VMware替代 | ZStack ZSphere虚拟化平台金融级高可用能力解析
在博通完成对VMware收购后,已全面推行订阅制模式,原有企业正面临虚拟化基础设施的刚性成本重构。越来越多的企业开始评估替代方案,用户除了关注新平台在TCO、迁移、生态等方面的能力外,平替高可用能力也是企业用户最关注的核心之一。
ZStack ZSphere作为新一代虚拟化平台,通过全栈高可用设计,为用户业务提供不同维度的高可用保护,包括:
- 从基础设施的高可用,到冗余网络架构和存储多副本多路径
- 从平台自身的高可用设计,到业务虚拟机的高可用保障
这种多层次的高可用架构,不仅确保了企业业务不间断运行,更为正在寻求VMware替代方案的企业提供了可靠的技术路径新选项,为企业构建了更加稳健、经济的虚拟化平台基础架构,带来99.99%金融级高可用性和稳定性服务。
一、 ZStack ZSphere “双管理节点”构建起平台管理高可用基石
在虚拟化平台的整体高可用架构中,管理节点的高可用性是核心与基石。管理节点负责整个平台的资源管控、监控、调度、分配和回收。管理节点若出现宕机,管理服务将不可用,直接影响到平台的运维管理、监控报警、自动化任务执行等,对平台的运维工作产生较大影响。因此,ZStack ZSphere通过双管理节点高可用(HA)方案,构建起金融级高可用架构,有效解决了管理服务单点故障的难题,确保平台管控面持续稳定运行。
ZStack ZSphere采用主备模式部署两个管理节点,通过虚拟IP对外提供服务。其核心实现依赖于内置的HA进程,该进程负责管理节点环境的初始化、服务监控及故障处理。HA进程持续监控关键服务状态,包括管理节点核心进程、Web UI及数据库。一旦检测到服务异常,便会通过Keepalived机制触发VIP漂移至对端健康节点,实现访问流量的秒级切换,最大限度减少管理中断时间。
为确保数据一致性,ZStack ZSphere采用数据库自动同步机制。当故障节点恢复后,数据库可自动完成数据同步,无需人工干预,保障了配置信息的完整性。方案还引入了独立的仲裁网关,有效避免了传统双节点集群中可能出现的“脑裂”问题,提升了集群决策的可靠性。
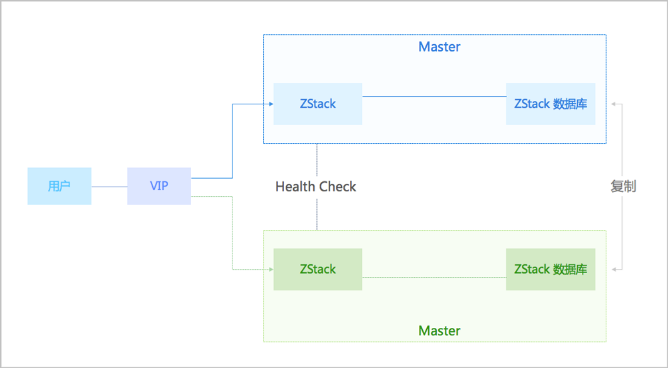
(ZStack双管理节点高可用方案图)
此外,ZStack提供了完善的状态监控功能,运维人员可实时查看主备管理节点的状态、VIP可达性、数据库同步状态及仲裁IP的健康情况,便于快速定位潜在风险。这套管理节点高可用方案部署简便,运维体验与单节点一致,却极大地提升了平台管理层的故障容忍度和业务连续性,为替换VMware提供了坚实可靠的基础保障。
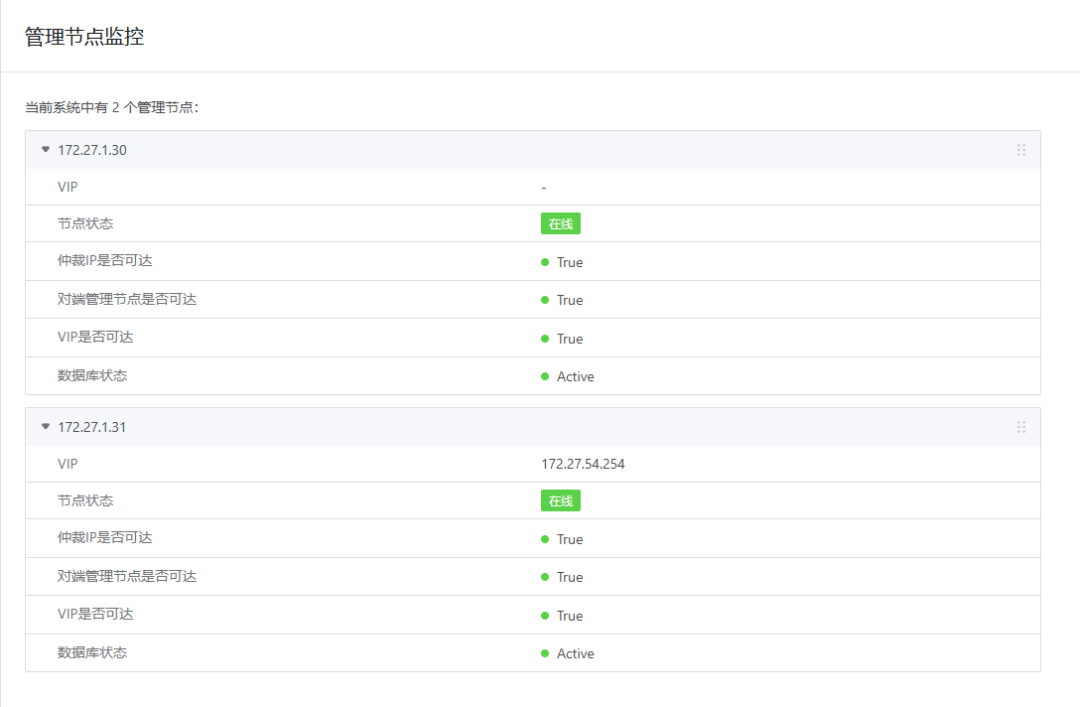
(ZStack管理节点监控界面)
二、 多种机制确保虚拟机高可用
在替换VMware时,用户都会关心当工作负载运行在新平台的虚拟机上时,高可用能力是否可以守住业务的“生命线”,保障业务连续性。
当用户从VMware迁移到ZStack ZSphere虚拟化平台后,为了保障虚拟机业务的高可用性,ZStack ZSphere平台会持续对集群内所有的服务器主机与虚拟机运行状况进行检测,一旦某台服务器发生故障,管理节点会持续进行检测,确定此服务器宕机后,会立即在集群内另一台服务器上重启所有受影响的虚拟机,保证业务的连续性。
ZStack ZSphere平台虚拟化高可用方案不需要专门的备用硬件,也不需要集成其他软件,就可以将停机时间和 IT 服务中断时间降到最低程度。同时避免单一操作系统或特定于应用程序的故障切换解决方案带来的成本和复杂性。
ZStack ZSphere平台提供多种虚拟机高可用故障迁移策略:针对虚拟机相关计算、存储、网络等资源发生故障时是否高可用至其他物理机启动。
1)轮询故障检测机制保障虚拟机顺利迁移
故障迁移策略支持检测以下资源状态:
- 管理网络连接状态:
- 检测虚拟机所在物理机与管理节点之间的网络连接状态。
- 若管理节点自身故障、或管理网络中断,均会导致管理网络连接状态故障。
- 存储网络连接状态 :
- 检测虚拟机访问其系统盘所在数据存储资源的网络连接状态。
- 若虚拟机系统盘所在数据存储自身故障、或存储网络中断,均会导致虚拟机存储网络连接状态故障。
- 业务网卡状态 :
- 若业务虚拟机使用的分布式交换机对应的上行链路业务网卡或者业务网卡直连的交换机网口发生故障,会导致虚拟机业务网卡故障。
基于资源状态检测,故障迁移策略支持真值表配置:
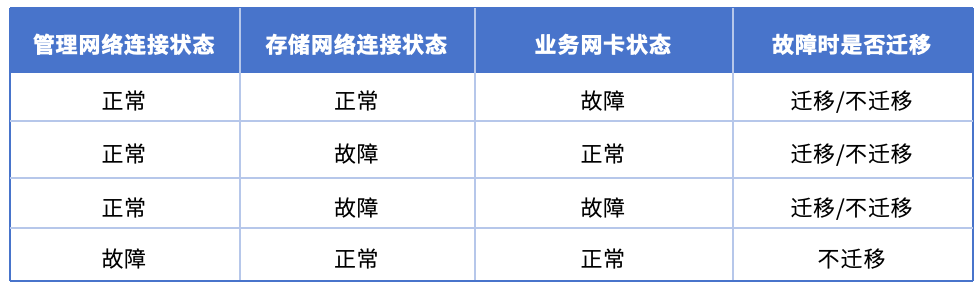
轮询检测虚拟机所在物理机状态,若物理机管理网络连接状态、存储网络连接状态、业务网卡状态任一状态异常,根据设置的虚拟机故障迁移策略,虚拟机将从其他物理机上启动运行。
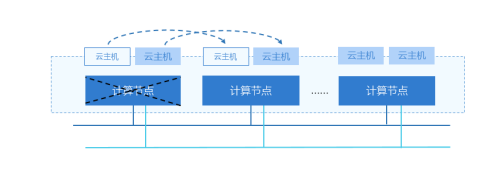
2)Fencer机制实现故障强制隔离
在高可用集群中,当一台主机被检测为发生故障时,尤其是当管理网络同时发生故障时,主机节点此时处于一个未知的状态,它有可能本身并未宕机,但是集群的其他部分认为该主机已故障,但该主机自身认为自己仍是健康的。
此时,它可能仍在运行其上的虚拟机,并尝试对共享存储进行读写。如果不对这台“被认定故障”的主机采取行动,就会导致灾难性后果:两台主机都认为自己对虚拟机有控制权,同时读写同一份共享存储上的虚拟磁盘文件,造成数据损坏。
为了解决这个致命问题,ZStack ZSphere在高可用集群中,引入了Fencer机制,来确保被宣告故障的主机上的虚拟机被强制隔离,使其无法再访问任何集群共享资源。
只有在确认故障主机上的虚拟机已经被正确隔离后,管理节点才会继续在健康节点上启动故障转移,恢复业务。
3)恢复执行与策略
高可用的恢复过程对虚拟机而言,这个过程类似于一次意外的断电重启。操作系统和应用程序会经历标准的启动过程。启动过程也会遵循平台对于虚拟机设置的调度策略规则,比如DRS规则,亲和组策略,重启优先级等。
三、基础设施金融级高可用
在基础设施层面,ZStack ZSphere构建了坚实的高可用基石,其核心在于消除单点故障,主要实现方式以网络高可用+存储高可用为主,确保为用户提供金融级高可用性和稳定性。
网络高可用:ZStack ZSphere通过网卡绑定技术,将物理服务器上的多个物理网卡聚合为一个逻辑网卡。这不仅提升了网络带宽,更核心的价值在于实现高可用与负载均衡。
当采用主动-备用(Active-Backup)模式时,只有主用网卡处理流量,备用网卡处于待命状态;一旦主用网卡或其连接的线路、交换机出现故障,备用网卡会在毫秒级内无缝接管,业务无感知。而对于需要更高吞吐量和冗余性的场景,则可以与物理交换机协作,启用基于IEEE 802.3ad标准的LACP(链路聚合控制协议) 模式。LACP模式能够将多条物理链路捆绑成一条逻辑链路,同时进行流量的负载分担,并动态维护链路状态。任何一条成员链路中断,其负载会被自动、快速地分发到剩余的健康链路上,从而实现了网络连接的高可用与高性能并存。
存储高可用:根据存储类型有所不同
对于分布式存储,其高可用性核心依赖于多副本机制。ZStack ZSphere在写入数据时,会将一份数据同步复制到集群内不同物理服务器上的多个存储节点(通常默认至少3副本)。这样,即使某个存储节点所在的整个服务器发生故障,数据依然可以从其他节点的副本上正常读取和写入,实现了数据层面的高可用,从根源上避免了单点故障导致的数据丢失。
对于集中式存储(如FC-SAN、IP-SAN),高可用则通过多路径技术来实现。服务器会配置多条物理上独立的HBA卡或网卡,分别连接到存储交换机的不同网络或直接连接到存储控制器。多路径软件会管理这些路径,当主路径上的任何组件(如HBA卡、光纤线、交换机端口)发生故障时,多路径软件会立即将I/O流量自动切换到可用的备用路径上,确保主机对存储的访问不会中断,为虚拟机提供持续、稳定的数据访问能力。
通过上述网络与存储的深度冗余设计,ZStack ZSphere在硬件层面构建了一个无单点瓶颈的坚固数据通道,为上层业务的高可用奠定了坚实基础。
结语
在基础架构高可用方面,ZStack ZSphere通过从基础设施管理、虚拟化平台自身到业务虚拟机的多层级、立体化高可用设计,构建了一个全方位、无单点的连续性保障体系。这套成熟的架构确保了企业关键业务能够实现不间断稳定运行,将故障带来的业务中断风险降至最低。
正是从架构设计就提供的稳健性与可靠性,使得ZStack能够实现100%核心场景对VMware替代。ZStack ZSphere不仅无缝承接并增强原有VMware环境的高可用能力,更以更优的总体拥有成本(TCO)和更开放的软硬件生态,为企业业务的平滑迁移与未来创新提供了坚实支撑。