【每天一个知识点】CAG:Context-Augmented Generation
🧩 一、CAG:Context-Augmented Generation(上下文增强生成)
核心思想:
通过“外部或结构化上下文”的显式引入,提升大模型生成的语义准确性、连贯性与可控性。
它是对传统 RAG(Retrieval-Augmented Generation) 的扩展,关注的不只是“检索文本”,而是“如何高质量地组织、选择与利用上下文”。
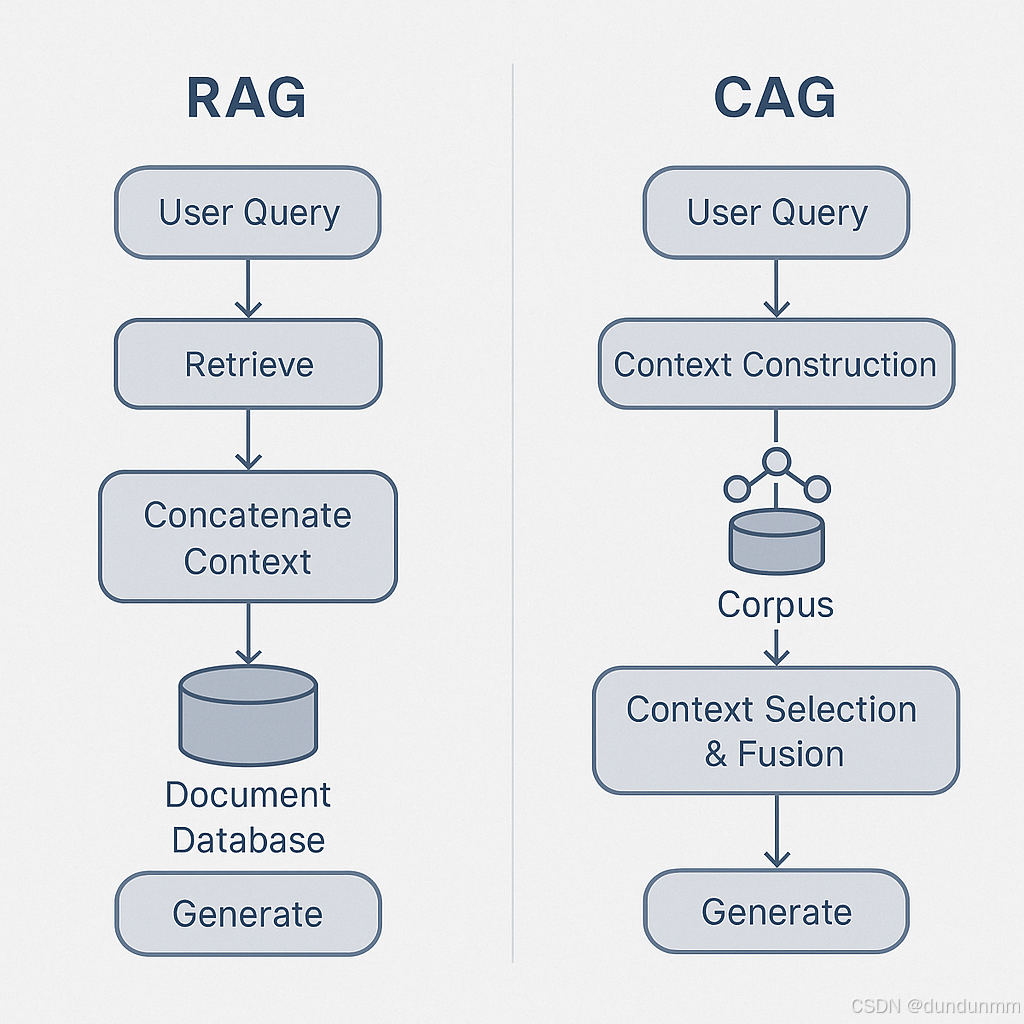
🔹 核心流程
User Query → Context Construction → Context Selection & Fusion → LLM Generate
🔹 上下文来源
-
🔸 检索式上下文(RAG)
从知识库检索相似内容; -
🔸 聚类式上下文(Clustering-CAG)
对知识库进行聚类或主题归纳; -
🔸 图式上下文(Graph-CAG)
利用知识图谱构造关联上下文; -
🔸 语义记忆上下文(Memory-CAG)
使用长期记忆结构动态提取上下文; -
🔸 对话上下文(Dialog-CAG)
在多轮交互中复用历史语境。
⚙️ 二、RAG vs. CAG:从检索增强到上下文增强
| 对比项 | RAG | CAG (Context-Augmented) |
|---|---|---|
| 增强维度 | 检索增强(Retrieval) | 上下文增强(Context) |
| 核心目标 | 引入外部知识,提高事实正确性 | 引入多类型上下文,提高生成一致性与推理深度 |
| 输入形式 | Query + 检索到的Top-K文档 | Query + 聚合后的多源上下文(文本、图、摘要等) |
| 典型机制 | 向量检索 + 拼接 | 上下文构建 + 筛选 + 融合(可含聚类、摘要、权重) |
| 适用场景 | QA、知识问答、事实型任务 | 复杂问答、决策推理、多轮对话、专业领域生成 |
| 上下文组织 | 扁平式(无结构) | 结构化(聚类、图谱、主题记忆) |
| 代表模型 | OpenAI RAG, LlamaIndex, LangChain RAG | GraphRAG, ClusterRAG, Dynamic-Memory RAG, Context-Tuning |
🧠 三、CAG 的关键增强技术
| 技术方向 | 功能说明 |
|---|---|
| 上下文聚类 (Context Clustering) | 对知识库聚类,生成主题级上下文(CAG的早期变体) |
| 上下文摘要 (Context Summarization) | 对相似文档进行压缩摘要,减少冗余与token占用 |
| 上下文选择 (Context Selection) | 利用注意力或重排序模型筛选最相关上下文 |
| 上下文融合 (Context Fusion) | 将多源上下文(文档、图谱、记忆)融合成统一输入 |
| 上下文记忆 (Context Memory) | 动态保存生成历史和用户意图,实现长程依赖 |
📊 四、关系总结图
┌──────────────┐│ RAG (Retrieval) │ → 检索增强└──────────────┘↓ 演化┌──────────────────────┐│ CAG (Context) │ → 上下文增强└──────────────────────┘↙ ↓ ↘Clustering-CAG Graph-CAG Memory-CAG(聚类上下文) (图结构上下文) (记忆上下文)
📚 五、总结一句话
RAG 让模型“找到正确的信息”;
CAG 让模型“在正确的语境中理解与生成”。