ScaleRL:掌握大语言模型强化学习的规模化艺术
标题
- 论文:The Art of Scaling Reinforcement Learning Compute for LLMs
- 链接:https://arxiv.org/pdf/2510.13786
- from:meta
- 代码:https://www.devvrit.com/scalerl_curve_fitting(用于拟合RL计算-性能缩放曲线的极简代码库)
TL;DR
本文针对LLM强化学习(RL)训练缺乏可预测规模化方法的问题,通过40万+ GPU小时的大规模实验,提出了基于S形曲线的预测框架,整合出高效可预测的RL训练方案ScaleRL。该方案在10万GPU小时训练中验证了稳定性与可预测性,性能超越现有主流方案,同时揭示了RL规模化的核心原则,让RL训练向预训练的可预测性靠拢。
背景
强化学习已成为LLM能力升级的核心技术,能解锁推理、智能体等关键能力,且RL训练的计算成本正急剧增长(部分模型RL计算量达预训练的3.75%,前沿模型代际间RL计算量增长超10倍)。但与预训练成熟的规模化定律不同,LLM的RL训练仍处于“经验驱动”阶段,缺乏统一的规模化评估框架,现有研究多是针对特定场景的零散方案,无法指导计算资源的高效缩放。
挑战
- 缺乏预测性框架:无法从小规模实验推断大规模RL训练的性能,导致研究依赖巨额计算资源,学术社区难以参与。
- 设计选择影响不明:损失聚合、归一化、数据课程学习等众多设计选择,对最终性能上限和计算效率的影响缺乏系统性分析。
- 稳定性与可扩展性矛盾:部分方法在小规模计算下表现优异,但规模化后性能饱和甚至下降,且易出现生成长度爆炸、数值不稳定等问题。
- 性能评估标准模糊:现有研究多关注下游任务表现,难以精准衡量RL方法的规模化潜力。
方法
1. 预测性缩放框架
提出S形计算-性能曲线模型,量化奖励增益与训练计算量的关系:
- 核心公式:

- 关键参数:A(渐近性能上限)、B(计算效率指数)、CmidC_{mid}Cmid(性能达到总增益50%时的计算量)
- 优势:相比预训练常用的幂律模型,更适配准确率等有界指标,低计算量数据即可精准预测大规模性能。
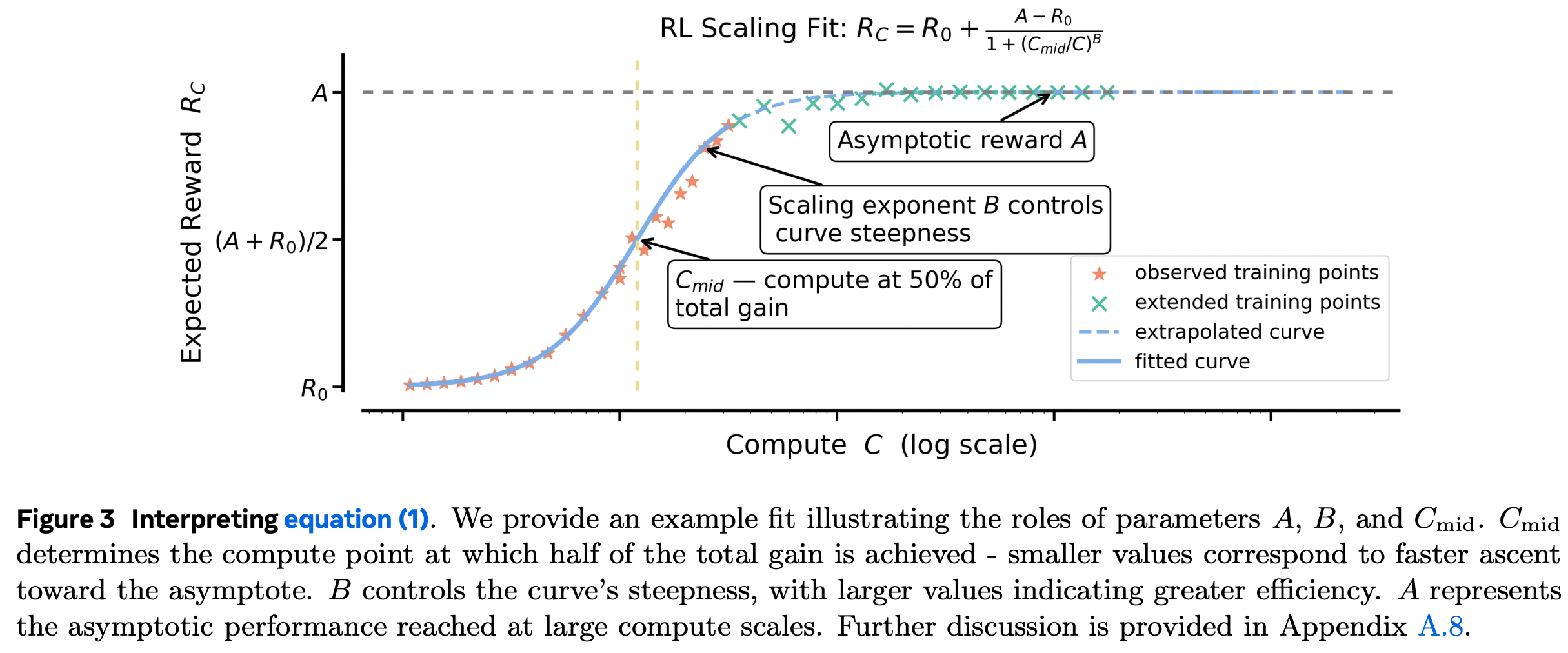
x 轴:使用的 GPU 训练小时数(计算量)
y 轴:验证性能(validation performance)
随着计算量增加,性能上升但趋于饱和 —— 典型的 S 形(logistic)曲线。
是根据样本数据(论文中提取的点),拟合出该 S 型曲线的参数,从而预测达到某一性能所需的计算量;
def logistic_curve(x, B, R0, Cmid, A):return R0 + (A-R0) / (1 + np.power(Cmid/x, B))
- x:GPU 小时数(训练资源)
- y:验证性能
- 参数含义:
- R0:初始性能(训练刚开始的性能)
- A:最终性能上限(asymptote)
- Cmid:达到一半性能增益时的 GPU 小时数(中点)
- B:曲线斜率控制项(增长快慢)
- 曲线形状:
- 当 x 很小时,性能 ≈ R0
- 当 x 很大时,性能 → A
- 当 x = Cmid 时,性能 ≈ (A + R0)/2
- B 越大,曲线越陡峭(增长更快)
- 曲线拟合方式:
- Dense 模型的训练计算量序列 gpu_hours_8b = np.array([i*100 for i in range(1, 74)])*13.25
- 对应验证性能 validation_perf_8b = […]
- Cmid 在 [4000, 16000] 间取 100 个值:C_mid_values = np.linspace(4000, 16000, 100)
- A 在 [0.5, 0.75] 间取步长 0.005:A_values = [i/1000 for i in range(500, 750, 5)]
- 这两个参数通过 网格搜索固定,剩下 B 通过曲线拟合求得。
- 用最小二乘法(scipy.optimize.curve_fit)寻找最佳 B;
- 对每组 (A, Cmid) 计算残差平方和(ss_res);
- 选择误差最小的参数组合作为最优拟合。
2. ScaleRL方案设计
实现初始说明:
- 使用一个8B参数的稠密模型,在可验证的数学题目上进行强化学习实验,从可预测的计算扩展行为角度研究多个设计维度,重点关注其渐近性能(A)和计算效率(B)
- 基础设置:使用 Polaris-53K 数据集,每个 batch 包含 768 个样本(48 个提示,每个提示生成 16 条推理路径)
- 在分布内验证数据上衡量预测性能:从Polaris-53k数据集中随机抽取1,000个提示作为验证集,其余用于训练。扩展曲线基于验证集上的平均通过率进行拟合,每100个训练步骤评估一次,每个提示生成16个样本。
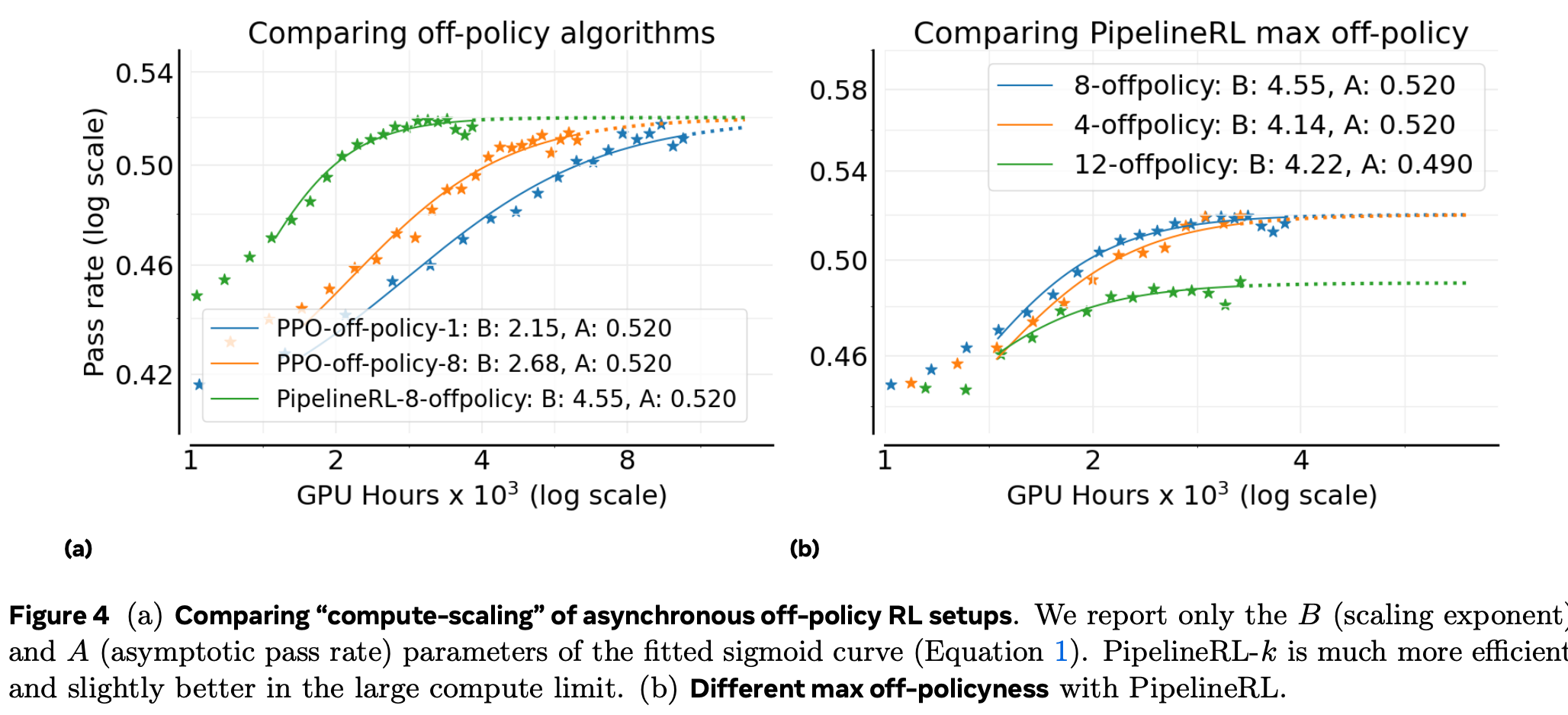
实验阶段一:首先研究异步离策略RL设置的选择,因为它对训练稳定性和效率具有普遍影响,独立于其他设计选择。
比较了两种离策略学习方法:PPO-off-policy-k 和 PipelineRL-k。
-
PPO-off-policy-k
- 异步 RL 默认方案,Qwen3、ProRL 等采用。
- 旧策略 πθoldgen\pi_{\theta_{\text{old}}}^{\text{gen}}πθoldgen 先生成整个 batch 的轨迹,再按 mini-batch 大小 B^\hat BB^ 做 k=B/B^k=B/\hat Bk=B/B^ 次梯度更新。
- 实验固定 B^=48\hat B=48B^=48 个提示(每提示 16 条样本),通过改变总 batch 大小 BBB 来设置 k∈{1,8}k\in\{1,8\}k∈{1,8}。
-
PipelineRL-k
- 流式生成:生成器持续产出轨迹;训练器完成一次更新后立即把新参数推送给生成器,生成器继续用新权重(保留旧 KV-Cache)完成剩余生成。
- 引入参数 kkk:训练器最多允许领先生成器 kkk 步。
- 减少生成器空闲时间,训练-生成耦合更紧密,更接近“准 on-policy”状态。
-
结果显示:图4a显示PipelineRL和PPO-off-policy在渐近性能A上相近,但PipelineRL在计算效率B上显著更优,因此能更快地达到性能上限A。这是因为PipelineRL减少了训练过程中的空闲时间,使得在相同计算预算下可以运行更多实验。我们还测试了PipelineRL的不同最大离策略步数,发现k=8是最优选择(图4b)
实验阶段二:算法设计选择
在确认 PipelineRL-8 作为新的基线后,我们系统研究了 6 个关键算法维度:
- 损失函数类型 比较三种主流选择:
-
DAPO:非对称裁剪 + token 级重要性采样 + prompt-level损失聚合
Token 级重要性权重: ρi,t=πθ(yi,t∣x,yi,<t)πθold(yi,t∣x,yi,<t)\rho_{i,t}= \frac{\pi_\theta(y_{i,t}|x,y_{i,<t})}{\pi_{\theta_{\text{old}}}(y_{i,t}|x,y_{i,<t})}ρi,t=πθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t)
非对称裁剪:clipasym(ρ,1−ε−,1+ε+)ε+≠ε−\text{clip}_{\text{asym}}(\rho,1-\varepsilon^-,1+\varepsilon^+)\quad \varepsilon^+\neq \varepsilon^-clipasym(ρ,1−ε−,1+ε+)ε+=ε− (向上裁剪更宽,防止熵塌缩)
Prompt-level 损失聚合:
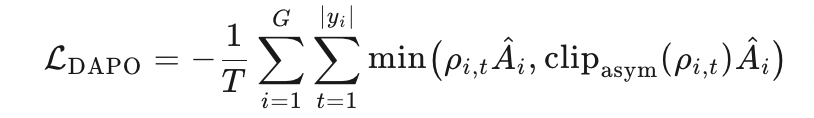
其中 (T=∑i∣yi∣T=\sum_i |y_i|T=∑i∣yi∣) 为总 token 数 -
GSPO:序列级重要性采样(Zheng et al., 2025a)
序列级重要性权重:ρi=πθ(yi∣x)πθold(yi∣x)=∏t=1∣yi∣πθ(yi,t∣x,yi,<t)πθold(yi,t∣x,yi,<t)\rho_i= \frac{\pi_\theta(y_i|x)}{\pi_{\theta_{\text{old}}}(y_i|x)} = \prod_{t=1}^{|y_i|} \frac{\pi_\theta(y_{i,t}|x,y_{i,<t})}{\pi_{\theta_{\text{old}}}(y_{i,t}|x,y_{i,<t})}ρi=πθold(yi∣x)πθ(yi∣x)=∏t=1∣yi∣πθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t)
裁剪/归一化均在 序列level 完成:
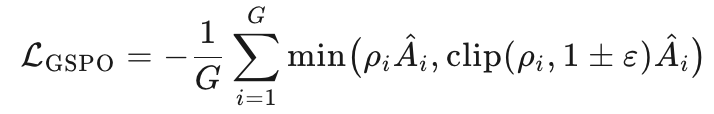
-
CISPO:截断 IS + 停梯度 REINFORCE(MiniMax et al., 2025;Yao et al., 2025)
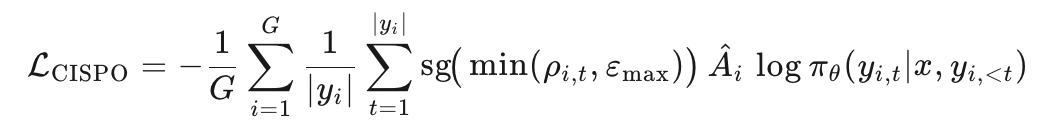
-
FP32 精度修正
生成器与训练器使用不同 kernel,导致 LM Head 处概率微小不一致,进而扭曲 IS 比例。MiniMax 等指出在 Head 层统一用 FP32 可缓解该问题。
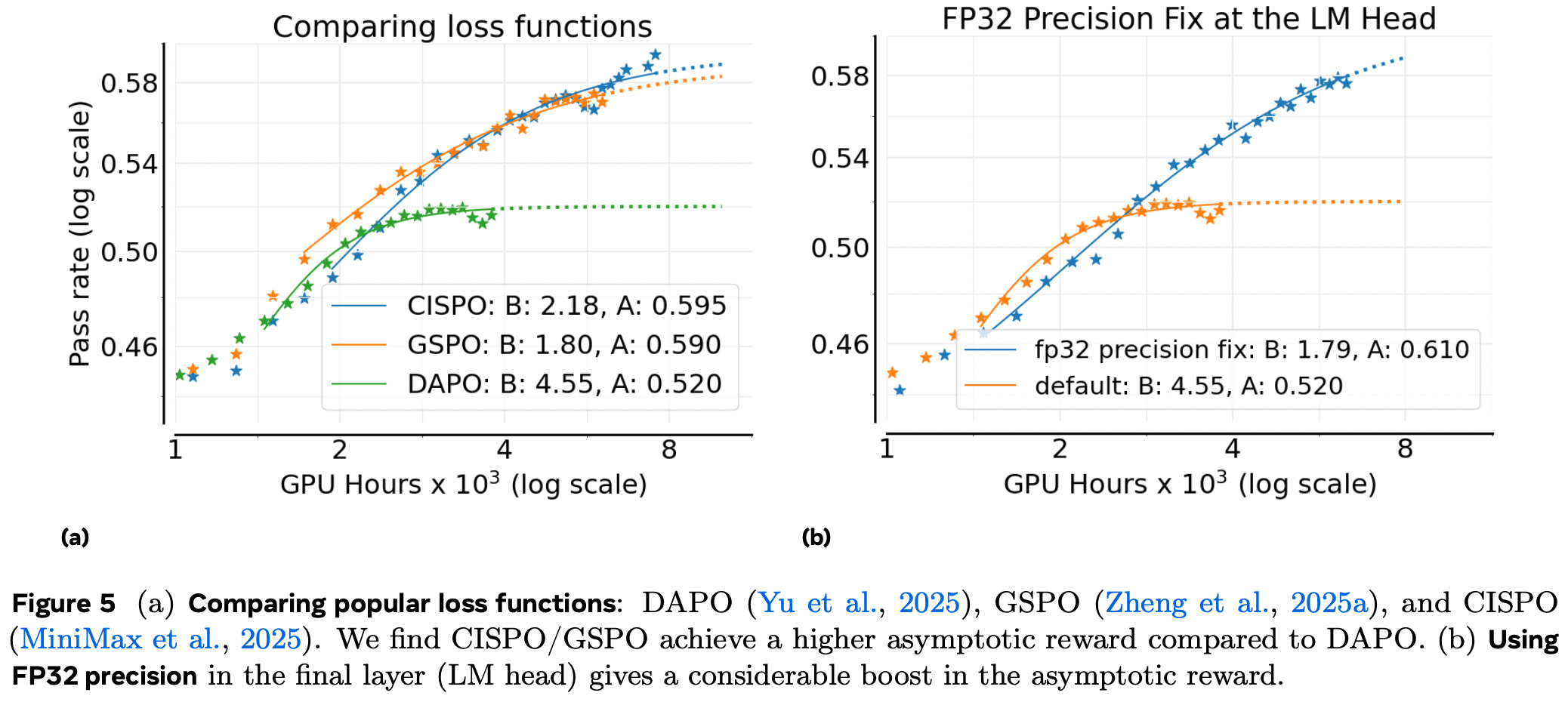
图 5a 显示:GSPO 与 CISPO 的渐近通过率 A 显著高于 DAPO;CISPO 后期略优于 GSPO,因此选为默认损失函数。
图 5b 显示:开启 FP32 后 A 从 0.52 → 0.61,遂纳入 ScaleRL。 -
损失聚合策略 比较三种粒度:
sample-average:(GRPO 默认)
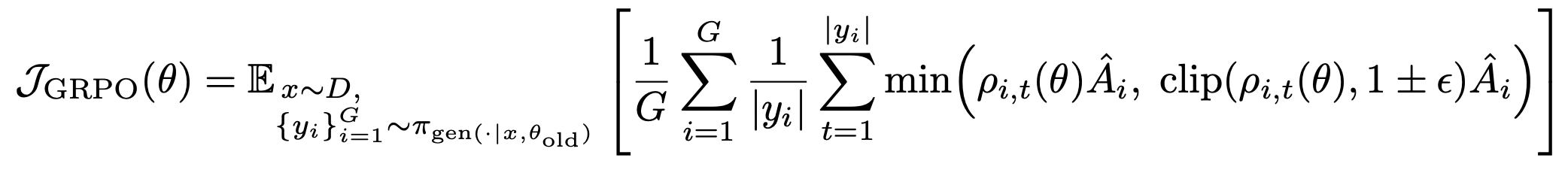
prompt-average:(DAPO 默认)
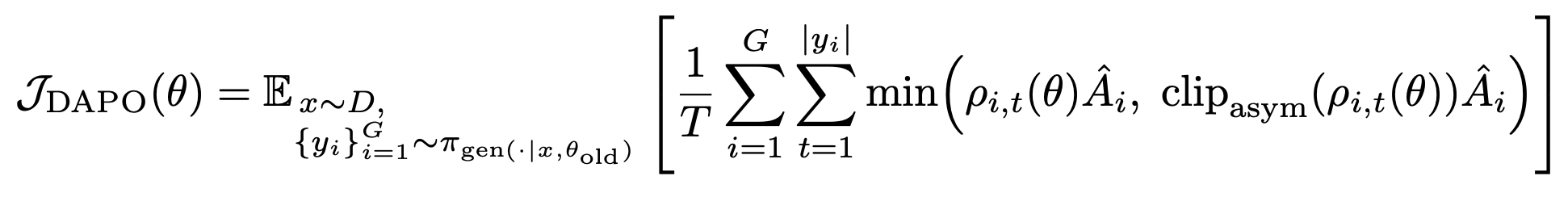
token-average:1个batch中所有 token 直接平均 -
优势归一化 对比:
prompt-level:同一提示的 rollout 内归一化(GRPO)
batch-level:整个 batch 内归一化(Hu et al., 2025a;Magistral)
no-normalization:仅去均值不除标准差(Dr. GRPO)
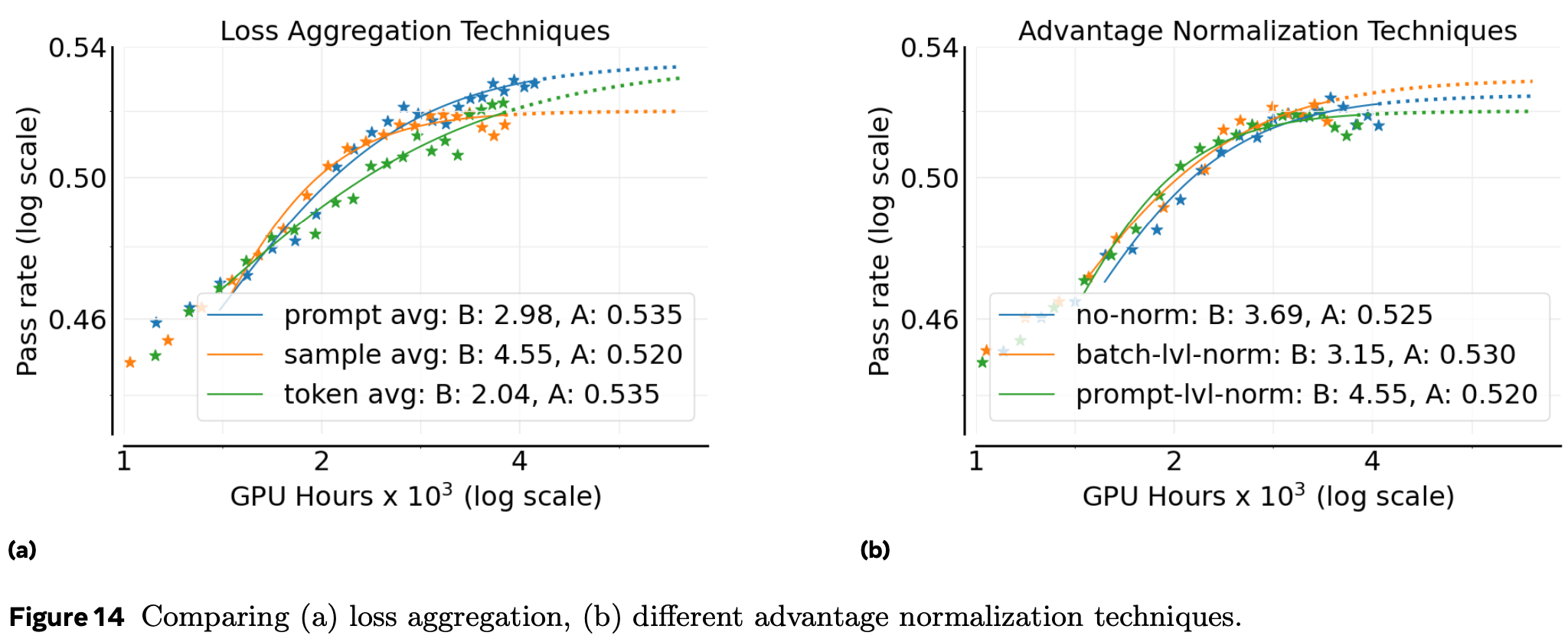
图 14a 结果:prompt-average 的 A 最高,故采用。
图 14b:三者最终性能相近,batch-level 理论上更稳健且略高效,被选为默认。 -
Zero-Variance 过滤:部分提示所有样本奖励相同(方差为 0),对策略梯度无贡献。过滤后只保留方差 >0 的提示
-
自适应 Prompt 过滤:观察到一旦某提示通过率达到 ≥0.9,后续 epoch 继续采样几乎不再提供有效梯度。(实现方式:维护历史通过率,永久剔除高通过率提示。)
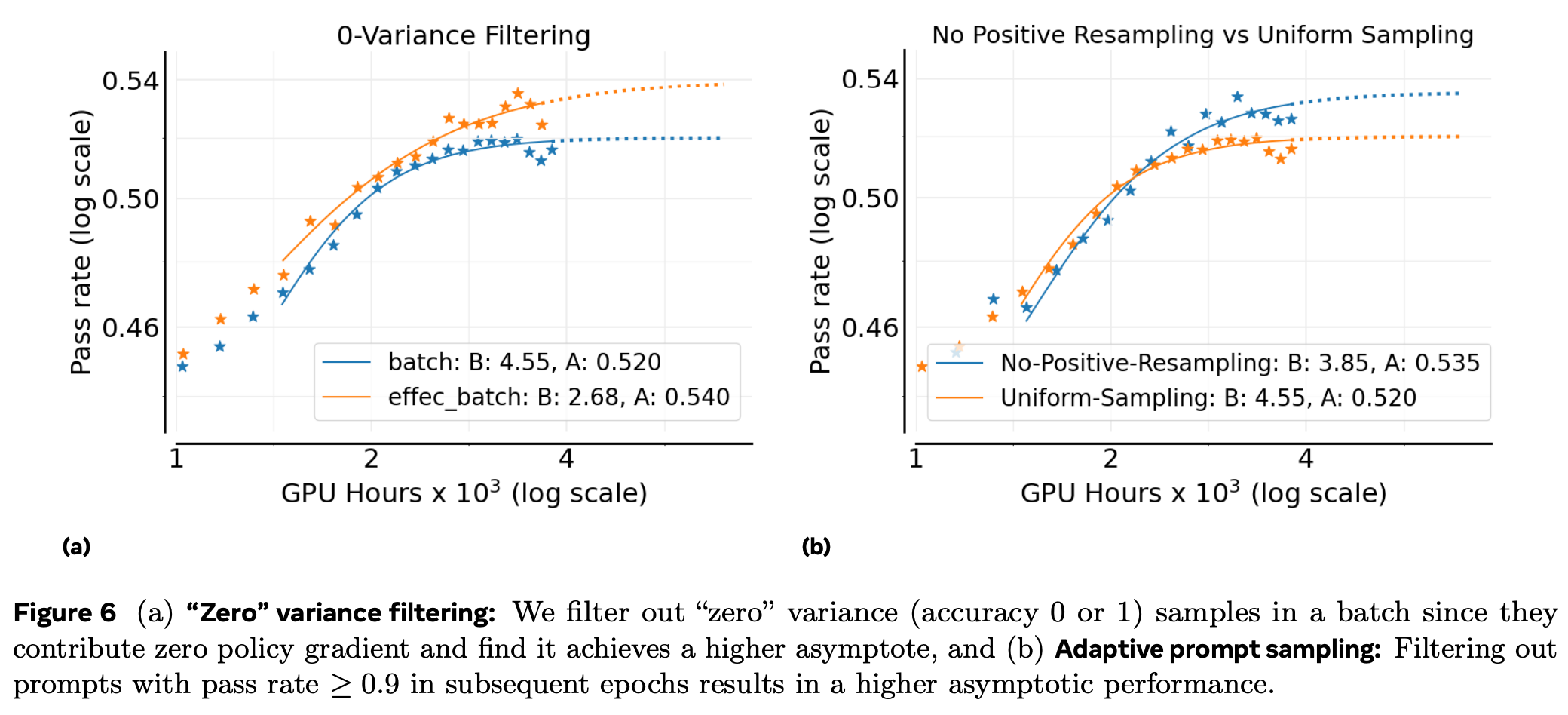
图 6a 显示过滤后 A 提高,ScaleRL 采用此策略。
图 6b 证实该课程策略能提升 A。
ScaleRL设计:
- 基础架构:异步PipelineRL(8步离策略度),减少训练空闲时间,提升效率。
- 损失与优化:CISPO截断重要性采样损失(兼顾稳定性与性能)、提示级损失聚合、批次级优势归一化。
- 稳定性保障:LM头使用FP32精度(缓解数值不匹配)、零方差过滤(剔除无梯度贡献的样本)、强制长度中断(避免生成过长,当思维链超过 10 k-12 k token 时插入
Okay, time is up. Let me stop thinking and formulate a final answer now.)。 - 数据策略:No-Positive-Resampling采样(剔除通过率≥0.9的简单样本),提升样本利用效率。
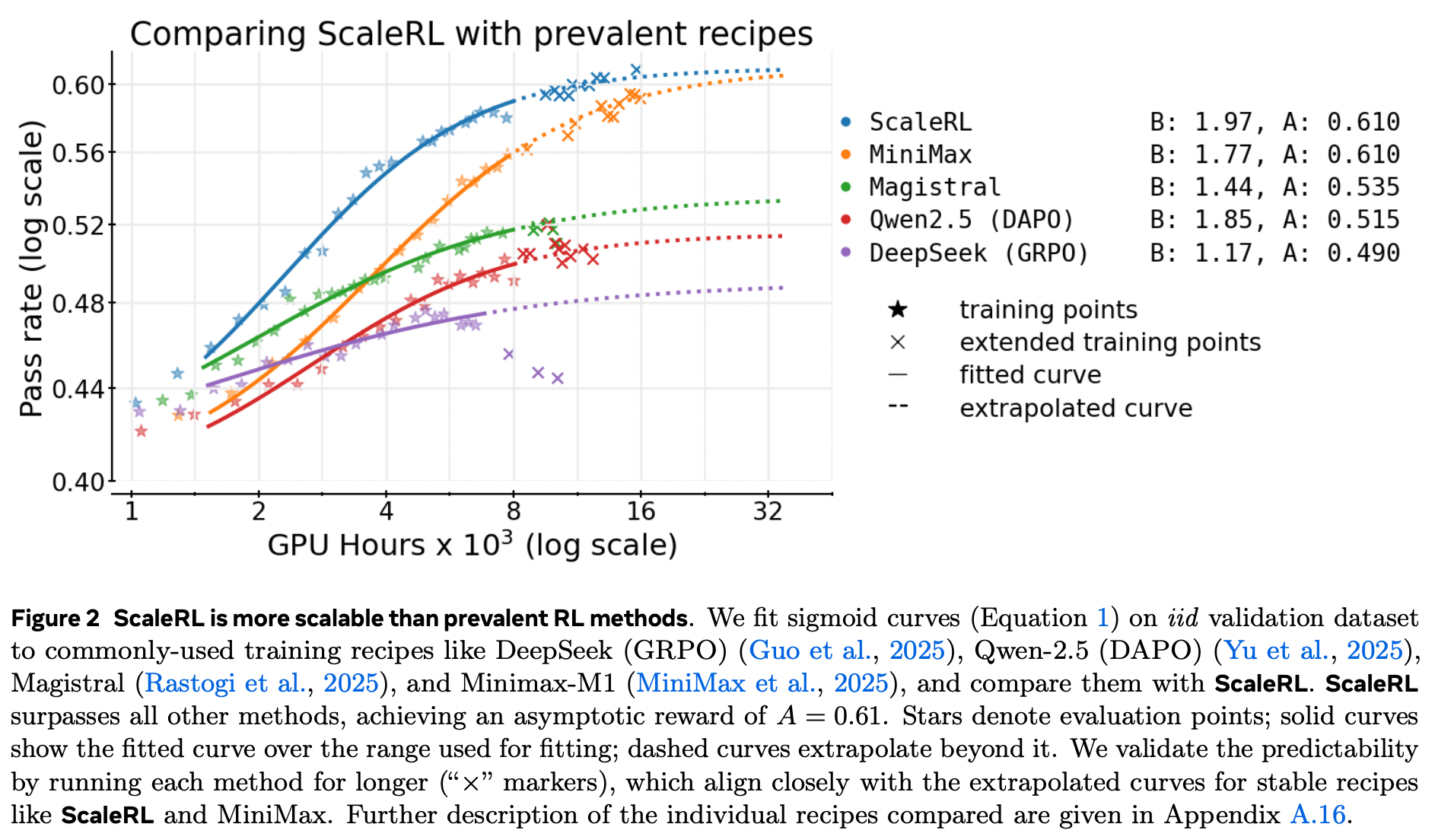
方案优越性:ScaleRL的渐近性能A=0.61,超越DeepSeek(GRPO)、Qwen2.5(DAPO)等主流方案,且计算效率更高(B=1.97)。
3. 留一法(LOO)消融
- 为验证上述每一点在“组合后”仍带来净收益,我们从 ScaleRL 出发,每次回退一个维度到第 2 节的基线设置,单独训练至 16 000 GPU-h。
- 所有 LOO 实验仅使用前 8 000 GPU-h 数据拟合,外推至 16 000 GPU-h,预测曲线与继续训练的实际点重合(图 7、图 8a),表明 ScaleRL 及其变体在大规模下依然稳定、可预测。
- 图 7 汇总了结果:
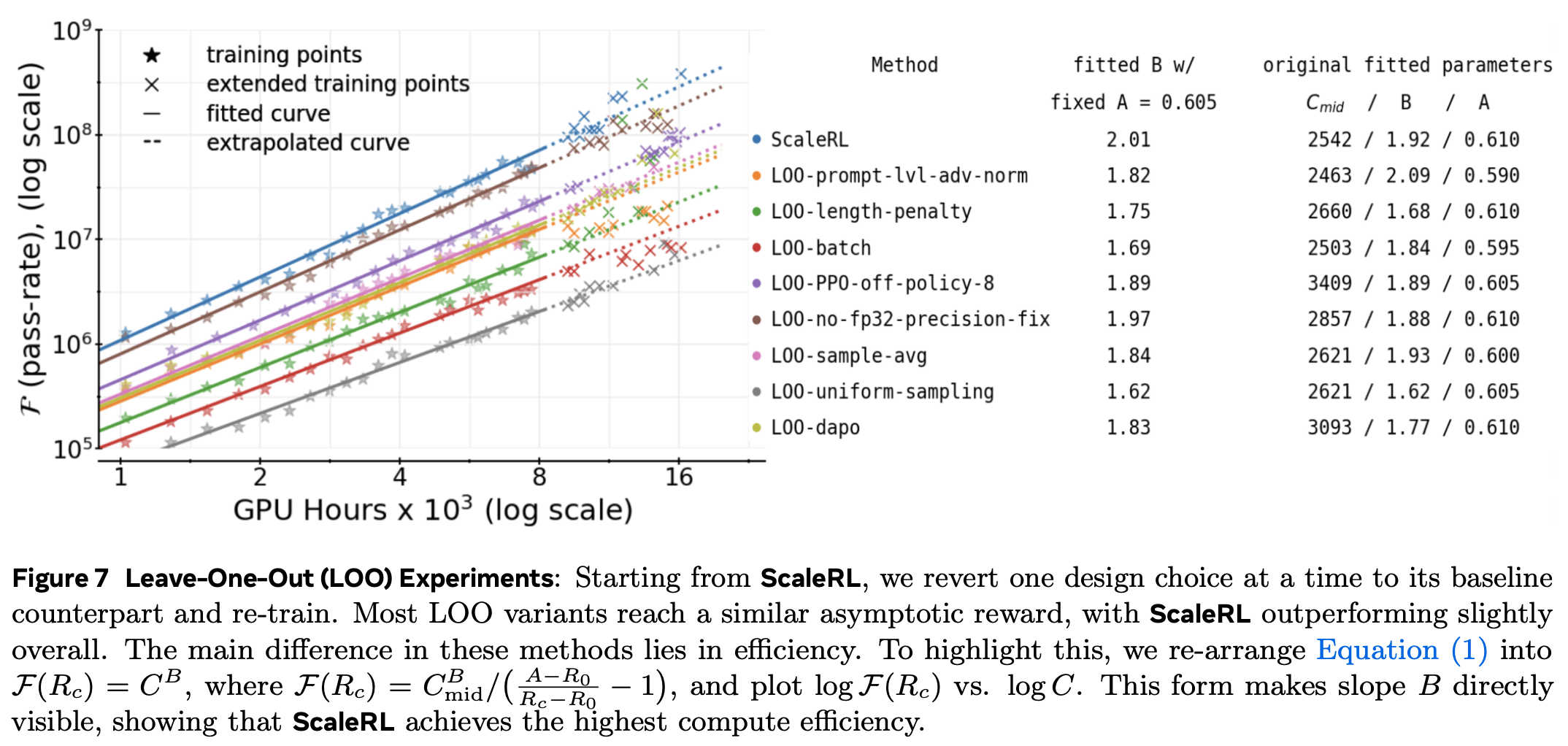
所有 LOO 变体的渐近通过率 A 与 ScaleRL 相近(±0.02 误差带内)。
主要差异体现在 计算效率 B(斜率越陡同样算力下性能越高)。
将 sigmoid 曲线固定 A=0.605 重新拟合,ScaleRL 的 B=2.01,优于任何 LOO 回退,证实每一点都贡献效率。
实验与结果
在固定或持续增加的计算预算下,应如何调整——上下文长度、batch 大小、每提示样本数、还是模型规模——才能最稳妥地获得性能提升?又能多早预测到这种回报?
实验
- 模型规模(MoE)
问题:ScaleRL 在更大模型上仍保持稳定与可预测性吗?
用 17B×16 Llama-4 Scout MoE 训练,曲线与 8B 稠密模型一样可预测(图 1)。
扩展点与拟合线重合,表明配方对模型规模 不变。
17B×16 的渐近性能 A 显著高于 8B,仅用 1/6 的 RL 计算量即可超越 8B 的最终表现。
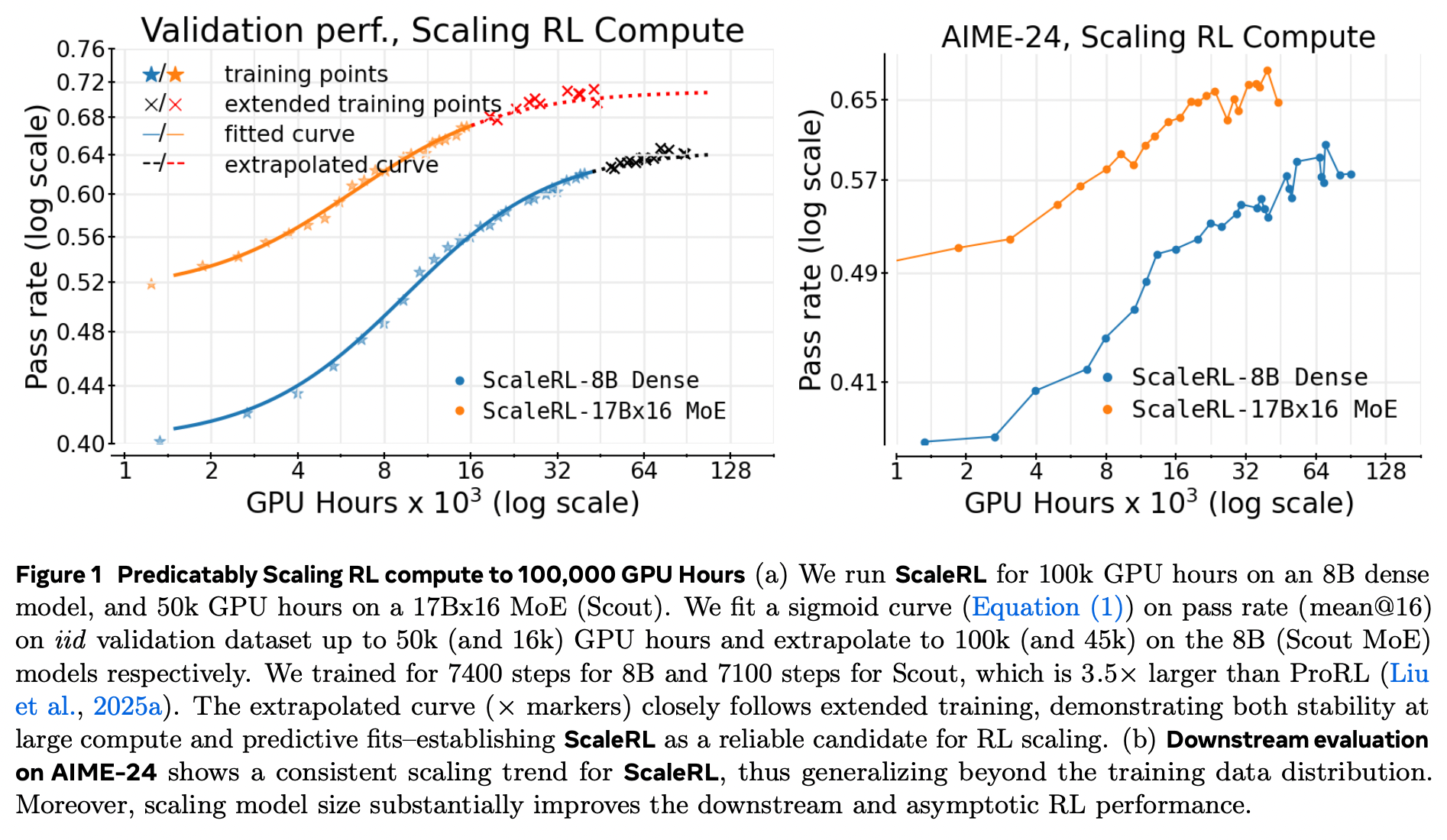
-
生成长度(上下文预算)
将生成长度从 14 k → 32 k token,早期进展变慢(B 降低、C_mid 升高),但 渐近线 A 一致抬高。
图 9 显示:32 k 曲线在足够算力后 全面超越 14 k,验证长上下文 RL 是 抬升天花板 而非单纯牺牲效率。
提前拟合可准确预测 32 k 的最终轨迹。
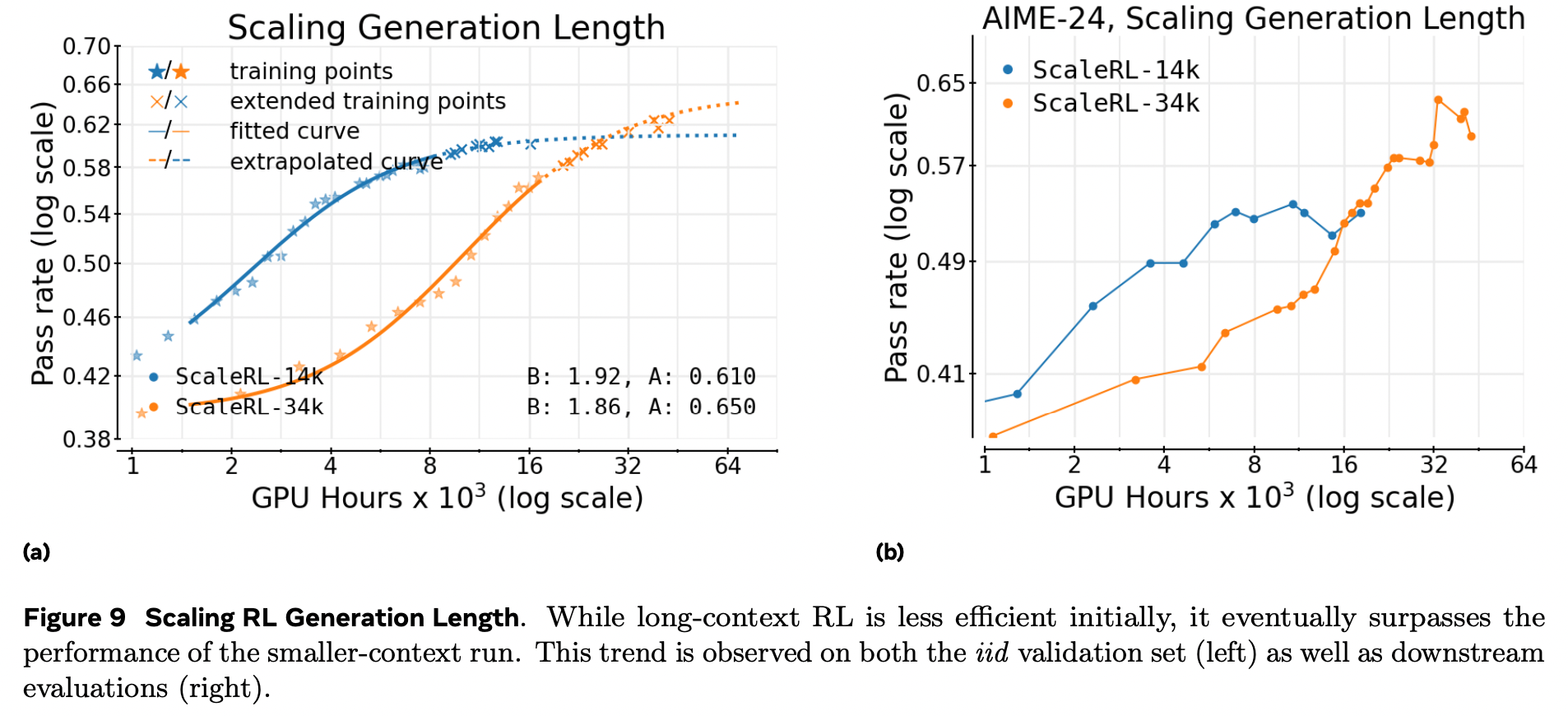
-
全局 batch 大小(提示数)
小 batch 在下游任务上早期便出现停滞,即使验证集仍在提升。
大 batch 可靠地提高 A,并消除下游停滞。
图 10a:batch=512 早期领先,但随计算量增加被 batch=2048 反超。
在最大数学运行中,batch 提到 2048 提示(32 k 样本)既稳定训练,也能用 前 50 k GPU-h 准确外推到 100 k。
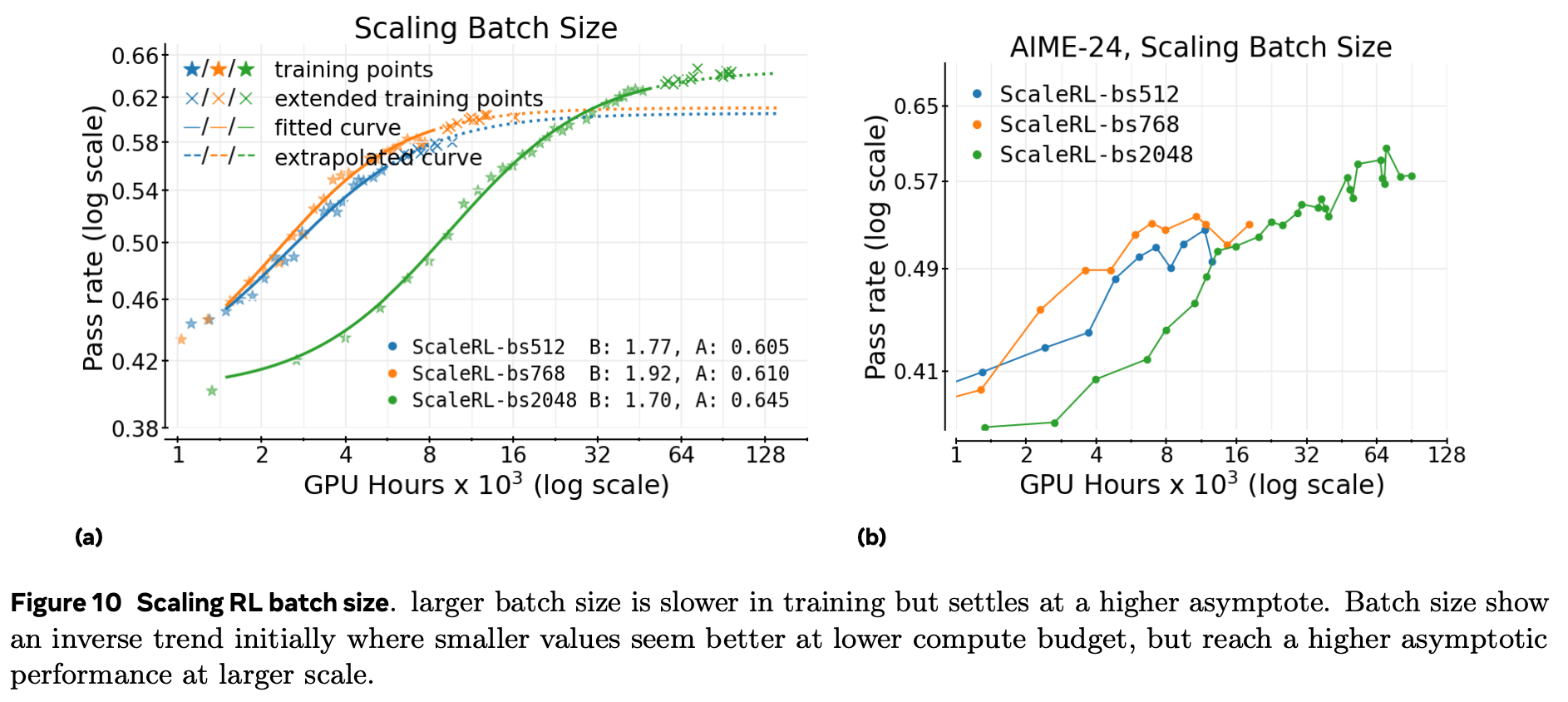
-
每提示样本数(固定总样本数)
固定总样本数,扫描每提示样本数 8→16→24→32,并反向调整提示数,使 batch 总量不变。
拟合曲线 几乎重叠(附录图 17)。
在 中等 batch 规模 下,该维度是 二阶因素;更大 batch(≥2 k)时差异可能显现,留待未来研究。
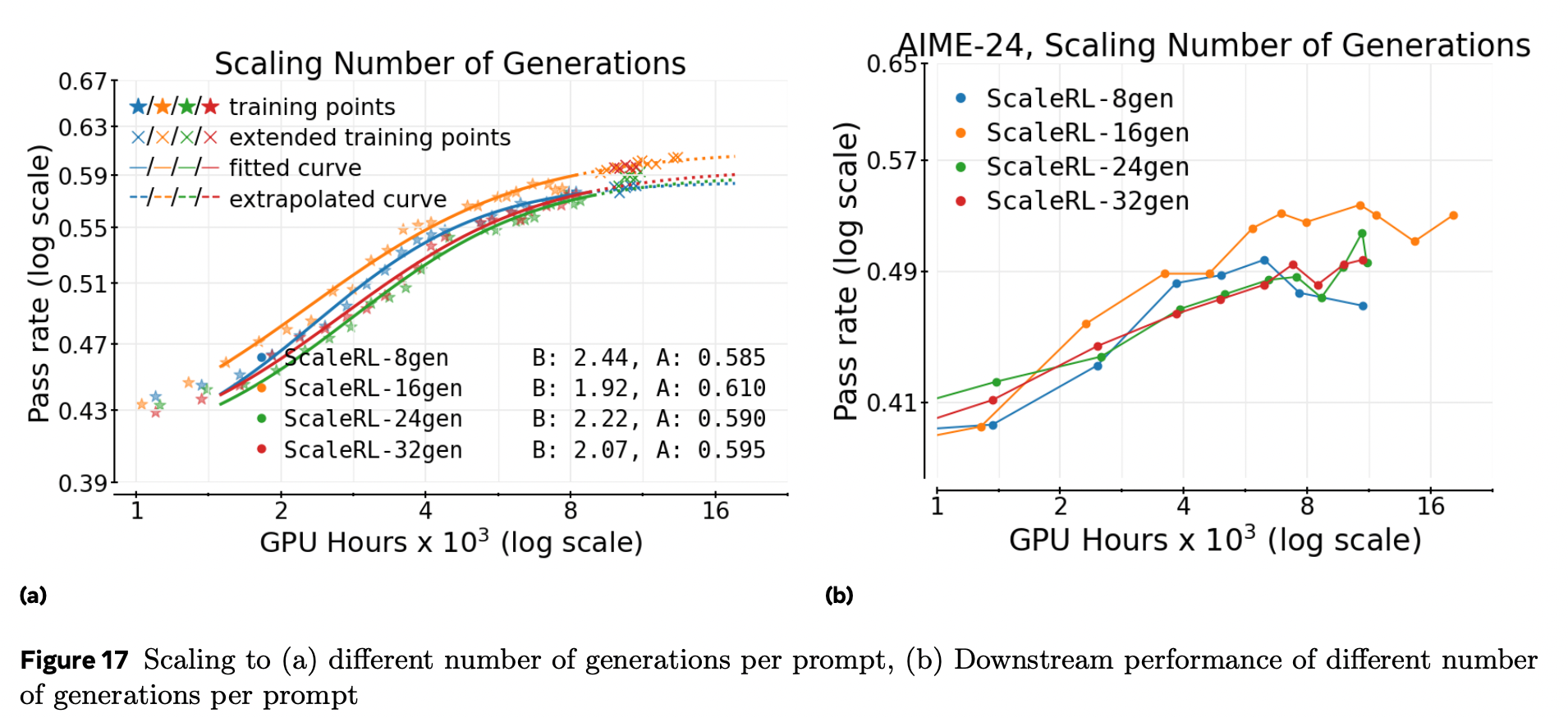
-
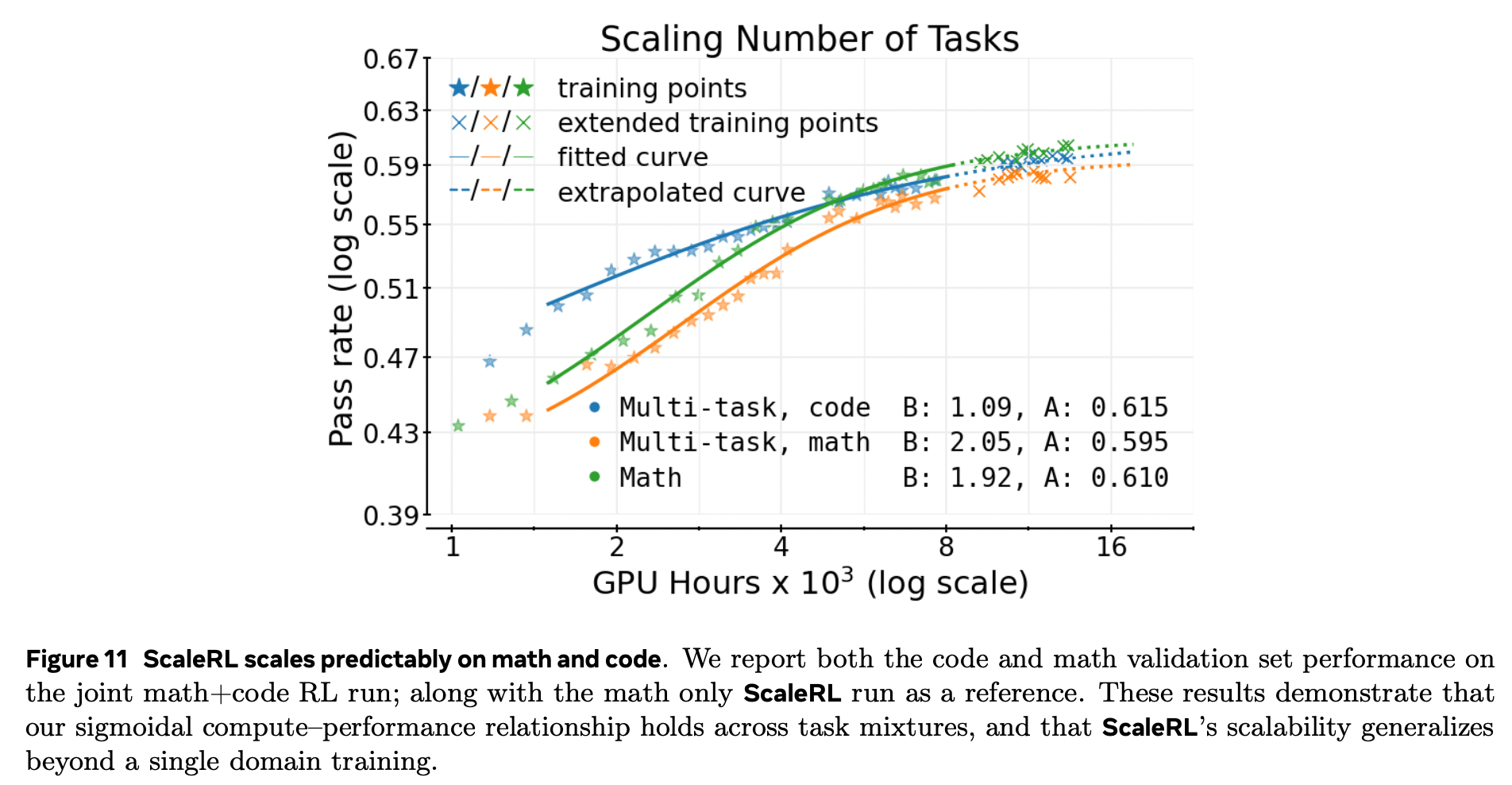
多任务 RL(数学 + 代码)
联合训练数学与代码,两条验证曲线均呈 平行幂律(图 11)。
延长训练与外推线 重合,表明 ScaleRL 的扩展性 跨领域成立。
初步结果鼓励在未来对更复杂多任务组合进行可预测扩展研究。
关键结果
- 方案优越性:ScaleRL的渐近性能A=0.61,超越DeepSeek(GRPO)、Qwen2.5(DAPO)等主流方案,且计算效率更高(B=1.97)。
- 预测性验证:基于50k GPU小时数据拟合的曲线,能精准预测10万GPU小时的性能,误差≤0.02。
- 多维度扩展性:
- 模型规模:17B MoE模型仅用8B模型1/6的计算量,就达到更高渐近性能(A=0.71)。
- 生成长度:32k tokens训练虽初期效率低,但最终渐近性能高于14k tokens(A=0.65 vs 0.61)。
- 批次大小:2048批次虽训练速度慢,但避免了小批次的下游性能停滞,渐近性能更优。
总结与启示
核心结论
-
RL规模化的关键是“先提上限再提效率”:
- 损失类型、FP32精度主要影响性能上限(A);
- loss 聚合、归一化、数据课程学习、长度惩罚等干预主要调节计算效率 B,对天花板 A 影响有限。
-
可预测性是规模化的前提:稳定的RL方案(如ScaleRL)遵循可重复的S形缩放轨迹,小规模实验即可指导大规模部署。
-
组合优化优于单点创新:ScaleRL无全新算法,而是通过系统性整合现有技术,解决了规模化中的稳定性、效率和预测性问题。
实践启示
- 对研究者:可利用S形曲线框架,低成本评估新RL方法的规模化潜力,减少计算资源浪费。
- 对工程落地:优先选择CISPO损失、PipelineRL架构、FP32精度等组件,兼顾性能与稳定性;监控截断率(建议控制在5%以下)可预警训练不稳定。
- 未来方向:需进一步探索预训练计算量、模型大小、RL数据量的联合缩放定律,以及多任务、长文本推理等场景的规模化方法。
局限性与展望
- 局限:实验主要集中在数学推理领域,多语言、多模态等场景的泛化性需进一步验证。
- 未来:可扩展至多轮RL、智能体交互等场景,结合结构化奖励和生成式验证器,优化RL计算资源分配。