虚拟化入门笔记
序
本文旨在对虚拟化相关的核心概念进行概要性介绍,作为整体性的知识普及。文中仅对主要原理和框架进行概述,具体的实现细节将在后续需要时再行深入探讨。
1、虚拟化技术简介
虚拟化技术是一种资源管理技术,它在下层计算资源与上层软件之间添加了一层抽象层,称为虚拟化层。虚拟化层负责分割、隔离并管理计算资源,并将资源划分为多个抽象的资源实例,提供给上层软件使用。上层软件拥有对抽象资源的完全控制权,然而,其对物理资源的使用会由虚拟化层进行调度和限制。
这又让我想起了刚开始接触到计算机科学时,看见的一句话:计算机科学领域内的任何问题都可以通过增加一个间接的中间层来解决
虚拟化是一项广泛应用的技术,它构成了几乎所有现代云计算和企业基础设施的基石。开发者利用虚拟化技术,可在单台机器上运行多个操作系统,并能在不影响主计算环境安全的前提下测试软件。虚拟化在服务器系统中尤为普及,对虚拟化的支持已成为大多数服务器级处理器的必备特性。这是因为虚拟化为数据中心提供了诸多关键优势,包括:
- 隔离性:虚拟化的核心在于为同一物理系统上运行的多个虚拟机提供隔离。这种隔离特性使得互不信任的计算环境能够共享物理系统资源。例如,两个竞争企业可以共享数据中心的同一台物理服务器,而无法访问彼此的数据。
- 高可用性:虚拟化支持工作负载在物理服务器间实现无缝透明迁移。该技术常用于将工作负载从需要维护更换的故障硬件平台迁移至其他正常节点(虚拟化实例是软件定义的,抽象于具体硬件)。
- 负载均衡:为优化数据中心的硬件与能效预算,必须尽可能充分利用每个硬件平台资源。通过虚拟机迁移技术,或将适配的工作负载整合部署于物理服务器,可实现硬件资源的最大化利用,从而为数据中心服务商提供最优能效方案,同时为租户带来最佳性能体验。
- 沙箱隔离:虚拟机可为可能干扰主机其他组件的应用程序提供沙箱运行环境。典型应用场景包括遗留系统程序或处于开发阶段的软件。将这些应用程序置于虚拟机中运行,可有效防止因程序缺陷或恶意代码影响物理主机上的其他应用程序或数据。
2、虚拟化技术类型
根据虚拟化层所在的层级不同,虚拟化技术可以分出以下两种常见类型:
- 硬件虚拟化(Hardware virtualization)
- 操作系统级虚拟化(OS-level virtualization)
2.1 硬件虚拟化
在硬件虚拟化技术中,物理主机被分割为一台或多台虚拟机(Virtual Machine)。每台虚拟机都可以看作一台独立的“计算机”,拥有自己的虚拟硬件(CPU、内存、硬盘、网络接口等),运行自己的操作系统和应用程序,通过虚拟化技术共享物理主机的硬件资源。
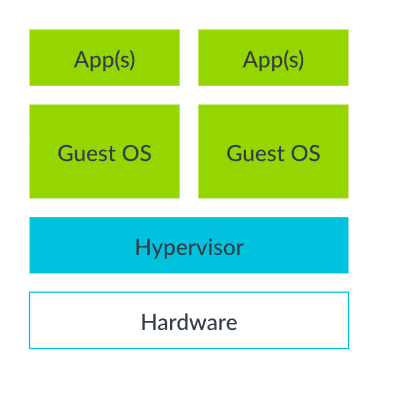
硬件虚拟化使得一台物理主机能够同时运行多个不同的操作系统,此时,被虚拟化的下层资源即为 CPU、内存、I/O 设备等硬件资源。用于创建、管理和执行虚拟机的虚拟化层被称为 Hypervisor,有时也被称为 Virtual Machine Monitor(VMM)。被虚拟化的物理主机称为宿主机(Host),而分割出的虚拟机称为客户机(Guest)。
在 1973 年的论文《Architectural Principles for Virtual Computer Systems》中,Robert P. Goldberg 将 Hypervisor 分成以下两类:
-
Type-1/Native/Bare-metal Hypervisor
- Hypervisor 直接运行在硬件上,可以直接调度硬件资源
- 性能损耗低,但使用的灵活度也较低,适合在服务器环境下使用
- 例:VMware ESXi、Xen、Microsoft Hyper-V、KVM
-
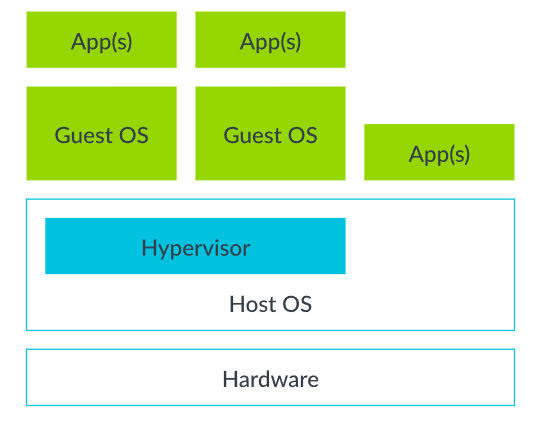
Type-2/Hosted Hypervisor
- Hypervisor 作为宿主机操作系统上的应用程序运行
- 需要通过操作系统实现资源调度,因此性能损耗较高
- 例:VMware Workstation、Oracle VM VirtualBox、QEMU
2.2 操作系统级虚拟化
在操作系统级虚拟化(OS-level virtualization)中,虚拟化的对象是操作系统内核及其调度的系统资源,而不像硬件虚拟化那样直接对硬件资源进行虚拟化。每个虚拟化实例都认为自己独占操作系统内核及其所调度的资源,但实际上,这些虚拟化实例是共享内核资源的,并且仍受到操作系统内核的调度与限制。这一类虚拟化技术一般依赖于操作系统内核提供的隔离与资源限制功能。
目前流行的、生态较好的虚拟化技术被称为容器(Containers),我们常用的 Docker 就属于一种容器实现。
与硬件虚拟化相比,操作系统级虚拟化的开销较小,也不依赖于硬件支持,但受到实现原理的限制,无法运行不同内核的操作系统。
2.3 全虚拟化和半虚拟化
- 全虚拟化(Full Virtualization)
- 虚拟化实现集中在 Hypervisor 上,操作系统可以不经修改地在 Hypervisor 上运行
- 总体来说,兼容性好,但性能可能较为低下。以模拟真实以太网设备为例:由于客户操作系统每次访问模拟寄存器都需由hypervisor 在软件层面进行处理,这种处理开销远高于直接访问物理设备寄存器
- 因为性能低下原因,实际应用并不广泛
- 半虚拟化(Paravirtualization)
- 操作系统与 Hypervisor 通过预先约定好的接口协作运行,通过修改客户操作系统核心组件,使其适配虚拟硬件平台而非物理机器
- 性能上一般强于完全虚拟化,但兼容性上可能略逊一筹
当代包括 Arm 在内的大多数支持硬件虚拟化的体系结构中,客户操作系统通常无需修改即可直接运行。除 I/O 外设(如块存储和网络设备)需采用半虚拟化设备及驱动程序(例如 Virtio 和 Xen PV Bus)外,客户操作系统仍会认为自身运行在真实硬件平台上
3、QEMU 和 KVM
在众多虚拟化技术中,KVM 和 QEMU 是两大基石型解决方案。理解它们对于掌握虚拟化概念至关重要。接下来的深入探讨,旨在通过这两个具体实例,清晰地展现虚拟化的核心思想与实现机制。
3.1 QEMU
最初 QEMU (Quick Emulator) 是一个系统模拟器,它可以在一种 architecture 的系统上模拟另一种 architecture 的另一种系统。不但模拟 CPU,还模拟各种外设。其中 CPU 的模拟主要是通过指令翻译的方式,所以速度比较慢。
它提供硬件虚拟化与处理器仿真功能。QEMU 运行在用户空间,无需内核支持即可通过驱动程序实现高效的系统仿真。该组件支持两种运行模式:
- Full system emulation:完整模拟整个计算机系统,包括特定类型的中央处理器及外围设备,其上可以运行一个完整的 guest OS
- User mode emulation:直接在本地运行针对不同 CPU 架构编译的单个程序进程。直接在 Host 上运行一个 guest 的可执行程序
下载 QEMU 源码,选定目标模拟平台,例如 Aarch64,编译成功后会生成 qemu-aarch64 和 qemu-system-aarch64 文件。
QEMU User mode基本使用方法
QEMU User mode 可在 Host 主机下直接执行程序,执行命令:
qemu-aarch64 /bin/ls -l
运行正常将打印当前目录文件信息。根据需要可以使用其他参数:
- -E OMP_NUM_THREADS=1 设置模拟环境的线程数为1,用于设置多线程程序的线程数量
- -s 8192000000 设置栈大小,以byte为单位,用于需要较大栈空间的应用程序
- -cpu max,sve=on,sve256=on 使能sve256指令功能
- -D qemu_log.txt 设置QEMU运行中打印log文件名
QEMU system mode基本使用方法
QEMU system mode 可以模拟启动 Linux 系统,以及在 Linux 正常执行程序。需要准备 Linux 内核镜像 Image 和文件系 filesystem.cpio.gz。 system mode 执行命令:
qemu-system-aarch64 \-m 8192 \-nographic \-cpu cortex-a57 \-machine virt,gic-version=3 \-smp cpus=4,cores=4,threads=1 \-kernel Image \-initrd filesystem.cpio.gz \-fsdev local,security_model=passthrough,id=fsdev0,path=${FILESYS_PATH} \-device virtio-9p-pci,id=fs0,fsdev=fsdev0,mount_tag=hostshare-append "console=ttyAMA0 sched_debug loglevel=8 ftrace_dump_on_oops earlyprintk=serial oops=panic nmi_watchdog=panic panic_on_warn=1 nokaslr"-D ./qemu_log_`date +%Y%m%d%H%M`.txt \
其中参数列表:
- -m 设置内存大小
- -nographic 设置为无图像模式
- -cpu 设置CPU型号
- -machine virt 设置机器型号为QEMU ARM Virtual Machine
- -smp 设置CPU核数和线程数
- -kernel 设置linux内核镜像
- -initrd 设置文件系统
- -fsdev和-device 使用9p virtio支持virtfs共享上当,其中${FILESYS_PATH}为Host主机中共享目录的路径
- -append 设置linux内核启动命令
- -D qemu_log.txt 设置QEMU运行中打印log文件名
Full system emulation 模式下,举一个 QEMU 模拟网卡外设的例子:
Intel E1000 网卡模拟器实现源码,qemu-xxx/hw/net/e1000.c 文件
它实现的是 e1000 的寄存器布局、DMA 逻辑、中断触发方式、描述符队列等行为

3.2 KVM
KVM 本身的设计目标非常明确:利用 Linux 内核已有的功能,高效、安全地虚拟化 CPU 和内存。它并不是一个完整的虚拟机管理器(Hypervisors)。
KVM 本质上是:
- 一个 Linux 内核模块(kvm.ko)
- 再加上架构相关模块(如 kvm-intel.ko、kvm-amd.ko、kvm-arm.ko)。这一点至关重要——KVM 通过利用底层 CPU 的硬件虚拟化扩展(如 Intel VT-x、AMD-V、ARM VE 等),让虚拟机的执行指令直接在物理 CPU 上运行,而不是像 QEMU 那样完全依靠软件模拟,从而极大提升了性能。
Hypervisor 与底层架构密切相关。它必须依赖 CPU 的虚拟化扩展来实现虚拟机的陷入、上下文切换与隔离。如果没有硬件支持,虚拟化只能通过软件仿真实现,不仅复杂度高,而且性能会大幅下降。
功能是:
- 让 Linux 内核自己变成一个 Type 1 Hypervisor。通过直接集成到内核代码中,KVM 使 Linux 能够直接承担 Hypervisor 相关的职责。KVM 本身就是 Linux 内核的一部分。这种深度的集成造就了二者之间一种共生关系:KVM 是 Linux 的一部分,而 Linux 也构成了 KVM 的基石。
- 提供 /dev/kvm 设备接口,供用户态程序调用;
- 通过 ioctl 等接口,用户态程序可以:
- 创建虚拟 CPU
- 分配虚拟内存
- 切换 Guest/Host 执行上下文
- 控制陷入(VM exit)
KVM 并不负责:
- 模拟硬件设备(网卡、磁盘、显卡等);
- 加载或管理虚拟机镜像;
- 提供 BIOS、引导、快照、VNC、命令行工具等。
因此,KVM 通常需要与上层用户态虚拟机管理程序配合使用,其中最常见的就是 QEMU。在这种组合中,QEMU 负责模拟外围设备和虚拟机管理逻辑,而 KVM 负责利用硬件虚拟化特性(如 Intel VT-x、AMD-V 等)实现 CPU 与内存的高效虚拟化执行。
通过将 QEMU 原本的纯软件 CPU/内存仿真交由 KVM 内核模块处理,虚拟机的执行效率可以获得显著提升。换言之,KVM + QEMU 才构成一个完整且高性能的虚拟化解决方案。
注意,QEMU + KVM 解决方案中,QEMU 已经不再是 3.1 节的原生 QEMU,而是经过修改后的 QEMU(qemu-kvm),配合 KVM 接口使用。
sudo apt install qemu-kvm
4、内存虚拟化
对于操作系统内核来说,内存资源的高效调度建立在对物理内存地址空间的两个假设上:从零开始、内存地址连续;而对于需要同时运行多个操作系统的 Hypervisor 来说,需要高效地调度内存资源,尽可能满足每个操作系统对内存的需求。
目前,主流操作系统使用页(Page)为单位来管理内存。在非虚拟化的环境下,操作系统使用页表将虚拟内存地址转换到物理内存地址,用于辅助完成这一转换的硬件被称为内存管理单元(Memory Management Unit,MMU)。主流 操作系统的虚拟内存管理功能都相当程度地依赖于 MMU,因此,在虚拟化环境下,Hypervisor 需要实现 MMU 虚拟化支持。
以 ARM 架构为例。使能虚拟化功能时,虚拟地址要经过两个阶段的转换。一个阶段由操作系统控制,另一个阶段由 Hypervisor 控制。
| 转换阶段 | 负责层级 | 页表由谁维护 | 转换含义 |
|---|---|---|---|
| Stage-1 | Guest OS (EL1) | Guest 自己 | Guest VA → Guest PA (GVA→GPA) |
| Stage-2 | Hypervisor (EL2) | Hypervisor | Guest PA → Host PA (GPA→HPA) |
Stage-1 → Stage-2 的链接转换是由硬件 MMU 自动完成的。
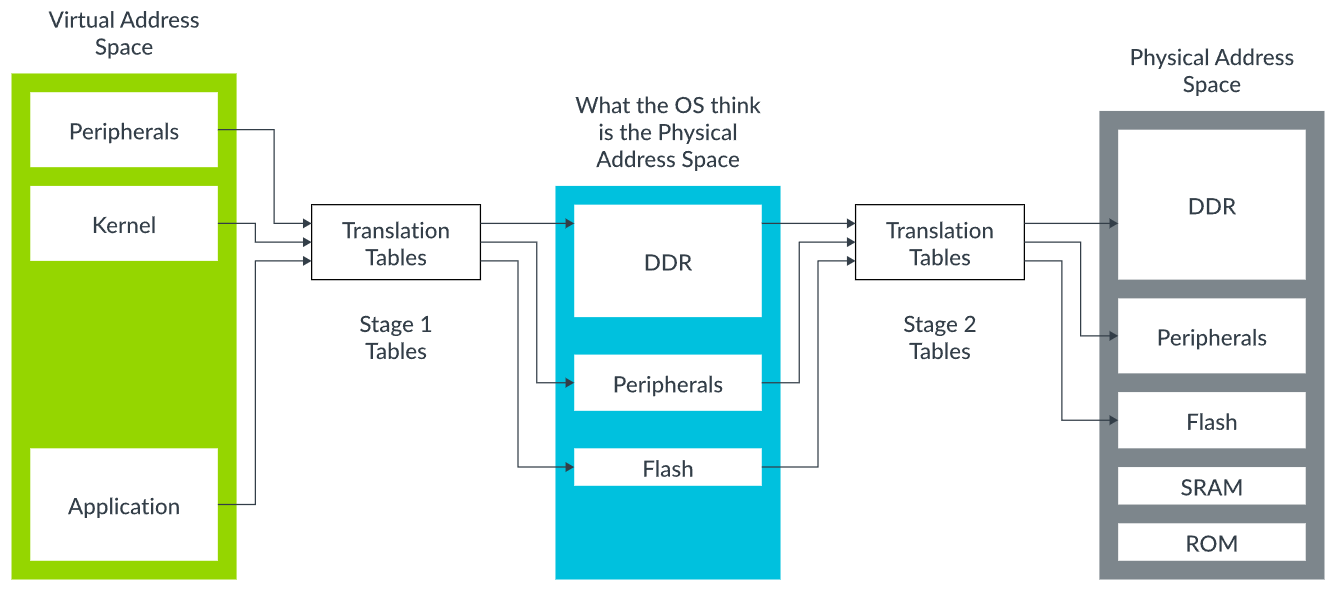
CPU 每当在 EL1(Guest 模式)执行内存访问时:
- 先查 Stage-1 页表(由 EL1 控制);
- 产生 GPA;
- 然后自动查 Stage-2 页表(由 EL2 控制);
- 产生最终的 HPA;
- 把访问请求送往物理内存。
整个流程是硬件管的,不需要任何软件陷入。
Guest OS 使用的 Stage-1 页表如下:
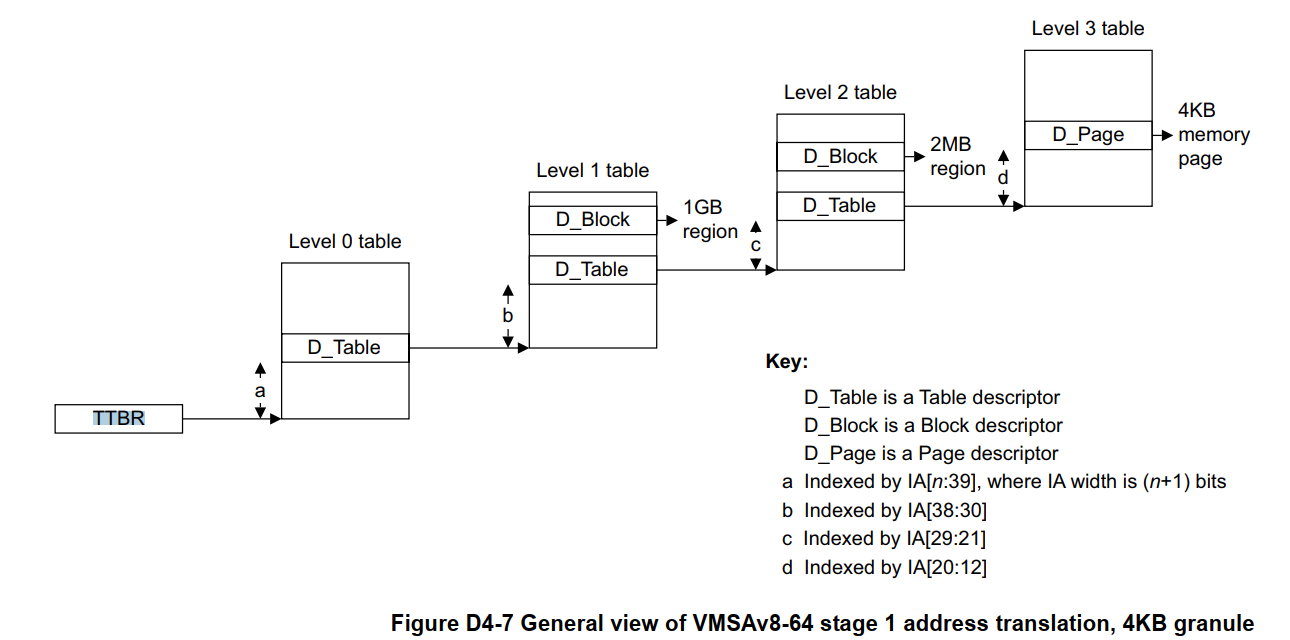
Hypervisor 使用的 Stage-2 页表如下:
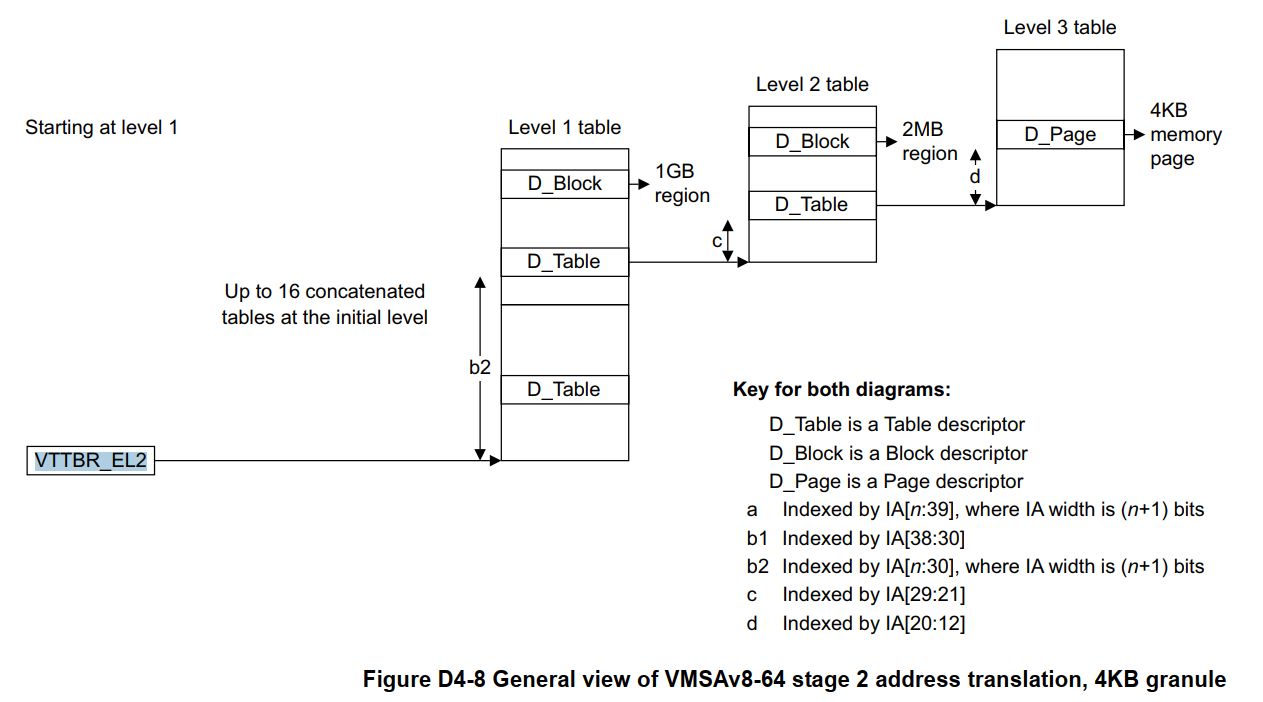
Stage2 转换允许 Hypervisor 控制虚拟机 VM 中内存视图。它允许 Hypervisor 控制一个虚拟机可以访问哪块内存映射的系统资源,以及这些资源应该出现在虚拟机地址空间的哪个位置。
这种控制内存访问的能力对于隔离是非常重要的。Stage2 转换用于保证一个虚拟机仅能够看到分配给它的资源,分配给其他虚拟机或 Hypervisor 的资源它是无法看到。
5、IO 虚拟化
在非虚拟化的环境下,操作系统内核通过驱动与 I/O 设备进行交互。从 CPU 的角度看,与设备的交互方式一般分为以下三种:
- 中断:当设备发生特定 I/O 事件时,通过中断信号通知 CPU,促使操作系统及时响应处理
- 寄存器访问:CPU 通过读写设备寄存器来控制设备状态或获取设备数据
- DMA:设备直接与内存进行数据交换,无需 CPU 介入控制
而在虚拟化架构中,Guest OS 与物理 I/O 设备之间多出了一个虚拟化层(Hypevisor),它们之间的交互必须由虚拟化层妥善处理。为此,I/O 虚拟化需要:
- 向 Guest OS 提供设备接口
- 截获并处理 Guest OS 向设备发起的访问操作
以下将讨论几类主流的 I/O 虚拟化的实现方式。
5.1 设备仿真
对于一些实现简单,且性能要求不高的 I/O 设备(如键盘、鼠标、简单网卡等),可以采用纯软件方式来完全模拟已有物理硬件的行为(例如 qemu-xxx/hw/net/e1000.c ,E1000 网卡模拟器)。
此时,Guest OS 可以直接使用现有的、为物理硬件实现的驱动来操作设备(Guest OS 认为自己运行在物理设备上),但对于 I/O 吞吐量较大的设备来说,纯软件实现可能带来无法忽略的性能开销。
5.2 半虚拟化
在这种架构中,Guest OS 通过在 I/O 子系统上加以修改,能够感知到自己运行在虚拟化环境中,并与 Hypervisor 协同工作。
以 Xen 使用的「分离驱动」架构为例。在这种架构中,驱动被分为两个部分:运行在 Guest OS 上的前端驱动(front-end driver)和运行在 Hypervisor 上的后端驱动(back-end driver)。前端驱动向 Guest OS 提供几类标准的设备接口,而后端驱动则负责操作实际物理硬件,前后端驱动之间通过共享内存,使用一个被称为 I/O ring 的数据结构来实现异步数据交换。
这种实现避免了设备仿真中硬件模拟开销较大等问题,Guest OS 通过采用经过性能优化的通信接口与 Hypervisor 协同工作,在 I/O 性能上优于完全的软件仿真。
5.2.1 Virtio
Virtio 是一套 I/O 半虚拟化开放标准,其同样采用分离驱动的架构,旨在规范各类 I/O 设备(如网络、存储设备等)的数据传输和事件处理方式,提升虚拟化环境的效率和兼容性。
在全虚拟化的解决方案中,Guest OS 要使用底层 Host 资源,需要 Hypervisor 来截获所有的请求指令,然后模拟出这些指令的行为,这样势必会带来很多性能上的开销。半虚拟化通过底层硬件辅助的方式,将部分没必要虚拟化的指令通过硬件来完成,Hypervisor 只负责完成部分指令的虚拟化,要做到这点,需要 Guest 来配合,Guest 完成不同设备的前端驱动程序(Front-end drivers),Hypervisor 配合 Guest 完成相应的后端驱动程序(Back-end drivers),这样两者之间通过某种交互机制就可以实现高效的虚拟化过程。
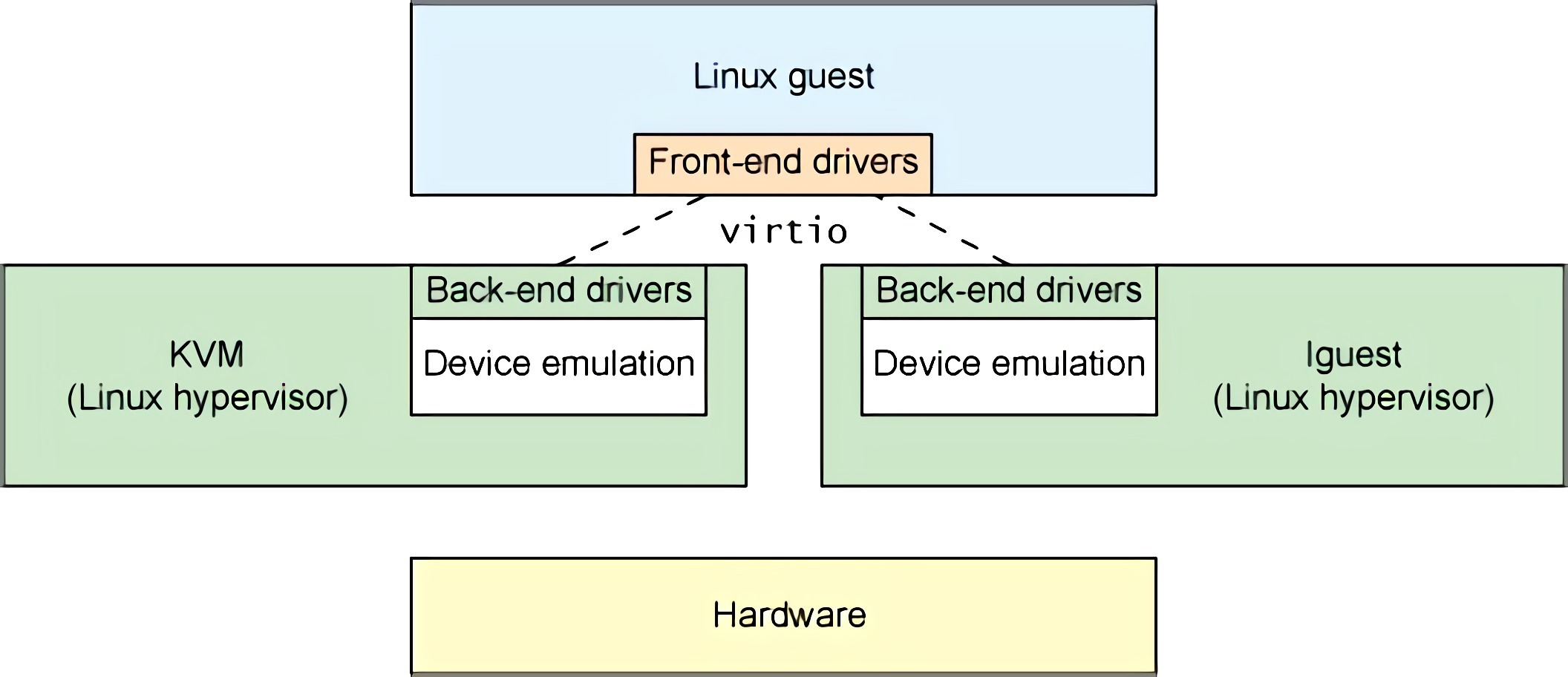
注意,上图中的 Device emulation,“设备模拟” 指对 guest 暴露的 virtio 寄存器、配置空间、设备状态等进行响应,让 Guest 的 virtio 驱动能工作。不是模拟真实厂商网卡寄存器、DMA 描述符、PHY 等!不要理解错了!
由于不同 Guest OS 前端设备其工作逻辑大同小异(如块设备、网络设备、PCI设备、balloon 驱动等),单独为每个设备定义一套接口实属没有必要,而且还要考虑扩平台的兼容性问题,另外,不同后端 Hypervisor 的实现方式也大同小异(如 KVM、Xen 等),这个时候,就需要一套通用框架和标准接口(协议)来完成两者之间的交互过程,Virtio 就是这样一套标准,它极大地解决了这些不通用的问题。
Virtio 的基本架构如下图所示:
当虚拟机使用 virtio 网卡时,Guest OS 直接使用 virtio 前端驱动(virtio-net.c) 来完成网络通信。在这种情况下,Guest 内部没有所谓 e1000 网卡型号的概念的!!!

后端驱动程序(Back-end drivers) 负责把这些 Virtio 请求转发给实际实现(软件、内核、或物理硬件)。
- 对于 Type-1 hypervisor(如 Xen、ESXi、KVM 内核级),
Guest OSvirtio 前端驱动↓virtqueue (共享内存)↓
Hypervisor(Type 1)virtio 后端(vhost/vDPA/virtio backend)↓Hypervisor 自己实现的物理驱动↓NIC / Disk / etc.- 对于 Type-2 hypervisor(如 QEMU/KVM、VirtualBox),
Guest OSvirtio 前端驱动↓virtqueue (共享内存)↓
Host OS (用户态 QEMU)virtio 后端(QEMU 或 vhost)↓Host OS 内核↓Host OS 的物理驱动↓NIC / Disk / etc.与传统的 Linux IO 虚拟化实现方式相比,virtio 具有多方面的显著优势。首先,它提供了通用接口,大大提高了代码的可重用性和跨平台性。以往针对不同的虚拟化平台和设备,需要开发不同的驱动程序,而有了 virtio,基于其通用接口,开发者可以更轻松地编写适用于多种虚拟化环境的驱动,减少了开发成本和工作量。
其次,在性能提升方面,virtio 表现出色。传统方式(全虚拟化)中频繁的 VMEntry、VMExit 以及多次上下文切换和数据复制导致性能低下,而 virtio 采用半虚拟化技术,通过底层硬件辅助,将部分没必要虚拟化的指令通过硬件完成,Hypervisor 只负责完成部分指令的虚拟化。同时,它通过虚拟队列(virtqueue)和环形缓冲区(virtio-ring)来实现前端驱动和后端处理程序之间高效的数据传输,减少了 VMEXIT 次数,使得数据传输更加高效,极大地提升了 I/O 性能,其性能几乎可以达到和非虚拟化环境中的原生系统差不多的 I/O 性能。
5.3 设备直通(Device passthrough)
在设备直通(也称为设备透传)技术中,Hypervisor 将物理 I/O 设备直接分配给特定的虚拟机,使得该虚拟机能够直接与硬件进行交互,而无需经过中间的软件仿真或分离驱动层。这种方式可能依赖于硬件支持(例如 Intel VT-d 或 AMD IOMMU)来实现 DMA 重映射和中断重映射等功能。
设备直通的性能是最好的,几乎能够获得原生的 I/O 性能,但独占设备使得其灵活性稍差,在配置上可能会略微复杂,并且可能会存在兼容性问题。
5.3.1 IOMMU
IOMMU(输入/输出内存管理单元)是一种硬件虚拟化技术,其功能类似于 CPU 中的 MMU,是一个向设备侧提供地址翻译功能的单元。不同的平台有不同的 IOMMU,例如 ARM 架构下,IOMMU 被称之为 SMMU。
地址转换机制
IOMMU 的核心任务之一就是地址转换,它把设备的 I/O 虚拟地址(IOVA,即设备发出的地址)映射为物理地址 。这一过程与 MMU 的页表机制颇为相似,但又有所不同。在 MMU 中,通过维护进程的页表,将 CPU 使用的虚拟地址转换为物理地址,实现进程之间的内存隔离与管理。而 IOMMU 则是为 I/O 设备提供类似的服务,每个设备或设备组都有自己对应的 I/O 页表。
以 x86 平台为例,当一个 32 位的 PCI 设备需要进行 DMA 操作时,如果它要访问的内存超出了其自身 4GB 的寻址能力(假设系统内存大于 4GB),IOMMU 便开始发挥作用。设备发出的 IOVA 会被 IOMMU 捕获,IOMMU 根据内部的 I/O 页表,将这个 IOVA 翻译为正确的物理地址。比如,系统为设备分配了一段位于 4GB 以上的物理内存,设备本身无法直接访问,但在 IOMMU 的帮助下,设备可以使用一个在其可寻址范围内的 IOVA,IOMMU 将这个 IOVA 准确映射到高端物理内存地址,从而实现设备对大内存的访问 。
内存保护原理
在计算机系统中,内存保护至关重要,IOMMU 在其中扮演着重要角色。恶意的设备驱动程序或者硬件故障,都可能导致设备对内存的非法访问,进而引发系统崩溃、数据泄露等严重问题。比如,恶意的设备驱动程序可能试图读取或写入它不应访问的内存区域,硬件故障可能导致设备发出错误的地址信号,访问到非预期的内存位置。
IOMMU 通过地址映射和权限管理来防止这些问题的发生。在地址映射方面,IOMMU 严格按照设定的 I/O 页表进行地址转换,只有被映射的地址才能被设备访问,这就避免了设备随意访问未授权的内存区域。权限管理上,IOMMU 为每个设备或设备组设置了不同的访问权限,如只读、只写、读写等。例如,一个存储设备可能被设置为只对特定的内存区域有读写权限,而对其他区域则没有任何访问权限,这样即使设备出现故障或者受到恶意攻击,也能最大限度地保障系统内存的安全 。
DMA 重映射原理
DMA 重映射是 IOMMU 的一项关键功能。传统的 DMA 操作要求内存是连续的,这在实际应用中限制很大,因为系统很难为设备分配大量连续的物理内存。有了 IOMMU,情况就大为不同。
IOMMU 可以将非连续的物理内存映射为设备看起来连续的内存区域。假设一个网络设备需要发送大量数据,这些数据存储在多个不连续的物理内存块中。在没有 IOMMU 时,设备驱动需要复杂的操作来处理这些分散的数据块。而有了 IOMMU 后,它可以将这些分散的物理内存块映射为一个连续的 IOVA 空间,设备只需按照这个连续的地址空间进行 DMA 操作,无需关心背后物理内存的实际布局。这不仅极大地方便了设备的操作,还提高了系统内存的利用率和整体性能,使得系统在处理大规模数据传输时更加高效 。
中断重映射原理(可选功能)
中断重映射是 IOMMU 的一个可选功能,在虚拟化场景中尤为重要。在传统的非虚拟化环境下,设备产生的中断信号直接发送到 CPU 的中断控制器,然后由 CPU 进行相应的处理。但在虚拟化环境中,情况变得复杂起来。
当多个虚拟机共享物理设备时,设备的中断信号需要准确地传递到对应的虚拟机中,这就需要 IOMMU 的中断重映射功能。设备产生的中断信号首先会被 IOMMU 捕获,IOMMU 根据预先配置的中断重映射表,将这个中断信号重定向到对应的虚拟机的虚拟中断控制器上。例如,在一个服务器虚拟化环境中,多个虚拟机同时运行不同的应用程序,每个虚拟机都有自己的网卡设备。当某个虚拟机的网卡接收到数据时,网卡产生的中断信号通过 IOMMU 重映射,准确地传递到该虚拟机的虚拟中断控制器,从而确保虚拟机能够及时响应网络数据的到来,保证了虚拟机中应用程序的正常运行 。
为什么说是可选功能?ARM 架构中的 SMMU 不支持中断重映射,中断重映射是由 GIC 中断控制器完成。而 Intel 中的 IOMMU 是支持中断重映射的。不同架构的 IOMMU 实现不同。
6、libvirt
libvirt 官网
libvirt 是广泛使用的、通用虚拟化管理工具,它提供多种命令行工具、多种语言的编程 API。可以用于管理各种虚拟化技术,例如 KVM、QEMU、Xen 和 LXC 等。
libvirt 的目标是:提供一个通用、稳定的抽象层,来安全有效的远程管理一个节点(node)之上的虚拟机。libvirt 库使得管理虚拟化环境变得更加容易,它可以用于创建、配置、启动、停止、暂停和恢复虚拟机,以及管理虚拟机的存储和网络等方面。
libvirt 主要由三个部分组成:API 库,一个守护进程 libvirtd 和一个默认命令行管理工具 virsh。
- API 库:提供统一 API(如:create VM、attach disk、define network),给上客户端调用。存在的形式为动态库 libvirt.so。
- libvirtd(可以理解为服务端):
- 提供 RPC 接口(通过 UNIX socket / TCP)供客户端调用;
- 接收 libvirt API 请求;
- 根据虚拟机类型,调用相应的 “driver 模块” 来执行实际操作。
- virsh:默认命令行管理工具,通过命令行,交互式的管理你的虚拟机
libvirt 的结构:核心 + 多驱动
+------------------------------+
| libvirt 客户端工具 |
| (virsh, virt-manager, etc) |
+--------------↑---------------+
| libvirt daemon (libvirtd) |
| - 驱动层 (drivers/) |
| - RPC 接口 (libvirt.so) |
+--------------↑---------------+
| 底层 Hypervisor 接口 |
| (QEMU/KVM, Xen, LXC, ESXi…)|
+------------------------------+
libvirtd 守护进程根据虚拟机类型,调用对应驱动(driver)模块。每种 hypervisor 都对应一个 libvirt driver,例如:
| Hypervisor | Libvirt 驱动模块 |
|---|---|
| QEMU / KVM | qemu_driver.c |
| LXC | lxc_driver.c |
| VMware ESXi | esx_driver.c |
| Hyper-V | hyperv_driver.c |
在用户工具层,诸如 virt-manager、OpenNebula 等虚拟化管理工具通常通过 libvirt API 对虚拟机进行本地或远程管理;
而诸如 OpenStack 这样的云平台,其计算节点(Nova compute)通常也以 libvirt 作为底层驱动之一 来管理虚拟机的生命周期。