LeetCode hot100:240 搜索二维矩阵 II:三种解法对比
问题描述:
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。
示例1
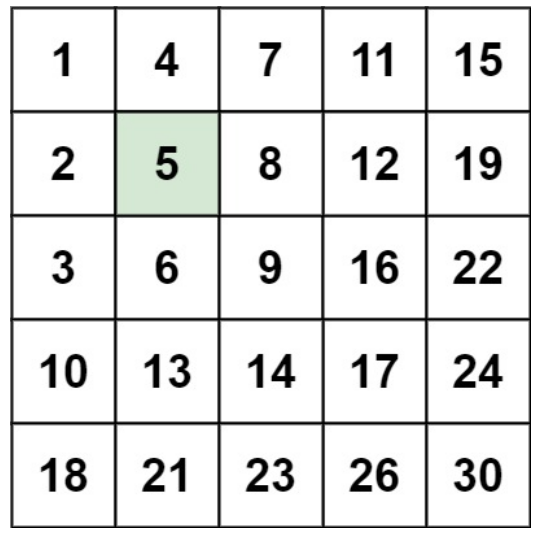
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]]
target = 5
输出:true
示例2:
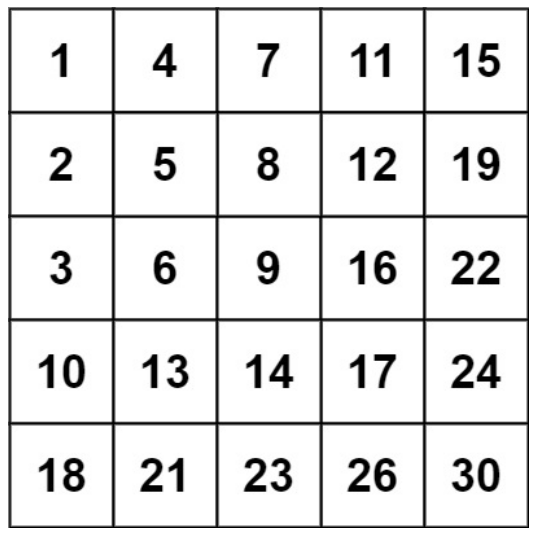
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]]
target = 20
输出:false
解决方法:
方法一:直接查找(暴力解法)
算法思路:
遍历矩阵中的每一个元素
如果找到目标值,立即返回
true如果遍历完所有元素都没有找到,返回
false
代码实现:
class Solution:def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:if not matrix or not matrix[0]:return False# 直接查找for row in matrix:for element in row:if element == target:return Truereturn False
复杂度分析:
- 时间复杂度:O(m × n) 需要遍历矩阵中的所有元素,在最坏情况下需要检查 m × n 次
- 空间复杂度:O(1) 只使用了常数级别的额外空间
优缺点:
- 优点:实现简单,代码直观易懂
- 缺点:没有利用矩阵的有序特性,效率较低
方法二:从右上角开始搜索(Z字形查找)
算法思路:
从矩阵的右上角
(0, n-1)开始搜索比较当前元素与目标值:
如果相等,返回
true如果当前元素大于目标值,说明目标值不可能在当前列,向左移动一列
如果当前元素小于目标值,说明目标值不可能在当前行,向下移动一行
如果搜索超出矩阵边界,返回
false
代码实现:
class Solution:def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:if not matrix or not matrix[0]:return False# 右上角开始m , n = len(matrix) , len(matrix[0])row,col = 0,n-1while row < m and col >= 0:if matrix[row][col] == target:return Trueelif matrix[row][col] > target:col -= 1else:row += 1return False复杂度分析:
- 时间复杂度:O(m + n) 总搜索次数为 m+n
- 空间复杂度:O(1) 只使用了常数级别的额外空间
方法三:从左下角开始搜索(Z字形查找)
算法思路:
从矩阵的左下角
(m-1, 0)开始搜索比较当前元素与目标值:
如果相等,返回
true如果当前元素大于目标值,说明目标值不可能在当前行,向上移动一行
如果当前元素小于目标值,说明目标值不可能在当前列,向右移动一列
如果搜索超出矩阵边界,返回
false
代码实现:
class Solution:def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:if not matrix or not matrix[0]:return False# 左下角开始row_len = len(matrix)list_len = len(matrix[0])first = row_len - 1second = 0while first >= 0 and second < list_len:flag = matrix[first][second]if flag == target:return Trueelif flag < target:second += 1else:first -= 1return False
复杂度分析:
- 时间复杂度:O(m + n) 总搜索次数为 m+n
- 空间复杂度:O(1) 只使用了常数级别的额外空间
问题详解:
为什么选择右上角或者左下角:
选择这两个特殊位置的原因在于它们处于"边界极值"的位置:
右上角:是该行的最大值,该列的最小值
左下角:是该行的最小值,该列的最大值
这种特性使得每次比较都能确定性地排除一整行或一整列,从而快速缩小搜索范围。
性能测试对比:
以示例的五阶矩阵查找5为例:
直接查找:需要检查约10-15个元素
右上角搜索:只需要检查5个元素
左下角搜索:只需要检查5个元素
随着矩阵规模的增大,性能差异会更加明显。
总结:
1、方法选择策略:
- 小规模数据:直接查找法代码简单,易于理解和维护;
- 大规模数据:右上角/左下角搜索法效率更高,推荐使用。
2、核心思想:利用矩阵的行列有序特性,从边界开始搜索,每次比较排除一行或一列。
3、算法优势:
右上角/左下角搜索:时间复杂度 O(m+n),远优于暴力搜索的 O(m×n);
直接查找:实现简单,适合快速开发和小数据集。
这种"步步为营"的搜索策略体现了分治思想,通过每次排除不可能的区域,逐步逼近目标值。