CV三大核心任务:目标检测、图像分割、关键点检测
计算机视觉的 “感知三剑客”
当自动驾驶汽车识别出前方横穿马路的行人(检测)、区分出车道线与路面(分割)、判断行人手臂摆动姿态(关键点检测)时,正是这三大任务在协同工作。简单来说:
目标检测:“找东西 + 贴标签”—— 定位图像中目标的位置(用边界框标记)并识别类别
图像分割:“像素级分类”—— 给每个像素分配类别标签,实现目标与背景的精确分离
关键点检测:“抓特征锚点”—— 定位目标的关键特征点(如人脸的眼睛、人体的关节)
三者构成计算机视觉的感知基石,从 “有没有”“是什么” 升级到 “在哪里”“长什么样” 的深度理解。
一、目标检测:从 “看见” 到 “定位” 的进化
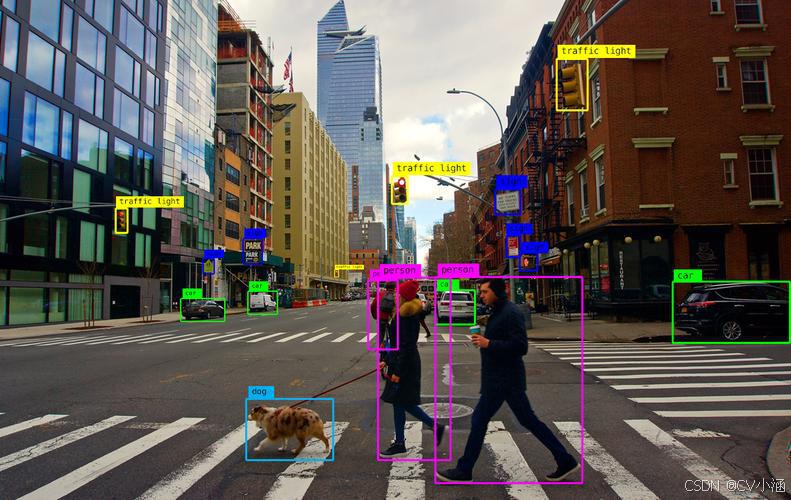
1.1 技术本质与核心指标
目标检测的核心是解决 “where + what” 问题,输出格式为(x1,y1,x2,y2,class,confidence),其中(x1,y1)(x2,y2)是边界框坐标,confidence代表预测可信度。
关键评估指标:
mAP(平均精度均值):衡量不同类别检测精度的综合指标,越高越好
FPS(每秒帧率):体现实时性,自动驾驶需≥30FPS,工业质检需≥50FPS
1.2 算法演进:从锚框到无锚框的跨越
传统方法阶段(2010 年前)
滑动窗口 + 特征工程:用固定大小窗口遍历图像,结合 HOG、SIFT 等手工特征分类
缺陷:速度慢(窗口数量达 10 万级)、精度低(依赖人工设计特征)
深度学习初代(2014-2017)
R-CNN 系列:开创 “候选区域 + 分类” 范式
R-CNN:先生成 2000 个候选框,再用 CNN 提取特征分类(FPS 仅 5)
Fast R-CNN:共享卷积特征,将 FPS 提升至 15
Faster R-CNN:用 RPN 网络自动生成候选框,实现端到端训练(COCO mAP 达 28.8%)
实时检测革命(2016 至今)
YOLO 系列:“你只看一次” 的单阶段检测
核心创新:将检测转化为回归问题,一次性输出边界框与类别
最新进展:YOLOv10 采用 CSPNet v3 骨干网络,模型体积仅 9.8MB,COCO mAP@0.5 达 62.1%,在无人机避障系统中误检率降低 76%
DETR 家族:Transformer 赋能的端到端检测
RT-DETR:融合 CNN 与 Transformer,通过可变形注意力将计算量降为 O (N),小样本场景性能衰减仅 5.3%,已用于特斯拉机器人视觉系统
锚框与无锚框之争
| 类型 | 代表算法 | 优势 | 缺陷 |
|---|---|---|---|
| 锚框 - based | Faster R-CNN | 精度高 | 锚框参数难调 |
| 无锚框 | CenterNet | 速度快、适配小目标 | 遮挡场景鲁棒性差 |
二、图像分割:像素级的 “精细画像”
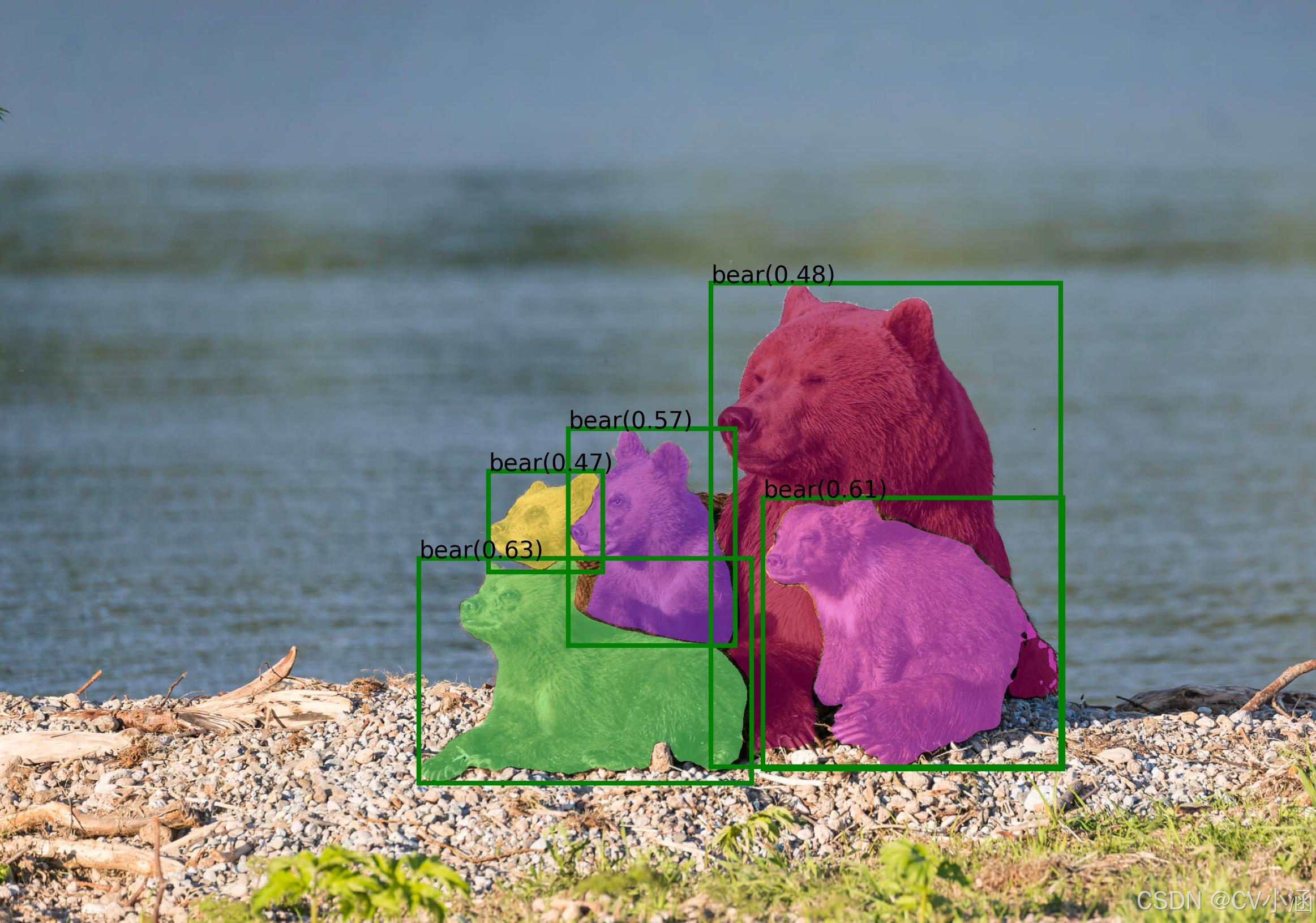
2.1 三大分割类型辨析
| 类型 | 核心目标 | 应用场景 | 示例 |
|---|---|---|---|
| 语义分割 | 给同类目标统一标签 | 自动驾驶路面识别 | 所有行人标为 “行人” |
| 实例分割 | 区分同类目标的不同个体 | 人群计数 | 每个行人标唯一 ID |
| 全景分割 | 语义 + 实例分割结合 | 机器人场景理解 | 路面(语义)+ 行人 ID |
2.2 技术演进:从传统方法到 AI 驱动
传统分割阶段(2000 年前)
阈值分割:如 OTSU 算法,按灰度值划分前景背景(适合高对比度图像)
区域生长:从种子点扩散合并相似像素(易受噪声干扰)
图论与聚类阶段(2000-2010)
Graph Cuts:将图像建模为图,通过最小割实现分割(需大量计算)
SLIC 超像素:生成紧凑的图像块,减少后续计算量(至今仍用于预处理)
深度学习时代(2010 至今)
FCN(2015):首次实现端到端语义分割,通过上采样恢复像素分辨率
U-Net(2015):编码 - 解码架构 + 跳跃连接,成为医疗分割黄金标准,MedSAM 基于此优化后肝脏分割 Dice 系数达 0.934
DeepLab 系列:引入空洞卷积与 ASPP 模块,解决多尺度分割问题
SAM(2023):交互式分割革命,基于 11 亿掩码的 SA-1B 数据集,支持文本 / 点 / 框提示,已集成到 Photoshop 2024
2.3 核心挑战与解决方案
小目标分割:如医疗影像中的微肿瘤,采用 U-Net++ 的嵌套结构提升细节捕捉
实时分割:MobileNet 作为骨干网络,牺牲 10% 精度换取 5 倍速度提升
弱监督分割:Grounded-SAM 结合 CLIP 模型,通过文本描述实现零样本分割,PASCAL VOC 精度达 91.3%
三、关键点检测:目标的 “骨骼定位”

3.1 技术原理与任务分类
关键点检测通过定位目标的关键特征点(如人脸 68 点、人体 17 关节),实现对目标姿态、形状的理解。按目标类型可分为:
人体姿态估计:检测关节点(如膝关节、肘关节)
人脸关键点检测:定位眼睛、鼻子等特征点
物体关键点检测:如车辆的车轮、门把手
3.2 两大技术路线对比
Top-Down(自上而下)
先用目标检测定位个体
再在单个目标内检测关键点
代表算法:Mask RCNN(将关键点建模为 one-hot mask)
优势:精度高,适合少目标场景
缺陷:速度慢(需先检测)
Bottom-Up(自下而上)
先检测全图所有关键点
再通过聚类分配给个体
代表算法:OpenPose、HigherHRNet
优势:速度快,适合人群密集场景
缺陷:易混淆相似关键点
3.3 前沿进展与应用
多任务融合:MultiTask-CenterNet 在同一网络中实现检测、分割与姿态估计,推理时间减少 40%
遮挡鲁棒性:采用注意力机制忽略遮挡区域,在 COCO 数据集上遮挡场景 AP 提升 18%
应用案例:健身 APP 的动作纠正(通过关节点计算角度)、动画制作的动作捕捉
四、三任务融合:1+1+1>3 的协同效应
4.1 经典融合模型解析
Mask RCNN(2017)
架构:在 Faster R-CNN 基础上增加分割头与关键点头
创新点:RoIAlign 替代 RoIPooling,解决像素量化误差,使分割精度提升 20%
能力扩展:可同时输出边界框、掩码与关键点,在人体关键点检测中保持三项任务性能平衡
Cascade Mask RCNN(2018)
核心改进:级联多个检测器,每个阶段用更高 IOU 阈值筛选样本
性能增益:在 COCO 数据集上实例分割 AP 较 Mask RCNN 提升 3.2 个百分点
OmniDet(2021)
多任务集大成者:融合检测、分割、关键点、深度估计等 6 大任务
鱼眼镜头适配:用 24 边多边形替代矩形框,解决畸变场景检测问题
4.2 融合的核心价值
数据效率:共享骨干网络特征,减少标注成本
性能互补:分割的像素级信息提升检测定位精度,检测的边界框约束关键点范围
工程优化:单模型替代多模型,降低部署成本(如自动驾驶感知系统体积减少 60%)
五、产业落地:从实验室到真实世界
5.1 典型应用场景
| 领域 | 检测应用 | 分割应用 | 关键点应用 |
|---|---|---|---|
| 自动驾驶 | 障碍物识别(车 / 人 / 动物) | 车道线 / 路面分割 | 行人姿态预判 |
| 医疗影像 | 肿瘤检测 | 器官 / 病灶分割 | 细胞形态分析 |
| 工业质检 | 缺陷定位 | 缺陷区域分割 | 零件装配对齐 |
| 娱乐传媒 | 人脸检测 | 背景虚化 | 表情捕捉 / 动作追踪 |
5.2 落地挑战与工程实践
算力约束:工业场景采用模型量化(INT8),精度损失 < 2%,推理速度提升 3 倍
标注成本:用 NVIDIA Omniverse 生成合成数据,宝马将缺陷检测训练时间从 6 周缩至 72 小时
鲁棒性优化:华为 ADS 3.0 融合多传感器,异形障碍物识别准确率达 99.6%
六、未来趋势
端到端统一建模:华为盘古 CV 实现三任务统一,减少人工设计组件
多模态驱动:结合文本、语音提示,如 Grounded-SAM 通过文字 “分割红色汽车” 自动生成掩码
小样本与零样本学习:解决医疗等稀缺数据场景问题,元学习技术加速落地
3D 感知升级:从 2D 关键点到 3D 姿态估计,支撑机器人交互与 AR/VR 应用
以上均为原创。