分布式专题——54 ElasticSearch集群架构生产最佳实践
1 节点角色配置方案
1.1 节点角色
-
在 7.9 版本之前,在配置节点时,只会涉及节点类型的知识:
-
主节点:负责集群管理(如分片分配、节点状态维护)和元数据维护,确保集群正常运行
-
数据节点:负责存储、检索和处理数据,提供搜索、聚合等核心数据操作功能
-
协调节点:处理客户端请求,协调数据节点工作,优化分布式搜索的执行流程
-
ingest 节点(数据预处理节点):负责数据预处理,如过滤、转换数据,处理后再将数据索引到数据节点
-
-
以 7.1 版本为例,若要配置“仅候选主节点”,需繁琐地声明“是主节点,且不是数据节点、不是 ingest 节点……”,配置如下:
node.master: true node.data: false node.ingest: false -
7.9 版本开始引入节点角色概念:
-
目的是让不同角色节点各司其职,简化配置并提升集群稳定性与性能;
-
配置逻辑从“声明不是什么”转变为“声明是什么”,例如同时承担“数据节点”和“候选主节点”角色,只需配置:
node.roles: [data, master]
-
-
以 8.X 版本为例,若不手动设置节点角色,默认节点角色为
cdhilmrstw。通过GET _cat/nodes?v接口可查看节点角色(如示例中node.role列显示cdhilmrstw);
-
以下是
cdhilmrstw各字母对应的节点角色缩写、英文释义与中文释义:节点角色缩写 英文释义 中文释义 c cold data node 冷数据节点 d data node 数据节点 f frozen data node 冷冻数据节点 h hot data node 热数据节点 i ingest node 数据预处理节点 l machine learning node 机器学习节点 m master-eligible node 候选主节点 r remote cluster client node 远程节点 s content data node 内容数据节点 t transform node 转换节点 w warm data node 温数据节点 / coordinating only node 仅协调节点 -
当集群节点数大于 6 个时,需手动设定、配置节点角色,以实现资源隔离、性能优化(避免单个节点承担过多角色导致负载过高)。
1.2 一个节点只承担一个角色的配置
-
开发环境 vs 生产环境的节点角色承担
-
开发环境:一个节点可承担多种角色(无需严格角色隔离,便于快速搭建测试);
-
生产环境:
- 需根据数据量、写入吞吐量、查询吞吐量选择部署方式;
- 建议设置单一角色的节点(通过角色分离实现资源优化、负载隔离,保障集群稳定性);
-
-
生产环境单角色节点的架构设计
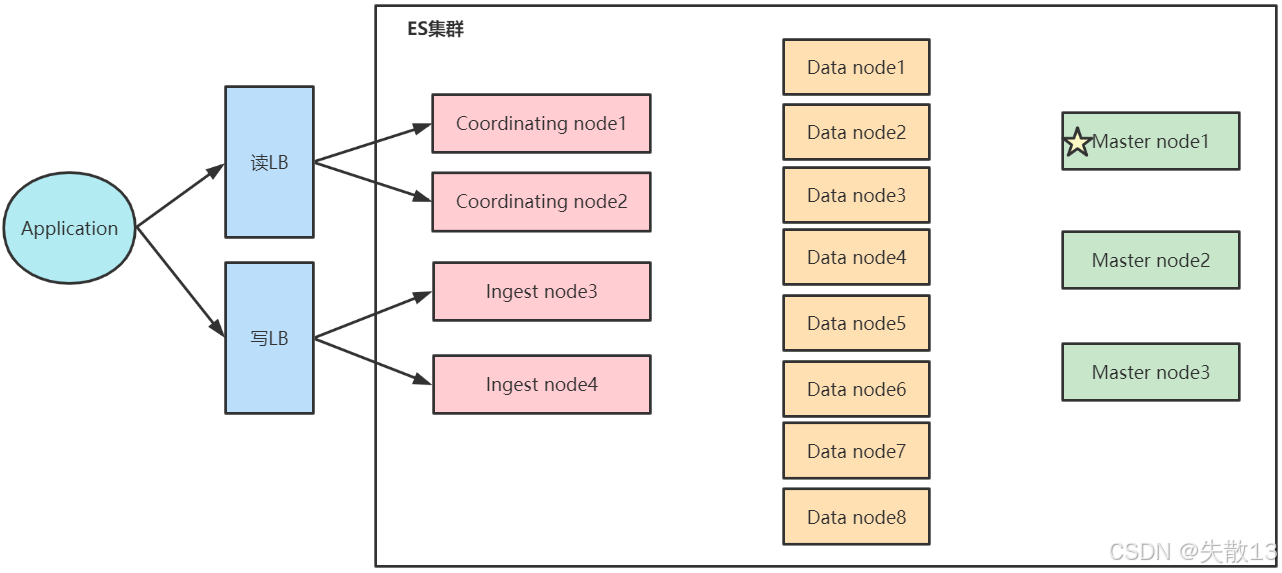
-
Application(应用层):发起读写请求;
-
读LB/写LB(负载均衡):分发读写请求,实现流量负载均衡;
-
ES集群内的单角色节点:
- Coordinating node(协调节点,共2个):仅承担协调节点角色,处理客户端请求的分发与结果聚合
- Ingest node(数据预处理节点,共2个):仅承担数据预处理角色,负责数据的过滤、转换等操作
- Data node(数据节点,共8个):仅承担数据节点角色,负责数据的存储、检索和处理
- Master node(主节点,共3个,其中Master node1为活跃主节点):仅承担候选主节点/主节点角色,负责集群管理(如分片分配、元数据维护)
-
-
单角色职责分离的好处:不同单角色节点因功能差异,在资源配置和优势上各有侧重
-
单一 master eligible nodes(候选主节点)
- 功能:负责集群状态(
cluster state)的管理 - 资源配置:使用低配置的CPU、RAM和磁盘(因主要处理集群元数据,对资源消耗较低)
- 功能:负责集群状态(
-
单一 data nodes(数据节点)
- 功能:负责数据存储及处理客户端数据类请求(如搜索、聚合)
- 资源配置:使用高配置的CPU、RAM和磁盘(需支撑大量数据的读写与计算,资源要求高)
-
单一 ingest nodes(数据预处理节点)
- 功能:负责数据预处理(如过滤、转换原始数据)
- 资源配置:使用高配置CPU、中等配置的RAM、低配置的磁盘(数据预处理对CPU计算要求高,对磁盘存储需求低)
-
单一 Coordinating Only Nodes(仅协调节点,也叫Client Node)
- 功能:仅承担协调节点角色,是客户端请求的“入口”,负责请求分发与结果聚合
- 资源配置:使用高配置CPU、高配置的RAM、低配置的磁盘(需处理大量请求的协调逻辑,对CPU和内存要求高)
- 生产建议:大集群建议配置此类节点,原因包括:
- 扮演“Load Balancers”,降低Master节点和Data Nodes的负载
- 负责搜索结果的
Gather/Reduce(即结果收集与聚合) - 隔离客户端不可预测的请求风险(如深度聚合操作可能引发内存溢出(OOM),仅协调节点可避免此类风险影响Master或Data节点)
-
1.3 增加节点的场景
-
场景一:磁盘容量无法满足需求时。数据节点负责存储数据,当现有数据节点的磁盘容量不足以容纳更多数据时,增加数据节点可以扩展集群的存储容量,从而满足数据存储的需求;
-
场景二:磁盘读写压力大时。数据节点承担数据的读写操作,当磁盘读写压力过高(如IO瓶颈),增加数据节点可以分散读写负载,提升数据读写的效率,缓解磁盘的压力;
-
场景三:系统中有大量的复杂查询及聚合时。协调节点(Coordinating 节点)负责处理客户端请求、协调数据节点工作以及聚合查询结果。当存在大量复杂查询和聚合操作时,增加协调节点可以提升查询请求的处理能力,优化分布式搜索的性能,从而提高查询的响应速度。
2 高可用场景部署方案
2.1 读写分离架构
2.2 Hot & Warm 架构
2.2.1 典型应用场景
-
在成本有限的前提下,Hot & Warm 架构可实现“客户关注的实时数据与历史数据硬件隔离”,从而最大化解决客户响应时间问题;
-
以具体业务场景为例:
-
业务痛点:每日增量 6TB 日志数据,高峰时段写入和查询频率极高,集群压力大,导致 ES 查询经常缓慢;
-
解决方案逻辑:
- ES 索引写入和查询速度依赖磁盘 IO 速度,因此将“热数据”(实时高频访问的日志)用 SSD 磁盘存储,提升查询效率;
- 若全部使用 SSD,成本过高且存放冷数据(历史归档日志)会造成资源浪费,因此采用 “普通 SATA 磁盘(HDD)+ SSD 磁盘”混搭,既保证热数据性能,又降低冷数据存储成本,最终实现“资源充分利用+性能大幅提升”的目标;
热数据(用户最关心的实时数据)→ Hot 节点(SSD 存储,高配置)
暖数据(用户关心优先级低的历史数据)→ Warm 节点(HDD 存储,低配置大容量)
冷数据(用户不太关心的归档数据)→ 可进一步扩展 Cold 节点(逻辑与 Warm 类似,侧重超大规模冷归档)
-
2.2.2 设计目的
-
ES 设计 Hot & Warm 架构主要基于以下原因:
-
ES 数据通常无 Update 操作,数据写入后以只读或历史归档为主,适合按“热度”分层存储
-
适用于基于时间(Time based)的索引数据且数据量较大的场景(如日志、时序数据等)
-
引入 Warm 节点后,可通过低配置、大容量的机器存放老数据,从而降低整体部署成本
-
-
Hot 节点和 Warm 节点在硬件配置、功能定位上有明显区分:
-
Hot 节点
- 硬件:通常使用 SSD 磁盘,需高配置机器(因索引写入对 CPU、IO 要求极高)
- 功能:负责新文档的持续写入(如实时日志、最新业务数据),承担高频的索引(Indexing)操作
-
Warm 节点
- 硬件:通常使用 HDD 磁盘(大容量、低成本),配置要求低于 Hot 节点
- 功能:负责保存只读的旧索引、较旧的数据,几乎无新数据写入,也不存在大量数据查询(仅承担历史数据归档和低频查询)
-
-
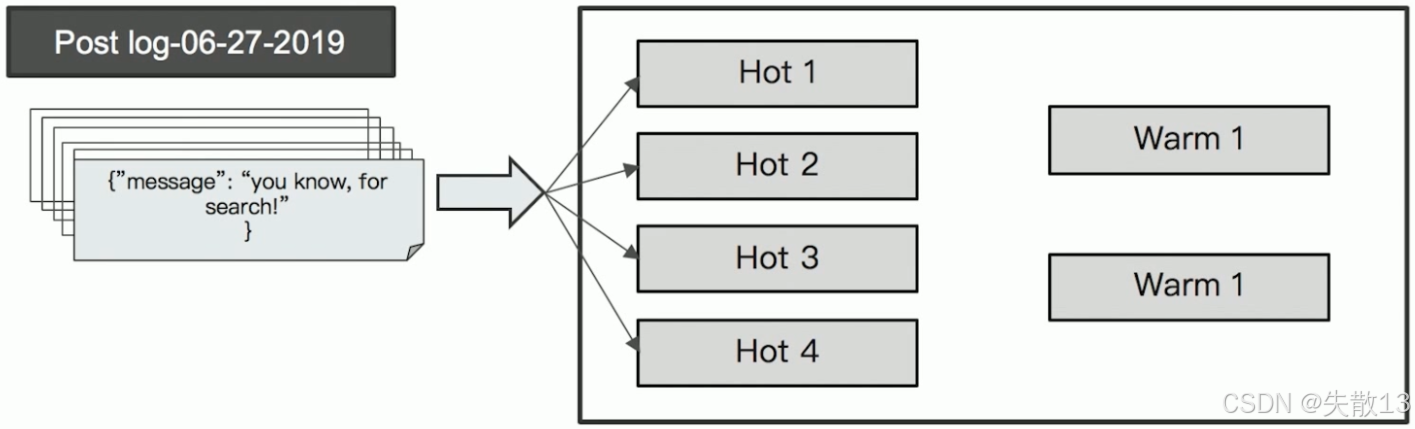
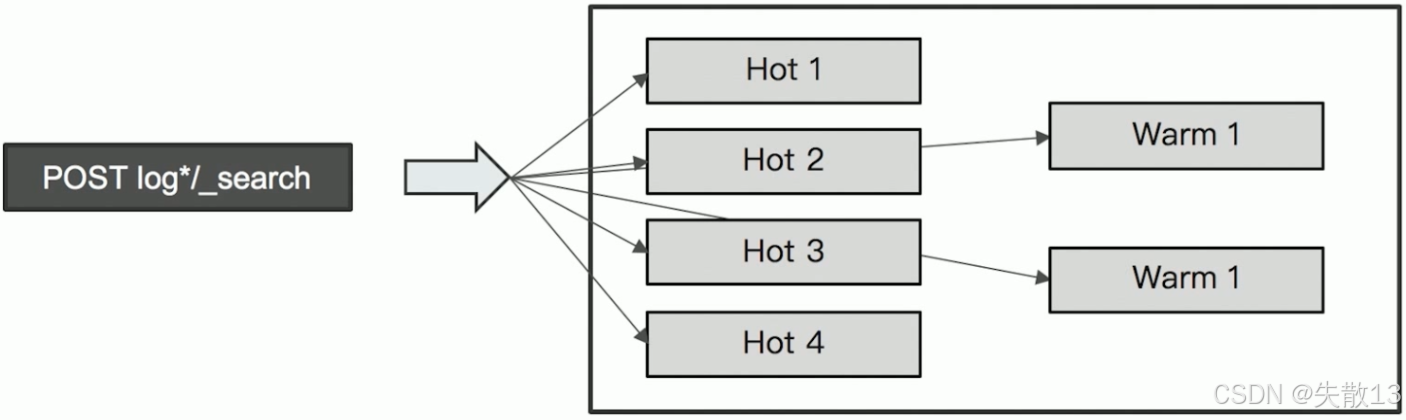
以日志数据为例,数据在 Hot & Warm 架构中的流转和处理逻辑如下:
-
Hot 节点阶段:新生成的日志(如
log-06-27-2019)首先写入 Hot 节点(图示中 Hot 1~4),利用 SSD 的高 IO 性能支撑实时索引写入需求; -
Warm 节点阶段:当日志数据变为“旧数据”后,会从 Hot 节点迁移到 Warm 节点(图示中 Warm 1~2),以大容量 HDD 存储,实现低成本归档。此时若有针对旧日志的查询(如
POST log/_search),会由 Warm 节点承担只读查询操作。
-
2.2.3 Hot & Warm 架构的配置
-
通过 Shard Filtering 实现 Hot&Warm 节点的数据迁移
-
Shard Filtering 是 Elasticsearch 中用于控制分片分配到指定节点的机制,其核心依赖“节点属性标记”和“索引分配规则”:
-
节点属性标记(
node.attr):通过自定义键值对(如my_node_type: hot或my_node_type: warm)标记节点的角色(Hot 或 Warm); -
索引分配规则(
index.routing.allocation):在索引的settings中配置规则,指定分片需分配到满足属性条件的节点。规则类型及含义如下:配置项 规则含义 index.routing.allocation.include.{attr}分片至少包含一个匹配的属性值 index.routing.allocation.exclude.{attr}分片不能包含任何匹配的属性值 index.routing.allocation.require.{attr}分片必须包含所有匹配的属性值
-
-
-
整个配置流程分为三步,即标记节点 → 配置热数据 → 迁移旧数据到 Warm 节点,每一步都有明确的操作和验证逻辑
-
标记节点(Tagging):通过
node.attr在配置文件(elasticsearch.yml)中标记节点的“热/温”角色,并验证标记结果;-
配置示例:
# 标记一个 Hot 节点 node.attr.my_node_type: hot# 标记一个 Warm 节点 node.attr.my_node_type: warm -
验证方式:通过 API
GET _cat/nodeattrs?v查看节点属性,可看到my_node_type对应的hot或warm标记(如下图中hotnode对应hot,warmnode对应warm);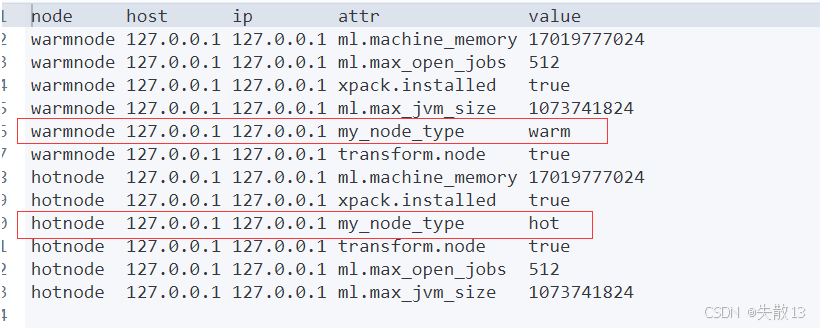
-
-
配置 Hot 数据(将新索引创建到 Hot 节点)
-
创建索引时,通过
index.routing.allocation.require强制分片分配到 Hot 节点; -
配置示例:
# 配置索引到 Hot 节点 PUT /index-2022-05 {"settings": {"number_of_shards": 2,"number_of_replicas": 0,"index.routing.allocation.require.my_node_type": "hot"} }# 写入文档 POST /index-2022-05/_doc {"create_time": "2022-05-27" } -
验证方式:通过 API
GET _cat/shards/index-2022-05?v查看分片分布,可看到分片被分配到hotnode上;
-
-
旧数据迁移到 Warm 节点
-
利用 Elasticsearch 的**动态设置(dynamic setting)**特性,后期修改索引的分配规则,将旧数据从 Hot 节点迁移到 Warm 节点;
-
配置示例:
# 修改索引设置,强制分片分配到 Warm 节点 PUT /index-2022-05/_settings {"index.routing.allocation.require.my_node_type": "warm" } -
验证方式:再次通过
GET _cat/shards/index-2022-05?v查看分片分布,可看到分片已迁移到warmnode上;
-
-
3 ES跨集群搜索(CCS)
3.1 ES单集群水平扩展存在的问题
-
单集群在水平扩展时,节点数不能无限增加,核心原因是:当集群的元数据(meta信息,包括节点、索引、集群状态等)过多时,更新压力会急剧增大。此时,集群中唯一的Active Master节点会成为性能瓶颈,进而导致整个集群无法正常工作;
-
早期版本中,ES通过Tribe Node实现多集群访问需求,但存在以下缺陷:
-
集群交互效率低:Tribe Node以Client Node的方式加入每个集群,集群中Master节点的任务变更需要Tribe Node回应后才能继续,增加了交互延迟
-
启动初始化慢:Tribe Node不保存Cluster State(集群状态)信息,一旦重启,需要重新获取各集群状态,初始化过程很慢
-
索引重名冲突:当多个集群存在索引重名的情况时,只能设置一种Prefer规则(优先选择某一集群的索引),无法灵活处理多集群索引重名场景
-
3.2 实战
-
Elasticsearch 5.3 引入了跨集群搜索功能(Cross Cluster Search),其设计优势在于:
-
允许任意节点扮演协调节点,以轻量方式代理搜索请求;
-
无需以 Client Node 的形式加入其他集群,解决了早期 Tribe Node 的诸多缺陷(如初始化慢、索引重名冲突等);
-
-
启动多集群(以3个集群为例)。通过命令行启动3个单节点集群,分别指定集群名、数据路径、端口等:
# 启动 cluster0 elasticsearch.bat -E node.name=cluster0node -E cluster.name=cluster0 -E path.data=cluster0_data -E discovery.type=single-node -E http.port=9200 -E transport.port=9300# 启动 cluster1 elasticsearch.bat -E node.name=cluster1node -E cluster.name=cluster1 -E path.data=cluster1_data -E discovery.type=single-node -E http.port=9201 -E transport.port=9301# 启动 cluster2 elasticsearch.bat -E node.name=cluster2node -E cluster.name=cluster2 -E path.data=cluster2_data -E discovery.type=single-node -E http.port=9202 -E transport.port=9302 -
动态配置远程集群(通过
_cluster/settingsAPI)。在任意集群上执行动态设置,指定要连接的远程集群信息:PUT _cluster/settings {"persistent": {"cluster": {"remote": {"cluster0": {"seeds": ["127.0.0.1:9300"],"transport.ping_schedule": "30s"},"cluster1": {"seeds": ["127.0.0.1:9301"],"transport.compress": true,"skip_unavailable": true},"cluster2": {"seeds": ["127.0.0.1:9302"]}}}} }-
seeds:配置远程集群的一个节点(用于建立连接) -
connected:若至少有一个到远程集群的连接,则为true -
num_nodes_connected:远程集群中已连接的节点数量 -
max_connections_per_cluster:远程集群的最大连接数 -
transport.ping_schedule:设置 TCP 层面的活性监听周期 -
skip_unavailable:设为true时,远程集群不可用时会被忽略;默认false,不可用时会报错 -
cluster.remote.connections_per_cluster:gateway 节点数量,默认 3 -
cluster.remote.initial_connect_timeout:节点启动时等待远程节点的超时时间,默认 30s -
cluster.remote.node.attr:节点属性过滤,用于筛选远程集群中符合条件的 gateway 节点(如node.attr.gateway: true) -
cluster.remote.connect:默认集群中任意节点可作为 federated client 连接远程集群;可设为false禁止部分节点连接 -
动态设置时需每次带上
seeds,确保连接稳定
-
-
在不同集群创建测试数据。分别在3个集群的
users索引中写入文档:# cluster0(localhost:9200) POST /users/_doc {"name": "shisan","age": "30" }# cluster1(localhost:9201) POST /users/_doc {"name": "monkey","age": "33" }# cluster2(localhost:9202) POST /users/_doc {"name": "mark","age": "35" } -
跨集群查询。通过指定“本地索引+远程集群:索引”的格式,执行跨集群联合查询:
GET /users,cluster1:users,cluster2:users/_search {"query": {"range": {"age": {"gte": 30,"lte": 40}}} } -
该查询会从本地
users索引、cluster1的users索引、cluster2的users索引中,联合检索age在 30~40 之间的文档,实现跨集群数据的统一查询。
4 Elasticsearch 集群容量规划
4.1 概述
-
容量规划的前提逻辑:规划时需保持资源余量,确保负载波动、节点丢失时集群仍能正常运行。核心要回答两个问题:
- “集群需要多少节点?”
- “索引需要多少分片?”
-
做容量规划时,需综合以下维度:
-
机器的软硬件配置(CPU、内存、磁盘类型等)
-
数据特征:单条文档大小、文档总数量、索引总数据量(结合时间维度的数据保留策略)、副本/分片数
-
写入模式:文档是批量写入(Bulk 大小)还是单条写入
-
读写复杂度:文档的查询、聚合操作的复杂程度
-
-
在规划前需先评估业务的性能需求,分为两类:
-
数据吞吐及性能需求
- 数据写入吞吐量:每秒需写入多少数据?
- 查询吞吐量:每秒需处理多少查询?
- 单条查询最大可接受返回时间
-
数据认知
- 数据格式与 Mapping 设计(字段类型、索引策略等)
- 实际查询、聚合的具体逻辑(如是否有深度聚合、跨字段查询等)
-
-
不同业务场景的容量规划逻辑不同:
-
搜索类:数据集大小固定或增长缓慢(如商品搜索、内容检索)
-
日志类:基于时间序列的连续写入(如系统日志、监控数据),增长速度快;通常结合 Warm Node 做数据老化处理(历史数据归档到低成本存储)
-
-
硬件选择需结合业务场景,核心规则如下:
-
磁盘类型:
- 数据节点尽可能用 SSD(搜索等性能要求高的场景必选);日志类且查询并发低的场景,可考虑机械硬盘
- 内存&硬盘比例:搜索类建议 1:10~20;日志类建议 1:50
-
单节点数据量:单节点数据建议控制在 2TB 以内,最大不超过 5TB
-
JVM 配置:JVM 内存设为机器内存的一半,且不超过 32G
-
节点部署:不建议在一台服务器上运行多个节点(避免资源竞争)
-
-
内存大小需根据节点存储的数据量估算,不同业务场景比例不同:
-
搜索类:建议比例 1:16(如节点内存 32G,可存储 32G×16=512G32G \times 16 = 512G32G×16=512G 数据,预留空间后实际约 400G)
-
日志类:建议比例 1:48~1:96(如节点内存 32G,可存储 32G×50=1.6TB32G \times 50 = 1.6TB32G×50=1.6TB 数据)
-
副本影响:总数据量需考虑副本,如 1T 原始数据+1 个副本,总数据量为 2T
-
-
根据业务需求选择部署策略:
-
若需高可靠、高可用,建议部署 3 台单一 Master 节点(避免 Master 单点故障)
-
若有复杂查询、聚合操作,建议设置专门的 Coordinating 节点(分担协调节点压力)
-
-
当集群资源不足时,按需扩容:
-
增加 Coordinating 节点/Ingest 节点:解决 CPU、内存开销问题(如复杂查询、数据预处理压力大时)
-
增加 数据节点:解决存储容量问题;需提前监控磁盘空间,避免分片分布不均,及时清理数据或新增节点
-
4.2 容量规划案例1:固定大小的数据集
-
以“产品信息库搜索”为例;
-
场景特性
-
被搜索的数据集很大但增长缓慢(无大量写入),核心关注搜索和聚合的读取性能
-
数据重要性与时间无关,关注搜索相关度
-
-
估算索引的数据量,然后确定分片的大小:
-
单个分片的数据量不超过20GB(避免分片过大导致查询性能下降)
-
可通过增加副本分片提高查询吞吐量(副本越多,读性能越强,但写性能和存储成本会增加)
-
-
索引优化手段(解决“单个索引数据量超大”的查询性能问题)——拆分索引
-
按枚举字段Filter拆分:若业务查询大量基于某一“数量有限的枚举字段”(如订单地区),可按该字段拆分索引(如按地区分索引);
-
大索引拆分为多个小索引:
- 优势:查询性能显著提升(小索引查询更高效);
- 兼容性:多索引查询可通过“查询中指定多个索引”实现,不影响业务逻辑;
-
按动态Filter字段启用Routing功能:若Filter字段值不固定,可通过自定义
_routing字段控制文档分片路由,公式为shard_num = hash(_routing) % num_primary_shards(_routing默认是_id,可自定义)。示例:# 创建带2个主分片的users索引 PUT /users {"settings": {"number_of_shards": 2} }# 写入文档时指定routing(如按用户分组路由) POST /users/_create/1?routing=shisan {"name":"shisan" }
-
4.3 容量规划案例2:基于时间序列的数据
-
以“日志/指标/舆情分析”为例;
-
场景特性
-
每条数据带时间戳,文档基本不更新(日志、指标类数据特性)
-
用户更关注近期数据查询,对旧数据查询较少
-
对数据写入性能要求高(需支撑持续的时序数据写入)
-
-
索引规划策略:创建时间序列索引
-
按时间维度拆分索引(Timed-base索引)
-
索引命名包含时间信息(如按天、周、月划分),例如
logs-2022-05-27 -
优势:
- 便于数据老化处理(结合Hot & Warm架构,旧索引迁移到低成本存储)
- 备份、删除效率高(直接删除旧时间索引即可)
-
-
基于Date Math动态创建索引;
-
通过Elasticsearch的Date Math语法,自动生成带时间信息的索引名,示例:
Date Math 语法 生成的索引名 <indexName-{now/d}>indexName-2022.05.27<indexName-{now/YYYY.MM}>indexName-2022.05 -
操作示例:
# 创建当天的日志索引(编码后URL格式) PUT /%3Clogs-%7Bnow%2Fd%7D%3E# 搜索当天的日志索引 POST /%3Clogs-%7Bnow%2Fd%7D%3E/_search
-
-
基于Index Alias管理最新数据。通过索引别名(Alias)统一管理“最新时间分片的索引”,避免业务端感知索引名变化,示例:
# 创建两天的时间索引 PUT /logs_2022-05-27 PUT /logs_2022-05-26# 每天定时更新别名:将别名logs_write指向最新索引,移除旧索引关联 POST /_aliases {"actions": [{"add": {"index": "logs_2022-05-27","alias": "logs_write"}},{"remove": {"index": "logs_2022-05-26","alias": "logs_write"}}] }# 通过别名查询最新日志数据 GET /logs_write
-
5 Elasticsearch 分片设计与管理
5.1 概述
-
单个分片的特性。从 Elasticsearch 7.0 开始,新创建索引时默认只有一个主分片
- 优势:可避免“查询算分不准、聚合结果不准”的问题;
- 劣势:单个索引仅一个分片时,集群无法实现水平扩展(即使新增节点,数据也无法分散到新节点,性能瓶颈无法突破);
-
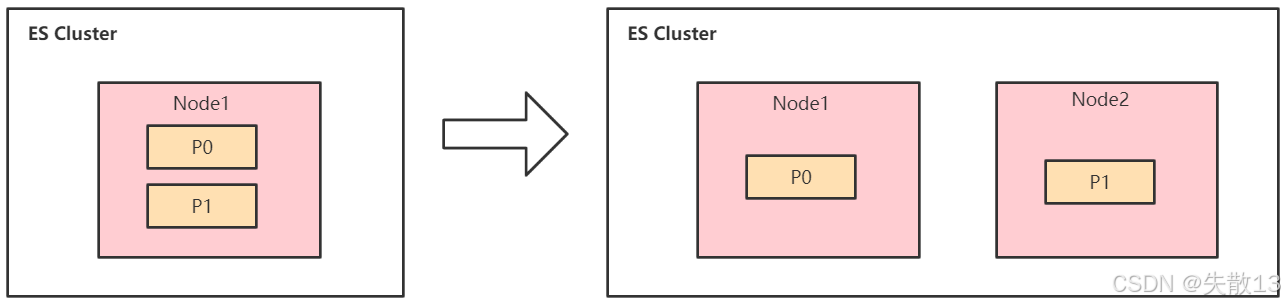
两个分片的特性(Shard Rebalancing);
-
当集群新增一个节点后,Elasticsearch 会自动进行分片移动(Shard Rebalancing);
-
示例:初始集群只有 Node1,包含两个分片(P0、P1);新增 Node2 后,P1 分片会自动迁移到 Node2,实现分片在节点间的负载均衡;
-
-
如何设计分片数。当“分片数 > 节点数”时
-
优势1:新数据节点加入集群后,分片可自动分配,且重新分配过程中系统无 downtime(服务不中断);
-
优势2:多分片的查询和写入可并行执行
- 查询:多个分片分布在不同节点,查询可并行执行,提升响应速度;
- 写入:数据可分散到多个机器,降低单节点写入压力;
-
-
分片设计案例
-
案例1:按时间与数据量规划
-
场景:每天产生 1GB 数据,索引设 1 个主分片 + 1 个副本分片,需保留半年数据;
-
计算:半年约 360 天,总数据量约 1GB×360=360GB1GB \times 360 = 360GB1GB×360=360GB,对应需 360 个分片(主+副本);
-
-
案例2:日志类多索引分片规划
-
场景:5 种不同日志,每天创建一个日志索引,每个索引设 10 个主分片,保留半年数据;
-
计算:半年约 30×6=180 天,总分片数为 5(日志类型)×10(主分片/索引)×180(天)=90005 \text{(日志类型)} \times 10 \text{(主分片/索引)} \times 180 \text{(天)} = 90005(日志类型)×10(主分片/索引)×180(天)=9000 个;
-
-
-
分片过多的副作用。分片是 Elasticsearch 水平扩展的最小单位,但过多分片会带来性能开销:
-
资源消耗:每个分片是一个 Lucene 索引,会占用机器的文件描述符、RAM、CPU 等资源,过多分片会导致额外性能开销
-
查询开销:每次搜索请求需从所有相关分片获取数据,分片过多会增加查询协调的成本
-
Master 负担:分片的元数据(Meta 信息)由 Master 节点维护,过多分片会加重 Master 管理负担。经验值:建议控制分片总数在 10 万以内
-
5.2 如何确定主分片数
-
从存储物理角度划分不同业务场景的单分片大小限制:
-
搜索类应用:单个分片不要超过 20 GB
-
日志类应用:单个分片不要大于 50 GB
-
-
控制分片存储大小的原因:
-
提高 Update 操作性能
-
减少 Merge 操作时的资源消耗
-
节点丢失后,具备更快的恢复速度
-
便于分片在集群内 Rebalancing(负载均衡)
-
5.3 如何确定副本分片数
-
副本是主分片的拷贝,核心作用:
-
提高系统可用性:可响应查询请求,防止数据丢失
-
资源消耗:需要占用与主分片一样的资源(存储、CPU、内存等)
-
-
对性能的影响
-
索引速度:副本会降低数据索引速度(有几份副本,CPU 资源消耗就会增加几倍)
-
查询性能:会减缓主分片的查询压力,但消耗同样的内存资源;若机器资源充足,提高副本数可提升整体查询 QPS
-
-
ES 分片策略会尽量保证节点分片数均匀,但以下场景会导致分配不均:
-
扩容新节点无数据,新索引集中在新节点
-
热点数据过于集中,引发性能问题
-
-
解决方式:通过配置限制每个节点的分片数,有两种级别:
index.routing.allocation.total_shards_per_node(索引级别):表示某个索引在每个节点上允许存在的分片数,默认 -1(无限制)cluster.routing.allocation.total_shards_per_node(集群级别):表示集群内每个节点允许存在的分片数,默认 -1(无限制)
注意:索引级别的配置会覆盖集群级别的配置;若目标节点的分片数超过配置上限,分片将无法分配到该节点
-
实战思考示例:5 个节点的集群,索引有 5 个主分片 + 1 个副本,
index.routing.allocation.total_shards_per_node如何设置?-
计算:(5+5)/5=2(5 + 5) / 5 = 2(5+5)/5=2(主分片+副本分片总数 ÷ 节点数);
-
生产建议:适当调大该数值,避免节点下线时分片无法正常迁移。
-