构建AI智能体:八十八、大模型编辑:从一本百科全书到可修订的活页本
一、前言
作为最前沿的开发者和体验者,我们也陆续对大模型有了更进一步的理解,不知道大家有没有遇到,当我们将这些强大的模型部署到实际业务场景时,也会面对一些很棘手的问题:传统大模型如同刻在石板上的百科全书,一旦训练完成,其知识体系便固化为静态存在。这种固有的局限性在快速变化的商业环境中尤为突出,产品信息更新、组织架构调整、市场策略转变,乃至法规政策修订,都要求模型能够实时适应变化,更棘手的是,模型可能存在的事实性错误、固有偏见或安全漏洞,若不能及时修正,将在实际应用中造成不可预估的风险。
在大模型落地应用过程中,知识过时和事实错误是亟待解决的痛点,我们也探讨过微调技术,传统微调虽能更新知识,但存在三大局限:
- 一是成本高昂,全参数训练消耗大量计算资源;
- 二是破坏性更新,易导致灾难性遗忘,影响模型原有能力;
- 三是效率低下,无法满足实时修正需求。
相比之下,大模型编辑技术无需耗费巨大的计算资源和时间成本,实现了外科手术式的精准干预,仅修改特定知识对应的神经元权重,在秒级完成知识更新,同时保持模型其他能力不受影响。这种参数高效的方法既能快速修正错误事实、更新时效信息,又能个性化定制知识,为生产环境中的大模型持续优化提供了切实可行的技术路径。在实际应用中,无论是金融行业对合规要求的即时响应、电商平台对产品信息的实时更新,还是客服系统对政策变化的快速适应,模型编辑都展现出巨大的实用价值。

二、什么是大模型编辑
通俗的理解,我们可以将传统的大模型视为一本印刷精美的、但出版后便无法更改的百科全书。一旦印刷完成,其中的所有知识就固定了。若要更新,唯一的办法是收集新数据,耗费巨量的计算资源重新印刷一版,相当于重新进行全量预训练或微调,这显然是低效且不切实际的。
因此,大模型编辑技术应运而生。它旨在像我们使用笔和便利贴修订一本活页书一样,能够快速、精准地对模型中的特定知识进行增加、删除或修改,而无需触动模型的其余部分。这使“百科全书”变成了一个可随时修订的活页本。
大模型编辑是一系列技术的总称,其目标是对一个已训练好的大模型进行局部、精确且高效的更新,以改变其对特定事实或行为的响应,同时最大限度地保留其在其他方面的原有能力。
核心目标:
- 有效性: 编辑后,模型对相关查询能给出新的、正确的答案。
- 泛化性: 编辑后的知识能推广到相关的、但表述不同的查询上。
- 局部性: 编辑不应影响模型与目标知识无关的其他知识和能力。
- 效率: 编辑过程应快速且计算成本低。
与传统微调的对比:
- 全参数微调: 如同为了修改书中的一句话而重写整本书,成本高昂且可能导致灾难性遗忘。
- 大模型编辑: 如同在书的特定页面上贴一张修正贴,精准、快速且不影响其他页面。
三、大模型编辑方法
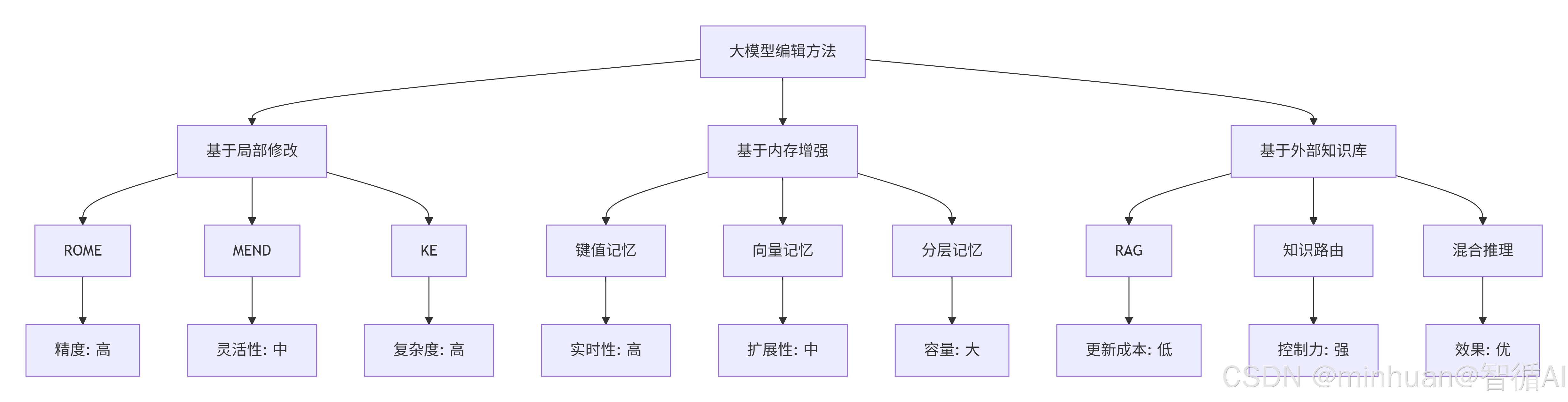
1. 基于局部修改的方法
核心思想:
直接修改模型中存储特定知识的局部参数,实现精准的知识更新。
详细流程:
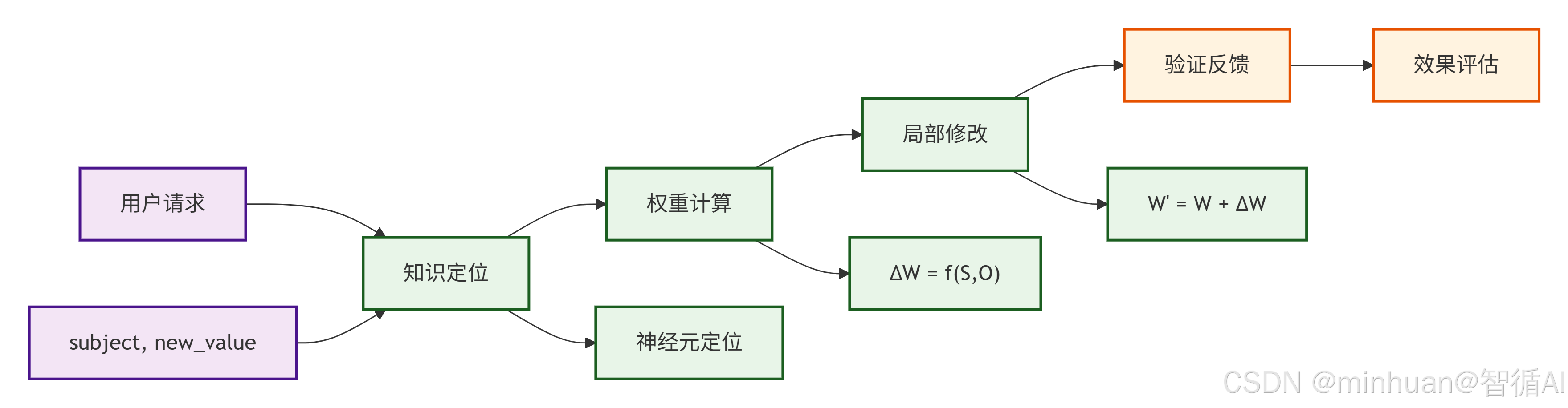
流程说明:
- 1. 用户请求
- 输入: (subject, new_value)
- 示例: ("苹果公司的CEO", "张伟")
- 功能: 接收编辑指令,明确要修改的知识主题和新值
- 2. 知识定位
- 过程:神经元定位
- 技术:因果追踪分析、激活模式识别、关键层识别
- 输出: 存储目标知识的特定神经元位置
- 3. 权重计算
- 公式: ΔW = f(S, O)
- S: Subject (主题)
- O: Objective (目标)
- 方法:
- ROME: 解权重更新方程
- MEND: 梯度分解优化
- KE: 直接权重调整
- 公式: ΔW = f(S, O)
- 4. 局部修改
- 操作: W' = W + ΔW
- 范围: 只修改定位到的特定神经元权重
- 特点: 参数高效,不影响其他知识
- 5. 验证反馈
- 评估内容:编辑准确性、副作用检测、泛化能力测试
- 反馈机制:根据验证结果调整编辑策略
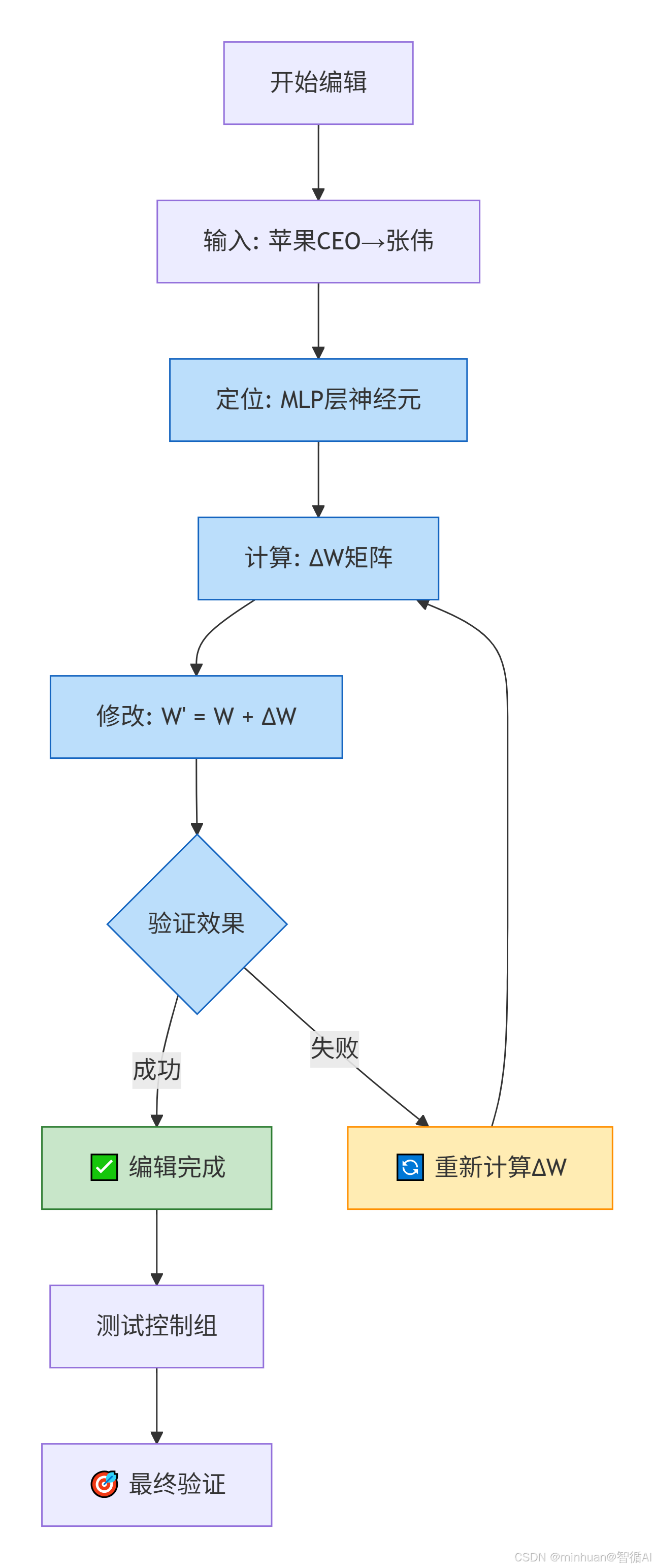
完整的工作流示例:
2. 基于内存增强的方法
核心思想:
为模型添加外部记忆模块,将编辑的知识存储在可单独更新的记忆中。
详细流程:
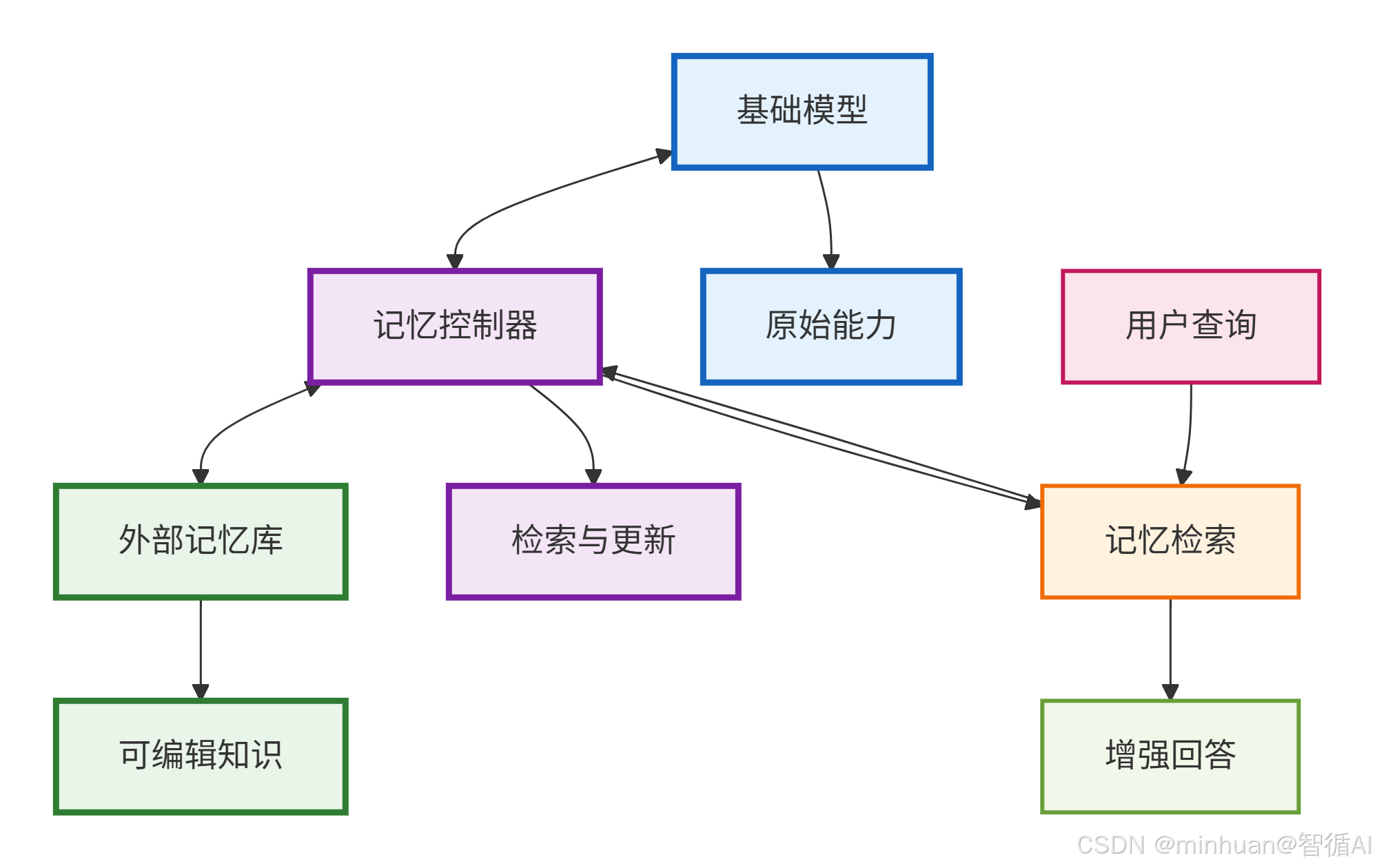
主要节点说明:
- 基础模型
- 功能: 提供原始的语言理解和生成能力
- 特点: 权重固定,不直接修改
- 输出: 基础的语言模型响应
- 记忆控制器
- 检索: 根据用户查询从记忆库中查找相关知识
- 更新: 管理记忆库的增删改操作
- 融合: 结合基础模型和记忆知识生成回答
- 技术实现:向量相似度检索、注意力机制融合、缓存管理策略
- 外部记忆库
- 存储内容:编辑后的知识事实、时效性信息、个性化数据
- 结构类型:键值对存储、向量数据库、图数据库
- 特点: 可独立更新,不影响基础模型
流程说明:
- 步骤1: 用户查询输入
- [用户查询] → [记忆检索]
- 用户提出问题或请求
- 系统接收查询并启动处理流程
- 步骤2: 记忆检索执行
- [记忆控制器] → [记忆检索] → [增强回答]
- 记忆控制器分析查询意图
- 从外部记忆库中检索相关知识片段
- 计算查询与记忆的相关性得分
- 步骤3: 回答生成与增强
- [记忆检索] → [增强回答]
- 无相关记忆: 直接使用基础模型生成回答
- 有相关记忆:
- 将记忆信息作为上下文提供给基础模型
- 基础模型基于增强的上下文生成更准确的回答
- 回答中融合了记忆库中的最新知识
记忆检索的详细流程:
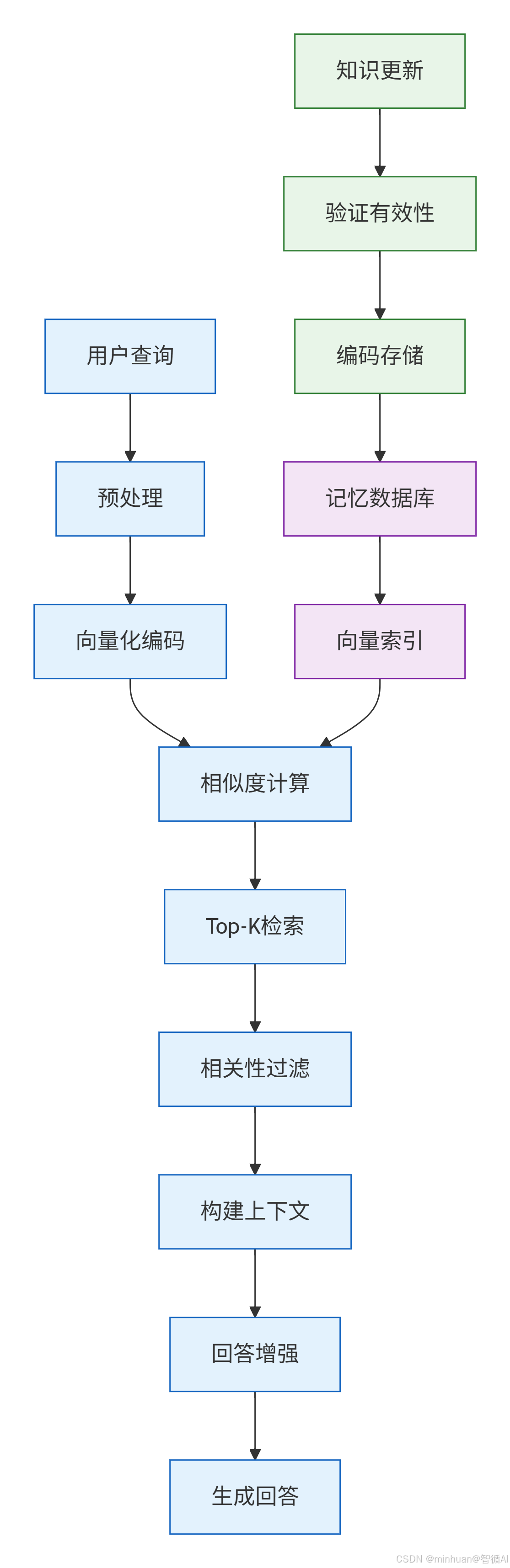
记忆检索流程说明:
- 1. 用户查询处理阶段
- 用户查询 → 预处理 → 向量化编码
- 用户查询: 接收原始问题输入
- 预处理: 清洗、分词、标准化文本
- 向量化编码: 将文本转换为数值向量表示
- 2. 记忆检索阶段
- 向量化编码 → 相似度计算 ← 向量索引 ← 记忆数据库
- 记忆数据库: 存储所有编辑后的知识
- 向量索引: 建立快速检索的数据结构
- 相似度计算: 比较查询向量与记忆向量的相似度
- 3. 结果处理阶段
- 相似度计算 → Top-K检索 → 相关性过滤 → 构建上下文
- Top-K检索: 返回最相似的K个记忆项
- 相关性过滤: 过滤掉低质量或无关的记忆
- 构建上下文: 将相关记忆组织成模型可理解的格式
- 4. 回答生成阶段
- 构建上下文 → 回答增强 → 生成回答
- 回答增强: 结合记忆上下文增强基础模型能力
- 生成回答: 输出融合了记忆知识的最终回答
- 5. 记忆更新阶段
- 知识更新 → 验证有效性 → 编码存储 → 记忆数据库
- 知识更新: 接收新的编辑知识
- 验证有效性: 检查知识的正确性和格式
- 编码存储: 将知识转换为向量并存入数据库
完整工作流程:

3. 基于外部知识库的方法
核心思想:
不修改模型内部参数,通过外部知识库和检索机制提供更新的知识。
详细流程:
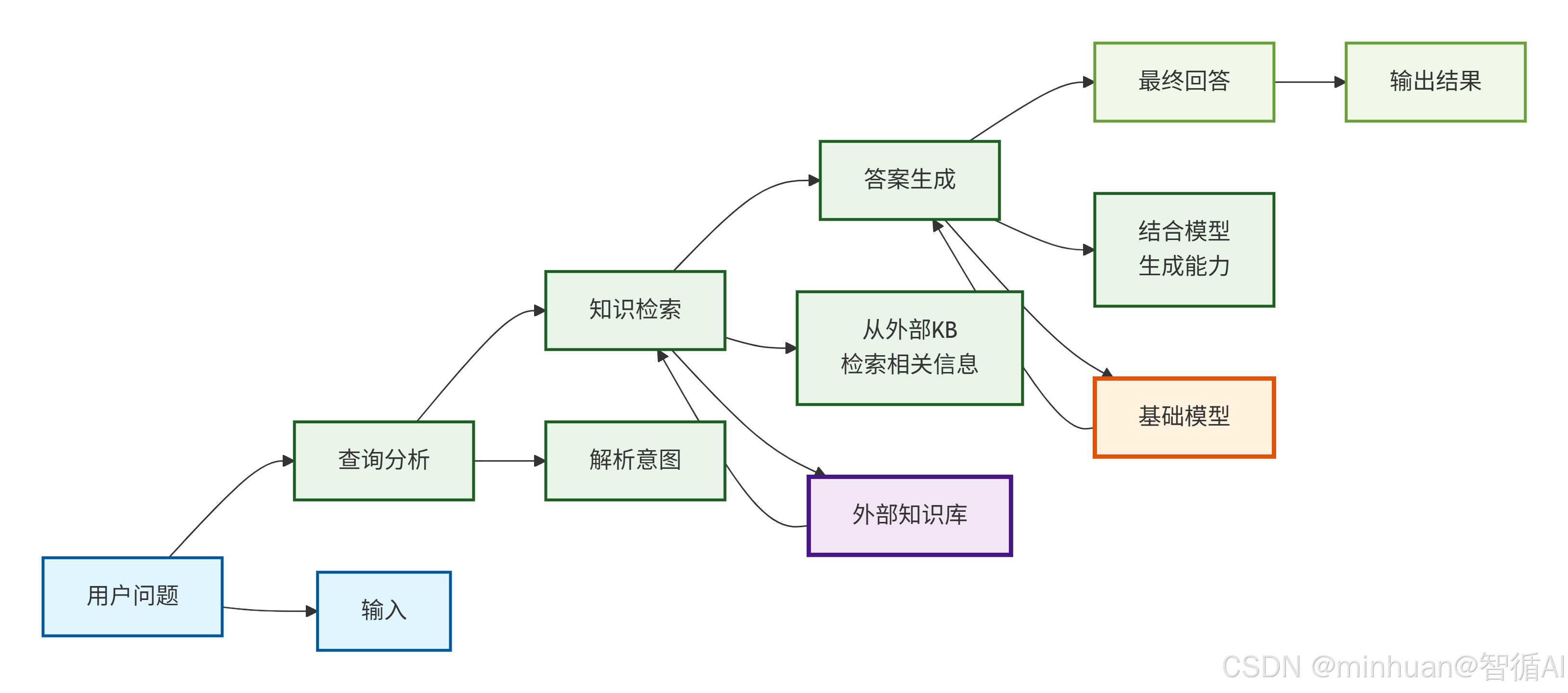
流程说明:
- 1. 用户问题/输入 → 查询分析/解析意图
- 输入: 接收原始用户问题
- 解析意图:
- 问题分类(事实查询、推理、建议等)
- 关键实体识别
- 查询重写和标准化
- 多语言处理
- 2. 查询分析 → 知识检索
- 从外部检索相关信息:
- 生成检索查询、多路检索策略、相关性评分、结果去重和排序
- 外部知识库
- 结构化数据(数据库、知识图谱)
- 非结构化文档(文档、网页)
- 实时数据源(API、流数据)
- 用户生成内容(评论、反馈)
- 从外部检索相关信息:
- 3. 知识检索 → 答案生成
- 结合模型生成能力:
- 知识片段选择和组织、上下文构建、提示工程优化、多源信息融合
- 结合模型生成能力:
- 4. 答案生成 → 最终回答
- 输出结果:
- 答案格式化和美化、引用来源标注、置信度显示、后续建议提供
- 输出结果:
4. 综合对比
应用场景推荐:
- 基于局部修改方法适用场景:
- 精准事实修正:CEO变更、产品信息更新
- 研究实验:模型知识结构分析
- 小规模编辑:单个或少量知识更新
- 基于内存增强方法适用场景:
- 中等规模编辑:企业知识库更新
- 实时性要求高:需要快速生效的编辑
- 保持模型完整性:不希望修改原始权重
- 基于外部知识库方法适用场景:
- 大规模知识管理:百科全书式知识更新
- 生产环境部署:需要稳定可靠的系统
- 多源知识整合:结合多个知识源
四、示例:基于知识库覆盖法的编辑实现
基于外部知识库覆盖的对Qwen1.5-0.5B编辑实现,通过智能路由机制实现知识更新。系统在初始化后建立可编辑的知识库,当用户提问时,首先检查知识库中是否有匹配的预设答案,如有则直接返回编辑后的知识,否则调用基础模型生成回答。
这种方法实现了即时生效的知识编辑,无需重新训练模型,保持了原有模型的完整性和其他知识能力,同时通过明确的来源标识区分编辑内容和原始模型输出,确保了系统的可解释性和可控性。
import torch
from modelscope import AutoModelForCausalLM, AutoTokenizer, snapshot_downloadclass SimpleModelEditor:def __init__(self, model_name="qwen/Qwen1.5-0.5B"):"""初始化模型编辑器"""cache_dir = "D:\\modelscope\\hub"local_model_path = snapshot_download(model_name, cache_dir=cache_dir)self.device = "cuda" if torch.cuda.is_available() else "cpu"self.tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)if self.tokenizer.pad_token is None:self.tokenizer.pad_token = self.tokenizer.eos_tokenself.model = AutoModelForCausalLM.from_pretrained(local_model_path,trust_remote_code=True,torch_dtype=torch.float16,device_map="auto")self.model.eval()# 知识库:存储编辑后的知识self.knowledge_base = {}print(" 模型编辑器初始化完成")def edit_knowledge(self, subject, new_answer):"""编辑知识:将新知识存入知识库"""print(f" 编辑知识: {subject} → {new_answer}")self.knowledge_base[subject] = new_answerreturn Truedef ask_question(self, question):"""回答问题:结合知识库和模型生成"""# 1. 检查知识库中是否有匹配的答案answer = self._check_knowledge_base(question)if answer:return f" {answer} [来自知识库]"# 2. 如果没有匹配,使用模型生成答案return self._generate_with_model(question)def _check_knowledge_base(self, question):"""检查知识库中的匹配答案"""question_lower = question.lower()# 简单匹配规则for subject, answer in self.knowledge_base.items():subject_lower = subject.lower()# 直接包含主题词if subject_lower in question_lower:return answer# 关键词匹配if "ceo" in question_lower and "ceo" in subject_lower:company = subject.split('的')[0]if company in question_lower:return answerif "首都" in question_lower and "首都" in subject_lower:country = subject.split('的')[0] if country in question_lower:return answerreturn Nonedef _generate_with_model(self, question):"""使用模型生成答案"""inputs = self.tokenizer(question, return_tensors="pt").to(self.device)with torch.no_grad():outputs = self.model.generate(**inputs,max_new_tokens=100,do_sample=True,temperature=0.7,pad_token_id=self.tokenizer.eos_token_id)response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)if question in response:response = response.replace(question, "").strip()return f" {response} [来自模型]"def demo_editing_process(self):"""演示完整的编辑过程"""print("\n" + "="*60)print(" 大模型编辑系统演示")print("="*60)# 初始状态测试print("\n1. 初始状态测试")initial_questions = ["苹果公司的CEO是谁?","特斯拉的CEO是谁?", "中国的首都是哪里?"]for q in initial_questions:answer = self.ask_question(q)print(f" {q}")print(f" {answer}\n")# 执行知识编辑print("\n2. 执行知识编辑")edits = [("苹果公司的CEO", "张伟"),("特斯拉的CEO", "李强"), ("中国的首都", "南京")]for subject, answer in edits:self.edit_knowledge(subject, answer)# 编辑后测试print("\n3. 编辑后效果验证")test_questions = ["苹果公司的CEO是谁?","特斯拉的CEO是谁?","中国的首都是哪里?","谁在领导苹果公司?", "特斯拉的负责人是谁?","中国首都是哪座城市?","太阳系有多少颗行星?" # 不相关的问题]for q in test_questions:answer = self.ask_question(q)print(f" {q}")print(f" {answer}\n")# 显示知识库状态print("\n4. 当前知识库内容")for subject, answer in self.knowledge_base.items():print(f" {subject} → {answer}")# 运行演示
if __name__ == "__main__":editor = SimpleModelEditor()editor.demo_editing_process()编辑过程:
- 知识库存储:将编辑后的知识存储在内存字典中
- 智能匹配:基于关键词和语义的简单匹配
- 模型兜底:未匹配时使用原始模型生成
执行流程:
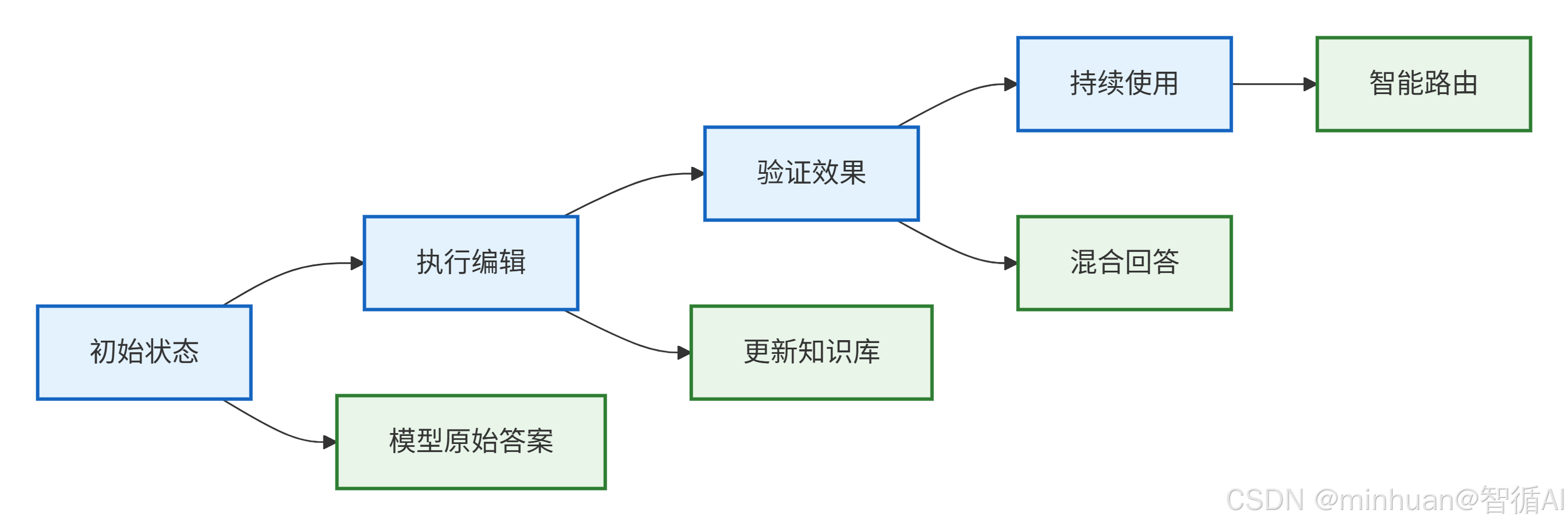
- 1. 初始状态
- 模型原始答案: 基于训练数据的固有知识
- 特点: 知识可能过时或不准确
- 示例: "苹果公司的CEO是蒂姆·库克"
- 2. 执行编辑
- 更新知识库: 将新知识存入编辑系统
- 操作: 添加、修改或删除特定知识
- 示例: 更新"苹果公司的CEO为张伟"
- 3. 验证效果
- 混合回答: 结合编辑知识和模型能力的回答
- 验证内容: 编辑准确性检查、副作用检测、泛化能力测试
- 输出: 确认编辑效果的质量
- 4. 持续使用
- 智能路由: 根据查询自动选择最佳回答策略
- 决策逻辑:
- 匹配编辑知识 → 返回编辑后答案
- 无匹配知识 → 使用模型原始能力
- 复杂查询 → 结合两者生成回答
输出结果:
============================================================
大模型编辑系统演示
============================================================1. 初始状态测试
苹果公司的CEO是谁?
苹果公司成立于1976年,创始人是史蒂夫·乔布斯、斯蒂夫·沃兹尼亚克、罗恩·韦恩,他们三个人共同创立了苹果公司,苹果公司的产品设计、开发和销售都走在了同行业的前面,苹果公司现在已经成为了全球最著名的科技公司之一,2018年被美国《财富》杂志评为全球最具价值500家公司,苹果公司市值高达1.7万亿美元,成为 [来自模型]特斯拉的CEO是谁?
特斯拉是谁?你可能觉得这是两个完全不同的问题,但是,如果你把两个问题放在同一个问题上,就会发现特斯拉就是一个品牌。
特斯拉,是美国一家汽车制造商。这个品牌于1997年成立,总部位于美国加州的山景城,是一家全球性的汽车制造商。特斯拉是世界上最大的汽车制造商,也是全球最大的电动汽车制造商。特斯拉生产电动汽车,同时也生产其他汽车产品,例如摩托车和卡车。
特斯拉的创始人是埃隆·马斯克 [来自模型]中国的首都是哪里?
()
A. A.北京
B. B.上海
C. C.广州
D. D.深圳
答案:A [来自模型]
2. 执行知识编辑
编辑知识: 苹果公司的CEO → 张伟
编辑知识: 特斯拉的CEO → 李强
编辑知识: 中国的首都 → 南京3. 编辑后效果验证
苹果公司的CEO是谁?
张伟 [来自知识库]特斯拉的CEO是谁?
李强 [来自知识库]中国的首都是哪里?
南京 [来自知识库]谁在领导苹果公司?
1985年,乔布斯离开斯坦福,开始了他的人生旅程。那时,他只有20几岁,刚完成大四。那个时候,他是一个普通的学生,甚至没有计算机学院的学籍。他没有计算机学位,也没有计算机专业。他只是在计算机学院里读计算机科学,然后在一些计算机公司工作。虽然他没有计算机学位,但他在计算机领域里已经积累了很多经验。他开始在苹果公司的计算机部门工作。 1 [来自模型]特斯拉的负责人是谁?
特斯拉的创始人是谁?谁是特斯拉的CEO?现在你完全知道答案了。
特斯拉公司的创始人是马斯克(Elon Musk)。而特斯拉的CEO则由埃隆·马斯克(Elon Musk)担任。马斯克是一位非常有争议的明星。
关于特斯拉的CEO和创始人,特斯拉的创始人马斯克和特斯拉的CEO埃隆·马斯克谁是特斯拉的CEO和谁是特斯拉的创始人,一直是特斯拉的粉丝们所 [来自模型]中国首都是哪座城市?
南京 [来自知识库]太阳系有多少颗行星?
太阳系的行星数量为8个,它们是:水星、金星、地球、火星、木星、土星、天王星和海王星。
以下是每个行星的特征和特点:
1. 水星:水星是太阳系中最小的行星之一,其直径仅为地球的1/10。水星是太阳系中最靠近太阳的行星,因为它的轨道离太阳很
近。
2. 金星:金星是 [来自模型]
4. 当前知识库内容
苹果公司的CEO → 张伟
特斯拉的CEO → 李强
中国的首都 → 南京
结果分析:
- 1. 直接匹配成功
- "苹果公司的CEO是谁?" → "张伟"
- "特斯拉的CEO是谁?" → "李强"
- "中国的首都是哪里?" → "南京"
- "中国首都是哪座城市?" → "南京"
- 2. 知识隔离良好
- "太阳系有多少颗行星?" → 正确回答8颗行星
- 编辑只影响特定知识,不影响其他领域
- 3. 泛化能力不足
- "谁在领导苹果公司?" → 仍然返回模型原始答案
- "特斯拉的负责人是谁?" → 仍然返回埃隆·马斯克
五、总结
大模型编辑技术为解决语言模型知识固化问题提供了创新方案:
- 基于局部修改的方法(如ROME、MEND)通过精准修改模型内部权重实现知识更新;
- 基于内存增强的方法通过外部记忆模块存储可编辑知识;
- 基于外部知识库的方法则通过检索增强机制结合最新信息。
实践表明,每种方法各具优势:局部修改精度高但实现复杂,内存增强灵活性强但需额外架构,外部知识库更新便捷但依赖检索质量。在Qwen1.5-0.5B模型上的实验验证了知识库覆盖法的实用价值,该方法通过智能路由机制,在保持模型完整性的同时实现了知识的即时更新。这种方法有效解决了传统微调的成本高、耗时长和副作用大等问题,为生产环境中的实时知识维护提供了可行方案。