Hello-Agents第一章深度解析:智能体的本质、构建与实践
Hello-Agents第一章深度解析:智能体的本质、构建与实践
作为智能体入门的核心章节,Hello-Agents第一章不仅搭建了智能体的基础认知框架,更通过理论+实战的模式,让“从LLM使用者到智能体构建者”的转型落地。本文将从核心概念拆解、代码逻辑剖析、习题深度解答三个维度,带大家吃透第一章的关键知识点,为后续复杂智能体构建筑牢根基。
一、核心概念:重新理解智能体的本质
1.1 智能体的定义与四要素
智能体的核心定义可概括为:能够通过传感器感知环境、自主通过执行器采取行动,以达成特定目标的实体。这个定义包含四个不可缺少的要素,用生活案例拆解更易理解:
- 环境(Environment):智能体所处的外部场景,比如自动驾驶的“道路交通”、交易算法的“金融市场”、智能旅行助手的“航旅服务网络”。
- 传感器(Sensors):感知环境的“触角”,可以是物理设备(摄像头、雷达),也可以是虚拟工具(API返回数据、用户输入)。例如旅行助手通过解析航旅API获取机票信息,就是传感器在工作。
- 执行器(Actuators):影响环境的“手脚”,物理设备(机械臂、方向盘)或虚拟操作(调用工具、生成文本)都属于此类。比如旅行助手调用预订API完成酒店下单,就是执行器的作用。
- 自主性(Autonomy):智能体的核心灵魂——无需预设指令,基于感知和内部状态独立决策。比如恒温器不会只被动响应温度变化,还会根据预设目标自主启停制冷/制热。
1.2 智能体的进化之路:从简单反射到LLM驱动
智能体的发展是“解决痛点→引入新特性→暴露新局限”的迭代过程,用“工具升级”的逻辑理解更清晰:
- 简单反射智能体:“条件-动作”的直接映射(如“温度>25℃→制冷”),无记忆、无预测,像“自动化开关”,适合简单场景。
- 基于模型的反射智能体:增加“内部世界模型”,具备初级记忆。比如隧道中的自动驾驶汽车,即使摄像头暂时看不到前车,仍能通过模型维持对前车位置的判断。
- 基于目标的智能体:明确目标并规划路径,像“带导航的步行者”。例如GPS导航根据“到达公司”的目标,规划最优路线。
- 基于效用的智能体:能权衡多目标(如“时间最短+成本最低”),像“会算账的决策者”。比如旅行助手在“低价”和“近景点”之间找平衡。
- 学习型智能体:通过强化学习自主优化策略,像“会总结经验的学习者”。比如AlphaGo通过千万次自我对弈,发现超越人类的棋路。
- LLM驱动智能体:以预训练模型为核心,具备强大的泛化能力,能理解模糊指令、动态调整策略,是当前智能体的主流范式。
1.3 智能体的三大分类维度
(1)按内部决策架构分类
对应智能体的进化路径:简单反射→基于模型→基于目标→基于效用→学习型,核心差异是“决策依赖的信息复杂度”。
(2)按时间与反应性分类
- 反应式智能体:毫秒级响应,无规划,适合动态场景。比如高频交易机器人捕捉瞬时市场机会,安全气囊系统的毫秒级触发。
- 规划式智能体:深思熟虑后行动,适合复杂任务。比如制定商业计划、规划跨国旅行,需要预判未来多种可能性。
- 混合式智能体:结合两者优势,底层快速反应(如用户反馈后即时调整推荐),高层规划长远目标(如制定5天旅行方案),LLM智能体多属于此类。
(3)按知识表示分类
- 符号主义:知识以“规则+符号”形式存储(如“IF发烧AND咳嗽→呼吸道感染”),透明可解释,但脆弱易失灵(未覆盖的新情况无法处理)。
- 亚符号主义:知识是数据中学习的统计模式(如神经网络识别猫的视觉特征),鲁棒性强,但像“黑箱”难以解释。
- 神经符号主义:融合两者,LLM智能体是典型代表——内核是神经网络(亚符号),生成的中间步骤(思想、API调用)是符号,实现“直觉+理性”的协同。
二、核心原理:智能体的运行机制与代码实现
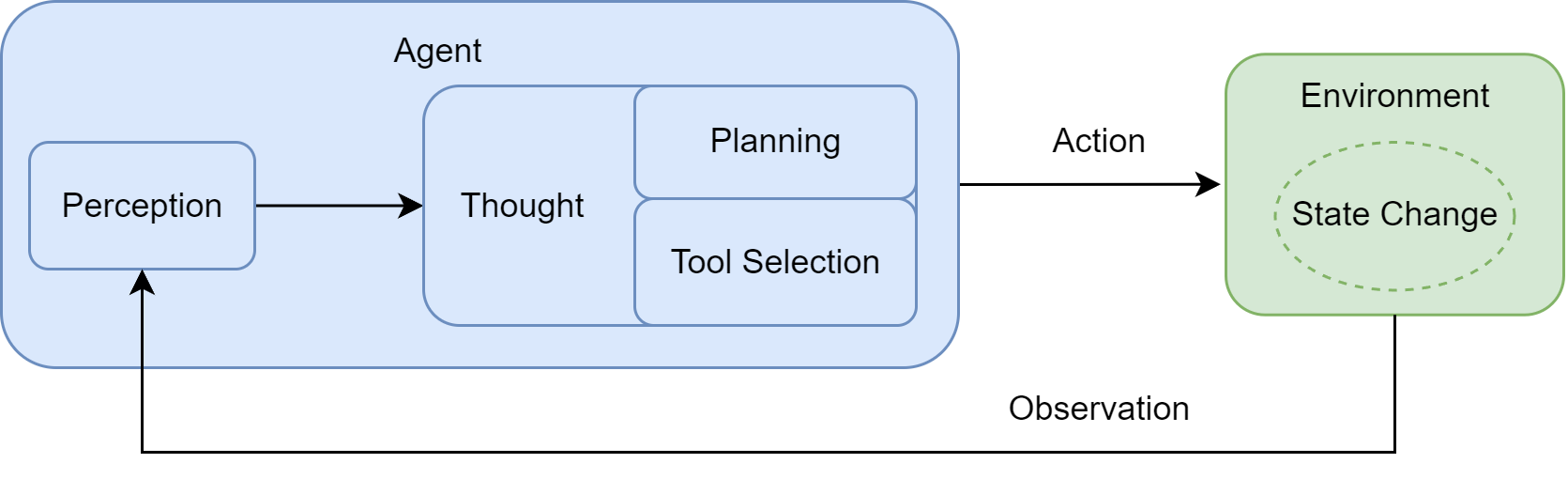
2.1 智能体的“感知-思考-行动”循环
智能体的运行核心是一个持续迭代的闭环,每一步都有明确的功能定位:
- 感知(Perception):通过传感器获取环境输入(用户指令、工具反馈),是循环的起点。
- 思考(Thought):LLM驱动的核心决策阶段,拆分为“规划”(分解任务、制定步骤)和“工具选择”(匹配最优工具及参数)。
- 行动(Action):通过执行器执行工具调用,改变环境状态。
- 观察(Observation):环境反馈行动结果,作为下一轮循环的输入,形成闭环。
这个循环的关键是“动态调整”——智能体不会一成不变执行初始计划,而是根据观察结果实时修正,比如旅行助手发现推荐酒店超出预算,会重新搜索符合预算的选项。
2.2 动手实践:5分钟构建智能旅行助手代码解析
原文的智能旅行助手案例是理解循环机制的最佳载体,逐模块拆解代码逻辑:
(1)工具函数:智能体的“手脚”实现
def get_weather(city: str) -> str:url = f"https://wttr.in/{city}?format=j1" # 天气API接口try:response = requests.get(url)response.raise_for_status() # 检查请求是否成功data = response.json() # 解析JSON数据current_condition = data['current_condition'][0]weather_desc = current_condition['weatherDesc'][0]['value']temp_c = current_condition['temp_C']return f"{city}当前天气:{weather_desc},气温{temp_c}摄氏度"except requests.exceptions.RequestException as e:return f"错误:查询天气时遇到网络问题 - {e}"except (KeyError, IndexError) as e:return f"错误:解析天气数据失败,可能是城市名称无效 - {e}"
- 功能:调用wttr.in免费API获取实时天气,格式化返回自然语言结果。
- 关键逻辑:
- 异常处理:覆盖“网络错误”和“数据解析错误”,避免工具调用崩溃,体现智能体的鲁棒性。
- 数据提取:从JSON响应中精准提取天气描述和气温,过滤冗余信息,符合LLM的输入习惯。
第二个工具函数get_attraction同理,通过Tavily搜索API,根据城市和天气推荐景点,核心是“将自然语言需求转化为搜索查询,再将搜索结果转化为结构化推荐”。
(2)LLM客户端:智能体的“大脑”封装
class OpenAICompatibleClient:def __init__(self, model: str, api_key: str, base_url: str):self.model = modelself.client = OpenAI(api_key=api_key, base_url=base_url)def generate(self, prompt: str, system_prompt: str) -> str:messages = [{'role': 'system', 'content': system_prompt},{'role': 'user', 'content': prompt}]response = self.client.chat.completions.create(model=self.model, messages=messages, stream=False)return response.choices[0].message.content
- 功能:封装兼容OpenAI接口的LLM调用,屏蔽不同服务商的接口差异。
- 关键逻辑:
system_prompt:定义智能体角色和行为规则(如“智能旅行助手”“工具使用规范”),是引导LLM决策的核心。- 消息格式:遵循Chat API的标准格式,
system角色设定全局规则,user角色传递具体任务。
(3)主循环:智能体的“闭环运行”核心
for i in range(5): # 限制最大循环次数,避免无限循环full_prompt = "\n".join(prompt_history)llm_output = llm.generate(full_prompt, system_prompt=AGENT_SYSTEM_PROMPT)prompt_history.append(llm_output)# 解析Thought和Actionaction_match = re.search(r"Action: (.*)", llm_output, re.DOTALL)if not action_match:breakaction_str = action_match.group(1).strip()if action_str.startswith("finish"):final_answer = re.search(r'finish\(answer="(.*)"\)', action_str).group(1)print(f"任务完成,最终答案: {final_answer}")break# 提取工具名称和参数,执行工具tool_name = re.search(r"(\w+)\(", action_str).group(1)args_str = re.search(r"\((.*)\)", action_str).group(1)kwargs = dict(re.findall(r'(\w+)="([^"]*)"', args_str))if tool_name in available_tools:observation = available_tools[tool_name](**kwargs)else:observation = f"错误:未定义的工具 '{tool_name}'"prompt_history.append(f"Observation: {observation}")
- 核心逻辑:
- 循环控制:设置最大循环次数(5次),是避免智能体陷入无限循环的“安全阀”,实际应用中可根据任务复杂度调整。
- 输出解析:用正则表达式提取
Action部分,解决LLM输出的非结构化问题,确保工具调用的准确性。 - 状态维护:
prompt_history记录“思考-行动-观察”的完整轨迹,让智能体具备上下文记忆,支持多步骤协作。
(4)运行流程解析
以“查询北京天气并推荐景点”为例,实际运行流程如下:
- 第一轮循环:LLM生成
Thought: 需要先查天气和Action: get_weather("北京"),工具返回“北京晴,26℃”。 - 第二轮循环:LLM结合观察结果,生成
Thought: 晴天适合户外景点和Action: get_attraction("北京", "Sunny"),工具返回颐和园、长城推荐。 - 第三轮循环:LLM整合结果,生成
Action: finish(answer="..."),任务完成。
这个过程完美体现了ReAct范式的核心——“思考指导行动,行动反馈思考”。
(5)运行结果
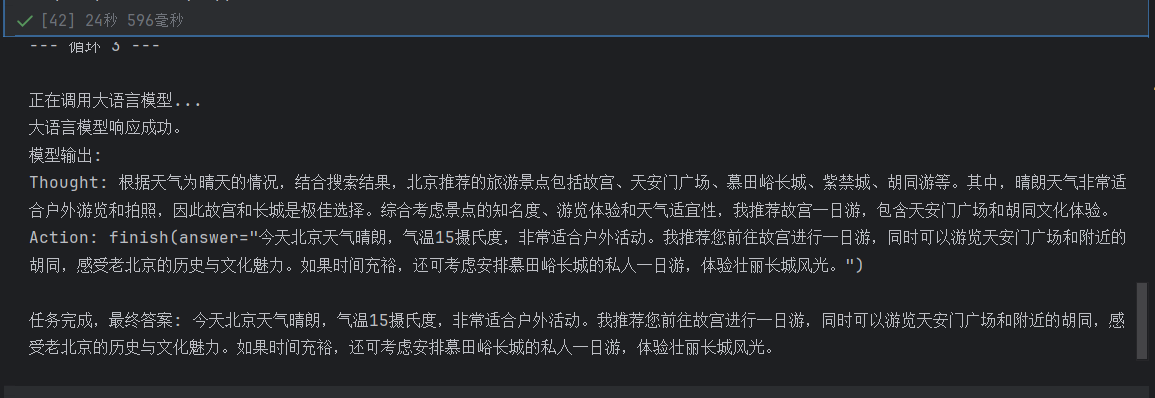
用户输入: 你好,请帮我查询一下今天北京的天气,然后根据天气推荐一个合适的旅游景点。
========================================
--- 循环 1 ---正在调用大语言模型...
大语言模型响应成功。
模型输出:
Thought: 用户请求查询北京今天的天气,并根据天气推荐一个合适的旅游景点。我需要先获取北京的实时天气信息,然后再根据天气情况搜索推荐的景点。
Action: get_weather(city="北京")Observation: 北京当前天气:Sunny,气温15摄氏度
========================================
--- 循环 2 ---正在调用大语言模型...
大语言模型响应成功。
模型输出:
Thought: 我已经获取到北京当前天气为晴天,气温15摄氏度。接下来,我将根据这个天气情况,搜索推荐的旅游景点。
Action: search_attraction(city="北京", weather="Sunny")Observation: 根据北京的Sunny天气,推荐以下景点:- Sunny Personal Tours (北京市) - 旅游景点点评 - Tripadvisor: 私人定制的北京夜游王府井美食街和胡同 · 3.0. (2). 街头美食游览 ; 从北京机场到慕田峪长城的往返旅游 · 5.0. (1). 中途停留游览 ; 私人一日游:慕田峪长城和紫禁城,包括午餐...
- 北京市10 大景点玩乐 - Tripadvisor: 1. 最佳迷你团:故宫、天安门广场、长城、胡同. 4.9. (1,416). 99%的旅行者推荐此体验. 99% 的点评者将此产品评为4 分或以上。 ; 2. 金山岭私人之旅,北京司马台和古北水乡...
- 上集】 漫步老北京 日行三萬步北京暴走打卡!! 故宫天壇逛皇 ...: 🔥🔥【北京旅行Vlog - 上集】✨漫步老北京🚶🚶日行三萬步北京暴走打卡!!👑故宫天壇逛皇城!😋必吃涮羊肉 + 胡同深處驚艷潮州菜 #北京美食探索|Beijing Travel Vlog 2025
Mountain Yam 任朗呈
41800 subscribers
1253 likes
70287 views
3 Jul 2025
✨北京自由行旅遊攻略!!這些地方你絕不能錯過!✨2025 北京...
========================================
--- 循环 3 ---正在调用大语言模型...
大语言模型响应成功。
模型输出:
Thought: 根据天气为晴天的情况,结合搜索结果,北京推荐的旅游景点包括故宫、天安门广场、慕田峪长城、紫禁城、胡同游等。其中,晴朗天气非常适合户外游览和拍照,因此故宫和长城是极佳选择。综合考虑景点的知名度、游览体验和天气适宜性,我推荐故宫一日游,包含天安门广场和胡同文化体验。
Action: finish(answer="今天北京天气晴朗,气温15摄氏度,非常适合户外活动。我推荐您前往故宫进行一日游,同时可以游览天安门广场和附近的胡同,感受老北京的历史与文化魅力。如果时间充裕,还可考虑安排慕田峪长城的私人一日游,体验壮丽长城风光。")任务完成,最终答案: 今天北京天气晴朗,气温15摄氏度,非常适合户外活动。我推荐您前往故宫进行一日游,同时可以游览天安门广场和附近的胡同,感受老北京的历史与文化魅力。如果时间充裕,还可考虑安排慕田峪长城的私人一日游,体验壮丽长城风光。
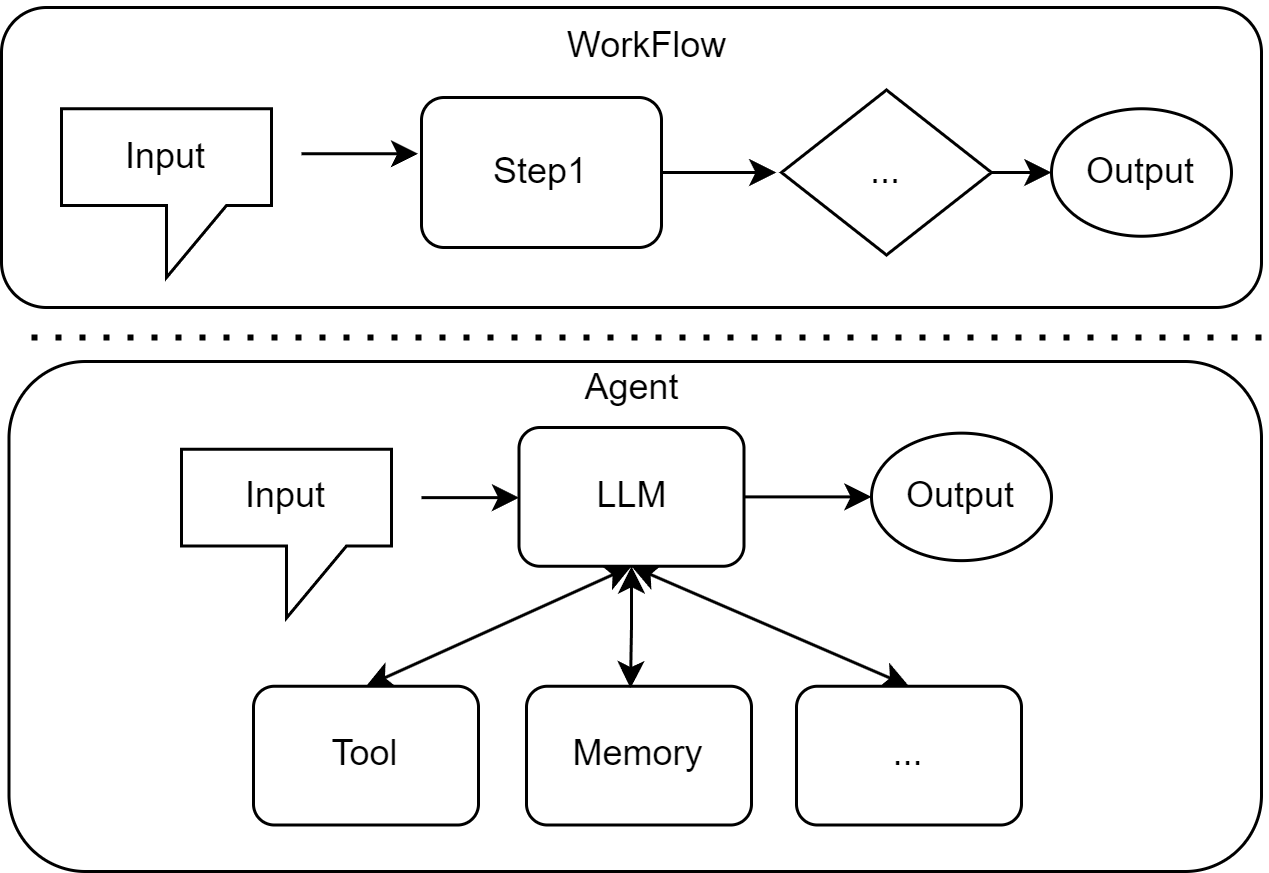
2.3 智能体的协作模式与Workflow差异
(1)两种核心协作模式
- 作为开发者工具:深度融入工作流,自动化繁琐任务,比如GitHub Copilot自动补全代码、Cursor编辑器的AI重构功能。
- 作为自主协作者:接收高层目标后自主完成,比如MetaGPT模拟团队分工生成完整代码库,CrewAI通过角色扮演完成复杂任务。
(2)与Workflow的本质区别
| 维度 | Workflow | Agent |
|---|---|---|
| 核心逻辑 | 预设固定流程(IF-THEN规则) | 目标驱动的自主决策 |
| 灵活性 | 低,无法应对未预设场景 | 高,动态调整策略 |
| 适用场景 | 简单重复任务(如费用报销审批) | 复杂开放任务(如旅行规划) |
举例:同样是“退款处理”,Workflow会预设“金额<500元自动通过”,而Agent会分析用户历史行为、商品状况,自主判断是否批准,甚至处理“商品已使用但质量问题”等未预设场景。
三、课后习题详细解答
习题1:判断以下主体是否为智能体,并说明类型及理由
题干:
分析以下四个case中的主体是否属于智能体,如果是,属于哪种类型(可从多个分类维度分析),并说明理由:
- case A:一台符合冯·诺依曼结构的超级计算机,拥有高达每秒2EFlop的峰值算力
- case B:特斯拉自动驾驶系统在高速公路上行驶时,突然检测到前方有障碍物,需要在毫秒级做出刹车或变道决策
- case C:AlphaGo在与人类棋手对弈时,需要评估当前局面并规划未来数十步的最优策略
- case D:ChatGPT扮演的智能客服在处理用户投诉时,需要查询订单信息、分析问题原因、提供解决方案并安抚用户情绪
解答:
-
case A:不属于智能体
理由:超级计算机仅具备计算能力,无法感知环境(无传感器)、自主行动(无执行器),也没有明确的目标导向,仅是被动执行预设计算任务,不符合智能体的核心定义。 -
case B:属于智能体
类型:- 内部决策架构:基于模型的反射智能体(具备内部世界模型,能追踪障碍物位置);
- 时间反应性:反应式智能体(毫秒级决策,无复杂规划);
- 知识表示:亚符号主义(通过神经网络学习驾驶模式)。
理由:具备完整四要素——环境(道路交通)、传感器(摄像头、雷达)、执行器(刹车、变道系统)、自主性(自主判断刹车或变道,无需人类干预),符合智能体定义。
-
case C:属于智能体
类型:- 内部决策架构:学习型智能体(通过强化学习优化策略);
- 时间反应性:规划式智能体(预判未来数十步棋路);
- 知识表示:亚符号主义(从海量对弈数据中学习模式)。
理由:能感知环境(棋盘局面)、自主行动(落子)、达成目标(赢棋),且通过强化学习自主进化,符合智能体定义。
-
case D:属于智能体
类型:- 内部决策架构:基于目标的智能体(目标是“解决投诉”);
- 时间反应性:混合式智能体(即时响应用户反馈,规划解决方案);
- 知识表示:神经符号主义(LLM内核+结构化查询/回复)。
理由:通过API感知订单信息(传感器)、生成解决方案(执行器)、自主分析投诉原因(自主性),具备完整的“感知-思考-行动”循环。
习题2:用PEAS模型描述智能健身教练,并分析环境特性
题干:
假设你需要为一个"智能健身教练"设计任务环境。这个智能体能够:
- 通过可穿戴设备监测用户的心率、运动强度等生理数据
- 根据用户的健身目标(减脂/增肌/提升耐力)动态调整训练计划
- 在用户运动过程中提供实时语音指导和动作纠正
- 评估训练效果并给出饮食建议
请使用PEAS模型完整描述这个智能体的任务环境,并分析该环境具有哪些特性(如部分可观察、随机性、动态性等)。
解答:
(1)PEAS模型描述
| 维度 | 具体描述 |
|---|---|
| Performance(性能度量) | 1. 训练计划与用户目标的匹配度;2. 用户运动效果(体脂率、肌肉量、耐力提升);3. 用户安全性(避免运动损伤);4. 用户满意度(指导实用性、饮食建议可行性) |
| Environment(环境) | 1. 物理环境:用户运动场景(健身房、居家、户外);2. 设备环境:可穿戴设备(心率监测器、运动传感器)、语音输出设备;3. 用户状态:实时生理数据、运动动作、健身基础、饮食习惯 |
| Actuators(执行器) | 1. 语音模块:实时指导、动作纠正;2. 文本模块:生成训练计划、饮食建议;3. 数据交互模块:向可穿戴设备发送监测指令 |
| Sensors(传感器) | 1. 可穿戴设备数据接口:采集心率、运动强度、动作姿态;2. 用户输入接口:接收健身目标、运动反馈(如“动作吃力”)、饮食反馈 |
(2)环境特性分析
- 部分可观察性:无法完全感知用户的主观状态(如肌肉酸痛程度、运动意愿),仅能通过生理数据间接推断,属于部分可观察环境。
- 随机性:用户的生理反应(如心率变化、疲劳速度)、运动动作规范性存在个体差异,且可能受外界因素(如天气、情绪)影响,属于随机性环境。
- 动态性:用户的生理状态随运动过程实时变化(如心率上升、肌肉疲劳),环境自身持续动态更新,属于动态环境。
- 多智能体交互:环境中存在其他“行动者”(用户自身的运动决策、其他健身者的干扰),属于多智能体环境。
习题3:对比Workflow与Agent方案处理售后退款申请
题干:
某电商公司正在考虑两种方案来处理售后退款申请:
方案A(Workflow):设计一套固定流程,例如:
A.1 对于一般商品且在7天之内,金额 < 100RMB 自动通过;100-500RMB 由客服审核;>500RMB 需主管审批;而特殊商品(如定制品)一律拒绝退款
A.2 对于超过7天的商品,无论金额,只能由客服审核或主管审批;
方案B(Agent):搭建一个智能体系统,让它理解退款政策、分析用户历史行为、评估商品状况,并自主决策是否批准退款
请分析:
- 这两种方案各自的优缺点是什么?
- 在什么情况下 Workflow 更合适?什么情况下 Agent 更有优势?
- 如果你是该电商公司的负责人,你更倾向于采用哪种方案?
- 是否存在一个方案 C,能够结合两种方案,达到扬长避短的效果?
解答:
(1)方案优缺点对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| Workflow | 1. 规则明确,决策透明可追溯;2. 执行高效,无延迟;3. 开发维护成本低;4. 避免人为偏见 | 1. 灵活性差,无法处理未预设场景(如“商品7天内但质量问题严重”);2. 用户体验差,特殊情况需人工介入;3. 规则迭代成本高(需修改流程) |
| Agent | 1. 灵活性强,自主处理复杂场景;2. 用户体验好,个性化决策;3. 可通过学习持续优化;4. 减少人工审核压力 | 1. 决策黑箱,可解释性差;2. 开发维护成本高(需训练模型、处理边缘案例);3. 存在决策错误风险;4. 需大量数据训练 |
(2)适用场景
-
Workflow更合适:
- 退款规则简单固定,无太多例外场景;
- 对决策透明度要求极高(如金融合规场景);
- 预算有限,无法承担Agent开发成本;
- 退款量极大,需毫秒级处理(如低价小商品退款)。
-
Agent更有优势:
- 退款场景复杂,存在大量例外情况(如定制商品质量问题、用户高等级会员特殊申请);
- 注重用户体验,需个性化决策;
- 人工审核成本高(如高客单价商品,客服审核效率低);
- 有足够的历史退款数据用于模型训练。
(3)推荐方案:方案C(混合方案)
(4)方案C设计:
- 核心逻辑:“简单场景用Workflow,复杂场景用Agent”
- 具体实现:
- 基础规则层(Workflow):处理7天内、金额<500RMB的一般商品退款,自动审批或按层级流转,保证高效处理;
- 复杂场景层(Agent):处理特殊商品、超期退款、高金额退款(>500RMB)、用户有特殊诉求的场景,Agent结合退款政策、用户历史行为(如是否高频退款)、商品状况(如是否使用、是否质量问题)自主决策;
- 人工复核层:Agent决策置信度低于阈值(如60%)的案例,流转至客服复核,同时将复核结果反馈给Agent用于模型优化。
- 优势:兼顾Workflow的高效透明和Agent的灵活智能,控制开发成本的同时提升用户体验。
习题4:扩展智能旅行助手功能
题干:
在1.3节的智能旅行助手基础上,请思考如何添加以下功能(可以只描述设计思路,也可以进一步尝试代码实现):
- 添加一个"记忆"功能,让智能体记住用户的偏好(如喜欢历史文化景点、预算范围等)
- 当推荐的景点门票已售罄时,智能体能够自动推荐备选方案
- 如果用户连续拒绝了3个推荐,智能体能够反思并调整推荐策略
解答:
(1)添加“记忆”功能
- 设计思路:在智能体状态中维护“用户偏好字典”,通过用户输入提取偏好,后续工具调用时自动融入参数。
- 代码实现关键步骤:
# 1. 初始化记忆字典 user_preferences = {"attraction_type": None, "budget": None}# 2. 提取用户偏好(在主循环中添加) def extract_preferences(user_input, preferences):# 正则提取预算(如“预算500元以内”)budget_match = re.search(r"预算(\d+)元", user_input)if budget_match:preferences["budget"] = int(budget_match.group(1))# 提取景点类型(如“喜欢历史文化景点”)if "历史" in user_input or "文化" in user_input:preferences["attraction_type"] = "历史文化"return preferences# 3. 工具调用时融入偏好 def get_attraction(city: str, weather: str, preferences: dict) -> str:query = f"'{city}' 在'{weather}'天气下,{preferences.get('attraction_type', '适合')}的旅游景点,预算{preferences.get('budget', '无限制')}元以内"# 后续搜索逻辑不变... - 实现逻辑:用户输入中提取偏好并存储,调用
get_attraction时将偏好融入搜索查询,让推荐更精准。
(2)门票售罄时推荐备选方案
- 设计思路:扩展工具函数,添加“门票查询”接口,若检测到售罄,自动调整搜索关键词(如“北京 晴天 历史文化景点 门票可售”)。
- 代码实现关键步骤:
def check_ticket_availability(attraction: str) -> bool:# 调用门票查询API(如大麦网API)url = f"https://api.example.com/ticket?attraction={attraction}"try:response = requests.get(url)data = response.json()return data["available"] # 返回是否可售except Exception as e:return True # API异常时默认可售# 修改get_attraction函数 def get_attraction(city: str, weather: str) -> str:# 初始搜索获取景点列表initial_results = tavily.search(query=f"{city} {weather} 景点推荐")final_results = []for result in initial_results:attraction = result["title"]if check_ticket_availability(attraction):final_results.append(result)else:# 推荐备选景点alternative = tavily.search(query=f"{city} 类似{attraction}的景点 门票可售")final_results.extend(alternative[:1]) # 取1个备选# 格式化返回...
(3)连续拒绝3次后调整推荐策略
- 设计思路:维护“拒绝计数器”,累计拒绝3次后,触发反思逻辑,调整搜索关键词(如从“热门景点”改为“小众景点”)。
- 代码实现关键步骤:
# 1. 初始化拒绝计数器 reject_count = 0 strategy = "popular" # 初始策略:热门景点# 2. 在主循环中添加拒绝处理 user_feedback = input("是否满意推荐?(满意/不满意)") if user_feedback == "不满意":reject_count += 1if reject_count >= 3:# 调整策略strategy = "niche" # 小众景点策略print("已为您调整推荐策略,将推荐小众特色景点...")reject_count = 0 # 重置计数器 else:reject_count = 0# 3. 工具调用时融入策略 query = f"{city} {weather} {strategy}景点推荐"
习题5:神经符号主义AI的“系统1”与“系统2”应用
题干:
卡尼曼的"系统1"(快速直觉)和"系统2"(慢速推理)理论为神经符号主义AI提供了很好的类比。请首先构思一个具体的智能体的落地应用场景,然后说明场景中的:
- 哪些任务应该由"系统1"处理?
- 哪些任务应该由"系统2"处理?
- 这两个系统如何协同工作以达成最终目标?
解答:
(1)应用场景:智能医疗问诊助手
- 核心目标:接收用户症状描述,初步判断疾病类型,提供就医建议和临时缓解方案。
(2)系统1(快速直觉)处理的任务
- 任务1:症状快速分类(如“发烧+咳嗽”归类为“呼吸道相关”);
- 任务2:常见疾病快速匹配(如“鼻塞+流涕+低烧”匹配“普通感冒”);
- 任务3:紧急情况识别(如“高烧39℃+呼吸困难”判断为紧急情况);
- 原理:基于神经网络的模式识别能力,快速处理结构化和非结构化数据,无需复杂推理,类似人类的直觉反应。
(3)系统2(慢速推理)处理的任务
- 任务1:复杂症状分析(如“长期低烧+体重下降+盗汗”需结合医学逻辑推理可能病因);
- 任务2:多疾病鉴别诊断(如“头痛”可能是感冒、高血压、颈椎病等,需逐一排除);
- 任务3:个性化就医建议生成(结合用户年龄、基础病史、地域医疗资源推理);
- 原理:基于符号逻辑的推理能力,利用医学规则库和知识图谱,进行分步推理,类似人类的理性思考。
(4)协同工作流程
- 系统1先处理用户输入:用户描述“发烧38.5℃+咳嗽+喉咙痛”,系统1快速归类为“呼吸道症状”,匹配“普通感冒”初步结论;
- 系统2介入验证:调用医学规则库,检查是否有遗漏症状(如是否有呼吸困难、胸痛),排除“肺炎”等严重疾病;
- 系统1生成临时缓解方案:基于直觉匹配的“普通感冒”,快速提供“多喝水、休息”等建议;
- 系统2生成就医建议:结合用户年龄(如“65岁以上”)、基础病史(如“有糖尿病”),推理建议“24小时未退烧需就医”;
- 最终整合结果:将系统1的快速建议和系统2的推理结论整合,反馈给用户。
习题6:智能体的局限性分析
题干:
尽管大语言模型驱动的智能体系统展现出了强大的能力,但它们仍然存在诸多局限。请分析以下问题:
- 为什么智能体或智能体系统有时会产生"幻觉"(生成看似合理但实际错误的信息)?
- 在1.3节的案例中,我们设置了最大循环次数为5次。如果没有这个限制,智能体可能会陷入什么问题?
- 如何评估一个智能体的"智能"程度?仅使用准确率指标是否足够?
解答:
(1)智能体产生“幻觉”的原因
- 模型本身的局限性:LLM的训练数据是概率分布的映射,并非事实知识库,当遇到未见过的知识时,会基于概率生成看似合理但错误的内容;
- 上下文信息不足:智能体的决策依赖感知到的环境信息,若工具返回数据不完整或有误,会导致推理链断裂,进而产生幻觉;
- 提示工程缺陷:若提示词未明确“基于事实”“禁止编造”等约束,LLM可能为了“完成任务”而编造信息;
- 推理链过长:多步骤任务中,每一步的微小误差会累积,导致最终结果与事实偏离(如旅行助手误将“颐和园”说成“颐和宫”)。
(2)无最大循环次数限制的问题
- 无限循环:智能体可能陷入“思考-行动-观察-再思考”的死循环(如反复查询同一信息,因工具返回格式不变而无法推进);
- 资源耗尽:持续调用LLM和工具会导致API费用激增、计算资源耗尽,尤其是复杂任务中;
- 任务超时:无法在合理时间内完成任务,影响用户体验(如旅行规划助手循环100次后仍未生成方案);
- 决策漂移:循环过程中可能偏离初始目标(如从“推荐景点”漂移到“查询景点历史”)。
(3)智能体“智能”程度的评估的评估维度
- 仅用准确率不够,需多维度评估:
- 任务完成率:是否能在规定条件下(如时间、资源限制)完成目标;
- 灵活性:遇到未预设场景时,是否能调整策略而非崩溃;
- 效率:完成任务的步骤数、资源消耗(如API调用次数、耗时);
- 鲁棒性:面对噪声数据(如用户输入错误、工具返回异常)时的容错能力;
- 可解释性:决策过程是否可追溯,而非黑箱输出;
- 用户满意度:结果是否符合用户预期,是否需要人工修正。
- 举例:一个旅行助手的准确率可能很高(推荐景点正确),但如果需要10次工具调用才能完成,效率过低,不能算作“高智能”;反之,一个助手可能偶尔推荐错误(准确率略低),但能快速调整策略、处理用户特殊需求,整体智能程度更高。
四、总结
第一章作为Hello-Agents的基础篇,核心是搭建“智能体是什么、如何工作、如何构建”的认知框架。通过学习,我们理清了智能体的定义、类型和运行机制,更通过动手复现智能旅行助手代码理解了“感知-思考-行动”循环的落地逻辑,最后通过习题巩固了知识点的应用。
五、参考资料
DataWhale:Hello-Agent