大模型应用评估指标学习笔记
参考:https://mp.weixin.qq.com/s/wcVPmyZl7mNGw2R-ZaCiMQ
1、传统NLP评估指标
在评估分类、翻译、摘要等传统 NLP 任务时,我们通常会借助准确率(accuracy)、精确率(precision)、F1 值、BLEU 和 ROUGE 这类传统指标。
🧩 一、分类任务指标(Accuracy、Precision、Recall、F1)
这些指标主要用于 分类任务(Classification),例如:
-
文本分类(正负面情感)
-
实体识别(是否识别对)
-
检索阶段的命中评估(是否检索到正确文档)
1️⃣ 准确率(Accuracy)
定义:

解释:
整体上模型预测对的比例。
适合样本平衡的任务。
例子:
有 100 条情感分类样本(正/负),预测正确 90 条 →
Accuracy = 90 / 100 = 0.9
⚠️ 注意: 如果样本极度不平衡(比如 95% 都是“负面”),模型只要一直预测“负面”,准确率仍然高,但其实没学到任何有用的规律。
2️⃣ 精确率(Precision)
定义:
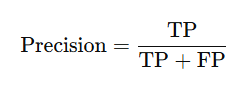
-
TP(True Positive):预测为正且确实是正的
-
FP(False Positive):预测为正但其实是负的
解释:
预测为“正”的样本中,有多少是真的正的。
反映“预测结果的质量”。
例子:
模型预测了 10 条是“正面”,其中 8 条是真的正面 →
Precision = 8 / 10 = 0.8
3️⃣ 召回率(Recall)
定义:
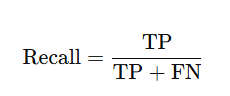
-
FN(False Negative):其实是正的但预测成负的
解释:
真正的“正样本”中,有多少被模型找到了。
反映“漏检情况”。
例子:
总共有 20 条真“正面”样本,模型找到了其中 8 条 →
Recall = 8 / 20 = 0.4
4️⃣ F1 值(F1-score)
定义:
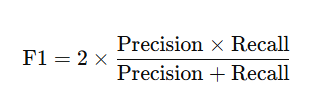
解释:
精确率和召回率的调和平均。
当希望平衡“预测正确率”和“覆盖率”时,使用 F1。
例子:
Precision = 0.8, Recall = 0.4 →
F1 = 2 × (0.8 × 0.4) / (0.8 + 0.4) = 0.533
✅ 总结类比:
| 指标 | 关注点 | 类比 |
|---|---|---|
| Accuracy | 整体对错比例 | “考试总分” |
| Precision | 预测为正的中有多少是真的 | “查到的都对吗?” |
| Recall | 所有正的中有多少被查到 | “有没有漏掉?” |
| F1 | 平衡 Precision 和 Recall | “综合表现” |
🧠 二、生成任务指标(BLEU、ROUGE)
这些指标主要用于 文本生成任务(Text Generation):
-
机器翻译
-
摘要生成
-
问答生成(答案文本匹配)
-
RAG中生成阶段的输出质量
5️⃣ BLEU(Bilingual Evaluation Understudy)
定义思路:
衡量 生成文本与参考文本在 n-gram 层面的重合度。

例子:
参考句子:
"the cat is on the mat"
生成句子:
"the cat is on mat"
-
1-gram 重合率 = 5/6
-
2-gram 重合率 = 3/5
→ BLEU ≈ 0.68
解释:
高 BLEU 表示生成文本在词序和用词上更接近参考答案。
⚠️ 缺点:词义不同但语义相同的句子 BLEU 可能仍低。
例如:“the cat is on the mat” vs “the mat has a cat on it”。
6️⃣ ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
定义思路:
关注 生成文本和参考文本的“召回率” — 即生成文本中有多少内容覆盖参考答案。
常见变体:
-
ROUGE-N:n-gram 层面重合率(如 ROUGE-1、ROUGE-2)
-
ROUGE-L:最长公共子序列(Longest Common Subsequence)
例子:
参考摘要:
“The stock price increased after the announcement.”
生成摘要:
“The announcement caused the stock to rise.”
ROUGE-1 会统计相同的 unigram(如 "the", "stock", "announcement"),
ROUGE-L 会发现两者在顺序上也有共同子序列 → 得分较高。
✅ 生成指标总结:
| 指标 | 主要衡量 | 特点 |
|---|---|---|
| BLEU | 精确匹配率(n-gram) | 常用于机器翻译;惩罚短句 |
| ROUGE | 召回率(内容覆盖) | 常用于摘要生成 |
📘 举个综合例子(对比场景)
| 任务 | 推荐指标 | 原因 |
|---|---|---|
| 文本分类(正负面) | Accuracy / F1 | 二分类标准 |
| 命名实体识别(NER) | Precision / Recall / F1 | 更关心召回率 |
| 文本匹配 / 检索 | Recall@k, MRR | 是否找到正确文档 |
| 机器翻译 | BLEU | 看翻译与参考译文一致程度 |
| 摘要生成 | ROUGE-L | 看生成摘要覆盖关键信息的程度 |
| 开放问答(RAG) | F1 + ROUGE / BLEU | 平衡文本正确性和语义覆盖 |
2、大语言模型基准测试
| 基准 | 覆盖范围 | 难度 / 目标 | 题型 /任务形式 | 适合评估什么 | 注意事项 |
|---|---|---|---|---|---|
| MMLU-Pro | 多学科(14 大领域,如数学、物理、法学、心理学 …) | 高 — 知识 +推理,多选10选项 | 多选题(闭卷) | 模型的广知识+推理能力 | 难度高;对生成、对话能力覆盖少 |
| GPQA | 三大科学领域(生物、物理、化学) | 很高 — 专家级、Google-proof | 多选题(448 道) | 模型在深科学知识+推理上的表现 | 覆盖面窄;只测选题型;模型训练数据可能含题目 |
| BIG-Bench | 非常宽(200+个任务,涵盖推理、数学、代码、偏见、语言、逻辑 …) | 极为广泛且难 | 多任务形式:多选、生成、编程、逻辑推理 … | 模型的广泛能力、边界能力、未来潜力 | 运行成本高;任务异质导致综合解释难;基准更新需求大 |
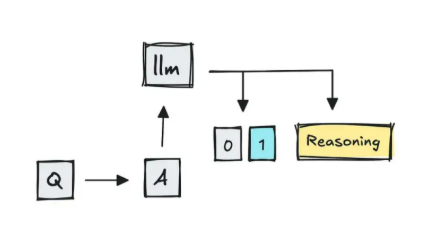
3、将LLM用作评估器
当问题存在歧义或属于开放式问题时,答案可能会出现波动。MT-Bench 就是采用 LLM 评分的基准测试之一,它将两个相互竞争的多轮对话答案提供给 GPT-4,并要求其判断哪个更好。
4、多轮对话系统的评估
4.1 首要关注的是相关性(连贯性)与完整性
相关性指标用于追踪 LLM 是否恰当地处理了用户的查询并保证不偏离主题;而若最终结果真正达成了用户目标,则完整性得分就高
4.2 第二个核心维度,是知识留存能力(Knowledge Retention)与应答可靠性(Reliability)
即:它是否记住了对话中的关键细节?能否确保不会“迷失方向”?仅记住细节还不够,它还需要能够自我纠正。
4.3 第三部分可追踪的是角色一致性与提示词遵循度,用于检验LLM是否始终遵循预设角色设定,是否严格执行系统提示词中的指令
4.4 接下来设计安全性的指标,例如幻觉和偏见/毒性
5、RAG系统的评估
🌐 一、RAG 系统中的评估层次
在一个典型的 RAG(Retrieval-Augmented Generation) 系统中,我们通常把评估分成三个阶段:
| 阶段 | 内容 | 主要指标 |
|---|---|---|
| 1. 检索阶段 (Retrieval) | 检索到相关文档 | Precision@k、Recall@k、Hit@k、MRR、nDCG |
| 2. 生成阶段 (Generation) | 基于检索结果生成答案 | BLEU、ROUGE、F1、BERTScore 等 |
| 3. 综合阶段 (End-to-End) | 检索+生成整体表现 | Faithfulness、Answer Accuracy、人类评测 |
5.1 检索环节,检验系统为特定查询抓取的文档是否精准
若检索环节得分偏低,可通过以下方式进行优化:制定更合理的文本分块策略、更换嵌入模型、引入混合搜索与重排序技术、使用元数据进行过滤等方法。我们先聚焦第一层 —— IR 指标。
📚 二、IR 指标的直观理解
假设我们有一个问题:
“Who developed the theory of relativity?”
语料库中有 1000 篇文档,只有 2 篇真正包含答案信息(爱因斯坦)。
我们让 RAG 的检索模块返回前 k=5 篇最相关的文档。
现在要评估这 5 篇中有多少篇是“真正相关的”,这就是 IR 指标的核心思想。
🔹 1. Precision@k(前 k 的精确率)
定义:

解释:
前 k 个结果中有多少比例是“真正相关的”。
例子:
-
检索返回 5 篇文档(k=5)
-
其中有 3 篇确实包含答案(相关)
作用:
反映检索结果的“纯度”。
高 precision 表示前 k 个结果都很干净、相关性高。
适合场景:
-
用户只看前几个文档或前几个段落。
-
系统生成阶段只取 top-k 文档输入。
🔹 2. Recall@k(前 k 的召回率)
定义:

解释:
模型找回了多少比例的“应找回的相关文档”。
例子:
-
总共有 2 篇相关文档
-
前 5 个结果中找到了其中 1 篇
作用:
反映“漏检率”。
高 recall 表示模型找回了更多真正有用的文档。
适合场景:
-
后续生成阶段需要看到尽可能多的信息。
-
对遗漏容忍度低(如医疗、法律场景)。
🔹 3. Hit@k(命中率)
定义:

解释:
是否“命中”至少一个正确文档。
作用:
最宽松的指标,用于衡量模型能否 至少 找到一篇相关文档。
在 RAG 场景中,只要有一篇包含关键信息,生成阶段就可能答对。
🔸 举个完整的例子
假设:
-
语料库中一共有 3 篇相关文档(D1, D2, D3)
-
检索模块返回前 5 篇: [D1, D4, D5, D2, D6]
| 排名 | 文档ID | 是否相关 |
|---|---|---|
| 1 | D1 | ✅ |
| 2 | D4 | ❌ |
| 3 | D5 | ❌ |
| 4 | D2 | ✅ |
| 5 | D6 | ❌ |
计算:
| 指标 | 计算 | 值 |
|---|---|---|
| Precision@5 | 2/5 | 0.4 |
| Recall@5 | 2/3 | 0.667 |
| Hit@5 | 至少有一个相关 | 1.0 |
🧮 三、它们的区别与互补关系
| 指标 | 关注点 | 优势 | 劣势 |
|---|---|---|---|
| Precision@k | 结果质量 | 反映前 k 结果是否“干净” | 不考虑是否覆盖全部 |
| Recall@k | 覆盖率 | 反映是否漏掉相关文档 | 不管误检是否多 |
| Hit@k | 是否至少命中 | 简单直观 | 不反映命中数量多少 |
在实践中,我们通常结合多个指标来全面判断检索性能。
⚙️ 四、RAG 评估中的典型做法
在 RAG 系统中,我们一般:
-
为每个查询(问题)事先准备“Ground Truth”文档(即真正含答案的文档 ID)。
-
检索模型输出前 k 个候选文档。
-
计算 Precision@k、Recall@k、Hit@k 等。
-
统计所有问题的平均值。
🧠 五、常见扩展指标
| 指标 | 定义 | 说明 |
|---|---|---|
| MRR (Mean Reciprocal Rank) | 平均倒数排名:1 / (正确文档的排名位置) | 越高表示越靠前找到正确文档 |
| nDCG (Normalized Discounted Cumulative Gain) | 对排名位置加权评分 | 兼顾相关性和顺序 |
| MAP (Mean Average Precision) | 平均精确率的平均 | 综合多个 recall 水平的 precision |
🎯 六、RAG 中的使用建议
| 场景 | 推荐指标 | 理由 |
|---|---|---|
| 检索模块优化(Dense/Hybrid) | Precision@k + Recall@k | 平衡“命中质量”与“覆盖度” |
| 调整 top-k 大小 | Recall@k | 评估是否扩大 k 能带来更多召回 |
| 快速 sanity check | Hit@k | 看系统能否至少命中一篇 |
| 生成端联合优化 | Recall@k + F1 (在生成阶段) | 确保检索足够信息支撑生成答案 |
5.2 生成指标
在 RAG(Retrieval-Augmented Generation) 系统中,生成阶段的评估指标(Generation Metrics)用于衡量模型在“拿到检索结果后,生成的答案质量”这一部分。
这些指标主要回答两个问题:
-
✅ 生成的 内容是否正确(Correctness)?
-
💬 生成的 表达是否自然、贴近参考答案(Fluency & Similarity)?
🧩 一、RAG 整体评估回顾
一个 RAG 系统评估通常分为三层:
| 阶段 | 目标 | 常见指标 |
|---|---|---|
| 1️⃣ 检索阶段 (Retrieval) | 是否找对文档 | Precision@k, Recall@k, Hit@k, MRR |
| 2️⃣ 生成阶段 (Generation) | 是否生成正确、自然的答案 | ROUGE, BLEU, METEOR, BERTScore, F1, Faithfulness |
| 3️⃣ 综合阶段 (End-to-End) | 检索 + 生成的整体问答表现 | Answer Accuracy, Faithfulness, Human Eval |
我们现在专讲第二层:生成阶段指标。
🧠 二、生成阶段指标分类总览
| 类型 | 目的 | 代表指标 | 特点 |
|---|---|---|---|
| 📖 基于文本重叠(Surface-based) | 看生成文本与参考答案在 词面上 是否相似 | BLEU, ROUGE, METEOR | 快速计算、直观但可能忽略语义 |
| 💡 基于语义相似度(Semantic-based) | 看生成文本与参考答案在 语义上 是否相似 | BERTScore, Sentence-BERT Cosine | 更符合语义理解,但需要大模型或编码器 |
| 🔍 基于事实一致性(Faithfulness-based) | 看生成文本是否与 检索文档事实一致 | Faithfulness, FActScore, GPT-based Eval | 用于防止“幻觉” |
| ⚖️ 分类或片段级别评估 | 对抽取类任务(如问答)进行逐词比较 | Exact Match (EM), F1 (token-level) | 常见于 QA 评估(如 SQuAD) |
📘 三、主流指标详解
1️⃣ ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
常用于:📄 摘要生成、问答生成、长文本输出。
定义:
衡量生成文本与参考答案在 n-gram 层面的重合程度。
常见版本:
-
ROUGE-1:1-gram(词)重合率
-
ROUGE-2:2-gram(词对)重合率
-
ROUGE-L:最长公共子序列(Longest Common Subsequence)
举例:
参考答案:
"The cat is on the mat"
生成答案:
"The cat lies on the mat"
重合词:the, cat, on, the, mat →
ROUGE-1 ≈ 5/6 ≈ 0.83
优点:
-
简单、直观、快速
-
对多样化文本任务通用
缺点:
-
只看词面重叠,不理解语义
(如 “lies” vs “is” 含义相同但不重叠)
2️⃣ BLEU(Bilingual Evaluation Understudy)
常用于:🌍 机器翻译、对话生成。
定义:

举例:
参考:"the cat is on the mat"
生成:"the cat is on mat"
→ BLEU ≈ 0.68
优点:
-
翻译和短文本生成领域标准指标
-
反映生成句子是否“接近参考”
缺点:
-
对同义词、语序变化不鲁棒
-
不适合自由生成或问答类任务
3️⃣ METEOR
常用于:机器翻译、自然语言生成。
与 BLEU/ROUGE 不同,考虑了词形还原与同义词匹配。
特点:
-
使用 WordNet 同义词库
-
计算加权 F-score:综合了精确率与召回率
-
考虑词序惩罚
优点:
比 BLEU 更符合人类主观评价。
缺点:
实现较复杂,依赖语言资源(如 WordNet)。
4️⃣ BERTScore
常用于:开放问答、生成式摘要、自由文本生成。
思路:
用 BERT 或 Sentence-BERT 对每个 token 向量化,计算语义相似度(Cosine similarity)。
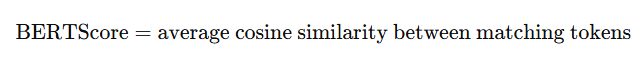
举例:
即使词面不同,如:
-
参考:"the cat is on the mat"
-
生成:"the feline sits on the rug"
虽然没有词面重叠,但语义相似,BERTScore 仍可达 0.85+。
优点:
-
语义层面,更贴近人类理解
-
对同义词、改写鲁棒
缺点:
-
计算慢
-
依赖预训练模型(如 RoBERTa-large)
5️⃣ Exact Match (EM) & F1 (token-level)
常用于:问答(QA)任务。
定义:

举例:
参考:"Albert Einstein"
生成:"Einstein"
→ EM = 0, 但 F1 ≈ 0.67
优点:
-
简洁明确,适合 QA 类任务
-
与 SQuAD、HotpotQA 等评测体系兼容
缺点:
-
对开放性回答不鲁棒(如 “He was Einstein” vs “Albert Einstein”)
6️⃣ Faithfulness(事实一致性)
常用于:RAG、摘要、事实生成任务。
定义:
评估生成答案是否与检索文档(evidence)一致,是否存在“幻觉(hallucination)”。
测评方式:
-
人工标注:是否忠实于来源文档
-
自动评测:FActScore、GPT-judge、LLM-as-a-judge 等
举例:
检索文档:
“Einstein developed the theory of relativity.”
生成答案:
“Newton developed the theory of relativity.”
→ 事实不一致 → Faithfulness = 0
优点:
-
检测幻觉、事实错误
-
RAG 系统质量的关键指标
缺点:
-
需要额外判断机制(LLM 或规则)
-
自动化仍具挑战性
📊 四、指标之间的对比总结
| 指标 | 类型 | 对语义敏感 | 对词序敏感 | 常用于 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| BLEU | 精确率 | ❌ | ✅ | 翻译 | 经典、稳定 | 忽略语义 |
| ROUGE | 召回率 | ❌ | ✅ | 摘要 | 易解释 | 词面匹配 |
| METEOR | F1 + 同义词 | ✅ | 部分 | 翻译、摘要 | 贴近人类 | 慢 |
| BERTScore | 语义 | ✅ | ❌ | QA、生成 | 语义鲁棒 | 依赖模型 |
| F1 / EM | 精确匹配 | ⚠️ 部分 | ❌ | QA | 明确直观 | 不适合开放回答 |
| Faithfulness / FActScore | 事实一致性 | ✅ | ❌ | RAG | 防幻觉 | 需外部验证 |
🧮 五、实践建议(RAG生成阶段)
| 评估目标 | 推荐指标 | 理由 |
|---|---|---|
| 生成答案是否与参考文本相似 | ROUGE / BERTScore | 语义+内容双重检查 |
| 答案是否完全正确 | EM / F1 | 精确比较 |
| 答案语义是否合理 | BERTScore | 适合开放回答 |
| 是否忠实于检索文档 | Faithfulness / FActScore | 防止幻觉 |
| 对话流畅自然 | BLEU / GPT-based Human Eval | 语法自然度 |
✅ 小结
🔹 BLEU / ROUGE:看词面重叠
🔹 METEOR / BERTScore:看语义相似
🔹 EM / F1:看答案对不对
🔹 Faithfulness:看是否编造幻觉
5.3 综合指标
“综合阶段指标(End-to-End Metrics)” 是 RAG(Retrieval-Augmented Generation)系统评估中最关键、也是最贴近实际应用的部分。
这阶段的目标是——不再只看检索准不准或生成流不流畅,而是整体上:答案对不对、逻辑通不通、有没有幻觉。
下面我来系统性地讲解:
🧩 一、什么是综合阶段(End-to-End Evaluation)
综合阶段(End-to-End Evaluation)是对 整个 RAG 系统 的最终表现进行评估的阶段。
它不关心内部的检索结果具体是什么、模型生成过程如何,而是直接关注:
“最终输出是否正确?”
“输出是否忠实于支持文档?”
“输出是否自然流畅、无幻觉?”
🧠 二、主要评估目标
| 目标 | 含义 |
|---|---|
| 答案正确性(Answer Correctness) | 生成的答案是否与标准答案一致 |
| 忠实度(Faithfulness / Groundedness) | 生成的内容是否真实地基于检索到的文档 |
| 一致性(Consistency) | 多轮回答或多个文档间信息是否前后一致 |
| 流畅性(Fluency / Coherence) | 输出的语言是否自然通顺、逻辑连贯 |
| 有用性(Helpfulness / Relevance) | 输出是否真正回答了用户问题 |
📊 三、常见综合阶段指标(End-to-End Metrics)
下面我分为三大类详细讲:
1️⃣ 答案准确类指标(Answer-level Metrics)
这些指标直接衡量最终回答与参考答案(Ground Truth)的接近程度。
| 指标 | 含义 | 计算方式 | 应用 |
|---|---|---|---|
| Exact Match (EM) | 生成答案与标准答案完全一致的比例 | 是否字符串完全相同 | QA任务,如 SQuAD |
| Answer F1 | 生成答案与标准答案在词级别的重叠程度(兼顾精确率与召回率) | $$ F1 = \frac{2PR}{P+R} $$ | QA、信息抽取 |
| Answer Recall / Precision | 在生成答案中,正确信息的召回率 / 精确率 | 实体匹配或关键词匹配 | 知识问答 |
| Answer Accuracy | 答案是否正确(0/1) | 逻辑判断、选择题类QA | MMLU等任务 |
✅ 例子:
标准答案:
“RAG 是一种结合检索与生成的方法。”
模型输出:
“RAG 结合了检索和生成模型。”
结果:
-
EM = 0(不完全一致)
-
F1 ≈ 0.9(词级重叠高)
-
BERTScore ≈ 0.95(语义接近)
2️⃣ 忠实度与幻觉检测类指标(Faithfulness / Groundedness Metrics)
RAG 的核心问题之一是 幻觉(Hallucination)。
这些指标用来检测模型是否“胡编乱造”,是否“忠实于检索文档”。
| 指标 | 含义 | 实现方式 | 示例 |
|---|---|---|---|
| Faithfulness Score | 输出内容与支持文档一致的程度 | 通过对比生成文本与检索文档内容,统计一致句比例 | 0~1越高越好 |
| Groundedness | 模型回答是否“有依据” | 用大模型判断“是否可由文档推导” | GPT评分或LLM-as-a-judge |
| Attribution Score | 每句生成内容是否能在文档中找到出处 | 自动句匹配或embedding相似度 | 检查引用是否正确 |
| FActScore | 针对事实性陈述的自动评分(基于信息抽取与验证) | 用信息抽取模型 + 检索验证模型 | QA/报告生成任务 |
✅ 例子:
支持文档提到“OpenAI 于 2015 年成立”。
模型回答:“OpenAI 于 2017 年成立。”
→ Faithfulness = 0(与事实不符)
3️⃣ 人类可读性与实用性指标(Human-like Metrics)
机器自动指标有时不能全面反映生成质量,因此常结合人工或大模型评估。
| 指标 | 含义 | 获取方式 |
|---|---|---|
| Fluency(流畅性) | 输出是否自然、语法正确 | 人类评分或语言模型评分 |
| Coherence(一致性) | 答案逻辑是否通顺、结构合理 | 人类评分或embedding一致性 |
| Relevance(相关性) | 输出是否真正回答了问题 | 人类或LLM评估 |
| Helpfulness(有用性) | 输出是否帮助用户理解问题 | 人类或LLM评分 |
| G-Eval / LLM-as-a-Judge | 使用大型语言模型对输出进行多维打分(如 GPT-4) | 常用于自动化评估 pipeline |
✅ 例子:
使用 GPT-4 对每个答案进行以下打分:
维度:Faithfulness, Relevance, Coherence, Fluency
每项 1~5 分,最终平均分作为综合指标。
⚙️ 四、典型综合评估流程(End-to-End Pipeline)
RAG 输入问题 → 检索文档 → 生成答案 → 综合评估
示例流程:
| 阶段 | 指标 | 工具/方法 |
|---|---|---|
| Step 1 | Answer Correctness (EM, F1) | 自动匹配 |
| Step 2 | Faithfulness / Groundedness | 语义检索 + LLM-as-a-Judge |
| Step 3 | Coherence / Fluency | GPT评分或BLEU/ROUGE |
| Step 4 | Aggregate Score | 加权平均或多维度汇总报告 |
🧮 五、一个真实例子
| 维度 | 指标 | 分值 |
|---|---|---|
| Accuracy | F1 | 0.87 |
| Faithfulness | Groundedness Score | 0.93 |
| Coherence | GPT Score | 4.5 / 5 |
| Fluency | GPT Score | 4.8 / 5 |
| 综合得分 | Weighted Sum | 0.91 |
这表示:
👉 模型生成的答案大体正确、忠实于文档、语言自然流畅。
💡 六、RAG 评估的趋势
现代 RAG 系统评估开始从“静态指标”→“语义理解”→“多维度一致性”演进:
| 阶段 | 方法 | 特点 |
|---|---|---|
| 传统阶段 | BLEU / ROUGE / EM | 仅比对词串 |
| 语义阶段 | BERTScore / Embedding Cosine | 语义级比较 |
| 智能阶段 | GPT-4 Judge / G-Eval / RAGAS | 大模型自动多维评估 |
🧭 七、小结表
| 指标类别 | 核心指标 | 评价维度 | 常见工具 |
|---|---|---|---|
| 答案准确类 | EM, F1, Accuracy | 正确性 | SQuAD, RAGAS |
| 忠实度类 | Faithfulness, Groundedness, FActScore | 幻觉检测 | GPT-4 Judge, RAGAS |
| 人类评分类 | Fluency, Coherence, Relevance | 可读性、实用性 | GPT评分、人评 |
| 复合指标 | 综合加权评分 | 整体性能 | 自定义 pipeline |
6、Agent的评估
“Agent 的评价指标(Agent Evaluation Metrics)” 是近年来在大模型应用中非常热门的研究主题,尤其是随着 LLM-based Agent(智能体) 在任务规划、工具调用、决策控制等场景的普及,如何科学地评估一个 Agent 的智能水平和可靠性 成为核心问题。
我来从专业角度系统地给你讲解这一部分内容👇
🧩 一、为什么要评估 Agent?
一个 Agent(智能体)通常具备以下能力:
-
理解任务(Task Understanding)
-
规划与推理(Planning & Reasoning)
-
行动执行(Action Execution)
-
与环境交互(Interaction / Tool Use)
-
自我反思与纠错(Reflection & Correction)
因此,Agent 的评价指标必须覆盖多个维度,而不能只看“输出对不对”。
🧠 二、Agent 评估的总体框架
可以从三个层次理解:
| 评估层级 | 目标 | 典型指标 |
|---|---|---|
| 🧩 微观层(Micro) | 评估单步推理、调用是否正确 | Function Call Accuracy、Action Success Rate |
| ⚙️ 中观层(Meso) | 评估完整任务流程是否顺畅 | Task Success Rate、Execution Efficiency |
| 🌍 宏观层(Macro) | 评估整体智能、鲁棒性与用户体验 | Generalization、Reliability、Human Preference |
📊 三、主要评价指标分类详解
① 任务成功率类(Task Success Metrics)
目标: 测量 Agent 是否完成了目标任务。
| 指标 | 含义 | 示例 |
|---|---|---|
| Task Success Rate (TSR) | Agent 是否成功完成目标任务 | 若 10 个任务中成功 8 个 → TSR = 80% |
| Goal Completion Rate | 最终目标的完成程度(部分成功记部分分) | 任务完成度 0~1 |
| Plan Execution Success | 执行的动作序列是否达成目标 | 是否调用了正确的API序列 |
| Subtask Completion Ratio | 子任务完成比例 | 多阶段任务中每阶段成功率 |
✅ 例子:
问答Agent若正确回答了问题 → TSR=1;若回答部分正确 → TSR=0.5。
② 动作与工具调用类(Action / Tool Use Metrics)
目标: 评估 Agent 调用外部工具(API、数据库、搜索引擎等)的能力与效率。
| 指标 | 含义 | 示例 |
|---|---|---|
| Action Accuracy | 工具调用参数是否正确 | 调用weather_api(city=“London”)正确率 |
| Tool Usage Efficiency | 使用工具的最优性 | 调用次数最少且成功 |
| Error Recovery Rate | 出错后能否自我纠错 | 错误调用后能否重新规划 |
| API Success Rate | API 调用成功比例 | 调用返回状态200的比例 |
| Latency / Cost Efficiency | 每次调用耗时或成本 | 调用次数×平均耗时 |
✅ 例子:
一个检索型Agent调用搜索API 5次,其中4次成功 → API Success Rate = 80%。
③ 推理与规划能力类(Reasoning / Planning Metrics)
目标: 衡量 Agent 的多步推理、计划和决策能力。
| 指标 | 含义 | 示例 |
|---|---|---|
| Plan Coherence | 计划是否逻辑合理、无冲突 | “先打开文件→再读取→再关闭” 合理 |
| Step Correctness | 每步推理是否正确 | 多步算术推理准确率 |
| Reasoning Depth | 推理层次数量 | 是否具备多跳(multi-hop)推理 |
| Chain-of-Thought Accuracy (CoT-A) | 思维链的逻辑合理性 | 与正确推理路径匹配度 |
| Causal Consistency | 因果推理是否正确 | 因果结论与前提一致 |
✅ 例子:
在一个多步计算任务中,如果 Agent 每步逻辑正确且最终结果正确 → CoT-A = 1.0。
④ 交互与协作类(Interaction Metrics)
目标: 衡量 Agent 与人类或其他 Agent 的协作质量。
| 指标 | 含义 | 示例 |
|---|---|---|
| Conversational Turn Success | 每轮对话是否推进任务 | 每一轮中是否取得进展 |
| Human Satisfaction Score | 人类主观满意度(Likert 评分) | 用户评分 1–5 |
| Helpfulness / Relevance | 回复是否有帮助且相关 | LLM 或人工评分 |
| Adaptability / Robustness | 面对意外输入的稳定性 | 用户乱输时能否纠正理解 |
| Cooperation Score | 多 Agent 协作时的配合程度 | 团队任务完成率 |
✅ 例子:
如果用户在3轮交互内获得想要的结果 → Turn Success = 高。
⑤ 可靠性与鲁棒性类(Reliability / Robustness Metrics)
目标: 测量 Agent 是否稳定、安全、可复现。
| 指标 | 含义 | 示例 |
|---|---|---|
| Error Rate | 任务或动作执行失败比例 | 出错次数 / 总执行次数 |
| Reproducibility Score | 同样输入是否能输出相同结果 | 随机性控制测试 |
| Safety Compliance | 是否违反安全策略 | 不输出违规内容 |
| Out-of-Distribution Robustness | 对异常输入的稳定性 | “边界测试”场景下的表现 |
✅ 例子:
Agent 在 100 次执行中仅 2 次崩溃 → Error Rate = 2%。
⑥ 综合表现与智能水平类(Holistic / Intelligence Metrics)
这些指标通常由人类或大模型自动打分,用于整体评估智能体水平。
| 指标 | 含义 | 示例 |
|---|---|---|
| Overall Task Score | 结合多项指标的加权总分 | TSR × 0.4 + CoT-A × 0.3 + Fluency × 0.3 |
| Human Preference Score (HPS) | 人类更倾向哪个 Agent 输出 | 比较式评分 |
| G-Eval / LLM-as-a-Judge | 由 GPT-4 等大模型对Agent输出自动打分 | Faithfulness / Reasoning / Helpfulness |
| Generalization Score | 新任务迁移能力 | 新任务成功率 |
| RAGAS for Agents | 对Agent输出忠实度的量化 | 检查引用准确性 |
🧮 七、Agent 评估自动化框架示例
一个完整的 Agent Evaluation Pipeline 通常包括以下步骤:
输入任务 → Agent 规划行动 → 执行工具调用 → 输出结果 → 自动评估
示意表:
| 阶段 | 指标 | 工具 / 方法 |
|---|---|---|
| 任务完成 | Task Success Rate, Goal Completion | 自定义任务脚本 |
| 工具使用 | Action Accuracy, API Success | 日志分析 |
| 推理能力 | CoT Accuracy, Plan Coherence | Chain-of-Thought 比对 |
| 交互能力 | Turn Success, Helpfulness | LLM Judge 或人工评估 |
| 综合质量 | G-Eval, HPS | GPT-4 / Claude 评估模型 |
🧭 八、常用评估框架与基准测试
| 基准 | 目标 | 特点 |
|---|---|---|
| GAIA (General AI Agent Benchmark) | 通用智能体评估 | 包含任务完成率、推理能力、工具使用 |
| AgentBench (2024) | 多任务智能体综合评测 | 14 类任务、细粒度指标 |
| OSWorld / WebArena | Web环境任务执行评测 | 行动正确率、计划成功率 |
| Mind2Web / MetaGPT Eval | 网页操作与代码生成Agent评估 | 多步执行准确率 |
| HELM / BigBench Hard | 泛化智能评估 | 语义、逻辑与推理维度 |
📘 九、小结:Agent 评估维度总览
| 评估维度 | 核心指标 | 对应能力 |
|---|---|---|
| 任务完成度 | Task Success, Goal Completion | 执行力 |
| 工具使用 | Action Accuracy, API Success | 外部操作能力 |
| 推理规划 | CoT Accuracy, Plan Coherence | 智能与逻辑 |
| 交互协作 | Turn Success, Helpfulness | 沟通与理解 |
| 稳定鲁棒 | Error Rate, Safety Score | 可靠性 |
| 综合智能 | G-Eval, Human Preference | 智能水平 |
是否希望我帮你生成一个「📊 Agent 自动化评估脚本模板(含任务成功率 + 工具调用 + GPT-Judge 综合评分)」?
我可以给出一个 Python + LangChain Agents + GPT-4 Judge 的版本,用于自动评测 Agent 的整体表现。
7、主流评估框架
MLFlow 最初为传统机器学习 pipelines 设计,因此针对 LLM 应用的预置指标较少。OpenAI 提供非常轻量的解决方案,需要用户自行设定评估指标(尽管它提供了一个示例库帮助入门)。
RAGAS 提供了丰富的评估指标,并且与 LangChain 集成,便于快速部署。
DeepEval 则提供了大量开箱即用的功能,其功能集完全覆盖 RAGAS 指标。