电脑硬件价格呈现持续上涨趋势及软件优化的必要性
2025年11月初电脑硬件价格呈现持续上涨趋势,尤其是CPU、内存和显卡等核心配件。以下是具体分析:
一、CPU价格暴涨
进入11月后,英特尔和AMD多款处理器价格突然上扬,部分型号涨幅达10%-12%。例如英特尔第12-14代酷睿系列散片与盒装版本均受影响,AMD的Ryzen 5000系列成本增加5-20美元。渠道监测显示,代理商已暂停发货或缩减库存配额,市场供应趋紧。
二、内存与固态硬盘持续攀升
DDR4内存单季涨幅达85%-90%,DDR5因制造商转产导致价格上涨。固态硬盘价格自6月起稳步上升,PCIe 5.0新品推出但3.0/4.0型号同样涨价。AI行业对存储需求暴增是主因,即使双十一期间优惠有限,后续产能恢复前价格仍可能继续上涨。
三、显卡市场分化
显卡市场整体平稳,但部分高端型号如RTX 5090价格翻倍。中端型号如RTX 5070 Ti(约7799元)和RTX 5070(约4999元)因供需关系价格波动较大。
我四月份刚刚入手了一台组装机,我最后加上国补的价格4559,配置如下:
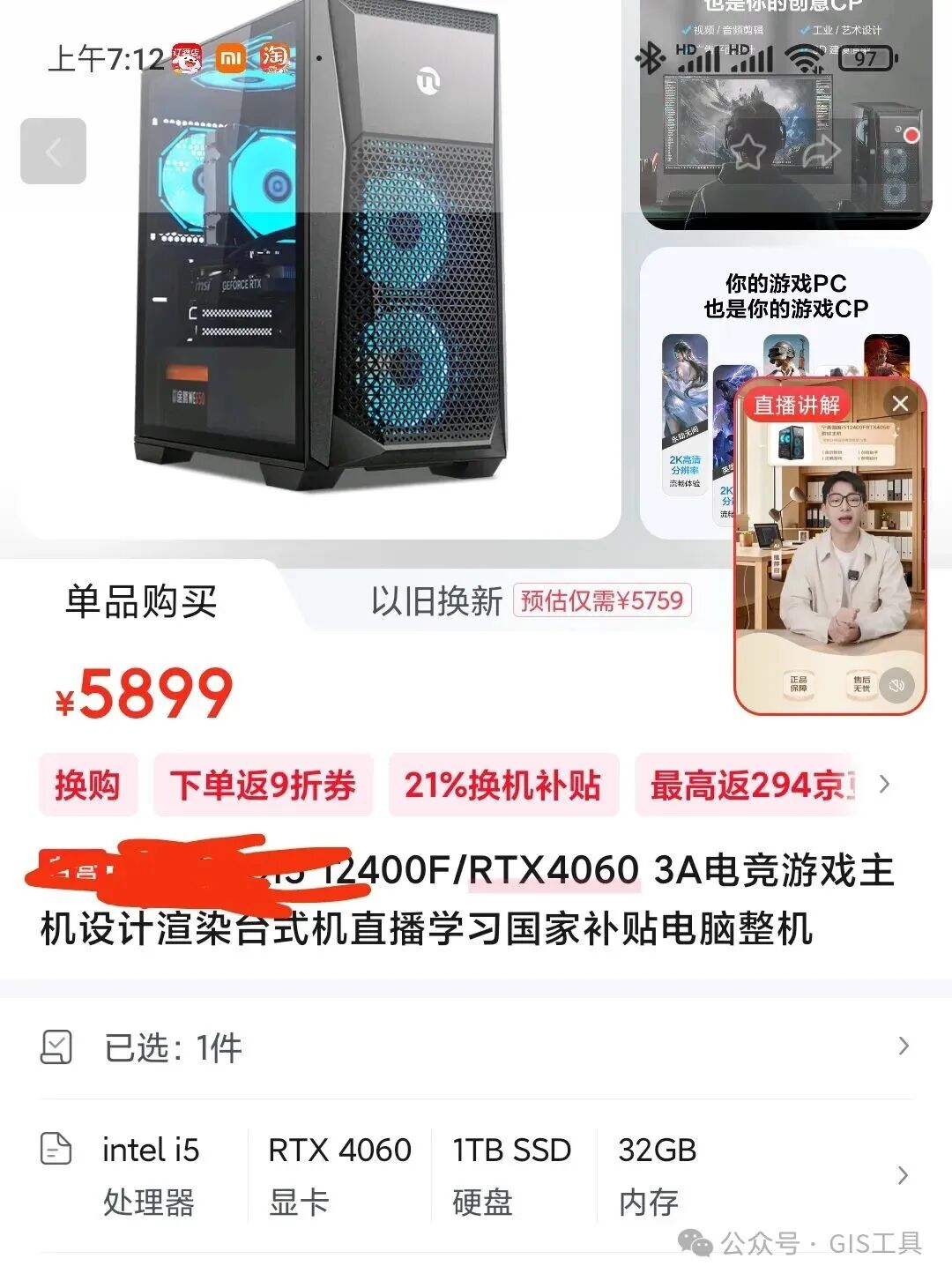
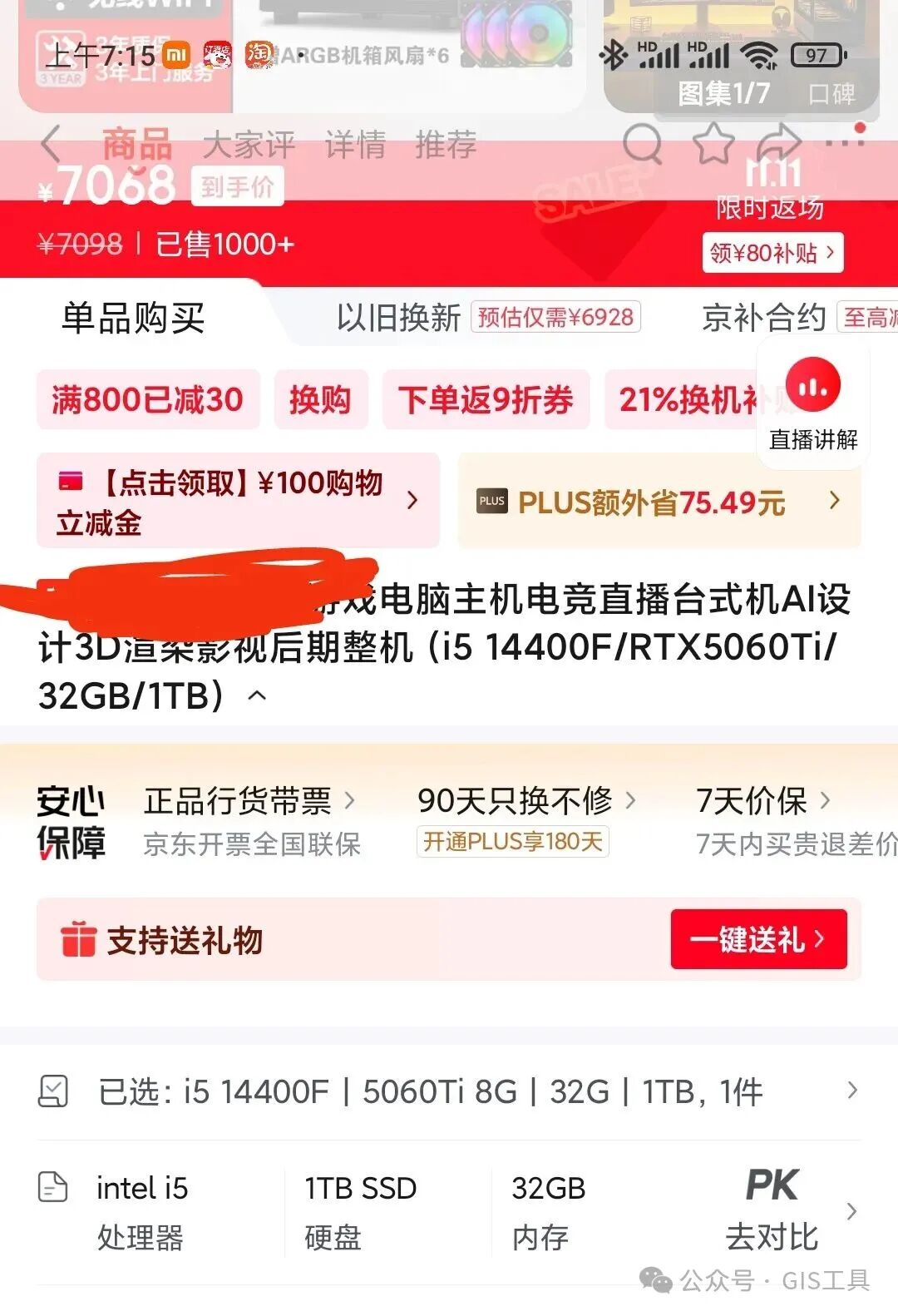
由于该型号电脑已经下架,我查了一款差不多类型的电脑做对比,价格是7068,也没有啥优惠:
在 AI 时代,硬件和算力的稀缺性已成为制约行业发展的核心瓶颈。随着大型语言模型(如 GPT 系列)和多模态 AI 的爆发,训练和推理的计算需求呈指数级增长。根据行业报告,全球 AI 算力需求预计到 2030 年将超过现有供应 10 倍以上,而 GPU 等高端芯片的生产瓶颈(供应链、地缘政治等因素)进一步加剧了这一问题。结果是,企业面临高昂的云服务费用、能源消耗激增,甚至是“算力饥荒”。因此,软件层面的优化已成为“开源节流”的关键路径,通过算法创新和工程实践来“挤出”更多效率,而非单纯依赖硬件堆砌。
为什么算力稀缺如此紧迫?
需求爆炸:一个像 Llama 3 这样的模型训练可能需要数百万 GPU 小时,推理时单次查询也消耗不菲。
供给瓶颈:NVIDIA 等厂商主导市场,但产能有限;新兴芯片(如 Grok 的 xAI 芯片)虽在研发,但短期内难以满足全球需求。
可持续性压力:AI 数据中心能耗相当于小国用电量,碳排放问题日益突出。 优化软件不是权宜之计,而是长远战略:据估计,通过优化可将算力消耗降低 50%-90%,让 AI 更普惠。
软件优化节省算力的核心策略软件优化主要聚焦于模型压缩、推理加速和分布式训练三个层面。下面用表格总结常见方法、原理及效果(基于 2025 年主流实践)
优化策略 | 原理与方法 | 节省算力效果(典型案例) | 适用场景 |
模型量化 | 将浮点参数(如 FP32)转换为低精度(如 INT8 或 FP4),减少内存和计算量。工具:TensorRT、ONNX Runtime。 | 减少 4-8 倍内存,推理速度提升 2-4 倍(如 MobileBERT 量化后部署手机)。 | 边缘设备、实时推理。 |
剪枝与稀疏化 | 移除模型中冗余权重(结构化/非结构化剪枝),或引入稀疏矩阵运算。工具:PyTorch Pruning API。 | 参数减少 90%,算力降 70%(EfficientNet 系列)。 | 大型 Transformer 模型。 |
知识蒸馏 | 用大模型“教”小模型,转移知识以缩小规模。方法:教师-学生框架。 | 模型大小减 50%-80%,准确率仅降 1-2%(DistilBERT)。 | 部署优化,从云到端。 |
混合精度训练 | 动态切换 FP16/BF16 和 FP32,加速矩阵运算。工具:AMP(Automatic Mixed Precision)。 | 训练速度提升 2-3 倍,能耗降 30%(GPT-3 训练实践)。 | 训练阶段,数据中心。 |
高效架构设计 | 采用 MoE(Mixture of Experts)或 FlashAttention 等机制,减少 KV 缓存和注意力计算。 | 推理时序长序列降 50% 算力(Llama 3 MoE 变体)。 | 长上下文生成、聊天机器人。 |
分布式与并行 | 模型并行(管道/张量并行)和数据并行,结合 FSDP(Fully Sharded Data Parallel)。 | 训练效率提升 5-10 倍(Megatron-LM 框架)。 | 多 GPU 集群训练。 |
这些策略往往结合使用,例如在 Hugging Face Transformers 中集成量化 + 剪枝,能让一个 7B 参数模型在消费级 GPU 上高效运行。实际案例与趋势(2025 年视角)
xAI 的实践:xAI 在 Grok 模型中强调“高效 AI”,通过自定义优化(如稀疏激活)减少了 40% 的推理算力需求,推动了更可持续的开发。
开源社区:项目如 MLPerf 基准测试显示,优化后模型在 TPU/v100 上性能翻倍。企业如 Meta 的 Llama 系列已内置多优化层。
未来方向:随着 Neuromorphic 计算和量子辅助优化的兴起,软件将更“硬件感知”,如自适应量化根据芯片类型动态调整。
总之,AI 不是“烧钱游戏”,而是“智造竞赛”。开发者应从设计伊始就嵌入优化思维——用 PyTorch/TensorFlow 的 profiler 工具监控瓶颈,从小模型迭代起步。