基于YOLO的深度学习框架用于从胸部X射线图像检测肺炎
摘要
肺炎仍是全球严重的健康问题,尤其影响儿童和老年人等弱势群体,及时准确的诊断对有效治疗至关重要。深度学习的最新进展显著提升了基于胸部 X 光片的肺炎检测效果,但当前许多方法仍面临可解释性、效率和临床适用性方面的挑战。本研究提出一种基于 YOLOv11 的深度学习框架,用于肺炎实时检测,并通过整合 Grad-CAM 实现视觉可解释性。为进一步增强鲁棒性,该框架融入了预处理技术,包括用于对比度提升的限制对比度自适应直方图均衡化(CLAHE)、感兴趣区域提取和肺部分割,确保精确定位的同时,提升对临床相关特征的关注。在两个公开数据集上的评估验证了该方法的有效性:在 COVID-19 放射影像数据集上,系统的宏平均准确率达 98.50%、精确率 98.60%、召回率 97.40%、F1 分数 97.99%;在胸部 X 光片 COVID-19 与肺炎数据集上,准确率为 98.06%,且精确率和召回率表现优异,F1 分数达 98.06%。Grad-CAM 可视化结果持续突出病理相关肺部区域,为放射科医生提供可解释、可信的预测结果。与近期其他方法的对比分析表明,所提方法在诊断准确率和透明度方面均具有优势。该框架结合实时处理能力、强大的预测性能和可解释输出,成为支持多样化医疗场景中肺炎与 COVID-19 诊断的可靠临床适用工具。
关键词:肺炎检测;YOLOv11;胸部 X 光成像;深度学习;可解释人工智能;Grad-CAM;COVID-19
数据可用性声明
这项工作中使用的数据集可在以下网址公开获取:https://www.kaggle.com/datasets/tawsifurrahman/covid19-radiography-database(2025 年 6 月 20 日访问)。https://www.kaggle.com/datasets/prashant268/chest-xray-covid19-pneumonia(2025 年 6 月 20 日访问)。
1. 引言
肺炎仍是全球发病和死亡的主要原因之一,尤其影响 5 岁以下儿童和老年人等弱势群体。世界卫生组织(WHO)估计,该疾病每年导致超过 250 万人死亡,凸显了对及时可靠诊断方法的迫切需求。胸部 X 光成像是检测肺炎的常用且经济高效的手段,但传统评估高度依赖放射科医生的专业知识,这可能导致解释的变异性和主观性,在医疗资源有限的场景中尤为明显 [1]。为应对这些挑战,自动肺炎检测系统因其有望提供一致、快速且可扩展的诊断支持而备受关注。早期自动检测不仅能协助临床医生决策,还能减轻医疗系统负担并改善患者预后 [2]。然而,传统计算机辅助诊断(CAD)系统通常依赖手工提取特征和浅层分类器,在不同成像条件和患者群体中的泛化能力有限 [3,4,5]。
近年来,深度学习(DL)已成为医学影像分析的变革性技术,在鲁棒性和检测准确率方面取得显著提升。特别是卷积神经网络(CNNs),在从原始图像数据中自动学习复杂视觉表征方面表现出卓越成效,无需人工提取特征 [6,7,8]。在基于深度学习的目标检测框架中,“你只看一次”(YOLO)模型因其能实现高精度实时分析而备受瞩目 [9,10],成为胸部 X 光片肺炎检测的有力方法 [11]。
尽管深度学习模型性能令人印象深刻,但临床应用中的主要顾虑是其缺乏透明度。为获得医疗专业人员的信任,此类模型必须提供可解释的结果,阐明预测背后的推理过程。因此,将可解释人工智能(XAI)技术整合到基于深度学习的肺炎检测框架中,对于促进临床接受度、确保伦理且可解释的诊断至关重要 [12,13]。
本文提出一种基于 YOLO 的可解释框架,专为胸部 X 光片肺炎检测设计。该方法结合 YOLO 的检测优势与事后可解释性技术,不仅能提供准确诊断,还能给出视觉依据,从而提升透明度和临床实用性。
所提框架采用最新的 YOLOv11 架构,与早期 YOLO 版本相比,在检测准确率和效率方面有显著提升。其增强的特征提取和无锚点检测机制,使其特别适用于识别胸部 X 光片中微小、低对比度的异常区域。这些能力有助于更精确地定位肺炎和 COVID-19 相关混浊区域,同时支持诊断准确性和临床可解释性。
本研究的贡献总结如下:
- 提出一种新型肺炎检测系统,结合 YOLOv11 用于实时目标检测和 Grad-CAM 用于视觉可解释性。
- 利用 Grad-CAM 生成诊断热力图,使临床医生能够可视化影响模型预测的关键区域,提升人工智能辅助决策的可解释性和可信度。
- 应用强大的预处理流程,包括基于 CLAHE 的对比度增强、感兴趣区域(ROI)提取和肺部分割,以改善特征定位并减少背景噪声。
- 基于两个公开基准数据集(COVID-19 放射影像数据库和胸部 X 光片 COVID-19 与肺炎数据集)验证所提框架,确保在多样化临床病例中的性能泛化性。
- 与最先进模型进行对比分析,在知名评估指标上表现出具有竞争力或更优的性能。
研究结构如下:第 2 节回顾肺炎检测的最新进展;第 3 节介绍所提基于 YOLO 的可解释肺炎检测框架;第 4 节详细说明模型的实验结果,并与最新相关研究进行性能对比;最后,第 5 节总结本研究的主要贡献并指出未来改进方向。
2. 文献综述
本节全面概述该领域最相关和最新的研究成果,重点关注不同模型架构、数据集、分类策略和性能指标。着重对比分析传统迁移学习、混合深度学习方法和定制设计的 CNN 在肺炎与 COVID-19 诊断中的应用。目的是明确当前方法的优势、局限性和趋势,以便更好地将所提基于 YOLO 的可解释框架置于现有研究体系中。
2.1 混合深度学习模型
结合多种架构或整合机器学习分类器与深度学习特征提取器的混合模型,因其性能提升而受到关注。Abdullah 等人 [14] 提出一种混合 CNN 模型,结合 VGG16 和 VGG19,通过平均池化实现特征融合,并使用密集神经网络进行分类。该模型在 COVID-19 放射影像数据库上训练,准确率达 92%。尽管相比单一 CNN 有改进,但存在类别不平衡和过拟合风险。Aslan 等人 [15] 将基于 ANN 的肺部分割与 8 个 CNN 模型(如 DenseNet201、ResNet50)的特征相结合,通过支持向量机(SVM)和其他机器学习算法进行分类,准确率达 96.29%。该方法虽准确,但因贝叶斯优化导致计算成本较高。Lakshmi 等人 [16] 采用贝叶斯优化的 SVM,结合 AlexNet 和 ResNet50 等模型提取的深度特征,准确率达 96.20%。尽管前景良好,但处理时间和过拟合风险限制了其实时应用。
2.2 迁移学习方法与定制 CNN 架构
利用预训练 CNN 架构的迁移学习已成为主流方法,尤其在医疗影像数据集有限的场景中。Singh 等人 [17] 和 El Houby [18] 分别使用 ResNet50 和 VGG19,准确率最高达 97%。El Houby 应用 CLAHE 和直方图均衡化等对比度增强技术,改善特征可见性。Chakravarthy 等人 [19] 使用 SEA-ResNet50 模型,在二分类任务中准确率达 97.50%,并采用可解释人工智能提升可解释性。Srinivas 等人 [20] 融合 InceptionV3 和 VGG16,准确率达 98%,但模型在未见过的数据上的鲁棒性仍不确定。研究人员还设计了针对肺炎检测任务的定制 CNN。Ullah 等人 [21] 提出 CovidDetNet,采用包含批量归一化和跨通道归一化的定制 CNN 结构,准确率达 98.40%,但受限于数据集多样性。P. Szepesi 和 L. Szilágyi [22] 优化了轻量级 CNN,通过丢弃层实现儿科肺炎检测,准确率最高达 97.76%,但模型在临床环境中的适用性仍不确定。F. Bayram 和 A. Eleyan [23] 提出一种深度学习方法,使用基于三流融合的 CNN 模型,在大型美国胸部 X 光片临床数据集上训练,准确率达 97.76%。其方法包括从灰度 X 光片、局部二值模式(LBP)和方向梯度直方图(HOG)图像中提取特征,然后拼接这些特征进行分类,并通过五折交叉验证验证有效性。
2.3 联邦学习
为在利用分布式训练的同时保护患者数据隐私,联邦学习(FL)已得到探索。Naz 等人 [24] 将联邦学习与 ResNet50 结合,在 COVID-19 放射影像数据库上,对独立同分布(IID)和非独立同分布(non-IID)数据均实现高达 98% 的准确率。然而,在大规模部署中,模型收敛和参数调优面临挑战。A. Kareem 等人 [25] 展示了联邦学习框架在数据隐私保护中的应用,支持医院和医疗机构之间的协作,利用实时数据集训练模型,同时保护隐私并实现高准确率。A. Mabrouk 等人 [26] 提出一种集成联邦学习(EFL)框架,用于胸部 X 光片肺炎检测,支持多家医院在私有数据上训练本地 CNN 模型(DenseNet、ResNet、MobileNet),形成本地集成模型,仅向中央服务器共享模型参数以聚合为全局集成模型。在胸部 X 光片数据集上的实验显示,准确率约为 96.63%,凸显了该框架在提升诊断性能的同时保护患者数据隐私的能力。
2.4 基于 YOLO 的检测模型
YOLO 架构因其实时目标检测能力而成为热门选择。Munna 等人 [27] 对比了 YOLOv3、YOLOv4 和 YOLOv6 在肺炎检测中的表现,其中 YOLOv6 性能最佳。尽管这些模型有效,但仍需进一步调优以适应临床部署。Yao [28] 通过掩码特征金字塔网络(MaskFPN)和空洞卷积增强 YOLOv3,平均精度(AP)达 83.70%,但细微病变的定位仍具挑战。Telaumbanua [29] 应用 YOLOv11 并结合标准预处理(缩放、归一化),准确率达 91.24%。该模型的优势在于灵敏度和特异度的平衡,但数据集限制影响其泛化能力。Zhao [30] 通过快速空间金字塔注意力(FASPA)机制改进 Fast-YOLO,使用超过 14,000 张重新标注的图像,模型在准确率和速度上均表现出色,这对实时场景至关重要。Xie 等人 [31] 通过整合可变形卷积网络 v2(DCNv2)和动态卷积等模块优化 YOLO 的鲁棒性,平均精度均值(mAP)达 97.80%。尽管性能优异,但可解释性被指出是其局限性。
2.5 替代技术与探索性模型
多项研究探索了替代深度学习或预处理方法以提升分类准确率。Zhang [32] 提出 NSEC-YOLO,整合自适应噪声抑制和全局感知聚合,实现最先进的准确率和推理速度。Hameed 等人 [33] 提出基于隐写术的医疗数据嵌入框架,虽不涉及分类,但凸显了基于图像的人工智能系统中的安全性考量。Das 等人 [34] 使用 U-Net 和 W-Net 进行分割和分类,F1 分数达 97.50%。该方法表现良好,但对图像质量和数据多样性敏感。Kailasam 和 Balasubramanian [35] 结合 CNN 和 YOLO 进行肺炎检测,准确率达 83%,但泛化性和可解释性仍存在问题。精确的肺部分割能增强模型对相关解剖区域的关注。Nguyen 等人 [36] 将基于 YOLOv5s 的肺部分割与 Faster R-CNN 和 YOLOv5s 结合,检测五种胸部异常。YOLOv5s 在速度和准确率上均优于 Faster R-CNN,但在小异常检测和超参数调优方面存在困难。H. M. Balaha 等人 [37] 提出一种阿基米德优化算法(AOA)引导的框架,用于医疗影像分割中的超参数优化。该方法包括四个阶段:种群初始化、适应度函数评估、种群更新和结果记录,AOA 用于优化激活函数、损失函数、优化器和批量大小等超参数。结果显示分割性能优异,R2 U-Net 2D 模型在 BUSI 数据集上准确率达 95.70%,V-Net 模型在 COVID-19 数据集上准确率达 99.20%。
文献综述揭示了几个关键趋势:混合模型和迁移学习在准确率基准中占主导地位;基于 YOLO 的模型在速度和定位方面表现突出;可解释性日益重要,尤其是在医疗应用中。然而,在实现模型泛化、实时部署和可解释性方面仍存在挑战。所提基于 YOLOv11 的框架通过结合高效目标检测与事后可解释性(Grad-CAM),解决了这些差距,提供了适用于临床的平衡解决方案。表 1 总结了与肺炎检测相关的最新研究成果。
Table 1. Summary of pneumonia detection related work.
| Ref. | Year | Dataset (# Images) | Model Used | Classification Type | Performance |
|---|---|---|---|---|---|
| [14] | 2024 | COVID-19 Radiography Database (9220 images) | Hybrid CNN (VGG16 + VGG19) + Avg Pooling | Binary | Accuracy: 92.00% |
| [31] | 2025 | Re-annotated images from MIMIC-CXR dataset (4194 images) | Fast-YOLO | Multi-class | Precision 95.20%, Recall 94.90% |
| [38] | 2020 | COVID-19 Radiography Database (5856 images) | AlexNet | Binary, 3-class, 4-class | Accuracy: 99.16%, 94.00%, 93.42% |
| [39] | 2022 | COVID-19 Radiography Database (21,000 images) | EfficientNetB1, MobileNetV2, NasNetMobile | 4-class | Accuracy: 96.13% |
| [40] | 2023 | COVID-19 Radiography Database, Chest X-ray (COVID-19 & Pneumonia), Other (25,000 images) | ResNet-50, VGG-19, AlexNet, MobileNet | Multi-center | Accuracy: 99.54%, 95.90%, 83.00% |
| [41] | 2022 | COVID-19 Radiography Database, Chest X-ray (COVID-19 & Pneumonia) (26,009 images) | CNN + ALO + NB/SVM/KNN/DT | Multi-class | Accuracy: 99.63% |
| [42] | 2024 | COVID-19 Radiography Database, Chest X-ray (COVID-19 & Pneumonia) (images) | VGG16, InceptionResNetV2, Custom CNN | Multiclass | Accuracy: 97.00%, 96.00%, 93.00% |
| [43] | 2024 | Chest X-ray (COVID-19 & Pneumonia) (6432 images) | CNN, Customized CNN (CCNN) | Multi-class | Accuracy: 95.62% |
| [44] | 2022 | Mendeley (5000 images) | U-Net, EfficientNetB1, XGBoost, RFE | Multi-class | Accuracy: 97.60% |
3. 研究方法
本节详细介绍基于 YOLOv11 和 Grad-CAM 的肺炎检测框架,整体工作流程包括图像预处理、肺区域分割、模型训练和可解释可视化。所提检测框架以 YOLOv11 架构为基础,相比 YOLOv8、YOLOv10 等前代版本进行了多项改进。YOLOv11 采用增强型骨干网络和特征金字塔(PAN-FPN)结构,能更高效地提取多尺度特征,提升对医学影像中常见的微小、低对比度病变的敏感性;同时采用无锚点检测与动态标签分配机制,减少定位误差并提高训练稳定性。高效注意力机制与解耦头设计的整合,进一步增强了特征表征能力和目标分类准确率。这些架构升级使 YOLOv11 收敛速度更快、精度更高、定位更准,特别适用于胸部 X 光片肺炎的精准可靠检测。
所提肺炎检测框架(如图 1 所示)整合了实时目标检测模型(YOLO)与可解释人工智能技术,既能准确定位受感染肺部区域,又能提供可解释性结果,为临床决策提供支持。该框架包含结构化流程,涵盖从输入图像获取到最终可解释预测的多个关键阶段。算法 1 概述了本研究中使用 YOLOv11 模型进行肺炎检测与可解释性分析的完整方法。
算法 1:基于 YOLOv11 的肺炎检测与可解释性分析
输入:胸部 X 光片图像数据集输出:分类结果与 Grad-CAM 热力图
| BEGIN 1. Dataset Selection and Preprocessing 1.1 Load Dataset Images 1.2 FOR each image in DatasetImages DO a. Apply ImageEnhancement(image) using CLAHE b. Perform LungSegmentation(image) c. Identify RegionOfInterest(image) d. Pass preprocessed image to pipeline END FOR 2. Model Training 2.1 Split the preprocessed dataset into: - TrainingSet - ValidationSet - TestSet 2.2 Apply Data Augmentation on TrainingSet 2.3 Train YOLOv11 model: Model ← TrainYOLOv11(TrainingSet, ValidationSet) 3. Model Evaluation 3.1 Evaluate TrainedModel using TestSet Results ← Evaluate(Model, TestSet) 3.2 FOR each test image in TestSet DO a. Predict class using TrainedModel b. Apply Grad-CAM to generate heatmap c. Overlay heatmap on test image END FOR 3.3 Display and Save: - Classification Results - Confusion Matrix - Grad-CAM Visualizations END |
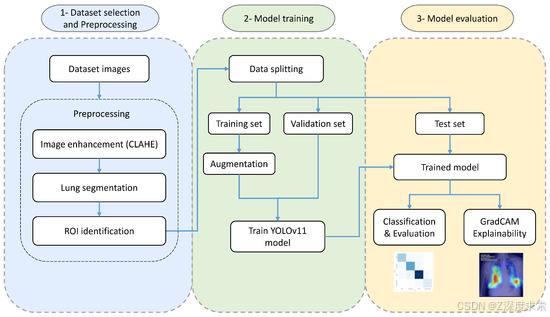
图 1.提出的肺炎检测框架。
3.1. 数据集描述
3.1.1. 数据集 1:COVID-19 射线照相数据库
3.1.2. 数据集 2:胸部 X 光检查(COVID-19 和肺炎)
3.2. 数据预处理
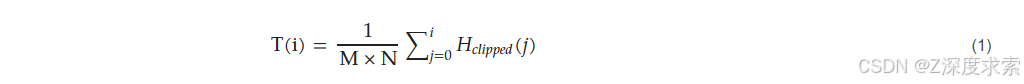
其中,M×N 为图像块的像素数量,𝐻𝑐𝑙𝑖𝑝𝑝𝑒𝑑(𝑗) 为灰度级 j 的裁剪直方图计数。为避免图像块之间出现突变,CLAHE 采用双线性插值法融合相邻图像块。该技术已被证实能有效增强磁共振成像(MRI)、计算机断层扫描(CT)和心电图(ECG)等医疗影像的可视化效果,在凸显细微特征的同时最大限度降低噪声放大。
根据所提框架,预处理流程(如图 2 所示)首先应用 CLAHE 技术,显著提升局部对比度和肺部关键特征的可见性。这种增强在放射成像中至关重要,因为细微的混浊区域可能提示病理变化。增强处理后,框架通过感兴趣区域(ROI)识别将关注焦点导向肺部区域,有效减少背景干扰。此外,通过执行肺部分割进一步分离目标解剖区域,确保后续的预测和解释严格针对肺部区域。该分割步骤也为 Grad-CAM 可视化的有效应用奠定了基础。
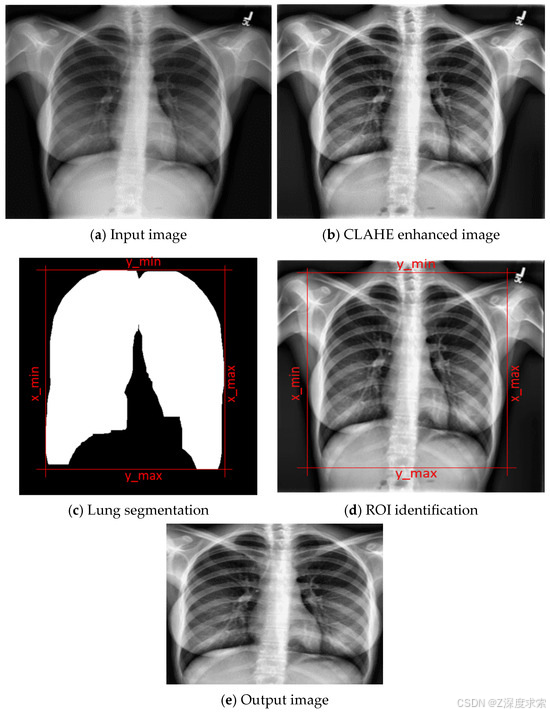
图 2.使用图像样本进行预处理步骤。
3.3. YOLOv11 模型架构
YOLOv11 模型架构代表了 YOLO 系列的高级迭代,旨在通过提高速度、准确性和特征表示来增强实时对象检测。YOLOv11 模型的架构如图 3 所示。它结合了一个精细的主干网络,用于高效的特征提取,通常建立在改进的 CSP(跨级部分)结构之上,以降低计算成本,同时保持梯度流。该模型的颈部采用 PANet(路径聚合网络)和注意力机制的组合来融合多尺度特征,有助于检测小的和重叠的物体,特别有利于医学成像任务,例如从胸部 X 射线图像检测肺炎。此外,YOLOv11 还引入了优化的无锚头,可改善边界框回归和分类性能,从而在各种物体检测基准测试中提供最先进的结果。该版本强调轻量级计算,使其适用于延迟和资源限制至关重要的医疗保健应用中的边缘部署。
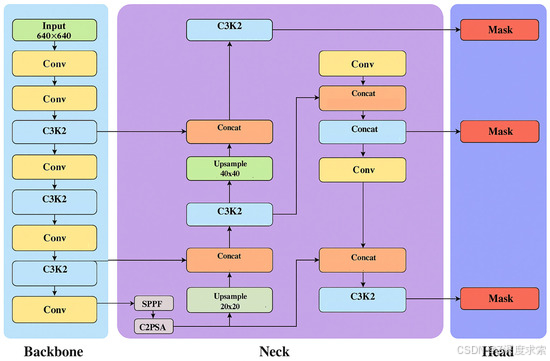
图 3.YOLOv11 架构
实验装置使用YOLOv11模型和表2中列出的参数。下表概述了在所提出的肺炎检测框架中实现YOLOv11模型的关键训练参数。该模型使用大小调整为 520 × 520 像素的图像对模型进行了 100 个纪元的训练,批量大小为 16 和三个输出类别(COVID-19、肺炎和正常)。优化器设置为自动选择最佳选项,初始学习率 (lr0) 为 0.01,动量值为 0.937,同时应用耐心参数 100 以防止过度拟合,允许在没有观察到进一步改进时提前停止。这些参数选择旨在平衡计算效率、收敛稳定性和分类性能,确保模型的鲁棒性和对实时临床应用的适用性。
Table 2. YOLOv11 model parameters used in the experiments.
| Parameter | Value |
|---|---|
| Epochs | 100 |
| Image size | 520 × 520 |
| Patience | 100 |
| Batch Size | 16 |
| Number of classes | 3 |
| Optimizer | Auto |
| Initial Learning Rate (lr0) | 0.01 |
| Momentum | 0.94 |
YOLOv11 检测框架会为每张输入图像预测一组边界框和类别概率。每个检测输出表示为向量(𝑥, 𝑦, 𝑤, ℎ, 𝑃_𝑜𝑏𝑗, 𝑃(𝑐∣𝑜𝑏𝑗)),其中(𝑥, 𝑦)代表边界框的中心坐标,𝑤和ℎ分别表示边界框的宽度和高度,𝑃_𝑜𝑏𝑗是目标置信度(用于指示该边界框包含目标的概率),𝑃(𝑐∣𝑜𝑏𝑗) 是条件类别概率。各类别的最终检测置信度计算公式为:𝑃_𝑜𝑏𝑗 × 𝑃(𝑐∣𝑜𝑏𝑗)。
用于优化 YOLOv11 模型的总损失函数𝐿是一个多组件目标函数,旨在联合最小化定位误差、目标置信度误差和分类误差,其表达式如下:
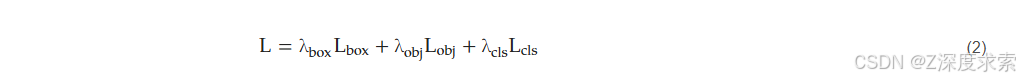

3.4 用于 YOLOv11 模型可解释性的 Grad-CAM 方法
梯度加权类激活映射(Grad-CAM)是一种广泛应用的可解释人工智能方法,用于对卷积神经网络的预测结果进行视觉解释。其工作原理是将目标输出的梯度反向追溯至最后一个卷积层,生成热力图以突出对预测最具影响力的图像区域。与早期方法不同,Grad-CAM 无需修改卷积神经网络的结构即可应用,因此适用于多种模型。这一特性在医学影像分析中尤为实用 —— 例如在胸部 X 光片肺炎检测中,明确诊断的依据能增强人们对系统决策的信任。热力图提供了直观且与空间对齐的洞察,帮助临床医生和研究人员确认网络关注的是具有医学意义的特征,而非无关模式 [50]。
Grad-CAM 的价值不仅体现在技术层面,更在于其能让人工智能预测结果更清晰易懂。通过将热力图叠加在胸部 X 光片上,它能直观地标示出引导 YOLOv11 模型做出决策的具体肺部区域。例如,在肺炎病例中,热力图突出的区域通常与实变或磨玻璃样混浊等典型征象对应,表明模型关注的是临床相关特征,而非无关背景细节。这种透明度能帮助放射科医生快速判断人工智能的推理是否与自身观察一致。由此,Grad-CAM 将模型从 “黑箱” 转变为辅助诊断的合作伙伴 —— 既建立了信任,又促进了临床应用,同时降低了依赖无解释预测的风险。
3.5 模型评估指标
模型评估指标是衡量机器学习和深度学习模型有效性的关键,在分类任务中尤为重要。最常用的指标包括准确率、精确率和召回率(或灵敏度)。这些指标通常基于混淆矩阵推导得出,混淆矩阵会将预测结果汇总为真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)四类 [51]。
精确率(Precision):该指标量化了在所有被预测为阳性的样本中,实际为阳性的比例。它反映了模型阳性预测的可靠性,这在医学诊断中至关重要,可最大限度减少假阳性警报。高精确率意味着假阳性的可能性更低,其数学表达式为:


![]()
| Predicted Positive | Predicted Negative | |
| Actual Positive | TP | FN |
| Actual Negative | FP | TN |
该矩阵作为计算关键评估指标(例如精度、召回率、F1 分数和准确性)的基础,从而提供对模型性能和诊断可靠性的整体评估。
4. 结果与讨论
本节介绍了所提出的基于YOLOv11的可解释的肺炎检测框架的实验结果,并使用两个基准胸部X射线数据集评估了其性能。评估包括对两个数据集中每个诊断类别的分类准确性、精确度、召回率和F1分数的详细分析。此外,该部分还展示了可视化结果,包括预测样本、混淆矩阵和基于Grad-CAM的解释,以展示模型的诊断能力和可解释性。还提供了与现有最先进方法的比较分析,以突出所提出框架的相对优势和独特贡献。
4.1. 实验设置
使用第 3.1 节中描述的预处理数据集进行模型训练和评估。如前所述,每个数据集都已经划分为训练、验证和测试子集,确保按比例的类表示和拆分之间的严格分离。所有图像的大小都调整为 320 × 320 像素,以与 YOLOv11 的输入尺寸保持一致。应用随机旋转和亮度调整等数据增强方法来提高泛化性并减少过拟合。模型训练是在 Kaggle 环境中执行的,使用 NVIDIA Tesla P100 GPU 和 16 GB 内存。性能评估基于标准指标,包括准确度、精确度、召回率、F1 分数和混淆矩阵,在每个训练时期后的测试集上计算。
4.2. 使用数据集1的实验结果
在 COVID-19 放射线照相数据库上进行训练和测试后,所提出的基于 YOLOv11 的肺炎检测模型在所有三个类别(COVID-19、正常和肺炎)中都取得了出色的性能。图 4 说明了模型的学习行为,训练和验证损失在连续的时期稳步下降,训练准确性持续提高,表明有效收敛,没有过度拟合的迹象。图5中的混淆矩阵证实了高分类准确性,只有少数错误分类,每个类别的敏感性和特异性都很强。图 6 中的可视化示例进一步验证了这些结果,显示了真实标签(图 a)和模型预测(图 b)之间的密切匹配。不同胸部 X 光样本的高度一致性凸显了该框架在准确区分 COVID-19、正常和肺炎病例方面的可靠性和稳健性。
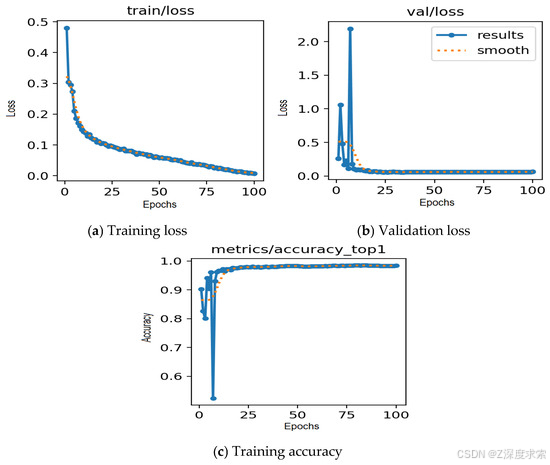
图 4.数据集 1 的模型性能。
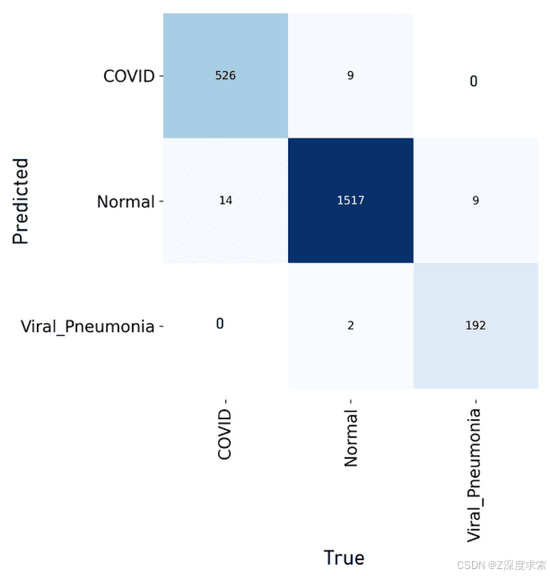
图 5.使用数据集1对所提模型进行混淆矩阵
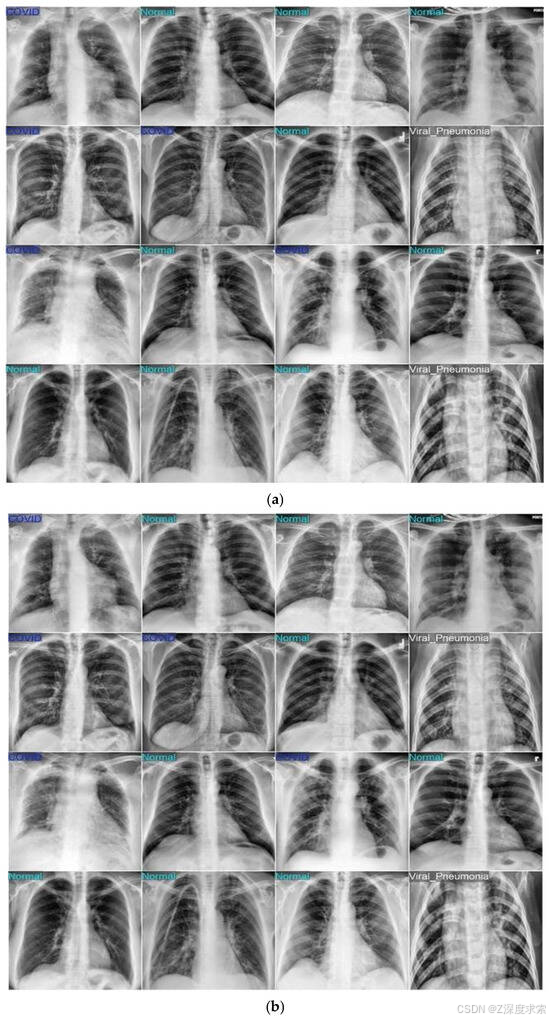
图6.使用数据集 1、(a) True 标签和 (b) 预测标签的模型预测样本
表 3 总结了基于YOLOv11的模型在COVID-19射线照相数据集上进行测试时的分类结果。该框架在所有三个类别(COVID-19、正常和肺炎)中都表现出一致的强劲结果,基于准确性、精确度、召回率和 F1 分数。具体来说,COVID-19 的准确率达到 98.98%,正常的准确率达到 98.50%,肺炎的准确率达到 99.52%。每个类别的准确率都高于 98%,而召回率从 COVID-19 的 97.41% 到肺炎的 99.28% 不等。F1 分数也显示出稳定性,值为 97.86%(COVID-19)、98.89%(正常)和 97.22%(肺炎)。宏观平均时,该框架实现了 98.96% 的准确率、98.60% 的准确率、97.40% 的召回率和 97.99% 的 F1 分数,证实了可靠和平衡的性能。图 7 直观地展示了模型如何做出决策,使用 Grad-CAM 为每个类别的胸部 X 射线样本生成热图。在每个示例中,原始图像(顶行)与 Grad-CAM 热图(底行)配对,其中较暖的颜色标记了该地区对预测影响最大的颜色。这些突出显示的肺部区域与已知的病理模式非常匹配,表明该模型的注意力集中在临床相关区域。表 3 中的可靠数值结果和图 7 中清晰的视觉解释不仅证明了基于 YOLOv11 的框架的准确性,而且证明了其透明度,使其成为可靠和可解释的临床使用的有前途的工具。
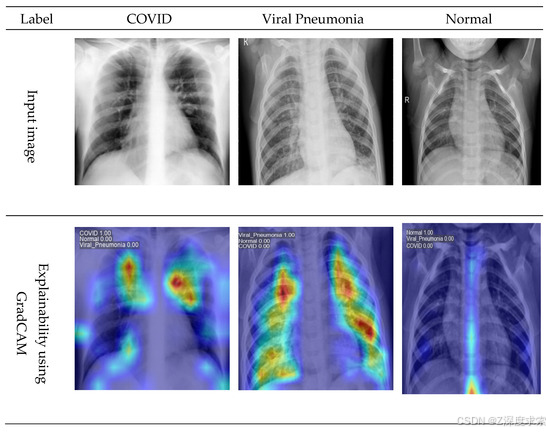
图7.使用 Grad-CAM 进行模型可解释性后数据集 1 中的样本
Table 3. The performance metrics of the proposed model using the first dataset.
| Class | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| VID | 98.98% | 98.32% | 97.41% | 97.86% |
| Normal | 98.50% | 98.51% | 99.28% | 98.89% |
| Pneumonia | 99.52% | 98.97% | 95.52% | 97.22% |
| Macro average | 98.50% | 98.60% | 97.40% | 97.99% |
4.3. 使用数据集2的实验结果
使用第二个数据集(胸部 X 光、COVID-19 和肺炎),所提出的 YOLOv11 框架在所有三个类别中都取得了一致的强劲成果。图 8a-c 显示了训练行为,其中训练和验证损失均稳步下降,准确率在稳定之前迅速升至 98% 以上,表明有效收敛,没有过度拟合的证据。图 9 中的混淆矩阵仅突出显示了少量错误分类:20 次正常扫描预测为肺炎,5 例肺炎病例被归类为正常,以及一张肺炎图像被错误标记为 COVID-19。这表明了明显的类别分离,特别是对于 COVID-19,它达到了近乎完美的准确性。图 10 进一步说明了这种可靠性,因为预测的标签与地面实况注释非常匹配,差异最小。
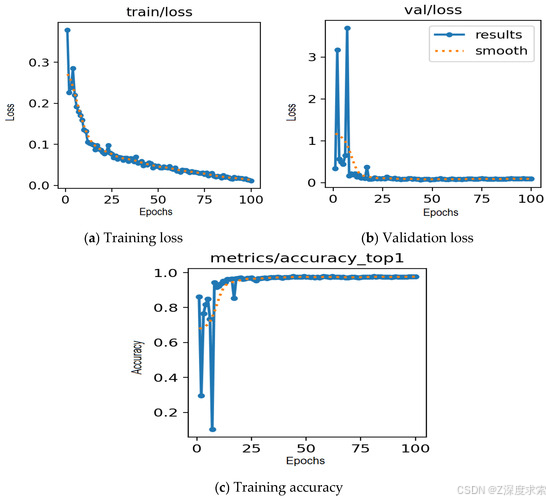
图8.使用数据集 2 的模型性能
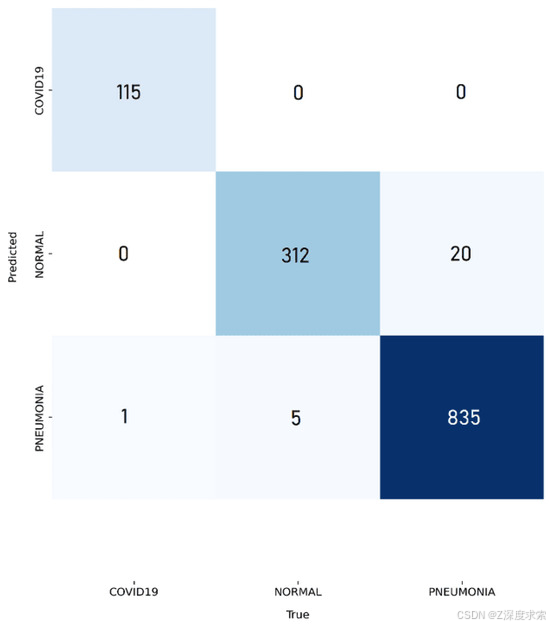
图 9.使用数据集 2 的所提模型的混淆矩阵
Table 4. The performance metrics of the proposed model using the second dataset.
| Class | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| COVID | 99.92% | 100% | 99.14% | 99.57% |
| Normal | 98.06% | 93.98% | 98.42% | 96.15% |
| Pneumonia | 97.98% | 99.29% | 97.66% | 98.45% |
| Macro average | 98% | 97.76% | 98.41% | 98.06% |
图 11 显示了对第二个数据集中代表性样本的基于 Grad-CAM 的视觉解释,涵盖 COVID-19、肺炎和正常病例。对于每个示例,原始胸部 X 射线图像与其相应的 Grad-CAM 热图一起显示,其中较暖的颜色表示对模型决策影响较大的区域。突出显示的肺部区域与已知的病理模式密切相关,证实该框架在做出预测时侧重于临床相关区域。这种可解释性增强了对模型输出的信任,并强调了其作为透明且可靠的临床使用工具的潜力。
4.4. 与最近相关工作的比较绩效评估
有必要根据现有的最先进方法评估基于YOLOv11的肺炎检测框架,以证明其临床潜力和相对优势。表 5 报告了与 COVID-19 射线照相数据集上的几个高级模型的比较,使用四个关键性能指标:准确度、精确度、召回率和 F1 分数。在该基准数据集中,所提出的YOLOv11系统实现了98.56%的宏观平均准确率、98.6%的准确率、97.45%的召回率和97.99%的F1分数。这些结果使其成为表现最好的方法之一,并凸显了其在肺炎和 COVID-19 分类任务中的竞争力。它明显优于混合DL + ML方法[14](92%准确率)、VGG19[18](93.38%准确率)和CNN[23](97.76%准确率)等模型。即使是像 Inception V3 与 VGG16 [20] 这样的高级组合,在所有指标上都达到了 98%,也略低于或与 YOLOv11 持平。基于YOLO的方法,如YOLOv3与MaskFPN [28]和Fast-YOLO [31],表现出了混合的性能。Yao 改进的 YOLOv3 在 RSNA 数据集上仅达到了 81% 的准确率,而 Fast-YOLO 则达到了较强的精度 (95.20%) 和召回率 (94.90%)。
Table 5. Performance evaluation against some related work.
| Ref. | Dataset | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|---|
| [14] | COVID-19 Radiography dataset | hybrid DL + ML | 92% | 93% | 92% | 92% |
| [15] | COVID-19 Radiography dataset | DenseNet201 + SVM | 96.29% | 96.42% | 96.42% | 94.53% |
| [16] | COVID-19 Radiography dataset | ResNet50 + SVM | 96.20% | - | - | - |
| [17] | Labeled Optical Coherence Tomography (OCT) and Chest X-Ray Images for Classification + Chest X-Ray Images (Pneumonia) | Adopted-CNN and ResNet50 | 97% | - | - | - |
| [18] | COVID-19 Radiography dataset | VGG19 | 93.38% | 94.12% | 96% | 95.05% |
| [20] | COVID-19 Radiography dataset | Inception V3 with VGG16 | 98% | 98% | 98% | 98% |
| [21] | COVID-19 Radiography dataset | DL + SVM | 98.40% | 97% | 96.66% | 96.82% |
| [23] | COVID-19 Radiography dataset | CNN | 97.76% | 97.78% | 97.76% | 97.76% |
| [24] | COVID-19 Radiography dataset | Federated Learning (FL) | 98% | 98% | 98% | 98% |
| [28] | RSNA dataset | Yolov3 with MaskFPN | 81% | - | - | - |
| [31] | Re-annotated images from MIMIC-CXR dataset | Fast-YOLO | - | 95.20% | 94.90% | - |
| Proposed | COVID-19 Radiography dataset | YOLOv11 | 98.50% | 98.60% | 97.45% | 97.99% |
| Chest X-ray (COVID-19 & Pneumonia) | YOLOv11 | 98% | 97.76% | 98.41% | 98.06% |
所提出的框架的一个主要优点是它能够执行实时对象检测,从而在不牺牲准确性的情况下实现快速诊断支持。此外,Grad-CAM 的结合提供了可比模型通常缺乏的可解释性组件,从而增强了用户信心,并使该方法更适合透明度至关重要的临床环境。在胸部 X 射线 COVID-19 和肺炎数据集上评估时,该系统还表现出很强的泛化性,保持了 98% 准确率、97.76% 准确率、98.41% 召回率和 98.06% F1 分数的高性能。在不同分布的数据集中取得一致的结果证明了基于YOLOv11的方法的稳健性和适应性。
4.5. 讨论
这些发现共同证明了拟议的基于YOLOv11的肺炎检测框架的有效性和临床前景,同时也指出了未来需要改进的领域。在两个基准数据集上,该模型在 COVID-19 射线照相数据集上达到了 98.50% 的宏观平均准确率,在胸部 X 射线 COVID-19 和肺炎数据集上达到了 98%。这些持续的高值证实了该框架识别严重肺部异常的强大能力,展示了最先进方法之间的竞争性能。这种方法的显着优势之一是集成了 Grad-CAM,它通过突出显示对模型预测影响最大的肺部区域来增强可解释性。
图 7 和图 11 所示的热图提供了清晰的视觉证据,补充了数字指标,提供了对模型决策的直接洞察。对于肺炎和 COVID-19 图像,Grad-CAM 突出显示了与典型病理体征相对应的区域,例如实变、浸润和磨玻璃样混浊。相比之下,正常的胸片仅显示肺野内的激活很少,这表明该模型侧重于医学上有意义的特征,而不是不相关的图像模式。这种行为建立了具有临床意义的基线,证实该框架侧重于医学相关区域而不是虚假图像伪影。总的来说,这些视觉解释支持诊断输出的有效性,并加强了临床对框架适用性的信任。这不仅提高了透明度,还建立了临床信任,因为放射科医生可以直观地验证人工智能的推理。CLAHE 和肺分割等预处理步骤进一步提高了模型的焦点和鲁棒性,而 YOLOv11 架构允许以较低的计算要求进行实时检测,这是在资源有限的环境中部署的一个重要功能。
这项工作并非没有局限性。使用的数据集虽然可靠,但涵盖了有限范围的患者人口统计和影像学变异,这可能会影响模型对不同临床环境的泛化程度。此外,Grad-CAM 的有用性取决于模型本身的准确性——如果模型错误,突出显示的区域可能会产生误导。尽管如此,总体研究结果表明,该框架是一种有效、高效且可解释的自动肺炎检测方法,通过更多样化的数据集和跨医院和成像系统的更广泛测试,具有进一步改进的明显潜力。
为了确保公平的比较,本研究中复制的所有基线模型都使用与所提出的YOLOv11框架相同的数据拆分、预处理和增强程序进行训练和评估。这种一致的设置保证了性能的差异反映了模型的能力,而不是数据或处理偏差。对于以前发表的原始数据或代码不可用的方法,报告的结果仅作为指示性比较,因为在相同的实验设置下不可能进行精确复制。由于缺乏外部研究的预测级输出,没有应用AUC的DeLong等统计测试;然而,在多个指标上的一致改进证明了所提出模型的稳健性和可靠性。
4.6. 临床意义和实际意义
该框架的临床意义不仅仅是高精度分数。实时性能、高诊断精度和可解释输出的结合使所提出的系统成为医疗保健环境中实用且有价值的工具,特别是那些资源有限的环境。实时准确检测和定位肺炎的能力可以显着缩短从成像到诊断的时间,从而实现早期治疗并有可能改善患者的预后。在接触经验丰富的放射科医生的机会有限的情况下,该自动化系统可以提供可靠的第二意见或作为初步筛查工具来优先考虑危重病例。集成的 Grad-CAM 可视化是临床信任和验证的关键,因为它们使医疗保健专业人员能够直观地确认模型的预测是基于医学上合理的证据,从而促进人工智能在临床实践中的更大接受度。该框架的稳健性在两个不同的公共数据集上得到了证明,表明其具有广泛、有效部署的潜力,以应对肺炎带来的全球健康挑战。
为了进一步提高所提出框架的泛化性和鲁棒性,未来的工作可能会整合鲁棒特征学习和弹性信号重建的概念。最近关于复杂场景解析和光场图像水印的研究已经证明了在嘈杂或失真的环境中保持特征稳定性和信号完整性的有效策略[52,53]。结合这些方法可以增强所提出的模型对非高斯噪声的适应性及其对多维医学成像场景的适用性。
5. 结论
肺炎仍然是一个严重的全球健康挑战,特别是在儿童和老年人等弱势群体中,快速准确的诊断可以挽救生命。传统的诊断方法虽然有价值,但经常面临实际挑战——从主观解释到获得放射科医生专家的机会有限,以及无法在资源有限的地区提供即时结果。本研究引入了一种新的、可解释的肺炎检测框架,该框架将 YOLOv11 的实时物体检测能力与 Grad-CAM 可视化相结合,以提高可解释性。该系统不仅具有很高的检测精度,而且还能精确定位受感染的肺部区域,为临床医生提供清晰、直观的预测解释。在两个基准数据集上进行了测试,该框架的性能始终优于或与领先的方法相匹配,展示了准确性和稳健性。展望未来,通过整合额外的医疗数据(例如 CT 扫描或患者记录),将其调整为在移动或边缘设备上用于现场诊断,以及探索联合学习以保护医院之间的隐私协作,该方法可以变得更加通用。虽然这项工作侧重于肺炎,但相同的框架可以扩展到检测和区分其他胸部疾病,例如结核病或肺癌,使其成为全面胸部疾病筛查的有力工具。未来的工作可以侧重于扩展模型以检测多种胸部疾病,整合临床和多模态数据,使用先进的 XAI 方法增强可解释性,验证更大和多样化数据集的性能。