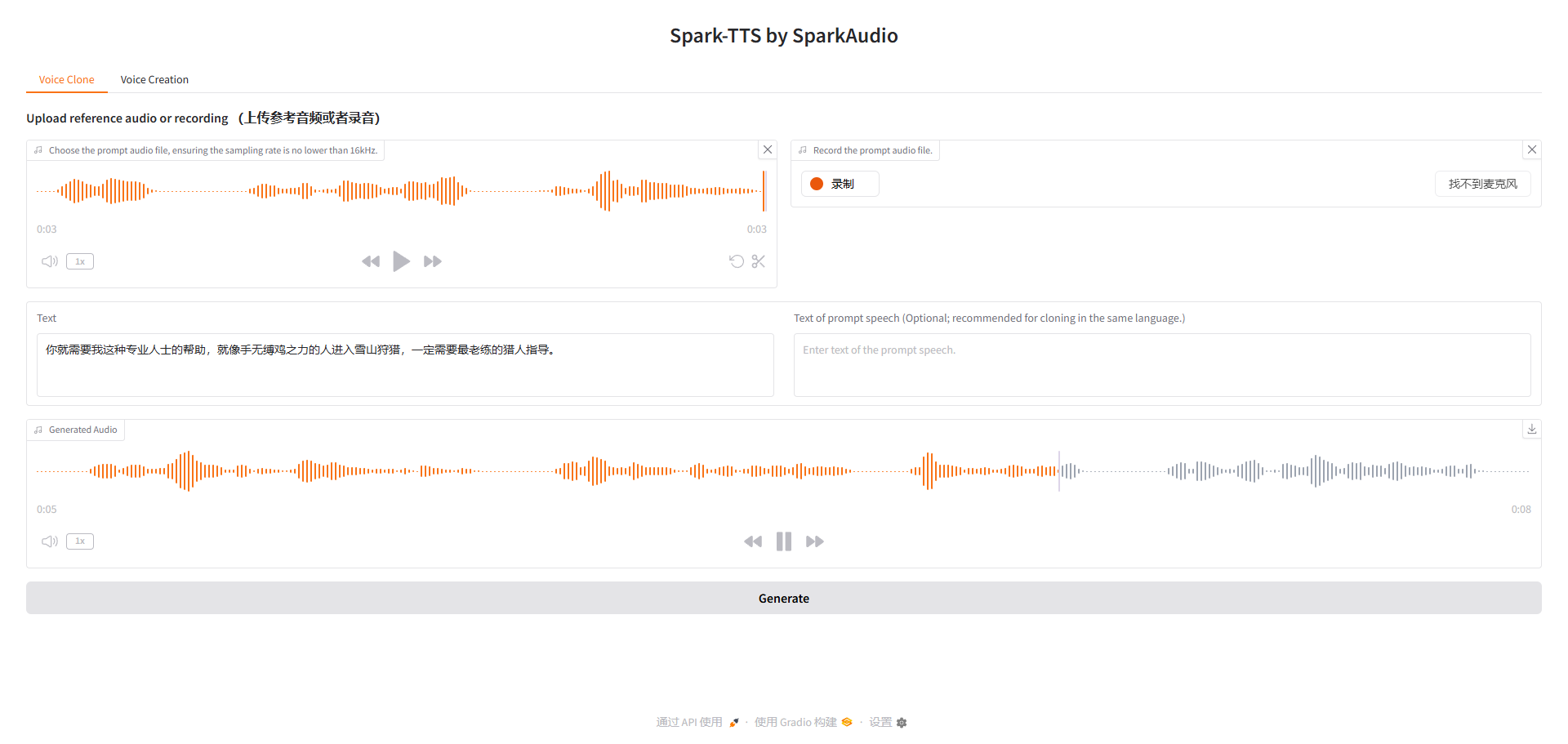
在ec2上部署indexTTS和尝试部署sparkTTS模型
模型比较,来自AI输出的结果如下
| 需求优先级 | 推荐模型 |
|---|---|
| 音色最像真人 + 多音字可控 | IndexTTS |
| 情感丰富 + 支持笑声/呼吸等 | CosyVoice |
| 低资源 + 快速部署 + 音色克隆 | SparkTTS |
部署indexTTS模型
- https://www.modelscope.cn/models/IndexTeam/Index-TTS
- https://github.com/index-tts/index-tts/blob/main/docs/README_zh.md
- https://indextts.org/zh
- https://indextts.org/zh/features/qwen3-tts
IndexTTS-2.0是哔哩哔哩自研语音生成大模型,一种通用且适用于自回归模型的语音时长控制方法。于2025/09/08发布,是首个支持精确合成时长控制的自回归TTS模型,支持可控与非可控模式。并且模型实现高度情感表达的语音合成,支持多模态情感控制。
下载模型
modelscope download --model IndexTeam/IndexTTS-2
# /home/ubuntu/.cache/modelscope/hub/models/IndexTeam/IndexTTS-2
克隆和初始化项目
git clone https://github.com/index-tts/index-tts.git && cd index-ttspip install uv
uv sync --all-extras --default-index "https://mirrors.aliyun.com/pypi/simple"
检测GPU设备存在
$ uv run tools/gpu_check.py
Scanning for PyTorch hardware acceleration devices...PyTorch: NVIDIA CUDA / AMD ROCm is available!* Number of CUDA devices found: 1* Device 0: "NVIDIA A10G"
PyTorch: No devices found for Intel XPU backend.
PyTorch: No devices found for Apple MPS backend.Hardware acceleration detected. Your system is ready!
查看帮助
$ uv run webui.py --help-h, --help show this help message and exit--verbose Enable verbose mode (default: False)--port PORT Port to run the web UI on (default: 7860)--host HOST Host to run the web UI on (default: 0.0.0.0)--model_dir MODEL_DIRModel checkpoints directory (default: ./checkpoints)--fp16 Use FP16 for inference if available (default: False)--deepspeed Use DeepSpeed to accelerate if available (default: False)--cuda_kernel Use CUDA kernel for inference if available (default: False)--gui_seg_tokens GUI_SEG_TOKENSGUI: Max tokens per generation segment (default: 120)
启动webui报错,程序试图下载 facebook/w2v-bert-2.0 模型的相关配置文件失败了。
facebook/w2v-bert-2.0是一个先进的语音表示模型,当使用"情感参考音频"功能时,需要将参考音频转换为特征向量w2v-bert-2.0用于提取这些音频的情感特征
requests.exceptions.ConnectionError: (MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /facebook/w2v-bert-2.0/resolve/main/preprocessor_config.json (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x725c09c30ca0>: Failed to establish a new connection: [Errno 101] Network is unreachable'))"), '(Request ID: a902c06d-18f9-453f-91ef-14ff89600781)')
...
OSError: We couldn't connect to 'https://huggingface.co' to load the files, and couldn't find them in the cached files.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
文档提到首次运行会额外下载部分小模型,需要设置镜像
export HF_ENDPOINT="https://hf-mirror.com"
运行日志会加载模型权重和以下子系统
- 语义编解码器 (semantic_codec)
- 声学模型 (s2mel - spectrogram to mel)
- 语音识别前端模型 (campplus)
- 声码器 (bigvgan)
>> semantic_codec weights restored from: ...
>> s2mel weights restored from: ...
>> campplus_model weights restored from: ...
>> bigvgan weights restored from: ...
webui界面,用qwen-tts生成音频提示后合成音频
- 如果要使用示例音频,需要通过git lfs额外下载大文件
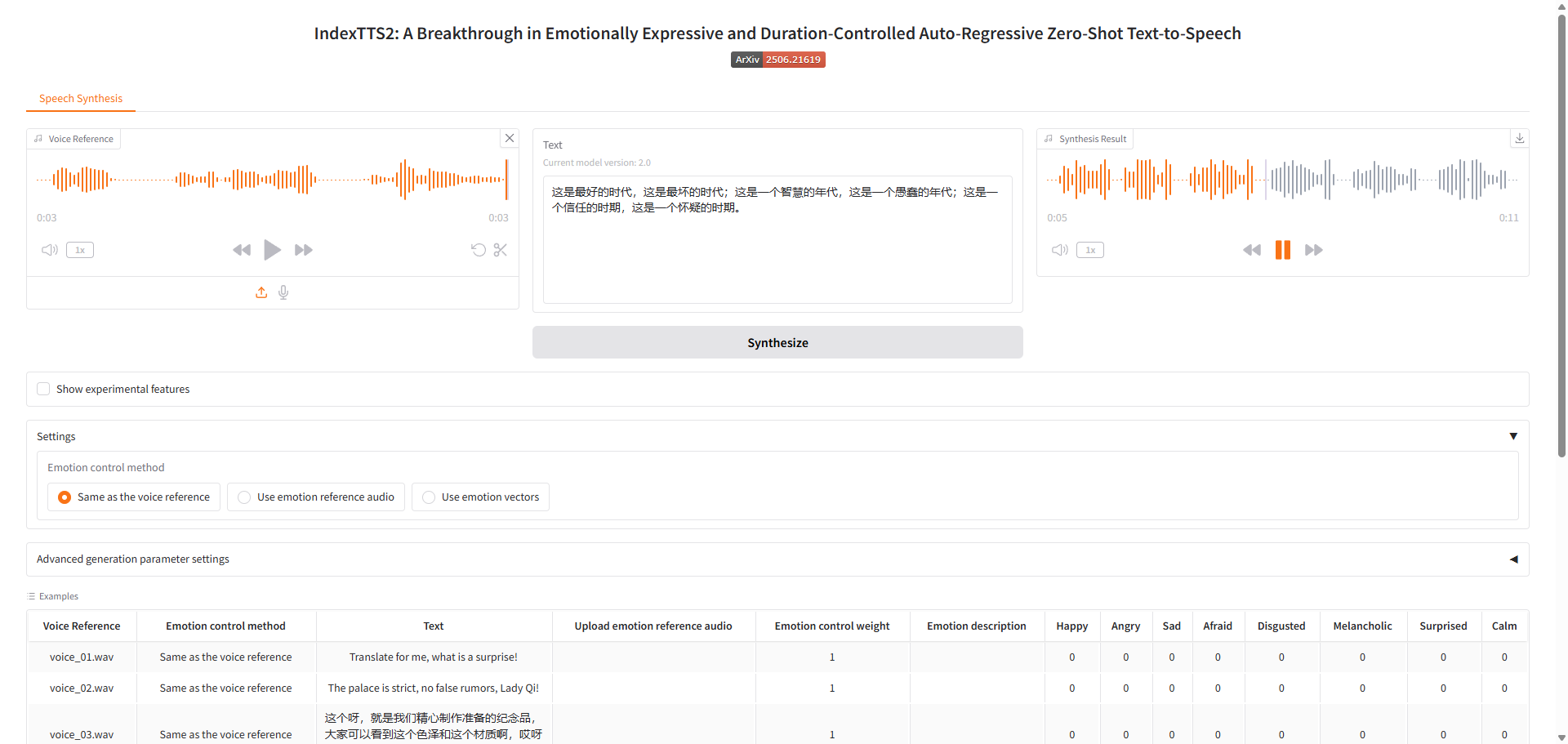
也可以通过脚本生成,额外的示例参考,如下是单一音色克隆。执行过程如下
- GPT模型权重从
gpt.pth恢复 - semantic_codec 权重从 HuggingFace 缓存加载,负责将音频信号转换为语义token序列,或将语义token序列还原为音频特征
- s2mel 权重从
s2mel.pth恢复,负责将语义编码转换为梅尔频谱图,包含语音的频率和时间信息,将抽象的语义 token 解码为具体的声学参数,作为桥梁连接高层语义信息和底层声学特征 - campplus 模型权重加载,通常用于从参考音频中提取说话人特征或嵌入向量
- bigvgan 权重加载(用于声码器),基于GAN的声码器,负责将梅尔频谱图转换为最终的音频波形
- 加载了多个核心组件:cfm、length_regulator、gpt_layer等
- 初始化文本正则化器(TextNormalizer)
- 加载 BPE 分词模型(bpe.model)
文本处理
- 使用 BPE 模型进行分词,将文本转换为 token 序列
- 并对文本进行标准化处理(数字、日期等规范化)
语音合成
- 语义编码:使用 GPT 模型生成语义 token 序列
- 声学特征转换:通过 s2mel 模型将语义特征转换为梅尔频谱
- 波形合成:使用 bigvgan 声码器将梅尔频谱转换为音频波形
from indextts.infer_v2 import IndexTTS2
checkpoints = "/home/ubuntu/.cache/modelscope/hub/models/IndexTeam/IndexTTS-2"
tts = IndexTTS2(cfg_path=f"{checkpoints}/config.yaml", model_dir=f"{checkpoints}", use_fp16=False, use_cuda_kernel=False, use_deepspeed=False)
text = "这是最好的时代,这是最坏的时代;这是一个智慧的年代,这是一个愚蠢的年代;这是一个信任的时期,这是一个怀疑的时期。"
tts.infer(spk_audio_prompt='examples/demo.wav', text=text, output_path="gen.wav", verbose=True)
参考论文,https://arxiv.org/abs/2506.21619
IndexTTS2 是一个级联系统,包含如下部分。并新增 T2E(Text-to-Emotion)模块 实现自然语言情感控制。
| T2S(Text-to-Semantic) | 自回归生成语义 token(基于文本 + 音色/情感提示 + 可选时长) |
|---|---|
| S2M(Semantic-to-Mel) | 非自回归生成梅尔频谱(引入 GPT 隐状态增强清晰度) |
| Vocoder | 使用 BigVGANv2 将梅尔转为波形 |
部署sparkTTS模型
- https://github.com/sparkaudio/spark-tts
- https://sparktts.io/zh
park-TTS 完全基于 Qwen2.5 构建,无需额外的生成模型如流匹配。它不依赖独立的模型来生成声学特征,而是直接从 LLM 预测的代码重建音频。
论文参考,https://arxiv.org/pdf/2503.01710
模型下载
modelscope download --model SparkAudio/Spark-TTS-0.5B
# /home/ubuntu/.cache/modelscope/hub/models/SparkAudio/Spark-TTS-0.5B
推理示例
bash example/infer.sh
推理入口为
python -m cli.inference \--text "${text}" \--device "${device}" \--save_dir "${save_dir}" \--model_dir "${model_dir}" \--prompt_text "${prompt_text}" \--prompt_speech_path "${prompt_speech_path}"
关于cli.inference的帮助,主要是初始化模型 (SparkTTS)并执行推理 (model.inference)和保存音频文件 (使用时间戳命名)
--model_dir # 模型目录路径,默认为 pretrained_models/Spark-TTS-0.5B
--save_dir # 音频保存目录,默认为 example/results
--device # CUDA设备编号,默认为0
--text # 必需参数,需要转换为语音的文本内容
--prompt_text # 提示音频的文字内容(可选)
--prompt_speech_path # 提示音频文件路径(可选)
--gender # 性别选项(male/female)
--pitch # 音调选项(very_low/low/moderate/high/very_high)
--speed # 语速选项(very_low/low/moderate/high/very_high)
实际的推理过程如下
-
使用模型生成语音对应的语义标记序列,从生成结果中提取语义与全局声学标记,利用音频解码器将标记还原为最终语音波形。
-
核心的
BiCodecTokenizer类是 Spark-TTS 系统中的音频编解码器组件,主要负责将音频信号转换为模型可处理的标记(tokens),以及将标记还原为音频波形。
def run_tts(args):...# Initialize the modelmodel = SparkTTS(args.model_dir, device)...logging.info("Starting inference...")# Perform inference and save the output audiowith torch.no_grad():wav = model.inference(args.text,args.prompt_speech_path,prompt_text=args.prompt_text,gender=args.gender,pitch=args.pitch,speed=args.speed,)sf.write(save_path, wav, samplerate=16000)logging.info(f"Audio saved at: {save_path}")
启动webui
python webui.py --device 0 --model_dir /home/ubuntu/.cache/modelscope/hub/models/SparkAudio/Spark-TTS-0.5B
报错,可能是兼容性问题,用pip install --upgrade gradio更新gradio
ERROR: Exception in ASGI application
Traceback (most recent call last):File "/home/ubuntu/vlmodel/.venv/lib/python3.12/site-packages/uvicorn/protocols/http/h11_impl.py", line
TypeError: argument of type 'bool' is not iterable
再次启动