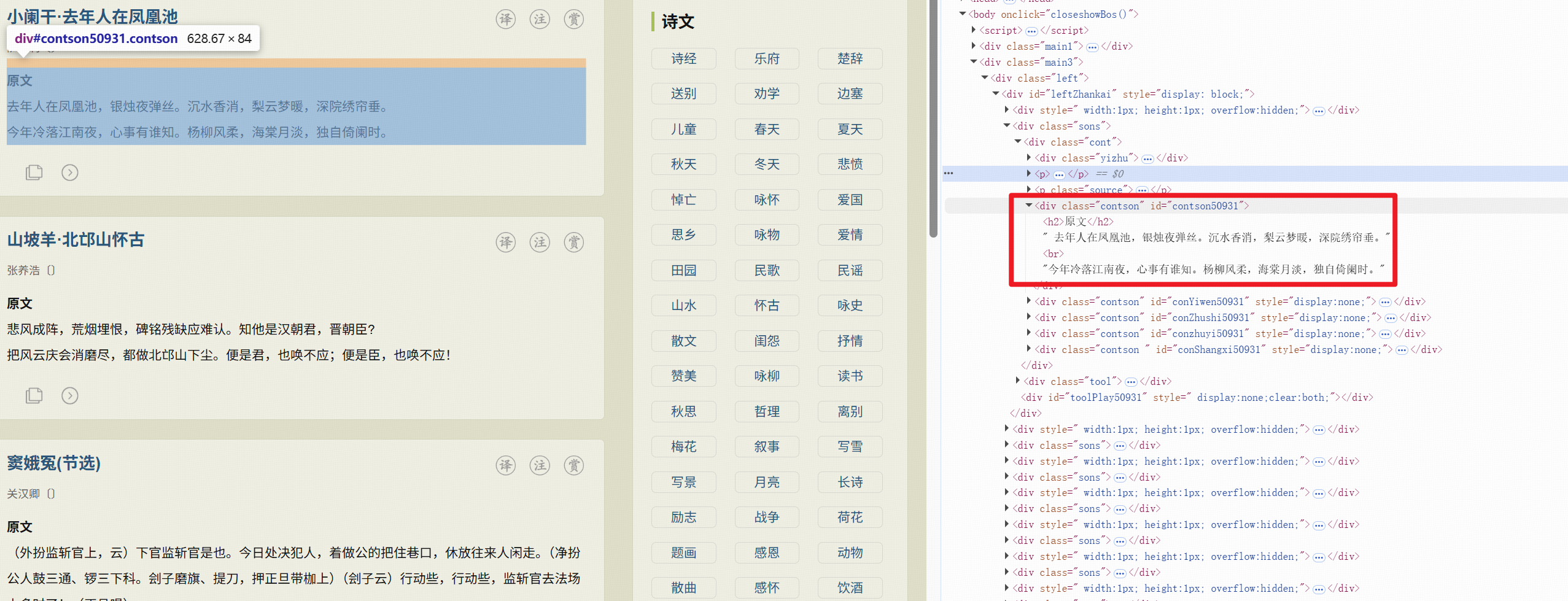
**CSS/XPATH 选择器:**直接通过选择器提取指定内容,返回结构化的字典;
检查网页,编写 css 选择器进行使用
async def main():async with AsyncWebCrawler() as crawler:result = await crawler.arun(url="https://www.xueshiwen.cn/",extract={"title": ".contson::text"})html_str = result.html # 获取到了清洗后的 Html 的信息进行采集处理;# 原生数据获取到之后即可按照之前的 XPATH 表达式, 使用 lxml.etree 的对象数据进行处理;# 本质属于传统的范畴, 此处不进行详细的赘述, 可以参考以前的数据采集的文章;案例二,直接使用的 CSS 选择器进行筛选
import asyncio from crawl4ai import AsyncWebCrawler, DefaultMarkdownGenerator, PruningContentFilter, JsonCssExtractionStrategy from crawl4ai.async_configs import BrowserConfig, CrawlerRunConfig # 导入采集的配置;async def main():browser_config = BrowserConfig()run_config = CrawlerRunConfig(word_count_threshold=10, # 采集的时候字数阈值的设置;exclude_external_links=True, # 过滤掉外部的链接;remove_overlay_elements=True, # 移除弹窗等元素;process_iframes=True # 处理 iframe 中的关系)async with AsyncWebCrawler(config=browser_config) as crawler: # 此处配置浏览器的设置;result = await crawler.arun(url="https://blog.csdn.net/weixin_45399602/article/details/148739200",config=run_config, # 此处设置运行时候的配置;css_selector=".article_content clearfix:nth-child(-n+30)" # 编写 CSS 选择器, 实现筛选)# print(result.markdown) # Print clean markdown contentprint("原有的Html 的长度:", len(result.html))print("筛选后的 Html 的长度:", len(result.cleaned_html))print(result.cleaned_html)if __name__ == '__main__':asyncio.run(main())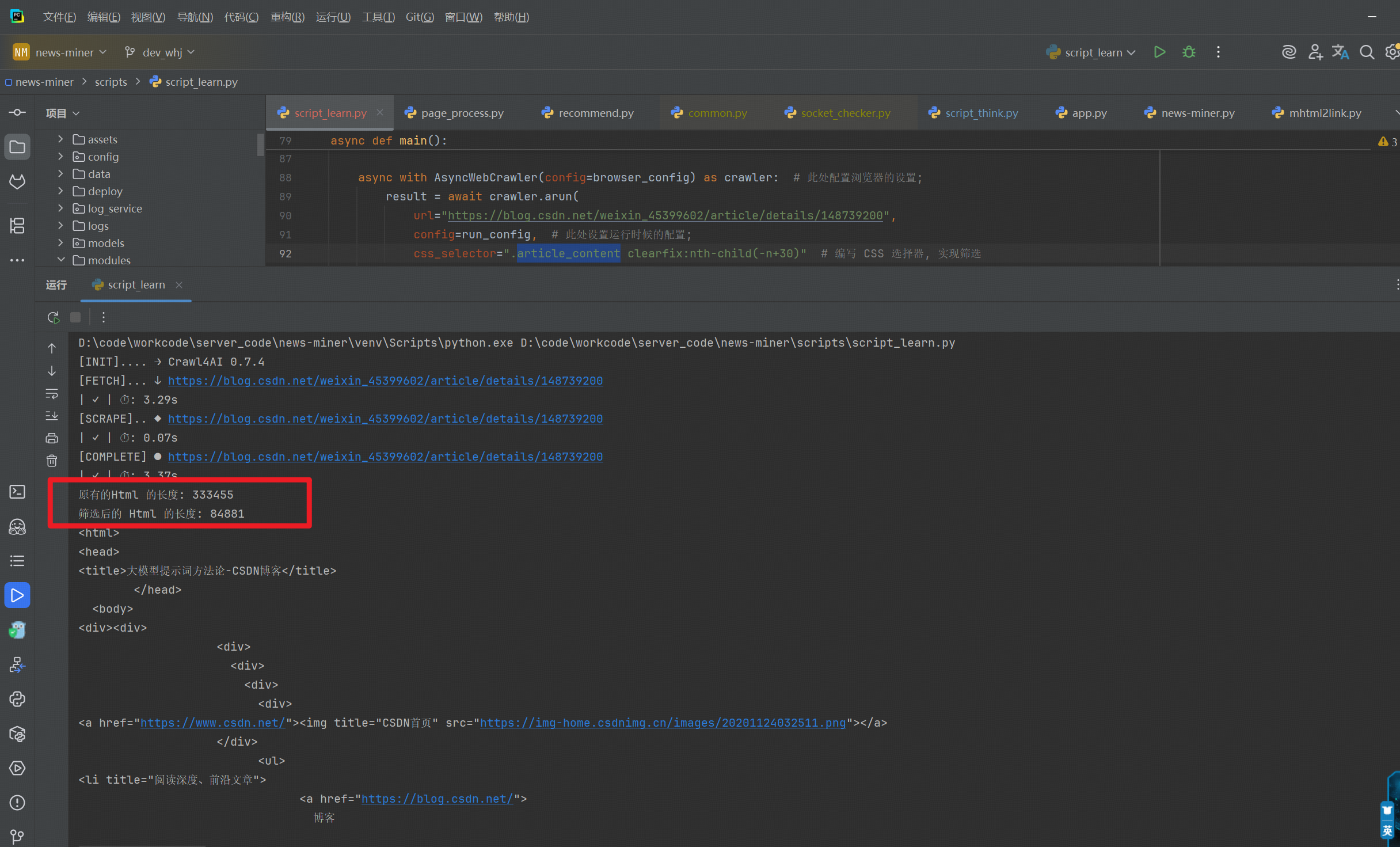
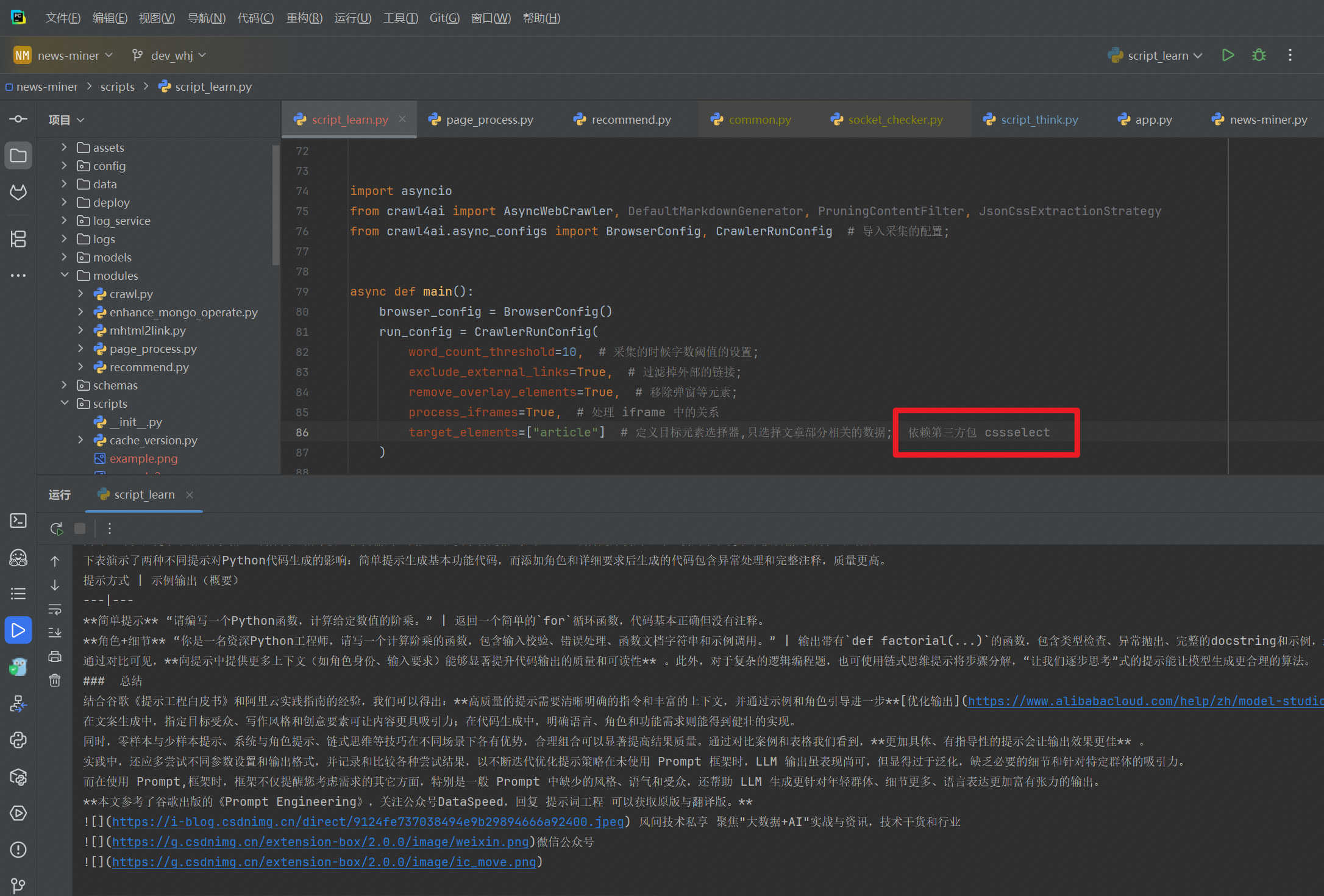
使用 target_elements 进行数据的提取
import asyncio from crawl4ai import AsyncWebCrawler, DefaultMarkdownGenerator, PruningContentFilter, JsonCssExtractionStrategy from crawl4ai.async_configs import BrowserConfig, CrawlerRunConfig # 导入采集的配置;async def main():browser_config = BrowserConfig()run_config = CrawlerRunConfig(word_count_threshold=10, # 采集的时候字数阈值的设置;exclude_external_links=True, # 过滤掉外部的链接;remove_overlay_elements=True, # 移除弹窗等元素;process_iframes=True, # 处理 iframe 中的关系target_elements=["article"] # 定义目标元素选择器,只选择文章部分相关的数据; 依赖第三方包 cssselect)async with AsyncWebCrawler(config=browser_config) as crawler: # 此处配置浏览器的设置;result = await crawler.arun(url="https://blog.csdn.net/weixin_45399602/article/details/148739200",config=run_config, # 此处设置运行时候的配置;)print(result.markdown)if __name__ == '__main__':asyncio.run(main())此时的 Markdown 的输出显示的比较接近正文的部分;
2.2.4 内置提取器
Crawl4AI 最强大的功能之一是从网站提取结构化 JSON,而无需依赖大语言模型。Crawl4AI 提供了多种无需大语言模型的提取策略:
-
通过
JsonCssExtractionStrategy和JsonXPathExtractionStrategy进行基于CSS或XPath选择器的模式提取 -
使用
RegexExtractionStrategy进行正则表达式提取,实现快速模式匹配
这些方法能够即时提取数据,即使是从复杂或嵌套的 HTML 结构中,也无需承担大语言模型的成本、延迟或环境影响。
为什么基本提取要避免使用大语言模型?
- 更快更便宜:无需 API 调用或 GPU 开销。
- 更低碳足迹:大语言模型推理可能消耗大量能源。基于模式的提取实际上零碳排放。
- 精确且可重复:CSS/XPath 选择器和正则表达式模式完全按您的指定执行。大语言模型的输出可能多变或产生幻觉。
- 易于扩展:对于数千个页面,基于模式的提取可以快速并行运行。
""" css 选择器的示例;
"""
import json
import asyncio
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig, CacheMode
from crawl4ai import JsonCssExtractionStrategyasync def extract_crypto_prices():# 1. 定义一个简单的提取模式schema = {"name": "Crypto Prices",# 选择器的元素从浏览器复制而来"baseSelector": "#mainBox > main > div.recommend-box.insert-baidu-box.recommend-box-style", # 重复元素"fields": [{"name": "title","selector": "div:nth-child(2) > div > div.content-blog.display-flex > div.title-box", # 定义选择器的策略;"type": "text"},{"name": "desc","selector": "div:nth-child(2) > div > div.content-blog.display-flex > div.info-box.display-flex > div","type": "text"}]}# 2. 创建提取策略extraction_strategy = JsonCssExtractionStrategy(schema, verbose=True)# 3. 设置爬虫配置(如果需要)config = CrawlerRunConfig(# 例如,如果页面是动态的,传递 js_code 或 wait_for# wait_for="css:.crypto-row:nth-child(20)"cache_mode = CacheMode.BYPASS,extraction_strategy=extraction_strategy,)async with AsyncWebCrawler(verbose=True) as crawler:# 4. 运行爬取和提取result = await crawler.arun(url="https://example.com/crypto-prices",config=config)if not result.success:print("Crawl failed:", result.error_message)return# 5. 解析提取的 JSONdata = json.loads(result.extracted_content)print(f"Extracted {len(data)} coin entries")print(json.dumps(data[0], indent=2) if data else "No data found")asyncio.run(extract_crypto_prices())

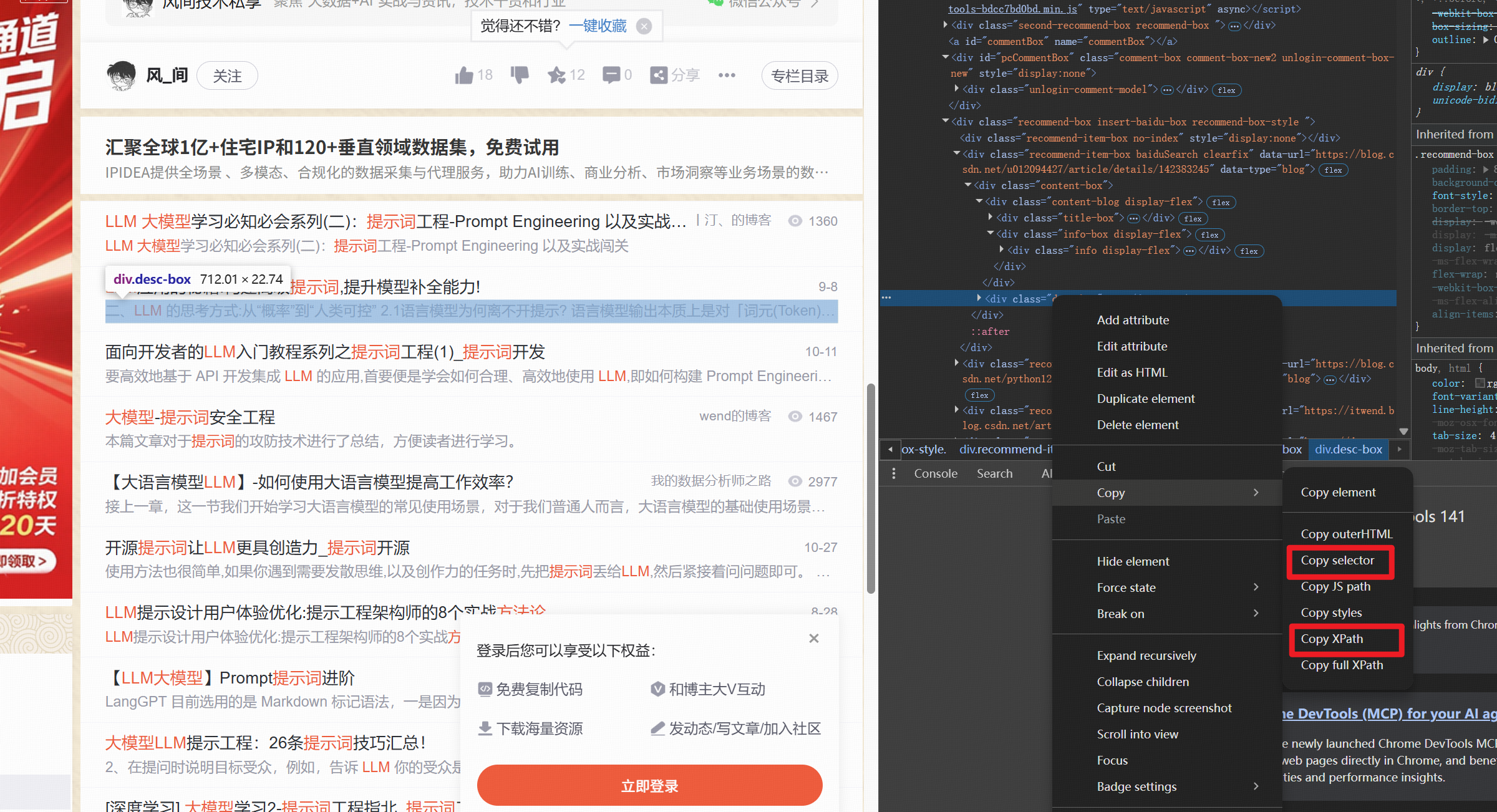
下一个使用 Xpath 的提取策略
import json
import asyncio
from tabnanny import verbosefrom crawl4ai import AsyncWebCrawler, DefaultMarkdownGenerator, CacheMode, JsonCssExtractionStrategy, \JsonXPathExtractionStrategy
from crawl4ai.async_configs import BrowserConfig, CrawlerRunConfig # 导入采集的配置;async def extract_crypto_prices():# 定义 xpath 选择字典schema = {"name": "xpath - blog","baseSelector": '//*[@id="mainBox"]/main/div[7]',"fields": [{"name": "title","selector": "./div/div/div[1]", # 定义选择器的策略;"type": "text"},{"name": "desc","selector": "./div/div/div[2]","type": "text"}]}extraction_strategy = JsonXPathExtractionStrategy(schema, verbose=True)# 3. 设置爬虫的配置;config = CrawlerRunConfig(# 例如,如果页面是动态的,传递 js_code 或 wait_for# wait_for="css:.crypto-row:nth-child(20)"cache_mode=CacheMode.BYPASS, # 忽略任何缓存的响应;extraction_strategy=extraction_strategy, # 设定上我们上述指定的策略对象;)# 设置上下文的运行与采集;async with AsyncWebCrawler(verbose=True) as crawler:result = await crawler.arun(url="https://blog.csdn.net/weixin_45399602/article/details/148739200",config=config,)if not result.success:# 采集异常的时候, 打印错误信息的;print(result.error_message)# 5. 解析提取 JSONdata = json.loads(result.extracted_content)print(f"Extracted {len(data)} coin entries")print(json.dumps(data[0], indent=2, ensure_ascii=False) if data else "No data found")if __name__ == '__main__':asyncio.run(extract_crypto_prices())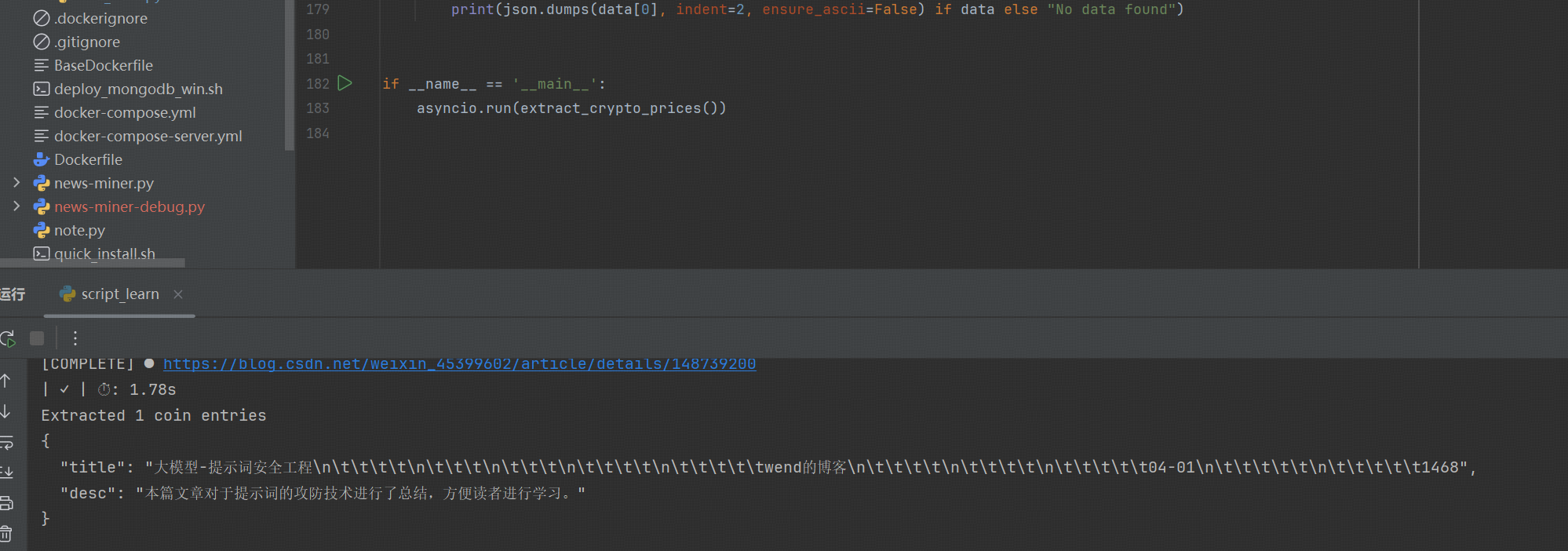
更多的内容查看:https://crawl4ai.docslib.dev/extraction/no-llm-strategies/
2.2.5 使用 LLM 提取数据
在某些情况下,你需要从网页中提取复杂或非结构化的信息,而这些信息难以通过简单的 CSS/XPath 模式解析。或者你需要AI驱动的洞察、分类或摘要。针对这些场景,Crawl4AI 提供了一种基于 LLM 的提取策略,该策略:
-
支持 LiteLLM 支持的任何大型语言模型(Ollama、OpenAI、Claude 等)。
-
根据需要自动将内容分块以处理令牌限制,然后合并结果。
-
允许你定义一个模式(如 Pydantic 模型)或更简单的“块”提取方法。
-
重要提示:基于 LLM 的提取可能比基于模式的方法更慢且成本更高。页面数据高度结构化,优先使用提取器进行提取;
-
为什么使用 LLM
- 复杂推理:如果网站的数据是非结构化的、分散的或充满自然语言上下文。
- 语义提取:需要理解能力的摘要、知识图谱或关系数据。
- 灵活:你可以向模型传递指令以执行更高级的转换或分类。
-
提取流程
-
分块(可选):如果 HTML 或 markdown 内容非常长,则将其分割成较小的片段(基于
chunk_token_threshold、重叠等)。 -
提示构建:对于每个块,库会形成一个提示,其中包括你的**
instruction**(以及可能的模式或示例)。 -
LLM 推理:每个块被并行或顺序发送到模型(取决于你的并发设置)。
-
合并:每个块的结果被合并并解析为 JSON。
-
-
关键参数
以下是重要的 LLM 提取参数概述。所有参数通常在
LLMExtractionStrategy(...)中设置,然后将策略配置在CrawlerRunConfig(..., extraction_strategy=...)llmConfig(LlmConfig):例如"openai/gpt-4"、"ollama/llama2"。
2.
schema(dict):描述你所需字段的 JSON 模式。通常由YourModel.model_json_schema()生成。
3.extraction_type(str):"schema"或"block"。
4.instruction(str):提示文本,告诉 LLM 你想要提取什么。例如,“将这些字段提取为 JSON 数组。”
5.chunk_token_threshold(int):每个块的最大令牌数。如果你的内容很大,可以将其拆分以供 LLM 处理。
6.overlap_rate(float):相邻块之间的重叠率。例如,0.1表示每个块有 10% 的文本重复,以保持上下文连续性。
7.apply_chunking(bool):设置为True以自动分块。如果希望单次处理,设置为False。
8.input_format(str):确定将哪个爬取结果传递给 LLM。选项包括:"markdown":原始 markdown(默认)。"fit_markdown":如果你使用了内容过滤器,则为过滤后的“fit”markdown。"html":清理过的或原始的 HTML。
9.
extra_args(dict):额外的 LLM 参数,如temperature、max_tokens、top_p等。
10.show_usage():你可以调用的方法,用于打印使用信息(每个块的令牌使用情况,总成本(如果已知))。
案例:
import os
import asyncio
import json
from typing import List# from lxml.parser import result
# 导入第三方包;
from pydantic import BaseModel, Field
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode, LLMConfig
from crawl4ai import LLMExtractionStrategyclass Blog(BaseModel):"""文章下的相关列表;"""title: strdesc: strasync def main():# 1. 定义大模型的配置;llm_strategy = LLMExtractionStrategy(llm_config=LLMConfig(base_url="....", api_token="EMPTY"), # 其他的参数查看参考文档补充schema=Blog.model_json_schema(), # Or use model_json_schema()extraction_type="schema",instruction="Extract all Blog objects with 'title' and 'desc' from the content.",chunk_token_threshold=1000,overlap_rate=0.0,apply_chunking=True,input_format="markdown", # or "html", "fit_markdown"extra_args={"temperature": 0.0, "max_tokens": 800})# 2. 构建浏览器的配置;crawl_config = CrawlerRunConfig(extraction_strategy=llm_strategy,cache_mode=CacheMode.BYPASS # 忽略缓存;)# 3. 创建浏览器的配置, 使用无头的模式;browser_cfg = BrowserConfig(headless=True)# 4. 设置采集的对象async with AsyncWebCrawler(config=browser_cfg) as crawler:result = await crawler.arun(url="https://blog.csdn.net/weixin_45399602/article/details/148739200",config=crawl_config,)if result.success:# 5. The extracted content is presumably JSONdata = json.loads(result.extracted_content)print("Extracted items:", data)# 极狐. Show usage statsllm_strategy.show_usage() # prints token usageelse:print("Error:", result.error_message)if __name__ == '__main__':asyncio.run(main())3. Crawl4ai 核心原理
Crawl4ai 并非简单的 爬虫 + AI 组合,而是以 AI 能力贯穿整个数据处理流程,核心围绕 理解内容 而非抓取数据。
-
智能目标识别:通过 LLM(大语言模型)分析抓取需求,自动识别网页中与目标相关的内容模块,无需人工编写固定 CSS/XPATH 规则。
-
动态内容解析:内置浏览器渲染引擎,能处理 JavaScript 动态加载、SPA(单页应用)等传统爬虫难攻克的场景,同时 AI 会过滤广告、导航栏等无关信息。
-
语义化提取:不局限于 “提取标签内文字”,可基于语义理解提取结构化信息。例如从新闻页中自动分离 “标题、作者、发布时间、核心段落”,无需预设字段规则。
-
反爬自适应:AI 会分析网站反爬机制(如验证码、IP 封锁频率),动态调整请求间隔、UA(用户代理)池,甚至模拟人类浏览行为(如滚动、点击),降低被封禁概率。
与传统爬虫的核心对比
| 对比维度 | Crawl4ai | 传统爬虫(如 Scrapy、BeautifulSoup) |
|---|---|---|
| 核心逻辑 | 以 “内容理解” 为核心,AI 驱动端到端处理 | 以 “规则抓取” 为核心,依赖人工定义的解析规则 |
| 技术依赖 | 依赖 LLM、浏览器渲染、机器学习模型 | 依赖 HTTP 请求、HTML 解析库、正则 / CSS/XPATH |
| 动态内容处理 | 原生支持 JS 渲染,无需额外配置 | 需集成 Selenium/Puppeteer,配置复杂且效率低 |
| 规则维护成本 | 无需人工写解析规则,AI 自动适配页面变化 | 页面结构变更后需重新编写规则,维护成本高 |
| 反爬应对 | AI 动态调整策略,自适应能力强 | 依赖预设的 IP 池、UA 池,应对新型反爬能力弱 |
| 适用场景 | 非结构化内容提取(如新闻、文档、评论)、复杂动态网站 | 结构化数据抓取(如商品列表、表格数据)、固定模板网站 |
-
Crawl4ai 更适合:
-
从无固定模板的网页中提取信息(如不同结构的博客文章、论坛评论)。
-
处理需要 理解语义 的需求(如提取某篇报告中的核心观点、总结新闻事件)。
-
攻克高反爬、高动态的网站(如需要登录验证、JS 加密的平台)。
-
-
传统爬虫更适合:
-
批量抓取结构固定的数据(如电商平台的商品价格、库存,政府公开的表格数据)。
-
对抓取速度要求极高、数据量极大的场景(传统爬虫轻量化,无 AI 计算开销)。
-
简单静态网页的数据抓取(无需渲染,直接解析 HTML 即可完成)。
-
4. 项目实战
import asyncio
from crawl4ai import AsyncWebCrawler, DefaultMarkdownGenerator, PruningContentFilter, JsonCssExtractionStrategy
from crawl4ai.async_configs import BrowserConfig, CrawlerRunConfig # 导入采集的配置;async def main():browser_config = BrowserConfig()run_config = CrawlerRunConfig(word_count_threshold=10, # 采集的时候字数阈值的设置;exclude_external_links=True, # 过滤掉外部的链接;remove_overlay_elements=True, # 移除弹窗等元素;process_iframes=True, # 处理 iframe 中的关系# target_elements=["article"] # 定义目标元素选择器,只选择文章部分相关的数据; 依赖第三方包 cssselect)async with AsyncWebCrawler(config=browser_config) as crawler: # 此处配置浏览器的设置;result = await crawler.arun(url="https://www.zhipin.com/beijing/?seoRefer=index",config=run_config, # 此处设置运行时候的配置;css_selector=".recommend-item-box baiduSearch clearfix" # 编写 CSS 选择器, 实现筛选)print(result.markdown)print(result.links['internal']) # 筛选出有用的链接;if __name__ == '__main__':asyncio.run(main())
5. 高效率的爬虫
参考文档:https://blog.csdn.net/gitblog_00777/article/details/152352812
当我们有大量的数据需要采集的时候就需要把相关链接大批量的交给框架去执行,而且我们做完采集之后可能需要对大批量的列表进行分析采集,这是时候 URL 的数量就已经比较多了,就需要使用效率较高的爬虫去执行任务;
上述的案例我们都是使用arun调用协程去执行的,多个 URL 的时候我们使用arun_many去调用相关的接口;
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode, MatchMode# 创建采集阶段的配置;
pdf_config = CrawlerRunConfig(url_matcher="*.pdf", # 通配符匹配cache_mode=CacheMode.BYPASS
)# 文章页面配置
article_config = CrawlerRunConfig(url_matcher=["*/news/*", "*blog*"], # 多模式OR匹配match_mode=MatchMode.OR,screenshot=True # 自动截图
)# 测试配置匹配逻辑
# configs = [pdf_config, article_config]
test_urls = ["https://www.w3.org/WAI/ER/tests/xhtml/testfiles/resources/pdf/dummy.pdf","https://www.bbc.com/news/articles/c5y3e3glnldo","https://api.github.com/users/github"
]async def main():async with AsyncWebCrawler() as crawler: # 匹配的程度和浏览器的配置相关;results = await crawler.arun_many(urls=test_urls, config=pdf_config) # 此处的 config 为配置列表对象, 或者配置对象;for res in results:print(f"{res.url} → {res.config_used.__class__.__name__}")if __name__ == '__main__':import asyncioasyncio.run(main())使用调度器,进行高级的多 URL 的爬取;
注意:Crawl4AI 支持用于并行或限流爬取的高级调度器,提供动态速率限制和内存使用检查。内置的 arun_many() 函数使用这些调度器来高效处理并发。
-
基础:在循环中使用
arun()(简单但效率较低) -
更好:使用
arun_many(),它通过适当的并发控制高效处理多个URL -
最佳:根据您的特定需求自定义调度器行为(内存管理、速率限制等)
-
使用调度器的原因:
- 自适应:基于内存的调度器,可以根据系统资源暂停或减速;
- 速率限制:内置速率限制,针对429/503响应采用指数退避
- 实时监控:实时显示正在进行的任务、内存使用情况和性能
- 灵活性:可在内存自适应或基于信号量的并发之间选择
5.1 速率限制器
class RateLimiter:def __init__(# 请求之间的随机延迟范围base_delay: Tuple[float, float] = (1.0, 3.0), # 请求延迟1-3 之间随机选择;# 最大退避延迟max_delay: float = 60.0, # 放弃前的重试次数max_retries: int = 3, # 触发退避的状态码rate_limit_codes: List[int] = [429, 503] # 触发其中的状态码之后直接规避;)

RateLimiter 与 MemoryAdaptiveDispatcher 和 SemaphoreDispatcher 等调度器无缝集成,确保请求正确节奏,无需用户干预。其内部机制管理延迟和重试,以避免服务器过载,同时最大化效率。
5.2 爬虫监视器
CrawlerMonitor 提供对爬取操作的实时可见性;
from crawl4ai import CrawlerMonitor, DisplayMode
monitor = CrawlerMonitor(# 实时显示中的最大行数max_visible_rows=15, # DETAILED 或 AGGREGATED 视图# DETAILED 显示单个任务状态、内存使用情况和时间# AGGREGATED, 显示摘要的信息和整体的进度;display_mode=DisplayMode.DETAILED
)
5.3 可用调度器
根据系统内存情况自动管理并发:
from crawl4ai.async_dispatcher import MemoryAdaptiveDispatcherdispatcher = MemoryAdaptiveDispatcher(memory_threshold_percent=90.0, # 如果内存超过此值则暂停, 默认值是 90;check_interval=1.0, # 检查内存的频率max_session_permit=10, # 最大并发任务数rate_limiter=RateLimiter( # 可选的速率限制base_delay=(1.0, 2.0),max_delay=30.0,max_retries=2),monitor=CrawlerMonitor( # 可选监控max_visible_rows=15,display_mode=DisplayMode.DETAILED)
)
5.4 简单并发控制
提供具有固定限制的简单并发控制:
from crawl4ai.async_dispatcher import SemaphoreDispatcherdispatcher = SemaphoreDispatcher(max_session_permit=20, # 最大并发任务数, 通过最简单的方式实现 rate_limiter=RateLimiter( # 可选的速率限制base_delay=(0.5, 1.0),max_delay=10.0),monitor=CrawlerMonitor( # 可选监控max_visible_rows=15,display_mode=DisplayMode.DETAILED)
)
5.5 调度结果
每个爬取结果都包含调度信息:
@dataclass
class DispatchResult:task_id: strmemory_usage: floatpeak_memory: floatstart极_time: datetimeend_time: datetimeerror_message: str = ""
通过 result.dispatch_result 访问:
for result in results:if result.success:dr = result.dispatch_resultprint(f"URL: {result.url}")print(f"Memory: {dr.memory_usage:.1f}MB")print(f"Duration: {dr.end_time - dr.start_time}")
非流式处理,采集完成之后统一处理;
import asynciofrom crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, RateLimiter, SemaphoreDispatcherurls = ['https://blog.csdn.net/hanwb2010/article/details/154112857','https://blog.csdn.net/codeshare1135/article/details/154183256','https://blog.csdn.net/m0_67641255/article/details/154183503','https://blog.csdn.net/baidu_41666295/article/details/154015073','https://blog.csdn.net/weixin_45399602/article/details/153396385','https://blog.csdn.net/weixin_45399602/article/details/153396258',# .....]async def my_main():print("1. 定义速率限制器")rate_limiter = RateLimiter(base_delay=(2.0, 4.0), # 2-4秒之间的随机延迟max_delay=30.0, # 延迟上限为30秒max_retries=5, # 在速率限制错误时最多重试5次rate_limit_codes=[429, 503] # 处理这些HTTP状态码)# 定义调度器_dispatcher = SemaphoreDispatcher(rate_limiter=rate_limiter,max_session_permit=10)browser_config = BrowserConfig()run_config = CrawlerRunConfig(word_count_threshold=10, # 采集的时候字数阈值的设置;exclude_external_links=True, # 过滤掉外部的链接;remove_overlay_elements=True, # 移除弹窗等元素;process_iframes=True, # 处理 iframe 中的关系# stream=True # 允许在爬虫阶段处理采集到的信息;)async with AsyncWebCrawler(config=browser_config) as crawler:results = await crawler.arun_many(urls=urls, dispatcher=_dispatcher, config=run_config)for result in results:try:if result._results[0].success:print(result._results[0].markdown[0:70] if result._results[0] else "当前为 NoneType")except Exception as e:print(f"当前结果提取异常:{e}")if __name__ == '__main__':import timestart = time.time()asyncio.run(my_main())end = time.time()print(f"总耗时:{end - start}") # 约 100 S在使用流式处理的时候,不建议上述的调试器
参考:https://github.com/unclecode/crawl4ai/issues/857
import asynciofrom crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, RateLimiter ,MemoryAdaptiveDispatcherurls = ['https://blog.csdn.net/hanwb2010/article/details/154112857','https://blog.csdn.net/codeshare1135/article/details/154183256','https://blog.csdn.net/m0_67641255/article/details/154183503','https://blog.csdn.net/baidu_41666295/article/details/154015073','https://blog.csdn.net/weixin_45399602/article/details/153396385','https://blog.csdn.net/weixin_45399602/article/details/153396258',# .....]async def process_result(result):"""实时处理单个爬取结果"""print(f"✅ 成功爬取: {result.url}")# 此处可添加解析、存储等逻辑(如写入数据库、提取关键信息)# 示例:打印内容长度print(f" 内容长度: {len(result.content)} 字符\n")async def my_main():print("1. 定义速率限制器")rate_limiter = RateLimiter(base_delay=(2.0, 4.0), # 2-4秒之间的随机延迟max_delay=30.0, # 延迟上限为30秒max_retries=5, # 在速率限制错误时最多重试5次rate_limit_codes=[429, 503] # 处理这些HTTP状态码)# 定义调度器# _dispatcher = SemaphoreDispatcher(# # rate_limiter=rate_limiter,# max_session_permit=10,# )_dispatcher = MemoryAdaptiveDispatcher(memory_threshold_percent=90.0,check_interval=1.0,max_session_permit=10,)browser_config = BrowserConfig()run_config = CrawlerRunConfig(word_count_threshold=10, # 采集的时候字数阈值的设置;exclude_external_links=True, # 过滤掉外部的链接;remove_overlay_elements=True, # 移除弹窗等元素;process_iframes=True, # 处理 iframe 中的关系stream=True # 允许在爬虫阶段处理采集到的信息;)async with AsyncWebCrawler(config=browser_config) as crawler:async for result in await crawler.arun_many(urls=urls, dispatcher=_dispatcher, config=run_config):try:if result.success:print("OK")await process_result(result)# print(result._results[0].markdown[0:70] if result._results[0] else "当前为 NoneType")except Exception as e:print(f"当前结果提取异常:{e}")if __name__ == '__main__':import timestart = time.time()asyncio.run(my_main())end = time.time()print(f"总耗时:{end - start}") # 约 90 S
但是这个情况,会出现内存过高的时候直接卡死的状况,导致任务卡在此处不进行执行;

6. 总结
Crawl4ai 是一款以 “AI 增强 + 动态渲染” 为核心的 Python 网页爬取框架,主打简单易用与智能数据处理,专为现代动态网页(如 SPA 单页应用)设计,核心价值是降低复杂网页爬取的技术门槛,同时提升数据提取的效率与质量。
Crawl4ai 打破了 “请求 - 解析” 的传统爬虫逻辑,核心优势在于 “AI 驱动的内容理解”:
-
传统爬虫(Scrapy/BeautifulSoup)依赖人工编写固定解析规则,页面结构变化后需重新维护;Crawl4ai 可通过 AI 自动识别目标内容,适配不同结构网页。
-
传统爬虫处理动态内容需额外集成 Selenium/Puppeteer,配置复杂;Crawl4ai 原生封装 Playwright,无需手动处理渲染细节。
-
传统爬虫难以应对非结构化内容提取(如从新闻 / 博客中分离 “标题 - 作者 - 核心观点”);Crawl4ai 结合语义理解,实现 “内容到结构化数据” 的直接转化。
-
优势场景:
- 动态网页爬取(SPA 应用、JS 加密内容)。
- 非固定模板数据提取(如不同结构的博客、论坛评论)。
- 快速原型开发(无需编写复杂解析规则,几行代码完成爬取 - 提取全流程)。
- 中低并发的精准数据采集(如行业报告、新闻摘要、商品信息)。
-
局限性:
- 高并发海量爬取场景:AI 处理与浏览器渲染存在性能开销,效率不及轻量化的传统爬虫(如 Scrapy)。
- 纯静态结构化数据:无需动态渲染与 AI 分析时,传统爬虫更简洁高效。
- LLM 依赖成本:AI 增强提取需消耗令牌,且受网络 / 模型响应速度影响。
-
核心价值
-
降低技术门槛:让非专业爬虫开发者通过自然语言或简单配置,即可完成复杂网页的数据提取。
-
平衡 “效率与精度”:提供 “无 LLM 精准提取” 与 “AI 灵活提取” 两种模式,按需选择以控制成本与效率。
-
工程化封装:整合渲染、反爬、并发、数据清洗等环节,形成闭环解决方案,减少开发者的重复工作。
-
-
使用建议
-
优先选择无 LLM 提取(CSS/XPath/ 正则)处理结构化数据,兼顾效率与成本。
-
爬取动态 / 非固定模板网页时,启用 AI 提取功能,通过 schema 定义输出格式,确保数据结构化。
-
高并发场景下,使用内存自适应调度器,合理设置并发数与请求延迟,避免 IP 封禁。
-
避免过度依赖 LLM:对于简单场景,传统提取方式更稳定,且无额外成本与延迟。
-
继续努力,终成大器。