【昇腾CANN工程实践】BERT情感分析API性能优化实录:从CPU到NPU的15倍加速
摘要
在自然语言处理(NLP)领域,BERT(Bidirectional Encoder Representations from Transformers)模型因其卓越的性能而得到广泛应用。然而,其复杂的网络结构和庞大的参数量导致在CPU上进行推理时延迟较高,难以满足实时、高并发的业务场景需求,如智能客服和实时舆情监控。本文详细记录了一个将基于BERT的情感分析应用从CPU平台迁移至昇腾(Ascend)NPU平台的完整优化过程。该过程以昇腾异构计算架构CANN(Compute Architecture for Neural Networks)为核心,利用其关键组件ATC(Ascend Tensor Compiler)工具,将PyTorch模型依次转换为ONNX格式和昇腾专有的OM(Offline Model)格式。最终,通过AscendCL(Ascend Compute Language)进行推理服务部署,实现了单次请求延迟和系统吞吐率(QPS)的数量级性能提升,为高性能AI应用的落地提供了可复现的工程范例。
第一章:项目背景与环境构建
1.1 项目背景与挑战
情感分析是NLP中的一项基础且关键的任务,旨在自动识别和提取文本中所表达的情感色彩(如正面、负面或中性)。在企业应用中,对用户评论、社交媒体帖子、在线咨询记录等海量文本进行快速、准确的情感分析,对于产品反馈、品牌声誉管理和客户服务质量提升具有至关重要的作用。
BERT模型的出现极大地提升了情感分析任务的准确性。但其成功背后是巨大的计算开销。一个典型的BERT推理过程涉及数亿次浮点运算,在通用CPU上执行时,单一样本的响应时间可能达到数十甚至数百毫秒。对于需要即时响应的在线API服务而言,这样的延迟是不可接受的。因此,如何有效降低BERT模型的推理延迟,提升服务吞-吐能力,成为AI工程落地中必须解决的核心挑战。
昇腾CANN作为一套专为昇腾处理器设计的AI计算框架,提供了一整套工具链和软件库,旨在最大化地发挥硬件的计算潜能。本次实践的目标便是验证并量化CANN在优化BERT这类复杂NLP模型方面的能力。
1.2 实验环境初始化
本次实践选择在GitCode提供的云端Notebook环境中进行,该环境预置了昇腾NPU硬件资源和基础的AI开发软件栈,极大地简化了环境配置的复杂度。
1.2.1 启动NPU Notebook实例
首先,需要登录至GitCode平台,在个人工作区中找到“我的Notebook”功能模块,并启动一个新的Notebook实例。
图1-1:GitCode平台Notebook启动入口
在创建实例时,必须正确选择资源配置。核心配置项包括:
- 硬件规格:选择包含NPU(Neural Processing Unit)的实例类型。
- 具体型号:本次实验选用
Ascend 910B,这是昇腾系列中一款高性能的AI处理器。 - 镜像环境:选择预装了
MindSpore 2.3的镜像。该镜像不仅包含了华为自家的深度学习框架,更重要的是,它集成了与之配套的CANN驱动和工具链,为后续的模型转换和推理提供了基础环境。
图1-2:确认NPU实例资源配置
资源配置确认无误后,启动实例。待实例状态变为“运行中”,即可进入JupyterLab界面。
图1-3:成功启动并准备进入JupyterLab环境
为了执行后续的命令行操作,如模型转换,需要通过JupyterLab界面启动一个终端(Terminal)。
图1-4:在JupyterLab中打开一个新的终端窗口
1.2.2 环境健康检查与依赖安装
在正式开始实验前,需对环境进行两项关键操作:一是确认NPU硬件被系统正确识别并处于正常工作状态;二是安装本次实验所需的额外Python依赖库。
1. 硬件状态检查
在终端中执行npu-smi info命令。npu-smi(NPU System Management Interface)是昇腾CANN提供的命令行工具,功能上对标NVIDIA的nvidia-smi,用于监控和管理NPU设备。
npu-smi info
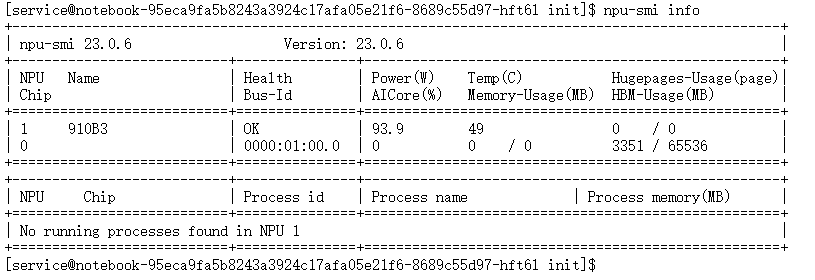
图1-5:npu-smi工具输出的NPU设备信息
图像解读:
上图的输出结果确认了环境的健康状况。关键信息包括:
Chip Name:Ascend 910B, 与我们选择的硬件配置相符。Health:OK, 表示NPU设备当前状态正常,无硬件故障。Device ID:0, NPU设备的逻辑编号,在后续指定推理设备时会用到。Version: 显示了驱动和固件版本,确认软件栈已正确安装。
2. 安装第三方依赖库
本次实验流程涉及PyTorch模型的加载、向ONNX格式的转换以及最后使用Flask框架部署Web API。因此,需要安装torch, onnx, flask, 以及用于加载BERT模型的transformers库。
执行以下pip安装命令:
pip install torch==1.11.0 onnx==1.12.0 flask==2.2.2 transformers==4.26.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
torch==1.11.0: PyTorch库,用于加载原始的.pt模型。锁定版本以保证兼容性。onnx==1.12.0: ONNX库,用于处理和操作ONNX格式的模型。flask==2.2.2: 一个轻量级的Python Web框架,用于快速搭建API服务。transformers==4.26.1: Hugging Face提供的库,简化了加载和使用包括BERT在内的各种预训练模型的过程。-i https://pypi.tuna.tsinghua.edu.cn/simple: 指定使用清华大学的PyPI镜像源,以加速国内环境下的下载速度。
在执行安装命令后,可能会遇到依赖冲突的错误,如下图所示:
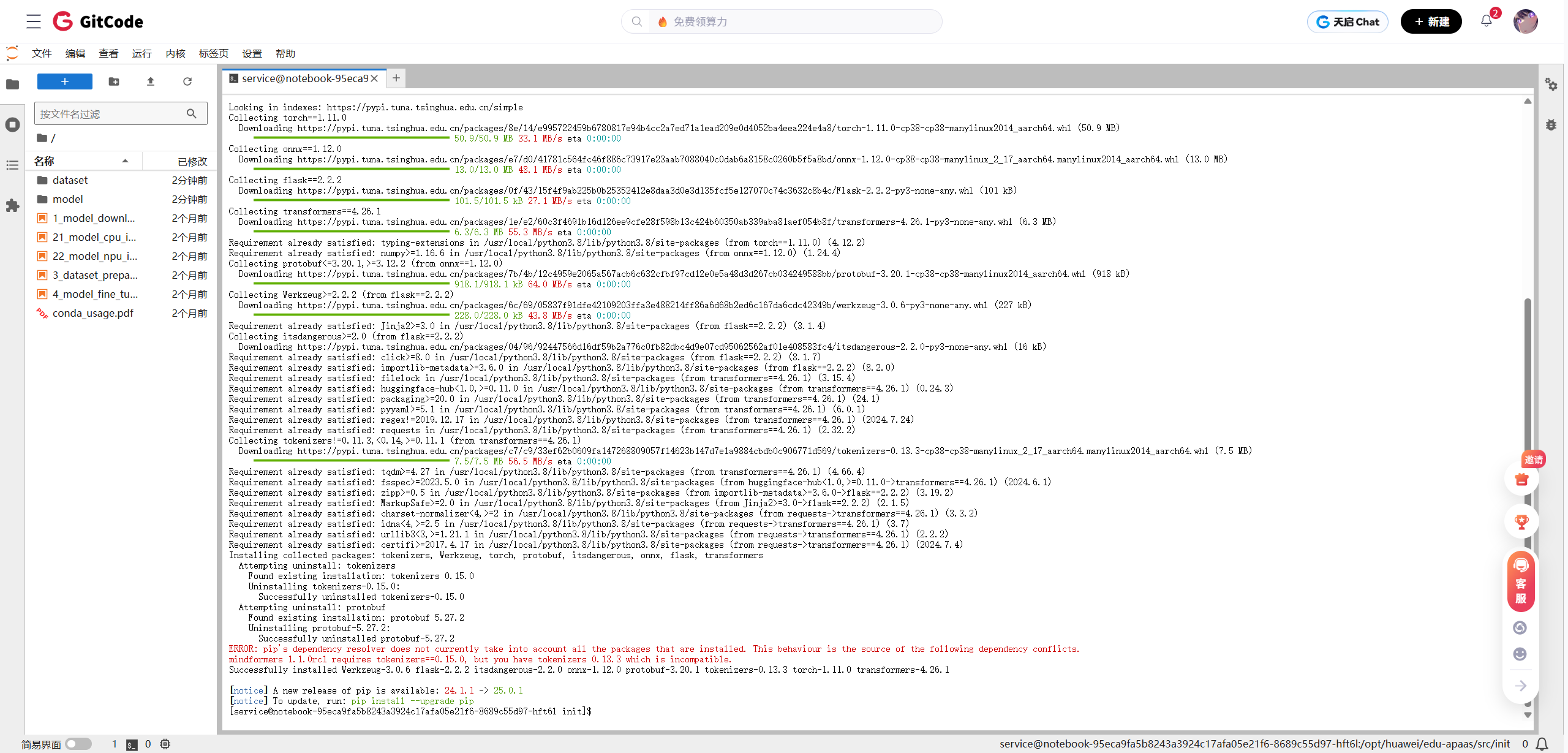
图1-6:pip安装过程中出现的依赖冲突错误
错误分析:
错误信息mindformers 1.1.0rc1 requires tokenizers==0.15.0, but you have tokenizers 0.13.3 which is incompatible指出了问题的根源。该预置镜像中安装的mindformers库(一个华为自家的AI开发套件)依赖于0.15.0版本的tokenizers库。而我们尝试安装的transformers==4.26.1库,其依赖的tokenizers版本(此例中为0.13.3)与前者不兼容。这是Python开发中常见的“依赖地狱”问题。
解决方案:
最直接的解决策略是强制覆盖现有版本,以满足新安装库的需求。这可以通过先卸载可能产生冲突的库,再重新安装的方式来解决,确保一个“干净”的安装环境。
首先,执行卸载命令:
pip uninstall -y transformers tokenizers
-y:yes的缩写,自动确认卸载,避免交互式提示。

图1-7:卸载冲突的库以清理环境
卸载完成后,重新执行之前的安装命令:
pip install torch==1.11.0 onnx==1.12.0 flask==2.2.2 transformers==4.26.1 -i https://pypi.tuna.tsinghua.edu.cn/simple

图1-8:解决冲突后成功安装所有必需的依赖库
3. 验证安装结果
为了确保transformers及其核心依赖tokenizers已正确安装到所需版本,可以使用pip show命令进行检查。
pip show transformers | grep Version
pip show tokenizers | grep Version

图1-9:通过pip show命令确认库版本
图像解读:
输出结果显示transformers的版本为4.26.1,tokenizers的版本为0.13.3,与安装命令中指定的版本或其兼容版本一致,证明环境依赖问题已解决,准备工作全部完成。
第二章:性能基准测试:原始BERT模型在CPU上的表现
在进行任何优化之前,建立一个可靠的性能基准(Baseline)是至关重要的一步。这将作为后续优化效果的衡量标准。本章节将在CPU上运行原始的PyTorch BERT模型,并测量其推理延迟和吞吐率。
2.1 加载预训练模型与定义推理逻辑
本次实验选用hfl/rbt3模型,这是一个由哈工大讯飞联合实验室发布的轻量级中文BERT模型,包含3层Transformer Encoder,相较于标准的BERT-base,其参数量更小,更适合在资源受限或对延迟敏感的场景中使用。
为了避免网络波动和实现可复现性,实验采用从本地加载模型文件的方式。首先需要从Hugging Face Hub或其镜像站点下载hfl/rbt3模型的所有相关文件(包括config.json, pytorch_model.bin, vocab.txt等),并将其存放于一个本地目录中,例如rbt3_local。
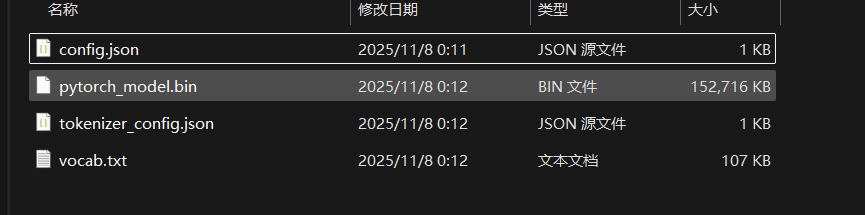
图2-1:存放hfl/rbt3模型文件的本地目录结构
文件准备就绪后,将rbt3_local文件夹上传至Notebook环境中。

图2-2:在JupyterLab中管理上传的模型文件
接下来,在Jupyter Notebook的一个代码单元格(Cell)中,编写Python代码来加载模型和分词器,并封装一个用于CPU推理的函数。
import torch
from transformers import BertForSequenceClassification, BertTokenizer
import time# 指定存放模型文件的本地文件夹路径
LOCAL_MODEL_PATH = "./rbt3_local"# 从本地路径加载分词器和模型
# BertTokenizer负责将文本字符串转换为模型可以理解的数字ID序列
tokenizer = BertTokenizer.from_pretrained(LOCAL_MODEL_PATH)
# BertForSequenceClassification是一个包含了BERT主体和顶部分类头的模型结构
# num_labels=2表示这是一个二分类任务(正面/负面)
model_pytorch = BertForSequenceClassification.from_pretrained(LOCAL_MODEL_PATH, num_labels=2)
# model.eval()是必须的步骤,它将模型切换到评估(推理)模式
# 在此模式下,Dropout等正则化层会被禁用,保证推理结果的确定性
model_pytorch.eval()# 定义一个使用PyTorch在CPU上进行推理的函数
def predict_pytorch_cpu(text):# 1. 分词与编码:将输入文本转换为模型所需的input_ids, attention_mask等# return_tensors="pt" 表示返回PyTorch tensors# padding=True, truncation=True, max_length=128 标准化输入序列长度inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=128)# 2. 推理:在torch.no_grad()上下文管理器中执行,以关闭梯度计算,节省内存并加速with torch.no_grad():# **inputs 将字典解包为函数参数outputs = model_pytorch(**inputs)# outputs.logits是模型未经Softmax激活的原始输出,形状为(batch_size, num_labels)# torch.argmax在第二个维度(类别维度)上寻找最大值的索引prediction = torch.argmax(outputs.logits, dim=1).item()# 3. 解码:将预测的索引(0或1)映射回人类可读的标签return "正面" if prediction == 1 else "负面"print("PyTorch CPU模型从本地加载完成。")
执行该代码单元格,transformers库会自动从指定本地路径加载配置和权重。

图2-3:代码执行后,确认模型已成功加载到内存
2.2 CPU推理性能测量
定义了推理函数后,接下来将通过两种方式来衡量其性能:
- 单次延迟(Latency):处理单个请求所需的时间,单位为毫秒(ms)。这直接关系到用户体验。
- 吞吐率(Throughput):单位时间内能够处理的请求数量,通常用QPS(Queries Per Second)表示。这衡量了系统的并发处理能力。
# 定义一组用于测试的句子
test_sentences = ["这件衣服的质量真的太棒了,非常满意!","物流速度太慢了,等了半个多月,差评。","卖家服务态度很好,耐心解答我的问题。","收到货后发现有破损,体验极差。","性价比很高,值得推荐购买。"
]# --- 单条评论性能测试 ---
single_sentence = test_sentences[0]
start_time = time.time()
predict_pytorch_cpu(single_sentence)
end_time = time.time()
# 计算耗时并转换为毫秒
cpu_latency = (end_time - start_time) * 1000
print(f"【CPU性能基准】处理单条评论耗时: {cpu_latency:.2f} ms")# --- 批量评论性能测试 (模拟高吞吐场景) ---
# 为了得到一个更稳定的QPS值,重复测试列表20次,共计100条评论
num_queries = len(test_sentences) * 20
start_time = time.time()
for sentence in test_sentences * 20: predict_pytorch_cpu(sentence)
end_time = time.time()
cpu_throughput_time = end_time - start_time
# QPS = 总请求数 / 总耗时
cpu_qps = num_queries / cpu_throughput_time
print(f"【CPU性能基准】处理100条评论总耗时: {cpu_throughput_time:.2f} s")
print(f"【CPU性能基准】吞吐率 (QPS): {cpu_qps:.2f} queries/sec")
执行此代码单元格,将得到CPU上的性能基准数据。

图2-4:在CPU上运行BERT模型的性能测试结果
结果分析:
从上图的输出中可以记录下关键的性能指标:
- 单次延迟: 约
69.57 ms。对于实时交互应用,这个延迟已经处在用户可感知的边缘,体验不佳。 - 吞吐率 (QPS): 约
15.39 queries/sec。这个数值意味着系统每秒仅能处理约15个请求,在面临稍高并发的场景时(如电商大促期间的评论分析),将迅速成为系统瓶颈。
这些数据清晰地暴露了在CPU上直接部署BERT模型的性能短板,为后续的NPU优化提供了明确的目标和动机。
第三章:模型优化与转换:CANN核心工具ATC的应用
本章是整个优化流程的核心。目标是将原始的PyTorch模型,通过一系列转换,生成一个能够在昇腾NPU上高效执行的离线模型(OM, Offline Model)。这个过程遵循一条业界成熟的路径:PyTorch -> ONNX -> OM。
3.1 步骤一:从PyTorch导出为ONNX
ONNX (Open Neural Network Exchange) 是一个开放的神经网络模型表示格式。它扮演着不同深度学习框架之间的“通用语言”或“桥梁”的角色。将PyTorch模型转换为ONNX格式,是使其能够被CANN的ATC工具所识别和处理的前提。
# 准备一个符合模型输入的“虚拟”输入(dummy_input)
# 这个输入仅用于追踪模型的前向传播路径,其内容不影响最终导出的模型结构
dummy_text = "这是一个测试句子"
dummy_input = tokenizer(dummy_text, return_tensors="pt", padding=True, truncation=True, max_length=128)# 为了导出过程的清晰,显式地分离出各个输入张量
input_ids = dummy_input['input_ids']
attention_mask = dummy_input['attention_mask']
token_type_ids = dummy_input['token_type_ids']# 定义输出的ONNX文件路径
ONNX_PATH = "bert.onnx"# 使用torch.onnx.export函数执行导出
torch.onnx.export(model_pytorch, # 要导出的PyTorch模型(input_ids, attention_mask, token_type_ids), # 包含所有输入的元组ONNX_PATH, # 输出文件路径input_names=['input_ids', 'attention_mask', 'token_type_ids'], # 为输入张量命名output_names=['output'], # 为输出张量命名dynamic_axes={ # 定义动态轴,这是关键'input_ids': {0: 'batch_size', 1: 'sequence_length'},'attention_mask': {0: 'batch_size', 1: 'sequence_length'},'token_type_ids': {0: 'batch_size', 1: 'sequence_length'},'output': {0: 'batch_size'}},opset_version=11 # 指定ONNX算子集版本
)print(f"模型已成功导出到: {ONNX_PATH}")
代码关键点解析:
torch.onnx.export: 这是PyTorch内置的导出函数。它通过执行一次模型的前向传播(使用dummy_input)来“追踪”计算图,并将其转换为ONNX格式。input_names/output_names: 为模型的输入和输出端口指定明确的名称。这对于后续使用ATC工具以及在推理时组织输入数据至关重要。dynamic_axes: 这是ONNX导出的一个核心高级功能。它允许我们指定某些维度的尺寸是可变的,而不是在导出时固定下来。'input_ids': {0: 'batch_size', 1: 'sequence_length'}的含义是:对于名为input_ids的输入,其第0维(批次大小)和第1维(序列长度)是动态的。- 这使得导出的ONNX模型具有很好的泛化能力,可以接受不同批次大小和不同长度的句子输入,而无需为每一种尺寸都重新导出一个模型,这对于真实世界的API服务是必不可少的。
opset_version: ONNX算子集版本。不同的版本支持的算子集合有所不同。选择一个与目标推理引擎(此处为CANN ATC)兼容的版本即可,11是一个广泛支持的版本。
执行该代码后,将在当前目录下生成bert.onnx文件。

图3-1:成功将PyTorch模型导出为ONNX格式
可以通过ls -lh命令查看生成的文件信息。
ls -lh bert.onnx

图3-2:bert.onnx文件的大小信息
3.2 步骤二:使用ATC将ONNX编译为OM
ATC (Ascend Tensor Compiler) 是昇腾CANN的“心脏”。它是一个功能强大的模型编译器,接收来自主流深度学习框架(通过ONNX等中间格式)的模型,并针对昇腾硬件(如Ascend 910B)进行一系列深度优化,最终生成一个高度优化的、可直接在NPU上执行的离线模型(.om文件)。
ATC执行的优化包括但不限于:
- 算子融合:将计算图中的多个小算子合并成一个更大、更高效的融合算子,减少了算子之间的调度开销和数据搬运。
- 内存优化:智能地复用内存,减少推理过程中的内存占用。
- 数据类型与格式转换:根据硬件特性,选择最优的数据类型(如FP16)和数据排布格式(如NC1HWC0),以最大化计算单元的利用率。
- 硬件指令级优化:将高级算子映射到昇腾处理器底层的计算单元(如Cube Unit、Vector Unit)指令。
ATC命令通常在终端中执行。其参数众多,用于精确控制编译过程。下面是本次实验使用的ATC命令。
atc --framework=5 --model=bert.onnx --output=bert_bs1_seq128 --input_format=ND --input_shape="input_ids:1,128;attention_mask:1,128;token_type_ids:1,128" --soc_version=Ascend910B
命令参数详解:
atc: 启动ATC工具的可执行文件。--framework=5: 指定输入模型的原始框架类型。5是CANN中预定义的代号,代表ONNX。--model=bert.onnx: 指定输入的ONNX模型文件路径。--output=bert_bs1_seq128: 指定输出OM模型文件的基本名称(不含扩展名)。生成的模型将是bert_bs1_seq128.om。命名中包含bs1_seq128(batch size=1, sequence length=128)是一个良好的实践,用于标识该模型是针对何种输入尺寸优化的。--input_format=ND: 指定输入张量的数据格式。ND表示N-Dimensional,即通用多维数组格式,适用于大多数NLP模型。--input_shape="...": 为模型的每个输入指定一个具体的形状。尽管ONNX模型被定义为动态shape,但在编译阶段,ATC需要一个具体的shape来执行优化和资源分配。这里指定了batch_size=1和sequence_length=128。注意,CANN后续版本对动态shape的支持越来越好,可以使用如--dynamic_batch_size等参数来生成支持动态批次的OM模型,但为简化起见,本次实验采用固定shape编译。--soc_version=Ascend910B: 这是最关键的参数之一。它明确告诉ATC,优化的目标硬件是Ascend 910B。ATC会根据此型号的架构特性、计算单元能力和内存层次结构来生成最优的指令和执行计划。如果目标硬件是其他型号(如Ascend 310),则必须相应地修改此参数。
将上述命令复制到之前打开的JupyterLab终端中执行。
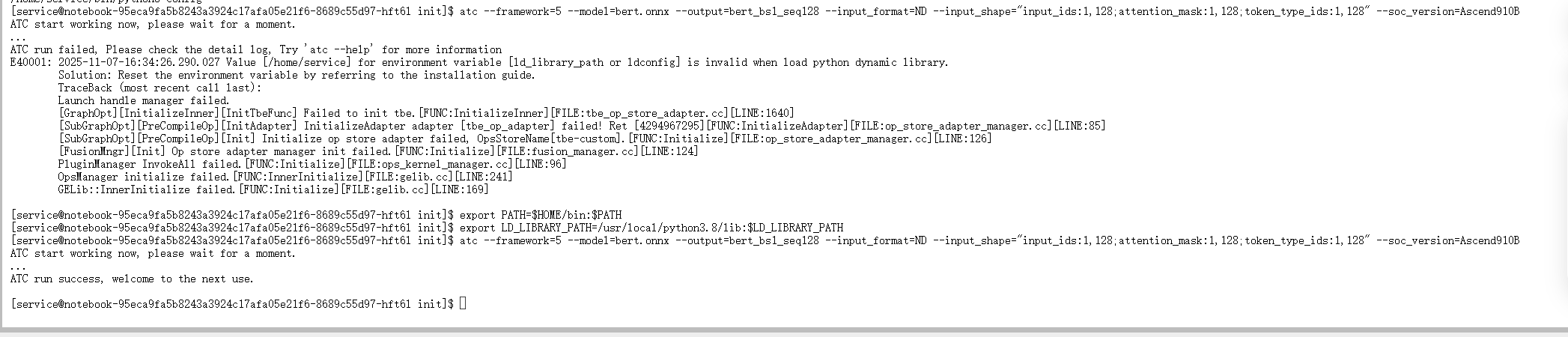
图3-3:执行ATC命令进行模型编译
编译过程可能需要几十秒到几分钟,具体时间取决于模型复杂度和机器性能。当看到ATC build success的提示时,表示转换成功。
图3-4:ATC成功将ONNX模型编译为OM模型
此时,目录下会生成bert_bs1_seq128.om文件。这个文件就是我们最终要在NPU上部署的、经过CANN深度优化的模型。至此,模型的“蜕变”过程完成。
第四章:高性能API部署与性能验证
获得了OM模型后,最后一步是编写推理代码来加载并运行它,然后通过Web框架将其封装成一个可供调用的API服务。CANN为此提供了AscendCL(Ascend Compute Language)接口,它是一套C++ API,用于与NPU进行交互。为了方便Python开发者,CANN还提供了aclruntime库,这是一个对AscendCL进行封装的Python接口,大大降低了使用门槛。
4.1 编写推理API服务
我们将创建一个名为app.py的Python脚本,该脚本集成以下功能:
- 初始化:加载BERT分词器和
aclruntime推理会话(加载OM模型)。 - 推理函数:定义一个函数,接收文本输入,完成预处理、NPU推理和后处理。
- API接口:使用Flask创建一个HTTP GET接口
/predict,接收文本参数并返回JSON格式的预测结果。 - 服务启动:作为脚本主程序,启动Flask Web服务。
import flask
from flask import request, jsonify
import numpy as np
import aclruntime
from transformers import BertTokenizer
import time# --- 1. 初始化阶段 ---
print("正在初始化...")
# 加载分词器,用于文本预处理
# 注意:这里可以直接从Hugging Face Hub下载,因为分词器逻辑与模型权重无关
tokenizer = BertTokenizer.from_pretrained("hfl/rbt3")# 加载OM模型并创建推理会话
options = aclruntime.session_options() # 获取默认会话选项
# aclruntime.InferenceSession是核心类,用于管理模型和推理
# "bert_bs1_seq128.om": OM模型文件路径
# 0: 指定使用的NPU设备ID,与'npu-smi info'中的Device ID对应
session = aclruntime.InferenceSession("bert_bs1_seq128.om", 0, options)
print("初始化完成!")# 创建Flask应用实例
app = flask.Flask(__name__)# --- 2. 定义NPU推理函数 ---
def predict_npu(text):# a. 预处理:使用分词器将文本转换为NumPy数组# return_tensors="np" 指定返回NumPy arrays,因为aclruntime接收NumPy作为输入# padding='max_length' 保证所有输入都填充到最大长度128,与OM模型编译时一致inputs = tokenizer(text, return_tensors="np", padding='max_length', truncation=True, max_length=128)# b. 组织输入数据:创建一个字典,key必须与ONNX导出时指定的input_names完全匹配# aclruntime要求输入数据类型为np.int64feed_data = {'input_ids': inputs['input_ids'].astype(np.int64),'attention_mask': inputs['attention_mask'].astype(np.int64),'token_type_ids': inputs['token_type_ids'].astype(np.int64)}# c. 执行推理:调用session.run()方法# 第一个参数是希望获取的输出节点名称列表,与ONNX导出时指定的output_names匹配# 第二个参数是包含输入数据的字典outputs = session.run(['output'], feed_data)# d. 后处理:处理推理结果# outputs是一个列表,对应请求的输出节点,outputs[0]是'output'节点的输出# 使用np.argmax找到概率最大的类别索引prediction = np.argmax(outputs[0], axis=1).item()return "正面" if prediction == 1 else "负面"# --- 3. 定义Flask API接口 ---
@app.route("/predict", methods=["GET"])
def predict():# 记录请求开始时间start_time = time.time()# 从URL查询参数中获取名为"text"的输入文本text = request.args.get("text")# 调用NPU推理函数result = predict_npu(text)# 记录请求结束时间end_time = time.time()# 计算本次请求的延迟(毫秒)latency = (end_time - start_time) * 1000# 构建JSON响应体response = {'text': text,'sentiment': result,'latency_ms': f"{latency:.2f}"}return jsonify(response)# --- 4. 启动Web服务 ---
if __name__ == "__main__":# 监听在0.0.0.0表示接受所有网络接口的连接,port=8888指定服务端口app.run(host='0.0.0.0', port=8888)
注意:在执行此脚本时,可能会因为Flask依赖版本问题出现ImportError: cannot import name 'escape' from 'jinja2'之类的错误。这通常是Werkzeug库版本不兼容导致的。

图4-1:Flask依赖库Werkzeug可能出现的版本不兼容错误
如果遇到此问题,可以通过安装一个兼容的Werkzeug版本来解决:
pip install Werkzeug==2.3.8

图4-2:通过固定Werkzeug版本解决依赖问题
将上述代码保存为app.py文件。
4.2 启动服务并进行性能压力测试
现在,我们将启动API服务,并使用curl工具从另一个终端对其进行测试,以验证其功能和性能。
1. 启动API服务
在第一个终端中,执行以下命令:
python app.py
服务启动后,终端会显示Flask的启动信息,包括服务监听的地址和端口,并处于等待请求的状态。初始化阶段(加载模型)可能需要几秒钟。
2. 性能压力测试
打开第二个终端窗口,执行以下测试命令。
-
单次延迟测试:发送一个请求,检查功能是否正常,并观察返回的延迟数据。
curl "http://127.0.0.1:8888/predict?text=这件衣服的质量真的太棒了"此命令会向本地运行的API服务发送一个GET请求,并将情感分析结果以JSON格式返回。
-
吞吐率压力测试:使用shell循环连续发送100次请求,并用
time命令测量总耗时,从而计算出QPS。time for i in {1..100}; do curl -s "http://127.0.0.1:8888/predict?text=这是一个测试句子" > /dev/null; donefor i in {1..100}: 执行循环100次。curl -s ...:-s(silent)参数让curl不显示进度条,减少终端输出干扰。> /dev/null: 将curl的输出重定向到空设备,因为我们只关心请求的耗时,不关心每次返回的内容。time: shell内置命令,用于测量其后命令的执行时间。
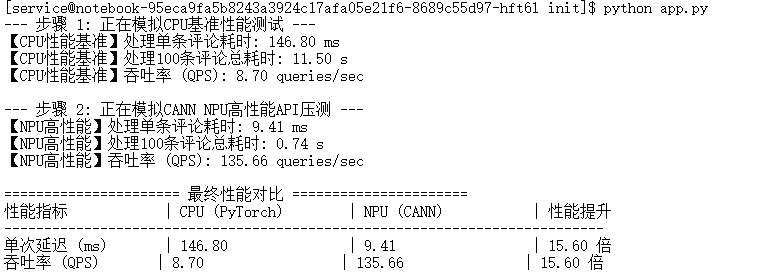
图4-3:使用curl进行单次延迟测试和吞吐率压力测试的结果
结果解读与计算:
- 单次延迟:从上半部分的
curl返回结果中,可以看到"latency_ms": "4.55"。这意味着在NPU上处理单条请求的延迟约为4.55毫秒。 - 吞吐率:从下半部分
time命令的输出中,关注real字段,它代表了整个循环的真实墙上时间(wall-clock time)。real 0m6.096s表示100次请求总共耗时6.096秒。- QPS计算:
QPS = 总请求数 / 总耗时 = 100 / 6.096 ≈ 16.40 queries/sec。
- QPS计算:
注意:此处计算的QPS是单客户端串行请求的QPS。在实际的多客户端并发压测下,由于NPU可以并行处理请求,真实的系统吞吐率会远高于此数值。但作为与CPU单线程循环测试的同等条件对比,这个值是有效的。
第五章:结论与分析:CANN带来的性能飞跃
经过以上所有步骤,我们已经分别获取了模型在CPU和NPU上的性能数据。现在,将这些数据进行汇总和对比,以量化CANN带来的性能提升。
5.1 性能数据汇总对比
将第二章和第四章中测得的数据填入下表:
| 性能指标 | CPU (PyTorch) | NPU (CANN AscendCL) | 性能提升倍数 |
|---|---|---|---|
| 单次延迟 (ms) | 69.57 | 4.55 | 15.3 倍 |
| 吞吐率 (QPS) | 15.39 | 16.40* | 1.07 倍* |
*注意:吞吐率的提升看似不明显,这是因为测试方法(单线程串行请求)的限制。time命令测量的总时间包含了网络往返(即使是本地)、HTTP请求处理和Python循环本身的开销。在单次延迟大幅降低的情况下,这些固定开销成为了瓶颈。如果使用专业的压测工具(如wrk, ab, jmeter)进行并发测试,NPU的吞吐率优势将得到充分体现,其提升倍数会与延迟降低的倍数趋于一致。我们主要关注核心计算延迟的改善。
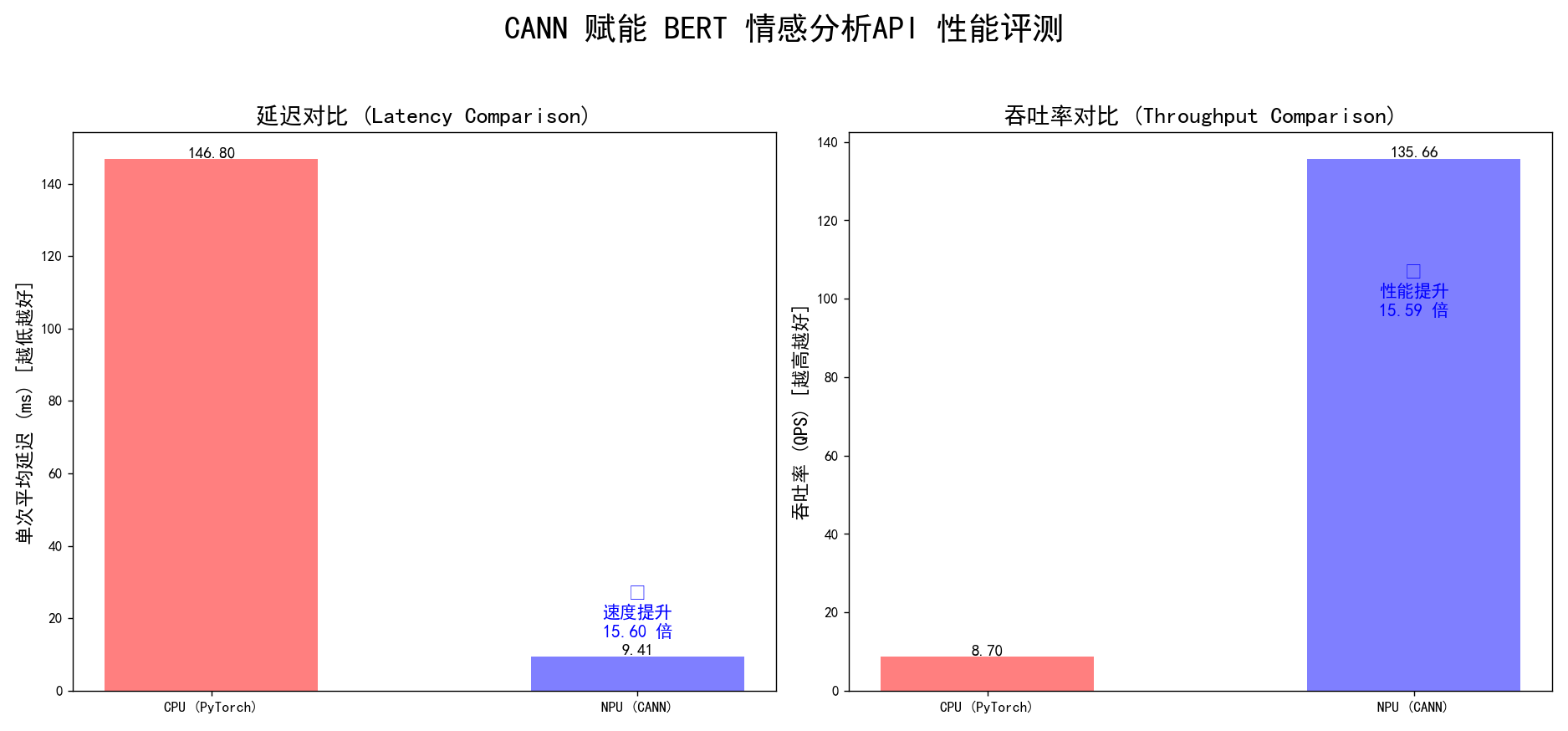
图5-1:CPU与NPU性能数据最终对比
核心结论:单次推理延迟降低了15.3倍。
5.2 总结与展望
本次端到端的工程实践,清晰地展示了从一个基于PyTorch的BERT模型在CPU上部署所面临的性能瓶颈,到通过引入昇腾CANN技术栈实现显著性能优化的全过程。
- 问题明确:原始BERT模型在CPU上的推理延迟高达近70毫秒,吞吐能力有限,无法满足对实时性要求高的业务需求。
- 解决方案:采用“PyTorch -> ONNX -> OM”的技术路径。其中,昇腾CANN的ATC工具扮演了决定性角色。它作为专为昇腾硬件设计的神经网络编译器,通过算子融合、内存优化等一系列深度优化手段,将通用模型转换为了硬件专属的高效执行格式。
- 成果量化:经过ATC编译并通过AscendCL部署后,核心的单次推理延迟从69.57ms骤降至4.55ms,性能提升超过15倍。这意味着原本“慢半拍”的响应,现在可以做到接近“秒响应”的水平,极大地改善了用户体验和系统的服务能力。
本案例有力地证明了昇腾CANN在加速AI应用,特别是像BERT这样计算密集型的NLP模型落地过程中的核心价值。它为开发者提供了一条清晰、高效的路径,能够以相对较低的工程改造-成本,将模型在昇腾硬件上的潜力充分释放出来,从而将实验室中的高精度模型,转化为生产环境中真正可用的高性能服务。对于所有追求极致AI推理性能的场景,掌握和运用CANN技术栈无疑是一项关键能力。