RLHF、DPO 算法
RLHF
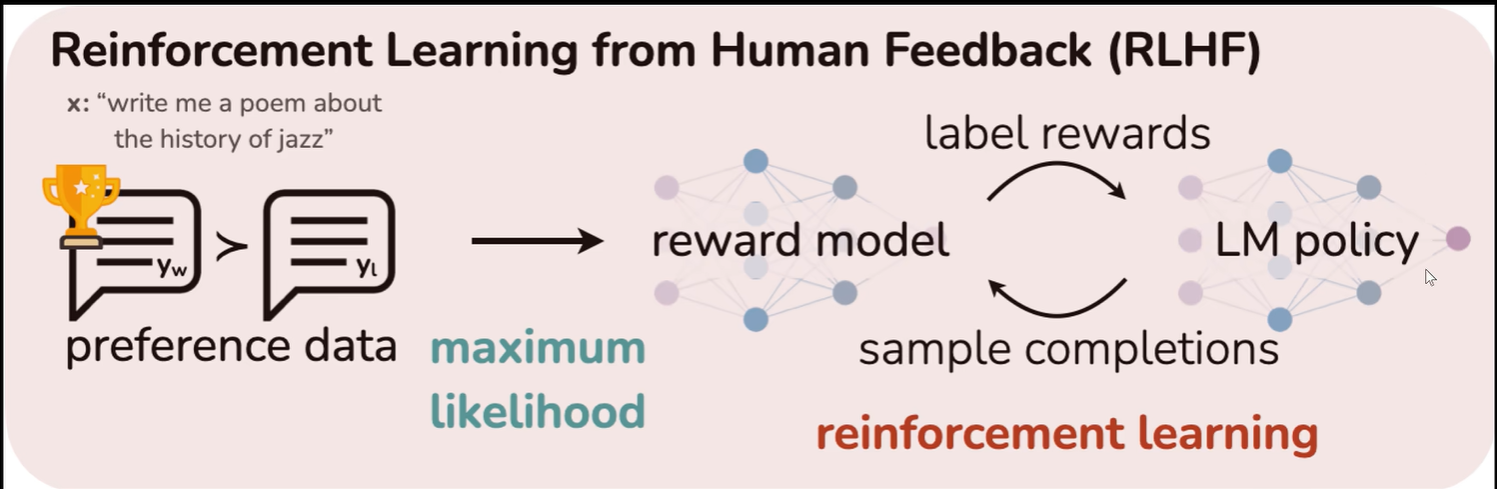
RLHF(Reinforcement Learning with Human Feedback) 是一种结合强化学习(Reinforcement Learning, RL)与人类反馈(Human Feedback)的技术,用于训练人工智能(AI)模型,尤其是大型语言模型(如 ChatGPT)或其他复杂的智能体。RLHF的核心思想是通过人类的评估和反馈来引导模型的学习过程,而不仅仅依赖于传统的奖励信号或预设的任务目标
RLHF的工作流程
-
预训练阶段:
在RLHF的初期,模型通常会在大量的无监督数据上进行预训练,像普通的语言模型一样,学习到一般性的语言理解和生成能力。 -
人类反馈数据收集:
在预训练之后,模型的输出会被用来生成一系列任务或对话,随后人类评审者对这些输出进行评分或给出偏好。例如,给定一对模型的答案,人类评审者会选择哪一个更合适,或者给出对回答的质量评分。 -
奖励模型训练:
通过收集到的人类反馈数据,训练出一个“奖励模型”(reward model),该模型能够预测某个特定行为或输出会获得多少奖励。这个奖励模型根据人类给出的反馈进行训练,学习如何量化模型行为的好坏。 -
强化学习训练:
最后,使用奖励模型作为环境的“奖励函数”,通过强化学习算法(如Proximal Policy Optimization,PPO)来训练模型的行为策略。强化学习算法通过与奖励模型的交互来优化模型,使得它能够根据人类的反馈生成更加符合预期的行为或输出。
RLHF工作流程如下图所示,其中y_w, y_x是模型对同一个问题生成的不同回答。
DPO
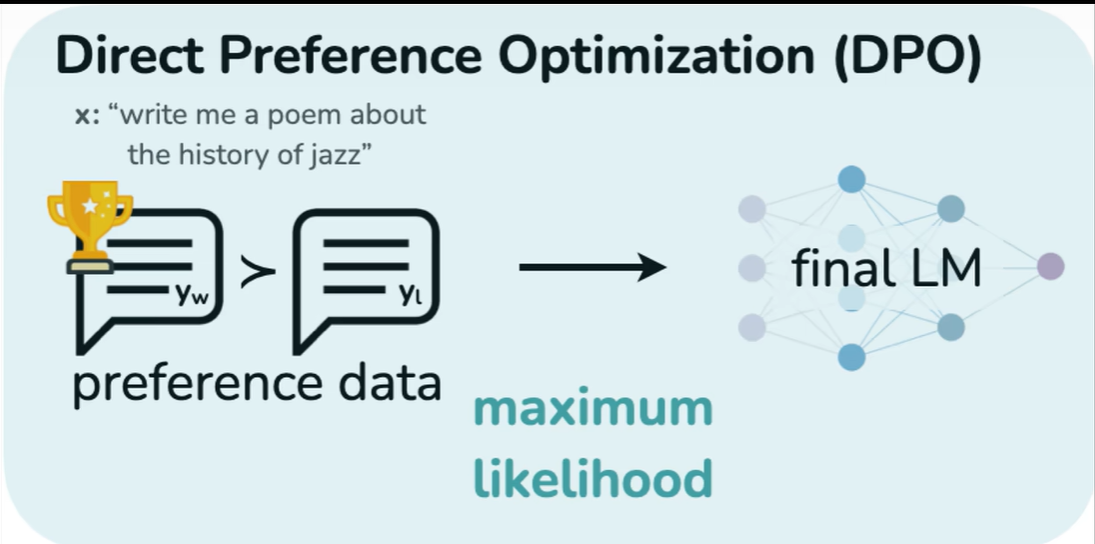
DPO(Direct Preference Optimization) 是一种用于训练语言模型的优化算法,旨在通过直接优化人类偏好的方式,改善模型的行为。DPO算法在强化学习与人类反馈(RLHF)的背景下发展,目的是在不依赖于复杂的奖励模型的情况下,直接优化模型输出的质量
DPO算法大概流程如下图所示,可以明显看出少了RM模型。
接下来引入几个基本概念:
Bradley-Terry模型:
Bradley-Terry模型是一种用来描述配对比较(pairwise comparison)中的概率的统计模型,广泛应用于竞争、偏好排序和选择模型等场景。它特别适用于那些我们需要根据不同选项的相对优劣来推断概率的情境,例如在体育比赛、推荐系统或者用户偏好排序中。
在Bradley-Terry模型中,我们假设有 n 个选项(或参与者),每对选项都会进行一次比较,结果是一个胜负关系。例如,在一个比赛中,两个选手 A 和 B 进行对决,我们会观察哪个选手获胜。
模型的核心假设是,每对选项的胜负取决于它们的“能力”或“优越性”。假设每个选项 i 有一个未知的“能力”参数 (通常
i>0),且更大的能力值对应着更高的获胜概率。
具体来说,对于两个选项 i 和 j,它们的胜负概率由以下公式给出:

结合具体例子来理解

为求出、
、
,使用对数最大似然估计
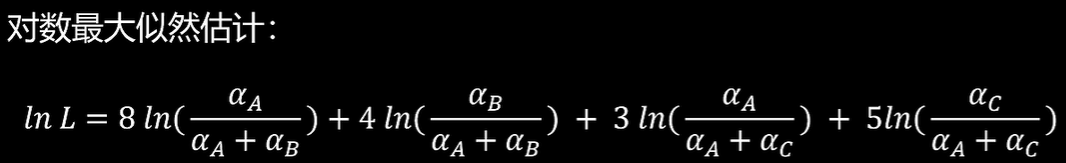
让对数最大似然估计求导为0即可。

函数形式为
,因此可以将损失函数化简为
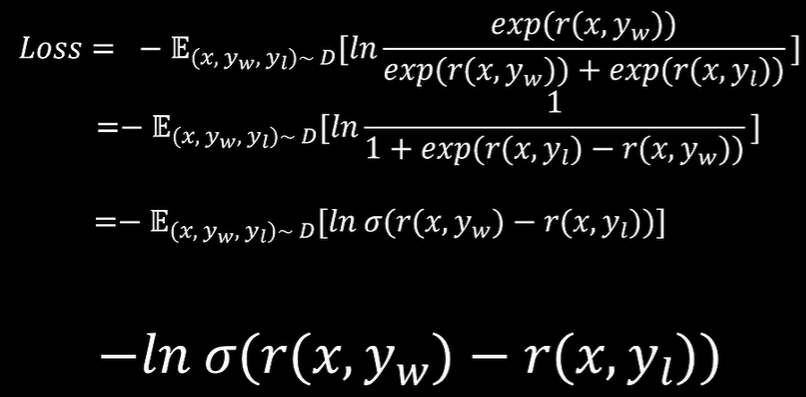
DPO损失函数
接下来可以开始DPO的讲解,DPO由以下几部分组成:
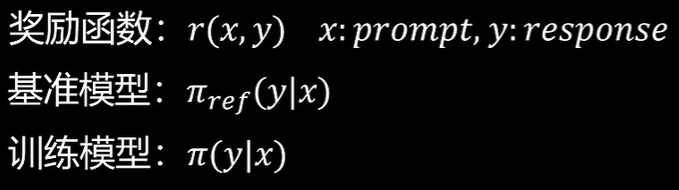
奖励模型的训练目标为
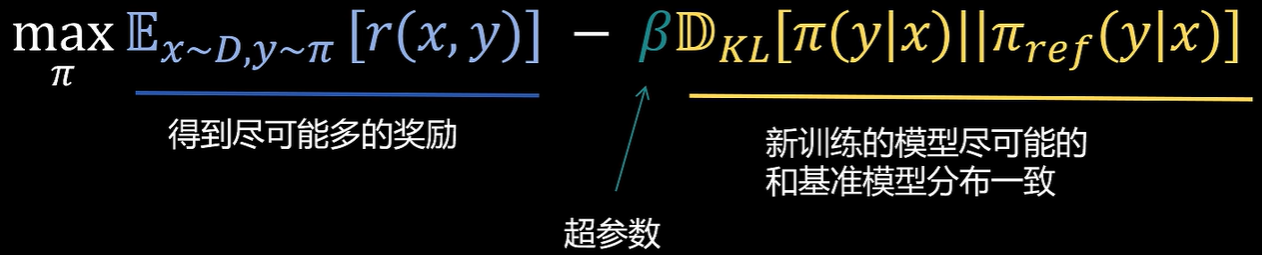
对训练目标进行化简
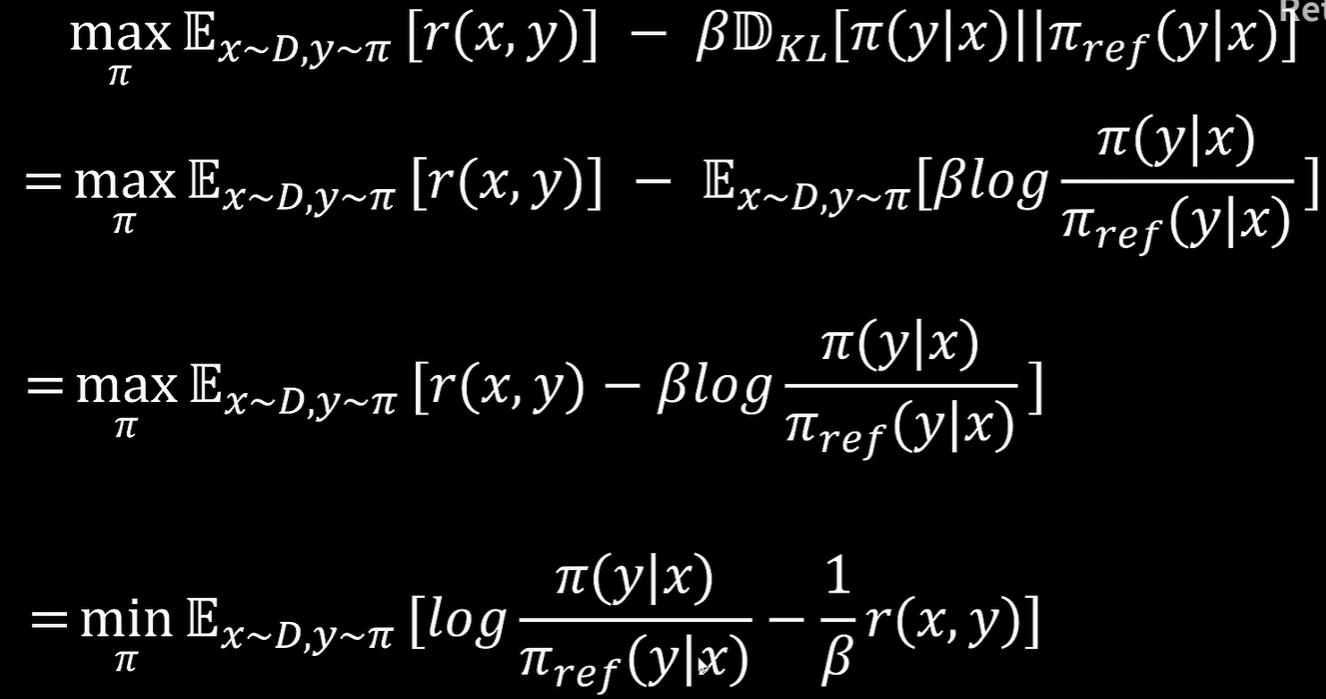
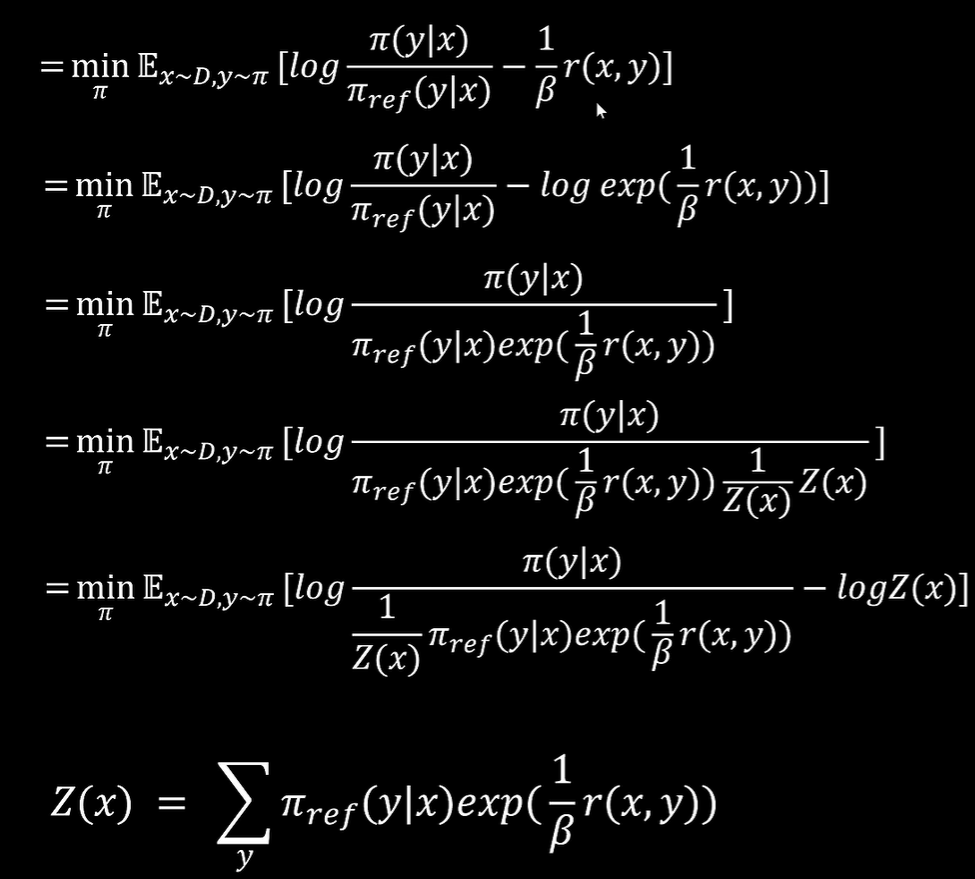
将Z(x)带入得
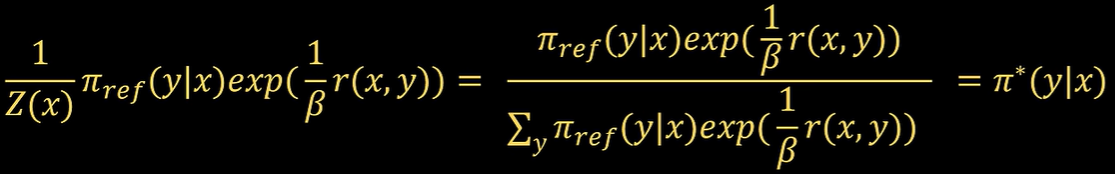
也就是说可表示为所有策略的和比某一种策略,因此可以视为概率分布,用
表示。
进一步化简为,由于Z(x)与无关,因此可以在第二部中去掉Z(x)
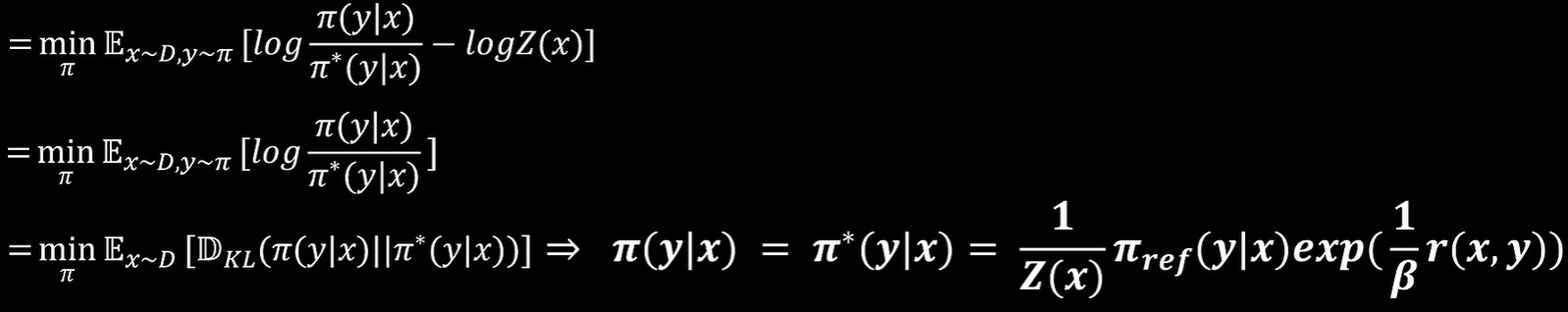
当和
相同时KL散度最小,也就是说需要训练的网络
为
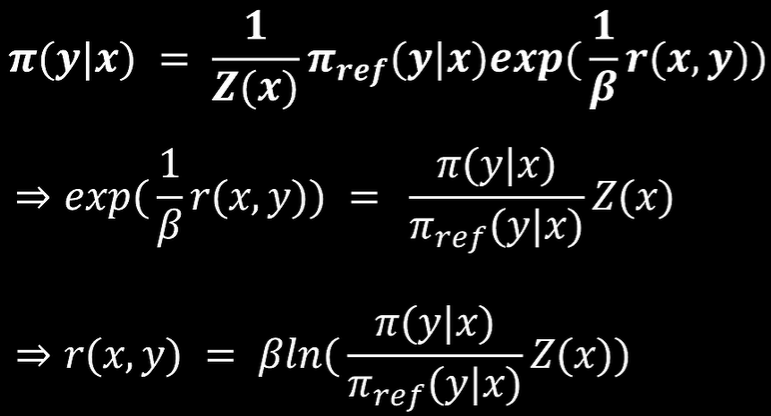
Bradely-Terry模型损失函数样式为
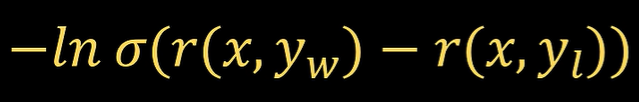
因此DPO损失函数为
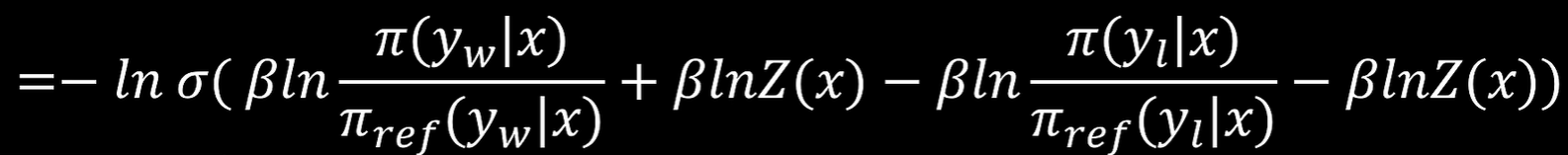
DPO损失函数为

参考:
DPO (Direct Preference Optimization) 算法讲解_哔哩哔哩_bilibili