【Kafka全攻略】Kafka从入门到实战:核心概念+实操配置+故障排查全攻略
目录
- 开篇:为什么Kafka成为分布式消息队列首选?
- 一、基础核心概念:3张图搞懂Broker、Topic与分区
- 二、分区策略选型:轮询vs按key,30秒选对不踩坑
- 三、重平衡机制:90%开发者踩过的坑与避坑指南
- 四、高可用核心:副本同步与ISR机制(数据不丢的关键)
- 五、性能调优:3个核心参数提升10倍吞吐量(直接抄作业)
- 六、故障排查:分区leader选举失败紧急恢复+永久避坑
- 核心知识点总结(1页表格)
- 问题快速索引(按场景检索)
- 互动答疑:你的Kafka踩坑经历分享
开篇:为什么Kafka成为分布式消息队列首选?
在分布式系统中,消息队列是“解耦、削峰、异步通信”的核心组件,而Kafka凭借高吞吐量、高可用、低延迟的特性,成为互联网、金融、电商等行业的首选——支持每秒10万级消息传输,单机可处理TB级数据,还能通过副本机制实现数据零丢失。
但很多开发者入门Kafka时,会被Broker、分区、ISR、重平衡等概念绕晕,实操中又会遇到消息乱序、吞吐量上不去、leader选举失败等问题。
本文整合6个核心主题,从基础概念到实战配置,再到故障排查,形成完整知识体系,无论是新手入门还是老手避坑,都能直接参考使用。
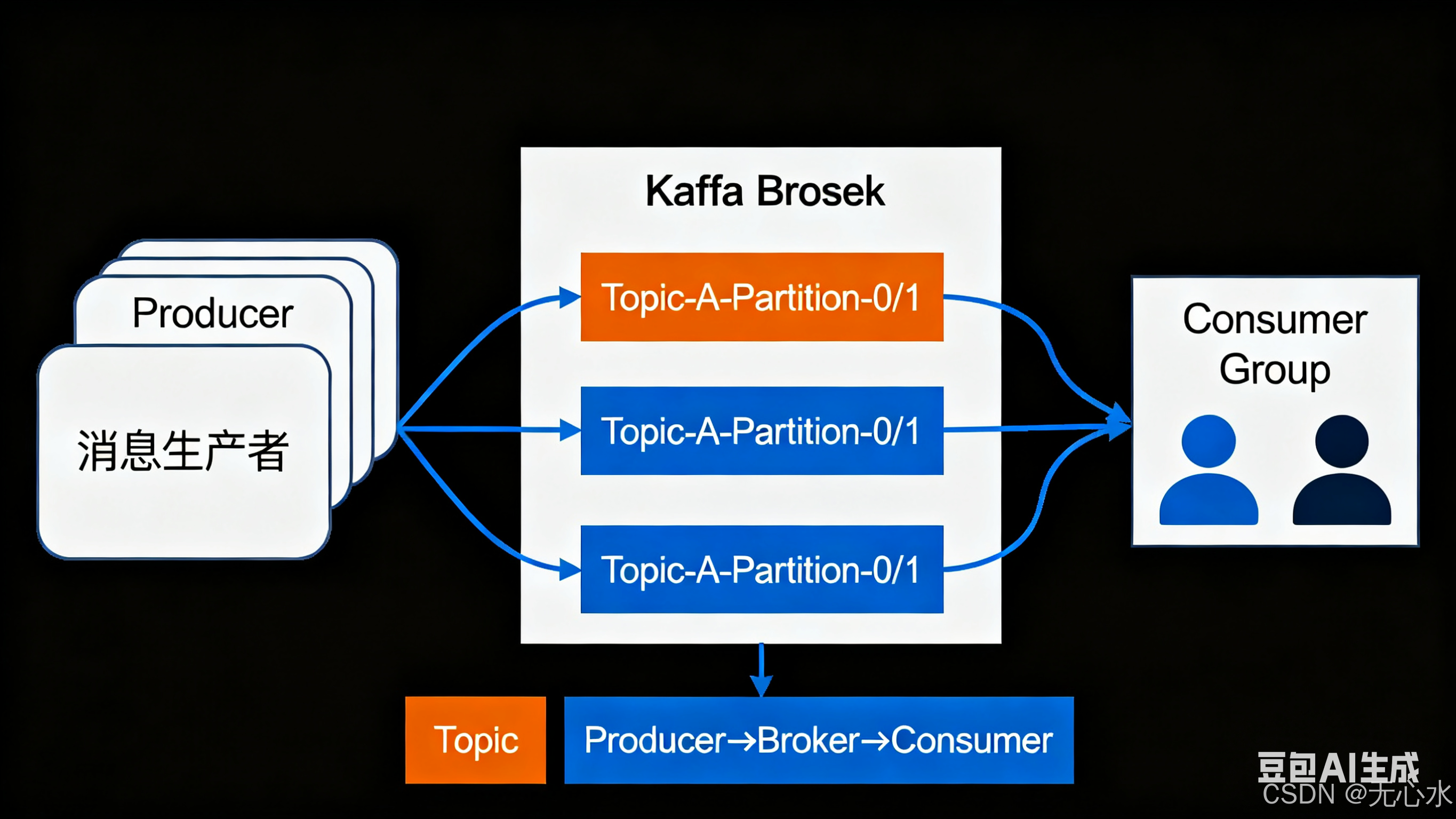
一、基础核心概念:3张图搞懂Broker、Topic与分区
刚接触Kafka的开发者,往往会被“Broker、Topic、分区”这三个基础组件搞混淆——其实它们是Kafka的“物理存储+逻辑分类+并行单元”核心架构,用通俗比喻+可视化图示,5分钟就能彻底理解。
1.1 Broker:Kafka的“快递网点”(物理存储节点)
- 通俗比喻:Broker就像小区周边的快递网点,负责接收、存储和转发“快递”(消息),是Kafka集群的物理基础。
- 核心定义:一台运行Kafka服务的服务器(物理机/虚拟机),集群中每个Broker有唯一编号(0、1、2…),生产环境建议部署3台以上保证高可用。
- 图示说明(文字可视化):
[Kafka集群]├─ Broker 0(服务器A):存储Topic1的部分分区、Topic2的部分分区├─ Broker 1(服务器B):存储Topic1的部分分区、Topic3的部分分区└─ Broker 2(服务器C):存储Topic2的部分分区、Topic3的部分分区 - 关键作用:接收生产者消息并写入磁盘、响应消费者请求、集群内数据同步(副本机制)。
1.2 Topic:Kafka的“快递分类筐”(逻辑消息类别)
- 通俗比喻:Topic就像快递网点的分类筐,按“业务类型”将消息分类,比如“电商订单筐”“物流轨迹筐”,避免不同业务消息混淆。
- 核心定义:消息的逻辑分类容器,生产者发送消息必须指定Topic,消费者消费必须订阅Topic,Topic本身不存储消息,实际存储在分区中。
- 图示说明(文字可视化):
[Kafka集群]├─ Topic:order-topic(订单消息)→ 关联3个分区├─ Topic:log-topic(日志消息)→ 关联2个分区└─ Topic:user-topic(用户消息)→ 关联4个分区 - 关键作用:实现业务隔离、支持按需订阅,分区数可根据业务吞吐量动态配置。
1.3 分区(Partition):Topic的“筐内格子”(并行存储单元)
- 通俗比喻:分区就像分类筐里的小格子,将一个Topic拆分成多个并行单元,既方便存储,又能多人同时分拣(提升处理效率)。
- 核心定义:Kafka最小的并行存储和处理单元,每个Topic可分1个或多个分区,每个分区对应Broker上的一个日志文件(.log),同一分区内消息严格FIFO有序,不同分区无全局顺序。
- 图示说明(文字可视化):
[Topic:order-topic(订单消息)]├─ 分区0 → 存储消息:msg1、msg4、msg7(Broker 0上)├─ 分区1 → 存储消息:msg2、msg5、msg8(Broker 1上)└─ 分区2 → 存储消息:msg3、msg6、msg9(Broker 2上) - 关键作用:提升并行处理能力、实现负载均衡、支持水平扩展(消息量增长时增加分区数)。
1.4 三者核心关系总结
| 组件 | 本质 | 核心作用 | 通俗对应 |
|---|---|---|---|
| Broker | 物理服务器(Kafka节点) | 存储和转发消息 | 快递网点 |
| Topic | 逻辑消息分类 | 隔离不同业务消息 | 快递分类筐 |
| 分区 | 最小并行存储单元 | 提升吞吐量、负载均衡 | 筐内小格子 |
搞懂了Broker、Topic、分区的基础关系,接下来核心问题就是——生产者发送消息时,如何将消息分配到不同分区?这就需要用到Kafka的“分区策略”,选对策略能避免消息乱序、热点分区等问题。
二、分区策略选型:轮询vs按key,30秒选对不踩坑
Kafka的分区策略直接决定消息的存储位置和处理效率——90%的消息乱序、负载不均问题,都源于策略选错。最常用的两种策略:轮询(默认)和按key分区,用原理+代码+场景对比,帮你快速决策。
2.1 轮询策略(Round-Robin):像“发扑克牌”一样平均分
- 通俗理解:消息按顺序依次分配到各个分区,每个分区轮流接收消息,实现绝对负载均衡。
- 实操表现(3个分区为例):
消息1 → 分区0 | 消息2 → 分区1 | 消息3 → 分区2 | 消息4 → 分区0... - 代码示例(默认策略,无需额外配置):
Properties props = new Properties(); props.put("bootstrap.servers", "broker0:9092,broker1:9092"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props); // 不指定key,触发轮询策略 producer.send(new ProducerRecord<>("log-topic", null, "用户A登录")); producer.send(new ProducerRecord<>("log-topic", null, "用户B下单")); - 优点:负载绝对均衡、零配置上手;缺点:同一类消息分散(如同一用户操作消息分到不同分区,无法保证顺序)。
- 适用场景:日志收集、监控数据等无顺序需求的场景。
2.2 按key分区(Key-Based):像“按部门归档”一样归类
- 通俗理解:按消息的key(如用户ID、订单号)做哈希计算(
hash(key) % 分区数),同一key的消息必然分到同一个分区,保证顺序性。 - 实操原理(3个分区为例):
key=用户A → hash(A)=100 → 100%3=1 → 分区1 key=用户A → 同一分区 → 分区1 key=用户B → hash(B)=200 → 200%3=2 → 分区2 - 代码示例(指定key即可触发):
// 发送消息时指定key(用户ID) producer.send(new ProducerRecord<>("order-topic", "user100", "用户100下单")); producer.send(new ProducerRecord<>("order-topic", "user100", "用户100支付")); // 同分区 - 优点:同一key消息绝对有序、支持按key聚合;缺点:可能出现热点分区(某key消息量过大导致分区积压)。
- 适用场景:订单流程、用户操作轨迹等有顺序需求的场景。
2.3 两种策略关键对比表
| 维度 | 轮询策略(无key) | 按key分区(有key) |
|---|---|---|
| 负载均衡 | ✅ 优秀(绝对平均) | ⚠️ 可能失衡(依赖key分布) |
| 消息顺序 | ❌ 同一类消息无序 | ✅ 同一key消息有序 |
| 适用场景 | 日志、监控等无顺序需求场景 | 订单、用户轨迹等有顺序需求场景 |
| 配置难度 | ✅ 零配置(默认) | ⚠️ 需要合理设计key |
| 典型问题 | 无法保证同类消息顺序 | 热点分区(需优化key) |
2.4 实操避坑:按key分区如何避免热点?
- 热点key“加盐”:在key后拼接随机数(如“爆款商品ID_123”),分散到多个分区;
- 提前预估key分布:热点key单独创建Topic并增加分区数;
- 全局顺序需求:只能用“单分区Topic”(牺牲并行能力,谨慎使用)。
解决了消息分配问题,接下来看消费端的核心机制——消费者组如何分配分区?这就不得不提“重平衡”,它是消费端最容易出问题的环节,90%的消费堆积、重复消费都和它有关。
三、重平衡机制:90%开发者踩过的坑与避坑指南
生产环境中,消费者组突然消费堆积、消息重复消费,大概率是“重平衡”在搞鬼。重平衡是Kafka消费者组的分区重新分配机制,看似自动优化,实则藏着不少坑,今天讲透原理、触发条件和避坑配置。
3.1 重平衡(Rebalance)本质:消费者组的“分工调整”
- 通俗比喻:消费者组是“团队”,分区是“任务”,重平衡就是团队人数变化(消费者加入/退出)或任务变化(分区增加)时,重新分配任务的过程,确保每个分区只被一个消费者消费。
- 核心定义:当消费者组内消费者数量、Topic分区数变化,或消费者心跳超时,Kafka会自动将分区重新分配给存活的消费者,保证消费唯一性。
3.2 触发重平衡的3个常见场景
- 消费者上下线:消费者进程崩溃、网络中断(退出),或新增消费者实例(扩容);
- Topic分区数增加:手动扩容Topic分区,消费者组需重新分配新增分区;
- 消费者心跳超时:消费者处理消息耗时过长,超过
session.timeout.ms(默认10秒),被判定为“死亡”。
3.3 重平衡的3个致命坑
- 消费暂停:重平衡期间所有消费者暂停消费,消息堆积(如10秒暂停=10万条堆积);
- 重复消费:消费者未提交offset就触发重平衡,新消费者从上次offset重新消费;
- 频繁触发:消费者频繁崩溃或心跳超时,反复重平衡拖垮集群。
3.4 重平衡核心流程(3步)
- 选协调者(Group Coordinator):从Broker中选一个“团队经理”,管理消费者组状态;
- 报名阶段(Join Group):所有存活消费者向协调者报名,选出1个leader消费者;
- 分工阶段(Sync Group):leader制定分区分配方案,协调者同步给所有消费者,恢复消费。
3.5 5个避坑配置(直接抄)
Properties props = new Properties();
// 1. 会话超时:设为30秒(默认10秒,留足处理时间)
props.put("session.timeout.ms", 30000);
// 2. 心跳间隔:设为5秒(建议是session.timeout的1/3~1/5)
props.put("heartbeat.interval.ms", 5000);
// 3. 每次拉取消息数:避免一次拉太多导致处理超时
props.put("max.poll.records", 100);
// 4. 开启静态成员:减少重启导致的重平衡(Kafka 2.3+支持)
props.put("group.instance.id", "consumer-1-instance-001");
// 5. 耗时任务异步处理:主线程快速提交offset
消费端稳定后,生产端最核心的需求就是“数据不丢”。Kafka如何保证Broker宕机后消息不丢失?答案是“副本同步”和“ISR机制”——这是Kafka高可用的核心基石。
四、高可用核心:副本同步与ISR机制(数据不丢的关键)
生产环境中Broker宕机,Kafka能秒级切换且消息不丢,全靠“副本同步”和“ISR机制”。副本是消息的冗余备份,ISR是“合格备份组”,两者配合能实现数据零丢失,今天讲透原理、流程和实操配置。
4.1 副本(Replica):Kafka的“消息备份”
- 通俗比喻:副本就像电脑里的文件备份,原文件(leader副本)存在C盘,备份(follower副本)存在D盘,C盘崩了D盘能直接用。
- 核心定义:
- 每个分区可配置1个或多个副本(生产环境建议3个);
- leader副本:主副本,处理读写请求,1个分区仅1个;
- follower副本:从副本,同步leader消息,1个分区可多个;
- 副本分散在不同Broker,避免单Broker宕机丢数据。
- 图示说明(文字可视化):
[Topic:order-topic → 分区0]├─ Broker0:leader副本(主副本,处理读写)├─ Broker1:follower副本(从副本,同步数据)└─ Broker2:follower副本(从副本,同步数据) - 关键作用:数据冗余、故障转移、分担读压力(部分场景)。
4.2 ISR机制:Kafka的“合格备份组”
- 通俗比喻:ISR(In-Sync Replicas)是“合格备份人员组”,只有能及时跟上leader节奏的副本,才在组里;跟不上的(数据落后太多)会被移出。
- 核心定义:
- ISR是与leader数据同步的副本集合(包含leader本身);
- follower需在
replica.lag.time.max.ms(默认10秒)内同步leader数据,否则移出ISR(进入OSR未同步集合); - leader选举仅从ISR中选择,确保数据一致性。
- 图示说明(文字可视化):
[分区0的ISR集合]├─ leader(Broker0):必在ISR中├─ follower1(Broker1):同步及时 → 在ISR中└─ follower2(Broker2):落后超10秒 → 移出ISR(OSR)
4.3 核心流程:副本同步+ISR动态调整
4.3.1 副本同步3步走
- 生产者发送消息到leader副本;
- leader写入本地日志,向所有follower发送同步通知;
- follower拉取消息并写入本地,返回“同步成功”确认。
4.3.2 ISR动态调整规则
- 同步及时→留在ISR;
- 超时未同步→移出ISR;
- 重新跟上节奏→重新加入ISR;
- 特殊情况:ISR为空时,开启
unclean.leader.election.enable(默认false)可从OSR选leader(可能丢数据,不推荐)。
4.4 高可用实操配置(直接抄)
4.4.1 创建Topic时指定副本数
# 3个分区,每个分区3个副本(生产环境推荐)
kafka-topics.sh --bootstrap-server broker0:9092,broker1:9092,broker2:9092 \--create --topic order-topic --partitions 3 --replication-factor 3
4.4.2 Broker全局配置
# 1. follower同步超时时间(默认10秒,调至30秒)
replica.lag.time.max.ms=30000
# 2. 禁止从OSR选leader(避免丢数据)
unclean.leader.election.enable=false
# 3. 最小同步副本数(配合acks=all)
min.insync.replicas=2
4.4.3 生产者配置(确保消息不丢)
props.put("acks", "all"); // 消息需被ISR所有副本确认
props.put("retries", 3); // 失败重试3次
4.5 常见问题:配置了副本还丢数据?
- 副本数太少(仅1个):Broker宕机直接丢数据;
- 开启
unclean.leader.election.enable=true:从OSR选leader导致数据不一致; - 生产者
acks≠all:消息仅写入leader就返回成功; min.insync.replicas=1:ISR只剩leader,宕机后新leader可能缺数据。
保证了数据不丢,接下来就是性能优化——Kafka默认配置的吞吐量较低,如何用最少的配置改动,实现吞吐量10倍提升?核心就是3个参数:批量发送、数据压缩、分区并行。
五、性能调优:3个核心参数提升10倍吞吐量(直接抄作业)
Kafka吞吐量上不去、延迟高,不用急着加机器!90%的性能问题都是参数没调好——批量发送、数据压缩、分区并行,这3个核心参数能直接将吞吐量从1万RPS冲到10万RPS,延迟控制在毫秒级,新手也能直接抄。
5.1 调优核心逻辑:找准瓶颈
Kafka性能瓶颈本质是3个:
- 网络请求频繁(每条消息单独发,浪费带宽);
- 数据体积大(未压缩,占用IO资源);
- 并行能力不足(分区太少,线程忙不过来)。
5.2 参数1:batch.size(批量发送)——“快递凑单发货”
- 通俗比喻:快递员凑够一车再送货,减少跑趟次数。
batch.size是生产者凑单阈值,攒够指定大小再批量发送。 - 实操配置:
props.put("batch.size", 163840); // 160KB(默认16KB) props.put("linger.ms", 5); // 最多等5ms,没凑够也发(避免延迟) - 注意事项:消息越大,
batch.size可适当调大(如1MB),但别超过1MB;实时性要求高的场景,linger.ms设1-5ms。
5.3 参数2:compression.type(数据压缩)——“文件压缩省空间”
- 通俗比喻:将大文件压缩成ZIP包传输,减少体积和传输时间。
- 实操配置:
props.put("compression.type", "lz4"); // 首选lz4(速度+压缩比平衡) - 压缩算法对比表:
| 算法 | 压缩比 | 压缩速度 | 适用场景 |
|------|--------|----------|----------|
| none | 1:1 | 最快 | 消息体<1KB |
| gzip | 1:4 | 较慢 | 离线日志归档 |
| snappy | 1:3 | 较快 | 常规实时场景 |
| lz4 | 1:3.5 | 最快 | 实时性+吞吐量双要求(首选) | - 注意事项:压缩和解压CPU开销<5%,可忽略;消费者自动解压,对业务透明。
5.4 参数3:Topic分区数(partitions)——“多开窗口办业务”
- 通俗比喻:银行多开窗口提升办理效率,分区数是Kafka并行处理的核心。
- 实操配置(创建Topic时指定):
# 10个分区(推荐分区数=消费者数×2) kafka-topics.sh --bootstrap-server broker0:9092,broker1:9092,broker2:9092 \--create --topic order-topic --partitions 10 --replication-factor 3 - 分区数估算公式:
推荐分区数 = 目标吞吐量 ÷ 单分区最大吞吐量- 单分区最大吞吐量:生产者1-2万RPS,消费者2-3万RPS;
- 例:目标5万RPS → 5万÷1万=5个(乘2留扩容空间,设10个)。
- 注意事项:单Topic分区数建议≤100,过多会增加Broker元数据压力;分区数≥消费者数(避免消费者空闲)。
5.5 调优前后数据对比
| 指标 | 调优前(默认参数) | 调优后(3个核心参数) |
|---|---|---|
| 吞吐量 | 1.2万 RPS | 12.5万 RPS(提升10倍) |
| 消息延迟 | 10-20ms | 1-3ms(降低80%) |
| 网络带宽占用 | 100MB/s | 25MB/s(降低75%) |
| 磁盘存储占用 | 100GB/天 | 28GB/天(降低72%) |
5.6 辅助优化配置(锦上添花)
// 生产者:增大缓冲区(默认32MB→64MB)
props.put("buffer.memory", 67108864);
// 消费者:每次拉取更多消息(默认500→2000条)
props.put("max.poll.records", 2000);
// Broker:批量刷盘(默认5秒)
log.flush.interval.ms=5000
5.7 调优避坑指南
- 别盲目调大
batch.size:超过2MB会导致延迟显著增加; - 别选gzip算法:实时场景下压缩速度太慢;
- 别让分区数远超消费者数:导致单个消费者处理过多分区,效率下降;
- 调优后监控:关注“批量发送率”(≥80%)、“压缩率”(≥70%)。
调优完成后,还需应对突发故障——Kafka最致命的故障之一是“分区leader选举失败”,一旦发生会导致分区读写不可用,业务直接受影响。接下来讲如何紧急恢复+永久避坑。
六、故障排查:分区leader选举失败紧急恢复+永久避坑
生产环境突发“Leader Not Available”报错,生产者发消息超时、消费者消费停滞,大概率是“分区leader选举失败”。这是Kafka集群最致命的故障,今天讲透原因、3步紧急恢复,还有永久避坑的配置,遇到问题直接照做。
6.1 故障本质:“群龙无首”的分区
- 通俗比喻:分区leader是“主心骨”,原leader宕机后,没人能从ISR(合格备份组)中当选新主心骨,导致分区读写不可用。
- 故障表现:
- 日志报错:
Leader election failed for partition [order-topic,0] due to no in-sync replicas available; - 命令查询:
kafka-topics.sh --describe --topic order-topic显示“Leader: -1”“Isr: []”; - 业务影响:生产者超时、消费者停滞。
- 日志报错:
6.2 选举失败的3个核心原因
- ISR集合为空:所有follower因同步滞后被移出ISR,仅leader自己,宕机后无合格备份;
- ISR中follower全不可用:副本集中在少数Broker,这些Broker同时宕机;
- 配置不当:开启
unclean.leader.election.enable=true,或副本数太少(仅1个)。
6.3 3步紧急恢复(先让业务跑起来)
第一步:定位问题(查看状态)
# 1. 查看Topic分区状态(重点看Leader、Isr列)
kafka-topics.sh --bootstrap-server broker0:9092,broker1:9092,broker2:9092 --describe --topic order-topic# 2. 检查Broker是否存活
kafka-broker-api-versions.sh --bootstrap-server broker0:9092 # 超时则宕机
- 结果判断:ISR为空→第二步;follower Broker宕机→先重启Broker→第三步。
第二步:紧急手动选举(ISR为空时慎用)
临时开启unclean选举(允许从OSR选leader),恢复后立即关闭:
# 1. 临时修改Broker配置(所有Broker)
echo "unclean.leader.election.enable=true" >> server.properties
# 2. 重启Broker
kafka-server-stop.sh && kafka-server-start.sh -daemon server.properties
# 3. 手动触发选举
kafka-leader-election.sh --bootstrap-server broker0:9092 --topic order-topic --partition 0 --election-type UNCLEAN
- 风险提示:可能丢数据,仅紧急场景使用,恢复后关闭该配置。
第三步:正常场景选举(ISR有可用follower)
# 触发指定分区优先选举(无数据丢失)
kafka-leader-election.sh --bootstrap-server broker0:9092 --topic order-topic --partition 0 --election-type PREFERRED# 或触发整个Topic选举
kafka-leader-election.sh --bootstrap-server broker0:9092 --topic order-topic --all-partitions --election-type PREFERRED
6.4 永久避坑:核心优化配置
# 1. 禁止unclean选举(强制保持默认false)
unclean.leader.election.enable=false
# 2. 延长同步超时时间(30秒)
replica.lag.time.max.ms=30000
# 3. 最小同步副本数=2
min.insync.replicas=2
# 4. 副本数≥3(创建Topic时指定replication-factor=3)
6.5 副本分布优化(避免单点风险)
- 同一分区的副本必须分散在不同Broker/机架;
- 校验命令:
kafka-topics.sh --describe --topic order-topic --bootstrap-server broker0:9092 | grep -E "Leader|Replica",确保副本分布在不同Broker。
6.6 监控预警配置
- 监控ISR状态:ISR中副本数<
min.insync.replicas时报警; - 监控Broker存活:宕机数≥副本数-1时紧急预警;
- 监控同步滞后:follower与leader消息差距超1000条时报警。
到这里,Kafka从基础概念、实操配置到故障排查的核心内容已全部覆盖。下面用1张表格总结所有核心知识点,再附上“问题快速索引”,方便后续遇到问题直接检索。
七、核心知识点总结(1页表格)
| 主题 | 核心组件/参数 | 关键结论 | 实操建议 |
|---|---|---|---|
| 基础概念 | Broker/Topic/分区 | 物理存储+逻辑分类+并行单元 | Broker≥3台,Topic分区数按吞吐量估算 |
| 分区策略 | 轮询/按key | 无顺序需求选轮询,有顺序需求选按key | 热点key加盐优化 |
| 重平衡 | session.timeout.ms/group.instance.id | 避免频繁触发,留足处理时间 | 设30秒超时,开启静态成员 |
| 高可用 | 副本/ISR/acks=all | 副本≥3+ISR监控+acks=all=数据不丢 | 禁止unclean选举,min.insync.replicas=2 |
| 性能调优 | batch.size/compression.type/分区数 | lz4压缩+160KB批量+分区数=消费者数×2 | 避免盲目调大参数,关注监控指标 |
| 故障排查 | leader选举失败 | 优先用PREFERRED选举,紧急场景临时开启UNCLEAN | 副本分散部署,监控ISR和Broker存活状态 |
八、问题快速索引(按场景检索)
| 遇到的问题 | 对应解决方案章节 |
|---|---|
| 不懂Broker/Topic/分区关系 | 一、基础核心概念 |
| 消息乱序、热点分区 | 二、分区策略选型 |
| 消费堆积、重复消费 | 三、重平衡机制避坑 |
| Kafka丢数据 | 四、副本同步与ISR机制 |
| 吞吐量低、延迟高 | 五、性能调优3个核心参数 |
| Leader Not Available报错 | 六、分区leader选举失败排查 |
| 分区分配不均 | 二、分区策略+六、副本分布优化 |
九、互动答疑:你的Kafka踩坑经历分享
本文覆盖了Kafka从入门到实战的核心知识点,无论是基础概念、实操配置,还是故障排查,都能直接落地使用。
你在使用Kafka时遇到过哪些问题?是消息乱序、吞吐量上不去,还是故障排查无从下手?欢迎在评论区分享你的踩坑经历和解决方案,我会逐一回复并补充到文章中,帮助更多开发者避坑!