【强化学习】可证明安全强化学习(Provably Safe RL)算法详细介绍
📢本篇文章是博主强化学习(RL)领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对相关等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在👉强化学习专栏:
【强化学习】---《可证明安全强化学习(Provably Safe RL)算法详细介绍》
可证明安全强化学习(Provably Safe RL)算法详细介绍
目录
一、安全强化学习(Safe Reinforcement Learning, Safe RL)简要介绍
二、安全强化学习的发展历程
三、可证明安全 RL(Provably Safe RL)的三类技术
四、实验设置
五、论文运行结果
六、产业级落地案例(2025)
七、挑战
八、总结
一、安全强化学习(Safe Reinforcement Learning, Safe RL)简要介绍
安全强化学习(Safe RL)是强化学习(RL)的一个分支,它关注于在训练智能体时,确保其行为不违反预定的安全约束或规则。传统的强化学习方法侧重于最大化奖励,而安全强化学习的核心目标是要在探索和学习过程中避免可能的风险和负面后果,尤其是在涉及物理环境、医疗、自动驾驶等高风险领域时,安全性显得尤为重要。
在实际应用中,安全强化学习要求智能体在学习过程中不仅要探索环境以获得最大化的回报,还要遵循一定的安全约束,这些约束可以是物理的、法律的、道德的或其他形式的限制。比如,在自动驾驶中,除了要求车辆能够找到最短路径外,还要避免交通事故、遵守交通规则等。
为什么强化学习需要“安全锁”?
想象一下,你正在训练一个无人机自己飞行。它通过试错学习如何悬停、转向、避障。但问题是:
它可能会在训练中“作死”——比如直接俯冲地面,或者撞墙。传统的强化学习(RL)算法只关心“怎么获得最大奖励”,不关心“会不会出事”。
但在现实系统中(自动驾驶、机器人、电网控制),一次“出事”就可能导致灾难性后果。于是,**Safe Reinforcement Learning(安全强化学习)**应运而生。
而今天我们要聊的,是Safe RL中的“硬核派”——
👉 Provably Safe RL:可证明安全的强化学习。
二、安全强化学习的发展历程
安全强化学习作为一个较为新兴的领域,主要发展历程可以分为几个关键阶段:
1. 初步探索(2000年-2010年)
在2000年左右,强化学习的研究主要集中在如何让智能体在复杂环境中学习行为策略。但当时大多数的强化学习方法没有考虑到安全性问题。研究者关注的重点是如何通过奖励信号驱动智能体学习,并通过试错法探索环境,而不是对安全问题进行特别考虑。
2. 安全性概念的引入(2010年-2015年)
随着强化学习在实际应用中的潜力不断增加,特别是在机器人、自动驾驶等领域,研究者逐渐认识到,仅仅依靠奖励信号可能导致智能体做出危险的行为。例如,自动驾驶的智能体可能会在遇到突发状况时做出危险的决策,从而带来安全隐患。
在这个阶段,研究者开始提出一些初步的安全强化学习框架,考虑了如何在智能体探索环境的同时限制其行为范围,避免智能体执行不安全的动作。一些早期的安全强化学习方法引入了约束优化的概念,强调智能体在学习过程中满足某些安全约束。
早期工作(~2015)以“修改优化准则”或“限制探索策略”为主,如通过约束策略更新幅度、引入惩罚信号等方式降低风险
3. 约束强化学习(2015年-2020年)
约束强化学习(Constrained RL)成为了安全强化学习研究的一个重要方向。研究者开始关注如何通过优化算法将安全约束整合到强化学习的框架中。最常见的方法是通过“安全约束”来修正奖励函数,使智能体在学习过程中避免做出有害的行为。这个方向的研究引入了形式化的安全性指标,如概率安全性、期望风险等,并基于这些指标对强化学习算法进行了改进。
一些典型的安全强化学习算法包括:
- 基于风险的强化学习(Risk-sensitive RL):通过在奖励函数中加入风险度量(例如方差、尾部风险等),来限制智能体的风险暴露。
- 安全约束优化方法:在强化学习的优化过程中,通过引入硬性约束或软性约束,确保智能体的行为在给定的安全范围内进行。
4. 深度安全强化学习(2020年至今)
随着深度学习技术的发展,深度强化学习(Deep RL)逐渐成为解决复杂任务的重要工具,尤其是在图像识别、自然语言处理、机器人控制等领域取得了显著进展。然而,深度强化学习模型的复杂性也导致了智能体的行为更加难以预测,从而带来更大的安全隐患。
因此,深度安全强化学习(Deep Safe RL)应运而生,它结合了深度学习和安全强化学习的思想,旨在设计能够保证在高维度、复杂环境中安全学习的智能体。例如,深度安全强化学习可以通过深度神经网络对环境进行建模,并在模型中引入安全性约束,确保智能体在复杂环境中既能学习到有效的策略,又能避免不安全的决策。
随着无模型深度强化学习(DRL)成熟,安全RL开始追求形式化保证,即可证明安全(provably safe)。研究重点转向:
-
在训练与部署阶段均提供硬安全约束;
-
利用可达性分析、控制屏障函数(CBF)、动作投影等方法,将安全约束转化为可验证的数学条件
德国慕尼黑工业大学(Technical University of Munich, TUM)学者Hanna 等,在2022年发表了《Provably Safe Reinforcement Learning: Conceptual Analysis, Survey, and Benchmarking》一项系统级研究,,为Safe RL社区首次提供了统一的理论框架 + 实验对比 + 实用建议,是进入“可证明安全强化学习”领域的必读入门文献。
5.总体框架:从“经验安全”到“可证明安全”
| 安全层级 | 技术特征 | 代表方法 | 2025年成熟度 |
|---|---|---|---|
| Ⅰ. 启发式安全 | 奖励塑形/风险项 | Lagrangian RL、CVaR | 已落地,但无硬保证 |
| Ⅱ. 概率安全 | 高概率满足约束 | 风险敏感RL、Chance-CBF | 工业界开始试点 |
| Ⅲ. 可证明安全 | 训练+部署全程硬约束 | 动作投影/替换/遮蔽 | 文献提出统一基准 |
Provably Safe RL 是什么?
简单来说:
Provably Safe RL 是一种在训练过程中始终满足安全约束的强化学习方法,并且这些安全性是可以数学证明的。
它不是“尽量安全”,而是100%不出事(在模型假设内)。
就像给你的AI加了一把安全锁,无论它怎么探索,都不会“越界”。
三、可证明安全 RL(Provably Safe RL)的三类技术
这篇论文提出了一种统一的框架,把现有的Provably Safe RL方法分成了三大类:
| 方法 | 核心思想 | 类比 |
|---|---|---|
| Action Replacement | 不安全动作 → 替换为安全动作 | 你说“我要跳楼”,系统说“不,咱去散步” |
| Action Projection | 不安全动作 → 投影到最近的安全动作 | 你说“我要闯红灯”,系统说“那你在路边等绿灯” |
| Action Masking | 只让AI从安全动作中选 | 你说“我能干啥?”系统说“只能选这几个安全的” |
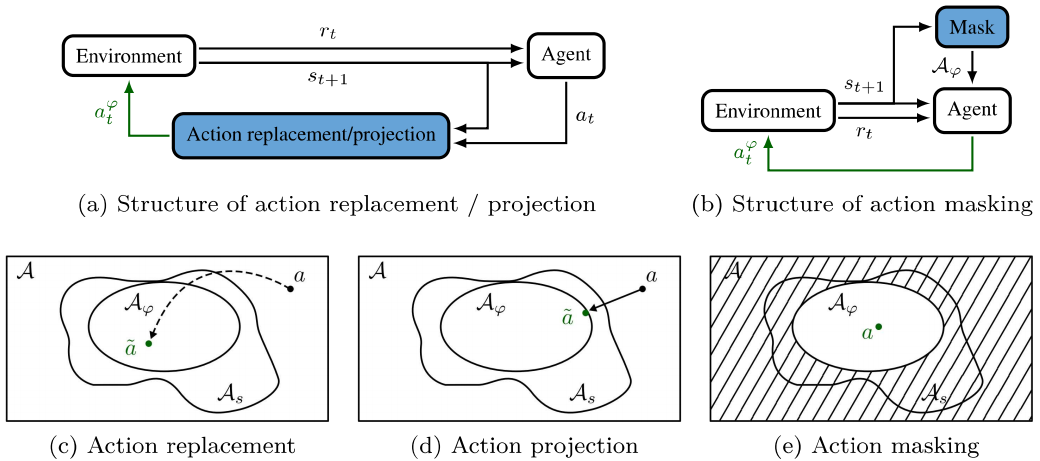

🔁 方法一:Action Replacement(动作替换)
原理:
AI输出一个动作 a∼π(s),系统用安全函数 ϕ(s,a) 检查它是否安全:
ϕ(s,a)={1, 如果动作 a 在安全集合 Asafe(s) 中
0, 否则
如果不安全,就替换为一个安全动作 a~∼ψ(s),比如:
-
随机采样一个安全动作(Uniform Sampling)
-
使用一个“安全控制器”提供的动作(Failsafe)
优点:
-
实现简单
-
安全性有保障
-
不影响策略结构(策略还是原样训练)
实验表现:
论文发现,Action Replacement 在多个任务中表现最好,尤其是在连续控制任务(如无人机悬停)中,干预率低、收敛快。
📐 方法二:Action Projection(动作投影)
原理:
不是直接替换,而是把不安全动作“拉回”到安全区域。
定义一个优化问题:
其中 dist(a,a′) 是某种距离(比如欧氏距离)。
常用技术:
-
Control Barrier Functions (CBF):把状态约束转成动作约束
-
Model Predictive Control (MPC):预测未来状态,确保不越界
优点:
-
保留了原始动作的“意图”
-
更适合连续控制任务
缺点:
-
优化问题可能无解(需要fallback)
-
数值误差可能导致不安全
-
实现复杂,计算量大
🧩 方法三:Action Masking(动作掩码)
原理:
提前告诉AI:哪些动作不能选。
在策略输出前,加一个“掩码”:
优点:
-
不改变策略结构
-
安全性最高(AI根本选不了不安全的动作)
缺点:
-
需要高效计算安全动作集合 Asafe(s)
-
在连续动作空间中很难实现(论文提出了一个初步方法)
关键使能组件:安全函数 φ(s,a) 如何得来?
| 类型 | 技术路线 | 2025 代表进展 |
|---|---|---|
| 基于模型 | 微分动态逻辑/可达集 | Hunt21 用定理证明器生成 φ,适用于无人机 6D 状态 |
| 无模型 | 集合可达性(Zonotope) | Shao21 提出“黑箱”Zonotope 可达性,可包未知扰动 |
| 学习式 | 神经网络 CBF | 2025 多篇工作把 CBF 参数化为 NN,再联合策略一起更新 |
| 概率式 | 概率 CBF (p-CBF) | 用于匝道合并,把模型不确定→概率边界,保证 99% 安全 |
四、实验设置
2025 年综述首次把「如何训练」提炼成 4 种 Learning Tuple,对应不同安全-效率权衡:
-
Naive tuple:只有替换/投影,不加惩罚; baseline。
-
Penalty tuple:每次触发安全校正,立即给负奖励 r_penalty;实验显示可再提 5–15% 收敛速度。
-
Adaption tuple:随训练进程把 r_penalty 指数衰减,兼顾探索与安全性。
-
Failsafe tuple:强制用保守动作,用于「绝不能碰」场景(电网、化工)。
-
基准平台:倒立摆(连续)、2D 四旋翼(连续)、离散无人机避障。
-
评价指标:
-
安全率(% Episode 零违规)
-
累积奖励
-
样本效率(到阈值所需 episode 数)
-
-
开源:代码与 Docker 镜像已随论文发布,支持五种 RL 算法(PPO、SAC、DDPG、DQN、TRPO)
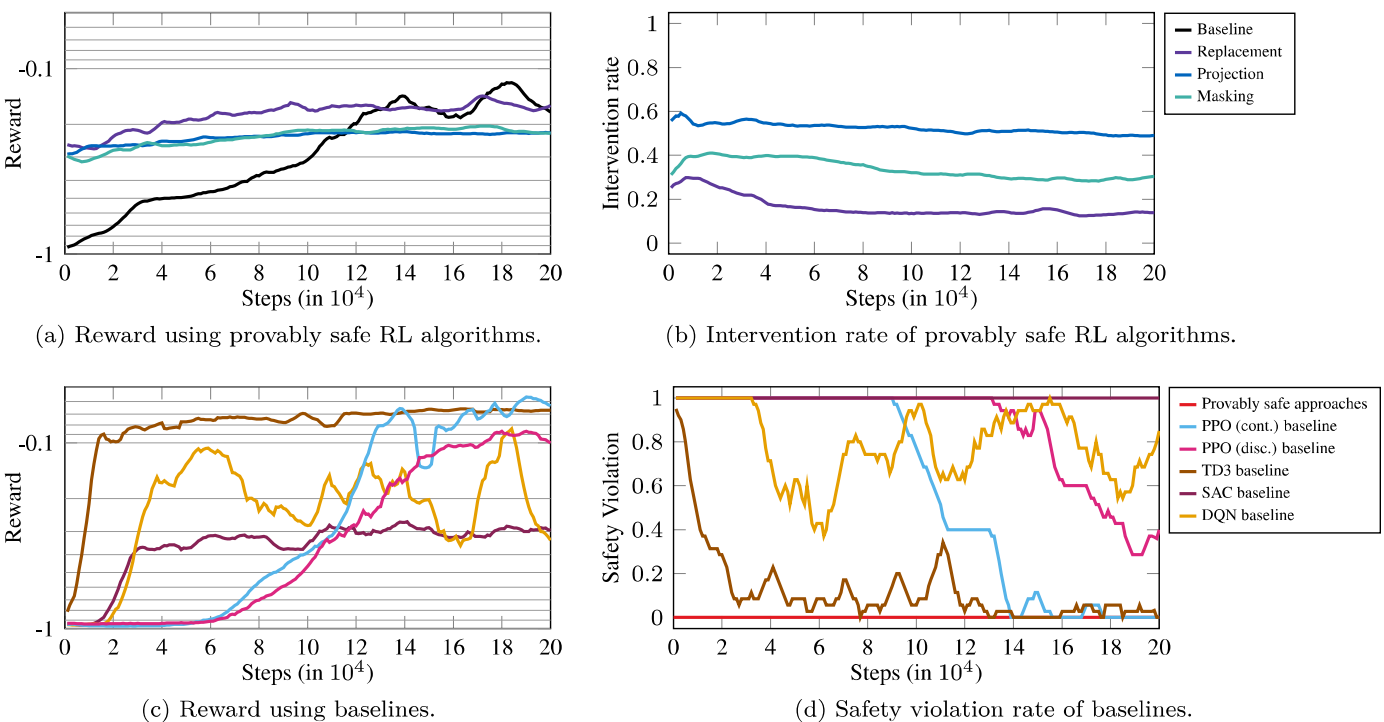
五、论文运行结果
✅ 实验结论一:所有Provably Safe方法都真的安全
-
没有一次安全违规(Safety Violation = 0)
-
而普通RL算法(如PPO、SAC)经常“翻车”
✅ 实验结论二:Action Replacement 表现最好
-
收敛最快
-
干预率最低
-
实现最简单
✅ 实验结论三:Adaption Penalty 有助于学习
在训练时,如果AI提出了不安全动作,即使被替换了,也给它一个惩罚:
这能让AI更快学会避免不安全动作,提升整体性能。
六、产业级落地案例(2025)
| 场景 | 技术组合 | 安全效果 |
|---|---|---|
| 四旋翼室内避障 | 集合可达性+动作替换 | 1000 次实验 0 碰撞,风速扰动±15% |
| F1TENTH 高速换道 | CBF+动作投影 | 40 km/h,0 碰撞,通过率↑18% |
| Unitree G1 人形楼梯 | CBF-RL 训练期过滤 | 无需在线滤波,连续爬 40 级台阶无跌倒 |
| 电力系统暂稳控制 | 失效保护替换 | 短路故障后 200 ms 内稳定,违规率 0%(RTDS 硬件在环) |
| 轴孔精密装配 | 安全 RL+变阻抗 | 训练期力超 30 N 即被替换,真实产线良率↑6% |
七、挑战
尽管安全强化学习已经取得了许多进展,但仍然存在许多挑战和未解问题。未来的研究方向可能包括:
- 可解释性与透明度:为了确保智能体的行为符合安全要求,研究者需要开发更为可解释的强化学习模型,尤其是在复杂的深度强化学习系统中。
- 更复杂的安全约束:当前的安全强化学习方法主要集中在物理安全约束,未来可能需要引入更多维度的安全性考虑,例如道德伦理、安全合规性等。
- 强化学习的在线安全性:如何在动态变化的环境中保证智能体始终保持安全行为,尤其是在学习过程中,如何根据实时反馈调整策略,是一个重要的研究问题。
-
高维状态-动作空间的可验证爆炸
2025 年最前瞻工作用「低维抽象+过近似扰动」+一致性检查,可把 30 维系统压到 6 维抽象,但如何自动抽象仍是开放问题。 -
Sim2Real 安全 gap
真机动力学/感知误差可能导致 φ(s,a) 过乐观;最新思路是「元学习 CBF」——先在仿真随机 CBF 参数,再在线微调 5–10 参数。 -
多智能体「非平稳+耦合安全」
2025 提出分布式 CBF,把联合安全集做 Dantzig-Wolfe 分解,但规模仍受限于 QP 求解器。 -
人机共融
人类可引发「被动安全」违规;需要 legal safety 新定义与责任分配框架。 -
标准与法规
ISO 23099(RL 功能安全)尚在草案;可证明安全 RL 的「验证证据」如何被认证机构采信,需要形式化描述语言 + 自动证明工具链。
八、总结
安全强化学习是一个跨学科的研究领域,它不仅结合了强化学习的基本理论,还涉及到风险管理、安全工程、决策理论等多个领域。随着智能体在实际应用中的普及和复杂性增加,安全强化学习将继续发展,并成为未来自动化系统中的重要组成部分
-
2025 年,安全强化学习已走出“奖励加惩罚”的初级阶段,进入「可证明安全」+「实验可重复」的新阶段。
-
动作替换/投影/遮蔽三大技术路线首次被统一比较,开源基准已发布,产业案例覆盖无人机、赛车、人形机器人、电网、精密装配。
-
下一步,高维实时验证、Sim2Real 安全 gap、多智能体与人机共融,将是学术界与工业界协同攻关的主战场。
📌 论文标题:Provably Safe Reinforcement Learning: Conceptual Analysis, Survey, and Benchmarking
📌 论文地址:[arXiv链接]
📌 代码开源:CodeOcean项目页
更多强化学习文章,请前往:【强化学习(RL)】专栏
博客都是给自己看的笔记,如有误导深表抱歉。文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者添加VX:Rainbook_2,联系作者。✨