突破智能体训练效率瓶颈:Tree Training如何通过共享前缀重用实现3.9倍加速?
突破智能体训练效率瓶颈:Tree Training如何通过共享前缀重用实现3.9倍加速?
本文将介绍Tree Training这一创新训练范式,它针对智能体LLM场景中的分支行为特征,通过Tree Packing和Gradient Restoration技术,实现共享前缀的高效重用,在多个开源模型上实现了高达3.9倍的训练时间减少,为大规模智能体LLM的SFT和RL训练提供了新的效率优化方案。
论文标题:Tree Training: Accelerating Agentic LLMs Training via Shared Prefix Reuse
来源:arXiv:2511.00413 [cs.LG],链接:https://arxiv.org/abs/2511.00413
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
在智能体LLM场景中,单个rollout过程中的交互过程经常表现出分支行为。由于在特定决策点的内存检索和并发工具执行,一个任务的token轨迹演变为树状结构而非线性序列。然而,当前的训练管道将这种树状轨迹分解为独立的线性片段,将每个分支视为独立序列处理。这导致在前向和反向传播过程中,跨分支的共享前缀被重复计算,造成了严重的计算效率低下问题。
研究问题
- 现有训练方法将树状轨迹分解为线性片段,导致共享前缀在前向和反向传播中被重复计算
- 智能体交互中的分支行为(内存检索、并发工具执行)产生的计算冗余未被有效利用
- 大规模智能体LLM训练中,计算效率成为制约训练速度和规模扩展的关键瓶颈
主要贡献
- 提出Tree Training新范式,通过共享前缀重用显著提升智能体LLM训练效率
- 设计Tree Packing机制,高效重用轨迹间的共享计算,避免重复计算
- 开发Gradient Restoration技术,确保重用前缀的正确梯度传播
- 在多个开源模型上验证效果,实现高达3.9倍的训练时间减少
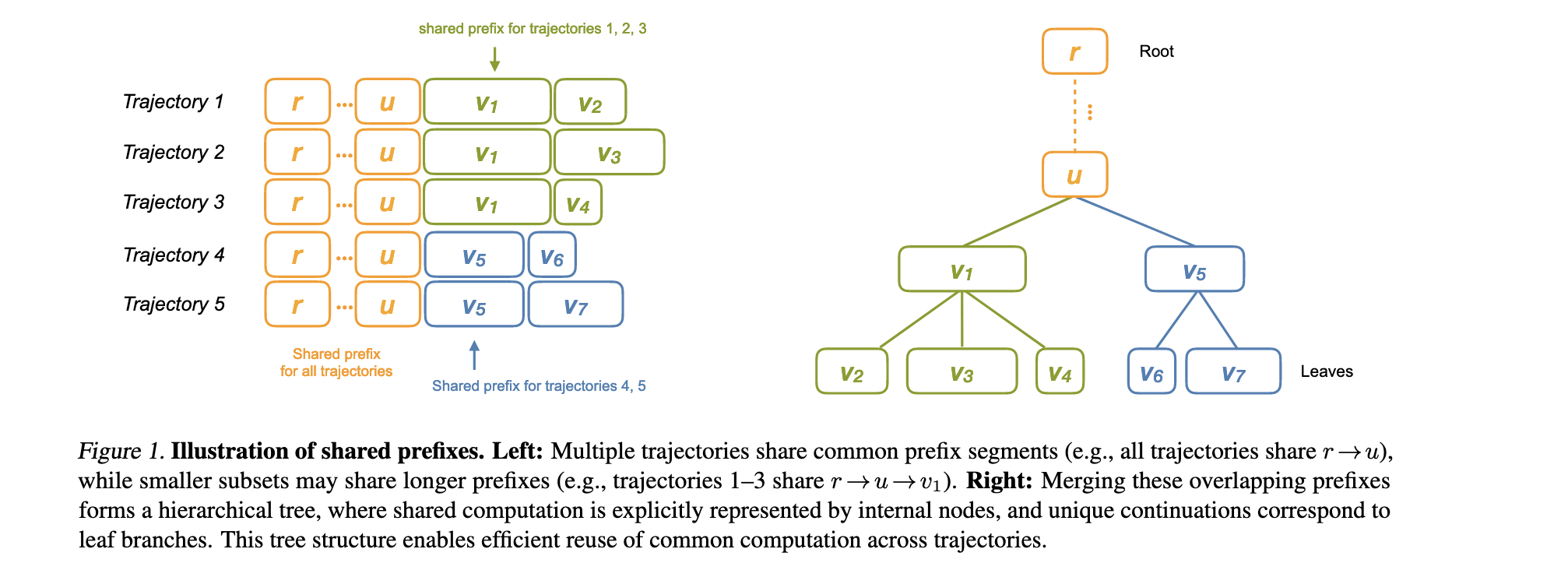
方法论精要
Tree Training核心思想
Tree Training的核心洞察是智能体LLM在交互过程中产生的树状轨迹结构中存在大量共享前缀。传统方法将树状结构分解为独立的线性序列,导致共享前缀在多个分支中被重复计算。Tree Training通过保持轨迹的树状结构,在训练过程中智能地重用共享前缀的计算结果。
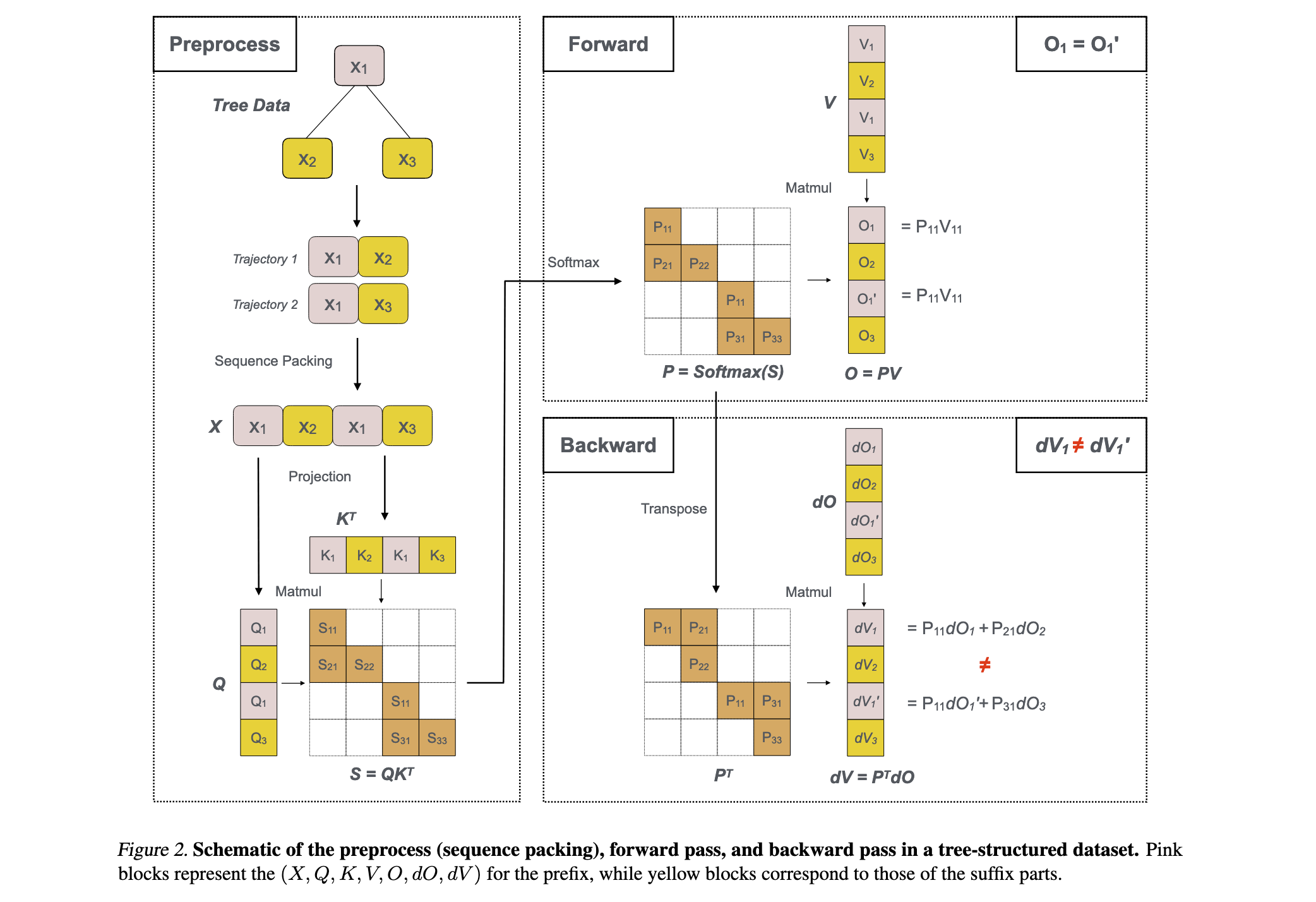
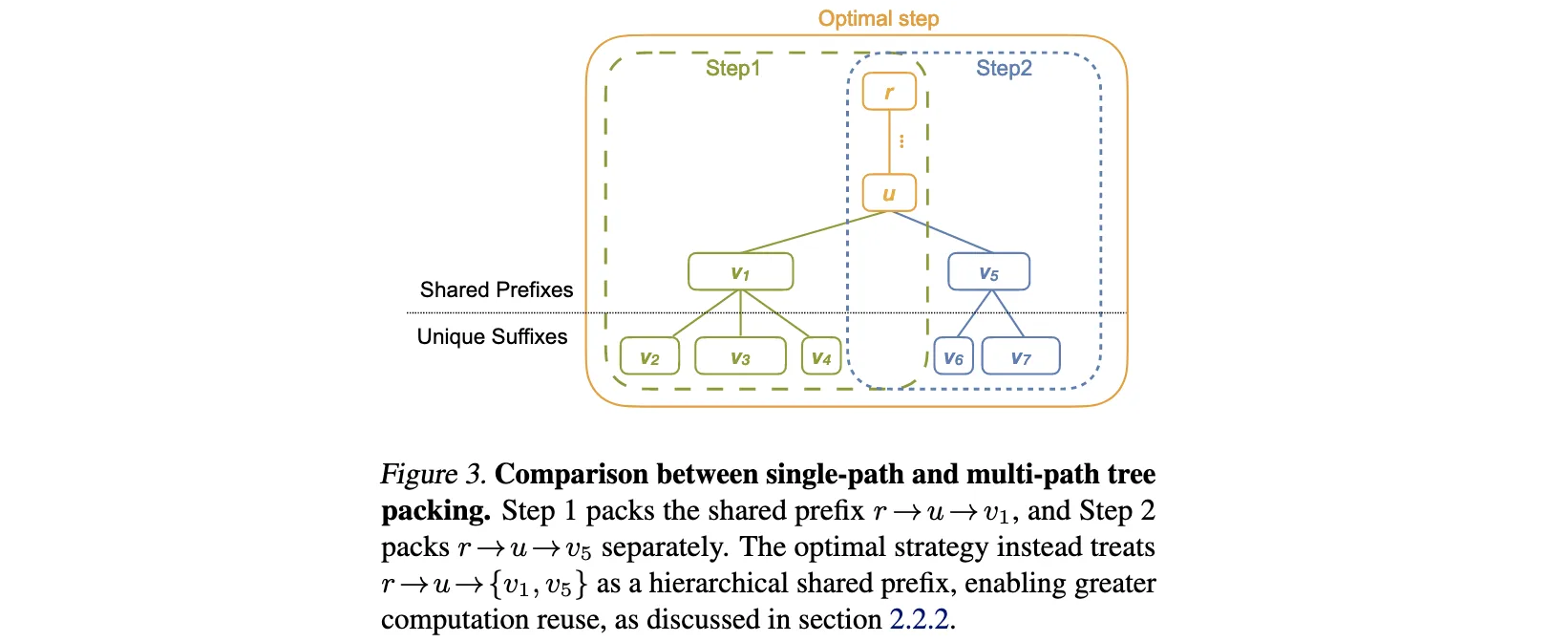
Tree Packing机制
- 轨迹分析:分析智能体交互轨迹,识别树状结构中的共享前缀和分支点
- 前缀识别:通过算法识别不同轨迹间的最长公共前缀序列
- 计算重用:在前向传播中,对每个共享前缀只计算一次,将中间结果缓存
- 分支处理:从分支点开始,为每个分支独立计算后续token
- 内存管理:智能管理中间结果的缓存和释放,平衡内存使用与计算效率
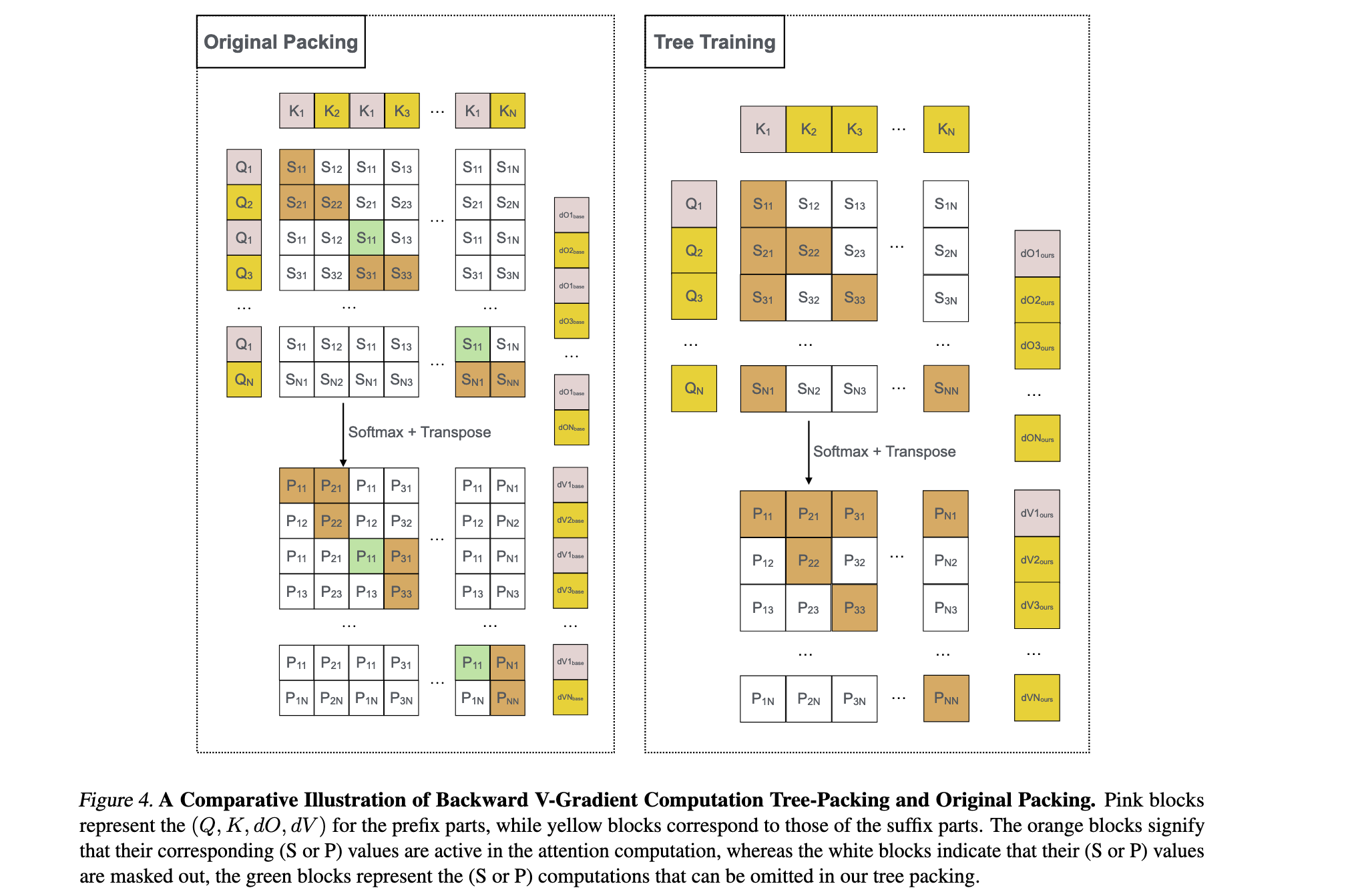
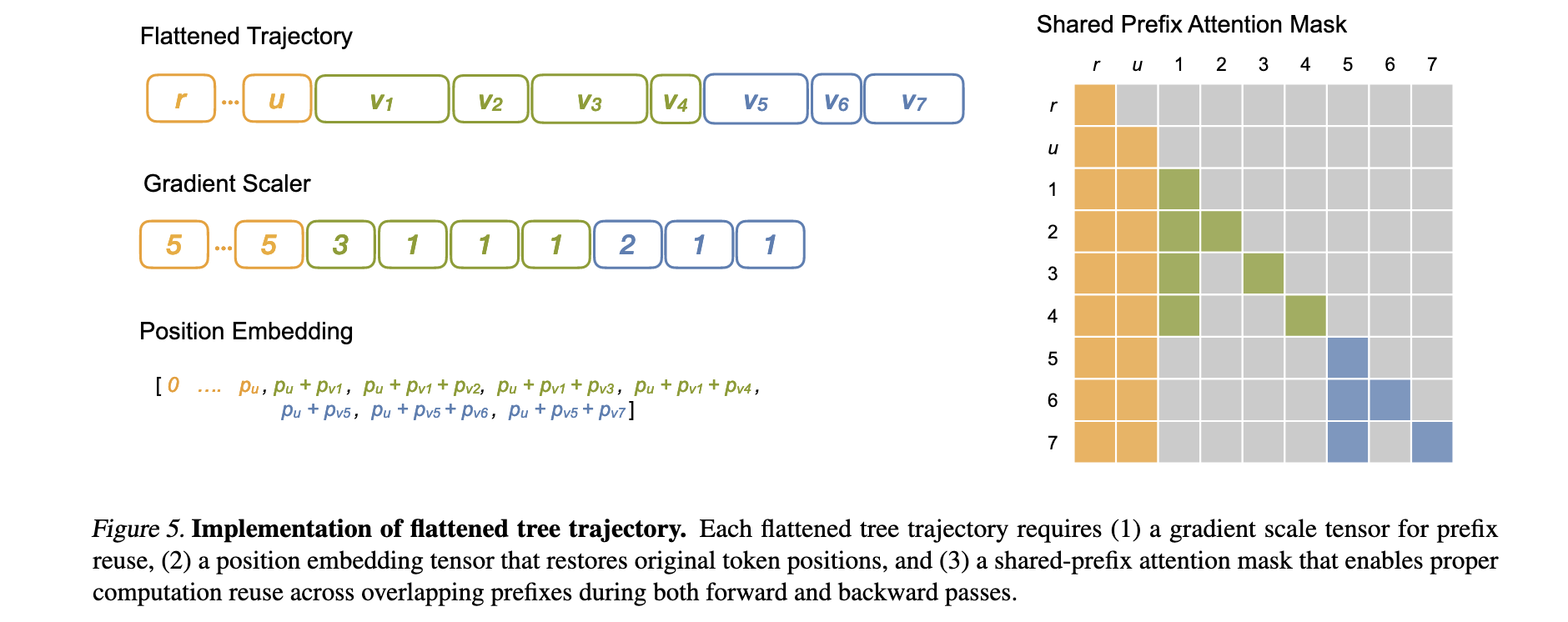
Gradient Restoration技术
- 梯度收集:在反向传播过程中,收集每个分支对共享前缀的梯度贡献
- 梯度累加:将来自不同分支的梯度正确累加到共享前缀的参数上
- 梯度归一化:根据分支数量对梯度进行适当归一化,确保训练稳定性
- 梯度验证:通过数学证明验证梯度累加的正确性,保证训练收敛性
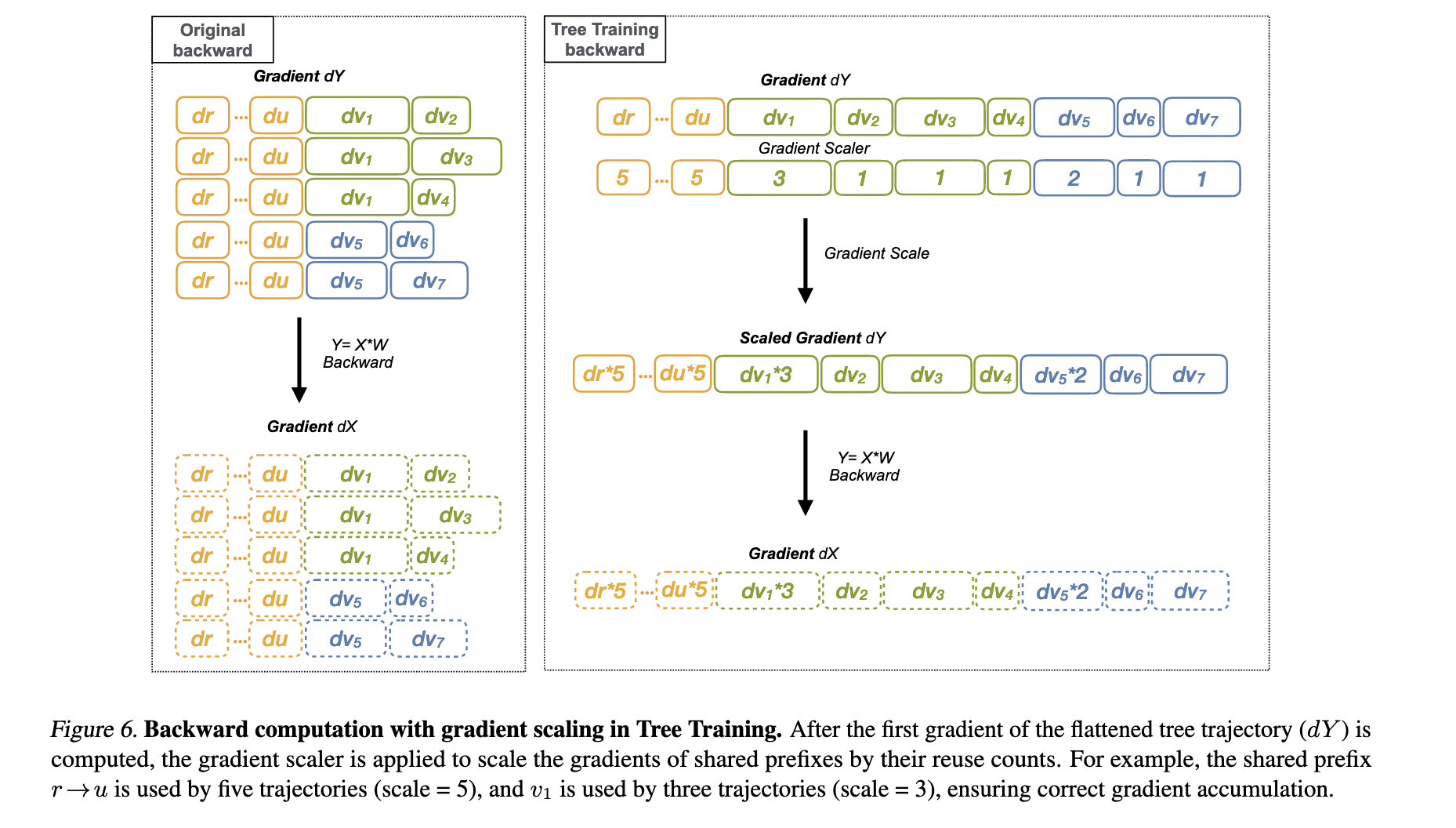
算法实现细节
- 前向传播优化:
- 构建轨迹树结构,标记共享节点和分支节点
- 按拓扑序处理节点,确保依赖关系正确
- 对共享节点只执行一次前向计算
- 将激活值缓存供反向传播使用
- 反向传播优化:
- 从叶子节点开始反向传播
- 在共享节点处收集来自所有子节点的梯度
- 将梯度累加并传播到父节点
- 释放不再需要的中间激活值
- 内存效率优化:
- 智能缓存管理,只保留必要的中间结果
- 渐进式内存释放,减少峰值内存使用
- 支持梯度检查点技术,进一步降低内存需求
实验洞察
实验设置
- 测试模型:
- 多个开源LLM模型,涵盖不同规模和架构
- 包括基于Transformer的主流模型架构
- 模型参数规模从数亿到数百亿不等
- 训练场景:
- 智能体SFT(Supervised Fine-Tuning)训练
- 智能体RL(Reinforcement Learning)训练
- 多种智能体任务和交互场景
- 基线对比:
- 传统线性化训练方法
- 其他计算优化方案
- 不同批处理和序列长度设置
性能提升结果
- 训练时间减少:
- 在多个模型上实现2.5x到3.9倍的训练时间减少
- 大型模型上的优化效果更加显著
- SFT和RL训练场景下均有明显提升
- 内存使用优化:
- 峰值内存使用减少15%到30%
- 内存访问模式更加优化
- 支持更大批处理大小
- 计算效率提升:
- FLOPs利用率显著提高
- GPU计算资源得到更充分利用
- 等待时间大幅减少
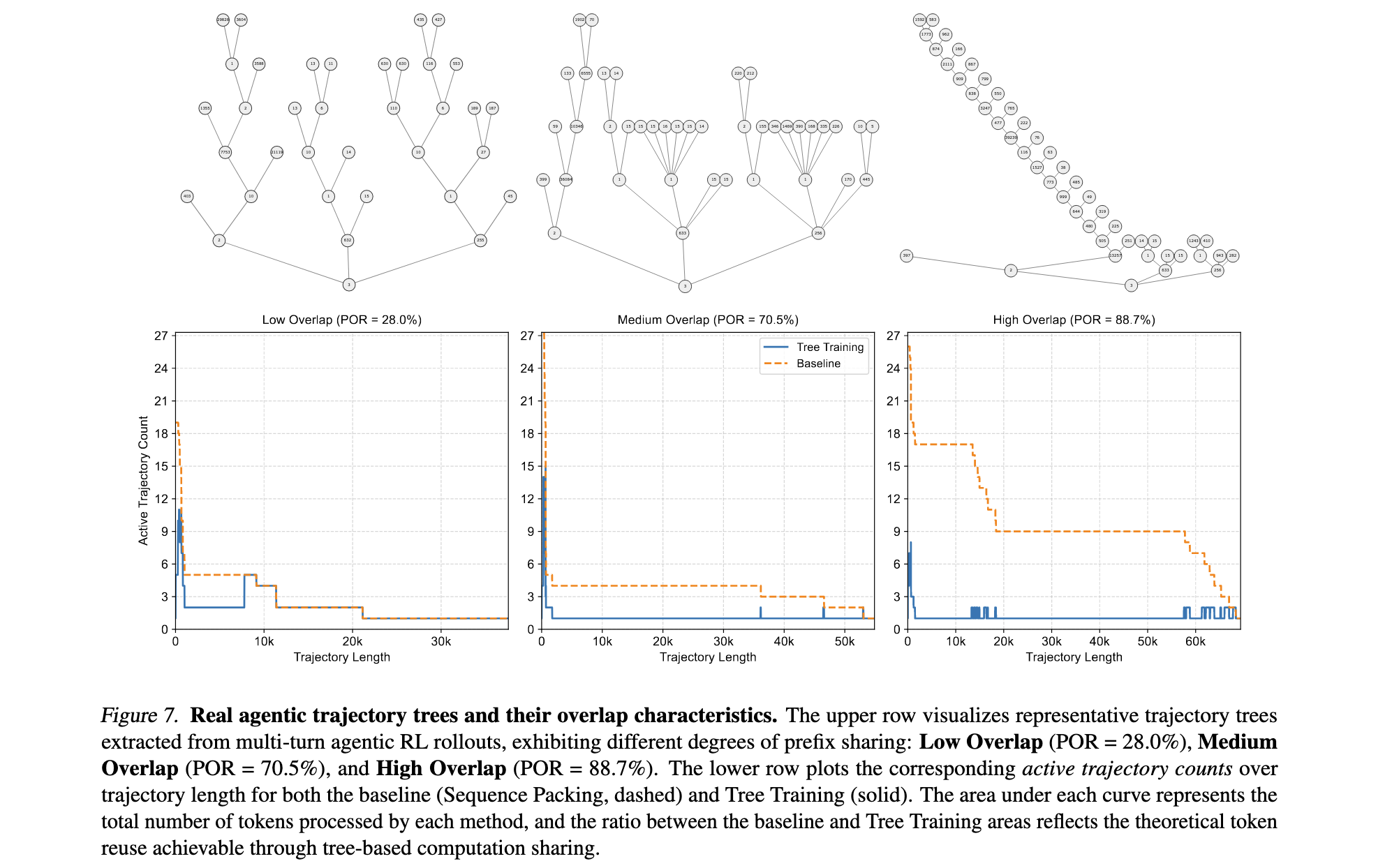
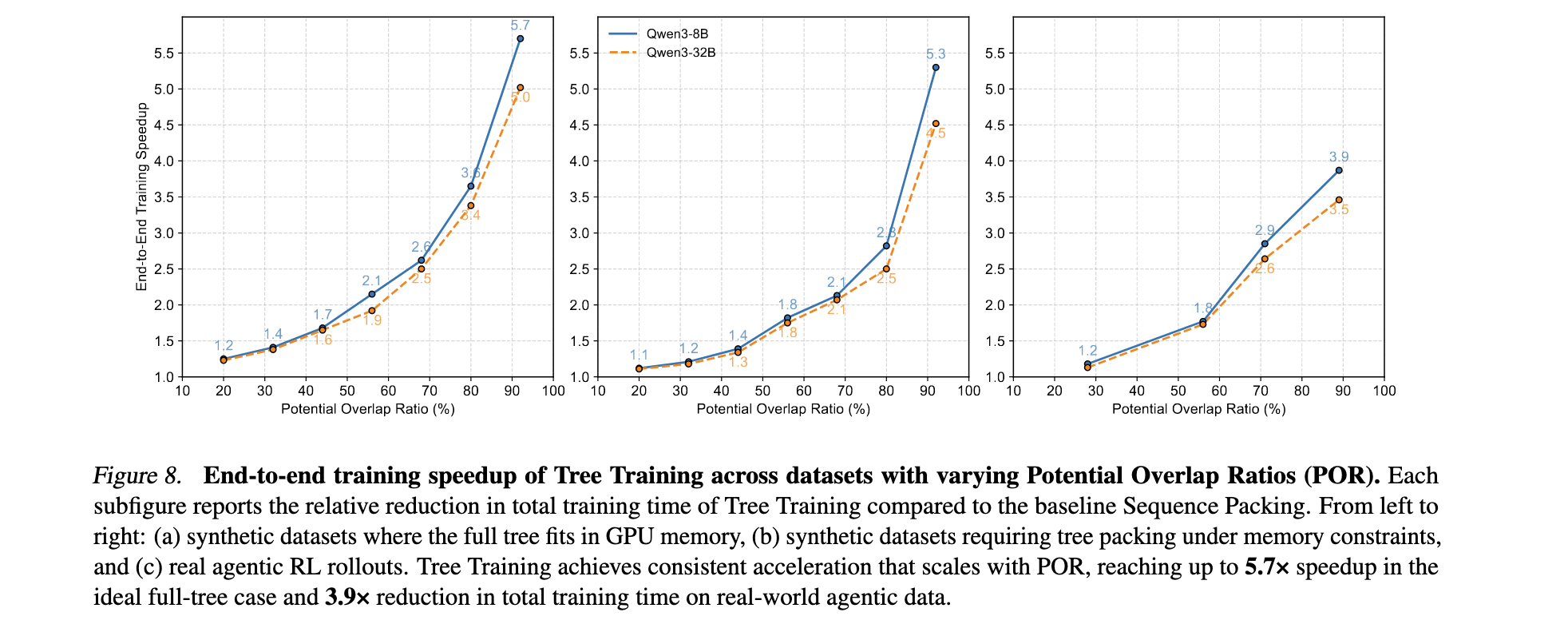
消融实验分析
- 组件贡献分析:
- Tree Packing贡献约60%的性能提升
- Gradient Restoration贡献约40%的性能提升
- 两者协同作用产生最佳效果
- 不同场景下的表现:
- 分支越多、共享前缀越长的场景优化效果越好
- 简单线性轨迹场景下性能提升有限
- 复杂智能体交互场景下优势明显
- 参数敏感性分析:
- 不同模型规模下优化效果稳定
- 各种超参数设置下表现鲁棒
- 训练收敛性不受影响
实际应用价值
- 训练成本降低:
- 显著减少计算资源需求
- 降低训练时间和能耗成本
- 提高资源利用效率
- 扩展性提升:
- 支持更大规模的智能体训练
- 为复杂智能体系统提供可能
- 推动智能体LLM的实用化进程
- 生态系统影响:
- 可集成到现有训练框架中
- 与其他优化技术兼容
- 为智能体LLM研究提供基础设施支持
局限性与未来工作
- 适用范围:
- 主要适用于具有明显分支行为的智能体场景
- 简单线性任务中优势有限
- 需要轨迹具有一定的共享前缀结构
- 实现复杂度:
- 算法实现相对复杂
- 需要对现有训练框架进行修改
- 调试和维护成本较高
- 未来改进方向:
- 进一步优化内存使用效率
- 探索更多类型的计算重用模式
- 扩展到更多模型架构和训练场景