Java集合框架深度剖析 — 从源码看ArrayList、HashMap的设计与优化
目录
摘要
一、集合框架总体架构与设计哲学
1.1 集合框架的演进历程
1.2 集合框架的接口层次结构
二、ArrayList深度源码解析
2.1 底层数据结构与核心字段
2.2 动态扩容机制详解
2.3 扩容过程可视化
2.4 性能分析与优化建议
三、HashMap深度源码解析
3.1 底层数据结构演进
3.2 哈希算法与索引计算
3.3 put操作完整流程
3.4 扩容机制resize()
3.5 红黑树优化机制
四、并发修改异常与故障快速机制
4.1 Fail-Fast机制原理
4.2 并发修改场景分析
五、性能对比与最佳实践
5.1 集合操作性能对比表
5.2 实战优化建议
六、总结与进阶思考
📌 核心要点回顾:
🚀 进阶思考问题:
🔧 性能调优检查表:
七、参考链接
摘要
Java集合框架是每个Java开发者必须掌握的核心基础设施,其设计理念和实现细节直接影响着应用程序的性能表现。本文将深入ArrayList、HashMap等核心容器的源码实现,通过架构图、性能对比图表和实战案例,揭示其背后的数据结构和算法选择。从数组动态扩容到红黑树优化,从哈希冲突解决到并发修改异常,本文将为你提供一幅完整的集合框架技术图谱。
一、集合框架总体架构与设计哲学
1.1 集合框架的演进历程
Java集合框架经历了从JDK 1.0的Vector、Hashtable到JDK 1.2的重新设计,再到JDK 1.5引入泛型、JDK 1.8引入Lambda表达式和Stream API的重大演进。
// JDK 1.0时代的集合(已过时但仍有使用)
Vector<String> oldVector = new Vector<>();
Hashtable<String, String> oldTable = new Hashtable<>();// 现代集合框架(推荐使用)
List<String> list = new ArrayList<>();
Map<String, String> map = new HashMap<>();
Set<String> set = new HashSet<>();1.2 集合框架的接口层次结构
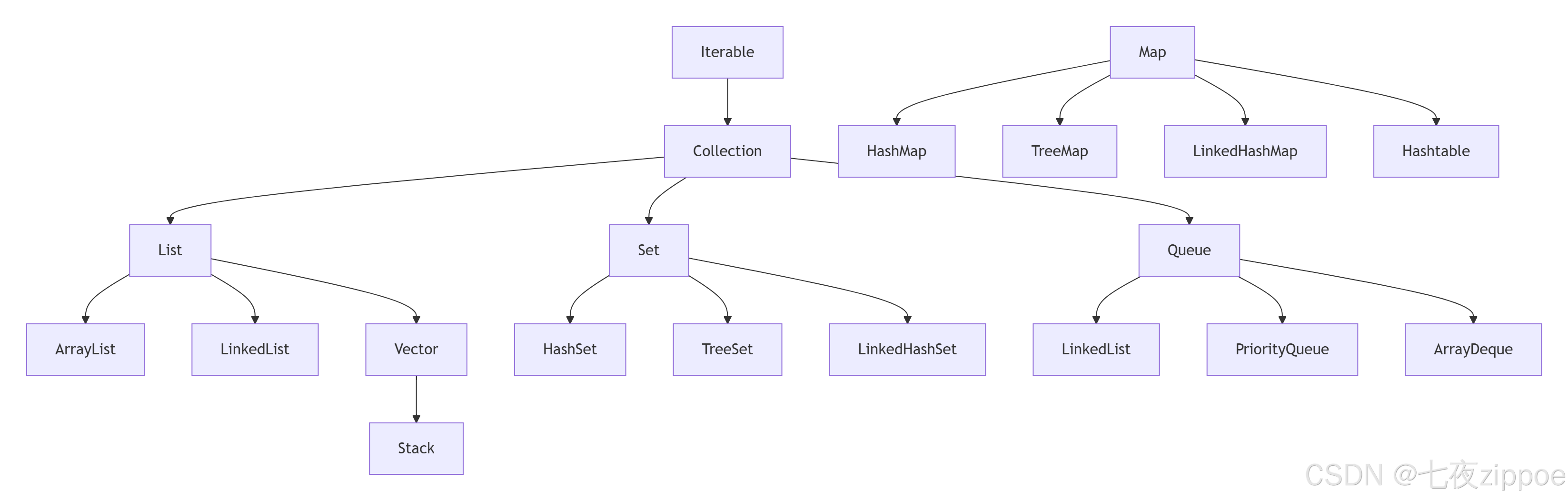
设计哲学:
- 接口与实现分离:
List接口与ArrayList、LinkedList实现 - 算法复用:
Collections工具类提供通用算法 - 迭代器模式:统一的遍历方式
- 泛型类型安全:编译时类型检查
二、ArrayList深度源码解析
2.1 底层数据结构与核心字段
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable {// 默认初始容量private static final int DEFAULT_CAPACITY = 10;// 存储元素的数组缓冲区transient Object[] elementData;// 列表中元素的实际数量private int size;// 空数组实例,用于空实例的共享private static final Object[] EMPTY_ELEMENTDATA = {};// 默认大小的空数组实例private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
}2.2 动态扩容机制详解
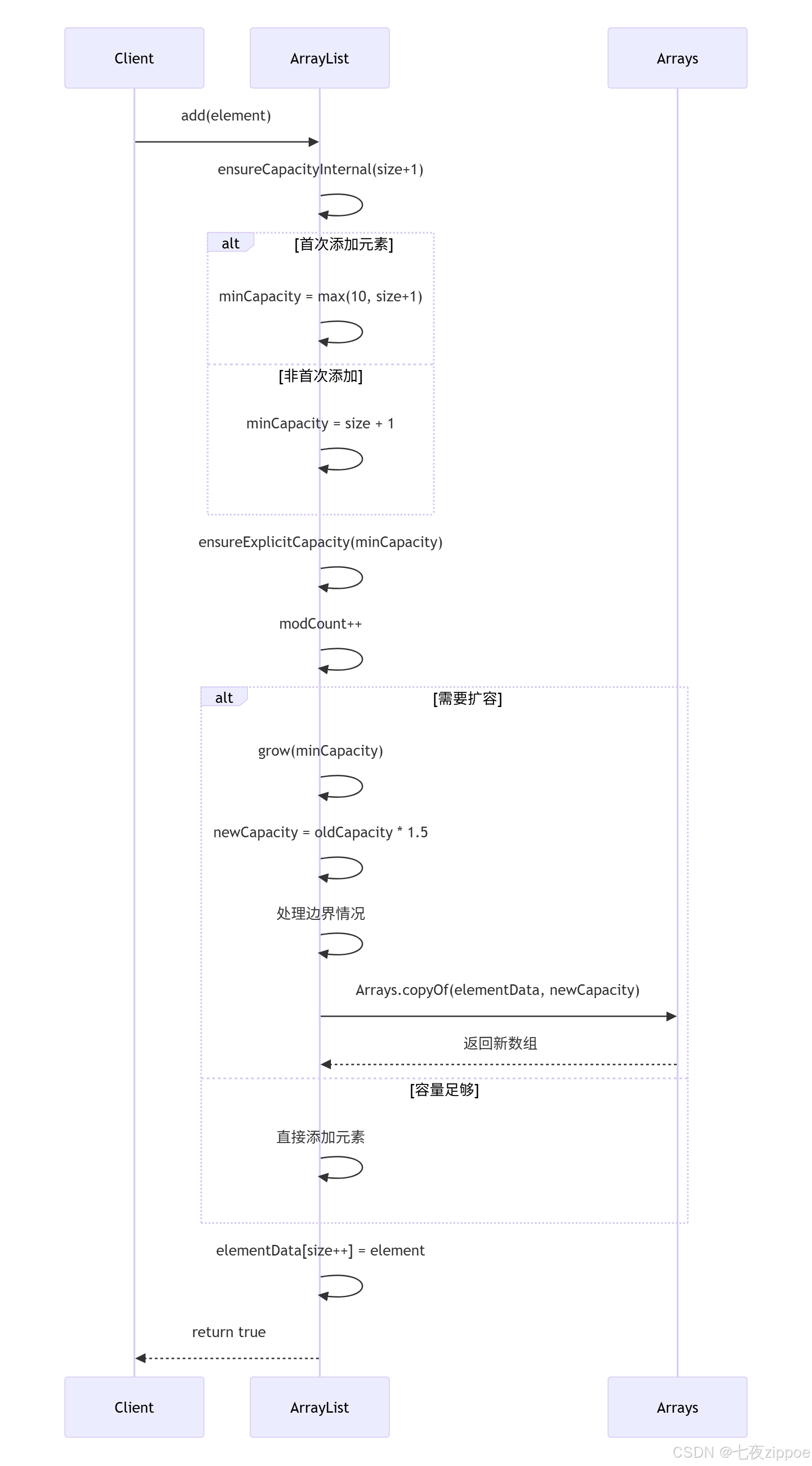
public boolean add(E e) {// 确保内部容量足够ensureCapacityInternal(size + 1);// 将元素添加到数组末尾elementData[size++] = e;return true;
}private void ensureCapacityInternal(int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {// 如果是第一次添加元素,选择默认容量和minCapacity中的较大值minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}ensureExplicitCapacity(minCapacity);
}private void ensureExplicitCapacity(int minCapacity) {modCount++; // 结构性修改计数器// 如果最小所需容量大于当前数组长度,则进行扩容if (minCapacity - elementData.length > 0)grow(minCapacity);
}private void grow(int minCapacity) {int oldCapacity = elementData.length;// 新容量 = 旧容量的1.5倍int newCapacity = oldCapacity + (oldCapacity >> 1);// 如果新容量仍小于最小所需容量,则使用最小所需容量if (newCapacity - minCapacity < 0)newCapacity = minCapacity;// 如果新容量超过最大数组大小限制,进行特殊处理if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// 数组拷贝到新数组elementData = Arrays.copyOf(elementData, newCapacity);
}2.3 扩容过程可视化
2.4 性能分析与优化建议
时间复杂度分析:
- 随机访问:O(1) - 基于数组索引
- 尾部插入:O(1) 摊销 - 考虑扩容的均摊成本
- 中间插入:O(n) - 需要移动后续元素
- 删除操作:O(n) - 需要移动后续元素
// 优化实践:预分配容量避免频繁扩容
public class ArrayListOptimization {public static void main(String[] args) {// 错误做法:频繁扩容List<Integer> badList = new ArrayList<>();for (int i = 0; i < 1000000; i++) {badList.add(i); // 可能经历多次扩容}// 正确做法:预分配容量List<Integer> goodList = new ArrayList<>(1000000);for (int i = 0; i < 1000000; i++) {goodList.add(i); // 无扩容开销}}// 批量添加优化public static void addAllOptimization() {List<Integer> list = new ArrayList<>();Integer[] array = new Integer[1000];// 填充array...// 优于循环添加Collections.addAll(list, array);// 或者list.addAll(Arrays.asList(array));}
}三、HashMap深度源码解析
3.1 底层数据结构演进
JDK 1.7及之前:数组 + 链表
JDK 1.8及之后:数组 + 链表/红黑树
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable {// 默认初始容量 - 必须是2的幂static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 16// 最大容量static final int MAXIMUM_CAPACITY = 1 << 30;// 默认负载因子static final float DEFAULT_LOAD_FACTOR = 0.75f;// 链表转红黑树的阈值static final int TREEIFY_THRESHOLD = 8;// 红黑树转链表的阈值static final int UNTREEIFY_THRESHOLD = 6;// 表的最小树化容量static final int MIN_TREEIFY_CAPACITY = 64;// 哈希表数组transient Node<K,V>[] table;// 键值对数量transient int size;// 结构性修改次数transient int modCount;// 扩容阈值 (capacity * loadFactor)int threshold;// 负载因子final float loadFactor;
}3.2 哈希算法与索引计算
// HashMap中的哈希函数
static final int hash(Object key) {int h;// 关键:让高位参与哈希计算,减少哈希冲突return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}// 计算数组索引
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 懒初始化:第一次put时初始化tableif ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 计算索引:i = (n - 1) & hashif ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {// 处理哈希冲突...}// ...
}索引计算原理:
hash = key.hashCode() ^ (key.hashCode() >>> 16)
index = (table.length - 1) & hash3.3 put操作完整流程
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 步骤1:表为空或长度为0,进行扩容if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 步骤2:计算索引位置,如果该位置为空,直接插入新节点if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {// 步骤3:处理哈希冲突Node<K,V> e; K k;// 情况1:key已存在且哈希相等if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))e = p;// 情况2:该节点是树节点else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 情况3:遍历链表else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);// 链表长度达到阈值,转换为红黑树if (binCount >= TREEIFY_THRESHOLD - 1)treeifyBin(tab, hash);break;}if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 步骤4:key已存在,替换valueif (e != null) {V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}// 步骤5:更新modCount和size,检查是否需要扩容++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;
}3.4 扩容机制resize()
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;// 计算新容量和新阈值if (oldCap > 0) {if (oldCap >= MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return oldTab;}// 新容量 = 旧容量 * 2else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr << 1; // 新阈值 = 旧阈值 * 2}// 初始化逻辑...// 重新哈希:将元素重新分布到新表中if (oldTab != null) {for (int j = 0; j < oldCap; ++j) {Node<K,V> e;if ((e = oldTab[j]) != null) {oldTab[j] = null;if (e.next == null)// 单个节点直接重新计算位置newTab[e.hash & (newCap - 1)] = e;else if (e instanceof TreeNode)// 红黑树拆分((TreeNode<K,V>)e).split(this, newTab, j, oldCap);else {// 链表优化重哈希:利用高位判断新位置Node<K,V> loHead = null, loTail = null;Node<K,V> hiHead = null, hiTail = null;Node<K,V> next;do {next = e.next;// 关键优化:判断高位bitif ((e.hash & oldCap) == 0) {// 位置不变if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;} else {// 新位置 = 旧位置 + oldCapif (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) {loTail.next = null;newTab[j] = loHead;}if (hiTail != null) {hiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab;
}3.5 红黑树优化机制
// 链表转红黑树
final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;// 先检查表容量是否达到最小树化容量if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize(); // 容量不足,先扩容而不是树化else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;// 将链表转换为TreeNode链表do {TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);// 将TreeNode链表转换为红黑树if ((tab[index] = hd) != null)hd.treeify(tab);}
}四、并发修改异常与故障快速机制
4.1 Fail-Fast机制原理
public abstract class AbstractList<E> {protected transient int modCount = 0;
}// 迭代器中的Fail-Fast检查
private class Itr implements Iterator<E> {int expectedModCount = modCount;public E next() {checkForCommodification(); // 检查modCount// ... 其他逻辑}final void checkForCommodification() {if (modCount != expectedModCount)throw new ConcurrentModificationException();}
}4.2 并发修改场景分析
public class ConcurrentModificationDemo {public static void main(String[] args) {// 场景1:迭代过程中修改集合List<String> list = new ArrayList<>(Arrays.asList("A", "B", "C"));// 错误示例:在迭代中直接修改try {for (String item : list) {if ("B".equals(item)) {list.remove(item); // 抛出ConcurrentModificationException}}} catch (ConcurrentModificationException e) {System.out.println("检测到并发修改: " + e.getMessage());}// 正确做法1:使用迭代器的remove方法Iterator<String> iterator = list.iterator();while (iterator.hasNext()) {String item = iterator.next();if ("B".equals(item)) {iterator.remove(); // 安全删除}}// 正确做法2:使用removeIf(Java 8+)list.removeIf("B"::equals);// 正确做法3:使用CopyOnWriteArrayList(并发场景)List<String> concurrentList = new CopyOnWriteArrayList<>(Arrays.asList("A", "B", "C"));for (String item : concurrentList) {if ("B".equals(item)) {concurrentList.remove(item); // 安全,但迭代的是旧数组快照}}}
}五、性能对比与最佳实践
5.1 集合操作性能对比表
| 操作 | ArrayList | LinkedList | HashMap | TreeMap |
|---|---|---|---|---|
| get/put | O(1) | O(n) | O(1) | O(log n) |
| add/remove(头) | O(n) | O(1) | - | - |
| add/remove(尾) | O(1)摊销 | O(1) | - | - |
| contains | O(n) | O(n) | O(1) | O(log n) |
| 迭代 | 快 | 慢 | 快 | 中 |
| 内存占用 | 小 | 大 | 中 | 中 |
5.2 实战优化建议
public class CollectionBestPractices {// 1. 选择合适的初始容量public void initialCapacityOptimization() {// 预估元素数量,避免频繁扩容Map<String, String> map = new HashMap<>(1000);List<Integer> list = new ArrayList<>(500);}// 2. 使用合适的哈希函数public void hashFunctionOptimization() {class GoodKey {private final String value;public GoodKey(String value) { this.value = value; }@Overridepublic int hashCode() {// 好的哈希函数:分布均匀return Objects.hash(value);}@Overridepublic boolean equals(Object obj) {// 必须重写equalsif (this == obj) return true;if (obj == null || getClass() != obj.getClass()) return false;GoodKey goodKey = (GoodKey) obj;return Objects.equals(value, goodKey.value);}}}// 3. 批量操作优化public void batchOperationOptimization() {List<Integer> source = Arrays.asList(1, 2, 3, 4, 5);List<Integer> target = new ArrayList<>();// 优于循环addtarget.addAll(source);// 或者使用Collections.addAllCollections.addAll(target, 1, 2, 3, 4, 5);}// 4. 使用不可变集合public void immutableCollectionUsage() {// Java 9+ 的工厂方法List<String> immutableList = List.of("A", "B", "C");Map<String, Integer> immutableMap = Map.of("A", 1, "B", 2);// 或者使用Collections.unmodifiableListList<String> unmodifiable = Collections.unmodifiableList(new ArrayList<>());}
}六、总结与进阶思考
📌 核心要点回顾:
-
ArrayList基于动态数组:随机访问快,中间插入删除慢,需要注意扩容开销
-
HashMap基于哈希表+红黑树:JDK 8的树化优化大幅提升了最坏情况性能
-
Fail-Fast机制:通过modCount检测并发修改,保证数据一致性
-
容量规划很重要:合适的初始容量和负载因子能显著提升性能
🚀 进阶思考问题:
-
为什么HashMap容量总是2的幂次方?这如何优化哈希分布和索引计算?
-
红黑树与链表的转换阈值为什么是8和6?这个选择的统计学依据是什么?
-
在多线程环境下,除了ConcurrentHashMap还有哪些线程安全的集合方案?
-
Java 8的Stream API如何与集合框架协同工作?背后的Spliterator机制是什么?
🔧 性能调优检查表:
- [ ] 为ArrayList设置合适的初始容量
- [ ] 为HashMap设置合理的初始容量和负载因子
- [ ] 为作为HashMap键的对象实现良好的hashCode()和equals()
- [ ] 在多线程环境下使用并发集合
- [ ] 避免在迭代过程中直接修改集合
- [ ] 考虑使用不可变集合保证线程安全
七、参考链接
-
Oracle集合框架教程
-
ArrayList源码分析
-
HashMap源码分析
-
Java集合框架性能比较
-
红黑树算法详解