AWS Bedrock Agent 结构化数据查询系统
摘要
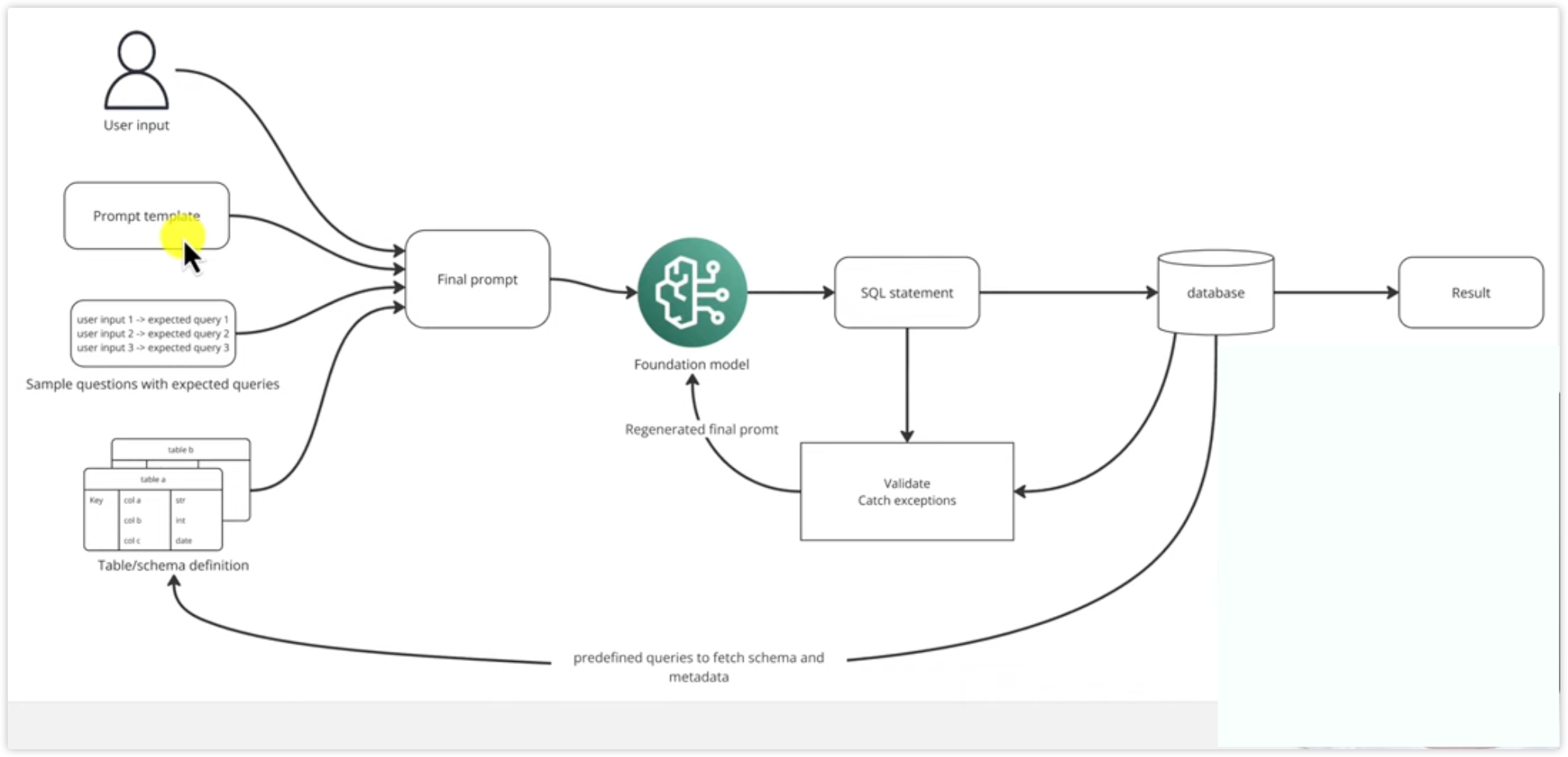
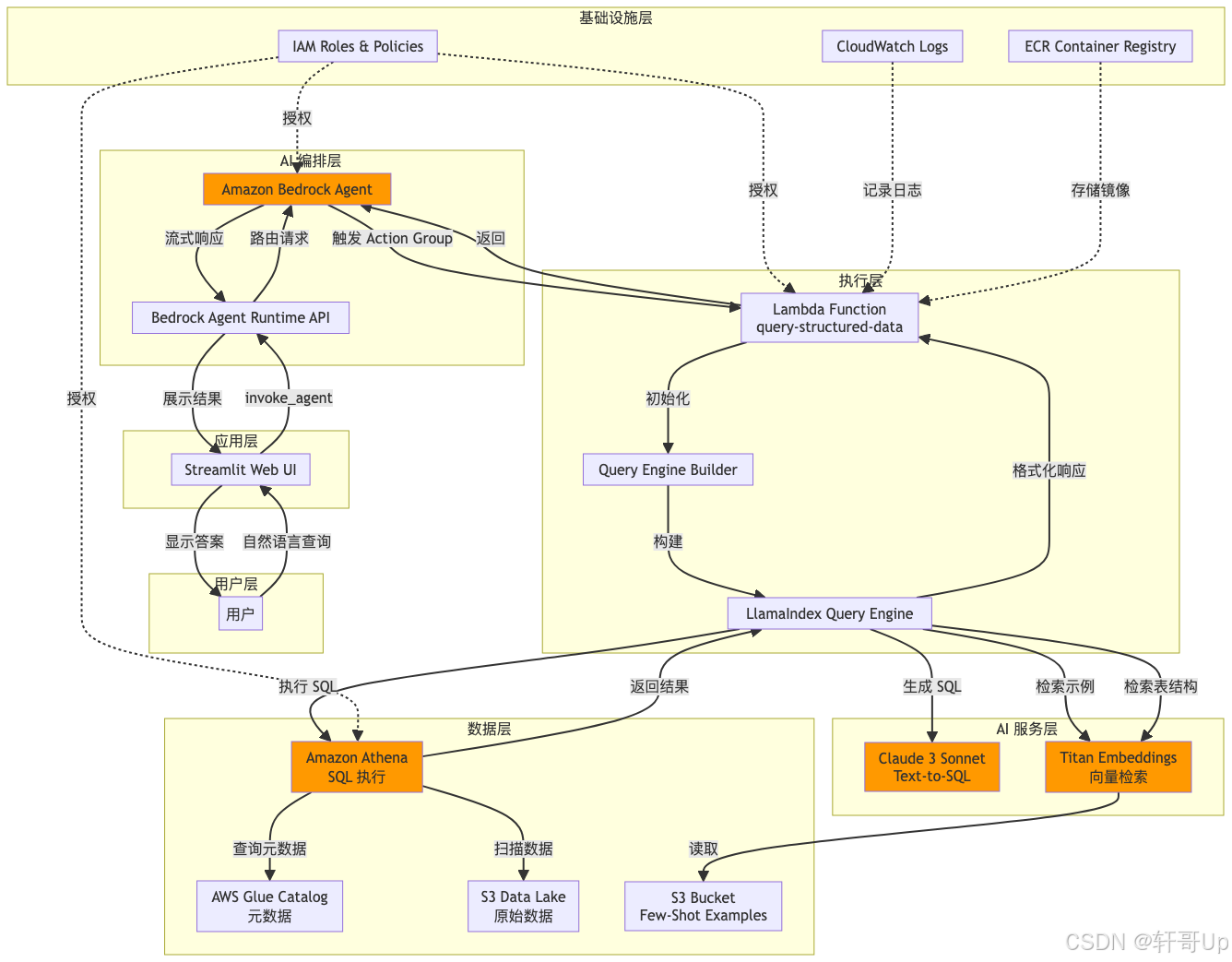
本文深度剖析基于 Amazon Bedrock Agent 的智能数据库查询系统,该系统通过 LLM 驱动的 Text-to-SQL 技术实现自然语言到结构化数据的查询转换。系统采用 Lambda 函数作为 Action Group、LlamaIndex 作为查询引擎、Athena 作为数据源,结合 Few-Shot Learning 和向量检索技术,构建了一个高效的 AI 驱动数据分析平台。本文将从架构设计、核心实现到部署实践进行全面解读。
1. 应用场景
本项目适用于以下典型业务场景:
1.1 企业数据分析
- 业务分析师无需掌握 SQL 语法,通过自然语言即可查询销售数据、产品信息、客户订单等结构化数据
- 支持复杂的多表关联查询,如"查询信用评级最高的供应商提供的产品类别"
1.2 智能客服系统
- 客服人员通过对话式界面快速检索订单状态、产品库存、客户历史记录
- 减少培训成本,降低查询错误率
1.3 数据探索与洞察
- 数据科学家通过自然语言快速探索数据分布和关联关系
- 支持动态生成 SQL 查询,适应不断变化的业务需求
1.4 跨部门数据协作
- 非技术部门(市场、运营、财务)可以自主获取数据洞察
- 减轻 IT 部门的查询请求压力
2. 学习目标
通过本项目的学习,您将掌握:
2.1 核心技术能力
- Amazon Bedrock Agent 架构设计:理解 Agent、Action Group、Knowledge Base 的协作机制
- Text-to-SQL 实现:掌握基于 LLM 的自然语言到 SQL 转换技术
- Few-Shot Learning 应用:学习如何通过示例提升 SQL 生成准确性
- 向量检索技术:理解 Embedding 在表结构选择和示例检索中的应用
- Serverless 架构实践:掌握 Lambda + Athena 的无服务器数据查询方案
2.2 关键代码模块
- 查询引擎构建(
build_query_engine.py):核心 SQL 生成逻辑
- Lambda 处理器(
index.py):Agent 请求的入口和响应处理
- 提示词工程(
prompt_templates.py):Text-to-SQL 的提示词设计
- 连接管理(
connections.py):AWS 服务的统一连接管理
3. 目录结构分析
aws-bedrock/
├── config/ # 配置文件目录
│ └── action_mapping_schema.yaml # Bedrock Agent API Schema 定义
├── iac/ # Infrastructure as Code (Terraform)
│ ├── agent.tf # Bedrock Agent 资源定义
│ ├── lambda.tf # Lambda 函数配置
│ ├── iam.tf # IAM 角色和策略
│ ├── s3.tf # S3 存储桶配置
│ ├── cloudwatch.tf # 日志和监控配置
│ ├── ecr.tf # ECR 镜像仓库配置
│ ├── network.tf # 网络配置
│ ├── variables.tf # Terraform 变量定义
│ └── main.tf # Terraform 主配置
├── query_structured_data_lambda/ # Lambda 函数核心代码
│ ├── index.py # Lambda 入口函数
│ ├── build_query_engine.py # 查询引擎构建逻辑
│ ├── connections.py # AWS 服务连接管理
│ ├── prompt_templates.py # LLM 提示词模板
│ ├── dynamic_examples.csv # Few-Shot 示例数据
│ ├── requirements.txt # Python 依赖包
│ ├── Dockerfile # Lambda 容器镜像构建
│ ├── README.md # Lambda 功能说明文档
│ ├── walk-through.ipynb # 功能演示 Notebook
│ └── data_model.png # 数据模型图示
├── streamlit_app/ # Web UI 应用
│ ├── app.py # Streamlit 主应用
│ ├── services/
│ │ └── bedrock_agent_runtime.py # Bedrock Agent 调用封装
│ ├── requirements.txt # UI 依赖包
│ ├── Dockerfile # UI 容器镜像
│ ├── env_vars.sh # 环境变量配置
│ ├── launch.json # 调试配置
│ └── logo.png # 应用 Logo
├── README.md # 项目说明文档
└── LICENSE # 开源协议目录结构说明
- config/:存放 Bedrock Agent 的 API Schema,定义了 Agent 可调用的 Action
- iac/:完整的 Terraform 基础设施代码,实现一键部署
- query_structured_data_lambda/:核心业务逻辑,实现 Text-to-SQL 转换和查询执行
- streamlit_app/:用户交互界面,提供对话式查询体验
4. 关键文件清单
| 文件路径 | 功能描述 | 重要性 |
|
| Lambda 入口,处理 Bedrock Agent 请求 | ⭐⭐⭐⭐⭐ |
|
| 查询引擎核心,实现 Text-to-SQL | ⭐⭐⭐⭐⭐ |
|
| 提示词模板,控制 SQL 生成质量 | ⭐⭐⭐⭐⭐ |
|
| AWS 服务连接管理 | ⭐⭐⭐⭐ |
|
| Few-Shot 示例数据 | ⭐⭐⭐⭐ |
|
| Bedrock Agent API 定义 | ⭐⭐⭐⭐ |
|
| Bedrock Agent 基础设施定义 | ⭐⭐⭐⭐ |
|
| Lambda 函数配置 | ⭐⭐⭐⭐ |
|
| Web UI 主应用 | ⭐⭐⭐ |
|
| Agent 运行时调用封装 | ⭐⭐⭐ |
5. 技术栈分析
5.1 核心技术组件
AI/ML 层
- Amazon Bedrock:托管的 LLM 服务,使用 Claude 3 Sonnet 模型
- LlamaIndex (v0.10.13):LLM 应用框架,提供查询引擎和向量索引能力
- Titan Embeddings:Amazon 的文本嵌入模型,用于向量检索
数据层
- Amazon Athena:Serverless SQL 查询引擎,支持 S3 数据湖查询
- AWS Glue:数据目录服务,管理表元数据
- SQLAlchemy (v2.0.23):Python SQL 工具包
- PyAthena:Athena 的 Python 驱动
计算层
- AWS Lambda:无服务器计算,运行 Text-to-SQL 逻辑
- Docker:容器化部署,Lambda 使用容器镜像
应用层
- Streamlit:快速构建数据应用的 Python 框架
- Boto3 (v1.34.57):AWS SDK for Python
基础设施层
- Terraform:基础设施即代码(IaC)工具
- Amazon ECR:容器镜像仓库
- Amazon S3:对象存储,存储查询结果和配置文件
- AWS IAM:身份和访问管理
- CloudWatch:日志和监控
5.2 技术栈依赖关系
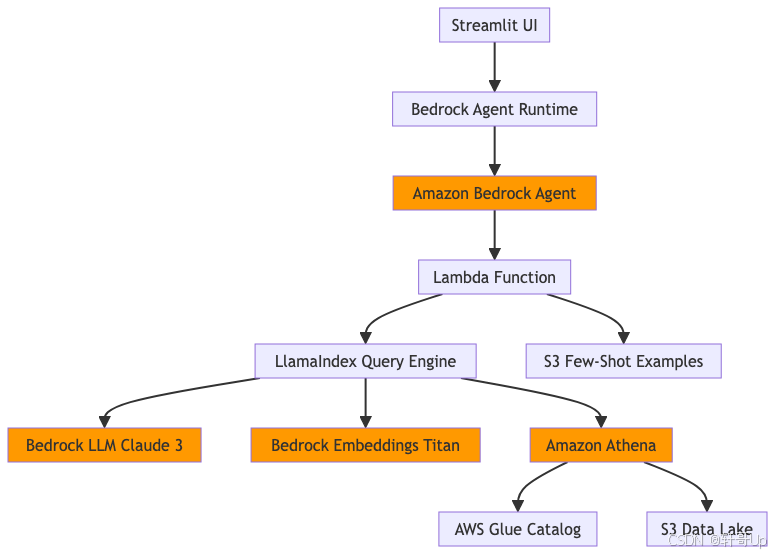
6. 设计模式识别
6.1 架构设计模式
6.1.1 Serverless 架构模式
- 无服务器计算:Lambda 按需执行,无需管理服务器
- 按使用付费:Athena 按扫描数据量计费
- 自动扩展:Lambda 和 Athena 自动处理并发请求
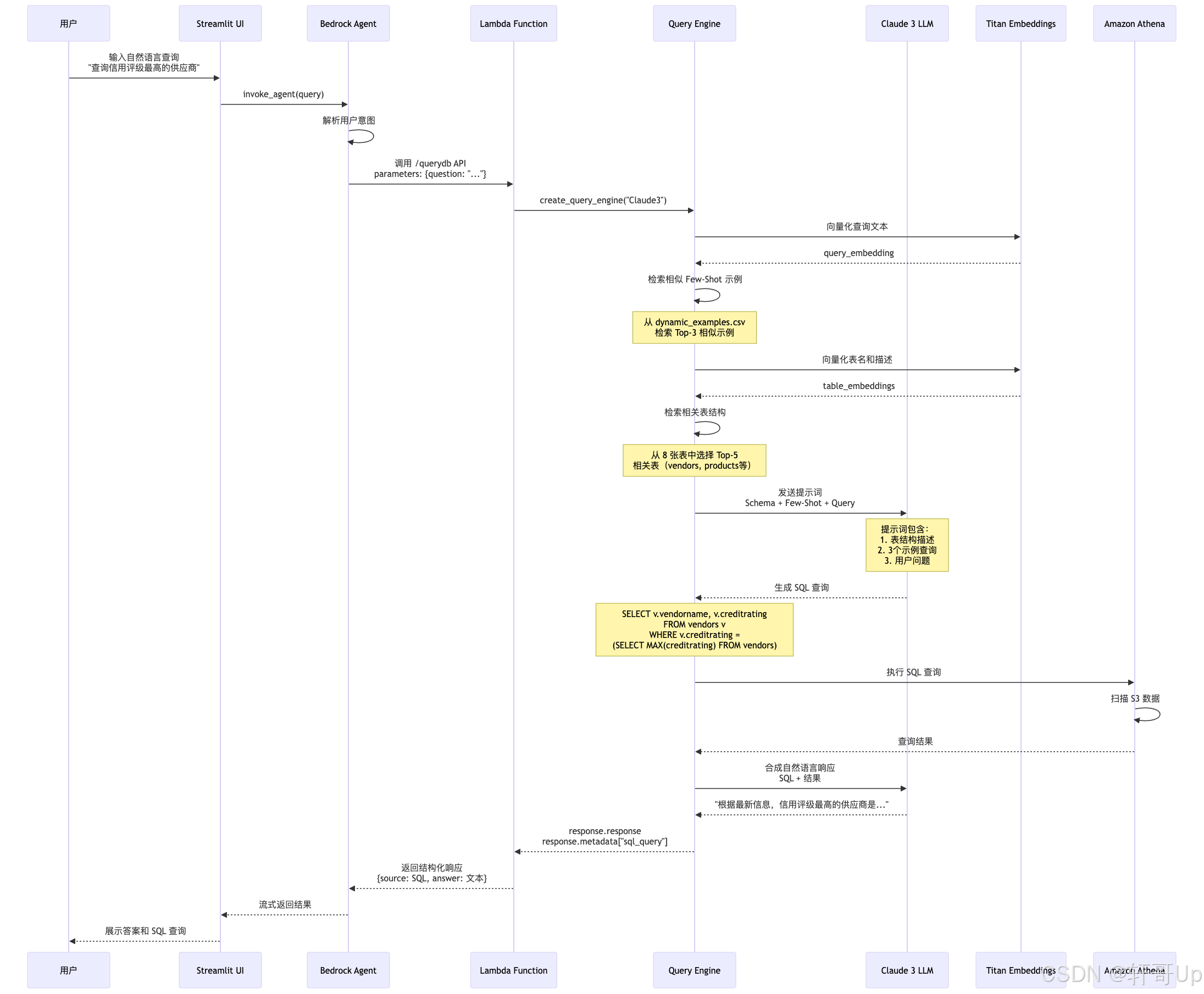
6.1.2 Agent 模式
- 自主决策:Bedrock Agent 根据用户意图选择合适的 Action Group
- 工具调用:Agent 通过 API Schema 调用 Lambda 函数
- 上下文管理:维护会话状态,支持多轮对话
6.1.3 RAG (Retrieval-Augmented Generation) 模式
- 向量检索:通过 Embedding 检索相似的 Few-Shot 示例
- 上下文增强:将检索到的示例注入到 LLM 提示词中
- 动态生成:基于检索结果生成准确的 SQL 查询
6.1.4 策略模式
- 模型抽象:通过
Connections.get_bedrock_llm()支持多种 Claude 模型切换
- 可配置性:通过环境变量控制模型选择和参数
6.2 代码设计模式
6.2.1 单例模式
connections.py 中的 Connections 类作为静态配置管理器:
# query_structured_data_lambda/connections.py
class Connections:region_name = "us-east-1"athena_bucket_name = os.getenv("ATHENA_BUCKET_NAME")text2sql_database = os.getenv("TARGET_DB")s3_resource = boto3.resource("s3", region_name=region_name)bedrock_client = boto3.client("bedrock-runtime", region_name=region_name)6.2.2 工厂模式
build_query_engine.py 中的 create_query_engine() 函数:
# query_structured_data_lambda/build_query_engine.py
def create_query_engine(model_name):# 创建 Embedding 模型embed_model = BedrockEmbedding(...)# 创建 Few-Shot 检索器few_shot_retriever, data_dict = get_few_shot_retriever(embed_model)# 创建 SQL 数据库连接sql_database = SQLDatabase(engine)# 创建 LLM 实例llm = Connections.get_bedrock_llm(model_name=model_name, max_tokens=1024)# 组装查询引擎query_engine = SQLTableRetrieverQueryEngine(...)return query_engine6.2.3 模板方法模式
prompt_templates.py 中定义的提示词模板:
# query_structured_data_lambda/prompt_templates.py
SQL_TEMPLATE_STR = """
Given an input question, first create a syntactically correct {dialect} query to run...
Question: {query_str}
SQLQuery: """6.2.4 适配器模式
bedrock_agent_runtime.py 封装了 Boto3 的 Bedrock Agent 调用:
# streamlit_app/services/bedrock_agent_runtime.py
def invoke_agent(agent_id, agent_alias_id, session_id, prompt):client = boto3.session.Session().client(service_name="bedrock-agent-runtime")response = client.invoke_agent(...)# 适配响应格式return {"output_text": output_text, "citations": citations, "trace": trace}7. 系统架构图