Paimon——官网阅读:理解文件
理解文件
本文旨在阐明各种文件操作对文件的影响。
本页面提供具体示例和实用技巧,以助力有效管理文件。此外,通过深入探讨诸如提交(commit)和压缩(compact)等操作,我们旨在深入解析文件的创建与更新过程。
前提条件
在深入阅读本页面内容之前,请确保已通读以下章节:
基本概念
主键表与追加表
如何在Flink中使用Paimon
理解文件操作
创建目录
通过 ./sql-client.sh 启动Flink SQL客户端,并逐行执行以下语句以创建一个Paimon目录。
CREATE CATALOG paimon WITH ('type' = 'paimon','warehouse' = 'file:///tmp/paimon'
);
USE CATALOG paimon;这只会在指定路径 file:///tmp/paimon 创建一个目录。
创建表
执行以下创建表语句将创建一个包含3个字段的Paimon表:
CREATE TABLE T (id BIGINT,a INT,b STRING,dt STRING COMMENT 'timestamp string in format yyyyMMdd',PRIMARY KEY(id, dt) NOT ENFORCED ) PARTITIONED BY (dt);
这将在路径 /tmp/paimon/default.db/T 下创建Paimon表 T,其模式存储在 /tmp/paimon/default.db/T/schema/schema-0 中。
向表中插入记录
在Flink SQL中运行以下插入语句:
INSERT INTO T VALUES (1, 10001, 'varchar00001', '20230501');
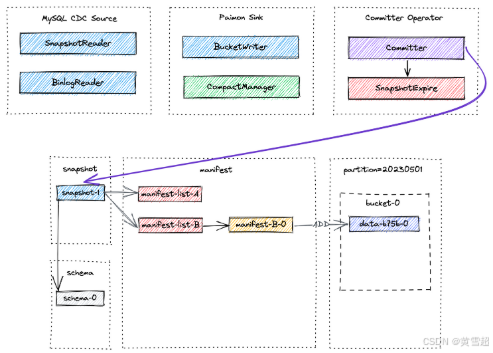
Flink作业完成后,记录将通过成功提交写入Paimon表。用户可以通过执行查询 SELECT * FROM T 验证这些记录的可见性,该查询将返回一行数据。提交过程会在路径 /tmp/paimon/default.db/T/snapshot/snapshot-1 创建一个快照。快照 snapshot-1 的文件布局如下所述:
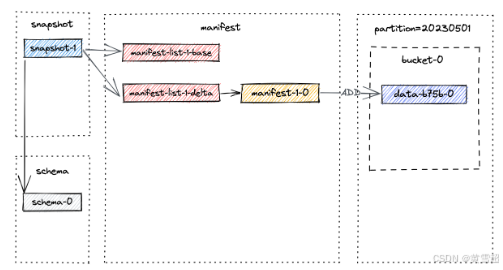
snapshot-1 的内容包含快照的元数据,如清单列表(manifest list)和模式ID:
{"version" : 3,"id" : 1,"schemaId" : 0,"baseManifestList" : "manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0","deltaManifestList" : "manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1","changelogManifestList" : null,"commitUser" : "7d758485-981d-4b1a-a0c6-d34c3eb254bf","commitIdentifier" : 9223372036854775807,"commitKind" : "APPEND","timeMillis" : 1684155393354,"logOffsets" : { },"totalRecordCount" : 1,"deltaRecordCount" : 1,"changelogRecordCount" : 0,"watermark" :-9223372036854775808
}请注意,一个清单列表包含快照的所有更改,baseManifestList 是基础文件,deltaManifestList 中的更改将应用于该基础文件。首次提交将生成1个清单文件,并创建2个清单列表(文件名可能与您实验中的不同):
./T/manifest: manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1 manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0 manifest-2b833ea4-d7dc-4de0-ae0d-ad76eced75cc-0
manifest-2b833ea4-d7dc-4de0-ae0d-ad76eced75cc-0 是清单文件(上图中的 manifest-1-0),它存储快照中数据文件的相关信息。
manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0 是 baseManifestList(上图中的 manifest-list-1-base),实际上为空。
manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1 是 deltaManifestList(上图中的 manifest-list-1-delta),它包含对数据文件执行操作的清单条目列表,在这种情况下是 manifest-1-0。
现在,让我们插入一批跨不同分区的记录,看看会发生什么。在Flink SQL中,执行以下语句:
INSERT INTO T VALUES (2, 10002, 'varchar00002', '20230502'), (3, 10003, 'varchar00003', '20230503'), (4, 10004, 'varchar00004', '20230504'), (5, 10005, 'varchar00005', '20230505'), (6, 10006, 'varchar00006', '20230506'), (7, 10007, 'varchar00007', '20230507'), (8, 10008, 'varchar00008', '20230508'), (9, 10009, 'varchar00009', '20230509'), (10, 10010, 'varchar00010', '20230510');
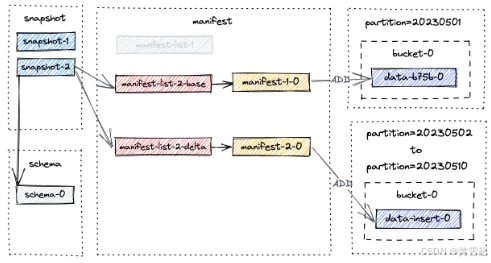
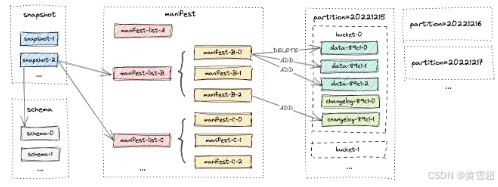
第二次提交发生,执行 SELECT * FROM T 将返回10行数据。一个新的快照 snapshot-2 被创建,其物理文件布局如下:
% ls -1tR. ./T: dt = 20230501 dt = 20230502 dt = 20230503 dt = 20230504 dt = 20230505 dt = 20230506 dt = 20230507 dt = 20230508 dt = 20230509 dt = 20230510 snapshot schema manifest./T/snapshot: LATEST snapshot-2 EARLIEST snapshot-1./T/manifest: manifest-list-9ac2-5e79-4978-a3bc-86c25f1a303f-1 # snapshot-2的增量清单列表 manifest-list-9ac2-5e79-4978-a3bc-86c25f1a303f-0 # snapshot-2的基础清单列表 manifest-f1267033-e246-4470-a54c-5c27fdbdd074-0 # snapshot-2的清单文件manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-1 # snapshot-1的增量清单列表 manifest-list-4ccc-c07f-4090-958c-cfe3ce3889e5-0 # snapshot-1的基础清单列表 manifest-2b833ea4-d7dc-4de0-ae0d-ad76eced75cc-0 # snapshot-1的清单文件./T/dt = 20230501/bucket-0: data-b75b7381-7c8b-430f-b7e5-a204cb65843c-0.orc... # 每个分区都有写入bucket-0的数据 ..../T/schema: schema-0
截至 snapshot-2 的新文件布局如下所示。
从表中删除记录
现在,让我们删除满足条件 dt>=20230503 的记录。在Flink SQL中,执行以下语句:
DELETE FROM T WHERE dt >= '20230503';
第三次提交发生,生成 snapshot-3。现在,列出表下的文件,你会发现没有分区被删除。相反,为 20230503 到 20230510 的分区创建了一个新的数据文件:
./T/dt = 20230510/bucket-0: data-b93f468c-b56f-4a93-adc4-b250b3aa3462-0.orc # 删除语句创建的新数据文件 data-0fcacc70-a0cb-4976-8c88-73e92769a762-0.orc # 插入语句创建的旧数据文件
这是合理的,因为我们在第二次提交中插入了一条记录(由 +I[10, 10010, 'varchar00010', '20230510'] 表示),然后在第三次提交中删除了该记录。执行 SELECT * FROM T 将返回2行数据,即:
+I[1, 10001, 'varchar00001', '20230501'] +I[2, 10002, 'varchar00002', '20230502']
截至 snapshot-3 的新文件布局如下所示。
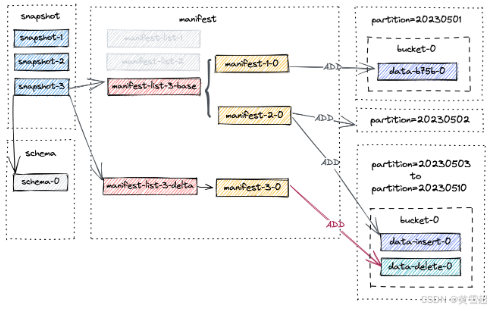
请注意,manifest-3-0 包含8个 ADD 操作类型的清单条目,对应8个新写入的数据文件。
合并表
如你可能已经注意到的,随着连续快照的产生,小文件的数量会增加,这可能导致读取性能下降。因此,需要进行全量压缩以减少小文件的数量。
现在让我们触发全量压缩,并通过 flink run 运行一个专门的压缩作业:
<FLINK_HOME>/bin/flink run \-D execution.runtime-mode = batch \/path/to/paimon-flink-action-0.9.0.jar \compact \--warehouse <warehouse-path> \--database <database-name> \ --table <table-name> \[--partition <partition-name>] \[--catalog_conf <paimon-catalog-conf> [--catalog_conf <paimon-catalog-conf> ...]] \[--table_conf <paimon-table-dynamic-conf> [--table_conf <paimon-table-dynamic-conf>] ...]
一个示例(假设你已在Flink主目录下)如下:
./bin/flink run \./lib/paimon-flink-action-0.9.0.jar \compact \--path file:///tmp/paimon/default.db/T
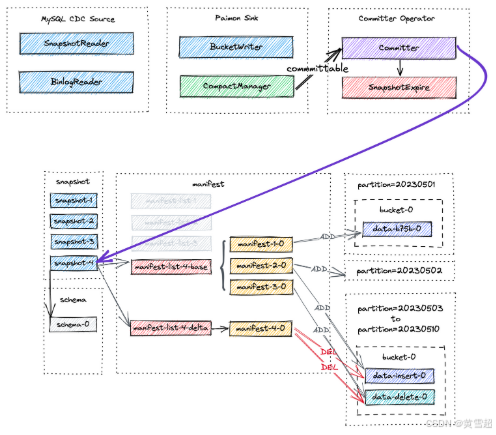
当前所有表文件都将被压缩,并创建一个新的快照 snapshot-4,其中包含以下信息:
{"version" : 3,"id" : 4,"schemaId" : 0,"baseManifestList" : "manifest-list-9be16-82e7-4941-8b0a-7ce1c1d0fa6d-0","deltaManifestList" : "manifest-list-9be16-82e7-4941-8b0a-7ce1c1d0fa6d-1","changelogManifestList" : null,"commitUser" : "a3d951d5-aa0e-4071-a5d4-4c72a4233d48","commitIdentifier" : 9223372036854775807,"commitKind" : "COMPACT","timeMillis" : 1684163217960,"logOffsets" : { },"totalRecordCount" : 38,"deltaRecordCount" : 20,"changelogRecordCount" : 0,"watermark" :-9223372036854775808
}截至 snapshot-4 的新文件布局如下所示。
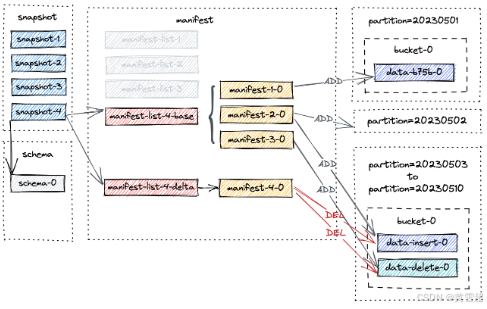
请注意,manifest-4-0 包含20个清单条目(18个 DELETE 操作和2个 ADD 操作):
对于
20230503到20230510的分区,对两个数据文件执行两个DELETE操作。对于
20230501到20230502的分区,对同一数据文件执行一个DELETE操作和一个ADD操作。
修改表
执行以下语句配置全量压缩:
ALTER TABLE T SET ('full-compaction.delta-commits' = '1');它将为Paimon表创建一个新的模式 schema-1,但在下次提交之前,实际上没有快照使用此模式。
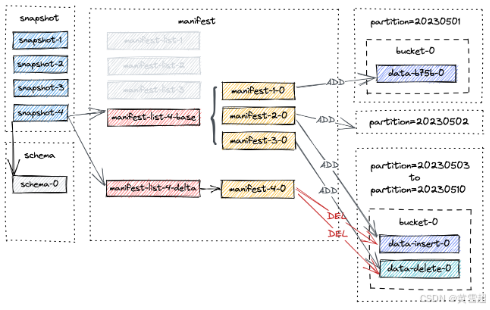
过期快照
请注意,标记的数据文件在快照过期且没有消费者依赖该快照之前不会真正被删除。有关更多信息,请参阅“过期快照”。
在快照过期过程中,首先确定快照的范围,然后标记这些快照中的数据文件以便删除。只有当存在类型为 DELETE 的清单条目引用特定数据文件时,才会标记该数据文件以便删除。此标记确保该文件不会被后续快照使用,可以安全删除。
假设上图中的所有4个快照即将过期。过期过程如下:
首先删除所有标记的数据文件,并记录任何更改的桶。
然后删除任何变更日志文件和相关清单。
最后删除快照本身并写入最早提示文件。
如果删除过程后有任何目录为空,它们也将被删除。
假设创建了另一个快照 snapshot-5 并触发了快照过期。snapshot-1 到 snapshot-4 将被删除。为简单起见,我们仅关注先前快照中的文件,快照过期后的最终布局如下所示。
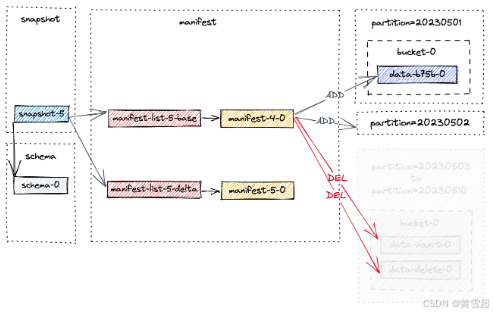
结果是,20230503 到 20230510 的分区被物理删除。
Flink流写入
最后,我们将通过CDC摄取示例来研究Flink流写入。本节将介绍变更数据的捕获和写入Paimon的过程,以及异步压缩、快照提交和过期背后的机制。
首先,让我们更仔细地研究CDC摄取工作流程以及所涉及的每个组件所扮演的独特角色。
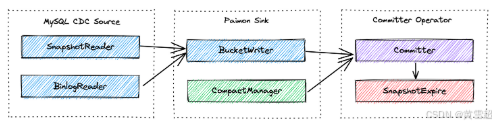
MySQL CDC源统一读取快照和增量数据,
SnapshotReader读取快照数据,BinlogReader分别读取增量数据。Paimon Sink在桶级别将数据写入Paimon表。其中的
CompactManager将异步触发压缩。Committer Operator是一个单例,负责提交和过期快照。
接下来,我们将介绍端到端的数据流。
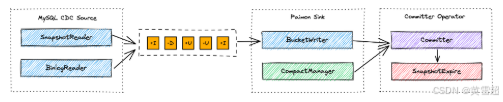
MySQL Cdc源读取快照和增量数据,并在规范化后将它们向下游发送。
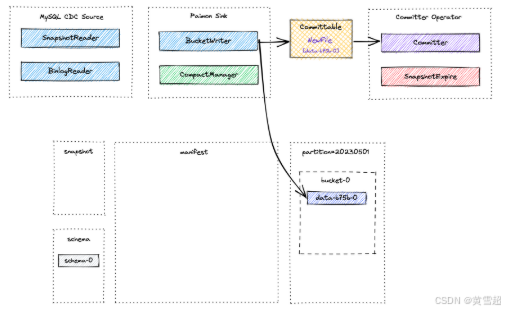
Paimon Sink首先在基于堆的LSM树中缓冲新记录,当内存缓冲区满时将它们刷新到磁盘。请注意,写入的每个数据文件都是一个排序运行(sorted run)。此时,不会创建清单文件和快照。就在Flink检查点发生之前,Paimon Sink将刷新所有缓冲的记录,并将可提交消息发送到下游,在检查点期间由Committer Operator读取并提交。
在检查点期间,Committer Operator将创建一个新的快照,并将其与清单列表相关联,以便该快照包含表中所有数据文件的信息。
在之后的某个时间可能会发生异步压缩,CompactManager 生成的可提交内容包含有关先前文件和合并文件的信息,以便 Committer Operator 可以构建相应的清单条目。在这种情况下,Committer Operator 可能会在 Flink 检查点期间生成两个快照,一个用于写入的数据(类型为 Append 的快照),另一个用于压缩(类型为 Compact 的快照)。如果在检查点间隔内没有写入数据文件,则只会创建类型为 Compact 的快照。Committer Operator 将检查快照过期情况,并对标记的数据文件执行物理删除。
理解小文件
许多用户担心小文件问题,因为小文件可能会导致:
稳定性问题:HDFS 中有太多小文件会使 NameNode 压力过大。
成本问题:HDFS 中的一个小文件会暂时占用至少一个块的大小,例如 128MB。
查询效率问题:查询太多小文件的效率会受到影响。
理解检查点
假设你正在使用 Flink Writer,每个检查点会生成 1-2 个快照,并且检查点会强制在分布式文件系统(DFS)上生成文件,因此检查点间隔越小,生成的小文件就越多。
1. 所以首先要做的是增加检查点间隔。
默认情况下,不仅检查点会导致文件生成,而且写入器的内存(write-buffer-size)耗尽也会将数据刷新到 DFS 并生成相应的文件。你可以启用 write-buffer-spillable,在写入器中生成溢出文件,以便在 DFS 中生成更大的文件。
2. 所以第二件事是增加 write-buffer-size 或启用 write-buffer-spillable。
理解快照
Paimon 维护文件的多个版本,文件的压缩和删除是逻辑上的,实际上并不会删除文件。只有当快照过期时,文件才会真正被删除,所以减少文件的第一种方法是缩短快照过期所需的时间。Flink 写入器会自动使快照过期。
请参阅“过期快照”。
理解分区和桶
Paimon 文件以分层方式组织。以下图片说明了文件布局。从快照文件开始,Paimon 读取器可以递归访问表中的所有记录。
例如,以下表:
CREATE TABLE MyTable (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED
) PARTITIONED BY (dt, hh) WITH ('bucket' = '10'
);表数据将物理切片到不同的分区和内部的不同桶中,所以如果总体数据量太小,单个桶中至少会有一个文件,建议你配置较少数量的桶,否则也会有相当多的小文件。
理解主键表的LSM
LSM 树将文件组织成几个排序运行(sorted runs)。一个排序运行由一个或多个数据文件组成,并且每个数据文件恰好属于一个排序运行。
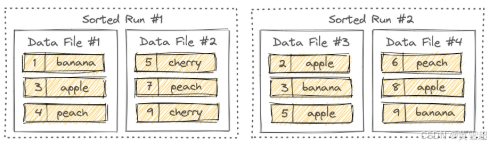
默认情况下,排序运行的数量取决于 num-sorted-run.compaction-trigger,请参阅“主键表的压缩”,这意味着一个桶中至少有 5 个文件。如果你想减少这个数量,可以保留较少的文件,但写入性能可能会受到影响。
理解桶式追加表的文件
默认情况下,追加操作也会自动进行压缩以减少小文件的数量。
然而,对于桶式追加表,为了保证顺序性,它只会压缩桶内的文件,这可能会保留更多的小文件。请参阅“桶式追加”。
理解全量压缩
也许你认为主键表的 5 个文件实际上还可以,但追加表(桶)在单个桶中可能有 50 个小文件,这是很难接受的。更糟糕的是,不再活跃的分区也会保留这么多小文件。
配置 full-compaction.delta-commits,以便在 Flink 写入时定期执行全量压缩。并且它可以确保在写入结束前对分区进行全量压缩。