Apache Flink CDC——变更数据捕获
Flink CDC
- 引言
- 一、简介
- 1.1、flink cdc介绍
- 1.2、cdc的种类
- 1.3、核心原理与架构
- 1.4、典型应用场景
- 1.5、支持的连接器
- 二、下载与相关依赖包
- 2.1、基础环境准备
- 2.1、下载 Apache Flink
- 2.2、下载Flink-cdc
- 二、数据实操
- 2.1、前置准备
- 2.1.1、开启mysql的binlog
- 2.1.2、为 Flink CDC 创建专门用户
- 2.1.3、确保数据库和 Flink 时区一致
- 2.1、Flink SQL(推荐)
- 2.1.1、需确保启动 Flink
- 2.1.2、编写flink-sql
- 2.1.2.1、MySQL 同步到 Doris的完整YML
- 2.1.2.2、Kafka 同步到 MySQL 完整 YAML
- 2.1.2.3、Kafka 同步到 Doris 完整 YAML
- 2.1.3、提交作业
- 2.1.4、确认Flink CDC 作业状态
- 2.2、Flink DataStream API
引言
在数据驱动的时代,企业对数据的实时性要求越来越高。传统的批处理数据集成方式(如每天凌晨执行 ETL 作业)已无法满足实时监控、实时分析、实时推荐等场景的需求。变更数据捕获 (Change Data Capture, CDC) 技术应运而生,它能够实时捕获数据库的变更(插入、更新、删除),是实现数据实时同步与集成的关键。Apache Flink CDC 并非一个独立的官方子项目,而是指 基于 Apache Flink 强大的流处理引擎构建的一套高效、可靠、低延迟的 CDC 解决方案集合。它已成为构建现代化实时数据管道和实时数仓的基石技术之一。
一、简介
1.1、flink cdc介绍
Apache Flink CDC 通过将强大的 Flink 流处理引擎与高效的 CDC 日志解析技术(如 Debezium)深度集成,提供了一套构建高性能、高可靠、低延迟实时数据管道的终极解决方案。它解决了传统数据集成方式在实时性、可靠性、复杂处理能力和架构简洁性上的诸多痛点。
其核心价值在于:
-
实时性: 秒级/毫秒级数据可见性。
-
可靠性: 端到端精确一次语义保障数据质量。
-
简化架构: “一站式” 完成捕获、处理、落地。
-
强大处理: 在数据流上实现复杂的实时 ETL 与计算。
-
生态融合: 无缝对接广泛的数据库源和多样化的目标系统。
随着企业对实时数据价值挖掘需求的日益迫切,Flink CDC 已成为构建现代数据基础设施(如实时数仓、数据湖、实时分析平台)不可或缺的关键技术。掌握 Flink CDC,意味着拥有了开启实时数据驱动业务大门的核心钥匙。
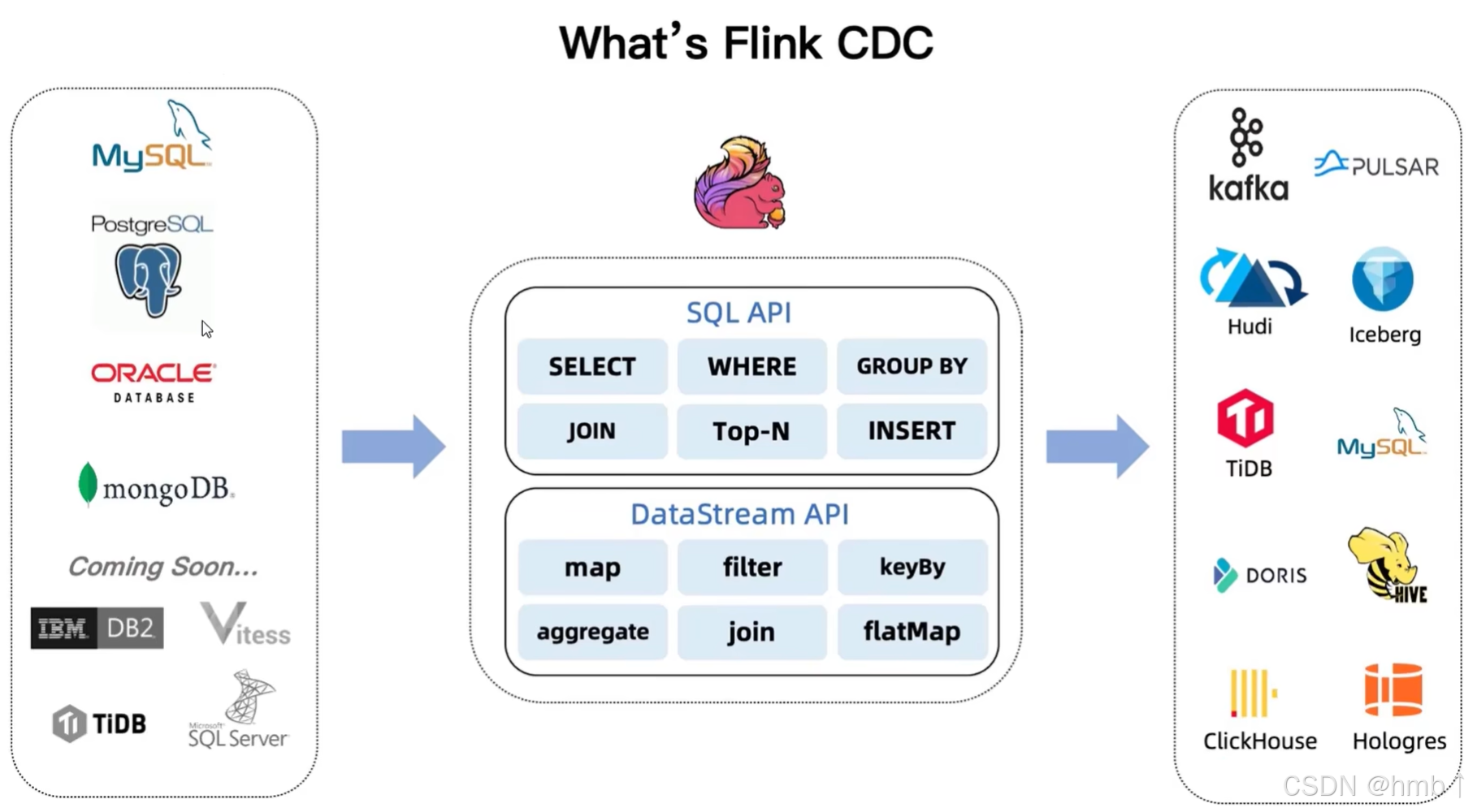
-
CDC (Change Data Capture变更数据捕获):
-
定义: 一种技术,用于识别和捕获源数据库(如 MySQL, PostgreSQL, Oracle, MongoDB 等)中发生的数据变更(INSERT, UPDATE, DELETE)。
-
目标: 实时或近实时地将这些变更事件流式传输到下游系统。
-
实现方式:
-
基于查询(轮询): 定期扫描表或特定列(如last_modified),效率低、延迟高、对源库压力大。
-
基于触发器: 在表上创建数据库触发器,在数据变更时触发动作。侵入性强(需改表结构),性能开销大,难以维护。
-
基于日志(最优): 直接读取数据库的事务日志(如 MySQL Binlog, PostgreSQL WAL, Oracle Redo Log, MongoDB Oplog)。这是最推荐的方式,因为它:
-
捕获所有变更。
-
延迟极低(接近实时)。
-
对源数据库侵入性最小(只读日志,不修改表结构或增加触发器)。
-
通常能提供变更前的数据(用于更新)和变更后的数据。
-
-
-
-
Apache Flink:
-
定义: 一个开源的、分布式的、高性能的流处理框架。
-
核心能力:
-
处理无界和有界数据流: 天然适合处理持续产生的 CDC 事件流。
-
精确一次(Exactly-Once)语义: 确保数据在流处理过程中不丢不重,是构建可靠数据管道的基石。
-
高吞吐、低延迟: 能够高效处理海量变更事件。
-
强大的状态管理: 支持大状态、容错的状态存储,使得在流上做复杂计算(如窗口聚合、流 Join)成为可能。
-
灵活的 API: 提供易用的 DataStream API (Java/Scala) 和声明式的 Table API / SQL。
-
丰富的连接器生态: 支持与各种数据源(Source)和数据汇(Sink)无缝集成。
-
-
1.2、cdc的种类
CDC 类型对比表(基于查询 vs. 基于 Binlog/日志)
| 对比维度 | 基于查询 (Query-Based CDC) | 基于 Binlog/日志 (Log-Based CDC) |
|---|---|---|
| 核心原理 | 定时轮询数据库表,通过 SQL 查询扫描增量数据(如按时间戳或自增 ID 过滤)。 | 直接读取数据库事务日志(如 MySQL Binlog、PostgreSQL WAL),实时解析变更事件。 |
| 执行模式 | 批处理 (Batch):周期性调度执行(如每分钟/小时)。 | 流处理 (Streaming):持续监听日志,事件触发实时处理。 |
| 实时性 | ⚠️ 低(依赖轮询间隔,延迟 = 调度周期)。 | ✅ 高(毫秒~秒级延迟,变更提交即捕获)。 |
| 对源库性能影响 | ⚠️ 高:频繁全表/范围扫描消耗大量 CPU 和 I/O 资源。 | ✅ 低:异步读取日志,对业务事务无干扰(只读操作)。 |
| 侵入性 | ✅ 低:只需读权限,不修改表结构。 | ✅ 低:仅需日志读取权限(如 MySQL 的 REPLICATION 权限)。 |
| 数据完整性 | ⚠️ 有限: - 难以捕获删除操作(需软删除); - 可能丢失中间状态更新。 | ✅ 完整: - 捕获所有增、删、改操作; - 提供变更前/后数据镜像。 |
| 事务一致性 | ⚠️ 弱:轮询间隔内多次更新仅捕获最终状态。 | ✅ 强:按事务提交顺序输出变更,保持原子性。 |
| 全量+增量支持 | ⚠️ 需自行实现:全量初始化与增量轮询逻辑分离。 | ✅ 原生支持:多数工具支持先全量快照后无缝切增量(如 Debezium、Flink CDC)。 |
| 典型架构 | 应用脚本 → 定时查询 → 写入目标系统 | 日志解析器 (e.g., Debezium) → 消息队列 (e.g., Kafka) → 流处理引擎 (e.g., Flink) → 目标系统 |
| 开源产品详解 | 无主流产品,常用方案: - 自定义 SQL 脚本 + Cron 调度; - Sqoop 增量导入(仍属批处理)。 - DataX | 1. Debezium: - 模式:独立服务或嵌入 Kafka Connect; - 支持库:MySQL, PG, Oracle, SQL Server 等; - 输出:结构化事件(JSON/Avro)。 2. Canal: - 模式:独立服务(Server+Client); - 专注 MySQL Binlog 解析; - 输出:ProtoBuf/JSON 到 MQ。 3. Maxwell: - 模式:轻量级独立进程; - 专注 MySQL,输出 JSON 到 Kafka/RabbitMQ。 4. Flink CDC: - 模式:嵌入 Flink Source Connector; - 基于 Debezium 增强,支持 SQL 处理流水线。 |
| 运维复杂度 | ✅ 低:逻辑简单,易调试。 | ⚠️ 中~高:需管理日志解析服务、消息队列、流处理作业,监控复杂度高。 |
| 适用场景 | - 低频增量同步(小时/天级); - 无删除操作的日志表同步; - 数据库不支持日志访问。 | - 实时数仓/数据湖入仓; - 微服务数据集成; - 数据库迁移; - 缓存更新、事件驱动架构。 |
| 局限 | ❌ 高延迟、高负载、无法捕获删除、数据一致性弱。 | ❌ 需开启数据库日志并授权;日志格式兼容性需验证(如 MySQL 8.x);复杂 DDL 变更处理需额外逻辑。 |
关键结论:
-
基于查询 CDC
- 仅适合非实时、低变更量场景
- 本质是批处理的妥协方案,不推荐用于核心生产链路。
-
基于 Binlog/日志 CDC
- 实时数据管道的黄金标准,主流开源产品生态成熟(Debezium/Flink CDC 为首选)。
- 需搭配流处理引擎(如 Flink)和消息队列(如 Kafka)构建完整架构。
- 选型建议:
- 需端到端流处理 → Flink CDC(一体化架构);
- 需解耦多消费者 → Debezium + Kafka(灵活扩展)。
1.3、核心原理与架构
Flink CDC 连接器的底层通常依赖于 Debezium 引擎。
-
获取快照:
-
当 Flink CDC 作业启动时,它首先会对源数据库执行一个 全量快照,将所有现有数据读取到 Flink 中。这确保了我们有完整的基线数据。
-
快照阶段支持并发读取,以加快速度。
-
-
增量读取 Binlog:
-
全量快照完成后,连接器会自动、无缝地切换到 增量读取 模式。
-
它连接到数据库的 Binlog(MySQL)或 WAL(PostgreSQL)等事务日志文件。
-
Debezium 引擎负责解析这些二进制日志,将其转换为统一的变更事件结构(包含 before、after、op 等字段)。
-
-
无锁读取:
- 现代 Flink CDC 连接器(如 MySQL-CDC 2.0+)实现了 无锁读取。在全量快照期间,它不会对源数据库加锁,避免了对线上业务的影响。
-
Exactly-Once 语义:
-
连接器会将读取的 Binlog 位置(如 LSN、GTID)作为状态保存在 Flink 检查点中。
-
当作业失败恢复时,Flink 会从上一个成功的检查点重启,并让 CDC Source 从对应的 Binlog 位置重新开始消费,从而保证了数据不丢不重。
-
1.4、典型应用场景
- 实时数据仓库与 ETL
将业务库(如 MySQL)的数据实时同步到数据仓库(如 ClickHouse、Doris)或数据湖(如 Hudi、Iceberg)。
- 微服务间数据同步
将一个服务的数据库变更实时同步到另一个服务的缓存(如 Redis)或搜索索引(如 Elasticsearch)中,用于构建 CQRS 架构。
- 物化视图
基于数据库的变更流,在 Flink 中构建实时的物化视图,进行复杂的多表关联和聚合计算。
- 审计与合规
实时捕获所有数据变更,用于审计、合规性检查或历史数据追踪。
- 异地多活/容灾备份
实现跨数据中心的数据库实时双向同步。
1.5、支持的连接器
CDC Source 连接器
| 连接器名称 | 标识符 | 数据源 | 核心功能 |
|---|---|---|---|
| MySQL CDC | mysql-cdc | MySQL | 直接解析 Binlog,支持无锁全量快照 + 增量流 |
| PostgreSQL CDC | postgres-cdc | PostgreSQL | 通过逻辑解码读取 WAL 日志 |
| MongoDB CDC | mongodb-cdc | MongoDB | 通过 Change Streams API 捕获变更 |
| Oracle CDC | oracle-cdc | Oracle | 通过 LogMiner 或 XStream API 读取 |
| SQL Server CDC | sqlserver-cdc | SQL Server | 利用内置 CDC 功能捕获变更 |
| TiDB CDC | tidb-cdc | TiDB | 兼容 MySQL 协议,类似 mysql-cdc |
| OceanBase CDC | oceanbase-cdc | OceanBase | 通过 liboblog 读取 Clog |
| Db2 CDC | db2-cdc | Db2 | 通过 Q-Replication 技术捕获变更 |
通用 Source 连接器
| 连接器名称 | 标识符 | 数据源 | 核心功能 |
|---|---|---|---|
| Kafka | kafka | Apache Kafka | 消费 Kafka 主题中的消息 |
| FileSystem | filesystem | 本地/HDFS/OSS/S3 | 读取文件系统中的文件 |
| RabbitMQ | rabbitmq | RabbitMQ | 消费 RabbitMQ 队列消息 |
| Pulsar | pulsar | Apache Pulsar | 消费 Pulsar 主题消息 |
| Kinesis | kinesis | AWS Kinesis | 消费 Kinesis 数据流 |
| HTTP | http | HTTP 接口 | 通过 HTTP 请求获取数据 |
二、下载与相关依赖包
2.1、基础环境准备
-
Java环境(JDK 8或11)
-
Flink 1.19.0
-
Flink CDC 3.3.0的连接器JAR包
-
数据库驱动(如MySQL连接器)
-
网络访问(确保端口8081可访问)
-
数据库配置(如MySQL的binlog等)
2.1、下载 Apache Flink
要先下载 Apache Flink!
Flink CDC 不是一个独立运行的程序,它是 基于 Apache Flink 构建的库/连接器。没有 Flink 引擎,Flink CDC 是无法运行的!
它们的关系:
-
Apache Flink:核心计算引擎(就像汽车的发动机)
-
Flink CDC:专门的数据采集插件(就像给发动机加的燃油系统)
下载链接: https://archive.apache.org/dist/flink/flink-1.19.0/flink-1.19.0-bin-scala_2.12.tgz
1、下载后解压:
# 解压
tar -xzf flink-1.19.0-bin-scala_2.12.tgz
2、设置环境变量
# 编辑系统配置文件
sudo vim /etc/profile# 在文件末尾添加:
export FLINK_HOME=/path/to/your/flink-1.19.0
export PATH=$FLINK_HOME/bin:$PATH# 保存后使配置生效
source /etc/profile
3、启动
# 进入 Flink 目录
cd /path/to/flink-1.19.0# 启动 Flink 集群
./bin/start-cluster.sh# 检查状态
./bin/flink list
4、访问webUI界面
http://localhost:8081/
2.2、下载Flink-cdc
链接: https://github.com/apache/flink-cdc/releases
包含flink-cdc和需要连接器依赖包,下面这些包要放在flink-cdc的lib目录下
-
Source Connector(源连接器)
功能:只能作为 Source,即从数据库捕获变更数据。
定位:这是 Flink CDC 的核心功能,专门用于拉取数据库的变更流。 -
Pipeline Connector(管道连接器)
功能:既能作为 Source,也能作为 Sink,是双向的。
定位:用于构建完整的数据管道,既可以从该数据源读,也可以向该数据源写。

二、数据实操
2.1、前置准备
2.1.1、开启mysql的binlog
vim /etc/my.cnf
添加以下内容
[mysqld]
server-id=1 # 设置一个唯一的服务器ID,避免冲突
log-bin=mysql-bin # 启用binlog,并指定日志文件的前缀
binlog-format=ROW # 设置binlog格式为ROW,ROW格式会记录每一条更改的SQL语句
expire_logs_days=10 # 设置binlog日志文件的过期时间为10天
重启MySQL服务
保存配置文件后,重启MySQL服务以使更改生效:
systemctl restart mysqld
确认是否开启成功
SHOW VARIABLES LIKE 'log_bin';
SHOW VARIABLES LIKE 'binlog_format';
SHOW VARIABLES LIKE 'server_id';
期望值:
| 变量名 | 期望值 |
|---|---|
| log_bin | ON |
| binlog_format | ROW |
| server_id | 非 0 的整数值 |
2.1.2、为 Flink CDC 创建专门用户
CREATE USER 'cdc_user'@'%' IDENTIFIED BY '你的密码';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'cdc_user'@'%';FLUSH PRIVILEGES;
2.1.3、确保数据库和 Flink 时区一致
3.1、检查 MySQL 时区
-- 查看 MySQL 全局和会话时区
SELECT @@global.time_zone, @@session.time_zone;-- 查看系统时区
SELECT @@system_time_zone;-- 查看当前时间
SELECT NOW(), UTC_TIMESTAMP();
3.2、检查 Flink 时区
# 在 Flink 所在服务器检查系统时区
date
timedatectl status# 检查 Java 默认时区(Flink 使用 JVM 时区)
java -XshowSettings:properties -version 2>&1 | grep user.timezone
3.3、修改 MySQL 配置文件 (/etc/my.cnf 或 /etc/mysql/my.cnf):
[mysqld]
default-time-zone = '+08:00'# 或者使用时区名称
# default-time-zone = 'Asia/Shanghai'
重启mysql
sudo systemctl restart mysql
3.4、配置 Flink 时区
在 $FLINK_HOME/conf/flink-conf.yaml中添加:
# 在 $FLINK_HOME/conf/flink-conf.yaml 中添加:# 设置作业管理器时区
env.java.opts.jobmanager: -Duser.timezone=Asia/Shanghai# 设置任务管理器时区
env.java.opts.taskmanager: -Duser.timezone=Asia/Shanghai# 设置 SQL 时区(Flink 1.13+)
table.local-time-zone: Asia/Shanghai# 或者使用 UTC 偏移量
# table.local-time-zone: +08:00
2.1、Flink SQL(推荐)
2.1.1、需确保启动 Flink
# 进入 Flink 目录
cd $FLINK_HOME# 启动 Flink 集群
./bin/start-cluster.sh
2.1.2、编写flink-sql
主要是要编写 源表(Source Table) - 数据来源 至 Sink 表(Sink Table) - 数据目的地 的yml
2.1.2.1、MySQL 同步到 Doris的完整YML
1、cdc需要的依赖,放在flink-cdc的lib目录下
flink-cdc-pipeline-connector-mysql-3.3.0.jar
flink-cdc-pipeline-connector-doris-3.3.0.jar
# MySQL JDBC 驱动(必须,用于 Doris 连接 MySQL 协议)
# 下载地址https://repo.maven.apache.org/maven2/mysql/mysql-connector-java/8.0.33/mysql-connector-java-8.0.33.jar
mysql-connector-java-8.0.33.jar
2、doris建表:
-- 在 Doris 中创建目标数据库和表
CREATE DATABASE IF NOT EXISTS ecommerce_analytics;CREATE TABLE IF NOT EXISTS ecommerce_analytics.products (product_id INT,product_name VARCHAR(255),product_price DECIMAL(10,2),product_category VARCHAR(100),product_status TINYINT,source_created_at DATETIME,source_updated_at DATETIME,sync_time DATETIME,batch_no VARCHAR(50)
) ENGINE=OLAP
DUPLICATE KEY(product_id)
DISTRIBUTED BY HASH(product_id) BUCKETS 10
PROPERTIES ("replication_num" = "1"
);
3、MySQL to Doris的yml示例
# ==================================================
# MySQL 同步到 Doris 完整配置
# 功能:将 MySQL 数据库的变更实时同步到 Doris
# 适用场景:数据仓库实时同步、OLAP 分析
# ==================================================# 管道基础配置
name: "MySQL to Doris Sync Pipeline" # 作业名称,在 Flink UI 中显示
type: "stream" # 作业类型:stream(流处理) 或 batch(批处理)
parallelism: 2 # 并行度,根据 CPU 核心数和数据量调整# ==================== 源表配置 (MySQL CDC) ====================
source:type: "mysql-cdc" # 源连接器类型:mysql-cdchostname: "localhost" # MySQL 服务器地址port: 3306 # MySQL 端口,默认 3306username: "flink_cdc_user" # MySQL 用户名(需要有 REPLICATION 权限)password: "your_password_123" # MySQL 密码# 数据库和表配置(二选一)# 方式一:指定具体数据库和表database-list: ["ecommerce", "user_center"] # 要同步的数据库列表table-list: ["ecommerce.products", "ecommerce.orders", "user_center.users"] # 要同步的完整表名(数据库.表名)# 方式二:使用正则表达式匹配(注释掉上面的 database-list 和 table-list)# database-include-list: "ecommerce|user_center" # 包含的数据库正则# table-include-list: "ecommerce\\.products|ecommerce\\.orders" # 包含的表正则# table-exclude-list: ".*_backup|.*_temp" # 排除的表正则(备份表、临时表等)server-id: "5400-5408" # MySQL CDC 客户端 ID,范围要唯一,避免与其他 CDC 客户端冲突server-time-zone: "Asia/Shanghai" # MySQL 服务器时区,必须与数据库时区一致# 启动模式配置startup-options: "initial" # initial: 先全量快照后增量 | earliest: 从最早binlog | latest: 从最新binlog# 快照配置(全量同步阶段)chunk-key:column: "id" # 用于数据分片的列,通常是主键scan:increment-snapshot:chunk-size: 5000 # 每个分片的数据量,影响内存使用和同步速度chunk-size-mb: 64 # 每个分片的最大大小(MB)# ==================== 目标表配置 (Doris) ====================
sink:type: "doris" # 目标连接器类型:dorisfenodes: "localhost:8030" # Doris FE 节点地址,多个用逗号分隔username: "root" # Doris 用户名password: "" # Doris 密码# 自动建表配置(如果目标表不存在,自动创建)table-create:enable: "true" # 是否启用自动建表properties:replication_num: "1" # 副本数,单机测试设为1,生产环境通常为3storage_format: "V2" # 存储格式:V1 或 V2(推荐V2)# 表映射配置(源表 -> 目标表)table-mapping:# 第一个表映射:商品表- source-table: "ecommerce.products" # 源表完整名称sink-table: "ecommerce_ods.products" # 目标表完整名称column-mapping: # 字段映射- source: "id" # 源表字段sink: "product_id" # 目标表字段- source: "name" sink: "product_name" - source: "price" sink: "product_price" - source: "category_id" sink: "category_id" - source: "created_at" sink: "create_time" - source: "updated_at" sink: "update_time" - source: "CURRENT_TIMESTAMP" # 使用 Flink 系统函数sink: "sync_time" # 同步时间(记录数据同步到 Doris 的时间)# 第二个表映射:订单表- source-table: "ecommerce.orders" sink-table: "ecommerce_ods.orders" column-mapping:- source: "id"sink: "order_id"- source: "user_id"sink: "user_id"- source: "total_amount"sink: "order_amount"- source: "status"sink: "order_status"- source: "created_at"sink: "create_time"# Doris 写入配置doris:sink:batch-size: 1000 # 批量写入大小,每批最多多少条记录batch-interval: "1s" # 批量写入间隔,达到时间或条数即写入max-retries: 3 # 写入失败重试次数label-prefix: "mysql_doris" # 导入任务标签前缀,用于唯一标识config:format: "json" # 数据传输格式:json 或 csvread_json_by_line: "true" # 每行一个 JSON 对象strip_outer_array: "true" # 去除外层数组# ==================== 管道处理配置 ====================
pipeline:name: "MySQL to Doris Sync" # 管道名称checkpoint:interval: "30s" # 检查点间隔,建议 30s-60stimeout: "10m" # 检查点超时时间mode: "EXACTLY_ONCE" # 语义:精确一次(EXACTLY_ONCE)或至少一次(AT_LEAST_ONCE)# 状态后端配置(存储计算状态)state:backend: "filesystem" # 状态后端类型:filesystem | rocksdb | heapcheckpoint-storage: "filesystem" # 检查点存储位置checkpoints-directory: "file:///tmp/flink-checkpoints/mysql-doris" # 检查点目录# 数据转换(可选 SQL 处理)transform:- type: "sql"query: |-- 数据清洗和转换示例-- 只同步有效的商品数据,并进行字段转换INSERT INTO ecommerce_ods.products SELECT id as product_id,TRIM(name) as product_name, -- 去除名称前后空格ROUND(price, 2) as product_price, -- 价格四舍五入到2位小数category_id,created_at as create_time,updated_at as update_time,CURRENT_TIMESTAMP as sync_timeFROM ecommerce.productsWHERE price > 0 -- 只同步价格大于0的商品AND status = 1 -- 只同步上架商品AND name IS NOT NULL -- 过滤名称为空的记录# ==================== 监控和指标配置 ====================
metrics:reporters:- type: "jmx" # JMX 监控,可用 JConsole 查看- type: "prometheus" # Prometheus 监控,用于 Grafana 展示port: 9249 # Prometheus 拉取端口enable-source-reader-metrics: "true" # 启用源读取器指标# ==================== 日志配置 ====================
logging:level: "INFO" # 日志级别:DEBUG | INFO | WARN | ERRORlog-consistency: "eventual" # 日志一致性:eventual 或 immediate# ==================== 容错配置 ====================
fault-tolerance:restart-strategy: # 重启策略type: "exponential-delay" # 指数退避重启initial-backoff: "5s" # 初始重启间隔max-backoff: "1m" # 最大重启间隔backoff-multiplier: 2 # 退避乘数reset-backoff-threshold: "10m" # 重置退避时间阈值
2.1.2.2、Kafka 同步到 MySQL 完整 YAML
需要的lib依赖
flink-cdc-pipeline-connector-kafka-3.3.0.jar
flink-cdc-pipeline-connector-jdbc-3.3.0.jar
mysql-connector-java-8.0.33.jar
# ==================================================
# Kafka 同步到 MySQL 完整配置
# 功能:将 Kafka 中的 JSON 消息实时同步到 MySQL
# 适用场景:事件数据入库、实时数据归档
# ==================================================name: "Kafka to MySQL Sync Pipeline"
type: "stream"
parallelism: 3 # 并行度,通常与 Kafka 分区数一致或为其倍数# ==================== 源表配置 (Kafka) ====================
source:type: "kafka" # 源连接器类型:kafkaproperties:bootstrap.servers: "localhost:9092" # Kafka 集群地址,多个用逗号分隔group.id: "flink-kafka-mysql-group" # 消费者组 ID,用于偏移量管理topic: "user-events" # Kafka 主题名称# 启动偏移量配置scan.startup.mode: "earliest-offset" # earliest-offset: 从最早 | latest-offset: 从最新 | timestamp: 从指定时间# 数据格式配置(JSON 格式)format: "json" # 数据格式:json | csv | avro | debezium-jsonjson.fail-on-missing-field: "false" # 字段缺失时是否失败json.ignore-parse-errors: "true" # 解析错误时是否忽略# 数据 Schema 定义(必须与 Kafka 消息结构匹配)schema:- name: "event_id" # 事件IDtype: "STRING" # 数据类型:STRING | INT | BIGINT | DOUBLE | TIMESTAMP 等- name: "user_id" type: "INT" - name: "event_type" type: "STRING" - name: "event_data" # 事件详细数据(JSON 字符串)type: "STRING" - name: "event_time" # 事件时间戳(毫秒)type: "BIGINT" - name: "device_info" # 设备信息(JSON 字符串)type: "STRING" # ==================== 目标表配置 (MySQL) ====================
sink:type: "jdbc" # 目标连接器类型:jdbcurl: "jdbc:mysql://localhost:3306/analytics" # JDBC 连接 URLusername: "analytics_user" # 数据库用户名password: "analytics_pwd_123" # 数据库密码table-name: "user_events" # 目标表名# 批量写入配置(提升写入性能)sink:buffer-flush:max-rows: 1000 # 每批最大记录数interval: "1s" # 批量写入间隔max-retries: 3 # 写入失败重试次数# 字段映射和转换column-mapping:- source: "event_id" # 直接映射sink: "event_id" - source: "user_id" sink: "user_id" - source: "event_type" sink: "event_type" - source: "event_data" sink: "event_data" - source: "FROM_UNIXTIME(event_time/1000)" # 时间戳转换:毫秒转 TIMESTAMPsink: "event_timestamp" - source: "device_info" sink: "device_info" - source: "CURRENT_TIMESTAMP" # 系统时间:记录处理时间sink: "process_time" # ==================== 数据转换和清洗 ====================
transform:- type: "sql"query: |-- 数据清洗和转换-- 过滤无效数据,进行字段标准化INSERT INTO analytics.user_eventsSELECT event_id,user_id,UPPER(TRIM(event_type)) as event_type, -- 事件类型转大写并去除空格event_data,FROM_UNIXTIME(event_time/1000) as event_timestamp, -- 时间戳转换-- 从 JSON 中提取设备类型JSON_VALUE(device_info, '$.device_type') as device_type,CURRENT_TIMESTAMP as process_timeFROM user_events_topicWHERE user_id IS NOT NULL -- 用户ID不能为空AND event_id IS NOT NULL -- 事件ID不能为空AND event_time > 1609459200000 -- 事件时间必须大于 2021-01-01(过滤历史测试数据)- type: "sql"query: |-- 自动建表语句(如果目标表不存在)-- 这个查询会在作业启动时执行,确保目标表存在CREATE TABLE IF NOT EXISTS analytics.user_events (event_id VARCHAR(50) PRIMARY KEY, -- 事件ID主键user_id INT, -- 用户IDevent_type VARCHAR(50), -- 事件类型event_data TEXT, -- 事件数据event_timestamp TIMESTAMP, -- 事件时间device_type VARCHAR(50), -- 设备类型process_time TIMESTAMP, -- 处理时间-- 索引配置(提升查询性能)INDEX idx_user_id (user_id),INDEX idx_event_time (event_timestamp),INDEX idx_event_type (event_type)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4# ==================== 管道配置 ====================
pipeline:name: "Kafka to MySQL Event Sync"checkpoint:interval: "20s" # 检查点间隔timeout: "5m" # 检查点超时时间mode: "EXACTLY_ONCE" # 精确一次语义# 状态后端配置state:backend: "rocksdb" # 使用 RocksDB,适合状态较大的场景checkpoint-storage: "filesystem" checkpoints-directory: "file:///tmp/flink-checkpoints/kafka-mysql"rocksdb:state.backend.rocksdb.memory.managed: "true" # 托管内存state.backend.rocksdb.memory.write-buffer-ratio: "0.5" # 写缓冲区比例# ==================== 错误处理配置 ====================
error-handling:strategy: "fail" # 错误处理策略:fail(失败) | ignore(忽略) | log(记录)dead-letter-queue:enable: "true" # 启用死信队列topic: "user-events-dlq" # 死信队列主题bootstrap.servers: "localhost:9092" # 死信队列 Kafka 地址# ==================== 监控配置 ====================
metrics:reporters:- type: "jmx" # JMX 监控- type: "prometheus" # Prometheus 监控port: 9250 # 监控端口# ==================== 资源限制 ====================
resources:taskmanager:memory:process.size: "2g" # TaskManager 进程内存managed.fraction: 0.7 # 托管内存比例jobmanager:memory:process.size: "1g" # JobManager 进程内存
2.1.2.3、Kafka 同步到 Doris 完整 YAML
需要的lib依赖
flink-cdc-pipeline-connector-kafka-3.3.0.jar
flink-cdc-pipeline-connector-doris-3.3.0.jar
mysql-connector-java-8.0.33.jar
# ==================================================
# Kafka 同步到 Doris 完整配置
# 功能:将 Kafka 实时数据流同步到 Doris 进行分析
# 适用场景:实时数据分析、用户行为分析、实时大屏
# ==================================================name: "Kafka to Doris Real-time Pipeline"
type: "stream"
parallelism: 4 # 并行度,建议与 Kafka 分区数匹配# ==================== 源表配置 (Kafka) ====================
source:type: "kafka"properties:# Kafka 集群配置(生产环境通常是多节点)bootstrap.servers: "kafka-broker1:9092,kafka-broker2:9092,kafka-broker3:9092"group.id: "flink-kafka-doris-group" # 消费者组 IDauto.offset.reset: "latest" # 偏移量重置策略:latest | earliest | none# 主题配置(支持多主题)topic: ["clickstream-events", # 点击流事件"purchase-events", # 购买事件"user-behavior-events" # 用户行为事件]# 或者使用正则表达式匹配主题(多主题时更方便)# topic-pattern: ".*-events" # 匹配所有以 -events 结尾的主题scan.startup.mode: "latest-offset" # 从最新偏移量开始消费# 数据格式配置format: "json"json.ignore-parse-errors: "true" # 忽略 JSON 解析错误json.timestamp-format.standard: "ISO-8601" # 时间戳格式标准# 数据 Schema 定义(必须与 Kafka 消息结构一致)schema:- name: "event_id" # 事件唯一标识type: "STRING"- name: "user_id" # 用户IDtype: "BIGINT"- name: "session_id" # 会话IDtype: "STRING"- name: "event_type" # 事件类型:click、view、purchase 等type: "STRING"- name: "page_url" # 页面URLtype: "STRING"- name: "referrer" # 来源页面type: "STRING"- name: "ip_address" # IP地址type: "STRING"- name: "user_agent" # 用户代理(浏览器信息)type: "STRING"- name: "event_timestamp" # 事件时间戳type: "TIMESTAMP(3)" # 精确到毫秒的时间戳- name: "properties" # 事件属性(JSON 格式扩展字段)type: "STRING"# ==================== 目标表配置 (Doris) ====================
sink:type: "doris"fenodes: "doris-fe:8030" # Doris FE 节点username: "flink_user" # Doris 用户名password: "doris_pwd_123" # Doris 密码# 多表映射配置(不同主题映射到不同 Doris 表)table-mapping:# 点击流事件 -> 点击流表- source-table: "clickstream-events"sink-table: "dws.clickstream_events"column-mapping:- source: "event_id"sink: "event_id"- source: "user_id"sink: "user_id"- source: "session_id"sink: "session_id"- source: "event_type"sink: "event_type"- source: "page_url"sink: "page_url"- source: "referrer"sink: "referrer_url"- source: "ip_address"sink: "client_ip"- source: "user_agent"sink: "user_agent"- source: "event_timestamp"sink: "event_time"- source: "properties"sink: "event_properties"- source: "CURRENT_TIMESTAMP"sink: "process_time"# 购买事件 -> 购买事件表- source-table: "purchase-events"sink-table: "dws.purchase_events"column-mapping:- source: "event_id"sink: "event_id"- source: "user_id"sink: "user_id"- source: "order_id"sink: "order_id"- source: "product_id"sink: "product_id"- source: "amount"sink: "purchase_amount"- source: "event_timestamp"sink: "purchase_time"- source: "CURRENT_TIMESTAMP"sink: "process_time"# Doris 高级配置doris:sink:batch-size: 2000 # 批量大小batch-interval: "2s" # 批量间隔max-retries: 5 # 最大重试次数label-prefix: "kafka_doris" # 导入标签前缀config:format: "json" # 数据格式read_json_by_line: "true" # 逐行读取 JSONstrip_outer_array: "true" # 去除外层数组table-create:enable: "true" # 启用自动建表properties:replication_num: "3" # 副本数(生产环境建议3)storage_format: "V2" # 存储格式 V2compression: "LZ4" # 压缩算法:LZ4 | SNAPPY | ZSTD# ==================== 数据转换和聚合 ====================
transform:- type: "sql"query: |-- 数据清洗和标准化处理INSERT INTO dws.clickstream_eventsSELECT event_id,user_id,session_id,UPPER(event_type) as event_type, -- 事件类型统一大写page_url,referrer as referrer_url,ip_address as client_ip,user_agent,event_timestamp as event_time,properties as event_properties,CURRENT_TIMESTAMP as process_timeFROM clickstream_events_topicWHERE user_id IS NOT NULL -- 过滤无用户ID的事件AND event_timestamp > TIMESTAMP '2024-01-01 00:00:00' -- 过滤历史测试数据AND page_url IS NOT NULL -- 过滤无页面URL的事件- type: "sql"query: |-- 实时聚合:每5分钟统计用户行为(用于实时大屏)INSERT INTO dws.user_behavior_aggSELECT user_id,TUMBLE_START(event_timestamp, INTERVAL '5' MINUTE) as window_start, -- 窗口开始时间TUMBLE_END(event_timestamp, INTERVAL '5' MINUTE) as window_end, -- 窗口结束时间COUNT(*) as total_events, -- 总事件数COUNT(DISTINCT session_id) as session_count, -- 会话数COUNT(DISTINCT event_type) as event_type_count, -- 事件类型数MAX(event_timestamp) as last_event_time, -- 最后事件时间CURRENT_TIMESTAMP as process_time -- 处理时间FROM clickstream_events_topicGROUP BY user_id,TUMBLE(event_timestamp, INTERVAL '5' MINUTE) -- 5分钟滚动窗口# ==================== 管道配置 ====================
pipeline:name: "Kafka to Doris Real-time Analytics"checkpoint:interval: "30s" # 检查点间隔timeout: "10m" # 检查点超时mode: "EXACTLY_ONCE" # 精确一次语义unaligned: "true" # 启用非对齐检查点(性能优化)# 状态后端配置(生产环境推荐 RocksDB)state:backend: "rocksdb"checkpoint-storage: "filesystem"checkpoints-directory: "hdfs:///flink/checkpoints/kafka-doris" # 生产环境建议用 HDFSsavepoints-directory: "hdfs:///flink/savepoints" # 保存点目录rocksdb:state.backend.rocksdb.memory.managed: "true" # 托管内存state.backend.rocksdb.writebuffer.size: "64MB" # 写缓冲区大小state.backend.rocksdb.block.cache-size: "256MB" # 块缓存大小# ==================== 容错和重启策略 ====================
restart-strategy:type: "exponential-delay" # 指数退避重启策略initial-backoff: "5s" # 初始重启间隔max-backoff: "1m" # 最大重启间隔backoff-multiplier: 2 # 退避乘数reset-backoff-threshold: "5m" # 重置退避阈值# ==================== 监控和告警配置 ====================
metrics:reporters:- type: "prometheus" # Prometheus 监控port: 9251 # 监控端口interval: "15s" # 指标收集间隔- type: "slf4j" # 日志输出interval: "1m" # 日志输出间隔enable-system-metrics: "true" # 启用系统指标# 自定义告警规则
alert:rules:- metric: "source_kafka_lag" # Kafka 消费延迟指标operator: ">" # 操作符:大于threshold: 10000 # 阈值:10000 条action: "log" # 动作:记录日志- metric: "sink_doris_failure_rate" # Doris 写入失败率operator: ">" threshold: 0.05 # 阈值:5%action: "email" # 动作:发送邮件# ==================== 资源配置(生产环境重要) ====================
resources:taskmanager:memory:process.size: "2g" # TaskManager 进程内存managed.fraction: 0.7 # 托管内存比例(用于 RocksDB)jobmanager:memory:process.size: "1g" # JobManager 进程内存# ==================== 日志配置 ====================
logging:level: "INFO" # 日志级别log-file: "/var/log/flink/kafka-doris-pipeline.log" # 日志文件路径# ==================== 高级特性配置 ====================
features:- name: "watermark-alignment" # Watermark 对齐(多源同步时重要)enabled: true- name: "idle-source-prevention" # 防止源空闲enabled: truetimeout: "5m"
2.1.3、提交作业
# 1. 修改配置文件中连接信息
# - 数据库地址、用户名、密码
# - Kafka 地址、主题名
# - Doris FE 地址# 2. 根据数据量调整并行度
# - 小数据量:parallelism: 1-2
# - 中等数据量:parallelism: 2-4
# - 大数据量:parallelism: 4-8# 3. 提交作业
# 进入 Flink CDC 目录
cd /path/to/flink-cdc# 提交 MySQL 到 Doris 作业
./bin/flink-cdc.sh /path/to/mysql-to-doris.yaml# 提交 Kafka 到 MySQL 作业
./bin/flink-cdc.sh /path/to/kafka-to-mysql.yaml# 提交 Kafka 到 Doris 作业
./bin/flink-cdc.sh /path/to/kafka-to-doris.yaml# 4. 监控作业状态
./bin/flink-cdc.sh list# 5.查看特定作业详情
./bin/flink-cdc.sh describe <job-id># 6.停止作业
./bin/flink-cdc.sh stop <job-id>
2.1.4、确认Flink CDC 作业状态
你可以通过以下方式确认任务是否在同步:
- 查看 Flink 作业状态
通过 Flink Web UI(默认 http://localhost:8081)查看作业是否处于 RUNNING 状态。
在作业的 Task Managers 中查看日志,是否有错误信息。
- 查看数据同步情况
目标端查询:在目标数据库(如 Doris)中查询是否已经有数据同步过来。
监控指标:在 Flink Web UI 中可以看到数据输入的记录数和数据输出的记录数。
- 日志查看
查看 TaskManager 的日志文件,通常位于 $FLINK_HOME/log/ 目录下,看是否有异常堆栈信息。
- 测试数据变更
在源数据库(如 MySQL)中插入、更新或删除一条数据,然后在目标端查看是否很快就能看到相应的变更。
2.2、Flink DataStream API
1、引入依赖
<properties><flink.version>1.17.1</flink.version><flink-cdc.version>3.3.0</flink-cdc.version>
</properties><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>${flink.version}</version></dependency><!-- Flink CDC 3.3.0 依赖 --><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>${flink-cdc.version}</version></dependency><!-- MySQL 驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.33</version></dependency>
2、代码
public class FlinkCDC_DataStream {public static void main1(String[] args) throws Exception {// TODO 1. 准备流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// TODO 2. 开启检查点 Flink-CDC将读取binlog的位置信息以状态的方式保存在CK,如果想要做到断点续传,// 需要从Checkpoint或者Savepoint启动程序// 2.1 开启Checkpoint,每隔5秒钟做一次CK ,并指定CK的一致性语义env.enableCheckpointing(3000L, CheckpointingMode.EXACTLY_ONCE);// 2.2 设置超时时间为 1 分钟env.getCheckpointConfig().setCheckpointTimeout(60 * 1000L);// 2.3 设置两次重启的最小时间间隔env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000L);// 2.4 设置任务关闭的时候保留最后一次 CK 数据env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 2.5 指定从 CK 自动重启策略env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.days(1L), Time.minutes(1L)));// 2.6 设置状态后端env.setStateBackend(new HashMapStateBackend());env.getCheckpointConfig().setCheckpointStorage("file://D:\\Flink\\CheckPointStorge");// TODO 3. 创建 Flink-MySQL-CDC 的 SourceMySqlSource<String> mySqlSource = MySqlSource.<String>builder().hostname("localhost").port(3306).databaseList("app_db") // set captured database.tableList("app_db.orders") // set captured table.username("root").password("root").deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String// 指定从那个地方开始获取.startupOptions(StartupOptions.initial()).build();// TODO 4.使用CDC Source从MySQL读取数据DataStreamSource<String> mysqlDS =env.fromSource(mySqlSource,WatermarkStrategy.noWatermarks(),"MysqlSource");// TODO 5.打印输出mysqlDS.print();// TODO 6.执行任务env.execute();}
}
会实时捕获数据库的操作并打印在控制台

输出数据结构
{"before": null, // 修改前数据"after": { // 修改后数据"id": 4,"price": "1","productName": "5"},"source": { // 数据源,包含链接类型,对应数据库名称以及表名称"version": "1.9.8.Final","connector": "mysql","name": "mysql_binlog_source","ts_ms": 0,"snapshot": "false","db": "app_db","sequence": null,"table": "orders","server_id": 0,"gtid": null,"file": "","pos": 0,"row": 0,"thread": null,"query": null},"op": "r", // 操作类型"ts_ms": 1752647776802,"transaction": null
}
op 值与操作类型对照表
| op 值 | 含义 | 说明 |
|---|---|---|
| “c” | Create | 新增记录(INSERT),before 为 null,after 包含新数据。 |
| “u” | Update | 更新记录(UPDATE),before 包含旧数据,after 包含新数据。 |
| “d” | Delete | 删除记录(DELETE),after 为 null,before 包含被删除数据。 |
| “r” | Read | 读取快照阶段记录(仅初始快照阶段出现,增量阶段不出现)。 |
| “t” | Truncate | 表截断操作(TRUNCATE TABLE),before 和 after 均为 null。 |
| “m” | Metadata | 表结构变更(如 ALTER TABLE),用于 Schema 演变。 |