字节开源InfinityStar框架以32倍速挑战Sora范式
目录
前言
一、跳出“大染缸”:视频生成的两种哲学
二、核心创新之一:像“搭乐高”一样生成视频,而非“和面”
三、核心创新之二:“站在巨人肩膀上”的视觉分词器
四、核心创新之三:让Transformer更“专注”,避免“走神”
五、成果:质量、速度与通用性的统一
结语:视频生成的“GPT时刻”即将来临?

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 字节开源InfinityStar框架
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在过去两年,AI视频生成的世界几乎被一种名为“扩散”(Diffusion)的技术范式所统治。从OpenAI的Sora到腾讯的混元视频,这些模型通过“从噪点中恢复图像”的方式,为我们带来了前所未有的视觉奇观。但在这份惊艳的背后,隐藏着一个巨大的痛点:慢。
生成一段短短几秒的高清视频,往往需要数十分钟甚至更长的时间。这种“分钟级等待”极大地限制了AI视频技术的实时应用和商业化落地。我们似乎陷入了一个“质量”与“速度”不可兼得的困境。
然而,字节跳动最新发布并全面开源的InfinityStar框架,正试图打破这个僵局。它没有继续在扩散模型的道路上“内卷”,而是选择了一条一度被认为“质量稍逊”的“自回归”(AutoRegressive)路线,并将其推向了前所未有的高度。结果是惊人的:58秒生成5秒720p高清视频,速度比主流扩散模型快32倍,同时在业界公认的VBench评测中,以80亿参数战胜了130亿参数的顶级扩散模型HunyuanVideo。
这不仅仅是一次性能上的超越,更可能是一次技术路线的“变天”。InfinityStar是如何做到的?

一、跳出“大染缸”:视频生成的两种哲学
要理解InfinityStar的革命性,我们得先了解视频生成的两种主流“哲学”。
(1)扩散模型(Sora为代表):像一位雕塑家,从一块混沌的“大理石”(随机噪点)开始,经过几十上百次的精雕细琢(去噪步骤),最终“恢复”出清晰的视频。这种方法效果好,细节丰富,但过程极其耗时。
(2)自回归模型(GPT为代表):像一位作家写小说,一个词一个词(a token by a token)地顺序写下去。它预测下一个视觉“单词”,理论上只需要一次前向传播,速度快。但问题在于,如何确保写出来的“视觉小说”既精彩(高质量)又连贯(时序一致),一直是巨大的技术挑战。
过去,自回归模型在视频领域一直扮演着追赶者的角色。InfinityStar的出现,首次证明了这条路不仅走得通,而且可能走得更快、更远。
二、核心创新之一:像“搭乐高”一样生成视频,而非“和面”
传统视频生成模型(包括Sora)倾向于将视频视为一个时空混合的“大面团”,时间和空间信息被揉在一起处理。这种方式虽然直观,但模型需要同时理解“猫的毛发纹理”(空间信息)和“它奔跑的姿态”(时间信息),学习难度很大。
InfinityStar提出了一种截然不同的思路:时空金字塔模型(Spacetime Pyramid Model)。
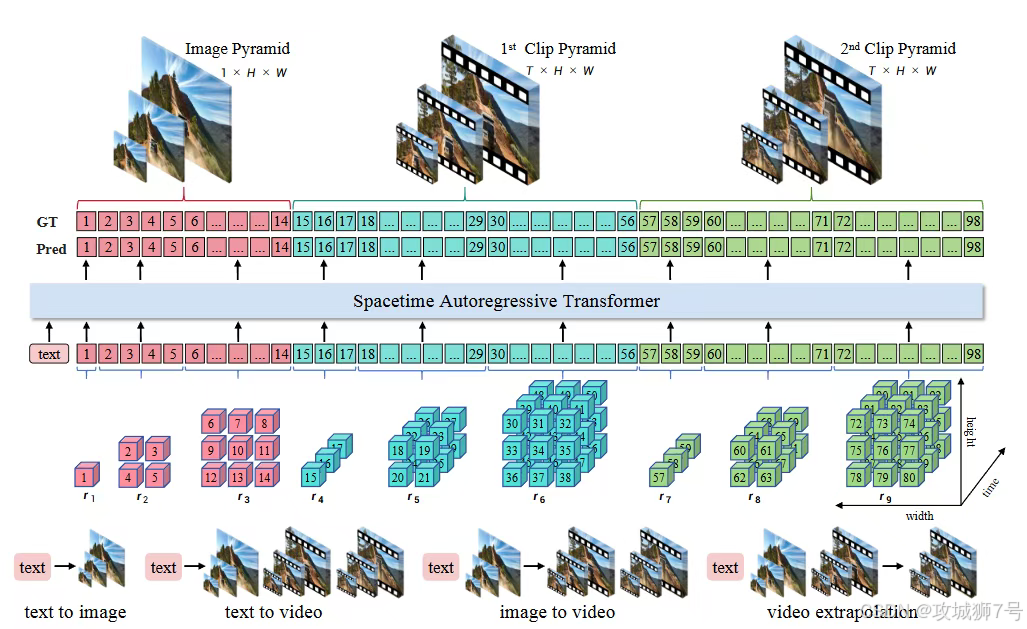
这个名字听起来复杂,但原理却非常巧妙,更像是“搭乐高”:
(1)先搭好“底座”(静态外观):模型首先将视频的第一帧作为一块特殊的“底座”,这个底座不包含运动信息,专门用来编码视频最核心的静态内容,比如场景布局、物体材质、颜色等。它就像一幅高质量的“照片”。
(2)再逐块添加“运动积木”(动态变化):在“底座”的基础上,模型开始一块接一块地生成后续的“运动积木”(视频片段)。每一块积木都包含固定的时长(比如80帧),专门用来编码运动信息。
这种“时空分离”的设计,带来了几个巨大的好处:
(1)学习更简单:模型可以将学习任务解耦,专注于在第一步学好“画画”(空间外观),在后续步骤学好“拍电影”(时间运动),而不是混在一起学。
(2)长视频成为可能:由于是按片段一块一块地生成,理论上只要算力允许,就可以无限地“搭积木”,生成任意长度的视频。
(3)多任务统一:生成图片,就是只搭第一块“底座”;生成视频,就是多搭几块“运动积木”。同一个模型,无需任何修改,就能同时胜任文生图、文生视频、图生视频等多种任务。
实验证明,这种解耦设计的确优越。当研究团队尝试将时间和空间耦合在一起处理时,模型的VBench分数立刻下降,并且视频失去了大量纹理细节。
三、核心创新之二:“站在巨人肩膀上”的视觉分词器
自回归模型的基础,是需要一个高质量的“视觉分词器”(Visual Tokenizer),它的作用是将连续的视频像素,转换成像语言一样的离散“单词”(Token),交给Transformer处理。
但从零开始训练一个视频分词器,成本极高。一段5秒的720p视频会生成近10万个Token,计算量是图像的数十倍。
InfinityStar为此提出了一种极为高效的策略:知识继承(Knowledge Inheritance)。

与其让一个新模型从零开始学习如何理解视频,不如让它直接“继承”一位行业顶尖“老师傅”的功力。具体来说:
(1)团队选用了业界顶尖的、已经训练好的连续视频VAE(一种视频压缩编码器)作为基础。这个VAE已经具备了强大的视频理解和表示能力。
(2)然后,他们在这个VAE的编码器和解码器之间,巧妙地插入了一个量化器,将连续的特征“翻译”成离散的Token。

这种“站在巨人肩膀上”的方法,让分词器的训练收敛速度提升了3倍,重建质量也远超从零训练的方案,为整个模型的高性能奠定了坚实的基础。
四、核心创新之三:让Transformer更“专注”,避免“走神”
有了强大的分词器和架构,最后一步是优化核心的Transformer引擎,让它在处理超长视频序列时更高效。
标准的注意力机制,要求模型在生成新内容时,回顾所有历史信息。对于长视频来说,这意味着上下文会爆炸式增长,很快就会耗尽显存(OOM)。
InfinityStar为此设计了时空稀疏注意力(Spacetime Sparse Attention, SSA)。
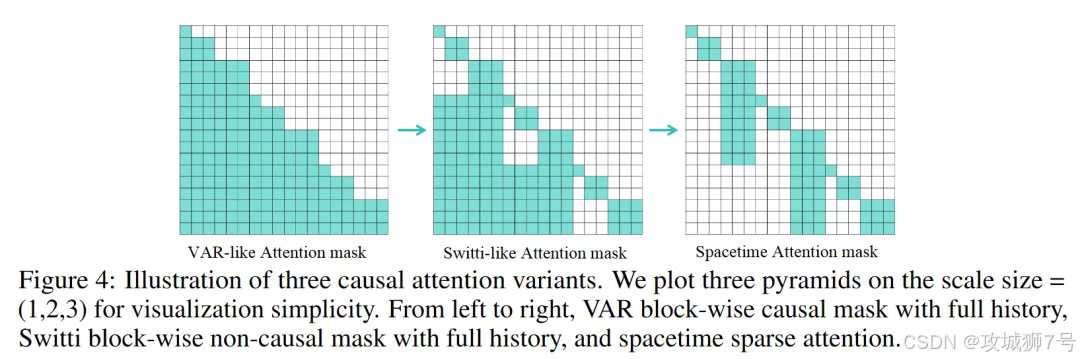
这个机制可以用一个简单的比喻来理解:一个学生在学习一门很长的课程时,不需要在学每一章时都去重读前面所有的章节。他只需要回顾一下上一章的总结(最后一个尺度),就能很好地衔接知识。
通过这种方式,模型只关注最相关的历史信息,将计算复杂度从O(N²)成功降低到了O(N),在一个161帧的视频生成任务中,实现了1.5倍的加速,同时显存占用降低了近30%,从根本上解决了长视频生成的显存瓶颈。
五、成果:质量、速度与通用性的统一
经过这一系列创新,InfinityStar交出了一份令人印象深刻的答卷:
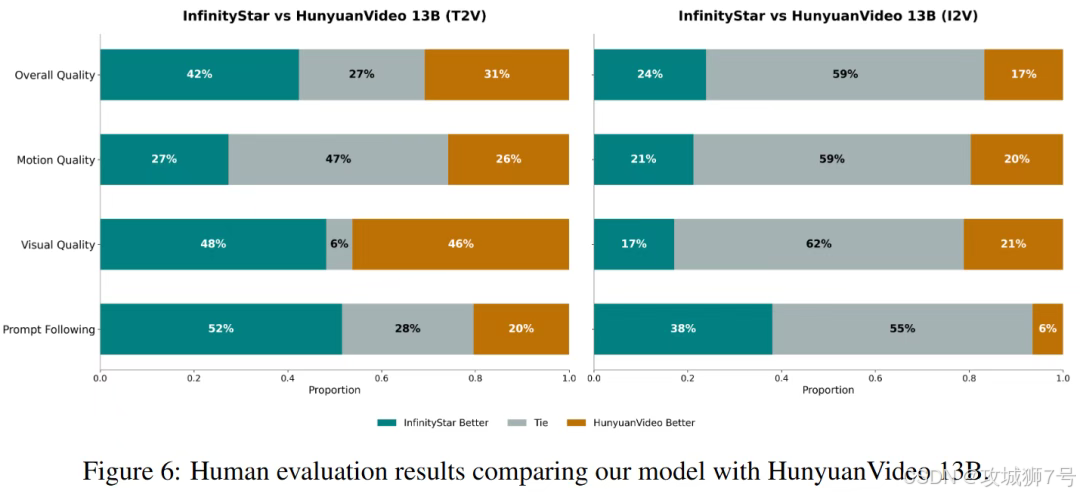
(1)质量:在VBench基准上获得83.74分,超越了参数量更大的扩散模型HunyuanVideo。在与后者的人工双盲评测中,无论是在文本遵循度、视觉质量还是运动平滑度上,InfinityStar都全面领先。
(2)速度:在单张A100 GPU上,生成5秒720p视频仅需58秒,而顶尖扩散模型Wan 2.1需要1864秒(超过30分钟),实现了超过32倍的加速。
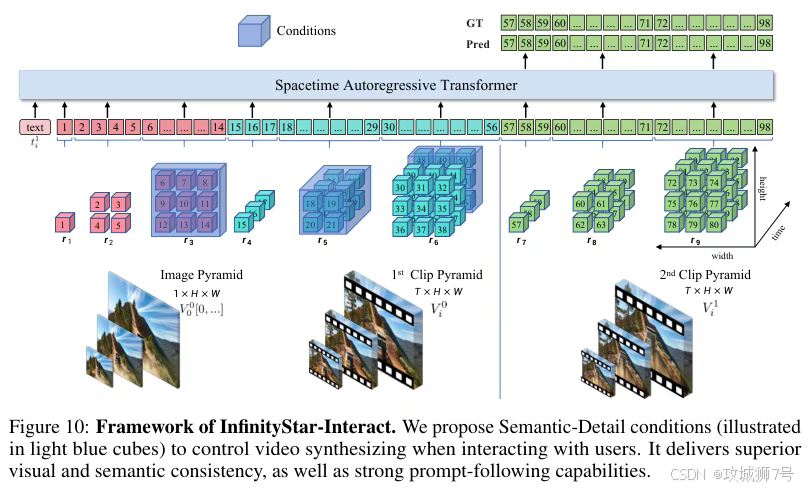
(3)通用性:同一个模型,无需任何微调,就能自然地支持文生图、文生视频、图生视频、视频续写等多种任务,展现了惊人的零样本泛化能力。

结语:视频生成的“GPT时刻”即将来临?
InfinityStar的出现,其意义远不止是发布了一款更快的视频模型。它更像是一次宣言:自回归这条在语言模型领域被GPT证明无比成功的道路,在视频生成领域同样拥有巨大的潜力。
它告诉我们,通过精巧的架构设计和系统性的工程优化,自回归模型完全可以在保持速度优势的同时,达到甚至超越扩散模型的生成质量。其开源的决定,更是为整个社区提供了一个强大的研究和应用基础,无疑将加速自回归视频生成技术生态的发展。
虽然目前模型在处理超高动态场景和超长交互时仍有局限,但它所指明的方向是清晰的。当视频生成的速度从“分钟级”迈入“秒级”,实时视频编辑、交互式内容生成、云端游戏渲染等过去遥不可及的应用场景,将真正变得触手可及。
扩散模型与自回归模型的路线之争,将推动整个AI视频生成技术更快地走向成熟。而由InfinityStar开启的这场“速度革命”,或许正在预示着,属于视频生成的“GPT时刻”,已经离我们不远了。
参考资料:
https://arxiv.org/pdf/2511.04675
https://github.com/FoundationVision/InfinityStar
https://huggingface.co/FoundationVision/InfinityStar
http://opensource.bytedance.com/discord/invite
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!