分布式专题——52 ElasticSearch自定义分词需求实战
1 分词器概述
- 分词是构建倒排索引的重要环节,倒排索引是信息检索等领域的关键技术,用于快速查找包含特定关键词的文档;
- 分词的分类维度:
- 按语言环境分:英文分词、中文分词等;
- 按实现方式分:标准分词器、空格分词器、停用词分词器等;
- 自定义分词器的场景:当传统分词器无法解决特定业务场景的问题时,需要自定义分词器来满足个性化需求。
1.1 认识分词
-
英文分词的特点:英语单词之间以空格或标点隔开,因此相对容易辨认和区分。例:
- 原句:
you cannot use from and size to page through more than 10,000 hits - 分词后:
you / cannot / use / from / and / size / to / page / through / more / than / 10,000 / hits
- 原句:
-
中文分词的特点:中文在单词、句子、段落之间没有空格,且存在“同样的字在不同句子中可拆解为不同组合”的现象,因此中文分词更具挑战性。例(“杭州市长春药店”):
-
错误分词:
杭州 / 市长 / 春药 / 店(语义错误,违背正常表达逻辑) -
正确分词:
杭州市 / 长春 / 药店(符合地理名称“杭州市”、地名“长春”、行业“药店”的语义逻辑)
-
1.2 为什么需要分词
-
中文分词是自然语言处理的基础,搜索引擎进行中文分词主要源于以下3个维度的原因:
-
语义维度:单字大多无法完整表达语义,而词往往能传递明确语义。分词作为预处理步骤,能让后续语义相关的分析(如语义理解、情感分析等)更准确;
-
存储维度:若所有文章按“单字”建立索引,所需的存储空间和搜索计算时间会大幅增加;按“词”索引可有效压缩存储和计算成本;
-
时间维度:借助倒排索引,分词后能以O(1)的时间复杂度(几乎是常数级时间),通过词组快速定位到对应文章,极大提升检索效率;
-
-
以“深入浅出Elasticsearch”检索为例
-
若以单字(如“深”“入”“浅”“出”)为索引:这些字在内容中出现次数极多,需添加无数条索引记录,检索效率极低;
-
若以词(如“深入”“浅出”)为索引:所需记录数显著减少;
-
若以短语(如“深入浅出”“Elasticsearch”)为索引:记录数更少,最终仅需匹配少量完全符合的文档,精准定位目标结果;
-
-
在 Elasticsearch 中设计索引的 Mapping 时,需根据业务用途确定是否分词:
-
若不需要分词(如精确匹配场景),建议设置字段类型为
keyword; -
若需要分词(如全文检索场景),建议设置为
text类型并指定分词器。
-
1.3 分词发生的阶段
1.3.1 写入数据阶段
-
分词发生在数据写入阶段(即数据索引化阶段),其分词逻辑由映射参数
analyzer决定; -
示例(基于 Elasticsearch 的
ik_max_word分词器):对文本“昨天,小明和他的朋友们去了市中心的图书馆”执行分词,通过POST _analyzeAPI 调用,指定analyzer: "ik_max_word"和待分词文本,返回的分词结果包含以下字段:token:分词后的词汇(如“昨天”“小明”“和他”“的”“朋友们”“去了”“市中心”“图书馆”等);start_offset/end_offset:词汇在原文本中的起始/结束位置(如“昨天”对应 0-2);type:词汇类型(如“CN_WORD”表示中文词汇,“CN_CHAR”表示中文单字);position:词汇在分词结果中的顺序位置(从 0 开始计数);
POST _analyze {"analyzer":"ik_max_word","text":"昨天,小明和他的朋友们去了市中心的图书馆" }// 返回结果: {"tokens": [{"token": "昨天","start_offset": 0,"end_offset": 2,"type": "CN_WORD","position": 0},{"token": "小明","start_offset": 3,"end_offset": 5,"type": "CN_WORD","position": 1},{"token": "和他","start_offset": 5,"end_offset": 7,"type": "CN_WORD","position": 2},{"token": "的","start_offset": 7,"end_offset": 8,"type": "CN_CHAR","position": 3},{"token": "朋友们","start_offset": 8,"end_offset": 11,"type": "CN_WORD","position": 4},{"token": "去了","start_offset": 11,"end_offset": 13,"type": "CN_WORD","position": 5},{"token": "市中心","start_offset": 13,"end_offset": 16,"type": "CN_WORD","position": 6},{"token": "的","start_offset": 16,"end_offset": 17,"type": "CN_CHAR","position": 7},{"token": "图书馆","start_offset": 17,"end_offset": 20,"type": "CN_WORD","position": 8}] }
1.3.2 执行检索阶段
-
分词发生在搜索发生时期,仅对搜索词产生作用;
-
以“图书馆”检索为例,基于 Elasticsearch 的倒排索引和
ik_smart分词器:- 数据索引化过程:文档“昨天,小明和他的朋友们去了市中心的图书馆”写入时,通过
ik_smart分词器分词为“昨天/小明/和他/的/朋友们/去了/市中心/的/图书馆”,并构建倒排索引存入 Elasticsearch; - 检索过程:执行“图书馆”检索时,
ik_smart分词器先对搜索词“图书馆”分词,再根据倒排索引查找所有包含“图书馆”的文档,完成检索匹配;
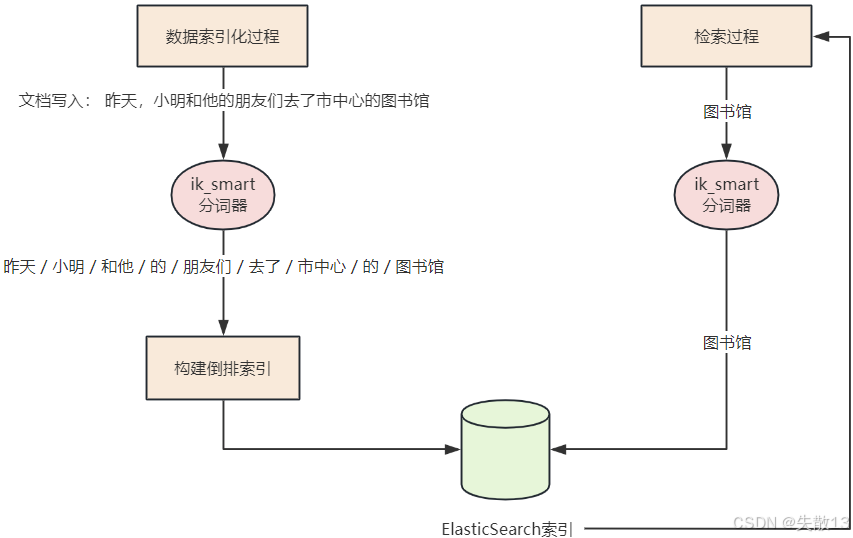
- 数据索引化过程:文档“昨天,小明和他的朋友们去了市中心的图书馆”写入时,通过
2 分词器的组成
-
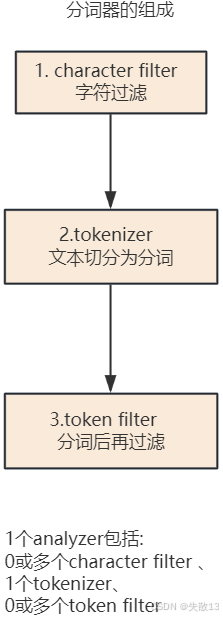
在 Elasticsearch 中,文档写入并转换为倒排索引前的“分析”操作由**分词器(analyzer)**实现,分词器由三部分组成:
-
character filter(字符过滤):分词前的预处理环节,过滤无用字符;
-
tokenizer(文本切分为分词):核心的分词切割环节,将文本切分为单个分词;
-
token filter(分词后再过滤):对已切分的分词进行后续过滤处理;
-
-
组成规则:1个
analyzer包含 0或多个 character filter、1个 tokenizer、0或多个 token filter。
2.1 字符过滤器(Character Filter)
- 字符过滤器以字符流为输入,通过添加、删除或修改字符来转换字符流,作用是分词前的预处理,过滤无用字符。其分类及说明如下。
2.1.1 HTML Strip Character Filter
- 作用:删除HTML元素(如
<b>标签),并解码HTML实体(如将&转义为&); - 示例(Elasticsearch API 配置):
PUT test_html_strip_filter {"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "html_strip", // 使用 HTML 标签过滤器"escaped_tags": ["a"] // 保留 <a> 标签,其他HTML标签删除}}}} }GET test_html_strip_filter/_analyze {"tokenizer": "standard","char_filter": ["my_char_filter"],"text": ["<p>I'm so <a>happy</a>!</p>"] }
2.1.2 Mapping Character Filter
- 作用:替换指定的字符(按映射规则等价替换);
- 示例(Elasticsearch API 配置):
PUT test_html_strip_filter {"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "mapping", // 使用字符映射过滤器"mappings": ["滚 => *", "垃 => *", "圾 => *"] // 将指定字符替换为*}}}} }GET test_html_strip_filter/_analyze {"char_filter": ["my_char_filter"],"text": "你就是个垃圾!滚" }
2.1.3 Pattern Replace Character Filter
- 作用:基于正则表达式替换指定的字符,支持更灵活的字符替换规则;
- 示例(Elasticsearch API 配置,以隐藏手机号中间四位为例):
PUT text_pattern_replace_filter {"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "pattern_replace", // 使用正则替换过滤器"pattern": "\"(\\d{3})\\d{4}(\\d{4})\"", // 正则匹配手机号格式(3位+4位+4位)"replacement": "$1****$2" // 替换为“前3位+****+后4位”}}}} }GET text_pattern_replace_filter/_analyze {"char_filter": ["my_char_filter"],"text": "您的手机号是18868686688" }
2.2 切词器(Tokenizer)
-
切词器(Tokenizer)负责初步进行文本分词。其处理逻辑为:
-
若已进行字符过滤,接收过滤后的字符流;若未进行字符过滤,接收原始字符流;
-
分词后会记录分词的顺序/位置(position)、起始值(start_offset)、偏移量(end_offset - start_offset);
-
Elasticsearch 官方内置多种切词器,默认切词器为 standard;
-
-
内置切词器分类(名称+用途)
分词器名称 分词器用途 Whitespace Analyzer 基于空格字符分词,不将词汇转为小写 Simple Analyzer 按照“非字母”切分(符号会被过滤),并对词汇进行小写处理 Stop Analyzer 在 Simple Analyzer 的基础上,额外移除停用词(如“的”“了”“a”“an”等无实义词汇) Keyword Analyzer 不进行切词,将输入的整个字符串作为一个分词返回(适用于精确匹配场景) Pattern Analyzer 基于正则表达式分词,默认使用 \W+(非字符分隔)规则进行切分Language 提供适用于 30 多种常见语言的分词器(针对不同语言的语法、词汇特点做适配)
2.3 词项过滤器(Token Filter)
-
词项过滤器用于处理切词完成后的词项,例如大小写转换、删除停用词、同义词处理等。Elasticsearch 官方预置了多种词项过滤器,也支持第三方或自定义开发。示例(大小写转换,将文本转为大写):
GET _analyze {"tokenizer": "standard","filter": ["uppercase"],"text": ["www.elastic.org.cn", "www elastic org cn"] }
2.3.1 停用词
-
停用词是切词完成后会被过滤掉的无实义词项,支持自定义;
-
英文停用词(english):
a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, such, that, the, their, then, there, these, they, this, to, was, will, with等; -
中日韩停用词(cjk):
a, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, s, such, t, that, the, their, then, there, these, they, this, to, was, will, with, www等;
-
-
例:内置停用词过滤,结果中“are”“you”等停用词会被过滤
GET _analyze {"tokenizer": "standard","filter": ["stop"],"text": ["What are you doing"] } -
例:自定义停用词过滤,结果中“www”“WWW”会被过滤
DELETE test_token_filter_stop PUT test_token_filter_stop {"settings": {"analysis": {"filter": {"my_filter": {"type": "stop","stopwords": ["www"],"ignore_case": true // 忽略大小写}}}} }GET test_token_filter_stop/_analyze {"tokenizer": "standard","filter": ["my_filter"],"text": ["What www WWW are you doing"] }
2.3.2 同义词处理
-
同义词处理用于将语义等价的词项进行关联,支持两种定义规则:
-
规则1:
a, b, c => d→a、b、c会被d代替。 -
规则2:
a, b, c, d→a、b、c、d是等价的。
-
-
同义词处理示例:结果中“good”会被替换为“excellent”
PUT test_token_filter_synonym {"settings": {"analysis": {"filter": {"my_synonym": {"type": "synonym","synonyms": ["good, nice => excellent"] // good、nice 被 excellent 代替}}}} }GET test_token_filter_synonym/_analyze {"tokenizer": "standard","filter": ["my_synonym"],"text": ["good"] }
2.4 练习
-
业务需求背景:存在一个作者字段(如
Li,Leilei;Han,MeiMei、Leilei,Li;MeiMei,Han等格式),需要对其进行精确匹配。若直接使用默认分词逻辑,会出现检索失效的情况(如检索lileilei查不出数据),因此需要自定义分词器来满足业务需求;POST /booksdemo/_bulk {"index":{"_id":1}} {"name":"Li,LeiLei;Han,MeiMei"} {"index":{"_id":2}} {"name": "LeiLei,Li;MeiMei,Han"}// 查不出数据 POST /booksdemo/_search {"query": {"match": {"name": "lileilei"}} } -
自定义分词器通过
character filter、tokenizer、token filter三个环节协同实现,具体配置如下:DELETE /booksdemo PUT /booksdemo {"settings": {"analysis": {"char_filter": { // 字符过滤器"my_char_filter": {"type": "mapping", // 映射过滤(mapping 类型),将字符“,”过滤掉(配置 “,” => “”)// 作用:预处理作者字段中的逗号,统一文本格式"mappings": [", => "]}},"tokenizer": { // 切词器"my_tokenizer": {"type": "pattern", // 自定义分词分隔符(pattern 类型),将“;”作为分词分隔符(配置 pattern: ";")// 作用:按分号将作者字段切分为多个分词单元"pattern": """\;"""}},"filter": { // 词项过滤器"my_synonym_filter": {"type": "synonym", // 同义词过滤(synonym 类型)"expand": true,"synonyms": [ // 添加同义词词组。作用:建立语义等价关系,支持不同写法的作者名精确匹配"leileili => lileilei","meimeihan => hanmeimei"]}},"analyzer": { // 自定义分词器 my_analyzer 整合上述组件"my_analyzer": {"tokenizer": "my_tokenizer", // 指定切词器"char_filter": [ // 指定字符过滤器"my_char_filter"],"filter": [ // 包含小写转换和同义词过滤"lowercase","my_synonym_filter"]}}}},"mappings": {"properties": {"name": { // 将 name 字段的类型设为 text,并指定分词器为 my_analyzer,确保写入和检索时使用自定义分词逻辑"type": "text","analyzer": "my_analyzer"}}} } -
测试:
// 验证分词结果:调用 _analyze API,分别对文本“Li,Leilei;Han,MeiMei”和“Leilei,Li;MeiMei,Han”进行分词,确认自定义分词逻辑(过滤逗号、按分号切分、同义词转换)生效 POST booksdemo/_analyze {"analyzer": "my_analyzer","text": "Li,LeiLei;Han,MeiMei" }POST booksdemo/_analyze {"analyzer": "my_analyzer","text": "LeiLei,Li;MeiMei,Han" }// 通过 _bulk API 写入两条测试数据 POST /booksdemo/_bulk {"index":{"_id":1}} {"name":"Li,LeiLei;Han,MeiMei"} {"index":{"_id":2}} {"name": "LeiLei,Li;MeiMei,Han"}// 执行检索 match: {name: "lileilei"},验证自定义分词器支持的同义词转换和精确匹配逻辑,确保能正确检索到目标文档 POST /booksdemo/_search {"query": {"match": {"name": "lileilei"}} }
3 Ngram 自定义分词实战
3.1 需求背景
-
当对
keyword类型的字段进行高亮查询时,若字段值为类似123asd456的字符串,查询子串(如s04)会导致整个字段串被高亮(如<em>123asd456</em>),但业务需求是仅对匹配的子串高亮(如只高亮s04); -
概括问题:明明只想查询字符串的一部分,却高亮整个字符串,如何解决?
3.2 解决方案分析
-
定义索引
my_index_phone,其中phoneNum字段类型为keyword:PUT my_index_phone {"mappings": {"properties": {"phoneNum": {"type": "keyword"}}} } -
批量写入测试数据:
POST my_index_phone/_bulk {"index":{"_id":1}} {"phoneNum":"13611112222"} {"index":{"_id":2}} {"phoneNum":"13944248474"} -
执行包含高亮的模糊检索,查询
phoneNum中以1111开头的记录:POST my_index_phone/_search {"highlight": {"fields": {"phoneNum": {}}},"query": {"bool": {"should": [{"wildcard": {"phoneNum": "1111*"}}]}} } -
高亮结果为
<em>13611112222</em>,即整个手机号字符串被高亮,而非仅匹配的1111子串;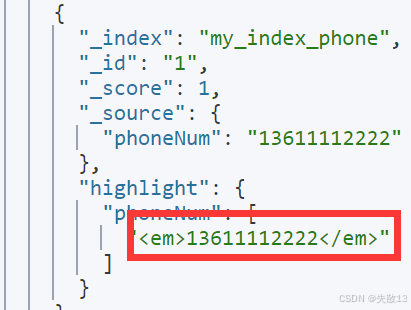
- 原因分析:
-
wildcard查询(类似 SQL 的like模糊匹配)解决了子串匹配的问题,但无法实现“子串局部高亮”; -
传统
text类型的标准分词器(如中文 ik 分词器、英文 english 分词器等)也无法解决该“子串匹配+局部高亮”的需求;
-
- 原因分析:
-
业务需求是**“输入子串能召回全串 + 检索的子串实现局部高亮”**,因此需要更换分词策略——Ngram 分词来实现。
3.3 Ngram 分词实战
3.3.1 Ngram分词定义
-
Ngram是一种基于统计语言模型的算法,核心思想是对文本进行滑动窗口操作,生成长度为
N的字节片段序列(每个片段称为gram)。通过统计gram的出现频度并过滤,形成文本的向量特征空间; -
其假设是:第
N个词的出现仅与前面N-1个词相关,整句概率为各词出现概率的乘积,这些概率可通过语料统计得到。常用的有Bi-Gram(二元语法)和Tri-Gram(三元语法)。
3.3.2 Ngram分词示例与应用场景
- 示例:以中文句子“你今天吃饭了吗”为例,其Bi-Gram分词结果为“你今”“今天”“天吃”“吃饭”“饭了”“了吗”;
- 应用场景:
- 场景1:文本压缩、拼写错误检查、字符串查找加速、文献语种识别;
- 场景2:自然语言处理自动化领域(自动分类、自动索引、超链自动生成、文献检索、无分隔符语言文本切分等);
- 场景3:Elasticsearch检索优化,针对无分隔符文本(如手机号)分词,提升检索效率(优于wildcard和正则匹配检索)。
3.3.3 实战
-
索引与分词器配置
DELETE my_index_phone PUT my_index_phone {"settings": {"number_of_shards": 1,"number_of_replicas": 0,"index_max_ngram_diff": 10,"analysis": {"analyzer": {"phoneNo_analyzer": {"tokenizer": "phoneNo_analyzer"}},"tokenizer": {"phoneNo_analyzer": {"type": "ngram","min_gram": 4, // 最小分词长度。默认1"max_gram": 11, // 最大分词长度。默认2"token_chars": ["letter", "digit"] // 指定分词结果包含的字符类型。此处保留字母和数字类型字符}}}},"mappings": {"dynamic": "strict","properties": {"phoneNo": {"type": "text","analyzer": "phoneNo_analyzer" // 字段指定自定义Ngram分词器}}} } -
批量写入测试数据
POST my_index_phone/_bulk {"index":{"_id":1}} {"phoneNo":"13611112222"} {"index":{"_id":2}} {"phoneNo":"13944248474"} -
分词结果验证(通过analyzer API)
POST my_index_phone/_analyze {"analyzer": "phoneNo_analyzer","text": "13611112222" }-
结果中会生成包含
"1111"的分词片段,验证Ngram分词对手机号子串的切分生效;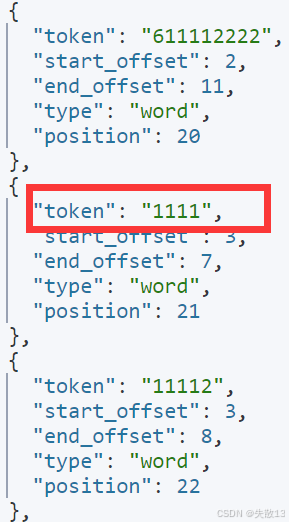
-
-
检索与高亮验证
POST my_index_phone/_search {"highlight": {"fields": {"phoneNo": {}}},"query": {"bool": {"should": [{"match_phrase": {"phoneNo": "1111"}}]}} }-
返回结果中高亮片段为
"136<em>1111</em>2222",实现了子串局部高亮,完美解决了“仅对匹配子串高亮”的业务需求;
-