SQLAlchemy2.0使用
最近一直在用python写一些脚本给业务同事处理数据用,用起来非常方便,所以最近在深入的学习python这门语言,基础语法已经学的差不多了,可以在内存里简单处理数据,感觉是时候学一门Python操作数据库的框架了,早晚用的着。
搜了一下Python的orm框架,SqlAlchemy是其中的佼佼者,就挑了这个最出名的框架研究。我本来打算在网上找点资料看,或者买点书,想着能先学会基本使用,不要涉及太多细节。但看了看市面上的大部分书是1.x版本,SqlAlchemy最新版已经到了2.x版本,网上有关的一些2.x的资料基本都是点状的,比较碎。那就没办法了,只能啃官方文档了,大而全,但是纯英文的,学起来要费劲一点,但好处是:官方文档是一手的最新资料。
文章目录
- 1、安装方法
- 2、SqlAlchemy的架构图
- 2.1、DBAPI
- 2.2、SQLAlchemy Core
- 2.2.1、Schema /Types
- 2.2.2、SQL Expression language
- 2.2.3、Connection Pooling
- 2.2.4、Dialect
- 2.3、SQLAlchemy ORM
- 2.3.1、声明式映射
- 2.3.2、命令式映射
- 3、数据库操作的2个核心对象
- 3.1、connection
- 3.2、session
- 4、关于Session
- 4.1、使用sessionmaker初始化session
- 4.2、Session的CRUD操作
- 4.2.1、查询
- 4.2.2、新增
- 4.2.3、删除
- 4.2.4、更新
- 4.3、session的事务管理
- 4.4、其他Session类型
- 4.4.1、scoped_session
- 4.4.1.1、通过请求绑定的方式实现
- 4.4.1.2、通过注入的方式实现
- 4.4.2、AsyncSession
- 4.5、多线程中使用Session
- 4.6、session的其他操作
- 5、core方式CRUD
- 5.1、单个新增
- 5.2、批量新增
- 5.3、删除
- 5.4、批量删除
- 5.5、更新
- 5.6、批量更新
- 5.7、查询
- 5.7.1、使用Sql Express Language构建查询Sql
- 5.7.2、使用text关键字构建查询SQl
- 6、orm方式CRUD
- 6.1、单个新增
- 6.2、批量新增
- 6.3、单个删除
- 6.4、批量删除
- 6.5、更新
- 6.6、批量更新
- 6.7、查询
- 7、ORM方式和Core方式总结
- 7.1、定位不同
- 7.2、 操作方式不同
- 7.3、API对比
- 8、SqlAlchemy的坑点
- 8.1、忘记释放连接
- 8.2、在线程里频繁的获取、关闭session或连接
- 8.3、接口压测
1、安装方法
# 除此之外,还有源码安装方式,具体安装方法参考官方文档
pip install SQLAlchemy
2、SqlAlchemy的架构图
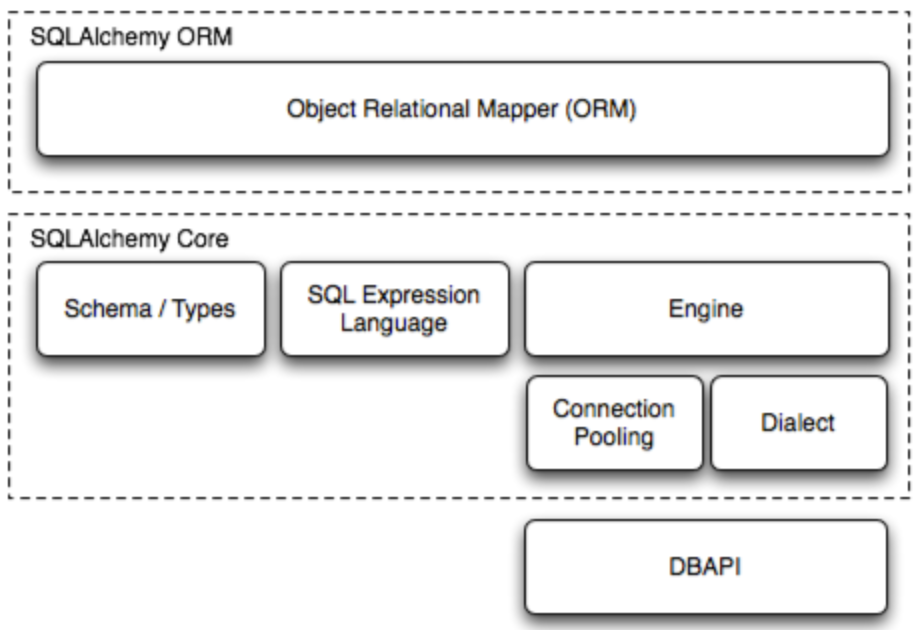
图中有三个主要的组件,从下往上,依次是:DBAPI、SQLAlchemy Core、SQLAlchemy ORM。这些组件间的依赖关系就是从下往上的,最底层的依赖是DBAPI,然后是Core,最后是ORM
2.1、DBAPI
简单理解就是java中的JDBC,Python官方定义了一套操作数据库的接口,ORM厂商可以依赖这一套接口来进行顶层的实现。SqlAlchemy是一个ORM厂商,所以它需要按照python DBAPI的相关接口定义来设计架构进而操作数据库。如果想要了解有哪些API,可以参考官方文档。
2.2、SQLAlchemy Core
Core方式是SqlAlchemy框架连接数据库的一种方式,类似于mybatis-plus的函数式编程。
def update_user_core(req: UpdateUser):with engine.connect() as connection:connection.execute(update(user_table).where(user_table.c.phone == req.phone).values(email=req.email))connection.commit()
可以看到和写SQL差不多,有update关键字、where关键字、value关键字,
更多用法,下面章节会讲到,暂且按下不表。
2.2.1、Schema /Types
Schema,元数据类型定义,比如:数据库表和业务对象之间的对应,数据库列名和业务字段名的对应等等这一类的。官方文档
from sqlalchemy import MetaData
from sqlalchemy import Table, Column, Integer, Stringmetadata_obj = MetaData()
user = Table("user",metadata_obj,Column("user_id", Integer, primary_key=True),Column("user_name", String(16), nullable=False),Column("email_address", String(60)),Column("nickname", String(50), nullable=False),
)
Types,就是数据库的字段类型和对象中的字段类型的对应。
比如:上述schema中的Integer,String这两个类型,对应数据库就是int和Varchar,还有很多类型的对应,具体可以查看官方文档
2.2.2、SQL Expression language
就是core层封装的一层SQL语句的抽象,比如我们上面提到的更新语句
# 根据条件更新
def update_user_core(req: UpdateUser):with engine.connection() as connection:connection.execute(update(user_table).where(user_table.c.phone == req.phone).values(email=req.email))connection.commit()
SqlAlchemy底层会把这个sql抽象转换成真正的SQL语句,
UPDATE user_table SET email = xxx WHERE phone = 'xxxx'
2.2.3、Engine
Engine是应用程序操作数据库的入口点。看一下官网给的这张图,应用程序操作数据库的流程,是从左向右,开头就是Engine
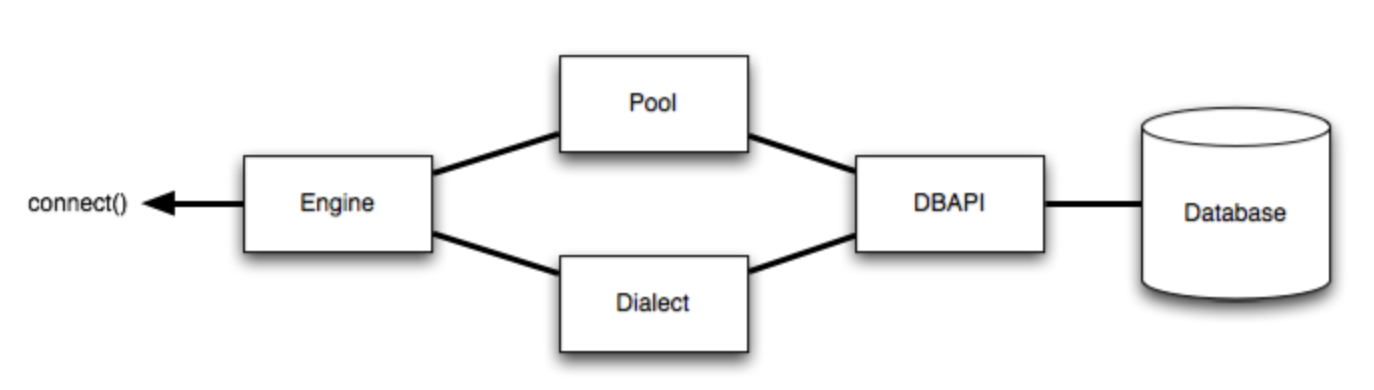
Engine的初始化方式
engine = create_engine("mysql+pymysql://root:111111@127.0.0.1:3309/sqlalchemy")
create_engine的第一个参数是url,这个url的含义如下:
dialect+driver://username:password@host:port/database
第一个代表数据库方言,我给的示例url,dialect是mysql,所以证明这个Engine是用来操作mysql数据库的,之后是驱动,我这里用的是pymysql库,还有其他的比如mysqlclient。然后就是我们熟悉的用户名、密码、ip、端口、数据库名称
这里需要注意,将用户名、密码写到链接里的这种方式,如果用户名或者密码包含特殊字符,注意对特殊字符编码,比如:密码包含@符号,kx@jj5/g,此时需要对@符号编码
import urllib.parse
urllib.parse.quote_plus("kx@jj5/g")
#输出: kx%40jj5%2Fg
# @符号被编码成了%40
如果你不想搞这个额外的编码,也可以选择用URL实例的初始化连接方式
from sqlalchemy import URL,create_engineurl_object = URL.create("postgresql+pg8000",username="dbuser",password="kx@jj5/g",# 不需要对密码的特殊字符额外编码host="pghost10",database="appdb",
)
# 官方的建议是:在一个应用系统中,一个数据库只建立一个engine即可
engine = create_engine(url_object)
create_engine方法的其他可选参数
1、pool_recycle: 数据库基本都有空闲超时时间,即:已建立的连接多长时间没有数据交互就会自动断开,比如mysql默认是8小时。这个参数的作用就是为了避免这个问题,空闲时间超过设定时间,即主动丢弃,并重新打开一条新连接。单位:秒。设置成-1,代表永不超时
2、echo: 输出sql。默认值False,将该值设置为True,可以查看SqlAlchemy生成的sql是什么样的,测试阶段可以打开,以观察SqlAlchemy生成SQL的行为
3、pool_size: 连接池固定的连接数量.QueuePool和SingletonThreadPool类型的连接池会使用该参数。设置成0,代表没有限制。如果要禁用该参数,将pool_class的值设置成NullPool即可。默认值5个
4、max_overflow: 连接池连接可以溢出的数量。通过设置一个合适的数量,来防止突发流量。这个参数只对QueuePool类型的连接池有效。默认值是5个。如果设置了该参数,则连接池的最大连接数 = pool_size + max_overflow。这里注意:max_overflow的连接用完即销毁,不会长时间保留
5、、pool_timeout: 获取连接的超时时间,单位:秒。可以设置小数,比如:0.05秒,即50毫秒,但这么小的时间一般不太可靠。只有QueuePool使用该参数
6、、pool_pre_ping: 获取连接前,验证连接是否可用。本质就是发送一个SELECT 1的简单语句
7、poolclass: 使用的连接池形式。还有很多其他选择,可以看看官方文档。链接:https://docs.sqlalchemy.org/en/20/core/pooling.html#sqlalchemy.pool.QueuePool
8、pool_use_lifo: 是否使用LIFO的拿连接顺序,默认情况下,该值为False,代表连接池拿连接的顺序是FIFO,轮着用每个连接,让每条连接都热。如果设置成True,代表后进先出,使用刚刚还回来的连接,刚刚还回来的连接基本都是可用的连接,每次只用这几条最热的连接,结合pool_recycle参数的使用,让冷连接慢慢被回收
有很多关于Engine的信息,我没有提到,感兴趣的可以读下官方文档
另外说一句,官方文档上建议我们将engine的配置写到模块的__init__.py文件中,然后在当前模块全局调用,如下图:
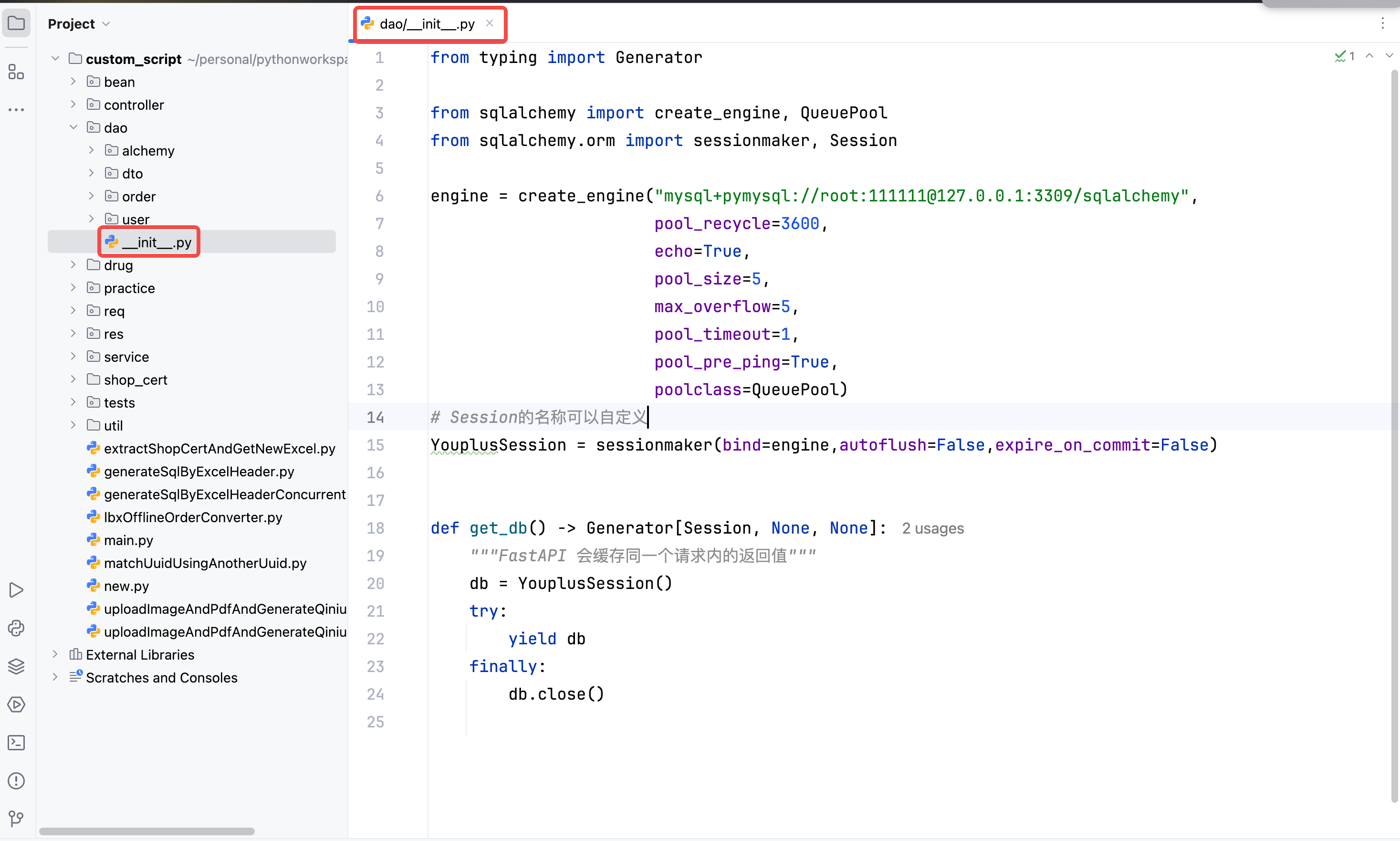
2.2.3、Connection Pooling
SqlAlchemy内部维护了一个连接池,避免重复开、关连接导致的开销。介绍Engine的时候,提到了一些连接池的配置。engine的大部分参数都是配置连接池用的。需要注意的是,初始化状态下,连接池中是没有连接的,只有应用程序申请使用一个连接时,连接池中才开始创建连接,所以它是懒加载式的
2.2.4、Dialect
数据库方言,我们可以通过在创建engine时指定一个数据库类型,后面的操作就可以根据你指定的方言来,目前SqlAlchemy支持绝大部分的开源数据库。
像mysql、mariaDB、oracle、PG、sqllite等等,其它的方言还有很多
2.3、SQLAlchemy ORM
ORM是连接数据库的另一种方式,下面也会讲到。从架构图上可以看到ORM是建立在Core方式之上的。ORM方式是官方比较建议的一种方式,ORM屏蔽掉了SQL底层的实现细节,让用户专注于业务
with YouplusSession() as session:user = session.scalars(select(User).where(User.phone == req.phone)).first()user.email = req.emailsession.commit()
比如上面这个例子,我们先查询用户,然后通过user.email的方式修改用户的邮箱,然后提交,user.email = req.email的操作,SQLAlchemy会生成UPDATE语句,不用我们手写。
这个操作是依赖User对象这个关系映射的,也就是图中提到的这个Object Relational Mapper(ORM),这其实类似于使用mybatis时的mapper文件定义,需要定义持久层框架的字段和数据表字段的对应关系。
SqlAlchemy提供了2种关系映射的方式。一种声明式,一种命令式(之前叫经典式,后来改名了)。
2.3.1、声明式映射
from sqlalchemy import Integer, String, ForeignKey
from sqlalchemy.orm import DeclarativeBase
from sqlalchemy.orm import Mapped
from sqlalchemy.orm import mapped_column# 声明一个基类,Base这个名字可以换成别的
class Base(DeclarativeBase):pass# 通过继承Base,获得SqlAlchemy定义好的ORM能力。此时User就不是一个普通的实体,而是一个可被追踪状态的实体。SqlAlchemy通过这个配置还能知道,需要关联哪些表,表里有哪些字段,字段是什么类型,主键是谁等等元信息
class User(Base):# 该实体关联的表名__tablename__ = "user"# mapped_column除了String类型,还有其他类型,https://docs.sqlalchemy.org/en/20/core/type_basics.html#generic-camelcase-typesid: Mapped[int] = mapped_column(primary_key=True)name: Mapped[str]fullname: Mapped[str] = mapped_column(String(30))nickname: Mapped[Optional[str]]
SqlAlchemy官方更推荐新用户使用声明式的方法来定义关系映射
2.3.2、命令式映射
命令式的关系映射
from sqlalchemy import Table, Column, Integer, String, ForeignKey
from sqlalchemy.orm import registry
# 声明一个registry。
# 声式和命令式的底层,其实都是一个registry对象
mapper_registry = registry()user_table = Table(# 关联的表名"user",mapper_registry.metadata,Column("id", Integer, primary_key=True),Column("name", String(50)),Column("fullname", String(50)),Column("nickname", String(12)),
)class User:pass# 将普通的User对象和命令式的声明绑定起来,User对象就会被SqlAlchemy跟踪,更新User对象属性的值
mapper_registry.map_imperatively(User, user_table)
3、数据库操作的2个核心对象
3.1、connection
connection,就是从engine的连接池中取出的物理连接,通过connection对象可以直接操作数据库,示例:
with engine.connect() as connection:connection.execute(insert(user_table).values(name=req.name,age=req.age,email=req.email,phone=req.phone)connection.commit()
connection不是线程安全的,多个线程不能共享同一个Connection

3.2、session
session的本意是会话,session相关的操作都是有状态的操作。session是构建在connection之上的,但是session操作数据库,有别于connection操作数据库,session操作数据库时,会跟踪操作实体的状态,这种方式也是SqlAlchemy官方推荐的方式,具体来说,当你使用session执行了一个查询或者其他操作后,session就会跟踪你当前操作的这个实体的状态,当你改变了实体的值时,session会将变动值更新到数据库。session内部维护了一个identity map的对象,通过identity map来持有实体类。session的初始化方式如下:
from sqlalchemy import create_engine
from sqlalchemy.orm import Session# 创建一个engine
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/")# 通过engine创建一个Session
# 使用with方式是官方推荐的方式,相当于初始化了一个上下文管理器,可以自动关闭session,类似于java的try-resources
with Session(engine) as session:# 将some_object管理起来session.add(some_object)session.add(some_other_object)# 提交新增some_object的操作session.commit()
如果你不想写session.commit,可以使用下面这种方式,就可以不用手动commit
# create session and add objects
with Session(engine) as session, session.begin():session.add(some_object)session.add(some_other_object)
4、关于Session
Session是SqlAlchemy中最常使用的对象,相对来说,直接使用Connection对象的时候较少,所以我们单独开一个大章节,聊一下这个Session
4.1、使用sessionmaker初始化session
刚开始介绍Session时,我们用的是Session绑定Engine的方式。但其实用的更多的是sessionmaker的方式
1)、sessionmaker的作用
sessionmaker类似于一个session模板,用这块模板创建出来的session自带标准配置
2)、例子
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker# 创建一个engine
engine = create_engine("postgresql+psycopg2://scott:tiger@localhost/")# 使用sessionmaker绑定一个engine,创建一个Session工厂
Session = sessionmaker(bind=engine,autoflush=False,expire_on_commit=False,info={'tenant_id': None, # 占位符'db_shard': 'default'}
)with Session.begin() as session:session.add(some_object)session.add(some_other_object)
# 自动提交,并且自动关闭Session
3)、sessionmaker支持的参数
bind:绑定具体的engine
class:创建新session对象的class对象
autoflush:是否自动将Session管理的持久化对象属性信息刷新到数据库
expire_on_commit:所有持久化对象,在session.commit()后是否自动过期,这是一种对一致性和性能的权衡。
# 默认行为: expire_on_commit=True
user = session.query(User).first() # 发出 SELECT
user.name = "Alice"
session.commit() # 事务提交# 此时 user 对象已过期
print(user.name) # **再次发出 SELECT**,重新加载数据# 设置为 False 时
session = Session(expire_on_commit=False)
user = session.query(User).first()
user.name = "Bob"
session.commit() # 提交后对象不过期print(user.name) # 直接读取缓存,不查询数据库
info:我们可以在创建session预制一些上下文信息,这些上下文信息以字典的形式存在。
小例子:
from sqlalchemy.orm import sessionmaker# 在工厂级别定义共享的 info 字典
MySession = sessionmaker(bind=engine,info={'tenant_id': None, 'db_shard': 'default'} # 预置信息
)# 创建 Session 实例时,每个都会获得此字典的副本
session1 = MySession()
session2 = MySession()print(session1.info) # {'tenant_id': None, 'db_shard': 'default'}
print(session2.info) # {'tenant_id': None, 'db_shard': 'default'}
关于这个info参数,官方文档里还提到了一句话
Note this dictionary is updated, not replaced, when the info parameter is specified to the specific Session construction operation.
这句话的意思是:我们通过sessionmaker构建了一个Session,更新这个Session的info信息时,新的info不会替换预制的info,而是合并,即:字典同名的key的value会被更新,不同名的key都会被保留
我们例子中的MySession的字典参数为:
{‘tenant_id’: None, ‘db_shard’: ‘default’}
然后我们在使用MySession时,可以通过info信息,更新MySession预制的info信息
def get_db() -> Generator[Session, None, None]:"""每次请求都创建新Session"""db = MySession(info={'tenant_id': "111","param":"333"})try:yield dbfinally:db.close()
在真正使用这个MySession时,获取到的就是更新后的信息
def search_user_dao(self, req: SearchUser,db:Session) -> UserRes:print(f"db的信息为:{db.info}")
输出:{‘tenant_id’: ‘111’, ‘db_shard’: ‘default’, ‘param’: ‘333’}
可以看到,对于同名属性,tenant_id,新的value值覆盖了旧的null,然后db_shard作为旧值保留了下来,param作为新值也保留了下来,证明info中的dict对象操作是一个更新的过程,而不是新的dict完整替换旧的dict
**kw
其他的可选参数
4.2、Session的CRUD操作
4.2.1、查询
from sqlalchemy import select
from sqlalchemy.orm import Sessionwith Session(engine) as session:# 构建查询实体对象的statementstatement = select(User).filter_by(name="ed")#1、查询所有name值为 "ed" 的用户列表,结果以ORM对象形式返回,操作起来很方便user_obj = session.scalars(statement).all()# 只查询指定的字段statement = select(User.name, User.fullname)# 2、结果集以row的形式返回,提取结果稍微麻烦点rows = session.execute(statement).all()# 查询请求,不需要执行session.commit# 3、使用主键查询,比如:当前例子,查询id=5的User对象my_user = session.get(User, 5)
4.2.2、新增
with Session(engine) as session:user1 = User(name="user1")user2 = User(name="user2")session.add(user1)session.add(user2)session.commit()
4.2.3、删除
with Session(engine) as session:# 标记2个对象为待删除session.delete(obj1)session.delete(obj2)session.commit()
4.2.4、更新
with YouplusSession() as session:user = session.scalars(select(User).where(User.phone == req.phone)).first()user.email = req.emailsession.commit()
4.3、session的事务管理
官网给的反例
### this is the **wrong way to do it** ###
class ThingOne:def go(self):session = Session()try:session.execute(update(FooBar).values(x=5))session.commit()except:session.rollback()raiseclass ThingTwo:def go(self):session = Session()try:session.execute(update(Widget).values(q=18))session.commit()except:session.rollback()raisedef run_my_program():ThingOne().go()ThingTwo().go()
正确的做法
### this is a **better** (but not the only) way to do it ###class ThingOne:def go(self, session):session.execute(update(FooBar).values(x=5))class ThingTwo:def go(self, session):session.execute(update(Widget).values(q=18))def run_my_program():with Session() as session:with session.begin():ThingOne().go(session)ThingTwo().go(session)
所以正确的做法是:使用with块结合session.begin,让Session自己控制正常处理后的commit和异常处理时的rollback
然后在service层或者controller层再处理异常
更多说明请查看原文档
4.4、其他Session类型
4.4.1、scoped_session
对于一个web应用来说,我们其实是希望,我们的整条链路都用一个session,避免混用session而导致的一些数据问题。scoped_session就是为了解决我们这个问题的。而且我觉着这个scope session才是做应用开发时最应该关注的session类型。
scoped_session底层使用注册表模式,关于注册表模式的解释,简单理解,就是一个dict类型,该dict类型有一个唯一的key,value是session对象。当通过唯一key访问registry中的session时,如果registry中没有值就新建一个,有值就直接返回。
scoped_session初始化步骤为:
from sqlalchemy.orm import scoped_session
from sqlalchemy.orm import sessionmaker
#获取session工厂对象
session_factory = sessionmaker(bind=some_engine)
#通过session工厂对象获取一个scope session,之后的使用步骤就和普通session一样了,本质上来说,scoped_session只是通过registry模式对普通的session进行了一层封装,以实现每个线程只有一个session对象
Session = scoped_session(session_factory)
从web入口开始生成一个session,然后经过service、dao,每次都使用同一个session,当我们的逻辑执行结束的时候,session销毁。官方关于scope session的使用给了一张图,如下:
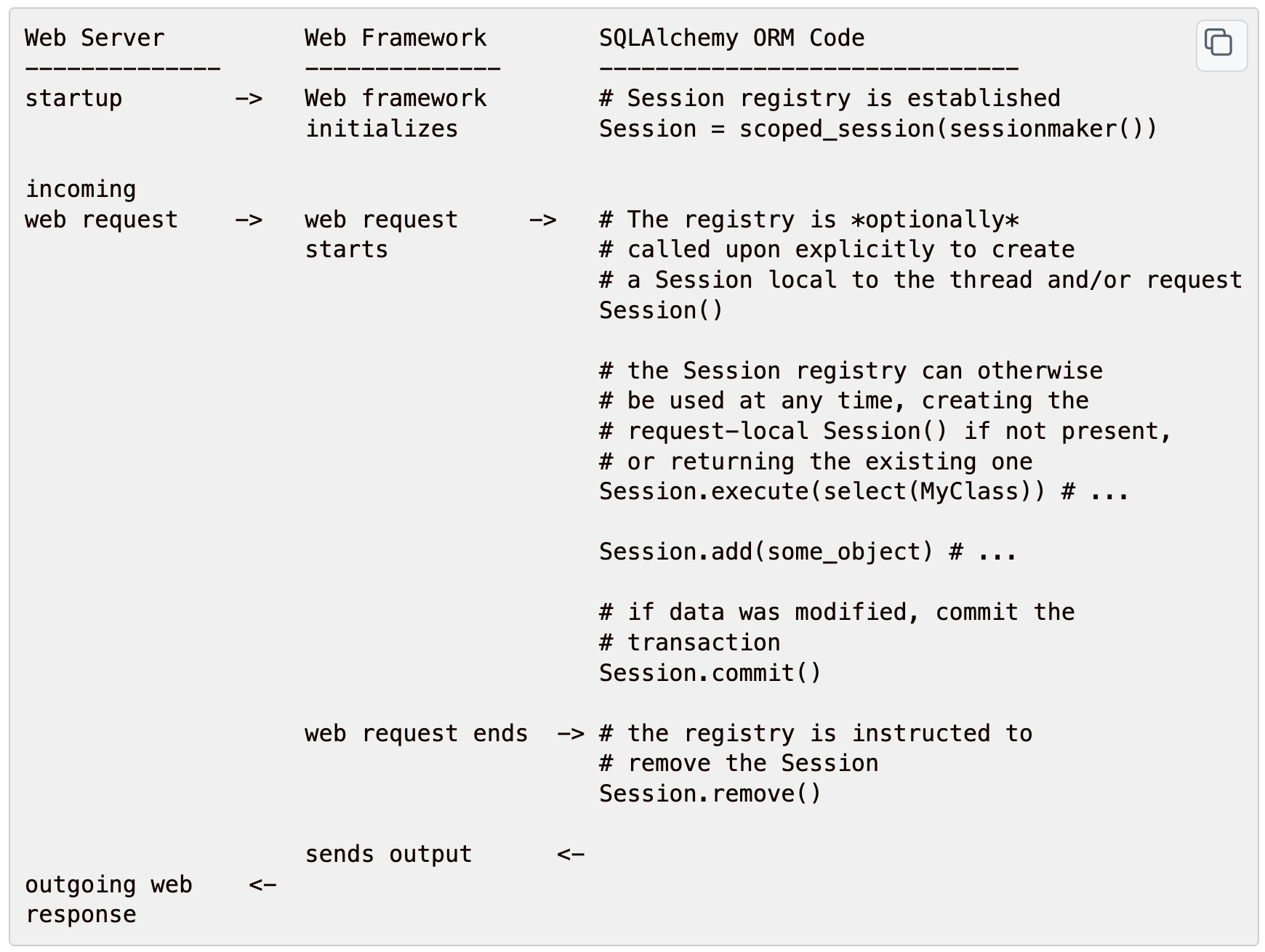
这张图,看着非常简单
1)、首先是web服务端启动,接着SQLAlchemy 的Scoped_session初始化完成
2)、当请求来的时候,registry会创建一个session,然后将其关联到线程上或者请求上,之后,这个请求里的每次获取Session,拿到的都是同一个Session
3)、请求执行完成,执行Session.remove(),结束
官网给的例子:
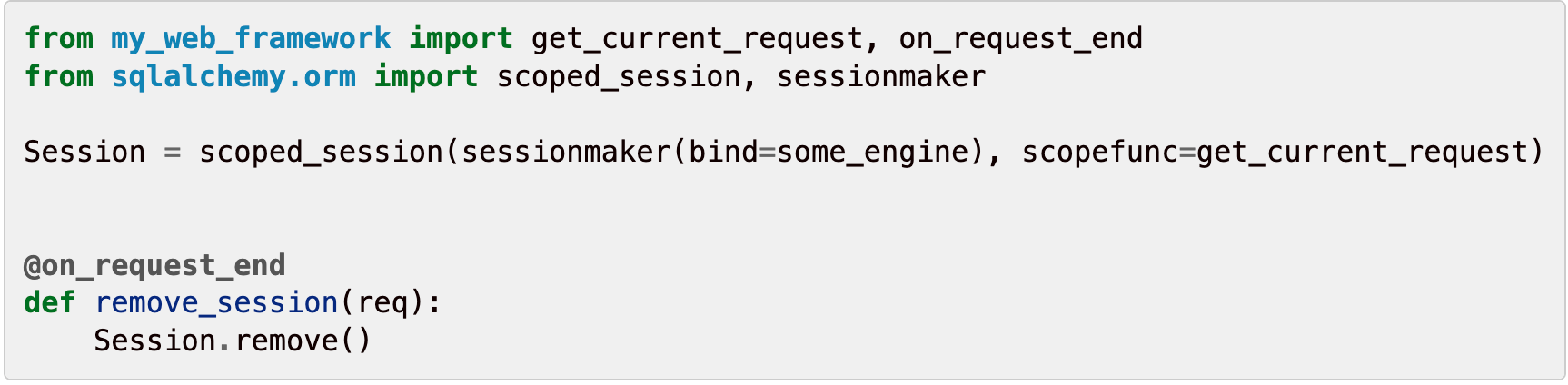
下面介绍两种实现,来确保同一个请求内获取到的Session是同一个
4.4.1.1、通过请求绑定的方式实现
这个就是参考上面这张图的伪代码的一种实现。
__ init__ .py
import contextvars
import threading
from typing import Generatorfrom sqlalchemy import create_engine, QueuePool
from sqlalchemy.orm import sessionmaker, Session, scoped_session# 1、创建Engine
engine = create_engine("mysql+pymysql://root:111111@127.0.0.1:3309/sqlalchemy",pool_recycle=3600,echo=True,pool_size=5,max_overflow=5,pool_timeout=1,pool_pre_ping=True,poolclass=QueuePool)# 2. 创建 sessionmaker 工厂
session_factory = sessionmaker(autocommit=False, autoflush=False, bind=engine)# 3.创建ContextVar来存储请求标识,将通过scopefunc将该请求标识和Session绑定
request_id_var = contextvars.ContextVar("request_id", default=None)# 使用request_id作为scopefunc
UMSSession = scoped_session(session_factory,scopefunc=request_id_var.get
)# --- 实现官网提到的 `on_request_end` 的功能 ---
# 请求结束时,关闭Scoped_session
def get_db_session_v3() -> Generator[Session, None, None]:# 从 scoped_session 注册表中获取/创建Sessiondb = UMSSession()try:yield dbfinally:# 关闭Sessiondb.close()UMSSession.remove()
test_dao.py
import logging
import timefrom sqlalchemy import bindparam
from sqlalchemy import insert, delete, select, text
from sqlalchemy import update
from sqlalchemy.orm import noloadfrom bean.user_bean import User
from dao import YouplusSession, engine, Session, MedSupplierSession, UMSSession
from dao.dto.order_dto import user_table
from req.UserRequest import RegisterUser, UpdateUser, DeleteUser, SearchUser
from res.user_bean import UserReslogging.basicConfig(level=logging.DEBUG, format='%(threadName)s - %(message)s')def search_user_dao_request_scope(req: SearchUser) -> UserRes:# 获取Scoped_Session,请求内部多次获取,得到的是同一个对象ums_session = UMSSession()# 多次获取,是同一个Session对象# ums_session1 = UMSSession()# 这行代码会返回True# print(f"ums_session1和ums_session是同一个对象,{ums_session1 is ums_session}")db_user = ums_session.scalars(select(User).where(User.phone == req.phone).options(noload(User.orders))).first()
test_service.py
def search_user_request_scope(req: SearchUser) -> UserRes:return search_user_dao_request_scope(req)
test_controller.py
# 通过依赖注入获取当前请求的Scoped_Session
# 同请求内多次调用会复用同一个Session实例
@user_controller.post("/search_depends_v3")
def search(req: SearchUser, db: Session = Depends(get_db_session_v3)):user = search_user_request_scope(req)print(user)return user
main.py
启动文件中增加一个中间件,类似于java的拦截器,向contextvars上下文中设置请求id,通过这个唯一的请求id来确保同一请求内获取到的是同一个Session
import logging
import time
import uuidimport uvicorn
from fastapi import FastAPI,Request
from starlette.responses import JSONResponsefrom controller.user_controller import user_controller as user_router
from dao import request_id_var, UMSSessionapp = FastAPI()
app.include_router(user_router, prefix="/user", tags=["user"])if __name__ == "__main__":print(app.routes)uvicorn.run("main:app", host="0.0.0.0", port=8081, log_level="info", workers=5)@app.middleware("http")
async def db_session_middleware(request: Request, call_next):# 为每个请求生成唯一IDrequest_id = f"{int(time.time() * 1_000_000)}-{uuid.uuid4()}"logging.info(f"Request id的值为: {request_id}")# 设置ContextVartoken = request_id_var.set(request_id)try:response = await call_next(request)return responsefinally:request_id_var.reset(token)
4.4.1.2、通过注入的方式实现
以上方式,还是有点麻烦的,需要使用很多技术来实现。有一种简单的办法,也能实现类似的效果。我们可以利用FastAPI的注入方式来实现另外一种同一个请求内使用同一个Session
__ init __.py
import contextvars
import threading
from typing import Generatorfrom sqlalchemy import create_engine, QueuePool
from sqlalchemy.orm import sessionmaker, Session, scoped_sessionengine = create_engine("mysql+pymysql://root:111111@127.0.0.1:3309/sqlalchemy",pool_recycle=3600,echo=True,pool_size=5,max_overflow=5,pool_timeout=1,pool_pre_ping=True,poolclass=QueuePool)
# Session的名称可以自定义
YouplusSession = sessionmaker(bind=engine, autoflush=False, expire_on_commit=False)def get_db() -> Generator[Session, None, None]:"""每次请求都创建新Session"""db = YouplusSession()try:yield dbfinally:db.close()
user_dao.py
import logging
import timefrom sqlalchemy import select
from sqlalchemy.orm import noload, Sessionfrom bean.user_bean import User
from req.UserRequest import SearchUser
from res.user_bean import UserReslogging.basicConfig(level=logging.INFO, format='%(threadName)s - %(message)s')class UserDao:def search_user_dao(self, req: SearchUser,db:Session) -> UserRes:db_user = db.scalars(select(User).where(User.phone == req.phone).options(noload(User.orders))).first()db_user.create_time = db_user.create_time.strftime("%Y-%m-%d %H:%M:%S")time.sleep(1)if not db_user:user = User("name_" + req.phone, 100, req.phone, "email_" + req.phone)db.add(user)db.commit()logging.info("plain insert")else:logging.info("plain skip")return UserRes.model_validate(db_user)
user_service.py
from sqlalchemy.orm import Sessionfrom dao.user.user_dao_depends import UserDao
from req.UserRequest import SearchUser
from res.user_bean import UserResclass UserService:def search_user(self, req: SearchUser,db:Session) -> UserRes:user_dao = UserDao()return user_dao.search_user_dao(req,db)
user_controller.py
@user_controller.post("/search_depends_v1")
def search(req: SearchUser,db: Session = Depends(get_db)):user_service = UserService()user = user_service.search_user(req,db)print(user)return user
相比之下,依赖注入的方式更简单一点,也更容易理解,很容易就能看到同一个请求用的是同一个Session。如果使用第一种方式,需要你了解一些Scoped_session的内部机制
4.4.2、AsyncSession
AsyncSession的应用场景是python的协程技术。常规session是线程不安全的,不能在多线程中使用。官方说的很明确,一个线程一个Session。
在官方文档,对这个是有专门介绍的,原文链接:Session是线程安全的吗?。


协程技术是单线程并发的,所以常规session是不能在协程技术里使用的,所以就有了AsyncSession技术,来应对这种场景。我这篇文章,主要先介绍如何通过SqlAlchemy来和数据库交互,先入个门,像AsyncSession这种需要进一步优化性能的,我就先不介绍了,后面找时间再补充这一块知识,但是我觉着协程的应用场景是IO,而数据库操作主要就是磁盘的IO操作,所以AsyncSession是一个业务侧很好的优化技术,需要深入了解的,有小伙伴如果现在就想看,可以异步官方文档,我贴在这,AsyncSession
4.5、多线程中使用Session
我写了一个多线程更新数据的例子,你可以直接粘走,在本地复现下
DDL语句
CREATE TABLE user
(id int AUTO_INCREMENT COMMENT '主键'PRIMARY KEY,name varchar(50) DEFAULT '' NULL COMMENT '姓名',age int DEFAULT 0 NULL COMMENT '年龄',email varchar(50) DEFAULT '' NULL COMMENT '邮件',phone varchar(50) DEFAULT '' NULL COMMENT '电话',create_time datetime DEFAULT CURRENT_TIMESTAMP NULL COMMENT '创建时间',update_time datetime DEFAULT CURRENT_TIMESTAMP NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
)COMMENT '用户表' CHARSET = utf8mb4;
测试数据
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('刘洋', 22, 'liu.yang@example.com_update_v2_v3', '18977067651', '2023-10-27 10:00:03', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('赵敏', 29, 'zhao.min@example.com_update_v2_v3', '13200998918', '2023-10-27 10:00:05', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('李四', 24, 'lisi@example.com_update', '13800000002', '2025-11-05 16:58:43', '2025-11-09 11:56:08');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('孙七', 26, 'sunqi@example.com_update_v2_v3', '13800000005', '2025-11-05 16:58:43', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('张伟', 35, 'zhangwei88@qq.com_update_v2_v3', '13800138000', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('李娜', 28, 'lina_2019@163.com_update_v2_v3', '13912345678', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('王强', 42, 'wangqiang.job@gmail.com_update_v2_v3', '18611112222', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('刘敏', 29, 'liumin_99@sina.com_update_v2_v3', '15033334444', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('陈杰', 31, 'chenjie123@126.com_update_v2_v3', '13555556666', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('杨静', 26, 'yangjing@outlook.com_update_v2_v3', '18877778888', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('赵磊', 38, 'zhaolei_1985@foxmail.com_update_v2_v3', '13799990000', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('黄艳', 24, 'huangyan_1999@hotmail.com_update_v2_v3', '13622223333', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('周洋', 45, 'zhouyang_runner@qq.com_update_v2_v3', '18344445555', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('吴娟', 27, 'wujuan021@163.com_update_v2_v3', '15966667777', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('徐伟', 33, 'xuwei_engineer@gmail.com_update_v2_v3', '13488889999', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('孙丽', 30, 'sunli_beauty@sina.com_update_v2_v3', '18711113333', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('马勇', 40, 'mayong_manager@126.com_update_v2_v3', '15122225555', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('朱芳', 25, 'zhufang_smile@outlook.com_update_v2_v3', '15544446666', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('胡军', 36, 'hujun_happy@foxmail.com_update_v2_v3', '18055557777', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('郭涛', 32, 'guotao_lee@hotmail.com_update_v2_v3', '15266668888', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('何静', 23, 'hejing_love@qq.com_update_v2_v3', '15877779999', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('林峰', 39, 'linfeng_mountain@163.com_update_v2_v3', '18188880000', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('高翔', 34, 'gaoxiang_fly@gmail.com_update_v2_v3', '13933335555', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
INSERT INTO `user` (name, age, email, phone, create_time, update_time) VALUES ('罗娟', 28, 'luojuan_sweet@sina.com_update_v2_v3', '13544446666', '2025-11-09 11:44:55', '2025-11-09 12:00:14');
测试程序
import loggingfrom sqlalchemy import create_engine, Column, Integer, String, DateTime, QueuePool
from sqlalchemy.orm import sessionmaker, declarative_base
from concurrent.futures import ThreadPoolExecutor, as_completed
import threadingengine = create_engine("mysql+pymysql://root:111111@127.0.0.1:3309/sqlalchemy",pool_recycle=3600,echo=True,pool_size=5,max_overflow=5,pool_timeout=1,pool_pre_ping=True,poolclass=QueuePool)# 创建 sessionmaker 工厂
SessionFactory = sessionmaker(bind=engine, expire_on_commit=False)# ==================== 2. ORM 模型 ====================
Base = declarative_base()class User(Base):__tablename__ = 'user'id = Column(Integer, primary_key=True)name = Column(String(50))age = Column(Integer)email = Column(String(50))phone = Column(String(50))create_time = Column(DateTime)update_time = Column(DateTime)def update_email_for_user(user_id: int) -> tuple:try:#在子线程中,通过Session工厂创建一个Sessionwith SessionFactory() as session:user = session.query(User).filter_by(id=user_id).with_for_update().first()if not user:return user_id, False, "用户不存在"original_email = user.emailuser.email = f"{original_email}_update"if user_id == 69:# 手动构建一个异常,确保当前更新操作不会影响到其他更新操作raise Exception("手动构建异常,看看是否会影响其他更新操作")session.commit()return user_id, True, f"成功: {original_email} -> {user.email}"except Exception as e:# 外层捕获,记录日志或执行重试logging.error(f"用户 {user_id} 更新失败: {e}")return user_id, False, f"异常: {str(e)}"def batch_update_emails(max_workers: int = 5):session = SessionFactory()try:# 获取所有用户的iduser_ids = [uid for (uid,) in session.query(User.id).order_by(User.id).all()]print(f"共找到 {len(user_ids)} 个用户")finally:session.close()# 使用线程池并发更新results = []with ThreadPoolExecutor(max_workers=max_workers, thread_name_prefix="EmailUpdater") as executor:# 提交所有任务future_to_id = {executor.submit(update_email_for_user, uid): uid for uid in user_ids}# 处理完成的任务for future in as_completed(future_to_id):user_id = future_to_id[future]try:result = future.result()results.append(result)print(f"[{threading.current_thread().name}] 用户ID={result[0]}: {result[2]}")except Exception as e:print(f"线程异常: {e}")# 汇总结果success_count = sum(1 for _, success, _ in results if success)print(f"\n更新完成: 成功 {success_count}/{len(user_ids)}")return resultsif __name__ == '__main__':# 更新所有用户邮箱,在邮箱后缀增加_updatebatch_update_emails(max_workers=5)
更新完成后,除了手动构建异常的那条更新失败,其他的更新操作都是成功的,对照数据库的数据看也是没有问题的
4.6、session的其他操作
session还有很多其他操作,可以查看官方文档
5、core方式CRUD
core方式主要依赖connection对象来完成数据库的操作
5.1、单个新增
# 使用了engine.begin,就不用手动提交事务了
with engine.begin() as connection:connection.execute(insert(user_table).values(name="小明",age=33,email="abc@qq.com",phone="18988787876"))connection.execute(get_insert_user_stmt(req))
更多说明请查看原文档
5.2、批量新增
# RegisterUser就是应用程序定义的普通实体对象,和SqlAlchemy的Table对象,以及ORM对象没有关系
class RegisterUser(BaseModel):age: intphone: stremail: strname: str = NotBlank("用户名不能为空")with engine.begin() as conn:test_data = [RegisterUser(name="张三", age=28, email="zhangsan@example.com", phone="13800000001"),RegisterUser(name="李四", age=24, email="lisi@example.com", phone="13800000002"),RegisterUser(name="王五", age=32, email="wangwu@example.com", phone="13800000003"),RegisterUser(name="赵六", age=30, email="zhaoliu@example.com", phone="13800000004"),RegisterUser(name="孙七", age=26, email="sunqi@example.com", phone="13800000005"),]# 把普通业务对象转成字典对象values = [u.model_dump() for u in test_data]conn.execute(text("INSERT INTO `user` (name, age, email, phone) VALUES (:name, :age, :email, :phone)"),values,)
5.3、删除
with engine.begin() as connection:#user_table.c是在获取列名,.c是column的缩写connection.execute(delete(user_table).where(user_table.c.phone == "19099091191"))
更多说明请查看原文档
5.4、批量删除
# 待删除的主键id数据
ids_to_delete = [5, 8, 12, 20]# .in_() 会生成 SQL 中的 `IN` 子句 (例如 `WHERE id IN (5, 8, 12, 20)`)
with engine.begin() as connection:result = connection.execute(delete(user_table).where(user_table.c.id.in_(ids_to_delete)))
5.5、更新
def update_user_core(req: UpdateUser):with engine.begin() as connection:connection.execute(update(user_table).where(user_table.c.phone == req.phone).values(email=req.email))
5.6、批量更新
# 根据id数据更新手机号数据
stmt = (update(user_table).where(user_table.c.id == bindparam("id")).values(name=bindparam("phone")))test_data = [RegisterUser(id=2, phone="13800000001"),RegisterUser(id=3, phone="13800000002"),RegisterUser(id=4, phone="13800000003")]values = [u.model_dump() for u in test_data]with engine.begin() as conn:conn.execute(stmt,values)
5.7、查询
5.7.1、使用Sql Express Language构建查询Sql
from sqlalchemy import selectwith engine.connect() as conn:stmt = select(user_table).where(user_table.c.name == "spongebob")for row in conn.execute(stmt):print(row)
5.7.2、使用text关键字构建查询SQl
如果你的sql非常复杂,用statement构建非常的繁琐,SqlAlchemy还支持一种text的方式,允许你手动构建sql,然后执行,但是要注意参数预编译,防止SQL注入攻击
举个简单的查询例子
stmt = text("SELECT x, y FROM some_table WHERE y > :y ORDER BY x, y")
with engine.begin() as connection:result = connection.execute(stmt, {"y": 6})for row in result:print(f"x: {row.x} y: {row.y}")
再举个更新的例子
with engine.connect() as connection:result = connection.execute(text("UPDATE some_table SET y=:y WHERE x=:x"),[{"x": 9, "y": 11}, {"x": 13, "y": 15}],)connection.commit()
text方式就像mybatis的XML方式一样,你可以构建一个很复杂的sql来检索或更新数据
6、orm方式CRUD
ORM方式的操作,主要依赖Session对象来完成,在上面章节介绍session时,已经提到了操作。我们在这里再补充点批量操作的方式。
6.1、单个新增
with YouplusSession() as session:user = User(name="异常验证name", age=1, email="abc.email", phone="18988787876");session.add(user)session.commit()
6.2、批量新增
with YouplusSession() as session:test_data = [User(name="张三", age=28, email="zhangsan@example.com", phone="13800000001"),User(name="李四", age=24, email="lisi@example.com", phone="13800000002"),User(name="王五", age=32, email="wangwu@example.com", phone="13800000003"),User(name="赵六", age=30, email="zhaoliu@example.com", phone="13800000004"),User(name="孙七", age=26, email="sunqi@example.com", phone="13800000005"),]session.execute(insert(User), test_data)session.commit()
更多说明请查看原文档
6.3、单个删除
def delete_user_orm_dao(req: DeleteUser):with YouplusSession() as session:#需要先根据入参的手机号查询到一个用户user = session.scalars(select(User).where(User.phone == req.phone)).first()#根据主键id删除数据session.delete(user)session.commit()
6.4、批量删除
def batch_delete_user_orm_dao(req: DeleteUser):phones = ['18900909876','17655657890','13211356786']with YouplusSession() as session:result = session.execute(delete(User).where(User.phone.in_(phones)))session.commit()
6.5、更新
# 单个更新,ORM方式V1
# 关于synchronize_session参数
# synchronize_session一共4个可选值
# 1)、auto:如果数据库支持Returning,使用fetch,否则使用evaluate
# 2)、fetch:根据主键加载数据库最新的数据更新到内存的session对象中
# 3)、evaluate:使用Sql语句的where条件来定位session中的对象并更新session对象。
# 如果有大量的session对象需要过期,不要用evaluate,官方文档专门提了这个点。
# SQLAlchemy 为了在 Python 层面判断哪些对象符合 WHERE 条件,必须先把这些过期对象一条条刷新——于是会发出 N 条 SELECT,性能爆炸
# 4)、False:不同步。就是你只关心新值是否更新到数据库中,不关心内存中对象的值是否更新
def update_user_orm_v1(req: UpdateUser):with YouplusSession() as session:stmt = (update(User).where(User.phone == req.phone).values(fullname="Name starts with S").execution_options(synchronize_session=False))session.execute(stmt)session.commit()# 单个更新,ORM方式V2.官方更推荐这种方式,官方的理由是,用户不需要关心sql,只关心业务逻辑即可
def update_user_orm_v2(req: UpdateUser):with YouplusSession() as session:user = session.scalars(select(User).where(User.phone == req.phone)).first()#修改User对象的email数据,此时该改动会被session跟踪user.email = req.email#将改动提交到数据库session.commit()
6.6、批量更新
with YouplusSession() as session:session.execute(update(User),[{"id": 1, "fullname": "Spongebob Squarepants"},{"id": 3, "fullname": "Patrick Star"},{"id": 5, "fullname": "Eugene H. Krabs"},],)
更多说明请查看原文档
6.7、查询
使用Sql Express language构建查询Sql
# 我们的User对象中,有一个orders的级联属性,代表用户的订单列表。所以在查询用户信息的时候,是否关联查询用户的订单数据,就需要关注下
with YouplusSession() as session:# 方式一:立即加载用户关联的订单,这会再次发起一次查询用户订单的sql查询# scalars,这种方式会将用户对象从row对象封装成User实体,取值会更方便# db_user = session.scalars(# select(User).where(User.phone == req.phone).options(selectinload(User.orders))).first()# 方式二:延迟加载用户的orders属性,当使用Order的product属性时,才开始加载User.orders# db_user = session.scalars(# select(User).where(User.phone == req.phone).options(# lazyload(User.orders).selectinload(Order.product))).first()# 方式三:不加载用户的orders属性db_user = session.scalars(select(User).where(User.phone == req.phone).options(noload(User.orders))).first()
7、ORM方式和Core方式总结
7.1、定位不同
从<编译原理之美>这个专栏里看到了一句话,这句话讲的是编译的事,但是我觉着形容ORM方式和Core方式的区别也是非常恰当的。
ORM方式:关心的是要什么,不关心过程
Core方式:关心的是如何做
前者更贴近人类社会的领域问题
后者更贴近计算机实现。
ORM隐藏了Sql的细节,让用户专注于业务。而Core方式需要用户关注细节实现,需要用户参与到构建Sql的细节。这是两种截然不同的处理方式
具体使用哪种方式,需要 结合场景。如果是简单的场景,ORM显然是更方便的
7.2、 操作方式不同
ORM方式主要依赖Session对象以及对应数据库表的关系映射来完成数据库的操作,SqlAlchemy隐藏了大量的底层实现细节,让用户只关注自己的业务即可,更面向对象。
Core方式主要依赖Connection对象以及对应数据库表的关系映射来完成操作,但是用户需要参与到Sql构建的细节中,对于刚从mybatis-plus中迁移过来的用户来说,显然更希望能直接看到Sql,更可控。但是从我上面的介绍,你也能看出来,ORM方式是更简单的。
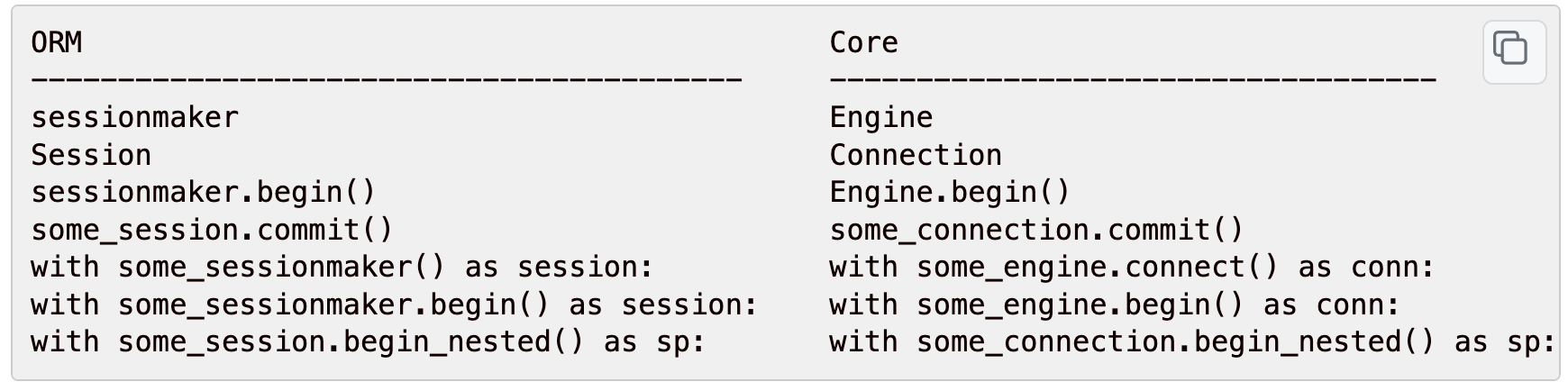
7.3、API对比
从官网上拿下来的一张图
8、SqlAlchemy的坑点
8.1、忘记释放连接
在SqlAlchemy中,推荐使用with上下文块来包裹Session,自动实现连接的释放,防止忘记
with YouplusSession() as session:# do something using session
8.2、在线程里频繁的获取、关闭session或连接
虽然通过with语句块能够自动关闭连接,但是也不要在一块业务逻辑中频繁的获取和关闭session,session底层依赖的是连接池,连接池的连接数量是有限的,在一个请求中,频繁获取session,高并发下,会很快把连接池数量打满,影响到其他请求。推荐一个请求,一个session,具体实现可以往上再看下"5.4章节"
8.3、接口压测
不是说SqlAlchemy在接口压测上有什么坑点。而是说通过接口压测发现一些坑点。有些错误,在小数据量下看不出来,但当请求量一大,就会出问题,接口压测算是一种避坑的方式。我平时用mac开发,推荐一个在mac上比较好用的压测命令:hey命令
支持传header和body参数
hey -n 500 -c 20 -m POST \-H "Content-Type: application/json" \-d '{"phone":"18977067651"}' \http://127.0.0.1:8081/user/search_depends_v1
更多的使用方式,可以在终端输入:hey -help来进行查看。
hey -help
好了,以上就是本章的全部内容