Hello-Agents第二章深度解析:智能体的进化之路——从符号逻辑到AI原生
Hello-Agents第二章深度解析:智能体的进化之路——从符号逻辑到AI原生
第二章作为Hello-Agents的“历史与理论基石篇”,以“问题驱动进化”为核心脉络,梳理了智能体从古典符号逻辑到现代LLM驱动的完整演进历程。本章不仅揭示了每一代智能体范式的核心思想与局限,更通过经典案例(如MYCIN、ELIZA)和技术迭代,构建了“问题→解决方案→新局限→新范式”的进化逻辑。本文将从核心理论拆解、经典代码解析、课后习题详解三个维度,带大家吃透第二章的关键知识点,理解智能体技术选型背后的历史必然性。
一、核心理论:智能体的进化逻辑与关键范式
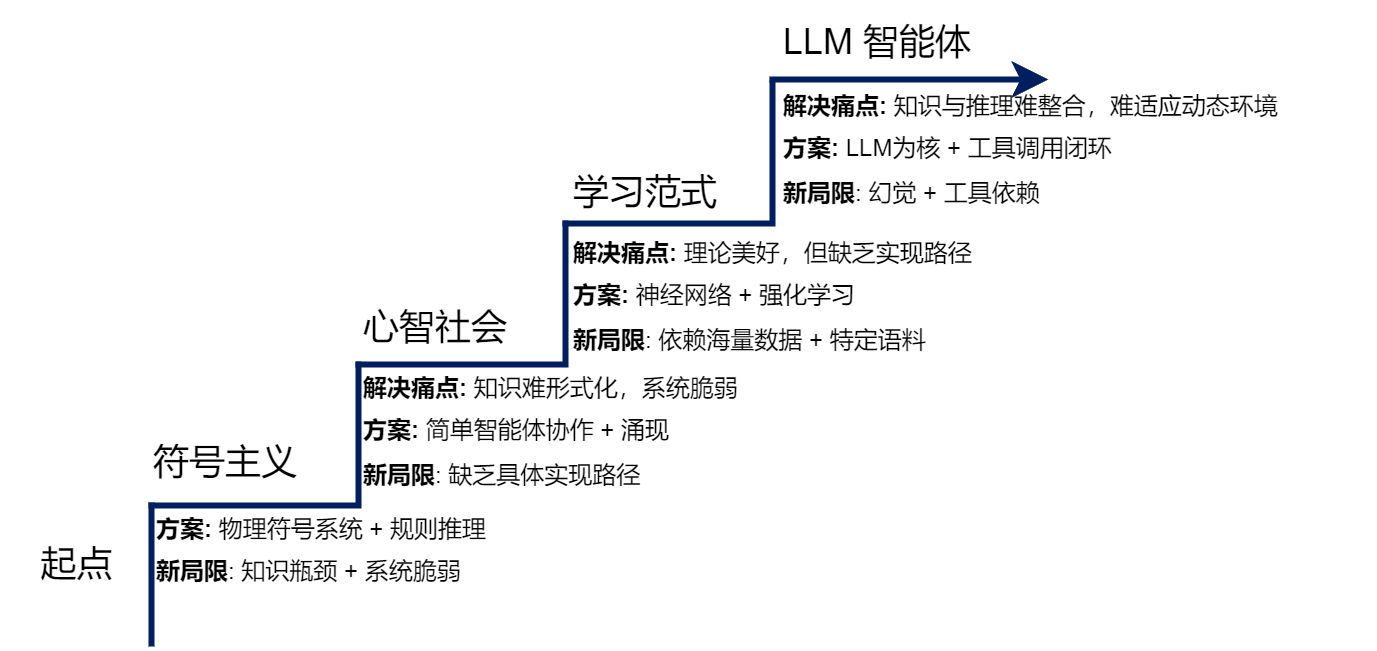
1.1 符号主义:智能的“规则编码时代”
符号主义是人工智能的第一个重要范式,核心信念是“智能源于对符号的逻辑操作”,其理论基石是物理符号系统假说(PSSH)。
核心假说解析
该假说包含两个关键论断,用通俗语言解释:
- 充分性论断:任何物理符号系统(能处理符号的物理实体,如计算机),都具备产生通用智能行为的潜力(只要符号操作规则足够完备)。
- 必要性论断:任何能展现通用智能的系统,本质上必然是物理符号系统(智能的核心一定是符号处理)。
简单说,符号主义认为“智能就是按规则处理符号”,就像图书馆管理员按分类规则整理书籍——符号是“书籍”,规则是“分类标准”,智能体是“管理员”。
代表成果与实践
- 专家系统(MYCIN):医疗诊断领域的里程碑,核心是“知识库+推理机”架构。知识库存储600条医学规则(如“IF发烧AND咳嗽→呼吸道感染”),推理机通过反向链推理(从“确定致病菌”目标反向推导所需证据)解决诊断问题,还引入置信因子(CF)处理医学不确定性。
- SHRDLU:“积木世界”智能体,首次集成语言理解、规划、记忆模块,能通过自然语言与虚拟积木交互(如“把蓝色积木放到红色积木上”),证明了在封闭环境中符号系统的有效性。
根本性局限
符号主义的衰落源于两个无法克服的痛点:
- 知识获取瓶颈:规则需人工编码,专家的内隐知识(如医生的直觉)难以转化为“IF-THEN”规则,且规模化构建知识库成本极高。
- 系统脆弱性:规则仅适用于封闭场景,遇到未覆盖的例外情况(如MYCIN遇到未知致病菌)就会失灵,即“框架问题”——无法高效判断动态世界中哪些事物未发生改变。
1.2 心智社会:分布式智能的思想萌芽
面对符号主义的局限,马文·明斯基提出**“心智社会”理论**,核心颠覆是“智能并非源于单一完美系统,而是大量简单智能体的协作涌现”。
核心思想拆解
- 简单智能体:每个智能体是“无心”的专门化过程(如识别线条的LINE-FINDER、负责抓握的GRASP),自身无复杂智能。
- 协作与涌现:简单智能体通过激活/抑制信号交互,形成功能更强的“机构”,复杂智能行为从局部交互中自发产生(如“搭建积木塔”需FIND-BLOCK、GRASP、PUT-ON-TOP等智能体协作)。
- 去中心化:无中央控制器,智能体间通过简单规则交互,类似人类社会的分工协作。
对多智能体系统的影响
该理论直接启发了分布式人工智能(DAI),奠定了三大核心思想:
- 去中心化控制:无中心节点,避免单点故障,适配复杂协作场景。
- 涌现式计算:复杂解决方案从简单局部规则中产生(如蚁群算法)。
- 智能体社会性:强调智能体间的通信、协商与信任,构建“计算社会”。
1.3 学习范式演进:从“人工编码”到“自主学习”
符号主义的局限催生了“学习范式”,核心转变是“智能不再依赖人工编码,而是从数据/经验中自主获取”,经历了三个关键阶段:
(1)联结主义:神经网络的崛起
- 核心思想:模仿生物大脑神经网络,知识以“连接权重”的形式分布式存储,而非显式规则。
- 关键突破:每个神经元仅执行简单计算(加权输入→激活函数→输出),通过反向传播算法迭代调整权重,自主学习数据中的模式。
- 优势与意义:解决了符号主义的“知识获取瓶颈”,能处理图像、声音等非结构化数据,鲁棒性更强(对噪声数据不敏感)。
(2)强化学习:交互中的“试错学习”
- 核心逻辑:智能体通过与环境的“感知-行动-奖励”循环自主优化策略,目标是最大化长期累积奖励(而非即时奖励)。
- 核心要素拆解(用AlphaGo举例):
- 智能体(Agent):AlphaGo的决策程序;
- 环境(Environment):围棋规则与对手;
- 状态(State):棋盘上棋子的当前位置;
- 行动(Action):落子位置;
- 奖励(Reward):赢棋得正向奖励,输棋得负向奖励。
- 学习过程:通过千万次自我对弈,AlphaGo从“试错”中调整策略,发现超越人类的棋路,体现了“从经验中学习”的核心优势。
(3)预训练-微调范式:大模型的诞生
- 核心逻辑:分两步实现通用能力与任务适配:
- 预训练阶段:在海量通用文本上通过自监督学习(如“预测下一个词”),让模型内化语言规律、事实知识与逻辑;
- 微调阶段:用少量特定任务标注数据调整模型,使其适配具体场景(如翻译、问答)。
- 关键突破:解决了符号主义的“泛化能力差”和强化学习的“数据依赖”问题,模型规模跨越阈值后会涌现出上下文学习、思维链推理等能力。
1.4 现代智能体:LLM驱动的“多模块协同架构”
LLM的出现融合了符号主义、联结主义、行为主义的优势,形成了现代智能体的核心架构,其运行机制是“感知-思考-行动-观察”的闭环:
- 感知:通过传感器(API、用户输入)获取环境观察;
- 思考:LLM作为核心,结合记忆模块(短期/长期记忆)进行规划、推理与决策;
- 行动:调用工具(搜索、代码执行、API)改变环境;
- 观察:接收工具反馈与环境变化,更新记忆并启动下一轮循环。
该架构实现了“直觉(亚符号)+理性(符号)”的协同,是神经符号主义的典型实践——LLM内核是神经网络(亚符号),生成的思想、API调用等是结构化符号。
二、经典代码解析:ELIZA聊天机器人——符号主义的实践缩影
第二章通过复现ELIZA(1966年诞生的经典聊天机器人),直观展示了符号主义的核心逻辑——“模式匹配+文本替换”。以下是代码的逐模块深度解析:
2.1 代码整体功能
ELIZA的核心是“伪装理解”:通过识别用户输入中的关键词和模式,应用预设规则将用户陈述转化为开放式提问,无需真正理解语义(如用户说“我为男朋友难过”,ELIZA回应“你为什么会为男朋友难过?”)。
2.2 核心模块拆解
(1)规则库:符号匹配的“核心引擎”
rules = {r'I need (.*)': ["Why do you need {0}?","Would it really help you to get {0}?","Are you sure you need {0}?"],r'Why don\'t you (.*)\?': ["Do you really think I don't {0}?","Perhaps eventually I will {0}.","Do you really want me to {0}?"],# 其他规则...r'.*': [ # 通配符规则,匹配所有未命中的输入"Please tell me more.","Let's change focus a bit... Tell me about your family.","Can you elaborate on that?"]
}
- 功能:定义“输入模式→响应模板”的映射,是符号主义“规则编码”的直接体现。
- 关键逻辑:
- 键(pattern):正则表达式,用于匹配用户输入中的特定模式(如
r'I need (.*)'匹配“我需要XXX”类句子); - 值(responses):响应模板列表,
{0}是占位符,用于填充正则匹配到的内容(如用户说“我需要帮助”,{0}替换为“帮助”); - 通配符规则(
r'.*'):兜底机制,确保所有输入都能得到响应,避免系统崩溃。
- 键(pattern):正则表达式,用于匹配用户输入中的特定模式(如
(2)代词转换:对话连贯性的“关键技巧”
pronouns_swap = {"i": "you", "you": "i", "me": "you", "my": "your","am": "are", "are": "am", "was": "were", "i'd": "you would","i've": "you have", "i'll": "you will", "yours": "mine", "mine": "yours"
}def swap_pronouns(phrase):words = phrase.lower().split() # 转为小写并分词swapped_words = [pronouns_swap.get(word, word) for word in words] # 替换代词return " ".join(swapped_words) # 重组句子
- 功能:解决“人称一致性”问题,让回应更自然(如用户说“我需要我的书”,匹配
I need (.*)后,{0}为“我的书”,经转换为“你的书”,响应变为“Why do you need your book?”)。 - 实现逻辑:
- 先将输入转为小写(避免大小写敏感,如“I”和“i”统一处理);
- 遍历每个单词,若在
pronouns_swap中则替换,否则保持原样; - 重组单词为完整句子,确保语法连贯。
(3)响应生成:模式匹配与模板填充
def respond(user_input):for pattern, responses in rules.items():match = re.match(pattern, user_input, re.IGNORECASE) # 忽略大小写匹配if match:captured_group = match.group(1) if match.groups() else '' # 提取匹配内容swapped_group = swap_pronouns(captured_group) # 代词转换response = random.choice(responses).format(swapped_group) # 随机选模板并填充return responsereturn random.choice(rules[r'.*']) # 兜底响应
- 核心流程(以用户输入“I need my phone”为例):
- 匹配规则:
re.match(r'I need (.*)', user_input)命中规则,match.group(1)提取“my phone”; - 代词转换:“my phone”转为“your phone”;
- 生成响应:从该规则的3个模板中随机选一个(如“Why do you need your phone?”)并返回。
- 匹配规则:
- 关键逻辑:
re.IGNORECASE确保匹配不受大小写影响(如“i need”“I Need”都能命中),提升系统鲁棒性。
(4)主循环:交互式对话的“入口”
if __name__ == '__main__':print("Therapist: Hello! How can I help you today?")while True:user_input = input("You: ")if user_input.lower() in ["quit", "exit", "bye"]:print("Therapist: Goodbye. It was nice talking to you.")breakresponse = respond(user_input)print(f"Therapist: {response}")
- 功能:实现用户与机器人的持续交互,直到用户输入退出指令(quit/exit/bye)。
- 特点:无状态设计——每次响应仅基于当前输入,不记忆历史对话,这是符号主义系统的典型局限。
2.3 代码的局限性(呼应章节理论)
ELIZA的设计清晰暴露了符号主义的核心问题:
- 无语义理解:仅机械匹配模式,无法真正理解含义(如用户说“I am not happy”,仍会匹配
I am (.*)生成语义不通的响应); - 无上下文记忆:每次响应独立,无法进行连贯多轮对话;
- 规则扩展性差:新增场景需手动添加大量规则,规则库规模会爆炸式增长,且易出现规则冲突。
三、课后习题详细解答
说明:以下习题仅为个人见解,若有疏漏,欢迎批评指正~
习题1:物理符号系统假说的理解与挑战
题干:
物理符号系统假说[1]是符号主义时代的理论基石。请分析:
- 该假说的"充分性论断"和"必要性论断"分别是什么含义?
- 结合本章内容,说明符号主义智能体在实践中遇到的哪些问题对该假说的"充分性"提出了挑战?
- 大语言模型驱动的智能体是否符合物理符号系统假说?
解答:
-
论断含义解析:
- 充分性论断:任何物理符号系统(能处理符号的物理实体,如计算机),都具备产生通用智能行为的“充分条件”——只要能按规则操作符号,就能展现智能。
- 必要性论断:任何能展现通用智能的系统,其本质“必然是”物理符号系统——智能的核心机制一定是符号处理。
-
对充分性论断的挑战(基于符号主义局限):
- 知识获取瓶颈:物理符号系统依赖完备的人工编码规则,但现实世界知识海量且模糊,专家的内隐知识(如医生的诊断直觉)无法转化为符号规则,导致系统无法覆盖复杂场景。
- 系统脆弱性:符号系统仅适用于封闭环境,遇到未预设的例外情况(如SHRDLU无法处理积木世界外的指令)就会失灵,无法像人类一样灵活变通。
- 框架问题:动态环境中,符号系统无法高效判断“哪些事物未发生改变”,需显式编码所有不变状态,计算成本极高。
-
LLM驱动的智能体与假说的关系:
- 不完全符合物理符号系统假说:
- 相同点:LLM生成的中间步骤(如思想、API调用、逻辑推理链)是结构化符号,具备“符号操作”的特征;
- 不同点:LLM的知识存储形式是神经网络的连接权重(亚符号),而非显式符号规则,其智能源于统计模式学习而非逻辑操作,突破了“物理符号系统是智能必要条件”的论断。
- 结论:LLM智能体是神经符号主义的融合产物,既包含符号操作的理性,又具备亚符号的直觉,不完全属于物理符号系统。
- 不完全符合物理符号系统假说:
习题2:MYCIN系统的局限与现代改进
题干:
专家系统MYCIN[2]在医疗诊断领域取得了显著成功,但最终并未大规模应用于临床实践。请思考:
- 除了本章提到的"知识获取瓶颈"和"脆弱性",还有哪些因素可能阻碍了专家系统在医疗等高风险领域的应用?
- 如果让现在的你设计一个医疗诊断智能体,你会如何设计系统来克服MYCIN的局限?
- 在哪些垂直领域中,基于规则的专家系统至今仍然是比深度学习更好的选择?请举例说明。
解答:
-
阻碍大规模应用的其他因素:
- 伦理风险:医疗诊断直接关系生命安全,符号系统的“黑箱推理”(规则链复杂难以追溯)无法提供可解释的诊断依据,一旦出错难以追责。
- 法律障碍:临床医疗需符合医疗规范,专家系统的诊断结果缺乏法律认可的有效性证明,医院和医生面临法律风险。
- 用户接受度:医生习惯基于自身经验和完整病历诊断,对机械的规则化诊断系统缺乏信任,且系统无法处理患者的个性化情况(如基础病史、生活习惯)。
- 维护成本高:医疗知识更新快(如新药、新诊断标准),需持续手动更新规则库,长期维护成本远超预期。
-
现代医疗诊断智能体的设计方案(克服MYCIN局限):
- 融合神经符号主义:以LLM为核心(处理自然语言病历、模糊语义),结合符号化医学知识图谱(确保诊断逻辑可追溯),实现“直觉+理性”协同。
- 引入记忆与学习能力:通过强化学习(RLHF)从临床数据中自主优化诊断规则,而非人工编码;加入长期记忆模块,记录患者历史病历,支持个性化诊断。
- 可解释性设计:生成“诊断逻辑链”(如“因患者发烧+咳嗽+血常规白细胞升高→推荐胸片检查→排除肺炎→诊断上呼吸道感染”),满足医疗伦理和法律要求。
- 人机协同机制:智能体提供诊断建议和依据,最终决策权交给医生,同时允许医生修正诊断结果,修正数据反向用于模型优化。
-
专家系统仍更优的垂直领域:
- 金融风控(信用卡欺诈检测):规则明确(如“单日异地消费3次+单次金额超5万→触发风控”)、可解释性要求高、需严格符合监管规则,专家系统透明可控,优于深度学习的黑箱决策。
- 工业设备故障诊断(如电梯故障):故障与原因的对应关系明确(如“电梯门无法关闭→传感器故障或门机电机故障”),规则固定且更新频率低,专家系统开发维护成本更低。
- 法律文书审核(合同条款合规性):法律条款是明确的符号规则(如“劳动合同需包含试用期、工资标准”),专家系统可精准匹配合规条款,避免深度学习的误判。
习题3:ELIZA的扩展实践与对比
题干:
在2.2节中,我们实现了一个简化版的ELIZA聊天机器人。请在此基础上进行扩展实践:
- 为ELIZA添加3-5条新的规则,使其能够处理更多样化的对话场景(如谈论工作、学习、爱好等)
- 实现一个简单的"上下文记忆"功能:让ELIZA能够记住用户在对话中提到的关键信息(如姓名、年龄、职业),并在后续对话中引用
- 对比你扩展后的ELIZA与ChatGPT,列举至少3个维度上存在的本质差异
- 为什么基于规则的方法在处理开放域对话时会遇到"组合爆炸"问题并且难以扩展维护?能否使用数学的方法来说明?
解答:
(1)新增规则实现(处理工作、学习、爱好场景)
# 新增规则添加到原有rules字典中
rules.update({r'I work as (.*)': ["What do you like most about being a {0}?","How did you become a {0}?","Does working as a {0} bring you satisfaction?"],r'I am studying (.*)': ["What challenges do you face while studying {0}?","Why did you choose to study {0}?","How do you feel about your progress in {0}?"],r'I like (.*) as a hobby': ["How often do you enjoy {0}?","What do you love most about {0}?","Have you met other people who share your hobby of {0}?"],r'I hate (.*) at work': ["What makes {0} so frustrating for you?","Have you tried to change how you deal with {0}?","How does {0} affect your overall work experience?"],r'My name is (.*)': ["Nice to meet you, {0}! Tell me more about yourself.","Hello {0}! What brings you here today?","Great to know you, {0}! How have you been lately?"]
})
(2)上下文记忆功能实现
# 初始化记忆字典,存储用户关键信息
user_memory = {"name": None, "age": None, "job": None, "hobby": None}def extract_memory(user_input, memory):"""从用户输入中提取关键信息并更新记忆"""# 提取姓名name_match = re.search(r'My name is (.*?)(\.|!|\s|$)', user_input, re.IGNORECASE)if name_match and not memory["name"]:memory["name"] = name_match.group(1).strip()# 提取年龄age_match = re.search(r'I am (\d+) years old', user_input, re.IGNORECASE)if age_match and not memory["age"]:memory["age"] = age_match.group(1)# 提取职业job_match = re.search(r'I work as (.*?)(\.|!|\s|$)', user_input, re.IGNORECASE)if job_match and not memory["job"]:memory["job"] = job_match.group(1).strip()# 提取爱好hobby_match = re.search(r'I like (.*?) as a hobby', user_input, re.IGNORECASE)if hobby_match and not memory["hobby"]:memory["hobby"] = hobby_match.group(1).strip()return memory# 修改respond函数,融入记忆引用
def respond(user_input, memory):# 先提取记忆memory = extract_memory(user_input, memory)# 优先使用包含记忆的响应if memory["name"]:for pattern, responses in rules.items():match = re.match(pattern, user_input, re.IGNORECASE)if match:captured_group = match.group(1) if match.groups() else ''swapped_group = swap_pronouns(captured_group)# 随机选择模板,若模板包含{1}则填充姓名response = random.choice(responses)if "{1}" in response:response = response.format(swapped_group, memory["name"])else:response = response.format(swapped_group)return response# 原有匹配逻辑for pattern, responses in rules.items():match = re.match(pattern, user_input, re.IGNORECASE)if match:captured_group = match.group(1) if match.groups() else ''swapped_group = swap_pronouns(captured_group)response = random.choice(responses).format(swapped_group)return responsereturn random.choice(rules[r'.*'])# 修改主循环,传入记忆字典
if __name__ == '__main__':print("Therapist: Hello! How can I help you today?")user_memory = {"name": None, "age": None, "job": None, "hobby": None}while True:user_input = input("You: ")if user_input.lower() in ["quit", "exit", "bye"]:farewell = "Goodbye. It was nice talking to you!"if user_memory["name"]:farewell = f"Goodbye {user_memory['name']}! It was nice talking to you!"print(f"Therapist: {farewell}")breakresponse = respond(user_input, user_memory)print(f"Therapist: {response}")
(3)扩展ELIZA与ChatGPT的本质差异
| 对比维度 | 扩展后的ELIZA | ChatGPT |
|---|---|---|
| 语义理解 | 无真正语义理解,仅基于正则模式匹配 | 基于预训练模型理解语义,能处理模糊指令和上下文关联 |
| 记忆机制 | 仅支持固定关键词的简单记忆(姓名、年龄等),无逻辑关联记忆 | 具备上下文理解能力,能记忆多轮对话中的逻辑关系(如“我喜欢爬山→推荐适合爬山的地方”) |
| 泛化能力 | 仅能处理预设规则覆盖的场景,未覆盖场景依赖通配符兜底 | 具备强大泛化能力,能处理未训练过的新场景(如即兴创作、逻辑推理) |
| 响应生成 | 基于模板填充,响应形式固定,无创造性 | 生成式响应,能根据上下文调整语气和内容,具备创造性(如故事续写、观点输出) |
(4)组合爆炸问题的数学说明
- 核心原因:开放域对话的输入组合是“指数级增长”,而规则库是“线性增长”,无法覆盖所有组合。
- 数学说明:假设对话中涉及
n个核心主题(如工作、学习、爱好、情绪等),每个主题有k种表达方式(如“我喜欢爬山”“爬山是我的爱好”),则可能的输入组合数为k^n(指数级)。例如:- 当
n=3(工作、学习、爱好),k=5(每种主题5种表达),组合数为5^3=125,需至少125条规则; - 当
n=10(更多主题),k=5,组合数为5^10=9,765,625,规则库规模爆炸式增长,人工维护完全不可行。
- 当
- 结论:规则库的线性扩展速度远低于输入组合的指数级增长,导致基于规则的方法在开放域对话中无法扩展。
习题4:心智社会理论与多智能体系统的关联
题干:
马文·明斯基在"心智社会"理论[7]中提出了一个革命性的观点:智能源于大量简单智能体的协作,而非单一的完美系统。
- 在图2.6"搭建积木塔"的例子中,如果 GRASP 智能体突然失效了,整个系统会发生什么?这种去中心化架构的优势和劣势是什么?
- 将"心智社会"理论与现在的一些多智能体系统(如CAMEL-Workforce、MetaGPT、CrewAI)进行对比,它们之间存在哪些关联和不同之处?
- 马文·明斯基认为智能体可以是"无心"的简单过程,然而现在的大语言模型和智能体往往都拥有强大的推 理能力。这是否意味着"心智社会"理论在大语言模型时代不再适用了?
解答:
-
GRASP智能体失效的影响及去中心化架构的优劣:
- 系统影响:搭建积木塔的流程中断——GRASP负责“抓取积木”,是核心执行模块,其失效后,即使FIND-BLOCK(找到积木)、PUT-ON-TOP(放置积木)等智能体正常,也无法完成“抓取→放置”的关键步骤,系统无法达成目标。
- 优势:
- 鲁棒性强:单个智能体失效仅影响特定功能,而非整个系统崩溃(如GRASP失效后,系统仍能完成“找积木”“规划放置位置”等步骤);
- 灵活性高:可通过替换或新增简单智能体扩展功能(如新增“旋转积木”智能体,无需重构整个系统);
- 并行高效:不同智能体可并行工作(如找积木的同时规划放置位置),提升任务效率。
- 劣势:
- 协调成本高:需设计复杂的交互规则(激活/抑制信号),确保多个智能体协同一致,避免冲突(如同时抓取同一个积木);
- 全局优化难:去中心化导致无中央控制器,难以全局优化任务流程(如无法调整智能体优先级以加快整体进度);
- 故障排查难:单个功能失效可能是多个智能体交互异常导致,难以定位具体故障模块。
-
心智社会理论与现代多智能体系统的关联与差异:
- 关联之处:
- 核心思想一致:均强调“简单模块协作涌现复杂智能”,而非单一完美系统;
- 去中心化控制:无中央节点,智能体(或角色)自主交互完成任务;
- 分工专业化:每个智能体(或角色)有明确职责(如MetaGPT中的“产品经理”“工程师”角色,对应心智社会的“简单智能体”)。
- 不同之处:
- 智能体复杂度:心智社会的智能体是“无心”的简单过程(如仅负责抓取、识别);现代多智能体系统的智能体是LLM驱动的,具备推理、规划能力(如CrewAI的“研究员”智能体能自主搜索、分析数据);
- 交互机制:心智社会依赖简单的激活/抑制信号;现代多智能体系统通过自然语言、通信协议(如MCP)进行复杂交互,支持动态协商;
- 学习能力:心智社会的智能体无自主学习能力,交互规则固定;现代多智能体系统可通过强化学习优化协作策略,适应新场景。
- 关联之处:
-
心智社会理论在LLM时代的适用性:
- 仍适用,但需结合时代特征演进:
- 理论核心未过时:“复杂智能源于简单模块协作”仍是现代多智能体系统的设计基础(如AutoGen的“对话智能体协作”、LangGraph的“节点协作”);
- 模块定义升级:明斯基的“简单智能体”对应现代系统的“功能模块”(如LLM负责推理、工具调用模块负责执行、记忆模块负责存储),模块本身可具备复杂能力(如LLM的推理能力),但协作逻辑仍遵循“局部交互涌现全局智能”;
- 新场景适配:LLM的强大能力降低了“简单模块”的协作成本(如自然语言交互替代复杂信号),但心智社会的“去中心化、分工协作、涌现性”核心思想,仍是构建复杂多智能体系统的关键指导。
- 仍适用,但需结合时代特征演进:
习题5:强化学习与监督学习的差异
题干:
强化学习与监督学习是两种不同的学习范式。请分析:
- 用AlphaGo的例子说明强化学习的"试错学习"机制是如何工作的
- 为什么强化学习特别适合序贯决策问题?它与监督学习在数据需求上有什么本质区别?
- 现在我们需要训练一个会玩超级马里奥游戏的智能体。如果分别使用监督学习和强化学习,各需要什么 数据?哪种方法对于这个任务来说更合适?
- 在大语言模型的训练过程中,强化学习起到了什么关键性的作用?
解答:
-
AlphaGo的强化学习“试错学习”机制:
- 核心逻辑:智能体(AlphaGo)通过与环境(围棋规则、对手)交互,在“试错”中优化策略,无需预设正确答案。
- 具体过程:
- 初始阶段:AlphaGo无任何围棋知识,仅知道规则,随机落子(“试错”的开始);
- 奖励反馈:每局对弈结束后,环境给出“赢棋”(正向奖励)或“输棋”(负向奖励)的反馈,无中间步骤的直接指导;
- 策略优化:学习元件根据奖励调整决策策略,强化“导致赢棋的棋路”,弱化“导致输棋的棋路”;
- 迭代升级:通过千万次自我对弈(持续试错),AlphaGo逐渐发现超越人类经验的最优棋路,最终形成强大的对弈策略。
-
强化学习适合序贯决策的原因及数据需求差异:
- 适合序贯决策的原因:
- 序贯决策的核心是“一系列行动的长期收益最大化”(如围棋需规划多步棋路、机器人导航需规划多步路径),强化学习的目标正是“最大化累积奖励”,而非单步最优;
- 强化学习能通过“状态-行动-奖励”循环,学习行动与长期结果的关联,适配序贯决策的“时间依赖性”(当前行动影响未来状态)。
- 数据需求的本质区别:
对比维度 强化学习 监督学习 数据类型 无标签的交互数据(状态、行动、奖励) 带标签的样本数据(输入→标签) 数据来源 智能体与环境交互生成(在线生成) 人工标注或历史数据(离线静态) 核心依赖 奖励函数设计(定义“好/坏”) 标签质量(定义“正确答案”) 学习目标 学习“最大化累积奖励的行动序列” 学习“输入到标签的映射关系”
- 适合序贯决策的原因:
-
超级马里奥游戏智能体的训练数据与方法选择:
- 监督学习所需数据:
- 需大量“专家演示数据”:即人类高手玩游戏的完整记录(如每一步的按键操作、游戏画面状态、得分);
- 数据格式:
(游戏画面状态, 专家按键操作)的样本对,需覆盖游戏中的所有场景(如跳跃、躲避敌人、吃道具)。
- 强化学习所需数据:
- 无需人工标注数据,仅需游戏环境提供的“奖励信号”(如得分增加→正向奖励、游戏失败→负向奖励、吃到道具→小正向奖励);
- 数据由智能体与游戏环境交互生成:
(游戏画面状态→智能体按键操作→环境反馈奖励→新状态)的循环数据。
- 更合适的方法:强化学习。
- 原因:超级马里奥是典型的序贯决策问题,需规划多步操作(如先跳跃再吃道具),且游戏场景组合极多,人工标注专家数据成本极高;强化学习可自主探索所有场景,通过奖励信号优化策略,更适配游戏的动态性和复杂性。
- 监督学习所需数据:
-
强化学习在LLM训练中的关键作用:
- 核心作用:解决“模型输出与人类意图对齐”的问题,即让LLM生成“有用、安全、符合人类偏好”的内容。
- 具体体现(以RLHF为例):
- 第一步(监督微调SFT):用标注数据让LLM学习基本任务,但无法保证输出符合人类偏好;
- 第二步(奖励模型训练RM):让人类对LLM的多个输出打分(偏好排序),训练奖励模型,定义“好输出”的标准;
- 第三步(强化学习PPO):以奖励模型的打分为“奖励信号”,通过强化学习优化LLM的输出策略,让模型生成更符合人类偏好的内容(如更安全、更有用、更连贯)。
- 关键价值:突破了监督学习“依赖标注数据”的局限,让LLM从“能生成内容”进化为“能生成高质量、符合人类需求的内容”。
习题6:预训练-微调范式的思考
题干:
预训练-微调范式是现代人工智能领域的重要突破。请深入思考:
- 为什么说预训练解决了符号主义时代的"知识获取瓶颈"问题?它们在知识表示方式上有什么本质区别?
- 预训练模型的知识绝大部分来自互联网数据,这可能带来哪些问题?如何缓解以上问题?
- 你认为"预训练-微调"范式是否可能会被某种新范式取代?或者它会长期存在?
解答:
-
预训练对知识获取瓶颈的解决及知识表示差异:
- 解决知识获取瓶颈的原因:
- 符号主义的知识获取依赖“人工编码规则/知识库”,成本高、规模化难;
- 预训练模型通过在海量互联网数据上自监督学习,自主内化知识(如语言规律、事实信息、逻辑关系),无需人工编码,极大降低了知识获取成本,突破了“知识获取瓶颈”。
- 知识表示方式的本质区别:
对比维度 符号主义 预训练-微调范式 表示形式 显式符号+规则(如“IF发烧AND咳嗽→呼吸道感染”) 隐式分布式向量(神经网络的连接权重) 知识存储 集中式知识库(规则库、知识图谱) 分布式存储(知识分散在模型参数中) 知识更新 手动修改规则/知识库,成本高 重新预训练或增量微调,相对灵活 泛化能力 弱,仅能处理规则覆盖的场景 强,能通过知识迁移处理新场景
- 解决知识获取瓶颈的原因:
-
预训练模型的问题及缓解方案:
- 潜在问题:
- 知识偏见:互联网数据包含人类社会的偏见(如性别偏见、种族偏见),模型会学习并放大这些偏见;
- 知识过时:预训练数据有时间窗口(如2023年的数据无法包含2024年的新事件),导致模型知识滞后;
- 虚假信息:互联网数据中存在错误、虚假信息,模型会学习这些“幻觉知识”;
- 隐私泄露:训练数据可能包含用户隐私信息(如个人联系方式、敏感数据),模型可能生成这些信息。
- 缓解方案:
- 数据清洗:预处理训练数据,过滤偏见、虚假信息和隐私数据,加入多样化数据平衡偏见;
- 知识更新:采用增量预训练(用新数据更新模型)、检索增强生成(RAG,实时从外部知识库获取新信息);
- 对齐技术:通过RLHF让模型输出符合人类价值观,减少偏见和有害内容;
- 隐私保护:采用联邦学习(不集中存储训练数据)、差分隐私(添加噪声保护隐私)等技术。
- 潜在问题:
-
预训练-微调范式的未来趋势:
- 不会被完全取代,但会持续进化,长期存在:
- 核心原因:该范式的“先学习通用知识,再适配具体任务”符合智能学习的本质规律,且能高效利用海量无标注数据,降低任务适配成本,这一核心优势无法被轻易替代;
- 进化方向:
- 更高效的微调方法:减少微调所需数据量和计算成本(如LoRA、QLoRA等参数高效微调技术);
- 动态知识更新:突破固定预训练窗口的限制,实现实时知识更新(如持续预训练+RAG融合);
- 多模态融合:从单一文本预训练扩展到文本、图像、音频等多模态预训练,适配更复杂任务;
- 可能的补充范式:不会出现“完全替代”的新范式,更可能是“预训练-微调+其他范式”的融合(如强化学习、符号逻辑),形成更强大的混合范式。
- 不会被完全取代,但会持续进化,长期存在:
习题7:不同时代的智能代码审查助手设计
题干:
假设你要设计一个"智能代码审查助手",它能够自动审查代码提交(Pull Request),概括代码的实现逻辑、 检查代码质量、发现潜在BUG、提出改进建议。
- 如果在符号主义时代(1980年代)设计这个系统,你会如何实现?会遇到什么困难?
- 如果在没有大语言模型的深度学习时代(2015年左右),你会如何实现?
- 在当前的大语言模型和智能体的时代,你会如何设计这个智能体的架构?它应该包含哪些模块(参考图 2.10)?
- 对比这三个时代的方案,说明智能体技术的演进如何使这个任务从"几乎不可能"变为"可行"
解答:
-
符号主义时代(1980年代)的设计方案与困难:
- 实现方案(基于规则编码):
- 知识库构建:人工编码代码审查规则(如“变量命名需符合驼峰命名法”“循环必须有终止条件”“数组访问需检查边界”),以“IF-THEN”规则形式存储;
- 代码解析:开发简单的代码语法解析器,将代码转换为符号化的抽象语法树(AST);
- 规则匹配:用符号匹配算法对比AST与审查规则,输出违规项和改进建议(如“数组访问未检查边界→建议添加索引判断”)。
- 面临的困难:
- 知识获取瓶颈:代码语言(如C、Java)的语法规则、最佳实践极多,人工编码所有审查规则成本极高,且难以覆盖边缘情况;
- 语言扩展性差:新增编程语言(如Python)需重新编码全套规则,无法复用;
- 无语义理解:仅能检查语法和编码规范,无法理解代码的业务逻辑,无法发现“逻辑BUG”(如“条件判断错误导致功能异常”);
- 系统脆弱性:代码写法灵活(如不同的循环实现方式),规则无法覆盖所有写法,易出现误判或漏判。
- 实现方案(基于规则编码):
-
深度学习时代(2015年左右)的设计方案:
- 实现方案(基于监督学习+深度学习模型):
- 数据准备:收集大量“代码+审查结果”的标注数据(如GitHub上的PR审查记录,包含代码、BUG描述、改进建议);
- 特征工程:提取代码的手工特征(如代码行数、循环嵌套深度、变量名长度、函数复杂度);
- 模型训练:
- 用分类模型(如CNN、RNN)训练“BUG检测模型”,输入代码特征,输出是否存在BUG及BUG类型;
- 用序列生成模型(如RNN)训练“改进建议生成模型”,输入有BUG的代码,输出改进后的代码片段;
- 审查流程:代码提交后,提取特征→输入模型→输出BUG检测结果和改进建议。
- 核心特点:无需人工编码规则,能学习数据中的审查模式,但依赖大量标注数据,且对代码语义的理解有限。
- 实现方案(基于监督学习+深度学习模型):
-
当前LLM与智能体时代的架构设计(参考图2.10):
智能代码审查助手的架构包含6个核心模块,遵循“感知-思考-行动-观察”循环:-
- 感知模块(Sensors):
- 代码解析器:读取PR中的代码文件(Python/Java等),转换为LLM可处理的文本格式;
- 上下文提取器:提取代码的关联信息(如项目文档、历史PR审查记录、代码注释);
- 工具接口:连接代码编译工具(检查语法错误)、单元测试工具(验证功能正确性)。
-
- 记忆模块(Memory):
- 短期记忆:存储当前PR的代码内容、审查进度、工具反馈结果;
- 长期记忆:存储项目编码规范、历史BUG案例、最佳实践库(如Python PEP8规范、安全编码指南)。
-
- 规划模块(Planning):
- 任务分解:将“代码审查”拆解为子任务(概括实现逻辑→检查语法规范→检测潜在BUG→评估代码质量→提出改进建议);
- 优先级排序:优先审查核心功能代码、高风险模块(如权限控制、数据处理)。
-
- 推理模块(LLM核心):
- 逻辑概括:基于代码和上下文,生成简洁的实现逻辑描述;
- BUG检测:结合长期记忆和代码语义,发现语法BUG、逻辑BUG、安全漏洞(如SQL注入、权限泄露);
- 建议生成:根据编码规范和最佳实践,生成具体、可执行的改进建议(如优化循环效率、简化条件判断)。
-
- 行动模块(Actuators):
- 工具调用:调用代码编译工具验证语法、单元测试工具验证功能、安全扫描工具检测漏洞;
- 结果生成:整合推理结果和工具反馈,生成结构化审查报告(包含逻辑概括、BUG列表、改进建议)。
-
- 观察模块(Observation):
- 工具反馈处理:接收工具执行结果(如单元测试失败信息、安全漏洞报告),更新记忆;
- 人工反馈接收:接收开发者对审查结果的反馈(如“误判”“建议无效”),用于模型优化。
-
-
三个时代方案对比:从“不可能”到“可行”的演进逻辑:
时代 核心能力 关键限制 演进突破 符号主义 仅能检查语法和固定规范 无法理解语义、规则难以规模化 从“人工编码知识”到“数据自主学习”,突破知识获取瓶颈 深度学习 能学习简单审查模式、检测常见BUG 依赖标注数据、语义理解有限 从“手工特征+浅层模型”到“LLM+多模块协同”,具备深度语义理解和自主决策能力 LLM智能体 理解复杂逻辑、检测深层BUG、生成精准建议 需高质量记忆库和工具集成 从“单一模型”到“智能体系统”,实现“感知-思考-行动-反馈”闭环,适配复杂、动态的代码审查场景 - 演进本质:智能体技术的演进,本质是“知识获取方式”和“决策能力”的升级——从人工编码到数据学习,再到自主决策;从处理简单规则到理解复杂语义,再到动态适应场景,最终让“智能代码审查”从依赖人工的“不可能”任务,变为高效、精准的“可行”任务。
四、总结
第二章的核心价值在于构建了“问题驱动进化”的认知框架——每一代智能体范式的诞生,都是为了解决上一代的核心局限。从符号主义的“规则编码”到心智社会的“分布式协作”,再到强化学习的“试错学习”和LLM的“预训练-微调”,智能体的进化始终围绕“如何更高效地获取知识、如何更灵活地适应环境、如何更自主地解决问题”三大核心问题。
通过本章的学习,我们理清了智能体的历史脉络,更能理解现代LLM驱动智能体的技术选型逻辑——它并非单一技术的突破,而是符号主义、联结主义、行为主义等多流派的深度融合。
五、ELIZA实现完整代码
import re
import random# 定义规则库:模式(正则表达式)->响应模板列
# 正则表达式
# (.*) 匹配任意字符,并捕获到一个组
# \? 匹配问号
# \. 匹配句号rules = {r'I need (.*)': ["Why do you need {0}?","Would it really help you to get {0}?","Are you sure you need {0}?"],r'Why don\'t you (.*)\?': ["Do you really think I don't {0}?","Perhaps eventually I will {0}.","Do you really want me to {0}?"],r'Why can\'t I (.*)\?': ["Do you think you should be able to {0}?","If you could {0}, what would you do?","I don't know -- why can't you {0}?"],r'I am (.*)': ["Did you come to me because you are {0}?","How long have you been {0}?","How do you feel about being {0}?"],r'.* mother .*': ["Tell me more about your mother.","What was your relationship with your mother like?","How do you feel about your mother?"],r'.* father .*': ["Tell me more about your father.","How did your father make you feel?","What has your father taught you?"],r'.*': ["Please tell me more.","Let's change focus a bit... Tell me about your family.","Can you elaborate on that?"]
}# 定义代词转换规则
pronouns_swap = {"i": "you","you": "i","me": "you","my": "your","am": "are","are": "am","was": "were","were": "was","i'd": "you would","i've": "you have","i'll": "you will","mine": "yours","yours": "mine"
}def swap_pronouns(phare):"""对输入短语中的代词进行第一/二人称转换"""words = phare.lower().split() # 转换为小写,并分词swapped_words = [pronouns_swap.get(word, word) for word in words] # 遍历每个单词,如果在代词转换规则中,则替换为对应的代词,否则保持原样return " ".join(swapped_words) # 连接词组def respond(user_input):"""根据规则库,生成回复"""for pattern, responses in rules.items():match = re.match(pattern, user_input, re.IGNORECASE) # 匹配输入短语与规则库中的模式,忽略大小写if match:# 捕获匹配到的部分captured_group = match.group(1) if match.groups() else '' # 如果匹配到捕获组,则取出该组内容,否则为空字符串# 代词转换swapped_group = swap_pronouns(captured_group) # 对捕获到的部分进行代词转换# 格式化回复模板,并随机选择一个response = random.choice(responses).format(swapped_group)return response # 返回回复# 如果没有匹配到特定规则,使用最后的通配符规则return random.choice(rules[r'.*'])# 主聊天循环
if __name__ == '__main__':print("Therapist: Hello! How can I help you today?")while True:user_input = input("You: ")if user_input.lower() in ["quit", "exit", "bye"]:print("Therapist: Goodbye. It was nice talking to you.")breakresponse = respond(user_input)print(f"Therapist: {response}")
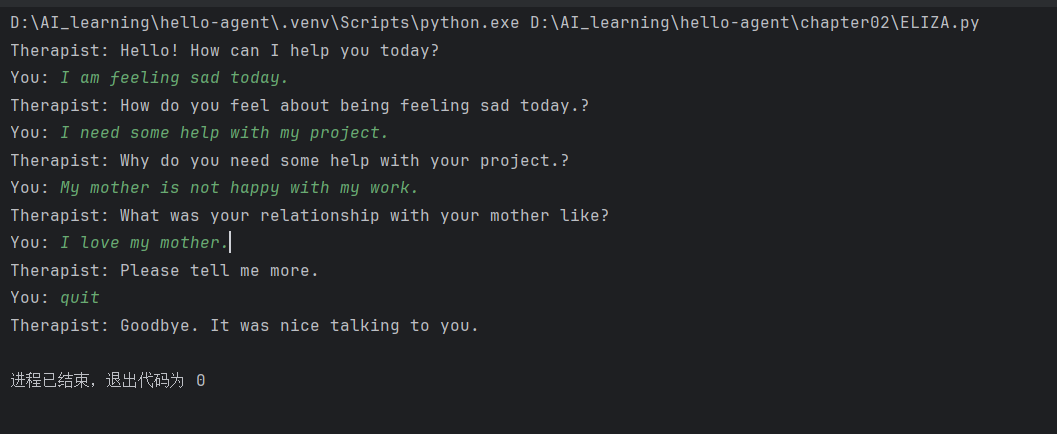
运行结果
六、参考资料
DataWhale:Hello-Agent