Detect Anything via Next Point Prediction论文解读
文章目录
- 摘要
- 1. Introduction
- 2. Task Formulation
- 2.1. Coordinate Formulation
- 2.2. Input Format
- 2.3. Output Format for Each Task
- 2.4. Model Architecture
- 3. Training Data
- 3.1. Public Datasets
- 3.2. Data Engines
- 3.2.1. Grounding Data Engine
- 3.2.2. Referring Data Engine
- 3.2.3. Other Data Engines

这篇论文的提示和数据处理可以借鉴参考!
摘要
长期以来,目标检测一直由传统的基于坐标回归的模型主导,如YOLO、DETR和Grounding DINO。尽管最近已有研究尝试利用多模态大语言模型(MLLMs)来解决这一任务,但它们面临着召回率低、预测重复、坐标错位等挑战。在这项研究中,我们填补了这一空白,提出了Rex-Omni——一个30亿参数规模的多模态大语言模型,它实现了最先进的目标感知性能。在COCO和LVIS等基准测试中,Rex-Omni在零样本设置下的性能达到或超过了基于回归的模型(如DINO、Grounding DINO)。这得益于三个关键设计:1)任务构建:我们使用特殊令牌来表示0到999的量化坐标,降低了模型的学习难度,并提高了坐标预测的令牌效率;2)数据引擎:我们构建了多个数据引擎来生成高质量的接地、指代和指向数据,为训练提供语义丰富的监督;3)训练流程:我们采用两阶段训练过程,将2200万数据上的有监督微调与基于GRPO的强化后训练相结合。这种强化学习后训练利用几何感知奖励,有效弥合了离散到连续坐标预测的差距,提高了边界框精度,并减轻了由初始有监督微调阶段的教师引导特性所导致的预测重复等不良行为。除了常规检测外,Rex-Omni固有的语言理解能力使其具备多种功能,如目标指代、指向、视觉提示、图形用户界面接地、空间指代、光学字符识别和关键点识别,所有这些功能都在专门的基准测试上进行了系统评估。我们相信,Rex-Omni为更具通用性和语言感知能力的视觉感知系统铺平了道路。
1. Introduction
目标检测[23, 87, 86, 85, 8, 122, 102, 60, 58, 127, 38, 99, 20]因其广泛的应用,长期以来一直是计算机视觉领域的一项基础性任务。该领域从早期基于CNN的架构(如YOLO[86]和Faster R-CNN[87])发展到基于Transformer的模型(如DETR[8]和DINO[122]),而任务本身也从传统的闭集检测演变为开集检测[59, 49, 29, 13, 72, 88, 35, 71, 72],以更好地应对新出现的现实世界挑战。
目标检测的一个首要目标是开发能够识别任意物体和概念的模型。解决这一问题的常用方法是开放词汇目标检测,其中像Grounding DINO [59]和DINO-X [88]这样的模型会利用文本编码器(例如BERT [37]或CLIP [81])来表示物体类别,并执行类别级别的开放集检测。尽管这些方法具有一定效果,但它们从根本上受到自身相对浅薄的语言理解能力的限制,这使得它们难以处理复杂的语义描述(在图2中,尽管输入提示是“红苹果”,Grounding DINO仍检测出了所有苹果)。因此,这些方法在充分实现这一目标方面存在固有的局限性。

相比之下,多模态大型语言模型(MLLMs)[74, 101, 65, 107, 11, 1, 44, 18, 105] 受益于其底层大语言模型强大的语言理解能力,为将高级语言理解融入目标检测提供了一条颇具前景的途径。一种常见的基于MLLM的方法[9, 116, 106, 120, 123, 30, 69, 33, 133, 24, 4]是将坐标表示为离散标记[10],并通过下一个标记预测来生成边界框。尽管从概念上看很巧妙,但现有的基于MLLM的方法在COCO等基准测试上的性能很少能与传统的基于回归的检测器相媲美。如图2所示,即使是像Qwen2.5-VL[4]这样先进的MLLM,在精确的目标定位方面也存在困难,此外还面临召回率低、坐标偏移和重复预测等局限性。
我们认为,基于多模态大语言模型(MLLM)的目标检测性能差异主要源于其当前构建和训练中存在的两个根本性挑战。首先,**多模态大语言模型通常将坐标预测视为离散的分类任务,直接生成绝对坐标值,并依赖交叉熵损失进行监督。**传统的基于回归的模型受益于具有连续性和几何感知的损失函数(如L1、GIoU),这些损失函数对微小的几何偏移直接敏感,而多模态大语言模型在将固定的离散标记集准确映射到连续像素空间时,面临着巨大的学习困难。如图2所示,即使是离散坐标预测中微小的像素错位,也可能导致交叉熵损失不成比例地增大,从而阻碍精确定位。这一固有挑战凸显了采取有效策略以降低坐标学习复杂度并为这种映射提供丰富数据的必要性。
其次,**多模态大语言模型(MLLMs)通常采用有监督微调(SFT)来实现教师引导的下一个token预测训练[79]。**尽管这种范式效率很高,但它在训练和推理之间造成了根本性的不匹配。在监督微调(SFT)过程中,模型总是以真实前缀为条件,即教师强制,这意味着它从未接触过自身可能存在缺陷的预测。这种训练设置无法捕捉模型在自主生成场景下的真实性能,本质上阻碍了模型培养出强大的行为感知能力。因此,在没有这种直接指导的自由形式推理过程中,模型往往难以规范自身的输出结构。这会导致异常的坐标序列生成,例如虚假的重复预测或目标遗漏,从而影响其整体性能。解决这两个相互交织的挑战,对于推进基于多模态大语言模型(MLLM)的目标检测至关重要。
为了克服这些固有的局限性,并充分释放多模态大语言模型(MLLMs)在精确且多功能的物体感知方面的潜力,我们提出了Rex-Omni——一个30亿参数规模的多模态大语言模型。该模型在性能上可与传统检测器相媲美,同时在语言理解能力方面表现尤为突出。我们通过三项核心设计原则来应对上述挑战:
• 任务制定:我们将视觉感知任务统一在坐标预测框架下,其中每个任务都被制定为生成一系列坐标。具体而言,点定位任务预测一个点,检测任务使用两个点形成边界框,多边形任务使用四个或更多点表示物体轮廓,关键点任务输出多个语义点。我们采用量化坐标表示,每个坐标值被映射到1000个离散标记中的一个,这些标记对应0到999的值。这种方法显著降低了坐标学习的复杂度,简化了优化过程,同时提高了空间表示的效率。
数据引擎:为了帮助模型学习1000个离散坐标标记与像素级位置之间的映射,并培养其对复杂自然语言表达的扎实理解能力,我们设计了多个专门用于定位、指代和指向任务的数据引擎。这些引擎为坐标预测生成高质量、语义丰富的视觉监督信号。
训练流程:我们采用两阶段训练模式。第一阶段,我们在2200万数据上进行有监督微调,以教授模型基本的坐标预测技能。第二阶段,我们应用基于GRPO的[92]强化后训练,并使用三个几何感知奖励函数。这个强化阶段有两个目的:一是通过持续的几何监督提高坐标预测的精度,二是至关重要的一点,它能减轻由初始有监督微调阶段的教师引导特性所导致的不良行为(如重复预测)。
经过这两阶段训练后,Rex-Omni在多种感知任务上都取得了优异的性能,如图1所示,这些任务包括目标检测、目标指称、视觉提示、GUI定位、布局定位、光学字符识别(OCR)、指向、关键点识别和空间指称。所有这些任务都是通过直接预测坐标点来完成的。为了定量评估其性能,首先在目标检测的核心基准数据集COCO [53]上对Rex-Omni进行了评估。在零样本设置下(未使用COCO数据进行训练),与传统的基于坐标回归的模型(如DINO-ResNet50、Grounding DINO)以及其他多模态大语言模型(如SEED1.5-VL [24])相比,Rex-Omni的F1分数表现更优。除了COCO之外,还在多种任务上进一步测试了Rex-Omni的性能,如长尾检测、指称表达理解、密集目标检测、GUI定位和OCR。Rex-Omni在这些任务中持续优于传统检测器和多模态大语言模型,从而构建了一个集精确定位与强大语言理解于一体的统一框架。
总之,Rex-Omni代表着在将强大的语言理解与精确的视觉感知相统一方面迈出的重要一步。通过精心整合有原则的任务规划、先进的借助数据引擎以及复杂的两阶段训练流程,我们证明多模态大语言模型(MLLMs)拥有定义下一代目标检测模型的巨大潜力,为视觉感知系统带来了前所未有的多功能性和真正具备语言感知能力的方法。
2. Task Formulation
在本节中,我们将介绍Rex-Omni的任务制定设计,包括其坐标表示、不同任务的具体输出格式以及模型架构的细节。
2.1. Coordinate Formulation
我们首先定义坐标预测的输出形式。利用多模态大语言模型(MLLMs)完成此任务的现有方法大致可分为三种范式,如图3a所示:1)直接坐标预测:受Pix2Seq[10]范式的启发,这些方法[9, 116, 106, 120, 123]将坐标值视为语言模型词汇表中的离散标记,使模型能够直接生成坐标输出;2)基于检索的方法:该方法[30, 69, 31, 33]包含一个额外的提议模块。大语言模型(LLM)经过训练以预测候选区域或边界框的索引,从而将输出表示为对预定义提议的检索任务;3)外部解码器:在这种策略[121, 108, 42, 61]中,大语言模型(LLM)预测特殊标记,其相应的嵌入随后被传递到负责生成最终坐标的外部解码器。我们为Rex-Omni采用直接坐标预测策略,这是由于其简单性、灵活性以及不依赖外部模块或额外监督的优势。
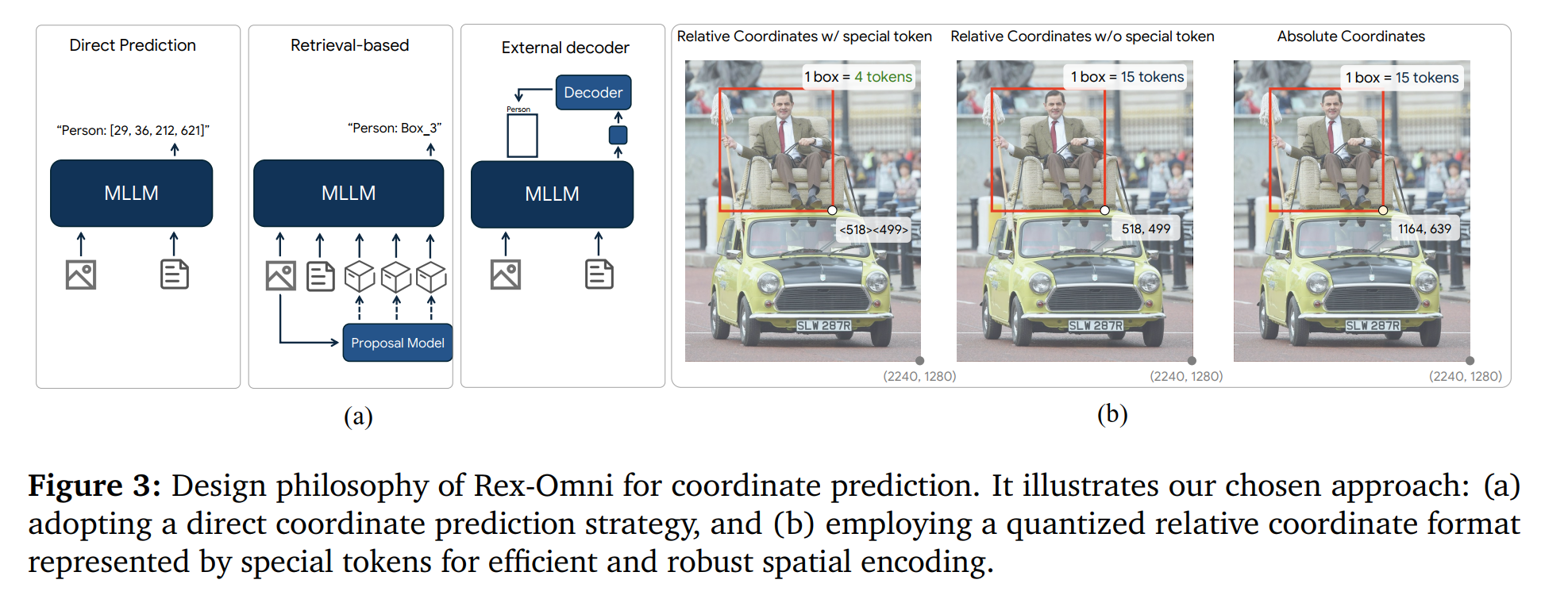
在直接坐标预测范式中,存在几种变体,如图3b所示:1)带特殊令牌的相对坐标:坐标被量化为0到999之间的值,每个坐标由大语言模型词汇表中的一个特殊令牌表示。因此,模型经过训练,可预测这1000个令牌作为坐标的表示。代表性模型是Pix2Seq[10]。2)不带特殊令牌的相对坐标:坐标同样被量化为1000个区间;不过,它们由多个原子令牌而非单个特殊令牌表示。代表性模型是SEED1.5-VL[24]。3)绝对坐标:这种方法使用绝对坐标,像1921这样的坐标值会被 token 化为单个数字(1、9、2、1)。代表性模型是Qwen2.5-VL[4]。我们选择带特殊令牌的相对坐标建模方法主要有两个原因:首先,选择相对坐标而非绝对坐标,通过将分类任务限制在一个有界范围内,从本质上降低了学习复杂度。
涵盖1000个类别。其次,使用专用的坐标特殊标记显著减少了每个坐标所需的标记长度。例如,一个边界框仅由四个特殊标记表示,相比之下,不采用这种方案则需要15个原子标记(包括分隔符)。这显著提高了标记效率和推理速度,尤其是在密集物体场景中。
2.2. Input Format
Rex-Omni为所有视觉感知任务采用了统一的基于文本的界面。每个任务都以自然语言查询的形式呈现,明确指定了需要在图像中识别的目标对象或关系。这种设计使模型能够在单一的指令驱动框架下无缝整合各种视觉-语言任务。
文本提示。在大多数任务中,模型会接收一张图像以及一个用自然语言表述的文本提示。该文本提示可以描述一个或多个对象。当指定多个目标时,它们对应的类别或指代表达式会用逗号连接。例如:
Example of a text prompt for multi-object detection
Please detect pigeon, person, truck, snow in this image. Return the output in box format.
针对不同的任务,我们设计了不同的查询风格来引导模型进行生成。
视觉提示。虽然文本提示具有很强的泛化性和可解释性,但在处理缺乏清晰语言描述的对象时存在局限性,尤其是稀有或视觉复杂的类别。如T-Rex2 [32]等先前的研究所示,某些对象本身很难仅通过文本表达。为解决这一问题,Rex-Omni支持视觉提示,允许用户提供边界框作为一种额外且直观的输入形式。
与现有方法[32, 88, 28]不同,这些方法将视觉提示视为特征匹配问题,通过从指示区域提取嵌入并将其与检测查询进行比较,而Rex-Omni采用了统一的基于文本的接口。给定一个框格式的视觉提示,首先将相应区域转换为量化的坐标标记。然后,通过自然语言指令引导模型识别所有与指示区域属于同一类别的对象。这种设计将视觉提示无缝集成到生成式文本框架中,使模型能够通过语言对视觉对应关系进行推理。
An example of visual prompting in Rex-Omni
Here are some example boxes specifying the location of several objects in the image: "object1": ["<12><412><339><568>", "<92><55><179><378>"]. Please detect all objects with the same category and return their bounding boxes in [x0, y0, x1, y1] format.
2.3. Output Format for Each Task
每个视觉任务的输出均统一表示为结构化的令牌序列,其中包括描述性短语、坐标令牌和用于划分界限的特殊令牌,其组织方式如下:
Basic output format of Rex-Omni
<|object_ref_start|>PHRASE<|object_ref_end|><|box_start|> COORDS<|box_end|>
在此,PHRASE表示坐标序列所代表对象的类别或描述,而COORDS指的是坐标序列。Rex-Omni基于Qwen2.5VL-3B构建,并且我们保留了Qwen2.5-VL用于任务格式化的原始特殊令牌,包括短语起始令牌(<object_ref_start>)、短语结束令牌(<object_ref_end>)、坐标起始令牌(<box_start>)和坐标结束令牌(<box_end>)。
对于涉及输出框的任务(例如目标检测),COORDS由一系列坐标组成,格式为[x0, y0, x1, y1],并按x0升序排序。例如:
An example of a task for outputting bounding boxes
<|object_ref_start|>person<|object_ref_end|><|box_start|><12><42><512><612>, <24><66><172><623>, ...<|box_end|>, ... (more phrases)
对于涉及输出点的任务(例如对象指向),COORDS由一系列[x0, y0]对组成。例如:
An example of a task for outputting points
<|object_ref_start|>button<|object_ref_end|><|box_start|><100><150>,<200><250>, ...<|box_end|>, ... (more phrases)
对于涉及输出多边形的任务,例如光学字符识别(OCR),COORDS由一系列坐标组成,格式为[x0, y0, x1, y1, x2, y2,…]。例如:
An example of a task for outputting polygons
<|object_ref_start|>text<|object_ref_end|><|box_start|><10><20>...<|box_end|>, ... (more phrases)
在关键点检测任务中,我们输出一种结构化的JSON格式,其中既包含物体的边界框,也包含其相关的关键点。
An example of keypoint detection task
{"person1": {"box": <0><123><42><256>, "keypoints": {"left eye": <32><43>, "right eye": <66><55>, ...}}, {"person2": {"box": <51><116><72><522>, "keypoints": {"left eye": <342><23>, "right eye": <16><571>, ...}}}
为了同时检测多个短语,不同短语对应的预测输出会用逗号连接。如果某个特定短语所指的对象不在图像中,相应的COORDS字段会替换为None。
2.4. Model Architecture
如图4所示,Rex-Omni基于Qwen2.5-VL-3B-Instruct模型构建,仅进行了极少的架构修改。原始的Qwen2.5-VL采用绝对坐标编码方案,而我们对该模型进行了调整,使其支持相对坐标表示,且未引入额外参数。具体而言,我们重新利用了模型词汇表中的最后1000个标记作为特殊标记,每个标记对应一个从0到999的量化坐标。

3. Training Data
为了让Rex-Omni同时具备精确的坐标预测能力和强大的语言理解能力,我们使用了两种训练数据来源:公开可用的数据集以及由我们定制设计的数据引擎生成的自动标注数据。
3.1. Public Datasets
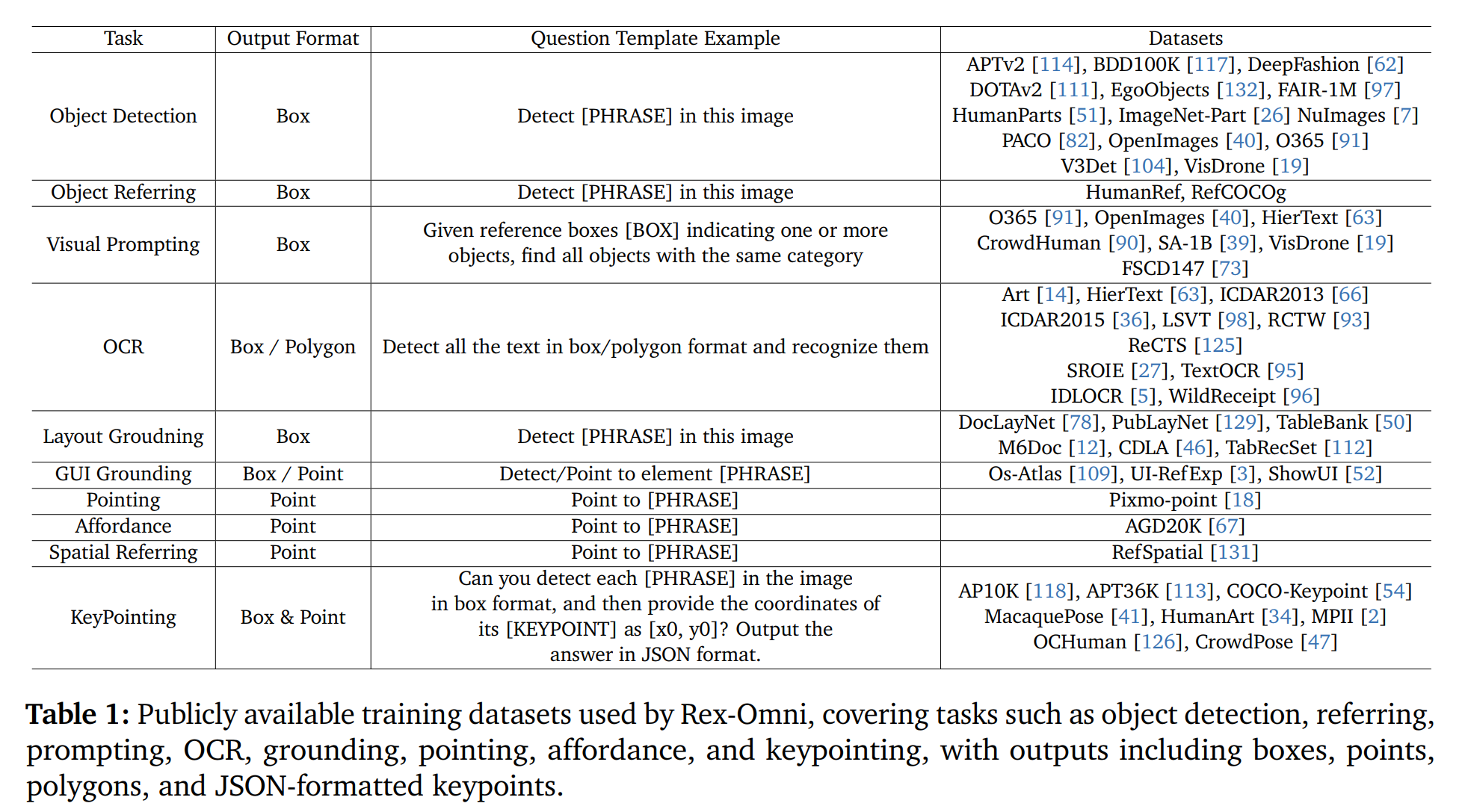
在表1中,我们列举了Rex-Omni在各种子任务训练中所使用的公开可用数据集,这些子任务包括目标检测、目标指代、视觉提示、光学字符识别(OCR)、布局定位、图形用户界面(GUI)定位、指向、功能定位、空间指代和关键点识别。针对每个任务,我们都定义了一组问题模板来构建相应的问答(QA)对。总共使用了约890万个公开数据样本。
3.2. Data Engines
对Rex-Omni进行有效的训练,需要学习其1000个量化坐标令牌与图像的连续像素空间之间的细粒度映射。这种能力需要的高质量训练数据量,远超过现有公共数据集通常所能提供的数量。此外,尽管许多公共数据集提供类别级别的标注,但那些能提供更丰富的实例级语义基础(例如指代表达式)的数据集,在规模和多样性上仍然不足。为解决这些局限性,我们开发了一套专门的数据引擎,旨在生成高质量、大规模的训练数据,这些数据是专为细粒度空间推理和复杂语言基础任务量身定制的。
3.2.1. Grounding Data Engine
构建大规模检测数据集的一种常见策略是开发一个接地数据引擎[29, 88, 89, 13, 77],这通常包括生成图像标题、提取候选短语,以及使用接地模型(例如Grounding DINO)为这些短语分配边界框。与先前的方法不同,我们在该流程中引入了一个短语过滤阶段,以提高标注质量。具体来说,我们的标注流程包括以下四个阶段:
• 图像 captioning:我们首先使用Qwen2.5VL-7B-Instruct为每张图像生成描述性字幕。这些字幕提供视觉内容的自然语言描述,通常涵盖场景中的多个对象。
短语提取:然后,我们应用(SpaCy ^{1})自然语言处理工具包从生成的标题中提取名词短语。这些短语可能包括基本类别名称(例如,桌面、柠檬)以及更具体的描述(例如,切片的黄色柠檬、绿色柠檬)。
短语过滤:这一步与先前的方法有显著不同。为减少数据模糊性,我们会移除包含形容词等描述性属性的名词短语(例如,“绿色柠檬”会被舍弃,而“柠檬”会被保留)。其原因在于,当前的接地模型难以准确解读这类描述性表达,往往会检测到某个类别的所有实例,而不考虑修饰语。例如,“绿色柠檬”这一短语可能会错误地触发对所有柠檬的检测,从而引入显著的标注错误。
短语定位:最后,我们使用DINO-X [88](一种开放词汇目标检测器)来生成与过滤后短语相对应的边界框。
对于这个数据引擎,图像主要来源于COYO [6]和SA-1B [39]数据集。我们进行了严格的预处理,包括丢弃低分辨率图像和过滤标记为NSFW的内容。这一过程得到了一个精心筛选的数据集,包含约300万张图像,每张图像都标注有高质量的接地标签。
3.2.2. Referring Data Engine
与主要强调对象类别名称的检测或定位数据不同,指代数据需要语义更丰富的自然语言描述,例如“穿黄色衬衫的男人”这样的短语。RexSeek[33]的研究强调,高质量的指代标注应允许单个指代表达式映射到多个实例,从而培养模型学习灵活且具有上下文感知的指代定位能力。然而,RexSeek对人工标注的依赖使其耗时费力,且本质上难以扩展。为解决这一局限性,我们设计了一个全自动的指代数据引擎,能够在无需人工监督的情况下生成大规模指代数据。
• 表达式生成:给定一张标注有边界框和相应类别标签的图像,我们向Qwen2.5-VL-7B输入该图像和类别信息,以生成一组指代表达式。每个表达式旨在自然地描述图像中存在的物体类别,模仿人类的描述方式。
• 指向:对于每个生成的指代表达,我们采用了最先进的指代模型Molmo[18]来生成相应的空间点。尽管Molmo仅输出点级预测,但它在理解和定位指代表达方面表现出强大的性能。
掩码生成:我们应用SAM[39]为图像中的每个真实边界框生成一个掩码。
点到框关联:Molmo生成的每个点都与SAM生成的掩码对齐。当一个点位于掩码内时,相应的边界框就会与指代表达式相关联,从而将语言锚定在对象区域。
对于这个数据引擎,我们使用了来自O365 [91]、OpenImages [40]的图像,以及由我们的Grounding Data Engine生成的额外数据。通过这个流程,我们获得了大约300万张带有自动生成的指代标注的图像。
3.2.3. Other Data Engines
除了基础数据和参考数据外,我们还开发了两个相对轻量级的数据引擎,用于生成指向任务和光学字符识别(OCR)任务的数据集。
• 点数据引擎:点级监督为边界框提供了一种高效的替代方案,尤其当物体边界模糊或难以划定(例如边缘、空白区域或精细结构)时。为了从框级监督中获取点标注,我们采用了一种几何感知策略。给定一个边界框,首先使用SAM来获取相应的分割掩码。然后,我们计算其最小面积的外接旋转矩形。
掩码并将其对角线的交点作为候选点。如果该点位于掩码内,则将其指定为框的点标注。通过这种转换,我们从现有的检测数据集以及我们的接地和参考数据引擎的输出中获得了大约500万个点级样本。
• OCR数据引擎:使用PaddleOCR2对包含文本内容的图像进行标注,提取文本区域的多边形边界及其对应的转录文本。对于每个提取的多边形,随后会计算其最小外接轴对齐矩形,作为其边界框表示。图像来源于COYO数据集,产生了约200万个带OCR标注的样本。
总的来说,结合公开可用的数据集和我们的标注流程生成的数据,我们获得了2200万张高质量的标注图像用于训练。