零门槛部署:在AMD MI300X上极速部署运行GPT-OSS 120B全流程实践
任何刚接触大语言模型(LLM)技术的新用户,都必须面对的最大难题就是“算力”。从显存、吞吐量到底层技术和软件,不同机器之间的差异足以让人头晕目眩;部署 LLM 时,这种差异会更加明显。归根结底,我们想在低成本下拿到最高质量,而真正的挑战就在于如何找到那个平衡点。
今天,我们就拿 AMD Instinct MI300X GPU 运行 GPT-OSS 120B 来近距离剖析这个问题。这个怪兽级 GPU 处理器是 AMD 的旗舰之一,拥有 192 GB HBM3 显存,理论峰值 653.7 TFLOPs,带宽高达 5.3 TB/s。MI300X 的显存比 H100 要高,而且云服务器的价格比 H100 更低(参考 DigitalOcean 云平台的价格),是测试大模型的理想平台。我们选用近期因“代理能力”和“代码能力”而热评不断的 OpenAI GPT-OSS 120B 作为示例模型。
本教程将手把手教你用 vLLM 在 AMD GPU 上跑通 GPT-OSS 120B。读完你将彻底掌握 vLLM、GPT-OSS,以及在 Gradient AMD GPU 服务器 上的每一步部署细节。
什么是 vLLM
vLLM 是一个开源的高性能推理引擎,专为以卓越的速度和内存效率提供大型语言模型(LLM)服务而设计。通过优化 GPU 内存利用率,vLLM 比许多其他竞争方案提供更快的响应速度、更高的吞吐量和更低的延迟。其核心创新包括 PagedAttention 算法、对连续批处理的支持,以及与 Hugging Face 等主流模型生态系统的无缝兼容性。我们推荐使用 vLLM,正是基于这些优势特性。
为何选 GPT-OSS
GPT-OSS(20B 和 120B 版本)是 OpenAI 今年早些时候发布的旗舰级开源大语言模型(LLM)。这两个版本分别在其尺寸类别中成为目前最强大的智能体(agentic)和编程模型之一。值得注意的是,在发布时,GPT-OSS 120B 在标准推理基准测试中的表现可与 o4-Mini 模型相媲美;而 20B 版本在仅配备 16GB 虚拟内存的边缘设备上运行时,其表现也与 o3-Mini 模型相当。
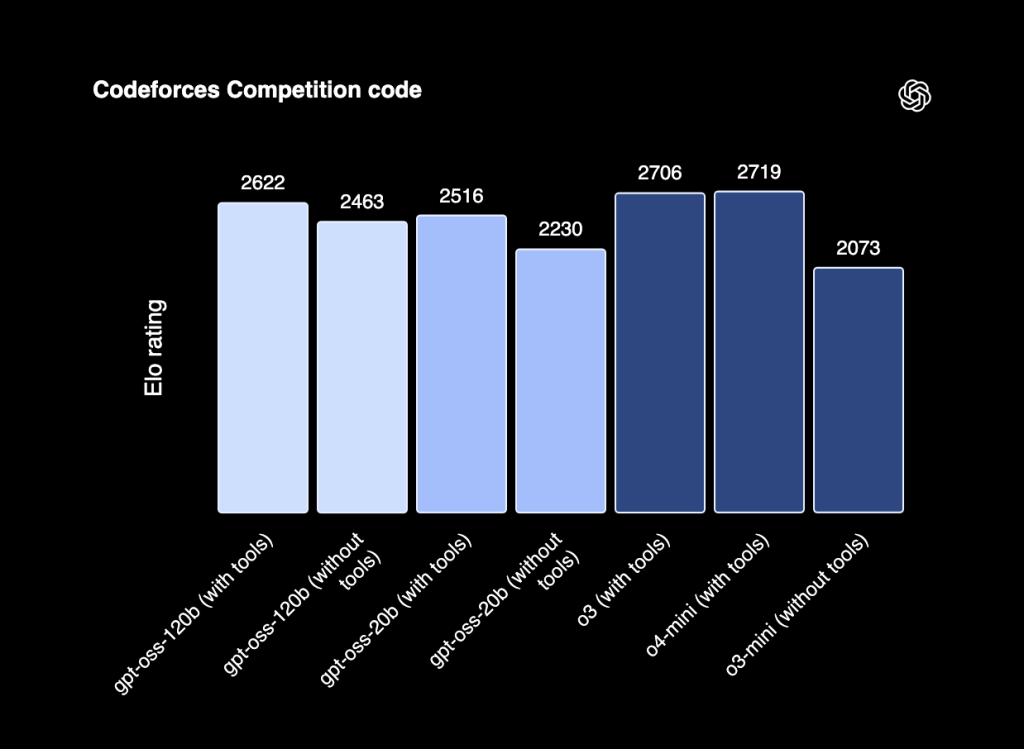
我们推荐使用 GPT-OSS 120B 的原因在于:其采用开源且宽松的 Apache 2.0 许可证,便于针对各类任务进行微调,并可在任何场景中自由使用;同时,它在推理和编程任务上达到了当前最先进的(SOTA)性能水平。如上图结果所示,该模型在 Codeforces 基准测试中,其推理能力与旗舰级 o3 和 o4-Mini 模型表现相当。基于这些优势,GPT-OSS 120B 是任何希望在 vLLM 上运行编程模型的用户的理想起点。
在 AMD MI300X GPU Droplet 上运行 vLLM
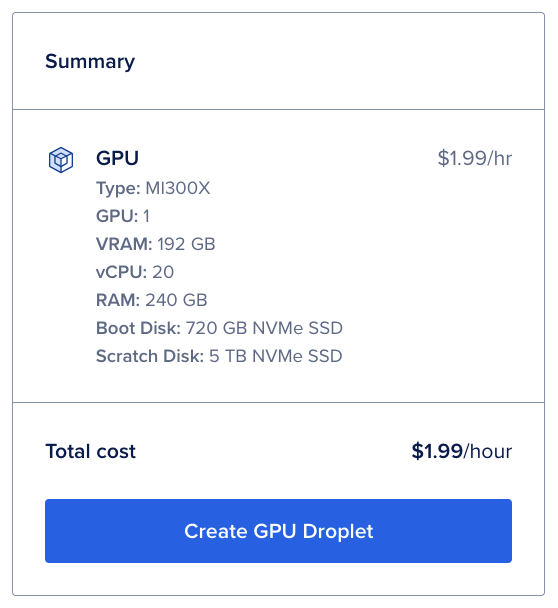
首先,我们将启动一台搭载 MI300X GPU 的 Droplet。登录你的 DigitalOcean 云平台账户(可访问 digitalocean.com 注册),点击左侧边栏中的“GPU Droplets”链接(注:Droplet 是 DigitalOcean 云服务器的产品名)。
进入创建界面后,选择 ATL (亚特兰大)数据中心——这是目前唯一提供 AMD GPU 的区域。向下滚动,在“GPU 平台”选项中选择“AMD”,然后选择单个 MI300X GPU。最后,从你团队可用的 SSH 密钥列表中选择一个密钥。
至此,你已准备好创建 Droplet!这里我们使用的 DigitalOcean 云平台的 AMD GPU Droplet 服务器是按需实例,每小时仅 1.99 美元
点击右上角的“创建 GPU Droplet”按钮以启动实例。GPU Droplet 的启动可能需要几分钟时间。
使用 Docker 设置 vLLM 运行环境
待 GPU Droplet 准备就绪后,使用本地终端通过 SSH 登录该机器。随后,导航至你希望工作的目录,即可开始使用 Docker 部署 vLLM。
在 vLLM 上部署 GPT-OSS
首先,我们将为部署设置一个快捷别名,用于下载并启动 Docker 容器。请将以下命令粘贴到终端中开始操作。该容器仅能在 MI300X GPU 上运行:
alias drun='sudo docker run -it --network=host --device=/dev/kfd --device=/dev/dri --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --shm-size 32G -v /data:/data -v $HOME:/myhome -w /myhome'drun rocm/vllm-dev:open-mi300-08052025
下载和启动过程可能需要一些时间。完成后,你将进入 Docker 容器内部。接下来,我们将在 AMD MI300X GPU Droplet 上部署 GPT-OSS 120b 模型。将以下命令粘贴至终端中启动服务:
export VLLM_ROCM_USE_AITER=1
export VLLM_USE_AITER_UNIFIED_ATTENTION=1
export VLLM_ROCM_USE_AITER_MHA=0vllm serve openai/gpt-oss-120b --compilation-config '{"full_cuda_graph": true}'
该命令将启动 vLLM 服务,首先下载模型文件至容器中。若一切运行正常,你将看到与上方截图一致的提示信息。之后,你即可通过 OpenAI 的 Python 库访问部署在 0.0.0.0:8000 或 localhost:8000 的模型。
与已部署的 GPT-OSS 120b 模型交互
接下来,我们需要了解如何与已部署的模型进行交互以真正使用它。我们在此介绍两种主要方法:使用 cURL 和 OpenAI 的 Python 库。
首先,我们来看 cURL 方法。打开一个新的终端窗口,SSH 登录到远程机器,然后粘贴以下代码。我们将用此示例向模型请求一个简单任务:讲一个笑话。
curl http://localhost:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "openai/gpt-oss-120b","messages": [{ "role": "system", "content": "You are a helpful assistant." },{ "role": "user", "content": "Tell me a joke." }],"temperature": 0.7,"max_tokens": 100}'
预期返回结果类似如下:
{"id": "[anonymized]","object": "chat.completion","created": 1762542942,"model": "openai/gpt-oss-120b","choices": [{"index": 0,"message": {"role": "assistant","content": "Sure, here's a classic one for you:\n\n**Why don’t scientists trust atoms?**\n\n*Because they make up everything!*","refusal": null,"annotations": null,"audio": null,"function_call": null,"tool_calls": [],"reasoning_content": null},"logprobs": null,"finish_reason": "stop","stop_reason": null}],"service_tier": null,"system_fingerprint": null,"usage": {"prompt_tokens": 85,"total_tokens": 134,"completion_tokens": 49,"prompt_tokens_details": null},"prompt_logprobs": null,"kv_transfer_params": null
}
通过此方法,你可以执行多种任务,例如代码补全、工具调用和复杂函数调用。你可以尝试使用你自己的提示词,体验该模型的强大能力!
若你更倾向于使用 Python 编程,我们推荐使用 OpenAI 的 Python 库。在运行 vLLM 服务的终端窗口之外,启动一个 Jupyter Lab 实例。在终端中粘贴以下命令以安装所需依赖:
python3 -m venv venv
source venv/bin/activate
pip install openai jupyter
jupyter lab --allow-root
使用 Cursor 或 VS Code 的内置浏览器功能,在本地浏览器中访问 Jupyter Lab(详细指引请参阅卓普云官网上的中文教程指南)。启动后,新建一个 Jupyter Notebook,在第一个代码单元格中粘贴以下 Python 代码:
from openai import OpenAI# 设置 OpenAI 的 API 密钥和 API 基地址以使用 vLLM 的 API 服务
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,
)chat_response = client.chat.completions.create(model="openai/gpt-oss-120b",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Tell me a joke."},]
)
print("Chat response:", chat_response)
若一切正常,你将看到类似以下的输出:
Chat response: ChatCompletion(id='chatcmpl-b600ce13dfd041a4a934ebe7826c8a44', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='Why don’t scientists trust atoms?\n\nBecause they **make up** everything!', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[], reasoning_content=None), stop_reason=None)], created=1762543674, model='openai/gpt-oss-120b', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=41, prompt_tokens=85, total_tokens=126, completion_tokens_details=None, prompt_tokens_details=None), prompt_logprobs=None, kv_transfer_params=None)
通过这种 Python 实现方式,你可以将 vLLM 集成到任意数量的应用程序和工作流中,包括自定义智能体。我们发现这种方法与 cURL 一样灵活实用,因为你可以充分利用 Python 生态系统中丰富的库和工具。
写在最后
得益于 vLLM 和 ROCm 社区的不懈努力,在 AMD MI300X GPU Droplet 上运行 GPT-OSS 非常简便。借助 GPU Droplet 的便捷性,用户只需数分钟即可在当前最先进的硬件上启动这一强大模型,真正实现开箱即用的高性能 AI 体验。
当然,你也可以尝试在 DigitalOcean 的 AMD MI325X GPU Droplet 服务器上跑 GPT OSS。如果你还需要了解 DigitalOcean 有哪些更优惠的 GPU 云服务器,可以直接咨询 DigitalOcean 中国区独家战略合作伙伴卓普云 aidroplet.com,卓普云负责为所有使用 DigitalOcean 云平的中国企业提供技术支持。