分布式专题——53 ElasticSearch高可用集群架构实战
1 为什么要使用ES集群架构
-
使用ES集群架构的核心原因,包含两个关键维度:
-
高可用性
- 服务可用性:允许部分节点停止服务,集群整体仍能提供服务;
- 数据可用性:部分节点丢失时,不会丢失数据(依赖数据副本机制);
-
可扩展性:当请求量提升或数据不断增长时,可将数据分布到所有节点上,通过增加节点实现水平扩展;
-
-
ES集群架构的优势:
-
提高系统的可用性:即使部分节点停止服务,剩余节点可继续执行数据和索引操作,集群服务不受影响;
-
存储的水平扩容:支持通过新增节点扩展存储容量,有效应对数据量增长;
-
-
ES集群架构的组件与数据分布示例
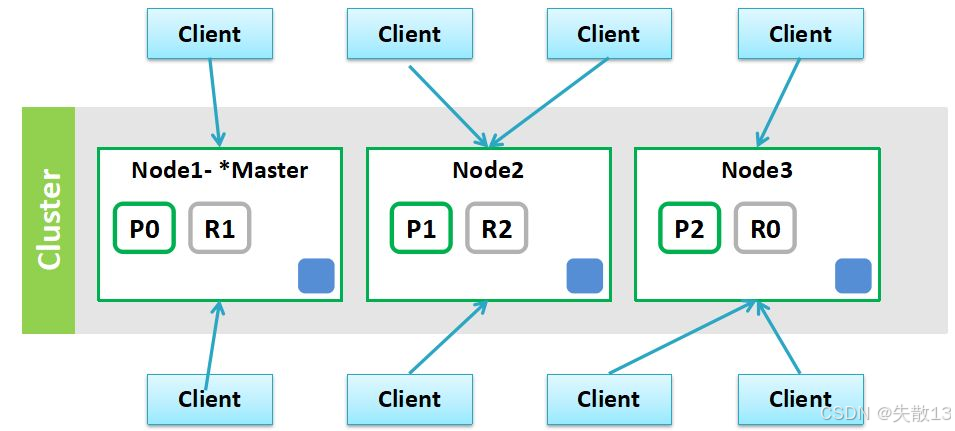
-
Client(客户端):多个客户端与集群交互,发起数据读写、索引等请求;
-
Cluster(集群):由多个节点(Node)组成的整体;
-
Node(节点):
- Node1(*Master节点):是集群的主节点,负责集群的元数据管理、节点状态监控等核心管理操作;
- Node2、Node3:是数据节点,承担数据存储、索引和查询等任务;
-
数据分片与副本(以P0、R1等为例):
- P(Primary Shard,主分片):是数据的原始分片,如图中的P0、P1、P2,负责承载部分数据的写入和查询;
- R(Replica Shard,副本分片):是主分片的副本,如图中的R1、R2、R0,用于数据冗余和故障恢复,同时也能分担查询压力;
这种分片+副本的机制,既实现了数据的水平拆分(提升存储和查询性能),又通过副本保证了数据可用性(主分片故障时,副本可升级为主分片)。
-
2 核心概念
2.1 集群
- 一个集群可包含一个或多个节点
- 不同集群通过名称区分,默认名称为“elasticsearch”
- 可通过配置文件或命令行(如
-E cluster.name=es-cluster)设定集群名称
2.2 节点
- 节点是一个Elasticsearch实例,本质是一个Java进程
- 一台机器可运行多个Elasticsearch进程,但生产环境建议一台机器只运行一个实例
- 每个节点有名称,可通过配置文件或启动命令(如
-E node.name=node1)指定 - 节点启动后会分配一个UID,保存在data目录下
2.3 分片
-
主分片(Primary Shard)
- 用于解决数据水平扩展问题,将数据分布到集群所有节点上;
- 一个分片是一个运行的Lucene实例;
- 主分片数在索引创建时指定,后续不允许修改(除非Reindex);
-
副本分片(Replica Shard)
- 用于解决数据高可用问题,是主分片的拷贝;
- 副本分片数可动态调整;
- 增加副本数可在一定程度上提高服务可用性(读取吞吐);
-
示例API:通过
PUT /blogs请求指定索引的主分片和副本分片数// 指定索引的主分片和副本分片数 PUT /blogs {"settings": {"number_of_shards": 3, // 主分片数"number_of_replicas": 1 // 副本分片数} }
2.4 分片架构
-
以
blogs索引为例,该索引有3个主分片(P0、P1、P2),每个主分片有一个副本分片(如R0是P0的副本分片)。在集群myes中,Node1承载P0和R1,Node2承载P1和R2,Node3承载P2和R0,通过这种分片+副本的分布,实现数据的水平扩展和高可用;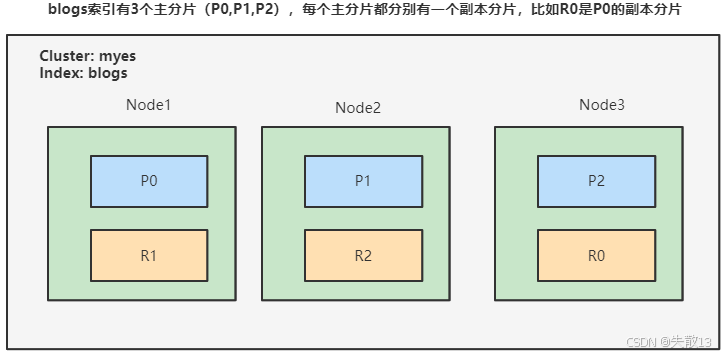
2.5 集群status
-
Green:主分片与副本都正常分配
-
Yellow:主分片全部正常分配,但有副本分片未能正常分配
-
Red:有主分片未能分配(例如服务器磁盘容量超过85%时创建新索引)
-
示例API:通过
GET /_cluster/health查看集群健康状况// 查看集群的健康状况 GET _cluster/health
2.6 CAT API查看集群信息
GET /_cat/nodes?v:查看节点信息GET /_cat/health?v:查看集群当前状态(红、黄、绿)GET /_cat/shards?v:查看各shard的详细情况GET /_cat/shards/{index}?v:查看指定分片的详细情况GET /_cat/master?v:查看master节点信息GET /_cat/indices?v:查看集群中所有index的详细信息GET /_cat/indices/{index}?v:查看集群中指定index的详细信息
3 搭建三节点ES集群
-
建议:每台机器先安装好单节点ES进程,并能正常运行,再修改配置,搭建集群;
IP ES节点名 192.168.65.213 node-1 192.168.65.207 node-2 192.168.65.208 node-3
3.1 ES集群搭建步骤
-
环境准备:
-
软件版本:Elasticsearch 8.14.3,操作系统 CentOS7;
-
用户创建:切换到 root 用户,创建
es用户;adduser es passwd es -
hosts 文件修改:编辑
/etc/hosts,添加各节点的 IP 与主机名映射:192.168.65.213 es-node1 192.168.65.207 es-node2 192.168.65.208 es-node3 -
关闭防火墙关闭:
# 查看防火墙状态 systemctl status firewalld # 关闭防火墙 systemctl stop firewalld # 禁用防火墙 systemctl disable firewalld
-
-
系统配置调整(解决引导检查问题)
-
生产模式下 ES 启动会触发引导检查(bootstrap checks)或称为启动检查,需调整以下系统限制;
所谓引导检查就是在服务启动之前对一些重要的配置项进行检查,检查其配置值是否是合理的。引导检查包括对JVM大小、内存锁、虚拟内存、最大线程数、集群发现相关配置等相关的检查,如果某一项或者几项的配置不合理,ES会拒绝启动服务;

-
文件描述符限制:ES 需要大量创建索引文件,需解除系统打开文件数限制
即解决报错:max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
# 切换到root用户 vim /etc/security/limits.conf# 末尾添加如下配置 * soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096 -
线程数限制:解决“无法创建本地线程”问题,用户最大可创建线程数太小
即解决报错:max number of threads [1024] for user [es] is too low, increase to at least [4096]
vim /etc/security/limits.d/20-nproc.conf# 改为如下配置 * soft nproc 4096 -
虚拟内存限制:调整最大虚拟内存区域,编辑 ``,添加:
vim /etc/sysctl.conf# 追加以下内容 vm.max_map_count=262144# 保存退出之后执行如下命令 sysctl -p
-
-
ES 配置修改
-
切换到
es用户,修改elasticsearch.yml; -
三个节点需保证集群名称一致、节点名称唯一,并配置节点发现、主节点选举等参数:
# 集群名称,三个节点必须一致 cluster.name: es-cluster # 指定节点名称,每个节点名称唯一(如 node-1、node-2、node-3) node.name: node-1 # 绑定 IP,开启远程访问,可以配置0.0.0.0 network.host: 0.0.0.0 # 指定web端口 #http.port: 9200 # 指定tcp端口 #transport.tcp.port: 9300 # 用于节点发现,一般配置集群的候选主节点 discovery.seed_hosts: ["es-node1", "es-node2", "es-node3"] # 7.0引入的集群引导节点配置,指定初始具有主节点资格的节点 cluster.initial_master_nodes: ["node-1","node-2","node-3"] # 解决跨域问题 http.cors.enabled: true http.cors.allow-origin: "*" # 初学者建议关闭security安全认证 xpack.security.enabled: false
-
-
各节点具体配置
-
192.168.65.213:
cluster.name: es-cluster node.name: node-1 network.host: 0.0.0.0 discovery.seed_hosts: ["es-node1", "es-node2", "es-node3"] cluster.initial_master_nodes: ["node-1","node-2","node-3"] http.cors.enabled: true http.cors.allow-origin: "*" xpack.security.enabled: false -
192.168.65.207:
cluster.name: es-cluster node.name: node-3 network.host: 0.0.0.0 discovery.seed_hosts: ["es-node1", "es-node2", "es-node3"] cluster.initial_master_nodes: ["node-1","node-2","node-3"] http.cors.enabled: true http.cors.allow-origin: "*" xpack.security.enabled: false -
192.168.65.208:
cluster.name: es-cluster node.name: node-2 network.host: 0.0.0.0 discovery.seed_hosts: ["es-node1", "es-node2", "es-node3"] cluster.initial_master_nodes: ["node-1","node-2","node-3"] http.cors.enabled: true http.cors.allow-origin: "*" xpack.security.enabled: false
-
-
启动每个节点的ES服务:
-
启动前注意事项:若之前运行过单节点模式,需删除
data目录(rm -rf data),否则无法加入集群; -
安装 IK 分词器(可选但推荐):
bin/elasticsearch-plugin install https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-8.14.3.zip -
启动 ES 服务:后台启动命令
bin/elasticsearch -d; -
验证集群:访问
http://192.168.65.213:9200/_cat/nodes?pretty,若能看到三个节点(node-1、node-2、node-3)的信息,则集群搭建成功;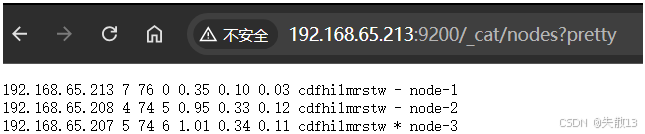
-
3.2 安装Cerebro客户端
-
Cerebro介绍
-
功能:可查看分片分配,通过图形界面执行常见索引操作;支持添加用户、密码或LDAP身份验证的网络界面。
-
技术栈:基于Scala的Play框架编写(后端,用于与Elasticsearch通过REST通信),前端是AngularJS编写的单页应用(SPA)。
-
项目地址:github.com/lmenezes/cerebro;
-
下载地址:https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.zip;
-
-
运行Cerebro
-
直接启动:执行
cerebro-0.9.4/bin/cerebro -
后台启动:通过
nohup bin/cerebro &命令在后台运行
-
-
访问与使用
-
访问地址:
http://192.168.65.207:9000/; -
连接ES集群:在“Node address”输入框中填入ES集群节点地址(如
http://192.168.65.207:9200),点击“Connect”建立连接; -
界面功能:连接后可查看集群概览(如集群名
es-cluster、节点数3 nodes)、节点详情(每个节点的IP、资源使用情况等)、索引和分片信息等。
-
3.3 安装Kibana
-
修改kibana配置:编辑
config/kibana.yml配置文件,进行如下设置vim config/kibana.ymlserver.host: "192.168.65.213" # 指定Kibana的绑定IP,用于网络访问 i18n.locale: "zh-CN" # 将Kibana界面语言设置为中文 -
运行Kibana:执行命令
nohup bin/kibana &,使Kibana在后台运行; -
查询Kibana进程:Kibana对外的TCP端口是5601,可通过命令
netstat -tunlp | grep 5601查看其进程状态; -
访问Kibana:访问地址为
http://192.168.65.213:5601/,通过该地址可进入Kibana的Web界面。
4 ES集群安全认证
4.1 ES集群安全认证的必要性
-
近年来ES数据泄露事件频发,凸显了集群安全认证的重要性,具体案例包括:
-
2019年:某ES数据泄露事件,泄露27亿个电子邮件地址,其中10亿个密码以明文存储,涉及国内多家互联网公司;
-
2021年:Group-IB报告显示,网络上暴露的ES实例超过10万个,约占2021年暴露数据库总数的30%;
-
2022年:漫画阅读平台Mangatoon遭遇数据泄露,黑客从不安全的ES数据库中窃取了2300万用户帐户信息;阿里巴巴遭遇重大数据泄露,涉及客户姓名、电话号、身份证号、居住地址等信息共计23TB;
-
-
参考官方文档:[Start the Elastic Stack with security enabled automatically | Elasticsearch Guide 8.14] | Elastic。
4.2 ES敏感信息泄露的原因
- Elasticsearch在安装后,不提供任何形式的安全防护;
- 不合理的配置导致公网可以访问ES集群。例如在
elasticsearch.yml文件中,server.host配置为0.0.0.0,这种配置会使集群暴露在公网环境中,增加了敏感信息泄露的风险。
4.3 基于Security的安全认证
-
ES 8 版本默认启动了 Security 安全特性;
-
比如 Windows 第一次启动ES,会输出以下信息:
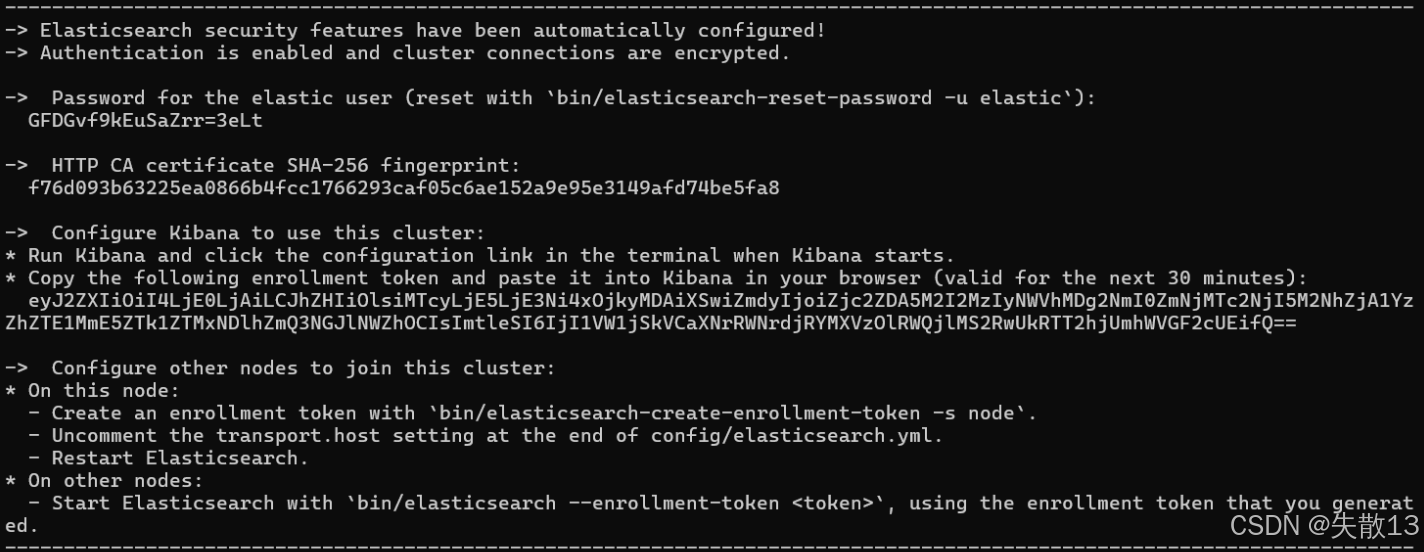
- elastic 用户密码:自动生成
elastic用户的初始密码(如上图中的GFDGVf9KEuSaZrr=3eLt),可通过bin/elasticsearch-reset-password -u elastic重置; - Kibana 注册令牌:生成用于 Kibana 连接集群的注册令牌(有效时长30分钟),需在 Kibana 启动时配置;
- 节点注册令牌:提供生成节点注册令牌的命令(
bin/elasticsearch-create-enrollment-token -s node),用于其他节点加入集群;
- elastic 用户密码:自动生成
-
首次启动 ES 时,会自动进行以下安全配置:
-
TLS 证书与密钥生成:为传输层(Transport)和 HTTP 层生成 TLS 证书(如
http.p12、http_ca.crt、transport.p12); -
配置文件自动写入:TLS 配置会被自动写入
elasticsearch.yml,关键配置包括:xpack.security.enabled: true xpack.security.enrollment.enabled: true xpack.security.http.ssl:enabled: truekeystore.path: certs/http.p12 xpack.security.transport.ssl:enabled: trueverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
-
-
-
账号密码管理
-
在 ES 8.x 版本中,
elasticsearch-setup-passwords工具已被弃用,密码管理需通过以下方式; -
自动生成密码:首次启动时自动生成
elastic用户密码,输出到控制台; -
重置密码:
# 自动生成新密码并输出到控制台 bin/elasticsearch-reset-password -u elastic # 手动指定新密码(下面命令执行后需输入两次自定义密码) bin/elasticsearch-reset-password -u elastic -i # 指定服务地址重置 bin/elasticsearch-reset-password --url "https://ip:9200" -u elastic -i
-
-
服务状态验证
-
ES 8.x 因默认开启 SSL,访问方式与 7.x 有差异;
-
7.x 访问方式:可直接通过
http://localhost:9200/访问; -
如果用上面的方式访问 8.x,会出现访问异常,原因:默认开启 SSL 后,若仍用
http协议访问localhost:9200,会出现“该网页无法正常运作”的错误(ERR_EMPTY_RESPONSE); -
解决与推荐访问方式:
- 临时关闭 SSL:将
xpack.security.http.ssl.enabled从true改为false(不推荐,属于规避问题); - 推荐用
https协议访问:通过https://localhost:9200/访问,此时会弹出登录框,输入elastic账号和对应密码后,可正常查看 ES 服务信息(如集群名称、版本、Lucene 版本等)。
- 临时关闭 SSL:将
-
4.4 三节点ES集群增加安全认证
4.4.1 node-1增加安全认证
-
前置操作:停止集群所有节点,并删除各节点的
data目录; -
修改
elasticsearch.yml配置文件:- 注释
discovery.seed_hosts: ["es-node1", "es-node2","es-node3"]; - 修改
cluster.initial_master_nodes为仅当前节点:cluster.initial_master_nodes: ["node-1"]; - 注释
xpack.security.enabled: false;
- 注释
-
启动node-1节点:
-
删除
data目录(不删除会报错),执行bin/elasticsearch -d后台启动; -
启动后查看
elasticsearch.yml,会自动新增Security相关配置(如xpack.security.enabled: true、TLS证书配置等);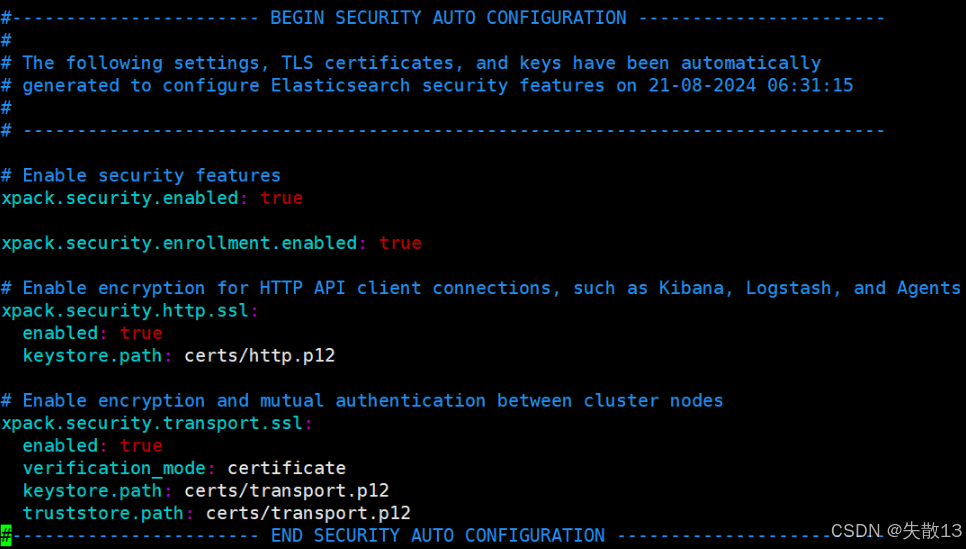
-
-
修改用户elastic的密码与测试
- 修改密码:执行
bin/elasticsearch-reset-password -u elastic -i,按提示输入两次自定义密码,完成elastic用户密码重置; - 测试访问:访问
https://192.168.65.213:9200/,会弹出登录框,输入elastic账号和新密码后,可正常查看ES服务信息(如节点名、集群名、版本等)。
- 修改密码:执行
4.4.2 node-2和node-3加入集群
-
修改
elasticsearch.yml配置文件:- 注释
discovery.seed_hosts: ["es-node1", "es-node2","es-node3"]; - 注释
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]; - 注释
xpack.security.enabled: false;
- 注释
-
向集群中加入新节点
- 默认情况下,要向集群中添加新节点,需要通过令牌来完成节点之间的通信;
- 生成注册令牌(node-1执行):执行
bin/elasticsearch-create-enrollment-token -s node,生成节点注册令牌; - 启动node-2、node-3并加入集群:
- 以node-2为例,执行
bin/elasticsearch --enrollment-token <enrollment-token> -d(将<enrollment-token>替换为上面生成的令牌); - node-3执行相同操作,注意:只有第一次加入集群需要带注册令牌,后续启动无需携带;
- 以node-2为例,执行
-
验证集群状态:通过Head插件查看集群,可看到node-1、node-2、node-3均正常加入,集群状态为绿色;

4.4.3 部署Kibana
-
进入ES目录,执行命令
bin/elasticsearch-create-enrollment-token -s kibana,生成用于Kibana注册的令牌; -
进入Kibana目录,执行命令
bin/kibana-setup --enrollment-token <enrollment-token>(将<enrollment-token>替换为上一步生成的令牌)。执行成功后会提示Kibana configured successfully.,表示Kibana注册完成; -
启动Kibana服务并访问
-
启动服务:执行
nohup bin/kibana &后台启动Kibana; -
访问Kibana:通过地址
http://192.168.65.213:5601/访问,会进入“欢迎使用Elastic”的登录界面; -
登录验证:输入用户名
elastic和对应的密码(之前修改的elastic用户密码),即可进入Kibana主界面。
-
4.4.4 部署Cerebro
-
编辑
conf/application.conf文件,配置连接 ES 集群的信息:vim conf/application.confhosts = [{host = "https://192.168.65.207:9200" // ES 集群的访问地址(带 HTTPS 协议)name = "es-cluster" // 集群名称标识auth = {username = "elastic"password = "123456"}} ] -
启动 Cerebro 服务:执行命令
nohup bin/cerebro -Dplay.ws.ssl.loose.acceptAnyCertificate=true &后台启动服务,其中参数-Dplay.ws.ssl.loose.acceptAnyCertificate=true用于宽松处理 SSL 证书验证(适配 ES 集群的 TLS 配置); -
通过地址
http://192.168.65.207:9000/访问 Cerebro 界面,即可基于配置的认证信息连接到 ES 集群,实现分片查看、索引操作等功能。