分布式专题——55 ElasticSearch性能调优最佳实践
1 ES底层读写工作原理分析
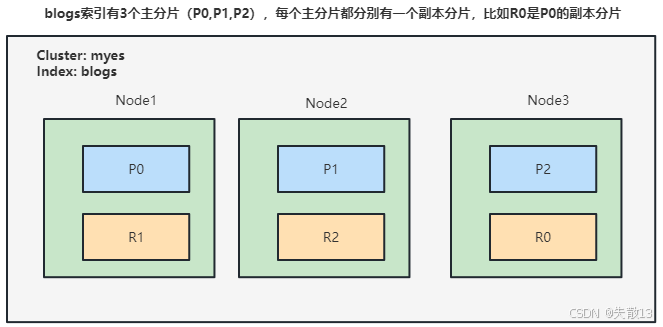
1.1 分片路由
-
Elasticsearch(ES)不是通过随机或轮询的方式选择存储节点,而是通过计算公式确定文档所属的分片(进而确定存储节点),公式为:
textshard_num = hash(_routing) % num_primary_shards;-
_routing:路由字段,默认取值为文档的_id字段,也可以由用户自定义; -
num_primary_shards:索引的主分片数量(如下图中blogs索引的主分片数为3,即P0、P1、P2); -
逻辑:对
_routing做哈希运算后,取模主分片数量,得到的结果就是文档要存储的主分片编号,进而确定对应的存储节点;
-
-
**为什么主分片创建后不能修改?**如果修改了主分片数量
num_primary_shards,会导致上述路由公式的计算结果完全失效——原本基于旧分片数计算出的“分片-文档”映射关系被破坏,ES将无法找到文档的存储位置。因此,索引的主分片数量在创建后不允许修改; -
读写请求的处理逻辑
-
写请求:必须先写入主分片(primary shard),再由主分片同步到所有副本分片(replica shard,如图中
R0、R1、R2); -
读请求:可以从主分片(primary shard)或副本分片(replica shard)中读取,ES采用随机轮询算法在可用的主分片和副本分片中选择读取源,以实现负载均衡。
-
1.2 ES写入数据的过程
-
选择协调节点:客户端选择一个ES节点发送写入请求,该节点成为coordinating node(协调节点)
-
路由与转发请求:协调节点对要写入的
document进行路由(通过hash(_routing) % num_primary_shards公式确定目标主分片),并将请求转发给对应主分片所在的节点 -
主分片处理并同步副本:目标节点上的primary shard(主分片)处理写入请求,然后将数据同步到对应的replica node(副本分片所在节点)
-
确认并返回结果:协调节点确认
primary shard和所有replica shard都完成写入后,向客户端返回请求结果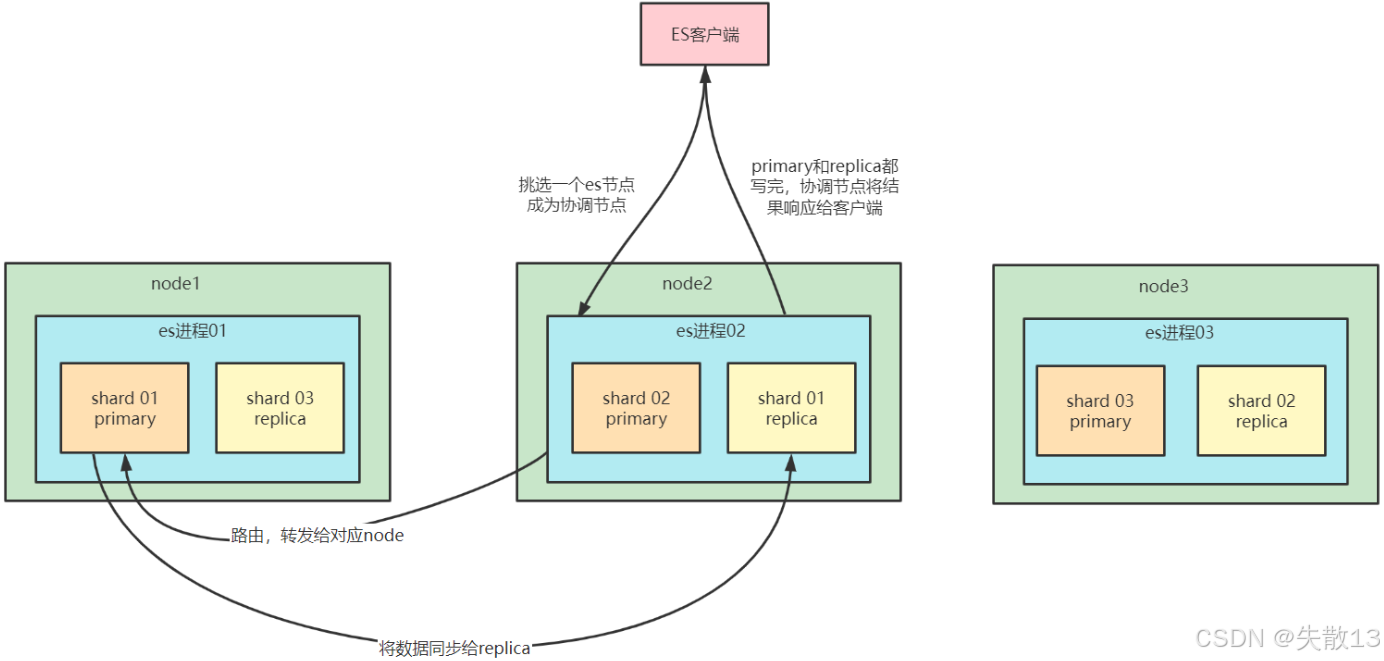
1.3 ES读取数据的过程
-
根据doc id查询数据的过程
-
选择协调节点:客户端发送请求到任意一个ES节点,该节点成为
coordinate node(协调节点) -
路由与负载均衡转发:协调节点对
doc id进行哈希路由(hash(_id) % shards_size),确定目标分片后,采用round-robin随机轮询算法,在primary shard及其所有replica shard中随机选择一个,将请求转发过去(实现读请求的负载均衡) -
返回文档给协调节点:接收请求的分片所在节点返回
document给协调节点 -
返回结果给客户端:协调节点将
document返回给客户端
-
-
根据关键词查询数据的过程(全文检索场景)
-
选择协调节点:客户端发送请求到一个
coordinate node(协调节点) -
转发搜索请求到所有分片:协调节点将搜索请求转发到所有相关分片对应的
primary shard或replica shard(任意其一即可) -
query phase(查询阶段):每个分片执行本地搜索,将自己的搜索结果返回给协调节点;协调节点对这些结果进行合并、排序、分页等操作,产出初步的搜索结果(如匹配的
doc id列表) -
fetch phase(获取阶段):协调节点根据初步结果中的
doc id,去各个节点上拉取实际的document数据,最终返回给客户端
-
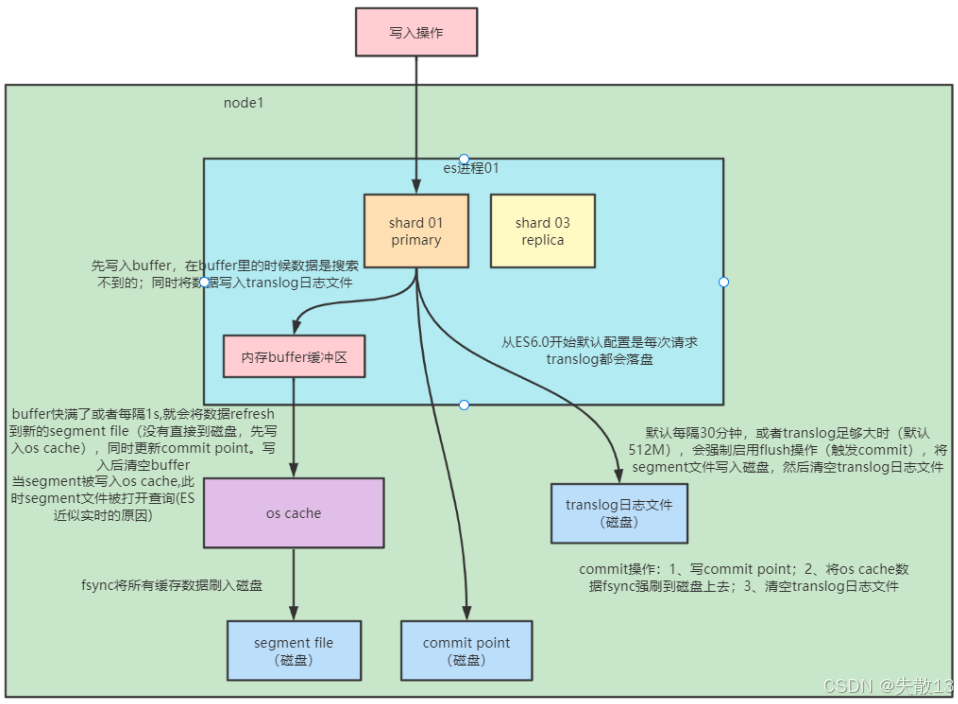
1.4 写数据底层原理
-
核心概念
-
segment file:存储倒排索引的文件,每个
segment本质是一个倒排索引。ES每秒生成一个segment文件;当文件过多或过大时,会自动执行segment merge(合并文件),合并时会物理删除已标注删除的文档; -
commit point:记录当前所有可用的
segment,每个commit point维护一个.del文件。ES删除数据时,先在.del文件中声明文档已删除;查询时,会根据commit point的.del文件过滤掉已删除的文档(逻辑删除,而非物理删除); -
translog日志文件:为防止ES宕机导致数据丢失,每次写入数据时会同时写入
translog日志(保障数据可靠存储)。从ES6.0开始,默认每次请求都会将translog落盘; -
os cache:操作系统缓存,数据写入磁盘前会先进入
os cache(内存级缓存),这是ES实现“近实时查询”的关键之一;
-
-
写入流程
-
写入buffer与translog:写入操作先将数据写入内存buffer缓冲区(此时数据不可搜索),同时将操作写入
translog日志文件(磁盘存储,保障可靠性); -
Refresh操作:生成segment并进入os cache:当
buffer满了或每隔1秒(由refresh_interval控制),会触发Refresh操作- 将
buffer中的数据生成新的segment文件,并写入os cache(此时segment在文件系统缓存中,可开放查询,这是ES“近实时查询”的原因); - 同时更新
commit point(但未持久化到磁盘),之后清空buffer;
- 将
-
Flush操作:持久化到磁盘:默认每隔30分钟,或当
translog足够大时(默认512M),触发Flush操作(提交commit)- 执行
fsync,将os cache中的segment file和commit point强制刷入磁盘; - 清空
translog日志文件,完成一次持久化流程;
- 执行
-
-
关键操作说明
-
Refresh:
- 流程:将
index buffer中的数据生成segment,放入os cache并开放查询,清空buffer; - 作用:提升搜索实时性,让新写入的数据能被查询到;
- 流程:将
-
Translog:即便
segment未写入磁盘,宕机重启后也能通过translog恢复数据(ES6.0后默认每次请求落盘,可靠性更高); -
Flush:
- 流程:删除旧
translog、生成并写入segment到磁盘、更新并写入commit point到磁盘; - 作用:完成数据的持久化,保障数据最终一致性。
- 流程:删除旧
-
2 提升集群读写性能的方法
2.1 数据建模优化
-
尽量将数据先行计算后存储,避免查询时使用
Script计算(如示例中查询时的脚本逻辑会增加开销)#避免查询时脚本 GET blogs/_search {"query": {"bool": {"must": [{"match": {"title": "elasticsearch"}}],"filter": {"script": {"script": {"source": "doc['title.keyword'].value.length()>5"}}}}} } -
尽量使用
Filter Context:利用缓存机制减少不必要的算分,提升查询效率 -
结合
profile、explainAPI分析慢查询,持续优化数据模型 -
避免使用
*开头的通配符查询(如示例中的wildcard查询“*白云+”,这类查询性能差)GET /es_db/_search {"query": {"wildcard": {"address": {"value": "*白云*"}}} }
2.2 优化分片
-
避免Over Sharing:分片过多会导致查询时需要访问每个分片,增加不必要的开销
-
控制单个分片大小:结合场景控制,如Search场景建议单个分片20GB,Logging场景建议50GB
-
Force-merge只读索引:对于基于时间序列的只读索引,执行
force merge减少segment数量,提升查询效率(示例中通过POST /my_index/_forcemerge手动触发)# 手动force merge POST /my_index/_forcemerge
2.3 提升写入性能的方法
-
写入性能优化目标:增大写入吞吐量,尽可能提升写入效率
-
客户端优化:
- 多线程、批量写:通过性能测试确定最佳文档数量
- 多线程需观察是否有HTTP 429(Too Many Requests)返回,实现重试和线程数自动调节
-
服务器端优化:先分解单个节点的性能问题,结合测试压榨硬件资源(如观察CPU、I/O阻塞、线程切换、堆栈状况,使用更好的硬件)
2.4 服务器端优化写入性能的手段
-
降低I/O操作
-
使用ES自动生成的文档ID(减少路由计算开销)
-
调整相关配置(如
Refresh Interval)
-
-
降低CPU和存储开销
-
减少不必要的分词:避免对无需分词的字段执行分词操作
-
避免不需要的
doc_values:减少内存和存储消耗 -
保证文档字段顺序一致:提升文档压缩率,减少存储占用
-
-
写入和分片的均衡负载:实现水平扩展,如使用
Shard Filtering、Write Load Balancer -
调整Bulk线程池和队列
-
客户端:
- 单个
bulk请求体数据量建议5-15m; - 写入端
bulk请求超时建议设置60s以上; - 尽量将数据轮询打到不同节点;
- 单个
-
服务器端:
- 索引创建是计算密集型任务,线程池配置为“CPU核心数+1”避免上下文切换;
- 队列大小适当增加但不要过大(避免内存成为GC负担);
-
ES线程池设置:Elasticsearch线程池调优指南-CSDN博客;
-
-
注意:ES 的默认设置,已经综合考虑了数据可靠性,搜索的实时性,写入速度,一般不要盲目修改。一切优化,都要基于高质量的数据建模。
2.5 建模时的优化
-
只需聚合不需要搜索的字段,将
index设置为false(减少索引开销) -
不要对字符串使用默认的
dynamic mapping:避免字段数量过多影响性能 -
通过
index_options控制倒排索引的内容,减少索引存储和查询开销 -
极致写入速度的权衡(牺牲可靠性/实时性)
-
牺牲可靠性:写入时将副本分片设为0,完成后再调整回去
-
牺牲搜索实时性:增加
Refresh Interval的时间(减少segment生成频率) -
牺牲可靠性:修改
Translog配置(如异步落盘)
-
2.6 关键配置调整
-
降低Refresh的频率
-
增加
refresh_interval的数值(默认1s,设置为-1可禁止自动refresh):避免频繁生成segment文件,但会降低搜索实时性(示例中通过PUT /my_index/_settings将refresh_interval设为10s)PUT /my_index/_settings {"index" : {"refresh_interval" : "10s"} } -
增大静态配置参数
indices.memory.index_buffer_size(默认10%,避免因内存触发自动refresh)
-
-
降低Translog写磁盘的频率(牺牲容灾能力)
-
index.translog.durability:默认request(每个请求落盘),可设置为async(异步写入) -
index.translog.sync_interval:设置为60s(每分钟执行一次同步) -
index.translog.flush_threshold_size:默认512m,可适当调大,超过该值触发flush
-
-
分片设定
-
副本在写入时设为0,完成后再增加(减少写入时的副本同步开销)
-
合理设置主分片数,确保均匀分配在所有数据节点上
-
通过
index.routing.allocation.total_shards_per_node限定每个索引在每个节点上的主分片数(避免数据热点)
-
2.7 例
DELETE myindex
PUT myindex
{"settings": {"index": {"refresh_interval": "30s", // 30s一次refresh"number_of_shards": "2"},"routing": {"allocation": {"total_shards_per_node": "3" // 控制分片,避免数据热点}},"translog": {"sync_interval": "30s","durability": "async" // 降低translog落盘频率},"number_of_replicas": 0},"mappings": {"dynamic": false, // 避免不必要的字段索引,必要时可以通过update by query索引必要的字段"properties": {}}
}
-
settings.index模块refresh_interval": "30s":控制ES的Refresh操作频率,默认是1秒生成一次segment并放入os cache供查询。这里设置为30秒一次,减少了segment的生成频率,降低了CPU和I/O开销,提升写入性能;但会牺牲部分搜索实时性(新写入数据需等30秒后才能被查询到);
-
number_of_shards": "2":设置索引的主分片数量为2。主分片数决定了数据的分片分布,需结合数据量和节点数合理设置,这里选择2个主分片是为了在“数据拆分粒度”和“查询开销”之间做平衡(分片过多会增加查询时的分片聚合开销); -
settings.routing.allocation模块total_shards_per_node": "3":限制每个节点上该索引可分配的主分片+副本分片总数为3。通过这种方式避免单个节点被该索引的分片过度占用,防止数据热点,保障集群资源的均衡分配;
-
settings.translog模块sync_interval": "30s":translog(事务日志)的同步间隔,默认是实时同步。设置为30秒后,translog每30秒才会同步一次,降低了磁盘I/O频率,提升写入性能;
-
durability": "async":控制translog的落盘策略,默认是request(每个写入请求都落盘,保障数据可靠性)。设置为async后,translog异步落盘,进一步提升写入吞吐量,但会牺牲部分容灾能力(宕机时可能丢失少量未落盘的写入数据); -
settings.number_of_replicas模块number_of_replicas": 0:设置索引的副本分片数量为0。副本主要用于高可用和读负载均衡,写入时副本需要同步数据,因此设置为0可以最大化写入性能;待写入完成后,可再将副本数调整回去以保障可靠性;
-
mappings模块dynamic": false:禁用“动态映射”,即ES不会自动为文档中新增的字段创建索引。这样可以避免因字段数量爆炸导致的性能开销,仅对properties中声明的字段建立索引;若后续需要为新字段建索引,可通过update by query手动处理;
-
properties": {}:这里可以定义具体的字段映射规则(如字段类型、分词器等),当前为空表示暂时未定义具体字段的精细化映射; -
整体优化目标:这段配置是一套**“极致写入性能优先”**的优化策略,通过减少
Refresh频率、异步落盘translog、关闭副本、禁用动态映射等手段,大幅提升写入吞吐量;同时通过控制分片分布避免数据热点,保障集群资源的均衡性。适合“写入压力大、对实时查询要求不高、后续可补全副本和索引”的业务场景。